
الجزء 1/3 هنا .
الجزء 2/3 هنا .
مرحبا بالجميع! وهنا هو الجزء الثالث من Kubernetes على دليل المعادن العارية! سأنتبه إلى مراقبة الكتلة وجمع السجلات ، وسنقوم أيضًا بتشغيل تطبيق اختبار لاستخدام مكونات نظام المجموعة المُعدة مسبقًا. ثم سنقوم بإجراء العديد من اختبارات الإجهاد والتحقق من ثبات نظام الكتلة هذا.
الأداة الأكثر شعبية التي يقدمها مجتمع Kubernetes لتوفير واجهة على شبكة الإنترنت والحصول على إحصائيات نظام المجموعة هي لوحة معلومات Kubernetes . في الواقع ، لا يزال قيد التطوير ، ولكن حتى الآن يمكنه توفير بعض البيانات الإضافية لاستكشاف مشكلات التطبيق وإدارة موارد نظام المجموعة.
الموضوع مثير للجدل جزئيا. هل صحيح أنك تحتاج إلى نوع من واجهة الويب لإدارة الكتلة ، أم أنها كافية لاستخدام أداة وحدة التحكم kubectl ؟ حسنا ، في بعض الأحيان هذه الخيارات تكمل بعضها البعض.
دعونا توسيع لوحة Kubernetes لدينا ونرى. عند النشر القياسي ، ستبدأ لوحة المعلومات هذه فقط على عنوان المضيف المحلي. وبالتالي ، تحتاج إلى استخدام الأمر kubectl proxy للتوسع ، لكنه لا يزال متاحًا فقط على جهاز التحكم kubectl المحلي. ليس سيئًا من وجهة نظر الأمان ، لكنني أرغب في الوصول إلى المستعرض ، خارج المجموعة ، وأنا مستعد لتحمل بعض المخاطر (بعد كل شيء ، يتم استخدام ssl مع رمز مميز فعال).
لتطبيق طريقة عملي ، تحتاج إلى تعديل ملف النشر القياسي في قسم الخدمة قليلاً. لفتح لوحة المعلومات هذه على عنوان مفتوح ، نستخدم موازن التحميل لدينا.
ندخل نظام الجهاز باستخدام الأداة المساعدة kubectl المكوّنة وننشئ :
control# vi kube-dashboard.yaml # Copyright 2017 The Kubernetes Authors. # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # ------------------- Dashboard Secret ------------------- # apiVersion: v1 kind: Secret metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard-certs namespace: kube-system type: Opaque --- # ------------------- Dashboard Service Account ------------------- # apiVersion: v1 kind: ServiceAccount metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard namespace: kube-system --- # ------------------- Dashboard Role & Role Binding ------------------- # kind: Role apiVersion: rbac.authorization.k8s.io/v1 metadata: name: kubernetes-dashboard-minimal namespace: kube-system rules: # Allow Dashboard to create 'kubernetes-dashboard-key-holder' secret. - apiGroups: [""] resources: ["secrets"] verbs: ["create"] # Allow Dashboard to create 'kubernetes-dashboard-settings' config map. - apiGroups: [""] resources: ["configmaps"] verbs: ["create"] # Allow Dashboard to get, update and delete Dashboard exclusive secrets. - apiGroups: [""] resources: ["secrets"] resourceNames: ["kubernetes-dashboard-key-holder", "kubernetes-dashboard-certs"] verbs: ["get", "update", "delete"] # Allow Dashboard to get and update 'kubernetes-dashboard-settings' config map. - apiGroups: [""] resources: ["configmaps"] resourceNames: ["kubernetes-dashboard-settings"] verbs: ["get", "update"] # Allow Dashboard to get metrics from heapster. - apiGroups: [""] resources: ["services"] resourceNames: ["heapster"] verbs: ["proxy"] - apiGroups: [""] resources: ["services/proxy"] resourceNames: ["heapster", "http:heapster:", "https:heapster:"] verbs: ["get"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: kubernetes-dashboard-minimal namespace: kube-system roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: kubernetes-dashboard-minimal subjects: - kind: ServiceAccount name: kubernetes-dashboard namespace: kube-system --- # ------------------- Dashboard Deployment ------------------- # kind: Deployment apiVersion: apps/v1 metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard namespace: kube-system spec: replicas: 1 revisionHistoryLimit: 10 selector: matchLabels: k8s-app: kubernetes-dashboard template: metadata: labels: k8s-app: kubernetes-dashboard spec: containers: - name: kubernetes-dashboard image: k8s.gcr.io/kubernetes-dashboard-amd64:v1.10.1 ports: - containerPort: 8443 protocol: TCP args: - --auto-generate-certificates # Uncomment the following line to manually specify Kubernetes API server Host # If not specified, Dashboard will attempt to auto discover the API server and connect # to it. Uncomment only if the default does not work. # - --apiserver-host=http://my-address:port volumeMounts: - name: kubernetes-dashboard-certs mountPath: /certs # Create on-disk volume to store exec logs - mountPath: /tmp name: tmp-volume livenessProbe: httpGet: scheme: HTTPS path: / port: 8443 initialDelaySeconds: 30 timeoutSeconds: 30 volumes: - name: kubernetes-dashboard-certs secret: secretName: kubernetes-dashboard-certs - name: tmp-volume emptyDir: {} serviceAccountName: kubernetes-dashboard # Comment the following tolerations if Dashboard must not be deployed on master tolerations: - key: node-role.kubernetes.io/master effect: NoSchedule --- # ------------------- Dashboard Service ------------------- # kind: Service apiVersion: v1 metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard namespace: kube-system spec: type: LoadBalancer ports: - port: 443 targetPort: 8443 selector: k8s-app: kubernetes-dashboard
ثم ركض:
control# kubectl create -f kube-dashboard.yaml control# kubectl get svc --namespace=kube-system kubernetes-dashboard LoadBalancer 10.96.164.141 192.168.0.240 443:31262/TCP 8h
حسنًا ، كما ترون ، أضاف BN عنوان IP 192.168.0.240 لهذه الخدمة. الآن حاول فتح https://192.168.0.240 لعرض Kubernetes Dashboard.
هناك طريقتان للوصول: استخدام ملف admin.conf من العقدة الرئيسية ، والذي استخدمناه مسبقًا عند إعداد kubectl ، أو إنشاء حساب خدمة خاص برمز أمان.
لنقم بإنشاء مستخدم مسؤول:
control# vi kube-dashboard-admin.yaml apiVersion: v1 kind: ServiceAccount metadata: name: admin-user namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1beta1 kind: ClusterRoleBinding metadata: name: admin-user roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: cluster-admin subjects: - kind: ServiceAccount name: admin-user namespace: kube-system control# kubectl create -f kube-dashboard-admin.yaml serviceaccount/admin-user created clusterrolebinding.rbac.authorization.k8s.io/admin-user created
أنت الآن بحاجة إلى رمز مميز لدخول النظام:
control# kubectl -n kube-system describe secret $(kubectl -n kube-system get secret | grep admin-user | awk '{print $1}') Name: admin-user-token-vfh66 Namespace: kube-system Labels: <none> Annotations: kubernetes.io/service-account.name: admin-user kubernetes.io/service-account.uid: 3775471a-3620-11e9-9800-763fc8adcb06 Type: kubernetes.io/service-account-token Data ==== ca.crt: 1025 bytes namespace: 11 bytes token: erJhbGciOiJSUzI1NiIsImtpZCI6IiJ9.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwna3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJr dWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi11c2VmLXRva2VuLXZmaDY2Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZ XJ2aWNlLWFjY291bnQubmFtZSI6ImFkbWluLXVzZXIiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiIzNzc1NDcxYS0zNjIwLTExZTktOTgwMC03Nj NmYzhhZGNiMDYiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZS1zeXN0ZW06YWRtaW4tdXNlciJ9.JICASwxAJHFX8mLoSikJU1tbij4Kq2pneqAt6QCcGUizFLeSqr2R5x339ZR8W4 9cIsbZ7hbhFXCATQcVuWnWXe2dgXP5KE8ZdW9uvq96rm_JvsZz0RZO03UFRf8Exsss6GLeRJ5uNJNCAr8No5pmRMJo-_4BKW4OFDFxvSDSS_ZJaLMqJ0LNpwH1Z09SfD8TNW7VZqax4zuTSMX_yVS ts40nzh4-_IxDZ1i7imnNSYPQa_Oq9ieJ56Q-xuOiGu9C3Hs3NmhwV8MNAcniVEzoDyFmx4z9YYcFPCDIoerPfSJIMFIWXcNlUTPSMRA-KfjSb_KYAErVfNctwOVglgCISA
انسخ الرمز المميز والصقه في حقل الرمز المميز على شاشة تسجيل الدخول.
بعد الدخول إلى النظام ، يمكنك دراسة المجموعة بعمق أكبر - أحب هذه الأداة.
والخطوة التالية نحو تعميق نظام مراقبة مجموعتنا هي تثبيت heapster .
يسمح لك Heapster بمراقبة كتلة الحاوية وتحليل أداء Kubernetes (الإصدار v1.0.6 والإصدارات الأحدث). إنه يوفر منصات مناسبة.
تقدم هذه الأداة إحصائيات حول استخدام الكتلة من خلال وحدة التحكم ، وتضيف أيضًا مزيدًا من المعلومات حول موارد العقدة والموقد إلى لوحة معلومات Kubernetes.
هناك صعوبة كبيرة في تثبيته على المعدن العاري ، وكنت بحاجة لإجراء بعض التحقيقات: لماذا لا تعمل الأداة في الإصدار الأصلي ، لكنني وجدت حلاً.
لذلك دعونا نواصل ونؤيد هذه الإضافة:
control# vi heapster.yaml apiVersion: v1 kind: ServiceAccount metadata: name: heapster namespace: kube-system --- apiVersion: extensions/v1beta1 kind: Deployment metadata: name: heapster namespace: kube-system spec: replicas: 1 template: metadata: labels: task: monitoring k8s-app: heapster spec: serviceAccountName: heapster containers: - name: heapster image: gcr.io/google_containers/heapster-amd64:v1.4.2 imagePullPolicy: IfNotPresent command: - /heapster - --source=kubernetes.summary_api:''?useServiceAccount=true&kubeletHttps=true&kubeletPort=10250&insecure=true --- apiVersion: v1 kind: Service metadata: labels: task: monitoring # For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons) # If you are NOT using this as an addon, you should comment out this line. kubernetes.io/cluster-service: 'true' kubernetes.io/name: Heapster name: heapster namespace: kube-system spec: ports: - port: 80 targetPort: 8082 selector: k8s-app: heapster --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1beta1 metadata: name: heapster roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:heapster subjects: - kind: ServiceAccount name: heapster namespace: kube-system
هذا هو ملف النشر القياسي الأكثر شيوعًا من مجتمع Heapster ، مع اختلاف بسيط فقط: لكي يعمل على نظامنا ، يتم تغيير السطر " source = " في نشر heapster كما يلي:
--source=kubernetes.summary_api:''?useServiceAccount=true&kubeletHttps=true&kubeletPort=10250&insecure=true
في هذا الوصف ، ستجد كل هذه الخيارات. لقد غيرت منفذ kubelet إلى 10250 وأوقفت التحقق من شهادة SSL (كانت هناك مشكلة صغيرة في ذلك).
نحتاج أيضًا إلى إضافة أذونات للحصول على إحصائيات العقدة في دور Heapster RBAC ؛ أضف هذه الأسطر القليلة في نهاية الدور:
control# kubectl edit clusterrole system:heapster ...... ... - apiGroups: - "" resources: - nodes/stats verbs: - get
باختصار ، يجب أن يبدو دورك في RBAC كما يلي:
# Please edit the object below. Lines beginning with a '#' will be ignored, # and an empty file will abort the edit. If an error occurs while saving this file will be # reopened with the relevant failures. # apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: annotations: rbac.authorization.kubernetes.io/autoupdate: "true" creationTimestamp: "2019-02-22T18:58:32Z" labels: kubernetes.io/bootstrapping: rbac-defaults name: system:heapster resourceVersion: "6799431" selfLink: /apis/rbac.authorization.k8s.io/v1/clusterroles/system%3Aheapster uid: d99065b5-36d3-11e9-a7e6-763fc8adcb06 rules: - apiGroups: - "" resources: - events - namespaces - nodes - pods verbs: - get - list - watch - apiGroups: - extensions resources: - deployments verbs: - get - list - watch - apiGroups: - "" resources: - nodes/stats verbs: - get
حسنًا ، لنقم الآن بتشغيل الأمر للتأكد من بدء عملية النشر بنجاح.
control# kubectl top node NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% kube-master1 183m 9% 1161Mi 60% kube-master2 235m 11% 1130Mi 59% kube-worker1 189m 4% 1216Mi 41% kube-worker2 218m 5% 1290Mi 44% kube-worker3 181m 4% 1305Mi 44%
حسنًا ، إذا تلقيت بعض البيانات عن الإخراج ، فسيتم كل شيء بشكل صحيح. دعنا نعود إلى صفحة لوحة المعلومات الخاصة بنا وتحقق من الرسوم البيانية الجديدة المتاحة الآن.
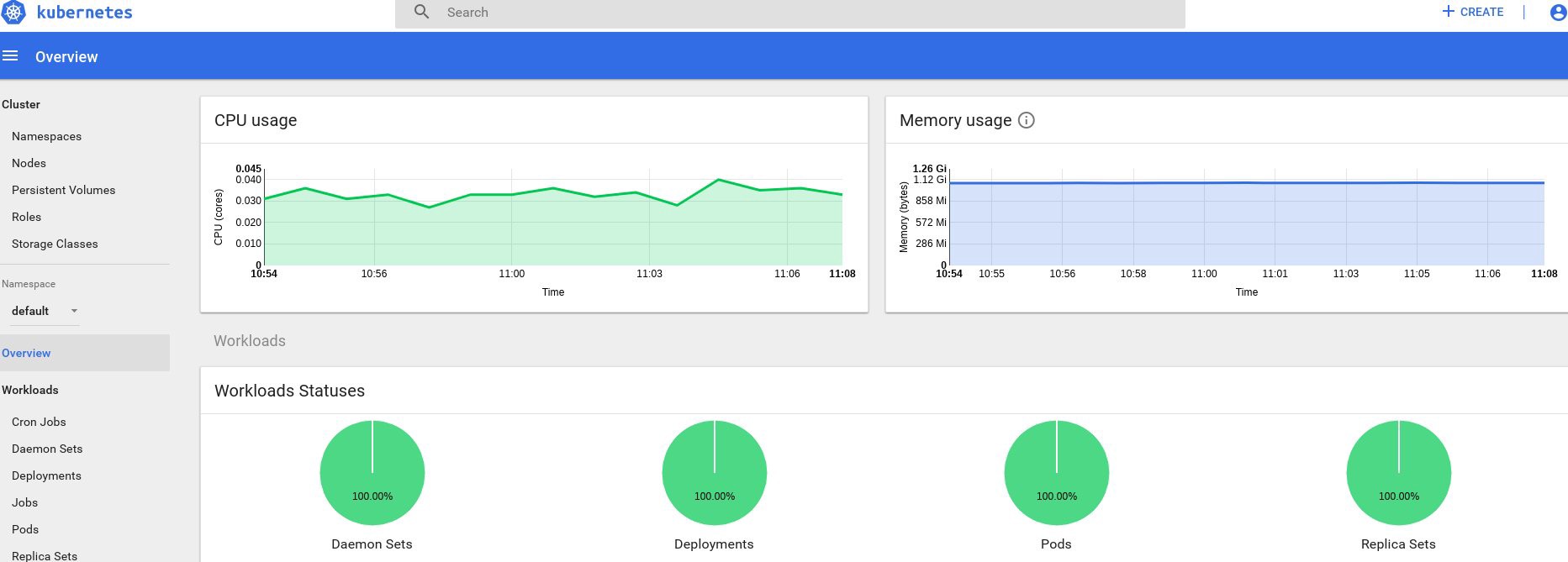

من الآن فصاعدًا ، يمكننا أيضًا تتبع الاستخدام الفعلي للموارد لعقد الكتلة ، الموقد ، إلخ.
إذا لم يكن ذلك كافيًا ، يمكنك تحسين الإحصاءات عن طريق إضافة InfluxDB + Grafana. سيضيف ذلك القدرة على رسم لوحات Grafana الخاصة بك.
سنستخدم هذا الإصدار من تثبيت InfluxDB + Grafana من صفحة Heapster Git ، لكن كالمعتاد ، سنقوم بإجراء تصحيحات. نظرًا لأننا قمنا بالفعل بتهيئة نشر heapster ، فإننا نحتاج فقط إلى إضافة Grafana و InfluxDB ، ثم تعديل تعديل النشر الحالي بحيث يضع المقاييس في Influx.
حسنًا ، دعنا ننشر نشرات InfluxDB و Grafana:
control# vi influxdb.yaml apiVersion: extensions/v1beta1 kind: Deployment metadata: name: monitoring-influxdb namespace: kube-system spec: replicas: 1 template: metadata: labels: task: monitoring k8s-app: influxdb spec: containers: - name: influxdb image: k8s.gcr.io/heapster-influxdb-amd64:v1.5.2 volumeMounts: - mountPath: /data name: influxdb-storage volumes: - name: influxdb-storage emptyDir: {} --- apiVersion: v1 kind: Service metadata: labels: task: monitoring # For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons) # If you are NOT using this as an addon, you should comment out this line. kubernetes.io/cluster-service: 'true' kubernetes.io/name: monitoring-influxdb name: monitoring-influxdb namespace: kube-system spec: ports: - port: 8086 targetPort: 8086 selector: k8s-app: influxdb
التالي هو Grafana ، ولا تنس تغيير إعدادات الخدمة لتمكين موازن تحميل MetaLB والحصول على عنوان IP الخارجي لخدمة Grafana.
control# vi grafana.yaml apiVersion: extensions/v1beta1 kind: Deployment metadata: name: monitoring-grafana namespace: kube-system spec: replicas: 1 template: metadata: labels: task: monitoring k8s-app: grafana spec: containers: - name: grafana image: k8s.gcr.io/heapster-grafana-amd64:v5.0.4 ports: - containerPort: 3000 protocol: TCP volumeMounts: - mountPath: /etc/ssl/certs name: ca-certificates readOnly: true - mountPath: /var name: grafana-storage env: - name: INFLUXDB_HOST value: monitoring-influxdb - name: GF_SERVER_HTTP_PORT value: "3000" # The following env variables are required to make Grafana accessible via # the kubernetes api-server proxy. On production clusters, we recommend # removing these env variables, setup auth for grafana, and expose the grafana # service using a LoadBalancer or a public IP. - name: GF_AUTH_BASIC_ENABLED value: "false" - name: GF_AUTH_ANONYMOUS_ENABLED value: "true" - name: GF_AUTH_ANONYMOUS_ORG_ROLE value: Admin - name: GF_SERVER_ROOT_URL # If you're only using the API Server proxy, set this value instead: # value: /api/v1/namespaces/kube-system/services/monitoring-grafana/proxy value: / volumes: - name: ca-certificates hostPath: path: /etc/ssl/certs - name: grafana-storage emptyDir: {} --- apiVersion: v1 kind: Service metadata: labels: # For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons) # If you are NOT using this as an addon, you should comment out this line. kubernetes.io/cluster-service: 'true' kubernetes.io/name: monitoring-grafana name: monitoring-grafana namespace: kube-system spec: # In a production setup, we recommend accessing Grafana through an external Loadbalancer # or through a public IP. # type: LoadBalancer # You could also use NodePort to expose the service at a randomly-generated port # type: NodePort type: LoadBalancer ports: - port: 80 targetPort: 3000 selector: k8s-app: grafana
وخلق لهم:
control# kubectl create -f influxdb.yaml deployment.extensions/monitoring-influxdb created service/monitoring-influxdb created control# kubectl create -f grafana.yaml deployment.extensions/monitoring-grafana created service/monitoring-grafana created
حان الوقت لتغيير نشر الكومة وإضافة اتصال InfluxDB إليها ؛ تحتاج إلى إضافة سطر واحد فقط:
- --sink=influxdb:http://monitoring-influxdb.kube-system.svc:8086
تحرير نشر heapster:
control# kubectl get deployments --namespace=kube-system NAME READY UP-TO-DATE AVAILABLE AGE coredns 2/2 2 2 49d heapster 1/1 1 1 2d12h kubernetes-dashboard 1/1 1 1 3d21h monitoring-grafana 1/1 1 1 115s monitoring-influxdb 1/1 1 1 2m18s control# kubectl edit deployment heapster --namespace=kube-system ... beginning bla bla bla spec: containers: - command: - /heapster - --source=kubernetes.summary_api:''?useServiceAccount=true&kubeletHttps=true&kubeletPort=10250&insecure=true - --sink=influxdb:http://monitoring-influxdb.kube-system.svc:8086 image: gcr.io/google_containers/heapster-amd64:v1.4.2 imagePullPolicy: IfNotPresent .... end
الآن يمكنك العثور على عنوان IP الخارجي لخدمة Grafana وتسجيل الدخول إلى النظام بداخله:
control# kubectl get svc --namespace=kube-system NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE ..... some other services here monitoring-grafana LoadBalancer 10.98.111.200 192.168.0.241 80:32148/TCP 18m
افتح http://192.168.0.241 في المستعرض ، ولأول مرة استخدم بيانات اعتماد المسؤول / المسؤول:

عندما سجلت الدخول ، كانت Grafana فارغة ، لكن لحسن الحظ ، يمكننا الحصول على جميع لوحات المعلومات الضرورية من grafana.com . تحتاج إلى استيراد اللوحات رقم 3649 و 3646. عند الاستيراد ، حدد مصدر البيانات الصحيح.
بعد ذلك ، راقب استخدام موارد العقد والموقد ، وقم بالطبع بإنشاء لوحات معلومات فريدة خاصة بك.
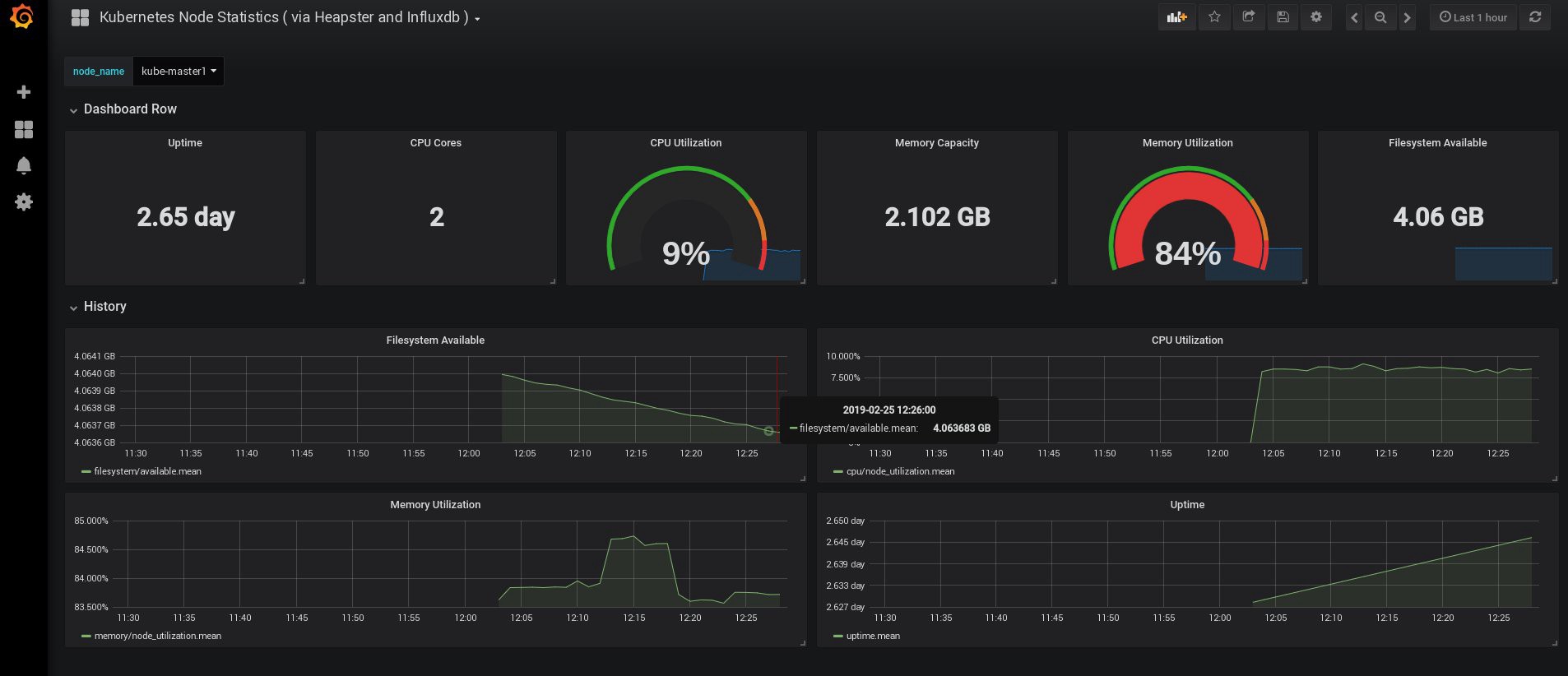
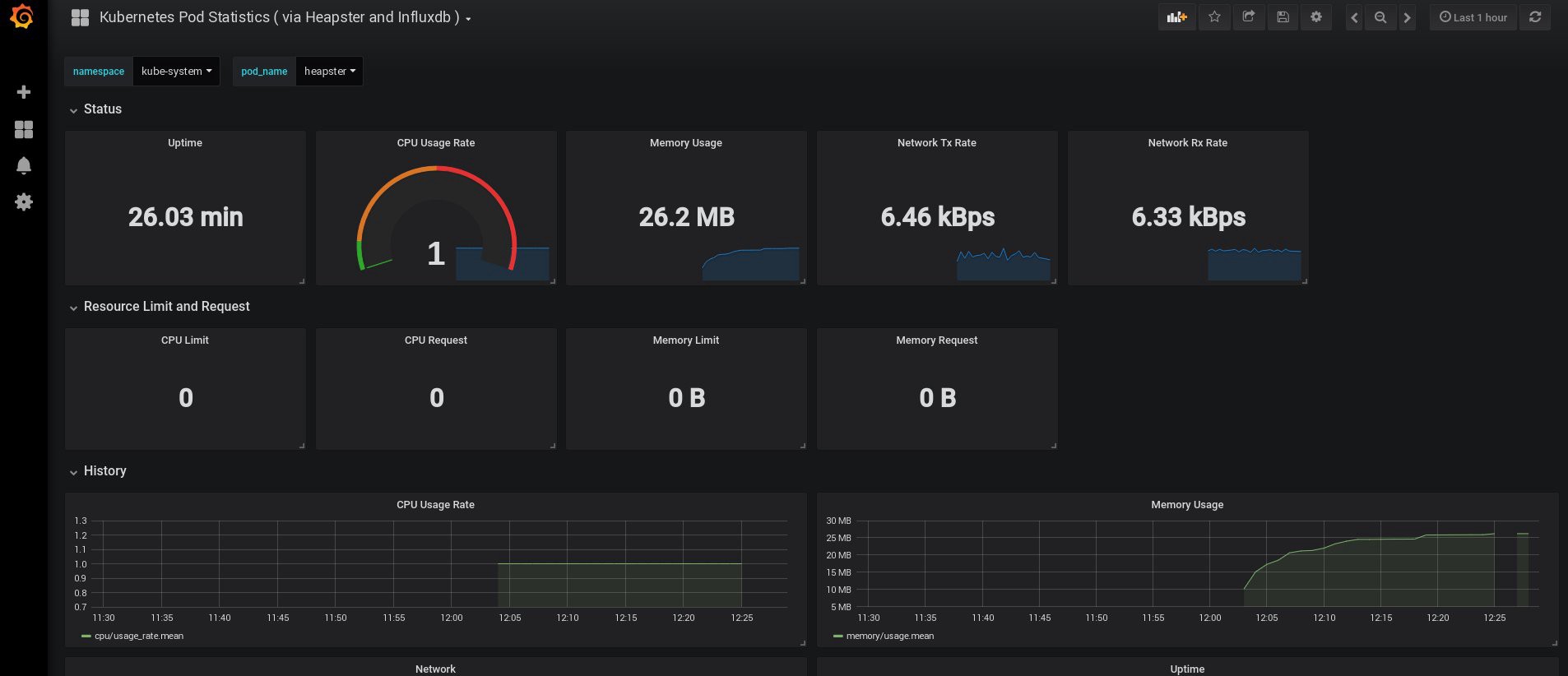
حسنًا ، الآن ، لننتهي بالمراقبة ؛ العناصر التالية التي قد نحتاج إليها هي سجلات لتخزين تطبيقاتنا ونظام المجموعة. هناك عدة طرق لتنفيذ ذلك ، ويتم شرحها جميعًا في وثائق Kubernetes. بناءً على تجربتي الخاصة ، أفضل استخدام المنشآت الخارجية لخدمات Elasticsearch و Kibana ، وكذلك وكلاء التسجيل الذين يعملون على كل عقدة عمل في Kubernetes. سيؤدي ذلك إلى حماية الكتلة من التحميل الزائد المقترن بعدد كبير من السجلات والمشاكل الأخرى ، وسيسمح باستلام السجلات ، حتى لو أصبحت الكتلة غير فعالة تمامًا تمامًا.
المكدس الأكثر شعبية في مجموعة سجلات لمحبي Kubernetes هو Elasticsearch و Fluentd و Kibana (EFK stack). في هذا المثال ، سنقوم بتشغيل Elasticsearch و Kibana على عقدة خارجية (يمكنك استخدام مكدس ELK الحالي) ، بالإضافة إلى Fluentd داخل المجموعة الخاصة بنا كقاعدة بيانات مجمعة لكل عقدة كعامل لجمع سجلات.
سوف أتخطى الجزء المتعلق بإنشاء جهاز VM باستخدام تركيبات Elasticsearch و Kibana ؛ هذا موضوع شائع إلى حد ما ، بحيث يمكنك العثور على الكثير من المواد حول أفضل طريقة للقيام بذلك. على سبيل المثال ، في مقالتي. ما عليك سوى إزالة جزء تكوين logstash من ملف docker -compose.yml ، وإزالة 127.0.0.1 أيضًا من قسم منافذ elasticsearch.
بعد ذلك ، يجب أن يكون لديك elasticsearch العمل متصلة بمنفذ VM-IP: 9200. لمزيد من الأمان ، قم بتكوين تسجيل الدخول: مفاتيح المرور أو الأمان بين fluentd و elasticsearch. ومع ذلك ، أنا في كثير من الأحيان حمايتهم ببساطة مع قواعد iptables.
كل ما تبقى يجب القيام به هو إنشاء daemonset بطلاقة في Kubernetes وتحديد العقدة elasticsearch : عنوان المنفذ الخارجي في التكوين.
نحن نستخدم الوظيفة الإضافية Kubernetes الرسمية بتكوين yaml من هنا ، مع تعديلات طفيفة:
control# vi fluentd-es-ds.yaml apiVersion: v1 kind: ServiceAccount metadata: name: fluentd-es namespace: kube-system labels: k8s-app: fluentd-es kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile --- kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: fluentd-es labels: k8s-app: fluentd-es kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile rules: - apiGroups: - "" resources: - "namespaces" - "pods" verbs: - "get" - "watch" - "list" --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: fluentd-es labels: k8s-app: fluentd-es kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile subjects: - kind: ServiceAccount name: fluentd-es namespace: kube-system apiGroup: "" roleRef: kind: ClusterRole name: fluentd-es apiGroup: "" --- apiVersion: apps/v1 kind: DaemonSet metadata: name: fluentd-es-v2.4.0 namespace: kube-system labels: k8s-app: fluentd-es version: v2.4.0 kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile spec: selector: matchLabels: k8s-app: fluentd-es version: v2.4.0 template: metadata: labels: k8s-app: fluentd-es kubernetes.io/cluster-service: "true" version: v2.4.0 # This annotation ensures that fluentd does not get evicted if the node # supports critical pod annotation based priority scheme. # Note that this does not guarantee admission on the nodes (#40573). annotations: scheduler.alpha.kubernetes.io/critical-pod: '' seccomp.security.alpha.kubernetes.io/pod: 'docker/default' spec: priorityClassName: system-node-critical serviceAccountName: fluentd-es containers: - name: fluentd-es image: k8s.gcr.io/fluentd-elasticsearch:v2.4.0 env: - name: FLUENTD_ARGS value: --no-supervisor -q resources: limits: memory: 500Mi requests: cpu: 100m memory: 200Mi volumeMounts: - name: varlog mountPath: /var/log - name: varlibdockercontainers mountPath: /var/lib/docker/containers readOnly: true - name: config-volume mountPath: /etc/fluent/config.d terminationGracePeriodSeconds: 30 volumes: - name: varlog hostPath: path: /var/log - name: varlibdockercontainers hostPath: path: /var/lib/docker/containers - name: config-volume configMap: name: fluentd-es-config-v0.2.0
ثم سنقوم بعمل تكوين محدد لل fluentd:
control# vi fluentd-es-configmap.yaml kind: ConfigMap apiVersion: v1 metadata: name: fluentd-es-config-v0.2.0 namespace: kube-system labels: addonmanager.kubernetes.io/mode: Reconcile data: system.conf: |- <system> root_dir /tmp/fluentd-buffers/ </system> containers.input.conf: |-
@id fluentd-containers.log @type tail path /var/log/containers/*.log pos_file /var/log/es-containers.log.pos tag raw.kubernetes.* read_from_head true <parse> @type multi_format <pattern> format json time_key time time_format %Y-%m-%dT%H:%M:%S.%NZ </pattern> <pattern> format /^(?<time>.+) (?<stream>stdout|stderr) [^ ]* (?<log>.*)$/ time_format %Y-%m-%dT%H:%M:%S.%N%:z </pattern> </parse>
# Detect exceptions in the log output and forward them as one log entry. <match raw.kubernetes.**> @id raw.kubernetes @type detect_exceptions remove_tag_prefix raw message log stream stream multiline_flush_interval 5 max_bytes 500000 max_lines 1000 </match> # Concatenate multi-line logs <filter **> @id filter_concat @type concat key message multiline_end_regexp /\n$/ separator "" </filter> # Enriches records with Kubernetes metadata <filter kubernetes.**> @id filter_kubernetes_metadata @type kubernetes_metadata </filter> # Fixes json fields in Elasticsearch <filter kubernetes.**> @id filter_parser @type parser key_name log reserve_data true remove_key_name_field true <parse> @type multi_format <pattern> format json </pattern> <pattern> format none </pattern> </parse> </filter> output.conf: |- <match **> @id elasticsearch @type elasticsearch @log_level info type_name _doc include_tag_key true host 192.168.1.253 port 9200 logstash_format true <buffer> @type file path /var/log/fluentd-buffers/kubernetes.system.buffer flush_mode interval retry_type exponential_backoff flush_thread_count 2 flush_interval 5s retry_forever retry_max_interval 30 chunk_limit_size 2M queue_limit_length 8 overflow_action block </buffer> </match>
التكوين أساسي ، لكنه يكفي لبدء سريعة ؛ فإنه سيتم جمع سجلات النظام والتطبيق. إذا كنت بحاجة إلى شيء أكثر تعقيدًا ، فيمكنك الاطلاع على الوثائق الرسمية بشأن الإضافات المتأثرة وتكوينات Kubernetes.
الآن لنقم بإنشاء مجموعة daemonset بطلاقة في مجموعتنا:
control# kubectl create -f fluentd-es-ds.yaml serviceaccount/fluentd-es created clusterrole.rbac.authorization.k8s.io/fluentd-es created clusterrolebinding.rbac.authorization.k8s.io/fluentd-es created daemonset.apps/fluentd-es-v2.4.0 created control# kubectl create -f fluentd-es-configmap.yaml configmap/fluentd-es-config-v0.2.0 created
تأكد من أن جميع القرون اللامعة وغيرها من الموارد تعمل بنجاح ، ثم افتح Kibana. في Kibana ، ابحث وأضف مؤشرًا جديدًا من fluentd. إذا وجدت شيئًا ما ، فسيتم إجراء كل شيء بشكل صحيح ، إن لم يكن ، تحقق من الخطوات السابقة وإعادة إنشاء مجموعة daemonset أو تحرير configmap:

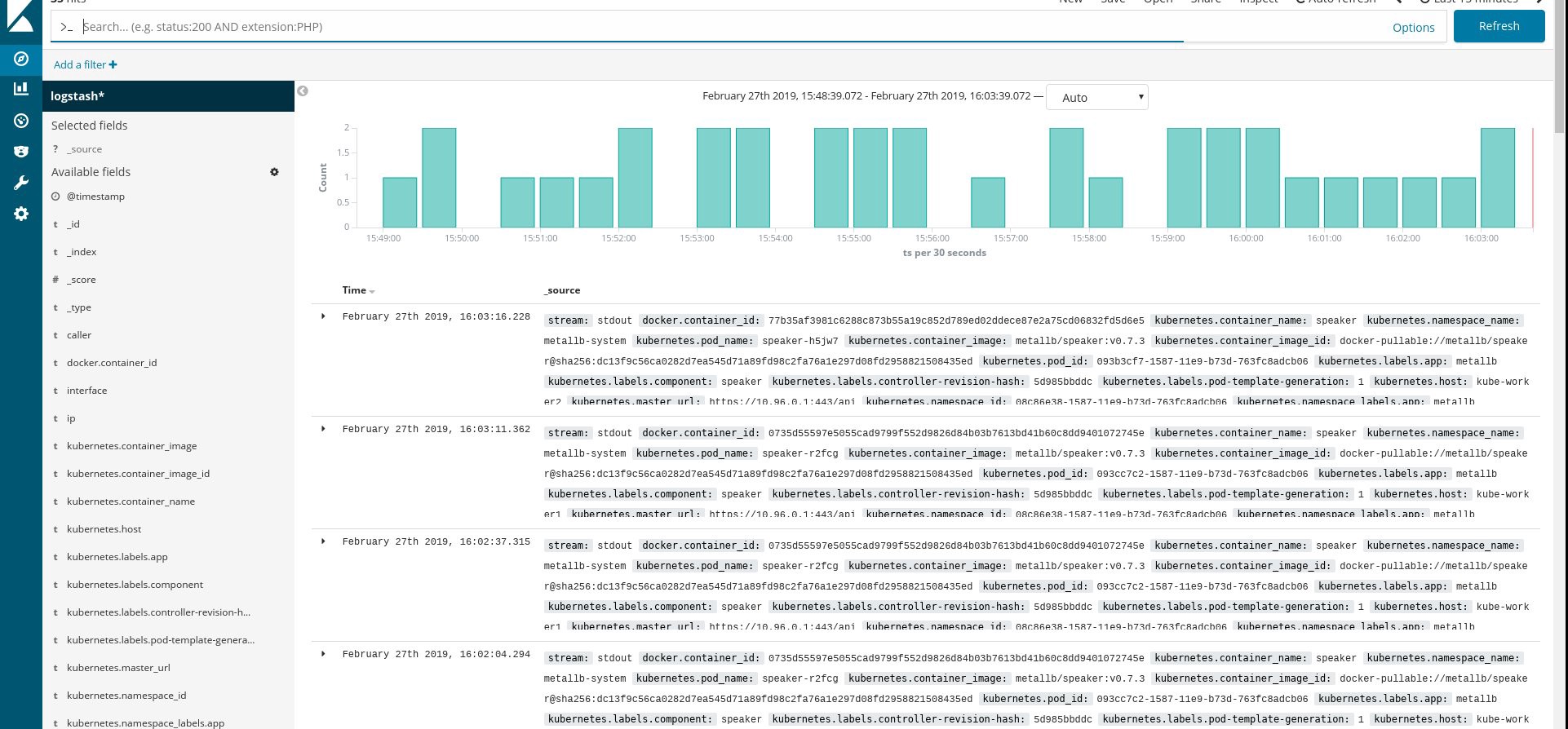
حسنًا ، بعد أن حصلنا على السجلات من الكتلة ، يمكنك إنشاء أي لوحات معلومات. بالطبع ، التكوين هو أبسط ، لذلك ربما تحتاج إلى تغييره لنفسك. كان الهدف الرئيسي هو إظهار كيف يتم ذلك.
بعد الانتهاء من جميع الخطوات السابقة ، حصلنا على مجموعة Kubernetes جيدة حقًا جاهزة للاستخدام. لقد حان الوقت لتضمين تطبيق اختبار ما ومعرفة ما يحدث.
على سبيل المثال ، خذ تطبيقي الصغير Python / Flask Kubyk ، والذي يحتوي بالفعل على حاوية Docker ، لذلك خذها من سجل عامل ميناء مفتوح. سنضيف الآن ملف قاعدة بيانات خارجية إلى هذا التطبيق - لهذا سنستخدم تخزين GlusterFS المكوّن.
أولاً ، نقوم بإنشاء وحدة تخزين PVC جديدة لهذا التطبيق (طلب وحدة التخزين الدائمة) ، حيث سنقوم بتخزين قاعدة بيانات SQLite بأوراق اعتماد المستخدم. يمكنك استخدام فئة الذاكرة التي تم إنشاؤها مسبقًا من الجزء 2 من هذا الدليل.
control# mkdir kubyk && cd kubyk control# vi kubyk-pvc.yaml kind: PersistentVolumeClaim apiVersion: v1 metadata: name: kubyk annotations: volume.beta.kubernetes.io/storage-class: "slow" spec: accessModes: - ReadWriteOnce resources: requests: storage: 1Gi control# kubectl create -f kubyk-pvc.yaml
بعد إنشاء PVC جديد للتطبيق ، نحن مستعدون للنشر.
control# vi kubyk-deploy.yaml apiVersion: apps/v1 kind: Deployment metadata: name: kubyk-deployment spec: selector: matchLabels: app: kubyk replicas: 1 template: metadata: labels: app: kubyk spec: containers: - name: kubyk image: ratibor78/kubyk ports: - containerPort: 80 volumeMounts: - name: kubyk-db mountPath: /kubyk/sqlite volumes: - name: kubyk-db persistentVolumeClaim: claimName: kubyk control# vi kubyk-service.yaml apiVersion: v1 kind: Service metadata: name: kubyk spec: type: LoadBalancer selector: app: kubyk ports: - port: 80 name: http
الآن لنقم بإنشاء خدمة ونشر:
control# kubectl create -f kubyk-deploy.yaml deployment.apps/kubyk-deployment created control# kubectl create -f kubyk-service.yaml service/kubyk created
تحقق من عنوان IP الجديد المخصص للخدمة ، بالإضافة إلى حالة العنوان الفرعي:
control# kubectl get po NAME READY STATUS RESTARTS AGE glusterfs-2wxk7 1/1 Running 1 2d1h glusterfs-5dtdj 1/1 Running 1 41d glusterfs-zqxwt 1/1 Running 0 2d1h heketi-b8c5f6554-f92rn 1/1 Running 0 8d kubyk-deployment-75d5447d46-jrttp 1/1 Running 0 11s control# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE ... some text.. kubyk LoadBalancer 10.109.105.224 192.168.0.242 80:32384/TCP 10s
لذلك ، يبدو أننا أطلقنا تطبيقًا جديدًا بنجاح ؛ إذا فتحنا عنوان IP http://192.168.0.242 في المستعرض ، يجب أن نرى صفحة تسجيل الدخول لهذا التطبيق. يمكنك استخدام بيانات اعتماد المسؤول / المسؤول لتسجيل الدخول ، ولكن إذا حاولنا تسجيل الدخول في هذه المرحلة ، فسنحصل على خطأ لأنه لا توجد قاعدة بيانات متاحة بعد.
فيما يلي مثال على رسالة خطأ في السجل من الموقد في لوحة معلومات Kubernetes:
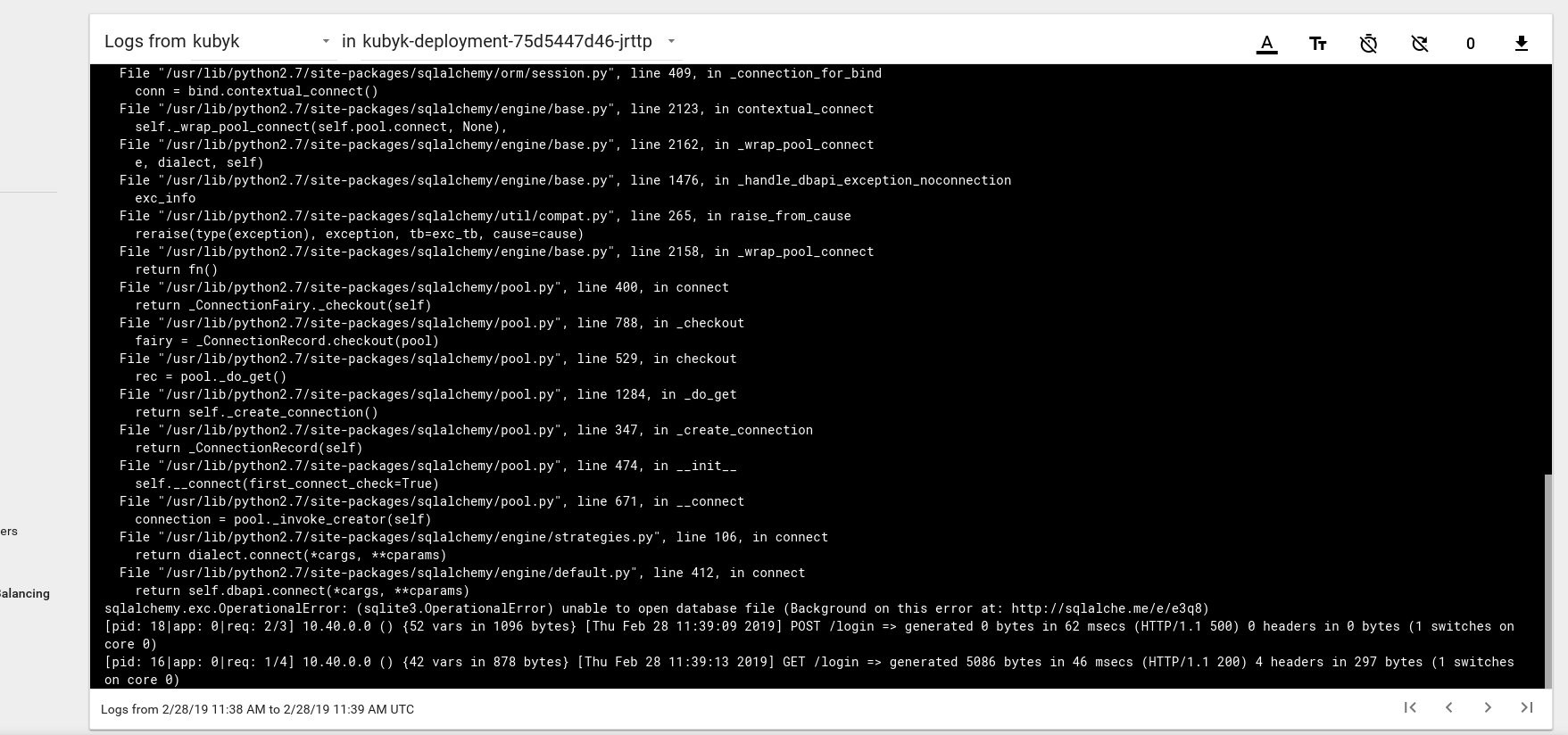
لإصلاح ذلك ، تحتاج إلى نسخ ملف SQlite DB من مستودع git الخاص بي إلى وحدة تخزين pvc التي تم إنشاؤها مسبقًا. سيبدأ التطبيق باستخدام قاعدة البيانات هذه.
control# git pull https://github.com/ratibor78/kubyk.git control# kubectl cp ./kubyk/sqlite/database.db kubyk-deployment-75d5447d46-jrttp:/kubyk/sqlite
نحن نستخدم الخيار "under" من التطبيق وأمر kubectl cp لنسخ هذا الملف إلى وحدة التخزين.
يجب أيضًا منح المستخدم nginx حق الوصول للكتابة إلى هذا الدليل ؛ يتم إطلاق طلبي من خلال مستخدم nginx باستخدام supervisord .
control# kubectl exec -ti kubyk-deployment-75d5447d46-jrttp -- chown -R nginx:nginx /kubyk/sqlite/
لنجرب تسجيل الدخول مرة أخرى:
رائع ، الآن تطبيقنا يعمل بشكل صحيح ، ويمكننا توسيع نطاق نشر kubyk إلى 3 نسخ متماثلة ، على سبيل المثال ، لوضع نسخة واحدة من التطبيق في عقدة عمل واحدة. نظرًا لأننا أنشأنا سابقًا وحدة تخزين pvc ، فإن جميع برامجنا التي تحتوي على نسخ متماثلة للتطبيق ستستخدم نفس قاعدة البيانات ، وبالتالي ستقوم الخدمة بتوزيع حركة المرور بين النسخ المتماثلة بطريقة دورية.
control# kubectl get deployments NAME READY UP-TO-DATE AVAILABLE AGE heketi 1/1 1 1 39d kubyk-deployment 1/1 1 1 4h5m control# kubectl scale deployments kubyk-deployment --replicas=3 deployment.extensions/kubyk-deployment scaled control# kubectl get po NAME READY STATUS RESTARTS AGE glusterfs-2wxk7 1/1 Running 1 2d5h glusterfs-5dtdj 1/1 Running 21 41d glusterfs-zqxwt 1/1 Running 0 2d5h heketi-b8c5f6554-f92rn 1/1 Running 0 8d kubyk-deployment-75d5447d46-bdnqx 1/1 Running 0 26s kubyk-deployment-75d5447d46-jrttp 1/1 Running 0 4h7m kubyk-deployment-75d5447d46-wz9xz 1/1 Running 0 26s
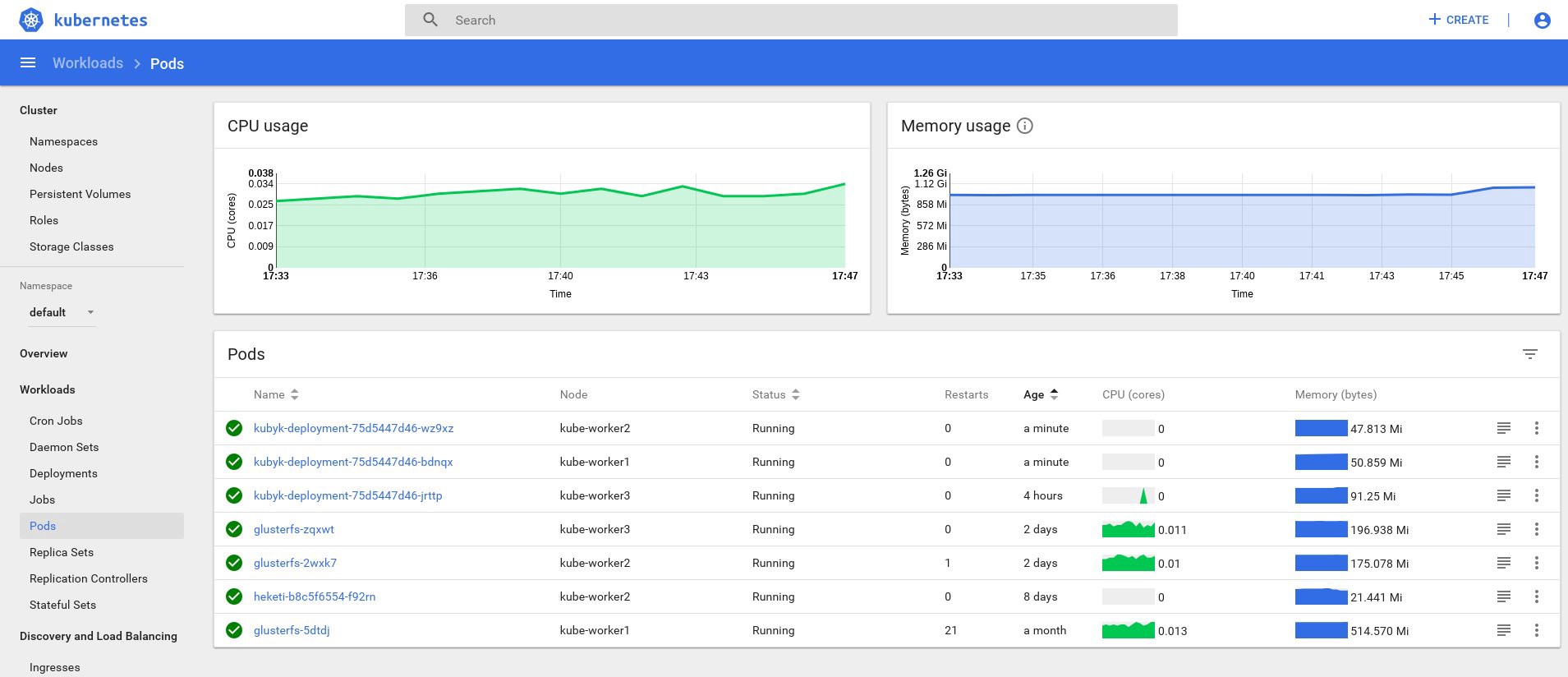
الآن لدينا نسخ متماثلة للتطبيق لكل عقدة عمل ، وبالتالي فإن التطبيق لن يتوقف عن العمل إذا فقد أي عقد. بالإضافة إلى ذلك ، لدينا طريقة بسيطة لتحقيق التوازن بين الحمل ، كما قلت سابقًا. ليس مكانا سيئا للبدء.
لنقم بإنشاء مستخدم جديد في تطبيقنا:
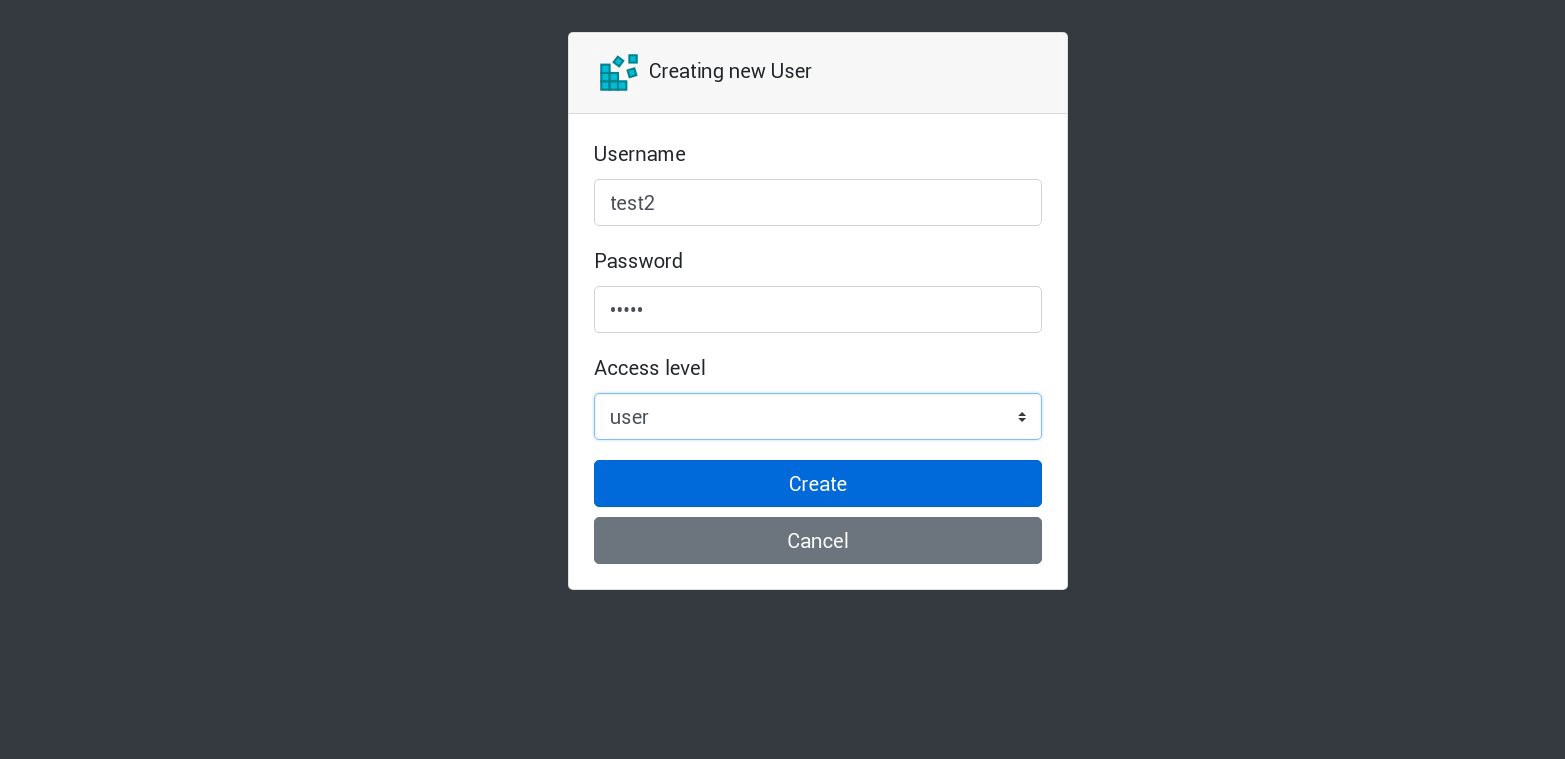
سيتم معالجة جميع الطلبات الجديدة بحلول الموقد التالي في القائمة. يمكن التحقق من ذلك من خلال سجلات الموقد. على سبيل المثال ، يتم إنشاء مستخدم جديد بواسطة التطبيق في فرع واحد ، ثم يجيب الفرعي التالي على الطلب التالي ، وهكذا. لأن هذا التطبيق يستخدم وحدة تخزين ثابتة واحدة لتخزين قاعدة البيانات ، فإن جميع البيانات ستكون آمنة حتى لو فقدت جميع النسخ المتماثلة.
في التطبيقات الكبيرة والمعقدة ، لن تحتاج فقط إلى وحدة تخزين مخصصة لقاعدة البيانات ، ولكن تحتاج إلى وحدات تخزين مختلفة لاستيعاب المعلومات الثابتة والعديد من العناصر الأخرى.
حسنا ، لقد انتهينا تقريبا. يمكنك إضافة العديد من الجوانب ، لأن Kubernetes موضوع ضخم وديناميكي ، لكننا سنتوقف عند هذا الحد. كان الهدف الرئيسي من هذه السلسلة من المقالات هو إظهار كيفية إنشاء مجموعة Kubernetes الخاصة بك ، وآمل أن تكون هذه المعلومات مفيدة لك.
PS
اختبار الاستقرار واختبارات الإجهاد ، بالطبع.
يعمل المخطط العنقودي من مثالنا دون عقد عمل واحدة ، عقد رئيسية واحدة ، وعقد واحدة أخرى. إذا أردت ، قم بتعطيلها وتحقق مما إذا كان تطبيق الاختبار سيعمل أم لا.
في تجميع هذه الأدلة ، قمت بإعداد مجموعة إنتاج لنظام مماثل تقريبًا. بمجرد إنشاء كتلة ونشر تطبيق فيها ، واجهت انقطاعًا كبيرًا في الطاقة ؛ تماما تم قطع جميع خوادم الكتلة - كابوس حية لمسؤول النظام. يتم إيقاف تشغيل بعض الخوادم لفترة طويلة ، ثم حدثت أخطاء في نظام الملفات عليها. لكن إعادة الإطلاق فاجأتني كثيرًا: تعافت مجموعة Kubernetes تمامًا. تم إطلاق جميع وحدات التخزين GlusterFS وعمليات النشر. بالنسبة لي ، هذا دليل على الإمكانات الكبيرة لهذه التكنولوجيا.
كل التوفيق وآمل أن أراكم قريباً!