
على مدار سنوات من تشغيل Kubernetes في الإنتاج ، جمعنا العديد من القصص المثيرة للاهتمام ، حيث أدت الأخطاء في مكونات النظام المختلفة إلى عواقب غير سارة و / أو غير مفهومة تؤثر على تشغيل الحاويات والقرون. في هذه المقالة ، قمنا باختيار بعض من أكثرها تكرارا أو مثيرة للاهتمام. حتى لو لم تكن محظوظًا بما يكفي لمواجهة مثل هذه المواقف ، فإن القراءة عن مثل هؤلاء المحققين الموجزين - بشكل خاص - عن كثب - هي دائما مسلية ، أليس كذلك؟
التاريخ 1. Supercronic وتجمد عامل ميناء
في إحدى المجموعات ، تلقينا بشكل دوري عامل تجميد ، والذي يتداخل مع الأداء الطبيعي للمجموعة. في الوقت نفسه ، تم ملاحظة ما يلي في سجلات Docker
level=error msg="containerd: start init process" error="exit status 2: \"runtime/cgo: pthread_create failed: No space left on device SIGABRT: abort PC=0x7f31b811a428 m=0 goroutine 0 [idle]: goroutine 1 [running]: runtime.systemstack_switch() /usr/local/go/src/runtime/asm_amd64.s:252 fp=0xc420026768 sp=0xc420026760 runtime.main() /usr/local/go/src/runtime/proc.go:127 +0x6c fp=0xc4200267c0 sp=0xc420026768 runtime.goexit() /usr/local/go/src/runtime/asm_amd64.s:2086 +0x1 fp=0xc4200267c8 sp=0xc4200267c0 goroutine 17 [syscall, locked to thread]: runtime.goexit() /usr/local/go/src/runtime/asm_amd64.s:2086 +0x1 …
في هذا الخطأ ، نحن مهتمون جدًا بالرسالة:
pthread_create failed: No space left on device . أوضحت دراسة سريعة
للوثائق أن Docker لم يتمكن من تفرع العملية ، مما تسبب في "تجميدها" بشكل دوري.
في مراقبة ما يحدث ، تتوافق الصورة التالية:

ويلاحظ موقف مماثل على العقد الأخرى:


على نفس العقد نرى:
root@kube-node-1 ~
اتضح أن هذا السلوك هو نتيجة لعمل
قرنة مع
supercronic (أداة مساعدة على الذهاب نستخدمها لتشغيل مهام cron في pods):
\_ docker-containerd-shim 833b60bb9ff4c669bb413b898a5fd142a57a21695e5dc42684235df907825567 /var/run/docker/libcontainerd/833b60bb9ff4c669bb413b898a5fd142a57a21695e5dc42684235df907825567 docker-runc | \_ /usr/local/bin/supercronic -json /crontabs/cron | \_ /usr/bin/newrelic-daemon --agent --pidfile /var/run/newrelic-daemon.pid --logfile /dev/stderr --port /run/newrelic.sock --tls --define utilization.detect_aws=true --define utilization.detect_azure=true --define utilization.detect_gcp=true --define utilization.detect_pcf=true --define utilization.detect_docker=true | | \_ /usr/bin/newrelic-daemon --agent --pidfile /var/run/newrelic-daemon.pid --logfile /dev/stderr --port /run/newrelic.sock --tls --define utilization.detect_aws=true --define utilization.detect_azure=true --define utilization.detect_gcp=true --define utilization.detect_pcf=true --define utilization.detect_docker=true -no-pidfile | \_ [newrelic-daemon] <defunct> | \_ [curl] <defunct> | \_ [curl] <defunct> | \_ [curl] <defunct> …
المشكلة هي: عندما تبدأ المهمة في supercronic ، فإن العملية الناتجة عنها
لا يمكن أن تنتهي بشكل صحيح ، وتتحول إلى
غيبوبة .
ملاحظة : لكي نكون أكثر دقة ، يتم إنشاء العمليات من خلال مهام cron ، ومع ذلك ، فإن supercronic ليس نظامًا أوليًا ولا يمكنه "تبني" العمليات التي أوجدها أطفاله. عند حدوث إشارات SIGHUP أو SIGTERM ، لا يتم إرسالها إلى العمليات الناتجة ، ونتيجة لذلك لا تنتهي العمليات الفرعية ، وتبقى في حالة الزومبي. يمكنك قراءة المزيد حول كل هذا ، على سبيل المثال ، في مثل هذه المقالة .هناك عدة طرق لحل المشكلات:
- كحل مؤقت - قم بزيادة عدد PIDs في النظام في وقت واحد:
/proc/sys/kernel/pid_max (since Linux 2.5.34) This file specifies the value at which PIDs wrap around (ie, the value in this file is one greater than the maximum PID). PIDs greater than this value are not allo‐ cated; thus, the value in this file also acts as a system-wide limit on the total number of processes and threads. The default value for this file, 32768, results in the same range of PIDs as on earlier kernels
- أو ، اجعل بدء المهام في supercronic ليس بشكل مباشر ، ولكن بمساعدة من نفس tini ، والتي هي قادرة على إكمال العمليات بشكل صحيح وليس إنشاء غيبوبة.
التاريخ 2. "الزومبي" عند إزالة مجموعة cgroup
بدأت Kubelet تستهلك الكثير من وحدة المعالجة المركزية:
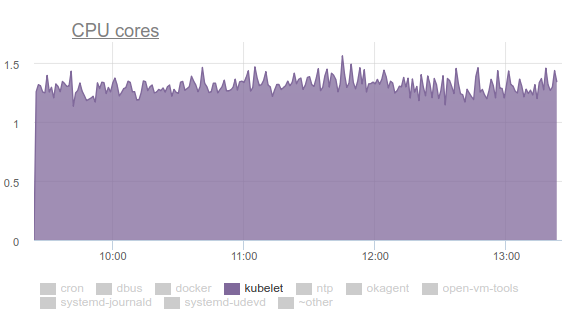
لا أحد يحب هذا ، لذلك قمنا بتسليح أنفسنا
بالكمال وبدأنا في التعامل مع المشكلة. وكانت نتائج التحقيق على النحو التالي:
- يقضي Kubelet أكثر من ثلث وقت وحدة المعالجة المركزية في سحب بيانات الذاكرة من جميع المجموعات:

- في القائمة البريدية لمطوري kernel ، يمكنك العثور على مناقشة للمشكلة . باختصار ، خلاصة القول هي أن ملفات tmpfs المختلفة وأشياء أخرى مماثلة لا يتم إزالتها بالكامل من النظام عند حذف مجموعة cgroup - ما يسمى memcg zombie . عاجلاً أم آجلاً ، سيتم إزالتها من ذاكرة التخزين المؤقت للصفحة ، ومع ذلك ، فإن الذاكرة الموجودة على الخادم كبيرة ولا ترى النواة نقطة تضييع الوقت في حذفها. لذلك ، لا تزال تتراكم. لماذا يحدث هذا حتى؟ هذا هو خادم مع وظائف كرون التي تخلق باستمرار وظائف جديدة ، ومعهم قرون جديدة. وبالتالي ، يتم إنشاء مجموعات cgroups جديدة للحاويات الموجودة بها ، والتي سيتم حذفها قريبًا.
- لماذا يقضي cAdvisor في kubelet الكثير من الوقت؟ يمكن رؤية ذلك بسهولة من خلال التنفيذ البسيط
time cat /sys/fs/cgroup/memory/memory.stat . إذا استغرقت العملية 0.01 ثانية على جهاز سليم ، ثم 1.2 ثانية على cron02 إشكالية. الشيء هو أن cAdvisor ، الذي يقرأ البيانات من sysfs ببطء شديد ، يحاول أن يأخذ في الاعتبار الذاكرة المستخدمة في zgie cgroups كذلك. - لإزالة الزومبي بالقوة ، حاولنا مسح ذاكرات التخزين المؤقت ، كما هو موصى به في LKML:
sync; echo 3 > /proc/sys/vm/drop_caches sync; echo 3 > /proc/sys/vm/drop_caches ، ولكن تبين أن النواة كانت أكثر تعقيدًا وعلقت الآلة.
ماذا تفعل؟ تم إصلاح المشكلة (
الالتزام والوصف ، راجع
رسالة الإصدار ) عن طريق تحديث Linux kernel إلى الإصدار 4.16.
التاريخ 3. SYSTEMD وجبلها
مرة أخرى ، تستهلك kubelet الكثير من الموارد على بعض العقد ، لكن هذه المرة هي الذاكرة:

اتضح أن هناك مشكلة في systemd المستخدمة في Ubuntu 16.04 ، ويحدث ذلك عند التحكم في عمليات
subPath التي تم إنشاؤها للاتصال بـ
subPath من ConfigMaps أو الأسرار. بعد اكتمال الجراب ، تظل
خدمة systemd وتثبيت الخدمة على النظام. مع مرور الوقت ، تتراكم كمية كبيرة. هناك حتى مشاكل في هذا الموضوع:
- kops # 5916 ؛
- kubernetes # 57345 .
... في آخرها تشير إلى PR في systemd:
# 7811 (المشكلة في systemd هي
# 7798 ).
لم تعد هناك مشكلة في Ubuntu 18.04 ، ولكن إذا كنت ترغب في الاستمرار في استخدام Ubuntu 16.04 ، فقد يكون حلنا بشأن هذا الموضوع مفيدًا.
لذلك ، قمنا بعمل DaemonSet التالية:
--- apiVersion: extensions/v1beta1 kind: DaemonSet metadata: labels: app: systemd-slices-cleaner name: systemd-slices-cleaner namespace: kube-system spec: updateStrategy: type: RollingUpdate selector: matchLabels: app: systemd-slices-cleaner template: metadata: labels: app: systemd-slices-cleaner spec: containers: - command: - /usr/local/bin/supercronic - -json - /app/crontab Image: private-registry.org/systemd-slices-cleaner/systemd-slices-cleaner:v0.1.0 imagePullPolicy: Always name: systemd-slices-cleaner resources: {} securityContext: privileged: true volumeMounts: - name: systemd mountPath: /run/systemd/private - name: docker mountPath: /run/docker.sock - name: systemd-etc mountPath: /etc/systemd - name: systemd-run mountPath: /run/systemd/system/ - name: lsb-release mountPath: /etc/lsb-release-host imagePullSecrets: - name: antiopa-registry priorityClassName: cluster-low tolerations: - operator: Exists volumes: - name: systemd hostPath: path: /run/systemd/private - name: docker hostPath: path: /run/docker.sock - name: systemd-etc hostPath: path: /etc/systemd - name: systemd-run hostPath: path: /run/systemd/system/ - name: lsb-release hostPath: path: /etc/lsb-release
... ويستخدم البرنامج النصي التالي:
... ويبدأ كل 5 دقائق مع supercronic المذكورة بالفعل. Dockerfile له يشبه هذا:
FROM ubuntu:16.04 COPY rootfs / WORKDIR /app RUN apt-get update && \ apt-get upgrade -y && \ apt-get install -y gnupg curl apt-transport-https software-properties-common wget RUN add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu xenial stable" && \ curl -fsSL https://download.docker.com/linux/ubuntu/gpg | apt-key add - && \ apt-get update && \ apt-get install -y docker-ce=17.03.0* RUN wget https://github.com/aptible/supercronic/releases/download/v0.1.6/supercronic-linux-amd64 -O \ /usr/local/bin/supercronic && chmod +x /usr/local/bin/supercronic ENTRYPOINT ["/bin/bash", "-c", "/usr/local/bin/supercronic -json /app/crontab"]
التاريخ 4. المنافسة في التخطيط القرون
تمت الإشارة إلى أنه: إذا تم وضع جراب على العقدة الخاصة بنا وتم ضخ صورتها لفترة طويلة جدًا ، فإن الجراب الآخر الذي "وصل" إلى العقدة نفسها ببساطة
لا يبدأ في سحب صورة الجراب الجديد . بدلاً من ذلك ، ينتظر أن يتم سحب صورة الجراب السابق. كنتيجة لذلك ، فإن الحافظة التي تم التخطيط لها بالفعل والتي يمكن تنزيل صورتها في غضون دقيقة واحدة فقط ستنتهي في حالة إنشاء
containerCreating لفترة طويلة.
في الأحداث ، سيكون هناك شيء مثل هذا:
Normal Pulling 8m kubelet, ip-10-241-44-128.ap-northeast-1.compute.internal pulling image "registry.example.com/infra/openvpn/openvpn:master"
اتضح أن
صورة واحدة من السجل البطيء يمكن أن تمنع النشر إلى العقدة.
لسوء الحظ ، لا توجد طرق كثيرة للخروج من الموقف:
- حاول استخدام Docker Registry مباشرة في الكتلة أو مباشرة مع الكتلة (على سبيل المثال ، GitLab Registry ، Nexus ، وما إلى ذلك) ؛
- استخدام المرافق مثل kraken .
التاريخ 5. تعليق العقد مع نفاد الذاكرة
أثناء تشغيل التطبيقات المختلفة ، تلقينا أيضًا موقفًا حيث يتعذر الوصول إلى العقدة تمامًا: لا يستجيب SSH ، تسقط جميع شياطين المراقبة ، ثم لا شيء (أو لا شيء تقريبًا) غير طبيعي في السجلات.
سأخبرك بالصور على مثال عقدة واحدة حيث تعمل MongoDB.
هذه هي الطريقة التي تبدو عليها
قبل الحادث:

وهكذا -
بعد الحادث:

في المراقبة أيضًا ، هناك قفزة حادة تتوقف فيها العقدة عن الوصول:
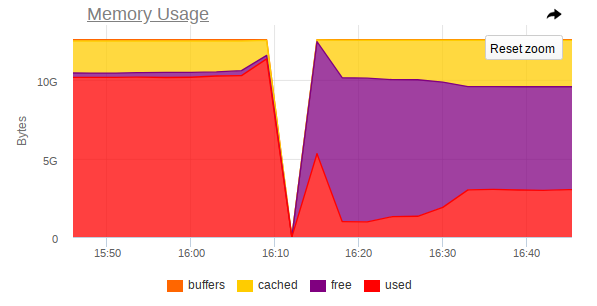
وبالتالي ، تظهر لقطات ما يلي:
- ذاكرة الوصول العشوائي على الجهاز بالقرب من النهاية.
- لوحظ حدوث قفزة حادة في استهلاك ذاكرة الوصول العشوائي ، وبعد ذلك تم تعطيل الوصول إلى الجهاز بالكامل بحدة ؛
- تصل مهمة كبيرة إلى Mongo ، مما يفرض على عملية DBMS استخدام المزيد من الذاكرة والقراءة النشطة من القرص.
اتضح أنه في حالة نفاد ذاكرة Linux (حدوث ضغط في الذاكرة) وعدم وجود تبادل ، ثم
قبل وصول قاتل OOM ، قد يحدث توازن بين إلقاء الصفحات في ذاكرة التخزين المؤقت للصفحة وإعادة كتابتها مرة أخرى على القرص. يتم ذلك بواسطة kswapd ، الذي يحرر بشجاعة أكبر عدد ممكن من صفحات الذاكرة للتوزيع لاحقًا.
لسوء الحظ ، مع وجود حمولة كبيرة من الإدخال / الإخراج ، إلى جانب مقدار صغير من الذاكرة الخالية ،
يصبح kswapd عنق الزجاجة للنظام بأكمله ، لأن
جميع أخطاء الصفحات في صفحات الذاكرة في النظام مرتبطة به. يمكن أن يستمر هذا لفترة طويلة جدًا إذا لم تعد العمليات ترغب في استخدام الذاكرة ، ولكن تم إصلاحها على حافة الهاوية القاتلة لـ OOM.
السؤال المنطقي هو: لماذا يأتي قاتل OOM متأخرا جدا؟ في التكرار الحالي لـ OOM ، يكون القاتل غبيًا للغاية: لن يقتل العملية إلا عندما تفشل محاولة تخصيص صفحة ذاكرة ، أي إذا فشل خطأ الصفحة. هذا لا يحدث لفترة طويلة ، لأن kswapd يحرر بشجاعة صفحات الذاكرة عن طريق مسح ذاكرة التخزين المؤقت للصفحة (كل القرص I / O في النظام ، في الواقع) مرة أخرى إلى القرص. بمزيد من التفصيل ، مع وصف للخطوات اللازمة للتخلص من هذه المشكلات في النواة ، يمكنك أن تقرأ
هنا .
يجب تحسين هذا السلوك باستخدام Linux 4.6+ kernel.
قصة 6. القرون هي في انتظار
في بعض المجموعات ، التي يوجد بها بالفعل العديد من القرون ، بدأنا نلاحظ أن معظمها كان معلقًا في حالة
Pending لفترة طويلة جدًا ، على الرغم من أن حاويات Docker نفسها كانت تعمل بالفعل على العقد ويمكنك العمل معها يدويًا.
لا حرج في
describe :
Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 1m default-scheduler Successfully assigned sphinx-0 to ss-dev-kub07 Normal SuccessfulAttachVolume 1m attachdetach-controller AttachVolume.Attach succeeded for volume "pvc-6aaad34f-ad10-11e8-a44c-52540035a73b" Normal SuccessfulMountVolume 1m kubelet, ss-dev-kub07 MountVolume.SetUp succeeded for volume "sphinx-config" Normal SuccessfulMountVolume 1m kubelet, ss-dev-kub07 MountVolume.SetUp succeeded for volume "default-token-fzcsf" Normal SuccessfulMountVolume 49s (x2 over 51s) kubelet, ss-dev-kub07 MountVolume.SetUp succeeded for volume "pvc-6aaad34f-ad10-11e8-a44c-52540035a73b" Normal Pulled 43s kubelet, ss-dev-kub07 Container image "registry.example.com/infra/sphinx-exporter/sphinx-indexer:v1" already present on machine Normal Created 43s kubelet, ss-dev-kub07 Created container Normal Started 43s kubelet, ss-dev-kub07 Started container Normal Pulled 43s kubelet, ss-dev-kub07 Container image "registry.example.com/infra/sphinx/sphinx:v1" already present on machine Normal Created 42s kubelet, ss-dev-kub07 Created container Normal Started 42s kubelet, ss-dev-kub07 Started container
بعد التنقيب حولنا ، افترضنا أن kubelet فقط ليس لديه وقت لإرسال خادم واجهة برمجة التطبيقات (API) لجميع المعلومات المتعلقة بحالة القرون وعينات الصلاحية / الاستعداد.
وبعد دراسة المساعدة ، وجدنا المعايير التالية:
--kube-api-qps - QPS to use while talking with kubernetes apiserver (default 5) --kube-api-burst - Burst to use while talking with kubernetes apiserver (default 10) --event-qps - If > 0, limit event creations per second to this value. If 0, unlimited. (default 5) --event-burst - Maximum size of a bursty event records, temporarily allows event records to burst to this number, while still not exceeding event-qps. Only used if --event-qps > 0 (default 10) --registry-qps - If > 0, limit registry pull QPS to this value. --registry-burst - Maximum size of bursty pulls, temporarily allows pulls to burst to this number, while still not exceeding registry-qps. Only used if --registry-qps > 0 (default 10)
كما ترون ،
القيم الافتراضية صغيرة جدًا ، وفي 90٪ تغطي جميع الاحتياجات ... ومع ذلك ، في حالتنا هذه لم تكن كافية. لذلك ، نضع هذه القيم:
--event-qps=30 --event-burst=40 --kube-api-burst=40 --kube-api-qps=30 --registry-qps=30 --registry-burst=40
... وأعد تشغيل kubelets ، وبعد ذلك رأوا الصورة التالية على الرسوم البيانية للوصول إلى خادم API:

... ونعم ، كل شيء بدأ يطير!
PS
للمساعدة في جمع الأخطاء وإعداد المقالة ، أعرب عن عميق امتناني للمهندسين العديدين لشركتنا ، ولا سيما أندريه كليمينيف (زميل من فريق البحث والتطوير) (
zuzzas ).
PPS
اقرأ أيضًا في مدونتنا: