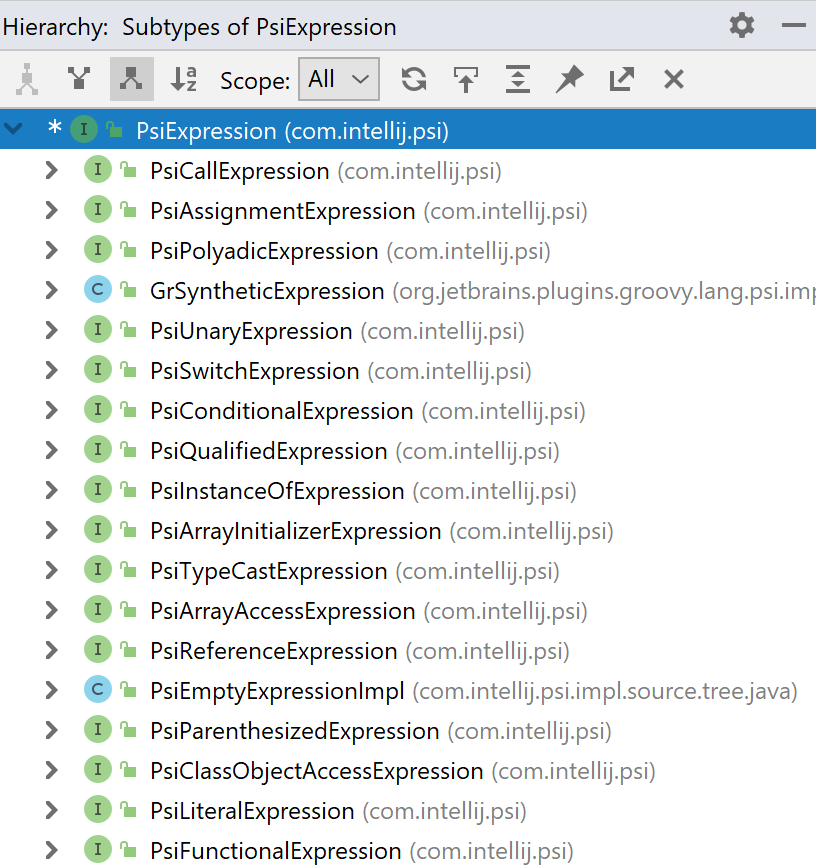
 ميزة هامة لأي IDE هي البحث والتنقل من خلال الكود. أحد خيارات بحث Java المستخدمة بشكل متكرر هو البحث عن جميع تطبيقات هذه الواجهة. غالبًا ما تسمى هذه الوظيفة "التسلسل الهرمي للنوع" وتبدو الصورة على اليمين.
ميزة هامة لأي IDE هي البحث والتنقل من خلال الكود. أحد خيارات بحث Java المستخدمة بشكل متكرر هو البحث عن جميع تطبيقات هذه الواجهة. غالبًا ما تسمى هذه الوظيفة "التسلسل الهرمي للنوع" وتبدو الصورة على اليمين.
التكرار خلال جميع فئات المشروع عند استدعاء هذه الوظيفة غير فعال. يمكنك حفظ التسلسل الهرمي للفئة الكاملة في الفهرس في وقت الترجمة ، لأن المترجم يقوم بإنشائه على أي حال. نقوم بذلك إذا تم بدء التحويل البرمجي بواسطة IDE نفسه ولم يتم تفويضه ، على سبيل المثال ، في Gradle. ولكن هذا لا يعمل إلا إذا لم يتغير شيء في الوحدة النمطية بعد التحويل البرمجي. لكن في الحالة العامة ، تعد أكواد المصدر مصدر المعلومات الأكثر صلة ، والفهارس مبنية على أكواد المصدر.
إن العثور على ورثة فورية مهمة بسيطة إذا لم نتعامل مع واجهة وظيفية. عند البحث عن تطبيقات واجهة Foo ، ستحتاج إلى البحث عن جميع الفئات التي توجد بها أدوات implements Foo ، وواجهات حيث توجد extends Foo ، وكذلك فئات مجهولة من النموذج new Foo(...) {...} . للقيام بذلك ، يكفي إنشاء شجرة بناء الجملة لكل ملف مشروع مسبقًا ، والعثور على الإنشاءات المقابلة وإضافتها إلى الفهرس.
بالطبع ، هناك دقة طفيفة هنا: ربما كنت تبحث عن واجهة com.example.goodcompany.Foo ، ولكن في مكان ما org.example.evilcompany.Foo مستخدم بالفعل. هل من الممكن وضع الاسم الكامل للواجهة الأصل في الفهرس مسبقًا؟ هناك صعوبات مع هذا. على سبيل المثال ، قد يبدو الملف الذي تستخدم فيه الواجهة كما يلي:
عند النظر إلى الملف فقط ، لا يمكننا أن نفهم ما هو الاسم الحقيقي الحقيقي Foo . عليك أن تنظر إلى محتويات عدة حزم. ويمكن تعريف كل حزمة في عدة أماكن (على سبيل المثال ، في عدة ملفات جرة). ستستغرق عملية الفهرسة وقتًا طويلاً إذا كان علينا ، عند تحليل هذا الملف ، أن نفعل الدقة الكاملة للشخصية. لكن المشكلة الرئيسية ليست في هذا الأمر ، لكن الفهرس المبني على ملف MyFoo.java سيعتمد ليس فقط على ذلك ، ولكن أيضًا على الملفات الأخرى. بعد كل شيء ، يمكننا نقل وصف واجهة Foo ، على سبيل المثال ، من حزمة org.example.foo إلى حزمة org.example.bar ، ولا نغير أي شيء في ملف MyFoo.java ، وسوف يتغير الاسم الكامل لـ Foo .
تعتمد الفهارس في IntelliJ IDEA فقط على محتويات ملف واحد. من ناحية ، يعد هذا مناسبًا جدًا: يصبح الفهرس المتعلق بملف معين غير صالح عندما يتغير هذا الملف. من ناحية أخرى ، يفرض هذا قيودًا كبيرة على ما يمكن وضعه في الفهرس. على سبيل المثال ، لا يمكن تخزين الأسماء الكاملة للفئات الأصل في الفهرس بشكل موثوق. ولكن ، من حيث المبدأ ، هذا ليس مخيف جدا. عند الاستعلام عن التسلسل الهرمي للنوع ، يمكننا العثور على كل ما يناسب الاسم المختصر ، ومن ثم تقوم هذه الملفات بإجراء تحليل صريح للشخصية وتحديد ما إذا كان يناسبنا حقًا. في معظم الحالات ، لن يكون هناك عدد كبير جدًا من الأحرف الإضافية ، وسيكون هذا الفحص سريعًا جدًا.
 يتغير الموقف بشكل كبير عندما يكون الفصل الذي نبحث عنه أحفاد هو واجهة وظيفية. ثم ، بالإضافة إلى الورثة الصريحة والمجهولة ، نحصل على تعبيرات lambda وروابط الطريقة. ماذا الآن لوضع في فهرس ، وماذا لحساب مباشرة في البحث؟
يتغير الموقف بشكل كبير عندما يكون الفصل الذي نبحث عنه أحفاد هو واجهة وظيفية. ثم ، بالإضافة إلى الورثة الصريحة والمجهولة ، نحصل على تعبيرات lambda وروابط الطريقة. ماذا الآن لوضع في فهرس ، وماذا لحساب مباشرة في البحث؟
لنفترض أن لدينا واجهة وظيفية:
@FunctionalInterface public interface StringConsumer { void consume(String s); }
هناك تعبيرات lambda مختلفة في التعليمات البرمجية. على سبيل المثال:
() -> {}
بمعنى أنه لا يمكننا تصفية سوى تلك lambdas التي تحتوي على عدد غير صحيح من المعلمات أو من الواضح أن نوع الإرجاع الخطأ ، على سبيل المثال باطل مقابل غير فراغ. عادة ما يكون من المستحيل تحديد نوع الإرجاع بدقة أكبر. قل ، في lambda s -> list.add(s) لهذا تحتاج إلى حل list الأحرف add ، وربما ، بدء إجراء استدلال كامل النوع. كل هذا طويل وسيتطلب تثبيت محتويات الملفات الأخرى.
نحن محظوظون إذا كانت واجهتنا الوظيفية تأخذ خمس حجج. ولكن إذا تطلب الأمر وسيطة واحدة فقط ، فإن هذا المرشح سيترك عددًا كبيرًا من اللمبات الإضافية. أسوأ من ذلك مع مراجع الأسلوب. من حيث المبدأ ، لا يمكن قول ظهور أي إشارة إلى طريقة ما إذا كانت مناسبة أم لا.
ربما يجب أن ننظر حول لامدا لفهم شيء ما؟ نعم ، في بعض الأحيان أنها تعمل. على سبيل المثال:
في جميع هذه الحالات ، يمكن العثور على الاسم المختصر للواجهة الوظيفية المقابلة من الملف الحالي ووضعه في الفهرس بجوار التعبير الوظيفي ، سواء كان مرجع lambda أو طريقة. لسوء الحظ ، في هذه المشروعات الحقيقية ، تغطي هذه الحالات جزءًا صغيرًا جدًا من جميع أنواع الحملان. في الغالبية العظمى من الحالات ، يتم استخدام لامدا كوسيطة لطريقة:
list.stream() .filter(s -> StringUtil.isNonEmpty(s)) .map(s -> s.trim()) .forEach(s -> list.add(s));
أي من هذه الثلاثة lambdas يمكن أن يكون من نوع StringConsumer ؟ فمن الواضح للمبرمج أن لا شيء. نظرًا لأنه من الواضح أن لدينا هنا سلسلة Stream API ، وهناك واجهات وظيفية فقط من المكتبة القياسية ، لا يمكن أن يكون نوعنا موجودًا.
ومع ذلك ، يجب ألا يترك IDE نفسه مضللاً ، يجب أن يقدم إجابة دقيقة. ماذا لو لم تكن list java.util.List على الإطلاق ، و list.stream() لا list.stream() java.util.stream.Stream على الإطلاق؟ للقيام بذلك ، يجب حل رمز list ، والذي ، كما نعلم ، لا يمكن القيام به بشكل موثوق فقط بناءً على محتويات الملف الحالي. وحتى إذا قمنا بتثبيته ، فلا ينبغي وضع البحث على تنفيذ المكتبة القياسية. ربما استبدلنا بالتحديد في هذا المشروع فئة java.util.List بفريقنا؟ يجب أن يستجيب البحث لهذا. حسنًا ، بالطبع ، يتم استخدام لامدا ليس فقط في التدفقات القياسية ، وهناك العديد من الطرق الأخرى حيث يتم نقلها.
نتيجة لذلك ، اتضح أنه يمكننا الاستعلام عن الفهرس للحصول على قائمة بجميع ملفات Java التي تستخدم lambdas مع العدد المطلوب من المعلمات ونوع الإرجاع صالح (في الواقع ، نحن فقط نتتبع أربعة خيارات: باطلة ، غير خالية ، منطقية ، وأي). ثم ماذا؟ لكل من هذه الملفات ، قم ببناء شجرة PSI كاملة (هل هي مثل شجرة التحليل ، ولكن مع دقة الحروف ، والاستدلال على الكتابة وغيرها من الأشياء الذكية) وتنفيذ بصدق لاستنتاج الكتابة لـ lambda؟ ثم في مشروع كبير ، لن تنتظر الحصول على قائمة بجميع تطبيقات الواجهة ، حتى لو كان هناك اثنان منها فقط.
اتضح أننا بحاجة إلى القيام بالخطوات التالية:
- اسأل الفهرس (رخيص)
- بناء PSI (غالي)
- نوع الطباعة امدا (مكلفة للغاية)
في الإصدار 8 من Java والإصدارات الأحدث ، يعد type inference عملية مكلفة بشكل غير معقول. في سلسلة معقدة من المكالمات ، يمكن أن يكون لديك العديد من معلمات أحرف البدل العامة ، والتي يجب تحديد قيمها باستخدام الإجراء الغاضب الموصوف في الفصل 18 من المواصفات. يمكن القيام بذلك في الخلفية للملف الحالي الجاري تحريره ، ولكن سيكون من الصعب القيام بذلك لآلاف الملفات غير المفتوحة.
هنا ، ومع ذلك ، يمكنك قطع الزاوية قليلاً: في معظم الحالات ، لا نحتاج إلى النوع النهائي. إذا لم يتم تمرير lambda فقط إلى طريقة تأخذ معلمة عامة في هذا المكان ، فيمكننا التخلص من الخطوة الأخيرة من استبدال المعلمة. قل ، إذا استنتجنا نوع lambda java.util.function.Function<T, R> ، فلن نتمكن من حساب قيم معلمات الاستبدال T و R : ولذا فمن الواضح ما إذا كان يجب إعادته إلى نتيجة البحث أم لا. على الرغم من أن هذا لن ينجح عند استدعاء طريقة مثل هذا:
static <T> void doSmth(Class<T> aClass, T value) {}
يمكن استدعاء هذه الطريقة كالتالي: doSmth(Runnable.class, () -> {}) . ثم سيتم عرض نوع lambda كـ T ، وعليك استبداله على أي حال. لكن هذه حالة نادرة. لذلك ، اتضح للحفظ ، ولكن ليس أكثر من 10 ٪. لم يتم حل المشكلة بشكل أساسي.
فكرة أخرى: إذا كان الاستدلال النوعي الدقيق معقدًا ، فلنصل إلى نتيجة تقريبية. دعها تعمل فقط على أنواع الفئات التي تم محوها ولا تقلل من مجموعة القيود ، كما هو مكتوب في المواصفات ، ولكن ببساطة اتبع سلسلة المكالمات. طالما أن النوع الذي تم مسحه لا يتضمن معلمات عامة ، فكل شيء على ما يرام. على سبيل المثال ، خذ الدفق من المثال أعلاه وحدد ما إذا كان lambda الأخير يطبق StringConsumer لدينا:
list المتغير -> اكتب java.util.List- طريقة
List.stream() - List.stream() نوع java.util.stream.Stream Stream.filter(...) → اكتب java.util.stream.Stream ، حتى أننا لا ننظر إلى وسيطات filter ، ما هو الفرقStream.map(...) طريقة - Stream.map(...) java.util.stream.Stream نوع ، بالمثل- طريقة
Stream.forEach(...) → هناك مثل هذه الطريقة ، المعلمة الخاصة بها هي من نوع Consumer ، والتي من الواضح أنها ليست StringConsumer .
حسنا ، لقد فعلوا دون الاستدلال الكامل. مع هذا النهج البسيط ، مع ذلك ، فمن السهل أن نواجه طرقًا مثقلة. إذا لم نبدأ استنتاج الكتابة بالكامل ، فلن تتمكن من تحديد الإصدار الزائد الصحيح. وإن لم يكن الأمر كذلك ، فمن الممكن في بعض الأحيان إذا كان عدد معلمات الطريقة يختلف. على سبيل المثال:
CompletableFuture.supplyAsync(Foo::bar, myExecutor).thenRunAsync(s -> list.add(s));
هنا يمكننا أن نفهم ذلك بسهولة
- هناك طريقتان
CompletableFuture.supplyAsync ، ولكن واحدة تأخذ وسيطة واحدة والثانية تأخذ اثنين ، لذلك اختر واحد يأخذ اثنين. تقوم بإرجاع CompletableFuture . - أساليب
thenRunAsync أيضًا طريقتان ، ومنه يمكنك اختيار الطريقة التي تأخذ وسيطة واحدة. المعلمة المقابلة من النوع Runnable ، مما يعني أنها ليست StringConsumer .
إذا قبلت عدة طرق نفس عدد المعلمات ، أو كان بعضها يحتوي على عدد متغير من المعلمات كما تبدو مناسبة ، فسوف يتعين عليك تتبع جميع الخيارات. ولكن في كثير من الأحيان هذا أيضا ليس مخيفا. على سبيل المثال:
new StringBuilder().append(foo).append(bar).chars().forEach(s -> list.add(s));
new StringBuilder() الواضح أن new StringBuilder() ينشئ java.lang.StringBuilder . للمصممين ، ما زلنا نسمح بالرابط ، لكن الاستدلال النوعي المعقد غير مطلوب هنا. حتى لو كانت هناك new Foo<>(x, y, z) ، فإننا لا نعرض قيم المعلمات النموذجية ، فنحن مهتمون فقط بـ Foo .- هناك
StringBuilder.append أساليب StringBuilder.append التي تأخذ وسيطة واحدة ، ولكنها جميعًا تُرجع نوع java.lang.StringBuilder ، لذلك لا يهم نوع foo و bar . - أسلوب
StringBuilder.chars واحد وإرجاع java.util.stream.IntStream . - أسلوب
IntStream.forEach واحد ويقبل نوع IntConsumer .
حتى لو بقيت عدة خيارات في مكان ما ، يمكنك تتبعها جميعًا. على سبيل المثال ، قد يكون نوع lambda الذي تم تمريره إلى ForkJoinPool.getInstance().submit(...) قد يكون ForkJoinPool.getInstance().submit(...) Runnable أو Runnable ، ولكن إذا كنا نبحث عن شيء ثالث ، فلا يزال بإمكاننا تجاهل ذلك lambda.
يحدث موقف غير سارة عند إرجاع أسلوب معلمة عامة. ثم ينهار الإجراء وعليك تشغيل الاستدلال الكامل للنوع. ومع ذلك ، دعمنا حالة واحدة. يظهر بشكل جيد في مكتبة StreamEx ، التي تحتوي على فئة مجردة AbstractStreamEx<T, S extends AbstractStreamEx<T, S>> أساليب تحتوي على مثل S filter(Predicate<? super T> predicate) . يعمل الأشخاص عادةً مع فئة معينة StreamEx<T> extends AbstractStreamEx<T, StreamEx<T>> . في هذه الحالة ، يمكنك إجراء استبدال معلمة النوع ومعرفة ذلك S = StreamEx .
حسنًا ، في العديد من الحالات تخلصنا من الاستدلال النوعي المكلف للغاية. لكننا لم نفعل شيئا مع بناء PSI. إنه لأمر مخز أن يتم تحليل الملف في خمسمائة سطر فقط لمعرفة أن اللمدا في السطر 480 لا يلائم طلبنا. دعنا نعود إلى ساحة مشاركاتنا:
list.stream() .filter(s -> StringUtil.isNonEmpty(s)) .map(s -> s.trim()) .forEach(s -> list.add(s));
إذا كانت list عبارة عن متغير محلي أو معلمة أسلوب أو حقل في الفصل الحالي ، فعندئذٍ في مرحلة الفهرسة ، يمكننا أن نجد إعلانها ونثبت أن الاسم المختصر للنوع هو
List وفقا لذلك ، في مؤشر لآخر امدا يمكننا وضع المعلومات التالية:
نوع lambda هذا هو نوع المعلمة للأسلوب forEach من وسيطة واحدة ، ودعا في نتيجة طريقة map من وسيطة واحدة ، ودعا في نتيجة طريقة filter من وسيطة واحدة ، ودعا في نتيجة طريقة stream من وسيطات صفر ، ودعا في كائن من نوع List .
كل هذه المعلومات متاحة في الملف الحالي ، مما يعني أنه يمكن وضعها في الفهرس. أثناء البحث ، نطلب من الفهرس الحصول على مثل هذه المعلومات حول جميع lambdas ومحاولة استعادة نوع lambda دون إنشاء PSI. أولاً ، يتعين عليك إجراء بحث عالمي عن الفصول الدراسية بقائمة الاسم المختصر. بالطبع ، لن نجد java.util.List فقط ، ولكن أيضًا java.awt.List أو شيء من رمز مشروع المستخدم. علاوة على ذلك ، سنقدم جميع هذه الفئات إلى نفس الإجراء من دقة النوع غير دقيقة التي استخدمناها من قبل. في كثير من الأحيان يتم تصفية الفئات الإضافية نفسها بسرعة. على سبيل المثال ، في java.awt.List لا توجد طريقة stream ، وبالتالي يتم استبعادها أكثر. ولكن حتى لو كان هناك شيء زائف معنا حتى النهاية ووجدنا العديد من المرشحين لنوع لامدا لدينا ، فهناك فرص جيدة لأنهم جميعا لن يتناسبوا مع طلب البحث ، وسنستمر في تجنب بناء PSI كامل.
من المحتمل أن يكون البحث العالمي مكلفًا للغاية (هناك العديد من فئات List في المشروع) ، إما أن بداية السلسلة غير مسموح بها في سياق ملف واحد (على سبيل المثال ، هذا الحقل من الفئة الأصل) ، أو ستتم مقاطعة السلسلة في مكان ما لأن الطريقة تُرجع معلمة عامة. بعد ذلك ، لا نستسلم على الفور ونحاول مرة أخرى أن نبدأ بعملية بحث شاملة عن طريقة التسلسل التالية. على سبيل المثال ، بالنسبة إلى map.get(key).updateAndGet(a -> a * 2) ، ذهبت العبارة التالية إلى الفهرس:
نوع lambda هو نوع المعلمة الوحيدة لطريقة updateAndGet ، والتي تسمى نتيجة طريقة get مع معلمة واحدة ، تسمى على كائن type Map .
دعونا نكون محظوظين وفي المشروع هناك نوع واحد فقط من Map - java.util.Map . يحتوي على أسلوب get(Object) ، لكن لسوء الحظ يقوم بإرجاع المعلمة العامة V ثم نقوم بإسقاط السلسلة ونبحث بشكل عام عن أسلوب updateAndGet واحدة (باستخدام الفهرس ، بالطبع). AtomicInteger ، هناك ثلاث طرق فقط في المشروع ، في AtomicInteger AtomicLong و AtomicReference و AtomicReference مع معلمات من النوع IntUnaryOperator و LongUnaryOperator و UnaryOperator ، على التوالي. إذا كنا نبحث عن أي نوع آخر ، فوجدنا أن لامدا لا تناسب ولا يمكن بناء PSI.
من المثير للدهشة ، هذا مثال حي على ميزة ، مع مرور الوقت ، تبدأ في العمل ببطء أكثر. على سبيل المثال ، أنت تبحث عن تطبيق واجهة وظيفية ، وهناك ثلاثة منها فقط في المشروع ، ويبحث IntelliJ IDEA عنهم لمدة عشر ثوانٍ. وتتذكر جيدًا أنه منذ ثلاث سنوات كان هناك أيضًا ثلاثة منهم ، وكنت تبحث عنها أيضًا ، ولكن البيئة أعطت إجابة في غضون ثانيتين على نفس الجهاز. وقد نما مشروعك ، على الرغم من ضخامة حجمه ، خلال ثلاث سنوات ، ربما بنسبة خمسة في المائة. بالطبع ، تبدأ في الاستياء العادل من ما أفسده هؤلاء المطورين من أن IDE بدأ يتباطأ بشكل رهيب. أيدي لتمزيق هؤلاء المبرمجين المؤسفة.
وربما لم نغير أي شيء على الإطلاق. ربما يعمل البحث كما كان قبل ثلاث سنوات. قبل ثلاث سنوات فقط ، انتقلت للتو إلى Java 8 ، وكان لديك ، على سبيل المثال ، مائة lambdas في مشروعك. والآن قام زملائك بتحويل الفصول المجهولة إلى lambdas ، وبدأوا في استخدام التدفقات بفاعلية أو ربط نوع من المكتبات التفاعلية ، نتيجة لمصطلح lambdas لم يصبح مائة بل عشرة آلاف. والآن ، من أجل استخلاص الثلاثة lambdas اللازمة ، يجب البحث عن IDE مائة مرة أخرى.
قلت "ربما" لأننا بالطبع نعود إلى هذا البحث من وقت لآخر ونحاول تسريعه. ولكن هنا عليك أن تتجول ليس ضد التيار ، ولكن حتى الشلال. نحن نحاول ، ولكن عدد lambdas في المشاريع ينمو بسرعة كبيرة.