تقوم الشبكات العصبية التلافيفية بعمل ممتاز في تصنيف الصور المشوهة ، على عكس البشر.

في هذه المقالة سأوضح لماذا يمكن للشبكات العصبية العميقة المتقدمة أن تتعرف تمامًا على الصور المشوهة وكيف يساعد ذلك في الكشف عن الاستراتيجية البسيطة والمدهشة التي تستخدمها الشبكات العصبية لتصنيف الصور الطبيعية. هذه الاكتشافات ، التي
نشرت في ICLR 2019 ، لها العديد من النتائج: أولاً ، أنها توضح أنه من الأسهل بكثير إيجاد حل "
ImageNet " أكثر مما كان يعتقد. ثانياً ، تساعدنا في إنشاء أنظمة تصنيف صور أكثر تفسيرًا ومفهومة. ثالثًا ، يفسرون العديد من الظواهر التي لوحظت في الشبكات العصبية التلافيفية الحديثة (SNA) ، على سبيل المثال ، ميلهم إلى البحث عن مواد (انظر أعمالنا الأخرى في ICLR 2019 وإدخال
المدونة المقابل) ، وتجاهل الترتيب المكاني لأجزاء من الكائن.
النماذج القديمة الجيدة "حقيبة الكلمات"
في الأيام الخوالي ، وقبل ظهور التعلم العميق ، كان التعرف على الصور الطبيعية بسيطًا للغاية: فنحن نحدد مجموعة من الميزات المرئية الرئيسية ("الكلمات") ، ونحدد عدد مرات ظهور كل ميزة بصرية في صورة ("الحقيبة") ، وتصنيف الصورة بناءً على هذه الأرقام. لذلك ، تسمى هذه النماذج في رؤية الكمبيوتر "حقيبة الكلمات" (حقيبة الكلمات أو BoW). على سبيل المثال ، افترض أن لدينا سمتين بصريتين ، العين البشرية والقلم ، ونريد تصنيف الصور إلى فئتين ، "الأشخاص" و "الطيور". سيكون نموذج BoW الأبسط هو هذا: لكل عين موجودة في الصورة ، نقوم بزيادة الشهادة لصالح "الشخص" بمقدار 1. والعكس بالعكس ، لكل قلم نقوم بزيادة الشهادة لصالح "الطائر" بمقدار 1. أي فئة تكسب مزيدًا من الأدلة ، ستكون هذه هي الدرجة.
إن خاصية ملائمة لنموذج BoW البسيط هي قابلية التفسير والوضوح لعملية اتخاذ القرار: يمكننا التحقق بدقة من السمات الخاصة للصورة التي تتحدث لصالح فئة معينة ، والتكامل المكاني للميزات بسيط للغاية (مقارنةً بالتكامل غير الخطي للميزات في الشبكات العصبية العميقة) ، وبالتالي فقط افهم كيف يتخذ النموذج قراراته.
كانت نماذج BoW التقليدية شائعة للغاية وعملت بشكل كبير قبل غزو التعليم العميق ، ولكن سرعان ما خرجت عن الموضة بسبب الكفاءة المنخفضة نسبيًا. لكن هل نحن متأكدون من أن الشبكات العصبية تستخدم استراتيجية قرار مختلفة اختلافًا جوهريًا عن BoW؟
شبكة مترجمة بعمق مع ميزات الحقيبة (BagNet)
لاختبار هذا الافتراض ، نجمع بين قابلية تفسير ووضوح نماذج BoW وكفاءة الشبكات العصبية. الإستراتيجية تبدو كالتالي:
- قسّم الصورة إلى أجزاء صغيرة qx q.
- نقوم بتمرير الأجزاء من خلال الشبكة العصبية للحصول على دليل على عضوية الصف (logits) لكل قطعة.
- تلخيص الأدلة في جميع القطع للحصول على حل على مستوى الصورة بأكملها.
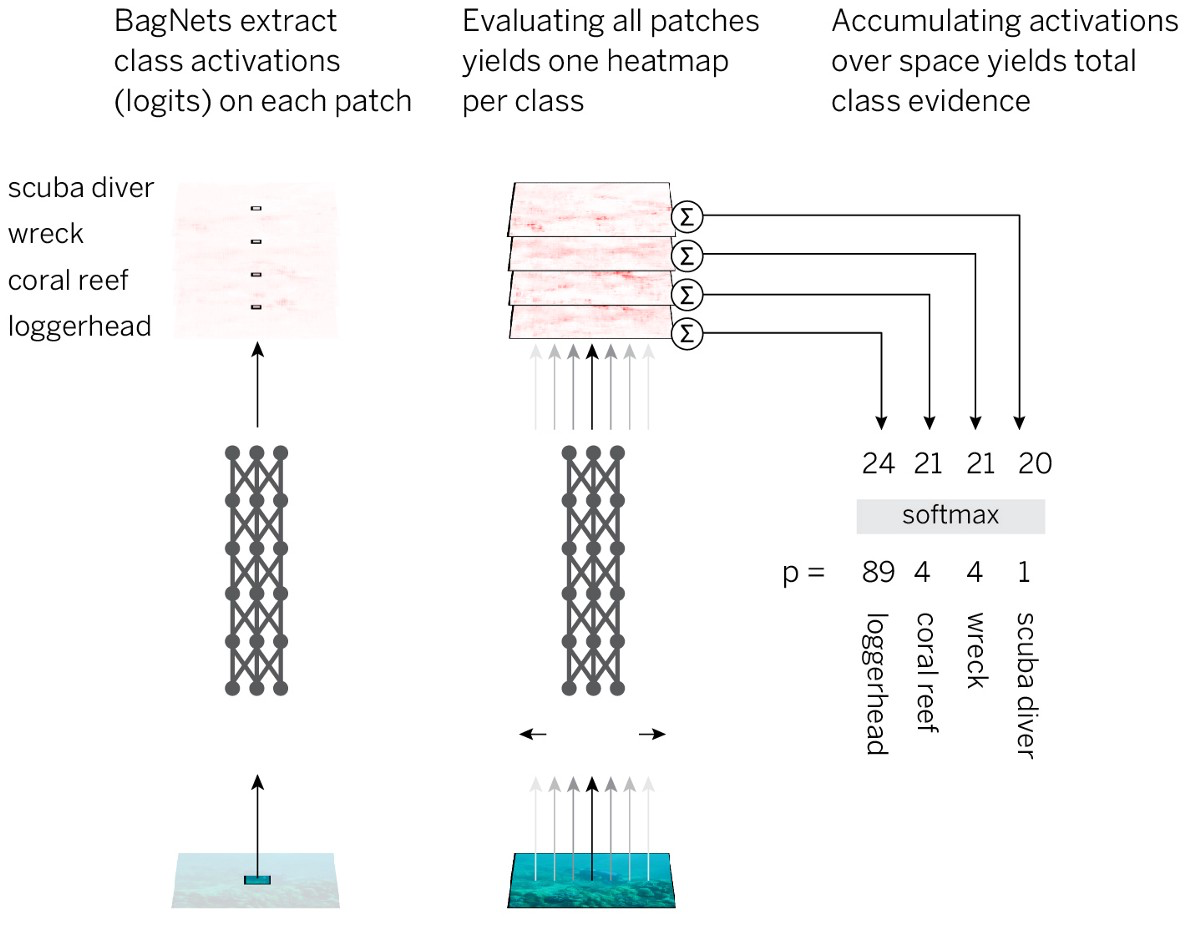
لتنفيذ هذه الإستراتيجية ، بأبسط الطرق ، نأخذ بنية ResNet-50 القياسية ونستبدل جميع ملفات 3x3 تقريبًا بملفات 1 × 1. ونتيجة لذلك ، لا يرى كل عنصر مخفي في آخر طبقة تلافيفية سوى جزءًا صغيرًا من الصورة (أي أن مجال إدراكهم أصغر بكثير من حجم الصورة). لذلك نتجنب العلامات المفروضة للصورة وأقرب وقت ممكن من نظام الحسابات القومية الموحد ، مع تطبيق إستراتيجية مخططة مسبقًا. نحن نسمي العمارة الناتجة BagNet-q ، حيث تشير q إلى حجم حقل الإدراك للطبقة العليا (اختبرنا النموذج بـ q = 9 و 17 و 33). يعمل BagNet-q أطول بحوالي 2.5 من ResNet-50.
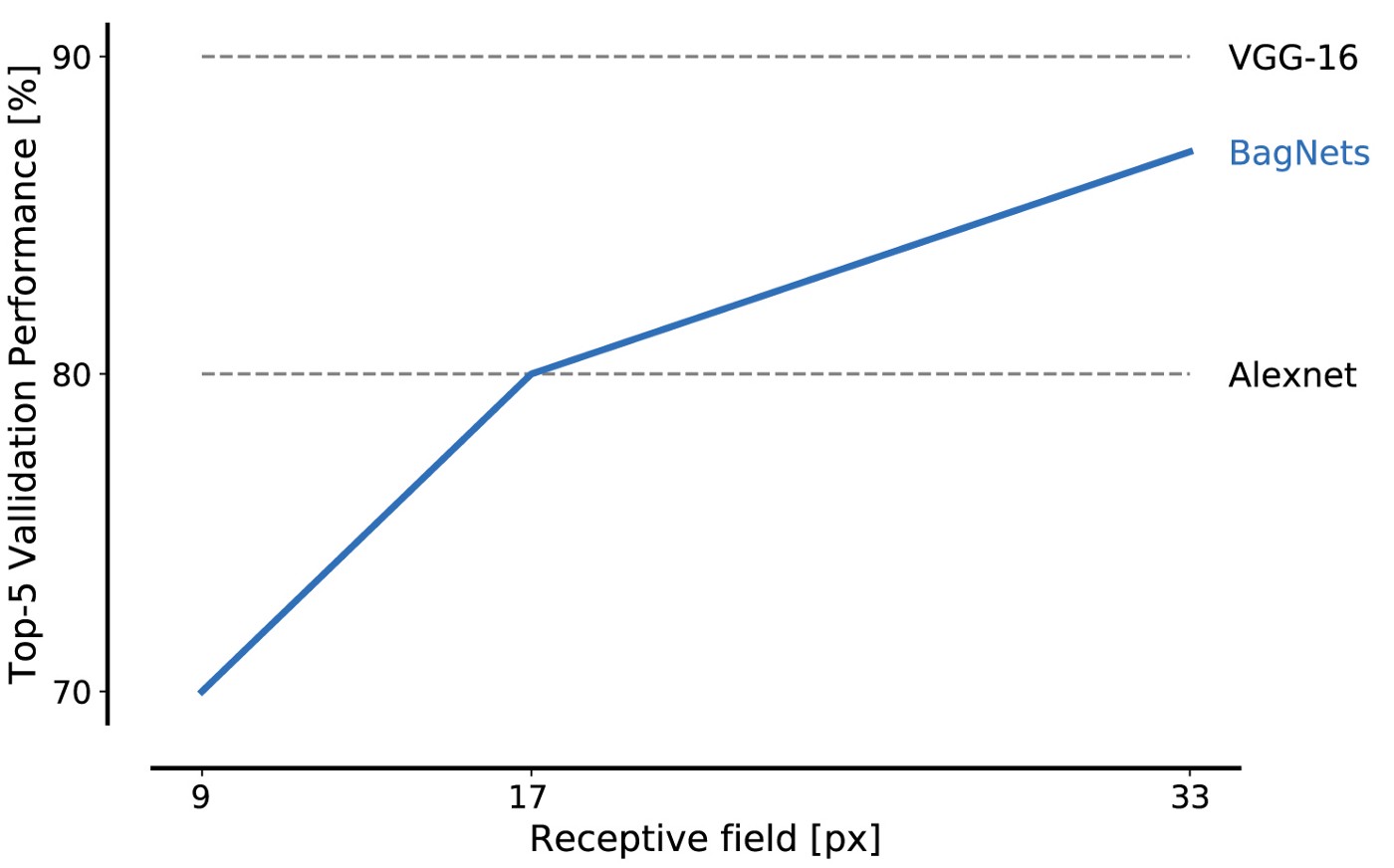
أداء BagNet على البيانات من قاعدة بيانات ImageNet مثير للإعجاب حتى عند استخدام القطع الصغيرة: شظايا 17 × 17 بكسل كافية لتحقيق كفاءة مستوى AlexNet ، وشظايا 33x33 بكسل كافية لتحقيق دقة 87 ٪ ، وإدخال أعلى 5. يمكنك زيادة الكفاءة عن طريق وضع حزم 3x3 بعناية أكبر وضبط المعلمات الفائقة.
هذه هي أول نتيجة رئيسية لدينا: يمكن حل ImageNet باستخدام مجموعة من ميزات الصور الصغيرة فقط. يمكن تجاهل العلاقات المكانية البعيدة لأجزاء التكوين ، مثل شكل الكائنات أو التفاعل بين أجزاء الكائن ، تمامًا ؛ ليست هناك حاجة مطلقة لحل المشكلة.
من الميزات الرائعة لـ BagNet'ov شفافية نظام صنع القرار الخاص بهم. على سبيل المثال ، يمكنك معرفة ميزات الصور التي ستكون أكثر ميزة لفئة معينة. على سبيل المثال ، عادة ما يتم التعرف على تنش ، سمكة كبيرة ، من خلال صورة الأصابع على خلفية خضراء. لماذا؟ لأنه في معظم الصور في هذه الفئة ، يوجد صياد يحمل كأسًا له. وعندما يتعرف BagNet بشكل غير صحيح على الصورة كخط ، يحدث هذا عادة لأنه توجد في مكان ما في الصورة أصابع على خلفية خضراء.
 الأجزاء الأكثر تميزا من الصور. يتوافق الصف العلوي في كل خلية مع التعرّف الصحيح ، والجزء السفلي من الأجزاء المشتتة التي أدت إلى التعرف غير الصحيح
الأجزاء الأكثر تميزا من الصور. يتوافق الصف العلوي في كل خلية مع التعرّف الصحيح ، والجزء السفلي من الأجزاء المشتتة التي أدت إلى التعرف غير الصحيحنحصل أيضًا على "خريطة الحرارة" الدقيقة ، والتي توضح أجزاء الصورة التي ساهمت في اتخاذ القرار.
 الصور الحرارية ليست تقريبية ؛ فهي تُظهر بدقة مساهمة كل جزء من الصورة.
الصور الحرارية ليست تقريبية ؛ فهي تُظهر بدقة مساهمة كل جزء من الصورة.يوضح BagNet أنه يمكنك الحصول على دقة عالية باستخدام ImageNet فقط على أساس الارتباطات الإحصائية الضعيفة بين الميزات المحلية للصور وفئة الكائنات. إذا كان هذا كافياً ، فلماذا تتعلم الشبكات العصبية القياسية ResNet-50 شيئًا مختلفًا تمامًا؟ لماذا يجب أن تدرس ResNet-50 العلاقات المعقدة واسعة النطاق مثل شكل كائن ما ، إذا كانت وفرة الميزات المحلية للصورة كافية لحل المشكلة؟
لاختبار الفرضية القائلة بأن الحسابات القومية الحديثة تلتزم باستراتيجية مماثلة لتشغيل أبسط شبكات BoW ، قمنا باختبار شبكات مختلفة - ResNet و DenseNet و VGG على "علامات" BagNet التالية:
- الحلول مستقلة عن الاختلاط المكاني لميزات الصورة (يمكن التحقق من ذلك فقط على طرز VGG).
- يجب ألا تعتمد تعديلات أجزاء مختلفة من الصورة على بعضها البعض (بمعنى تأثيرها على عضوية الفصل).
- يجب أن تكون الأخطاء التي تم إجراؤها بواسطة SNA القياسية و BagNet'ami مشابهة.
- يجب أن تكون SNS و BagNet القياسية حساسة للميزات المماثلة.
في جميع التجارب الأربعة ، وجدنا سلوكيات مشابهة بشكل مدهش لـ SNS و BagNet. على سبيل المثال ، في التجربة الأخيرة ، نظهر أن BagNet هو الأكثر حساسية (إذا ، على سبيل المثال ، تتداخل) إلى نفس الأماكن في الصور مثل SNA. في الواقع ، تتنبأ خرائط حرارة BagNet (خرائط الحساسية المكانية) بحساسية DenseNet-169 بشكل أفضل من خرائط الحرارة التي تم الحصول عليها عن طريق طرق الإسناد مثل DeepLift (حساب خرائط الحرارة مباشرة لـ DenseNet-169). بطبيعة الحال ، فإن SNA لا يكرر بالضبط سلوك BagNet ، ولكن بعض الانحرافات تظهر. على وجه الخصوص ، كلما أصبحت الشبكات أكثر عمقًا ، زادت أحجام الميزات وزاد امتداد التبعيات. لذلك ، فإن الشبكات العصبية العميقة تمثل بالفعل تحسنا مقارنة بنماذج BagNet ، لكنني لا أعتقد أن أساس تصنيفها يتغير إلى حد ما.
تجاوز تصنيف BoW
يمكن أن تفسر مراقبة عملية صنع القرار في أسلوب استراتيجيات BoW بعض الميزات الغريبة لنظام الحسابات القومية. أولاً ، هذا ما يفسر سبب ارتباط نظام الحسابات القومية
بالقوام . ثانياً ، لماذا لا يكون نظام الحسابات القومية حساسًا
لخلط أجزاء من الصورة. قد يفسر هذا أيضًا وجود ملصقات للخصوم واضطرابات خصومة: يمكن وضع إشارات مربكة في أي مكان في الصورة ، ومن المؤكد أن SNS ستلتقط هذه الإشارة ، بغض النظر عما إذا كانت تلائم بقية الصورة.
في الواقع ، يوضح عملنا أن نظام الحسابات القومية ، عند التعرف على الصور ، يستخدم الكثير من القوانين الإحصائية الضعيفة ولا يشرع في دمج أجزاء من الصورة على مستوى الأشياء ، كما يفعل الناس. وينطبق الشيء نفسه على الأرجح على المهام الأخرى والطرائق الحسية.
نحن بحاجة إلى التخطيط بعناية للهياكل والمهام وأساليب التدريب لدينا للتغلب على الميل إلى استخدام الارتباطات الإحصائية الضعيفة. نهج واحد هو ترجمة تشويه التدريب SNA من الميزات المحلية الصغيرة إلى أكثر عالمية. والآخر هو إزالة أو استبدال تلك الميزات التي لا يجب أن تعتمد عليها الشبكة العصبية ، وهو ما فعلناه في
منشور آخر لـ ICLR 2019 ، باستخدام المعالجة المسبقة لنقل النمط لإزالة نسيج كائن طبيعي.
ومع ذلك ، تبقى واحدة من أكبر المشكلات هي تصنيف الصور: إذا كانت الميزات المحلية كافية ، فلا يوجد حافز لدراسة "الفيزياء" الحقيقية للعالم الطبيعي. نحن بحاجة إلى إعادة هيكلة المهمة بطريقة تحريك النماذج لدراسة الطبيعة المادية للأشياء. للقيام بذلك ، على الأرجح ، سيتعين عليك الذهاب إلى أبعد من التدريس القائم على الملاحظة البحتة إلى الارتباط بين بيانات المدخلات والمخرجات حتى تتمكن النماذج من استخراج العلاقات السببية.
تشير نتائجنا معًا إلى أن نظام الحسابات القومية يمكنه اتباع استراتيجية تصنيف بسيطة للغاية. تؤكد حقيقة أنه يمكن إجراء مثل هذا الاكتشاف في عام 2019 على قلة فهمنا للميزات الداخلية لعمل الشبكات العصبية العميقة. عدم وجود فهم لا يسمح لنا بتطوير نماذج وهندسة محسنة بشكل أساسي تعمل على سد الفجوة بين تصور الإنسان والآلة. إن تعميق فهمنا سيتيح لنا اكتشاف طرق لتضييق هذه الفجوة. قد يكون ذلك مفيدًا للغاية: في محاولة لتحويل نظام الحسابات القومية نحو الخواص الفيزيائية للأشياء ، حققنا فجأة
مقاومة للضوضاء على المستوى البشري. أتوقع ظهور عدد كبير من النتائج الأخرى المثيرة للاهتمام في طريقنا إلى تطوير نظام الحسابات القومية ، الذي يفهم حقًا الطبيعة المادية والسببية لعالمنا.