مرحبا يا هبر!
اسمي أنطون ماركيلوف ، أنا مهندس خدمات في شركة يونايتد تريدرز. نحن منخرطون في مشاريع بطريقة أو بأخرى مرتبطة بالاستثمارات والبورصات وغيرها من المسائل المالية. نحن لسنا شركة كبيرة للغاية ، ونحو 30 مهندس تطوير ، والمقاييس مناسبة - أقل بقليل من مائة خوادم. أثناء النمو الكمي والنوعي لبنيتنا التحتية ، توقف الحل الكلاسيكي "نبقي كل من التطبيق وقاعدة البيانات الخاصة به على نفس الخادم" ليناسبنا سواء من حيث الموثوقية والسرعة. من جانب المحللين ، كانت هناك حاجة لإنشاء استعلامات قاعدة بيانات مشتركة ، فقد سئم قسم التشغيل من العبث مع النسخ الاحتياطي ومراقبة عدد كبير من خوادم قاعدة البيانات. علاوة على ذلك ، فإن تخزين الحالة على نفس الجهاز مثل التطبيق نفسه يقلل بدرجة كبيرة من مرونة تخطيط الموارد ومرونة البنية التحتية.
كانت عملية الانتقال إلى البنية الحالية تطورية ، وتم اختبار حلول مختلفة لتوفير واجهة مريحة للمطورين والمحللين ، ولزيادة موثوقية هذا الاقتصاد برمته وإدارته. أريد أن أتحدث عن المراحل الرئيسية لتحديث قواعد بيانات إدارة قواعد البيانات الخاصة بنا ، وما الذي أحدثناه وما هي القرارات التي توصلنا إليها ، ونتيجة لذلك ، بيئة مستقلة تتسامح مع الأخطاء توفر طرقًا مريحة للتفاعل مع مهندسي التشغيل والمطورين والمحللين. آمل أن تكون تجربتنا مفيدة للمهندسين من الشركات ذات الحجم الكبير.
هذه المقالة هي ملخص لتقريري في مؤتمر UPTIMEDAY ، وربما يكون تنسيق الفيديو أكثر راحة لشخص ما ، على الرغم من أن الكاتب أفضل بيدي قليلاً من المتكلم الفم.
تم
استعارة "رجل ندفة الثلج" مع KDPV دون خجل من مكسيم دوروفيف.
أمراض النمو
لدينا بنية microservice ، تتم كتابة الخدمات بشكل رئيسي في Java أو Kotlin باستخدام إطار Spring. بجانب كل خدمة microservice توجد قاعدة PostgreSQL ، كل شيء يتم تغطيته بواسطة nginx في الأعلى لتوفير الوصول. يعد microservice النموذجي تطبيقًا على Spring Boot يقوم بكتابة بياناته إلى PostgreSQL (جزء من التطبيقات في نفس الوقت وإلى ClickHouse) ، ويتواصل مع الجيران من خلال Kafka ويحتوي على بعض نقاط REST أو GraphQL للتواصل مع العالم الخارجي.
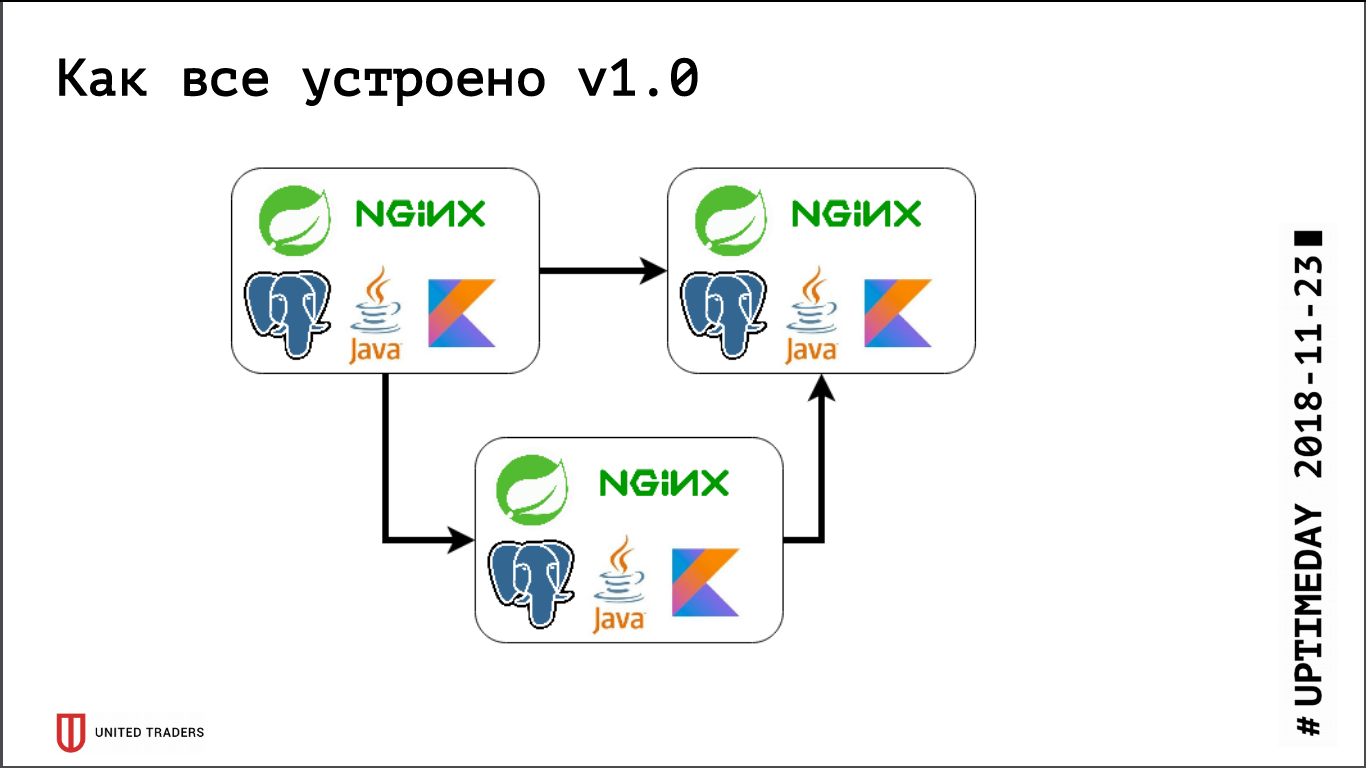
في السابق ، عندما كنا صغيرين للغاية ، احتفظنا فقط بعدة خوادم في DigitalOcean ، لم يكن كافكا موجودًا بعد ، كل الاتصالات كانت من خلال REST. وهذا هو ، أخذنا جافا ، تثبيت Java ، PostgreSQL ، nginx هناك ، أطلق Zabbix هناك ، بحيث يراقب موارد الخادم وتوافر نقاط نهاية الخدمة. لقد نشروا كل شيء بمساعدة Ansible ، كان لدينا قواعد لعب موحدة ، وأربعة إلى خمسة أدوار عرضت الخدمة بأكملها. طالما كان لدينا ، على سبيل المثال ، 6 خوادم قيد الإنتاج و 3 خوادم في الاختبار - يمكنك التعايش معها بطريقة أو بأخرى.
ثم بدأت مرحلة التطوير النشط ، وتزايد عدد التطبيقات ، وتحولت عشر خدمات ميكروية إلى أربعين وظيفة ، وبدأت وظائفها تتغير ، بالإضافة إلى التكامل مع الأنظمة الخارجية مثل CRM ومواقع العملاء وما شابه ذلك. حصلنا على الألم الأول. بدأت بعض التطبيقات تستهلك المزيد من الموارد ، وتوقفت عن الوصول إلى الخوادم الحالية ، وحصلنا على قطرات ، وجرنا التطبيقات ذهابًا وإيابًا ، واخترنا الكثير من الأيدي. إن الأمر مؤلم للغاية - لا أحد يحب الأعمال الميكانيكية الغبية ، - أردت أن أقرر بسرعة. لذلك ذهبنا وجهاً لوجه - أخذنا للتو 3 خوادم كبيرة مخصصة بدلاً من 10 قطرات سحابية. أدى هذا إلى إغلاق المشكلة لفترة من الوقت ، ولكن أصبح من الواضح أن الوقت قد حان للتوصل إلى خيارات لنوع ما من إعادة تزامن وإعادة توازن الخادم. بدأنا ننظر عن كثب إلى حلول مثل DC / OS و Kubernetes ، ونزيد تدريجياً خبرتنا في هذا المجال.
في نفس الوقت تقريبًا ، كان لدينا قسم تحليلي ، والذي كان يحتاج إلى تقديم طلبات صعبة بانتظام ، وإعداد التقارير ، ولوحة القيادة الجميلة ، وهذا جلب لنا الألم الثاني. أولاً ، قام المحللون بتحميل القاعدة بشدة ، وثانياً ، كانوا بحاجة إلى استعلامات قواعد البيانات المشتركة ، لأن أبقى كل microservice شريحة بيانات ضيقة إلى حد ما. لقد اختبرنا العديد من الأنظمة ، أولاً حاولنا حلها جميعًا من خلال النسخ المتماثل على مستوى الجدول (كان مرة أخرى في PostgreSQL التاسع ، ولم يكن هناك نسخ متماثل منطقي من الصندوق) ، لكن الحرف الناتجة الناتجة عن pglogical و Presto و Slony-I و Bucardo لم رتبت. على سبيل المثال ، لم يدعم pglogical الترحيل - تم طرح نسخة جديدة من الخدمة المجهرية ، وتغير هيكل قاعدة البيانات ، و Java نفسها غيرت الهيكل باستخدام Flyway ، وعلى النسخ المتماثلة في pglogical ، يجب تغيير كل شيء يدويًا. خلاف ذلك ، إما كان هناك شيء مفقود ، أو كان من الصعب للغاية.
سوبر الرقيق
كنتيجة للبحث ، تم إنشاء حل بسيط ووحشي يسمى Superslave: أخذنا خادمًا منفصلاً ، وتم تكوينه كعبد لكل خادم إنتاج على منافذ مختلفة ، وإنشاء قاعدة بيانات افتراضية تجمع بين قواعد البيانات من العبيد عبر postgres_fdw (مجمع بيانات أجنبي). وهذا هو ، تم تنفيذ كل هذا عن طريق وسائل postgres القياسية دون تقديم كيانات إضافية ، ببساطة وبشكل موثوق: مع طلب واحد كان من الممكن الحصول على البيانات من عدة قواعد بيانات. قدمنا هذا crossbase الظاهري للمحللين. ميزة إضافية هي أن النسخة المتماثلة للقراءة فقط ، حتى مع وجود خطأ في حقوق الوصول ، لا يمكنها كتابة أي شيء هناك.
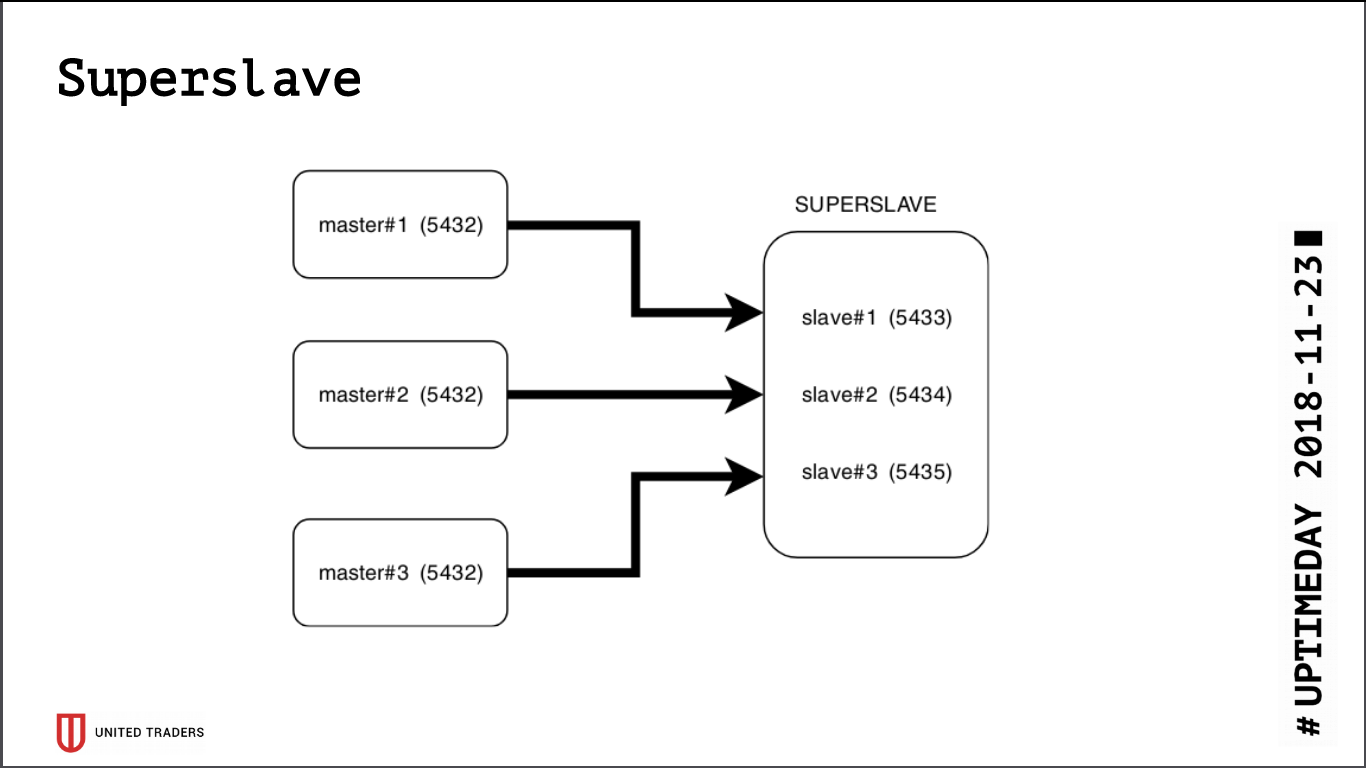
أخذنا
Redash للتصور ، فهو يعرف كيفية رسم الرسوم البيانية ، وتنفيذ الطلبات على جدول ، على سبيل المثال مرة واحدة في اليوم ، ولديه نظام وافر من الحقوق ، لذلك نسمح للمحللين والمطورين بالذهاب إلى هناك.

في موازاة ذلك ، استمر النمو ، ظهر Kafka في البنية التحتية كحافلة و ClickHouse لتخزين التحليلات. يتم تجميعها بسهولة من خارج منطقة الجزاء ، بدا عبيدنا الفائق على خلفيتهم وكأنه حفرية خرقاء. بالإضافة إلى ذلك ، بقي PostgreSQL ، في الواقع ، الحالة الوحيدة التي يجب سحبها بعد التطبيق (إذا كان لا يزال يتعين نقلها إلى خادم آخر) ، وأردنا حقًا الحصول على تطبيق عديم الجنسية للدخول عن كثب في تجارب مع Kubernetes وله منصات مماثلة.
بدأنا نبحث عن حل يلبي المتطلبات التالية:
- خطأ التسامح: عندما تسقط خوادم N ، تواصل الكتلة العمل ؛
- للتطبيقات ، يجب أن يبقى كل شيء كما كان من قبل ، لا توجد تغييرات في الكود ؛
- سهولة النشر والإدارة ؛
- عدد أقل من طبقات التجريد عبر PostgreSQL العادية ؛
- مثالي ، تحميل موازنة بحيث لا تذهب جميع الطلبات إلى خادم واحد ؛
- من الناحية المثالية ، هو مكتوب بلغة مألوفة.
لم يكن هناك الكثير من المرشحين:
- تكرار النسخ المتماثل القياسي (repmgr ، Patroni ، Stolon) ؛
- النسخ المتماثل القائم على الزناد (لونديست ، سلوني) ؛
- تكرار استعلام الطبقة الوسطى (pgpool-II) ؛
- النسخ المتماثل متزامن مع خوادم متعددة النواة (بوكاردو).
مع جزء كبير ، كان لدينا بالفعل تجارب سيئة أثناء بناء crossbase ، لذلك بقي Patroni و Stolon. كتب Patroni في Python ، Stolon in Go ، ولدينا خبرة كافية في اللغتين. علاوة على ذلك ، لديهم بنية ووظائف متشابهة ، لذلك تم الاختيار لأسباب ذاتية: تم تطوير Patroni بواسطة Zalando ، وحاولنا ذات مرة العمل مع مشروع Nakadi (REST API for Kafka) ، حيث واجهنا نقصًا حادًا في الوثائق.
Stolon
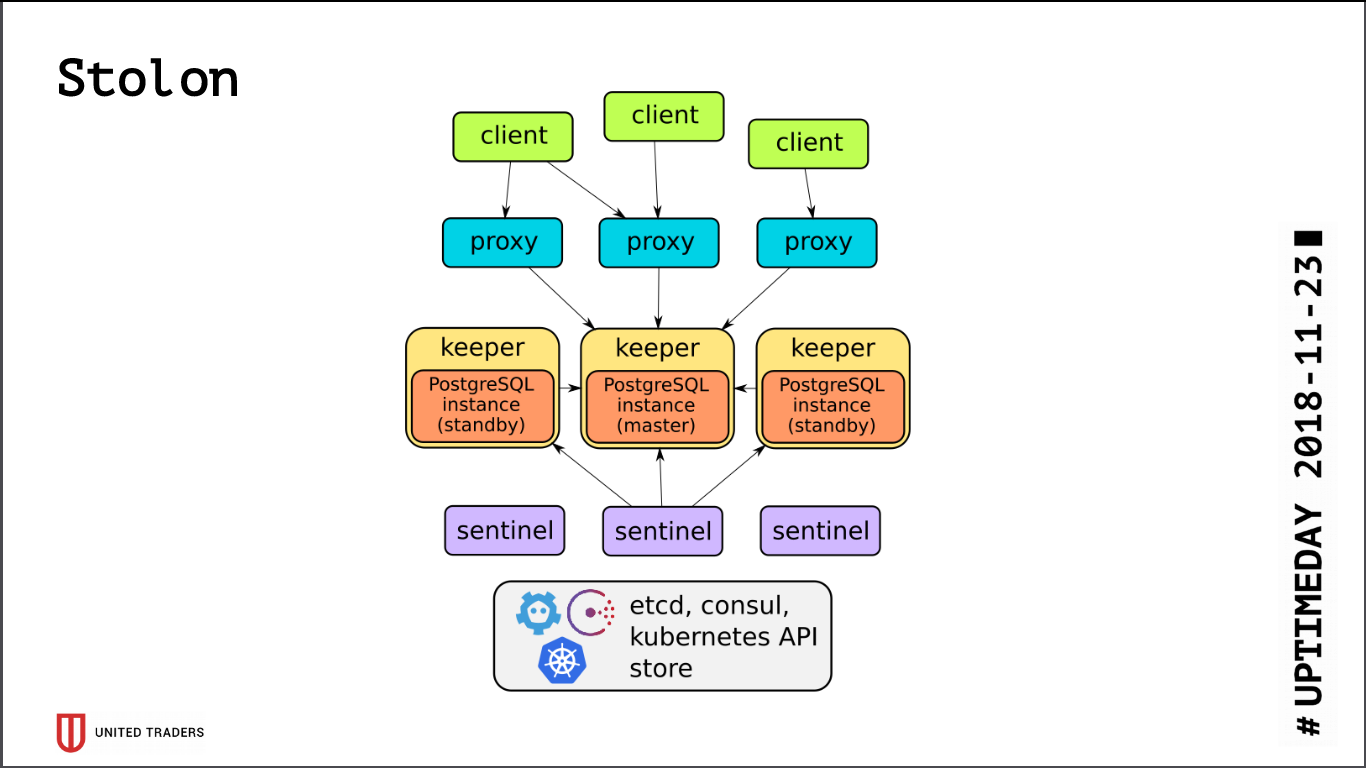
بنية
Stolon بسيطة للغاية: هناك خوادم N ، ويتم اختيار الرائد باستخدام etcd / القنصل ، يتم تشغيل PostgreSQL في وضع المعالج وتكرارها إلى خوادم أخرى. ثم ينتقل وكلاء البروتوكولات stolon إلى برنامج PostgreSQL-master هذا ، متظاهرين بأنهم تطبيقات مع postgres عادية ، ويذهب العملاء إلى هؤلاء الوكلاء. في حالة اختفاء السيد ، تتم إعادة الانتخاب ، ويصبح شخص آخر سيدًا ، والباقي في وضع الاستعداد. هناك القليل من طبقات التجريد ، يتم تثبيت PostgreSQL كالمعتاد ، والتحذير الوحيد هو أن تنسيق PostgreSQL يتم تخزينه في etcd ، ويتم تكوينه بشكل مختلف إلى حد ما.
عند اختبار المجموعة ، اكتشفنا بعض المشكلات:
- لا يعرف Stolon كيفية العمل على ZooKeeper أو القنصل أو غيرها فقط ؛
- etcd حساسة للغاية IO. إذا احتفظت بوظيفة PostgreSQL و etcd على نفس الخادم ، فستحتاج بالتأكيد إلى محركات أقراص صلبة سريعة.
- حتى في SSD ، من الضروري تكوين مهلات الخ ، وإلا فكل شيء سينهار تحت الحمل - ستعتقد المجموعة أن السيد قد توقف وانقطع الاتصال باستمرار ؛
- بشكل افتراضي ، يكون max_connections على PostgreSQL صغيرًا (200) ، تحتاج إلى زيادته حسب احتياجاتك ؛
- سوف تتخطى مجموعة من ثلاثة etcd وفاة خادم واحد فقط ، ومن الأفضل أن يكون لديك تكوين ، على سبيل المثال 5 etcd + 3 Stolon ؛
- خارج الصندوق ، جميع الاتصالات تذهب إلى السيد ، والعبيد لا يمكن الوصول إلى الاتصال.
نظرًا لأن جميع الاتصالات بـ PostgreSQL تنتقل إلى المعالج ، فإننا نواجه مشكلة في طلبات التحليل الكثيفة مرة أخرى. رد فعل مؤلم في بعض الأحيان إلى الحمل الكبير على السيد وتبديله. ويؤدي تبديل المعالج إلى قطع الاتصالات دائمًا. تم إعادة تشغيل الطلب ، وبدأ كل شيء من جديد. للحصول على حل بديل ، تم كتابة
برنامج نصي Python طلب عناوين stolonctl من العبيد الحية وإنشاء تكوين لـ HAProxy ، مع إعادة توجيه الطلبات إليهم.
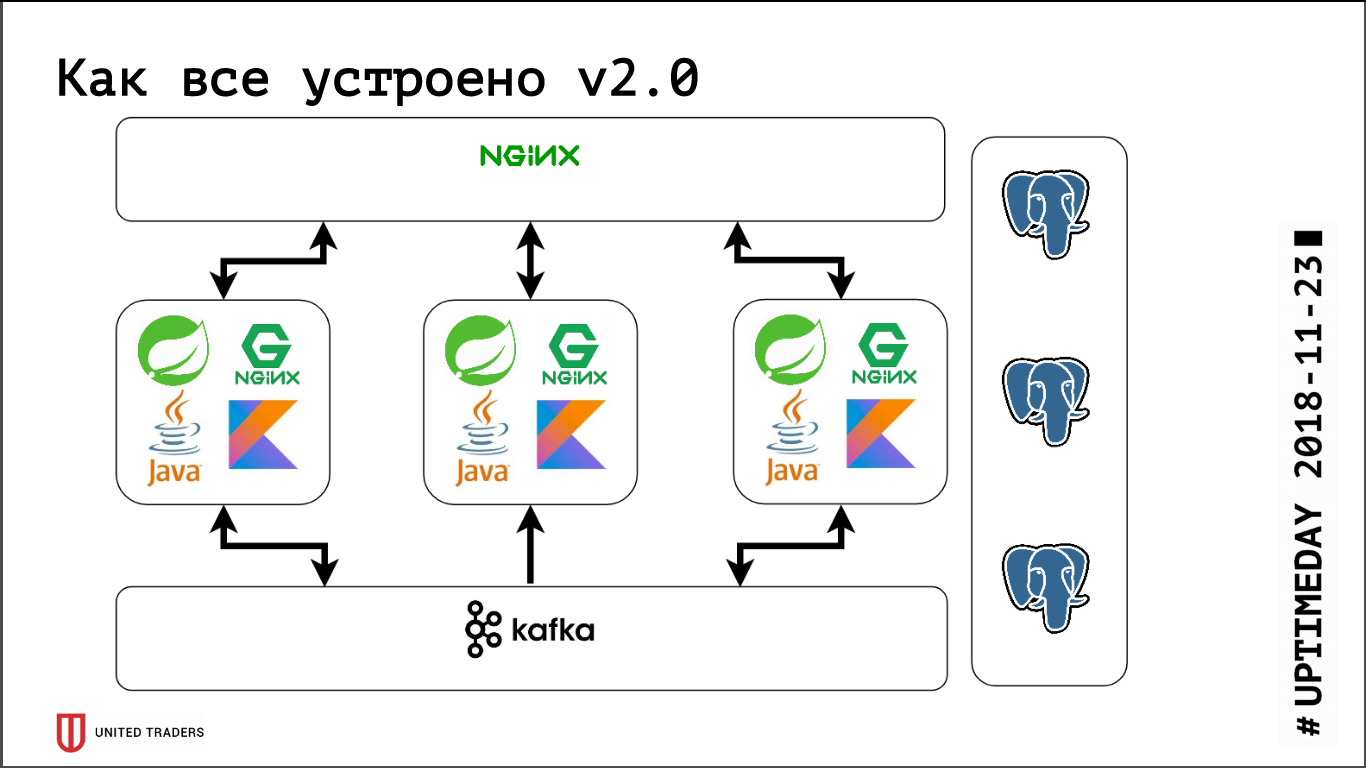
تم إيقاف الصورة التالية: تذهب الطلبات من التطبيقات إلى منفذ الوكيل stolon ، الذي يعيد توجيهها إلى الرئيسي ، وتذهب الطلبات من المحللين (وهم دائمًا للقراءة فقط) إلى منفذ HAProxy ، الذي يرميهم إلى بعض الرقيق.
أيضًا ، حرفيًا اليوم ، تم اعتماد PR في Stolon ، مما سمح بإرسال معلومات حول مثيلات Stolon إلى اكتشاف خدمة تابع لجهة خارجية.
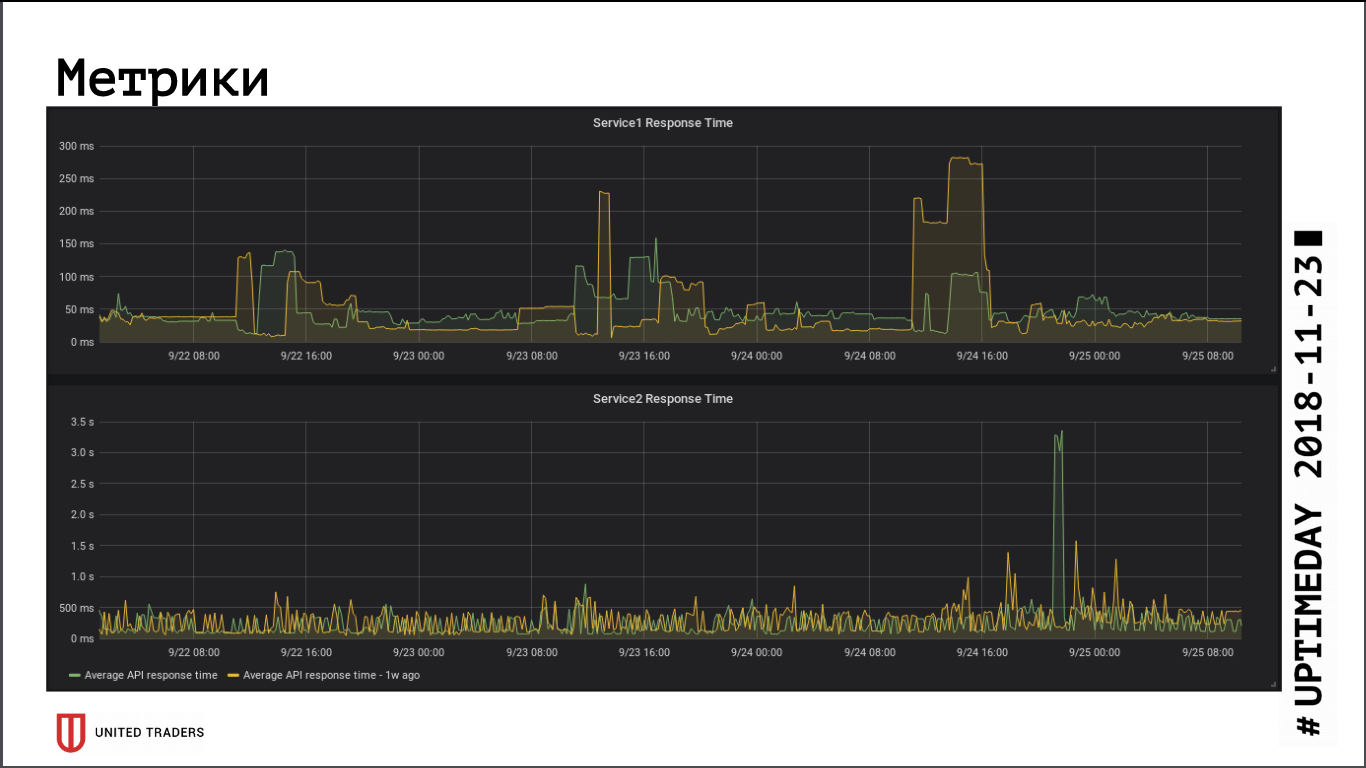
بقدر ما نستنتج من مقاييس سرعة استجابة التطبيق ، فإن الانتقال إلى كتلة بعيدة لم يكن له تأثير كبير على الأداء ، لم يتغير متوسط وقت الاستجابة. تم تعويض زمن الوصول الناتج عن الشبكة ، على ما يبدو ، عن طريق حقيقة أن قاعدة البيانات موجودة الآن على خادم مخصص.
Stolon دون مشاكل ينجو من تعطل المعالج (فقدان الخادم ، وفقدان الشبكة ، وفقدان القرص) ، عندما يأتي الخادم إلى الحياة - يقوم تلقائيًا بإعادة تعيين النسخة المتماثلة. أضعف نقطة في Stolon هي الخ ، وضعت الفشل في ذلك الكتلة. كان لدينا حادث نموذجي: مجموعة من ثلاثة العقد الخ ، تم قطع اثنين. كل شيء ، تم كسر النصاب القانوني ، الخ في حالة غير صحية ، لا تقبل مجموعة Stolon أي اتصالات ، بما في ذلك الطلبات من stolonctl. نظام الاسترداد: قم بتشغيل etcd على الخادم الباقي إلى كتلة عقدة واحدة ، ثم أضف الأعضاء مرة أخرى. الخلاصة: من أجل البقاء على قيد الحياة بعد وفاة اثنين من الخوادم ، يجب أن يكون لديك ما لا يقل عن 5 حالات الخ.
رصد الأخطاء واصطيادها
مع نمو البنية التحتية وتعقيد الخدمات المصغرة ، أردت جمع مزيد من المعلومات حول ما يحدث داخل التطبيق وجهاز Java. لم نتمكن من تكييف Zabbix مع البيئة الجديدة: إنه غير مريح للغاية في ظروف البنية التحتية المتغيرة. اضطررت إما إلى طحن عكازين من خلال واجهة برمجة التطبيقات (API) ، أو تسلقها بيدي ، وهو أمر أسوأ. قاعدة بياناتها غير ملائمة بشكل جيد للأحمال الثقيلة ، وبشكل عام ، من غير المريح وضع كل هذا في قاعدة بيانات علائقية.
نتيجة لذلك ، اخترنا بروميثيوس للرصد. لديه مشغل خارج الصندوق لتطبيقات Spring لتوفير المقاييس ، بالنسبة إلى Kafka قاموا بتفكيك JMX Exporter ، والذي يوفر أيضًا المقاييس بطريقة مريحة. هؤلاء المصدرين الذين لم يتم العثور عليهم "في المربع" ، كتبنا أنفسنا في بيثون ، هناك حوالي عشرة منهم. نحن نتصور Grafana ، وجمع السجلات مع Graylog (لأنه يدعم الآن Beats).
نستخدم
ترقب لجمع الأخطاء. يكتب كل شيء في شكل منظم ، يرسم الرسوم البيانية ، ويظهر ما حدث في كثير من الأحيان ، في كثير من الأحيان أقل. عادةً ما يذهب المطورون إلى Sentry فورًا بعد النشر ، معرفة ما إذا كان هناك أي ذروة ، أو هناك حاجة ماسة إلى التراجع. اتضح للقبض على الأخطاء بسرعة دون انتقاء السجلات.
كل هذا في الوقت الحالي ، إذا كان تنسيق المقالات يناسب القراء ، فسوف نستمر في الحديث عن بنيتنا الأساسية ، فلا يزال هناك الكثير من المرح: حلول كافكا والتحليلات للأحداث التي تمر بها ، قناة CI / CD لتطبيقات Windows والمغامرات مع Openshift.