أنا معجب كبير بكل ما
يفعله Fabien Sanglard ، وأنا أحب مدونته ، وقرأت
كلاً من غلاف
كتبه ليتم تغطيته (تم وصفه في
بودكاست Hansleminutes حديثًا).
كتب فابيان مؤخرًا تدوينًا رائعًا حيث قام
بفك تشفير جهاز تتبع الشعاع
الصغير ، وقام
بفك تشفير الشفرة وشرح الرياضيات بطريقة رائعة. أنا حقا أوصي بأخذ الوقت الكافي لقراءة هذا!
لكن ذلك جعلني أتساءل عما
إذا كان من الممكن نقل رمز C ++ إلى C # ؟ منذ أن اضطررت إلى كتابة الكثير من لغة C ++ في
وظيفتي الرئيسية مؤخرًا ، اعتقدت أنه يمكنني تجربتها.
لكن الأهم من ذلك ، أردت أن أحصل على فكرة أفضل
عما إذا كانت لغة C # هي لغة منخفضة المستوى ؟
سؤال مختلف بعض الشيء ، لكن ذو صلة: كم هو مناسب لـ "برمجة النظام"؟ حول هذا الموضوع ، أوصي حقًا
بمشاركة Joe Duffy الممتازة من عام 2013 .
منفذ الخط
لقد بدأت ببساطة بتحويل سطر
شفرة C ++ غير المشفر بسطر إلى C #. كان الأمر بسيطًا جدًا: يبدو أن الحقيقة لا تزال تقال إن C # هو C ++++ !!!
يوضح المثال بنية البيانات الرئيسية - 'vector' ، فيما يلي مقارنة ، C ++ على اليسار ، C # على اليمين:

لذلك ، هناك بعض الاختلافات في بناء الجملة ، ولكن بما أن .NET يسمح لك بتحديد
أنواع القيمة الخاصة بك ، فقد تمكنت من الحصول على الوظيفة نفسها. يعد هذا أمرًا مهمًا لأن التعامل مع "vector" كهيكل يعني أنه يمكننا الحصول على "موقع بيانات" أفضل ولا نحتاج إلى إشراك أداة تجميع مجمعي البيانات المهملة في .NET ، لأنه سيتم دفع البيانات إلى المكدس (نعم ، أعلم أن هذه تفاصيل تنفيذ).
لمزيد من المعلومات حول
structs أو "أنواع القيم" في .NET ، انظر هنا:
على وجه الخصوص ، في آخر مشاركة لـ Eric Lippert ، نجد مثل هذا الاقتباس المفيد الذي يوضح "أنواع القيم" الحقيقية:
بطبيعة الحال ، فإن أهم حقيقة حول أنواع القيم ليست تفاصيل التنفيذ ، وكيفية تخصيصها ، بل المعنى الدلالي الأصلي "لنوع القيمة" ، أي أنه يتم نسخها دائمًا "حسب القيمة" . إذا كانت معلومات التخصيص مهمة ، فسنطلق عليها "أنواع الكومة" و "أنواع المكدس". لكن في معظم الحالات لا يهم. في معظم الوقت ، فإن دلالات النسخ وتحديد الهوية ذات صلة.
الآن لنرى كيف تبدو بعض الطرق الأخرى بالمقارنة (مرة أخرى C ++ على اليسار ، C # على اليمين) ، أولاً
RayTracing(..) :
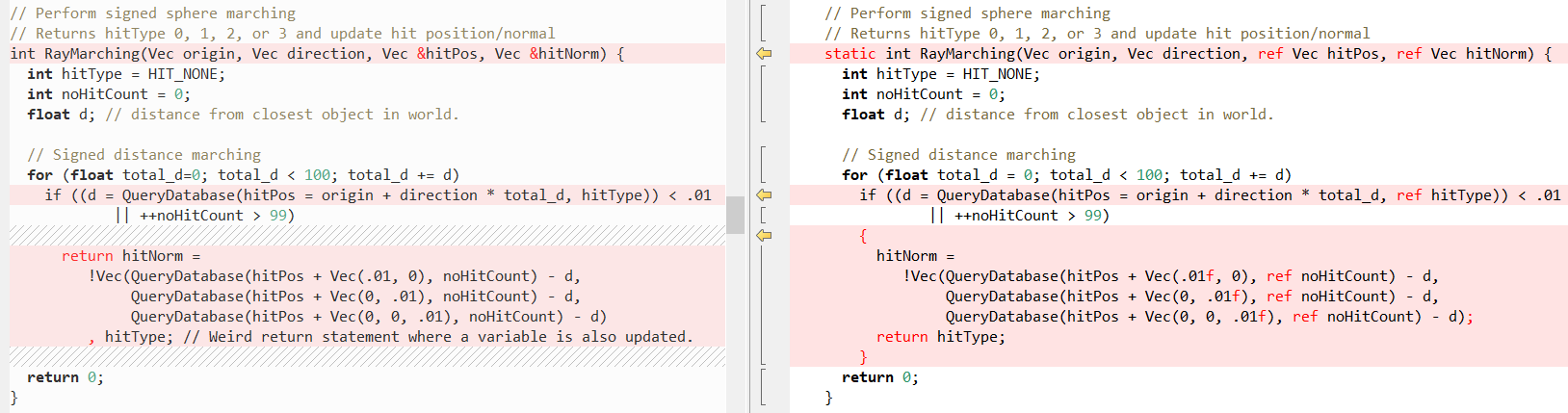
ثم
QueryDatabase (..) :
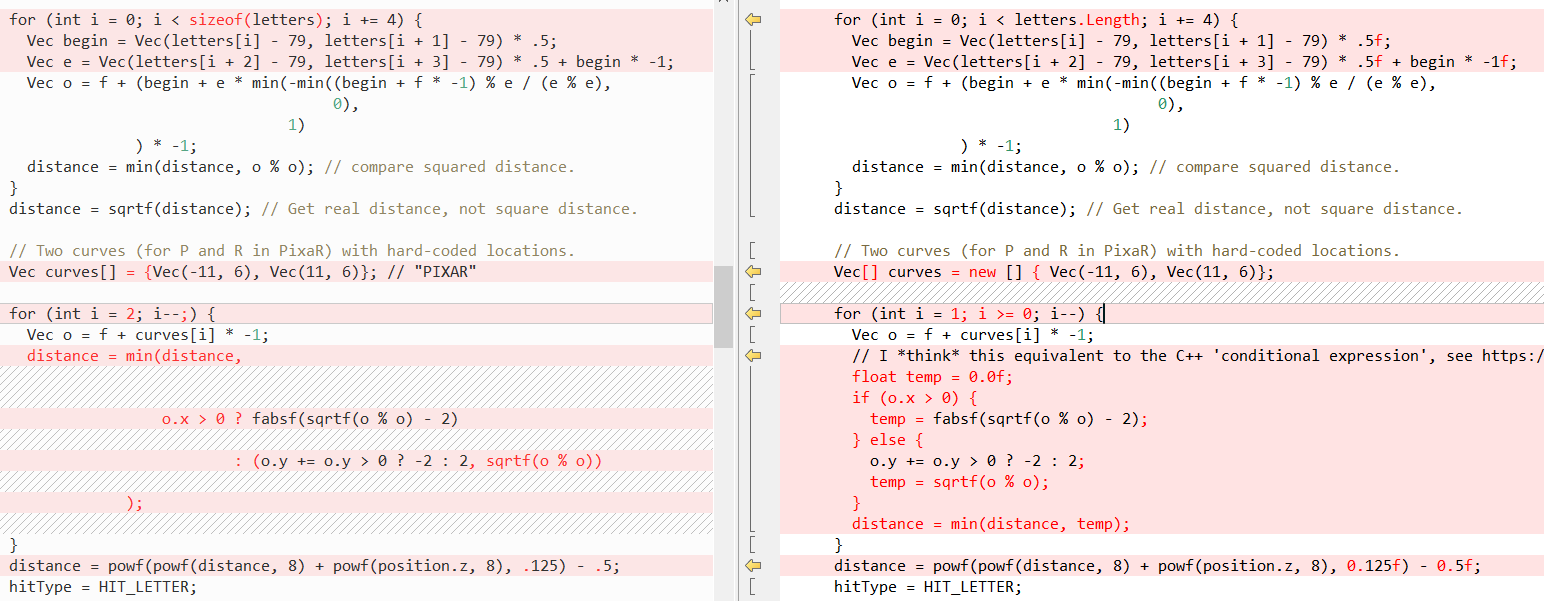
(انظر
منشور فابيان للحصول على شرح لما تفعله هاتان الوظيفتان)
لكن مرة أخرى ، الحقيقة هي أن C # يجعل من السهل جدًا كتابة رمز C ++! في هذه الحالة ، تساعدنا الكلمة الرئيسية
ref ، مما يسمح لنا بتمرير
قيمة حسب المرجع . استخدمنا
ref في طريقة الدعوة لبعض الوقت ، ولكن في الآونة الأخيرة ، بذلت جهود لحل
ref مكان آخر:
الآن سيؤدي استخدام
ref بعض الأحيان إلى تحسين الأداء ، لأنه عندئذٍ لا يلزم نسخ الهيكل ، راجع المعايير في
المنشور بواسطة آدم ستينكس و
"مصائد الأداء تشير إلى السكان المحليين وتعيد المراجع في C #" لمزيد من المعلومات.
ولكن الشيء الأكثر أهمية هو أن مثل هذا البرنامج النصي يوفر منفذ C # الخاص بنا بنفس السلوك مثل شفرة مصدر C ++. على الرغم من أنني أريد أن أشير إلى أن ما يسمى "الروابط المدارة" ليست هي نفسها "المؤشرات" ، على وجه الخصوص ، لا يمكنك إجراء حساب عليها ، انظر المزيد حول هذا هنا:
إنتاجية
وبالتالي ، تم نقل الرمز جيدًا ، ولكن الأداء مهم أيضًا. خاصة في جهاز تتبع الشعاع ، والذي يمكنه حساب الإطار لعدة دقائق. يحتوي C ++ code على متغير
sampleCount ، والذي يتحكم في جودة الصورة النهائية ، مع
sampleCount = 2 كما يلي:

من الواضح ليست واقعية جدا!
ولكن عندما تصل إلى
sampleCount = 2048 ، يبدو كل شيء أفضل
بكثير :

لكن البدء بـ
sampleCount = 2048 يستغرق وقتًا طويلاً للغاية ، لذلك يتم تنفيذ جميع عمليات التشغيل الأخرى بقيمة
2 من أجل تلبية دقيقة واحدة على الأقل. يؤثر تغيير
sampleCount فقط على عدد مرات تكرار حلقة التعليمات البرمجية الأبعد ، راجع
هذا المعرف للحصول على شرح.
النتائج بعد منفذ خط "ساذج"
لمقارنة C ++ و C # بشكل جوهري ، استخدمت أداة
windows-windows ، وهذا هو منفذ الأمر unix. النتائج الأولية تبدو مثل هذا:
| C ++ (VS 2017) | .NET Framework (4.7.2) | .NET Core (2.2) |
|---|
| الوقت (ثانية) | 47.40 | 80.14 | 78.02 |
| في جوهر (ثانية) | 0.14 (0.3٪) | 0.72 (0.9٪) | 0.63 (0.8٪) |
| في مساحة المستخدم (بالثانية) | 43.86 (92.5٪) | 73.06 (91.2 ٪) | 70.66 (90.6 ٪) |
| عدد أخطاء خطأ الصفحة | 1143 | 4818 | 5945 |
| مجموعة العمل (KB) | 4232 | 13 624 | 17 052 |
| ذاكرة مقذوف (KB) | 95 | 172 | 154 |
| ذاكرة غير وقائية | 7 | 14 | 16 |
| ملف المبادلة (KB) | 1460 | 10 936 | 11 024 |
في البداية ، نرى أن رمز C # أبطأ قليلاً من إصدار C ++ ، لكنه يتحسن (انظر أدناه).
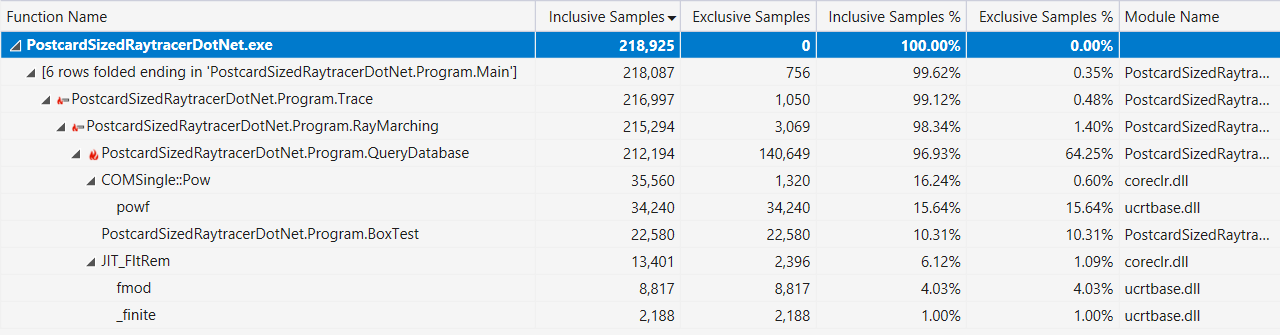
ولكن لنرى أولاً ما الذي يقوم به .NET JIT بالنسبة لنا حتى مع هذا المنفذ الساذج "الساذج". أولاً ، تقوم بعمل جيد في تضمين أساليب المساعد الأصغر. يمكن ملاحظة ذلك في إخراج أداة
Inlining Analyzer الممتازة (أخضر = مدمج):
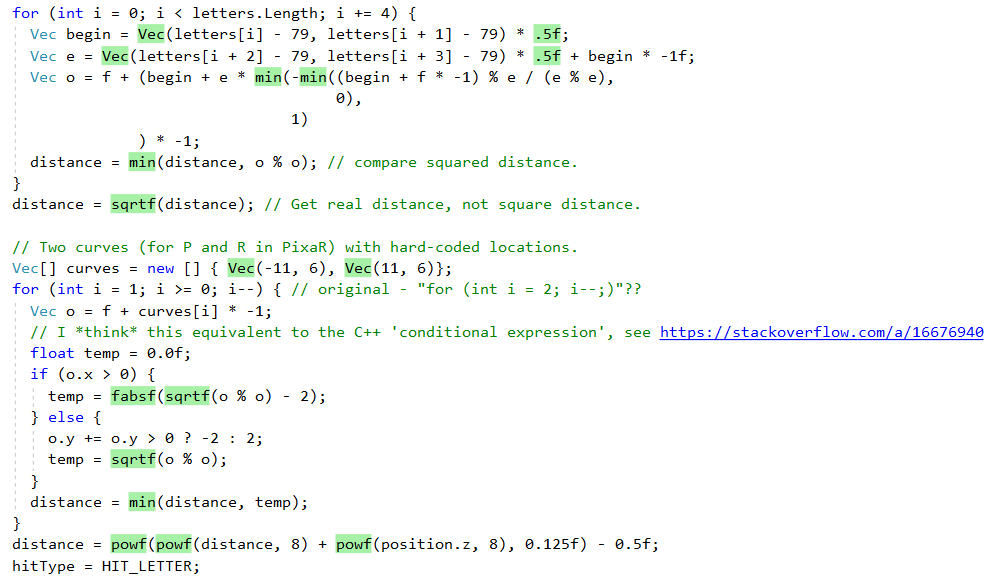
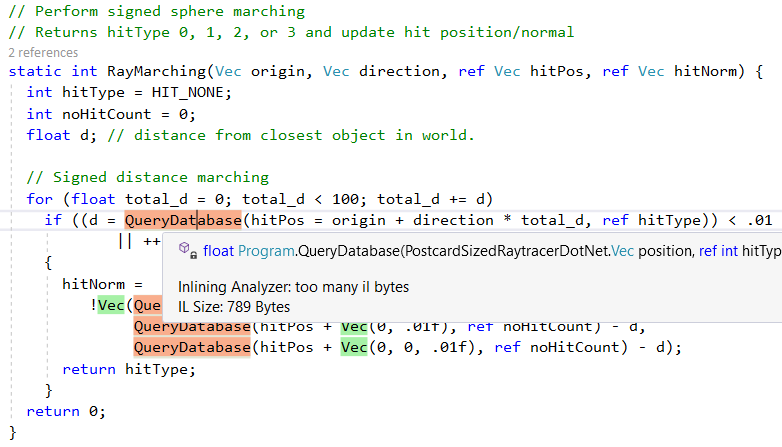
ومع ذلك ، فإنه لا يقوم بتضمين كافة الطرق ، على سبيل المثال ، بسبب التعقيد ،
QueryDatabase(..) تخطي
QueryDatabase(..) :
ميزة أخرى مترجم .NET Just-In-Time (JIT) هي تحويل استدعاءات أسلوب معين إلى إرشادات وحدة المعالجة المركزية المقابلة. يمكننا أن نرى هذا في العمل مع وظيفة قذيفة
sqrt ، وهنا هو شفرة المصدر C # (لاحظ استدعاء
Math.Sqrt ):
وهنا هو رمز المجمّع الذي ينشئه .NET JIT: لا توجد دعوة إلى
Math.Sqrt ويتم استخدام إرشادات المعالج
vsqrtsd :
; Assembly listing for method Program:sqrtf(float):float ; Emitting BLENDED_CODE for X64 CPU with AVX - Windows ; Tier-1 compilation ; optimized code ; rsp based frame ; partially interruptible ; Final local variable assignments ; ; V00 arg0 [V00,T00] ( 3, 3 ) float -> mm0 ;# V01 OutArgs [V01 ] ( 1, 1 ) lclBlk ( 0) [rsp+0x00] "OutgoingArgSpace" ; ; Lcl frame size = 0 G_M8216_IG01: vzeroupper G_M8216_IG02: vcvtss2sd xmm0, xmm0 vsqrtsd xmm0, xmm0 vcvtsd2ss xmm0, xmm0 G_M8216_IG03: ret ; Total bytes of code 16, prolog size 3 for method Program:sqrtf(float):float ; ============================================================
(للحصول على هذه المشكلة ، اتبع
هذه التعليمات ، استخدم
الوظيفة الإضافية "Disasmo" VS2019 أو انظر
SharpLab.io )
تُعرف هذه البدائل أيضًا باسم العناصر
الجوهرية ، وفي الكود أدناه يمكننا أن نرى كيف تقوم JIT بإنشاءها. يعرض هذا المقتطف التعيين لـ
AMD64 فقط ، ولكن JIT تستهدف أيضًا
X86 و
ARM و
ARM64 ، الطريقة الكاملة
هنا .
bool Compiler::IsTargetIntrinsic(CorInfoIntrinsics intrinsicId) { #if defined(_TARGET_AMD64_) || (defined(_TARGET_X86_) && !defined(LEGACY_BACKEND)) switch (intrinsicId) {
كما ترون ، يتم تطبيق بعض الأساليب مثل
Sqrt و
Abs ، بينما يستخدم البعض الآخر وظائف وقت تشغيل C ++ ، على سبيل المثال ،
powf .
يتم شرح هذه العملية برمتها بشكل جيد في المقالة
"كيف يتم تطبيق Math.Pow () في .NET Framework؟" ، يمكن أيضًا رؤيته في مصدر CoreCLR:
النتائج بعد تحسينات الأداء البسيطة
أتساءل عما إذا كنت تستطيع تحسين منفذ السذاجة على الفور. بعد بعض التنميط ، قمت بإجراء تغييرين رئيسيين:
- إزالة تهيئة صفيف مضمن
- استبدال وظائف
Math.XXX(..) مع نظائرها في MathF.()
يتم شرح هذه التغييرات بمزيد من التفصيل أدناه.
إزالة تهيئة صفيف مضمن
لمزيد من المعلومات حول سبب ضرورة ذلك ، راجع
إجابة Stack Overflow الممتازة من
Andrei Akinshin ، إلى جانب المعايير ورمز المجمع. لقد توصل إلى الاستنتاج التالي:
استنتاج
- لا. NET ذاكرة التخزين المؤقت صفيف ترميز المحلية؟ مثل تلك التي وضعت المترجم Roslyn في البيانات الوصفية.
- في هذه الحالة ، سيكون هناك النفقات العامة؟ لسوء الحظ ، نعم: لكل مكالمة ، ستقوم JIT بنسخ محتويات المصفوفة من البيانات الأولية ، والتي تستغرق وقتًا إضافيًا مقارنة بالصفيف الثابت. يقوم وقت التشغيل أيضًا بتحديد الكائنات وإنشاء حركة مرور في الذاكرة.
- هل هناك أي حاجة للقلق بشأن هذا؟ ربما. إذا كانت هذه طريقة ساخنة وتريد تحقيق مستوى جيد من الأداء ، فأنت بحاجة إلى استخدام صفيف ثابت. إذا كانت هذه طريقة باردة لا تؤثر على أداء التطبيق ، فربما تحتاج إلى كتابة التعليمات البرمجية المصدر "جيدة" ووضع الصفيف في منطقة الأسلوب.
يمكنك رؤية التغييرات التي تم إجراؤها في
هذا الفرق .
باستخدام وظائف MathF بدلا من الرياضيات
ثانياً ، والأهم من ذلك ، قمت بتحسين الأداء بشكل كبير عن طريق إجراء التغييرات التالية:
#if NETSTANDARD2_1 || NETCOREAPP2_0 || NETCOREAPP2_1 || NETCOREAPP2_2 || NETCOREAPP3_0
بدءًا من .NET Standard 2.1 ، توجد تطبيقات ملموسة للوظائف الرياضية الشائعة
float . تقع في فئة
System.MathF . لمعرفة المزيد حول واجهة برمجة التطبيقات هذه وتطبيقها ، انظر هنا:
بعد هذه التغييرات ، تم تقليل الفرق في أداء التعليمات البرمجية C # و C ++ إلى حوالي 10٪:
| C ++ (VS C ++ 2017) | .NET Framework (4.7.2) | .NET Core (2.2) TC OFF | .NET Core (2.2) TC ON |
|---|
| الوقت (ثانية) | 41.38 | 58.89 | 46.04 | 44.33 |
| في جوهر (ثانية) | 0.05 (0.1٪) | 0.06 (0.1٪) | 0.14 (0.3٪) | 0.13 (0.3٪) |
| في مساحة المستخدم (بالثانية) | 41.19 (99.5 ٪) | 58.34 (99.1 ٪) | 44.72 (97.1٪) | 44.03 (99.3 ٪) |
| عدد أخطاء خطأ الصفحة | 1119 | 4749 | 5776 | 5661 |
| مجموعة العمل (KB) | 4136 | 13،440 | 16،788 | 16652 |
| ذاكرة مقذوف (KB) | 89 | 172 | 150 | 150 |
| ذاكرة غير وقائية | 7 | 13 | 16 | 16 |
| ملف المبادلة (KB) | 1428 | 10 904 | 10 960 | 11 044 |
TC - تجميع متعدد المستويات ،
Tiered Compilation (
أفترض أنه سيتم تمكينه افتراضيًا في .NET Core 3.0)
للتأكد من اكتمالها ، فيما يلي نتائج عدة عمليات:
| تشغيل | C ++ (VS C ++ 2017) | .NET Framework (4.7.2) | .NET Core (2.2) TC OFF | .NET Core (2.2) TC ON |
|---|
| TestRun-01 | 41.38 | 58.89 | 46.04 | 44.33 |
| TestRun-02 | 41.19 | 57.65 | 46.23 | 45.96 |
| TestRun-03 | 42.17 | 62.64 | 46.22 | 48.73 |
ملاحظة : يرجع الفرق بين .NET Core و .NET Framework إلى عدم وجود MathF API في .NET Framework 4.7.2 ، لمزيد من المعلومات ، راجع
تذكرة الدعم .Net Framework (4.8؟) للحصول على netstandard 2.1 .
زيادة الإنتاجية
أنا متأكد من أنه لا يزال من الممكن تحسين الكود!
إذا كنت مهتمًا بحل اختلاف الأداء ،
فإليك رمز C # . للمقارنة ، يمكنك مشاهدة كود المجمّع C ++ من خدمة
Compiler Explorer الممتازة.
أخيرًا ، إذا كان ذلك مفيدًا ، فإليك ناتج ملفات تعريف Visual Studio مع عرض "المسار السريع" (بعد تحسينات الأداء الموضحة أعلاه):
هل لغة C # منخفضة المستوى؟
أو بشكل أكثر تحديدا:
ما هي ميزات اللغة في C # / F # / VB.NET أو وظيفة BCL / Runtime التي تعني "المستوى المنخفض" * البرمجة؟
* نعم ، أنا أفهم أن "المستوى المنخفض" هو مصطلح شخصي.
ملاحظة: لدى كل مطور لـ C # فكرته الخاصة حول مستوى "المستوى المنخفض" ، سيتم اعتبار هذه الوظائف أمراً مسلماً به من قبل مبرمجي C ++ أو Rust.
هذه هي القائمة التي صنعتها:
- المرجع يعود والسكان المحليين المرجع
- "المرور والعودة بالرجوع لتجنب نسخ الهياكل الكبيرة. يمكن أن تكون الأنواع الآمنة والذاكرة أسرع من غير آمنة! "
- رمز غير آمن في. NET
- "تختلف لغة C # الأساسية ، كما تم تعريفها في الفصول السابقة ، اختلافًا كبيرًا عن C و C ++ حيث إنها تفتقر إلى المؤشرات كنوع بيانات. بدلاً من ذلك ، يوفر C # الارتباطات والقدرة على إنشاء كائنات تحكمها أداة تجميع مجمعي البيانات المهملة. يجعل هذا التصميم ، إلى جانب الميزات الأخرى ، لغة C # أكثر أمانًا من لغة C أو C ++. "
- المؤشرات المدارة في. NET
- "يوجد نوع آخر من المؤشر في CLR - مؤشر مدار. يمكن تعريفه كنوع أكثر ارتباطًا يمكن أن يشير إلى مواقع أخرى ، وليس فقط إلى بداية الكائن. "
- سلسلة C # 7 ، الجزء 10: امتداد <T> وإدارة الذاكرة العالمية
- "System.Span <T> هو مجرد نوع مكدس (
ref struct ) يلتف كل أنماط الوصول إلى الذاكرة ؛ إنه نوع للوصول الشامل المستمر للذاكرة. يمكننا أن نتخيل تطبيق Span مع إشارة وهمية وطول يقبل جميع أنواع الوصول إلى الذاكرة الثلاثة. "
- التوافق ("C # Programming Guide")
- "يوفر .NET Framework إمكانية التشغيل المتداخل مع تعليمات برمجية غير مُدارة من خلال خدمات استدعاء النظام الأساسي
System.Runtime.InteropServices وتوافق C ++ وتوافق COM (إمكانية التشغيل المتداخل COM)."
كما ألقيت صرخة على Twitter وحصلت على خيارات أكثر بكثير لإدراجها في القائمة:
- بن آدمز : "أدوات مدمجة للأنظمة الأساسية (تعليمات وحدة المعالجة المركزية)"
- مارك جرافيل : "بطاقة SIMD عبر Vector (التي تسير على ما يرام مع Span) منخفضة * جميلة ؛ يجب على .NET Core (قريبًا؟) تقديم أدوات وحدة المعالجة المركزية المضمنة المباشرة لاستخدام أكثر وضوحًا لتعليمات وحدة المعالجة المركزية المحددة "
- وضع علامة Gravell : "JIT قوية: أشياء مثل مجموعة elision على المصفوفات / الفواصل الزمنية ، وكذلك استخدام قواعد لكل بنية T لإزالة أجزاء كبيرة من التعليمات البرمجية التي يعرفها JIT بالتأكيد أنها غير متوفرة لهذا T أو على وجه الخصوص وحدة المعالجة المركزية (BitConverter.IsLittleEndian ، Vector.IsHardwareAccelerated ، إلخ) "
- كيفن جونز : "أود أن أذكر بشكل خاص فصول
MemoryMarshal وغير Unsafe ، وربما بعض الأشياء الأخرى في System.Runtime.CompilerServices "
- Theodoros Chatsigiannakis : "يمكنك أيضًا تضمين
__makeref والباقي"
- Damer : "القدرة على إنشاء رمز ديناميكي يطابق تمامًا المدخلات المتوقعة ، بالنظر إلى أن الأخير سيعرف فقط في وقت التشغيل وقد يتغير بشكل دوري؟"
- روبرت هاكن : "الانبعاثات الديناميكية لـ IL"
- فيكتور بايبيكوف : لم يذكر ستاكالوك. من الممكن أيضًا كتابة IL النقي (غير ديناميكي ، وبالتالي يتم حفظه في استدعاء دالة) ، على سبيل المثال ، استخدم
ldftn المخزنة مؤقتًا ldftn بهم من خلال calli . يوجد قالب proj في VS2017 يجعل هذا الأمر بسيطًا من خلال إعادة كتابة الطرق extern + MethodImplOptions.ForwardRef + ilasm.ex »
- Victor Baybekov : "MethodImplOptions.AggressiveInlining أيضًا" ينشط البرمجة منخفضة المستوى ، بمعنى أنه يسمح لك بكتابة تعليمات برمجية عالية المستوى بعدة طرق صغيرة ولا تزال تتحكم في سلوك JIT للحصول على نتيجة محسنة. خلاف ذلك ، نسخ ولصق مئات أساليب LOC ... "
- بن آدمز : "استخدام نفس اصطلاحات الاتصال (ABI) كما هو الحال في النظام الأساسي الأساسي ، و p / تستدعي التفاعل؟"
- فيكتور بيبكوف : "أيضًا ، نظرًا لأنك ذكرت # fsharp - فهي تحتوي على
inline تعمل على مستوى IL إلى JIT ، وبالتالي فقد تم اعتبارها مهمة على مستوى اللغة. C # هذا ليس كافيًا (حتى الآن) بالنسبة لمبات lambdas ، والتي تعد دائمًا مكالمات افتراضية ، وغالبًا ما تكون الحلول البديلة غريبة (الأدوية المحدودة محدودة) "
- Alexandre Mutel : "SIMD مضمن جديد ، مرحلة ما بعد المعالجة لفئة Unsafe Utility / IL (على سبيل المثال ، custom ، Fody ، وما إلى ذلك). بالنسبة لـ C # 8.0 ، مؤشرات الوظائف القادمة ... "
- ألكساندر موتيل : "فيما يتعلق ب IL ، يدعم F # مباشرة IL في لغة ، على سبيل المثال"
- OmariO : " BinaryPrimitives . مستوى منخفض ، لكنه آمن "
- كوجي ماتسوي : "ماذا عن جهاز التجميع المدمج؟ من الصعب على كل من مجموعة الأدوات ووقت التشغيل ، ولكن يمكن أن يحل محل الحل الحالي p / invoke وتطبيق الكود المدمج ، إن وجد "
- فرانك أ. كروجر : "Ldobj، stobj، initobj، initblk، cpyblk"
- كونراد جوز الهند : "ربما يتدفقون التخزين المحلي؟ مخازن حجم ثابت؟ ربما يجب أن تذكر القيود غير المدارة والأنواع المشوهة :) "
- سيباستيانو ماندالا : "مجرد إضافة صغيرة إلى كل ما قيل: ماذا عن شيء بسيط ، مثل ترتيب الهياكل وكيف يمكن أن يؤثر ملء الذاكرة والمحاذاة والترتيب الميداني على أداء ذاكرة التخزين المؤقت؟ هذا شيء يجب أن أستكشفه بنفسي. "
- Nino Floris : "الثوابت المضمنة عبر readonlyspan ، stackalloc ، finalizers ، WeakReference ، المندوبين المفتوحين ، MethodImplOptions ، MemoryBarriers ، TypedReference ، varargs ، SIMD ، Unsafe.AsRef ، يمكن تعيين أنواع الهياكل وفقًا للتخطيط (يستخدم لـ TaskAwaiter وإصداره)"
في النهاية ، أود أن أقول إن C # بالتأكيد يسمح لك بكتابة التعليمات البرمجية التي تبدو مثل C ++ ، وبالاشتراك مع مكتبات وقت التشغيل والفئة الأساسية توفر الكثير من الوظائف ذات المستوى المنخفض.مزيد من القراءة
مترجم انفجر الوحدة: