بالنسبة لأولئك الذين هم كسولون جدًا في قراءة كل شيء: يُقترح دحض سبع خرافات شعبية ، والتي تعتبر في مجال أبحاث التعلم الآلي غالبًا ما تكون صحيحة ، اعتبارًا من فبراير 2019. تتوفر هذه المقالة على
موقع ArXiv الإلكتروني بتنسيق pdf [باللغة الإنجليزية].
الأسطورة 1: TensorFlow هي مكتبة الموتر.
الأسطورة 2: تعكس قواعد بيانات الصور الصور الحقيقية الموجودة في الطبيعة.
الأسطورة 3: لا يستخدم باحثو MO مجموعات اختبار للاختبار.
الأسطورة 4: تدريب الشبكة العصبية يستخدم جميع بيانات الإدخال.
الأسطورة 5: تطبيع الدُفعة مطلوب لتدريب الشبكات المتبقية العميقة جدًا.
الأسطورة 6: الشبكات التي تحظى بالاهتمام أفضل من الالتواء.
الأسطورة 7: خرائط الأهمية هي طريقة موثوقة لتفسير الشبكات العصبية.
والآن للحصول على التفاصيل.
الأسطورة 1: TensorFlow هي مكتبة الموتر
في الواقع ، هذه مكتبة للعمل مع المصفوفات ، وهذا الاختلاف كبير جدًا.
في
الحوسبة العليا مشتقات مصفوفة وتنسور التعبيرات. لاو وآخرون. يوضح مؤلفو
NeurIPS 2018 أن مكتبة التمايز التلقائي الخاصة بهم ، القائمة على حساب التفاضل والتكامل الحقيقي ، تحتوي على أشجار تعبير أكثر إحكاما. الحقيقة هي أن حساب التفاضل والتكامل tensor يستخدم تدوين الفهرس ، والذي يسمح لك بالعمل على قدم المساواة مع الوضعين المباشر والعاكس.
يخفي ترقيم المصفوفة فهارس لتسهيل التدوين ، ولهذا السبب غالباً ما تصبح أشجار تعبير التمايز التلقائي معقدة للغاية.
النظر في الضرب المصفوفة C = AB. لدينا
للوضع المباشر و
على العكس. لإجراء الضرب بشكل صحيح ، تحتاج إلى مراقبة صارمة لترتيب الواصلات واستخدامها. من وجهة نظر التسجيل ، يبدو هذا مربكًا بالنسبة لشخص متورط في MO ، ولكن من وجهة نظر الحسابات ، يعد هذا عبءًا إضافيًا على البرنامج.
مثال آخر ، أقل تافهة: c = det (A). لدينا
للوضع المباشر و
على العكس. في هذه الحالة ، من الواضح أنه من المستحيل استخدام شجرة التعبير لكلا الوضعين ، بالنظر إلى أنها تتكون من عوامل تشغيل مختلفة.
بشكل عام ، الطريقة التي تنفذ بها TensorFlow والمكتبات الأخرى (على سبيل المثال ، Mathematica و Maple و Sage و SimPy و ADOL-C و TAPENADE و TensorFlow و Theano و PyTorch و HIPS autograd) التمايز التلقائي ، الأمر الذي يؤدي إلى حقيقة أنه من أجل الاتجاه المباشر والعكس يتم إنشاء أشجار تعبير مختلفة وغير فعالة في الوضع. ترقيم الموتر يتجنب هذه المشاكل بسبب تبادلية الضرب بسبب تدوين الفهرس. للحصول على تفاصيل حول كيفية عمل ذلك ، انظر الورقة العلمية.
اختبر المؤلفون طريقتهم من خلال إجراء تمايز تلقائي للنظام العكسي ، المعروف أيضًا باسم الانتشار الخلفي ، في ثلاث مهام مختلفة ، وقاس الوقت الذي استغرقه لحساب الهسيين.

في المشكلة الأولى ، تم تحسين الوظيفة التربيعية x
T Axe. في الثانية ، تم حساب الانحدار اللوجستي ، في عامل المصفوفة الثالثة.
على وحدة المعالجة المركزية (CPU) ، تحولت طريقتهم إلى أن يكون حجم الطلب أسرع من المكتبات الشائعة مثل TensorFlow و Theano و PyTorch و HIPS autograd.
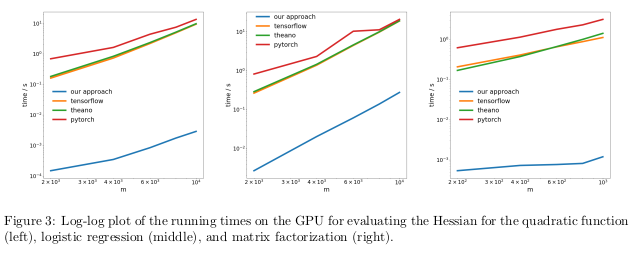
على GPU ، لاحظوا تسارع أكبر ، بقدر ثلاثة أوامر من حيث الحجم.
العواقب:حساب المشتقات لوظائف الترتيب الثاني أو العالي باستخدام مكتبات التعليم العميق الحالية يعد مكلفًا للغاية من الناحية الحسابية. يتضمن ذلك حساب التنسورات العامة من الدرجة الرابعة مثل Hessians (على سبيل المثال ، في MAML وتحسين نيوتن من الدرجة الثانية). لحسن الحظ ، الصيغ التربيعية نادرة في التعلم العميق. ومع ذلك ، فهي غالبًا ما توجد في التعليم الآلي "الكلاسيكي" -
SVM ، طريقة المربعات الصغرى ، LASSO ، العمليات الغوسية ، إلخ.
الأسطورة 2: تعكس قواعد بيانات الصور صورًا حقيقية
يحب الكثير من الناس الاعتقاد بأن الشبكات العصبية تعلمت التعرف على الأشياء أفضل من الأشخاص. هذا ليس كذلك. يمكن أن يكونوا متقدمين على الأشخاص على أساس الصور المحددة ، على سبيل المثال ، ImageNet ، ولكن في حالة التعرف على الكائنات من الصور الحقيقية من الحياة العادية ، فلن يتمكنوا بالتأكيد من تجاوز شخص بالغ عادي. وذلك لأن اختيار الصور في مجموعات البيانات الحالية لا يتزامن مع اختيار جميع الصور الممكنة التي يتم مواجهتها بشكل طبيعي في الواقع.
في عمل قديم إلى حد ما ،
انظر إلى "التحيز Dataset Bias". تورالبا وإفروس. CVPR 2011. ، اقترح المؤلفون دراسة التشوهات المرتبطة بمجموعة من الصور في اثني عشر قاعدة بيانات شائعة ، ومعرفة ما إذا كان من الممكن تدريب المصنف لتحديد مجموعة البيانات التي أخذت منها هذه الصورة.

فرص التخمين عن طريق الخطأ لمجموعة البيانات الصحيحة هي 1/12 ≈ 8٪ ، في حين أن العلماء أنفسهم تعاملوا مع المهمة بمعدل نجاح> 75٪.
لقد قاموا بتدريب SVM على رسم
بياني تدرج اتجاهي (HOG) ووجدوا أن المصنف أكمل المهمة في 39٪ من الحالات ، وهو ما يتجاوز بشكل كبير عدد الزيارات العشوائية. إذا كررنا هذه التجربة اليوم ، مع أكثر الشبكات العصبية تقدماً ، فسنرى بالتأكيد زيادة في دقة المصنف.
إذا كانت قواعد بيانات الصور تعرض الصور الحقيقية للعالم الحقيقي بشكل صحيح ، فلن يكون علينا أن نكون قادرين على تحديد مجموعة البيانات التي تأتي منها صورة معينة.

ومع ذلك ، هناك سمات في البيانات تجعل كل مجموعة من الصور مختلفة عن غيرها. لدى ImageNet العديد من سيارات السباق التي من غير المرجح أن تصف السيارة العادية "النظرية" ككل.

حدد المؤلفون أيضًا قيمة كل مجموعة بيانات عن طريق قياس مدى عمل المصنف المدرب على مجموعة واحدة مع الصور من مجموعات أخرى. وفقًا لهذا المقياس ، تبين أن قواعد البيانات LabelMe و ImageNet كانت الأقل تحيزًا ، حيث حصلت على تصنيف 0.58 باستخدام طريقة "سلة العملات". تبين أن جميع القيم أقل من الوحدة ، مما يعني أن التدريب على مجموعة بيانات مختلفة يؤدي دائمًا إلى ضعف الأداء. في عالم مثالي بدون مجموعات متحيزة ، ينبغي أن تكون بعض الأرقام قد تجاوزت الرقم.
اختتم المؤلفون تشاؤمهم:
فما هي قيمة مجموعات البيانات الموجودة لخوارزميات التدريب المصممة للعالم الحقيقي؟ يمكن وصف الجواب الناتج بأنه "أفضل من لا شيء ولكن ليس كثيرًا".
الأسطورة 3: لا يستخدم باحثو MO مجموعات اختبار للاختبار
في الكتاب المدرسي الخاص بالتعلم الآلي ، يتم تدريسنا لتقسيم مجموعة البيانات إلى التدريب والتقييم والتحقق. تساعد فعالية النموذج ، المدربة على مجموعة التدريب ، وتقييمها على التقييم الشخص المعني في MO على صقل النموذج لزيادة الكفاءة في استخدامه الفعلي. لا يلزم لمس مجموعة الاختبار حتى ينتهي الشخص من التعديل لتوفير تقييم غير متحيز للفعالية الحقيقية للنموذج في العالم الحقيقي. إذا قام شخص ما بالغش باستخدام مجموعة اختبار في مراحل التدريب أو التقييم ، فإن النموذج يتعرض لخطر التكيُّف الشديد مع مجموعة بيانات معينة.
في عالم أبحاث التنافسية المفرطة في التنافسية ، غالبًا ما يتم تقييم الخوارزميات والنماذج الجديدة من خلال فعالية عملهم باستخدام بيانات التحقق. لذلك ، لا معنى للباحثين في كتابة أو نشر أوراق تصف الأساليب التي تعمل بشكل سيء مع مجموعات بيانات الاختبار. وهذا يعني ، في جوهره ، أن مجتمع منطقة موسكو ككل يستخدم مجموعة اختبار للتقييم.
ما هي عواقب هذا الاحتيال؟

مؤلفو
هل CIFAR-10 المصنفون يعممون على CIFAR-10؟ Recht et al. حقق ArXiv
2018 في هذه المشكلة عن طريق إنشاء مجموعة اختبار جديدة لـ CIFAR-10. للقيام بذلك ، قاموا بعمل مجموعة مختارة من الصور من Tiny Images.
اختاروا CIFAR-10 لأنها واحدة من مجموعات البيانات الأكثر استخدامًا في MO ، وهي ثاني أكثر مجموعة شعبية في NeurIPS 2017 (بعد MNIST). يتم أيضًا وصف عملية إنشاء مجموعة بيانات لـ CIFAR-10 بشكل جيد وشفاف ، في قاعدة بيانات Tiny Images الكبيرة هناك الكثير من التسميات التفصيلية ، حتى تتمكن من إنتاج مجموعة اختبار جديدة ، مما يقلل من التحول في التوزيع.

وجدوا أن عددًا كبيرًا من النماذج المختلفة للشبكات العصبية في مجموعة الاختبار الجديدة أظهرت انخفاضًا كبيرًا في الدقة (4٪ - 15٪). ومع ذلك ، ظلت رتبة الأداء النسبي لكل نموذج مستقرة إلى حد ما.
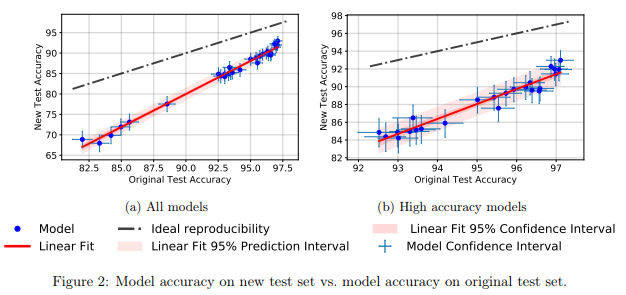
بشكل عام ، أظهرت النماذج ذات الأداء الأفضل انخفاضًا أقل دقة مقارنةً بالنماذج ذات الأداء الأسوأ. هذا أمر جيد لأنه يترتب على ذلك أن فقدان تعميم النموذج بسبب الغش ، على الأقل في حالة CIFAR-10 ، يتناقص مع قيام المجتمع باختراع أساليب ونماذج MO المحسنة.
الأسطورة 4: تدريب الشبكة العصبية يستخدم كل المدخلات
من المقبول عمومًا أن
البيانات هي نفط جديد ، وأنه كلما زاد عدد البيانات المتوفرة لدينا ، كلما تمكنا بشكل أفضل من تدريب نماذج التعلم العميقة التي أصبحت الآن غير كفؤة وعالية الكفاءة.
في
دراسة تطبيقية لنسيان المثال أثناء التعلم الشبكي العصبي العميق. تونيفا وآخرون. يوضح مؤلفو
ICLR 2019 التكرار الكبير في عدة مجموعات شائعة من الصور الصغيرة. من المثير للدهشة ، يمكن ببساطة إزالة 30 ٪ من البيانات من CIFAR-10 دون تغيير دقة الشيك بمقدار كبير.
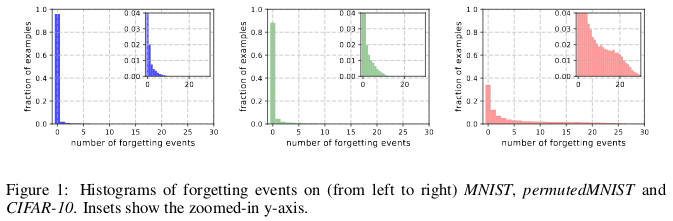 تاريخ النسيان من (اليسار إلى اليمين) MNIST ، permutedMNIST و CIFAR-10.
تاريخ النسيان من (اليسار إلى اليمين) MNIST ، permutedMNIST و CIFAR-10.يحدث النسيان عندما تصنف الشبكة العصبية صورة بشكل غير صحيح في الوقت t + 1 ، بينما في الوقت t كانت قادرة على تصنيف الصورة بشكل صحيح. يتم قياس تدفق الوقت بتحديثات SGD. لتتبع النسيان ، أطلق المؤلفون شبكتهم العصبية على مجموعة بيانات صغيرة بعد كل تحديث SGD ، وليس على جميع الأمثلة المتوفرة في قاعدة البيانات. الأمثلة التي لا تخضع للنسيان تسمى أمثلة لا تنسى.
وجدوا أن 91.7 ٪ MNIST ، و 75.3 ٪ permutedMNIST ، و 31.3 ٪ CIFAR-10 ، و 7.62 ٪ CIFAR-100 هي أمثلة لا تنسى. هذا أمر مفهوم بشكل حدسي ، لأن زيادة تنوع وتعقيد مجموعة البيانات يجب أن تجعل الشبكة العصبية تنسى المزيد من الأمثلة.

يبدو أن الأمثلة المنسية تظهر ميزات أكثر غرابة ونادرة مقارنة بميزات لا تنسى. قارنهم المؤلفون بنواقل الدعم في SVM ، حيث يبدو أنهم يرسمون حدود حدود القرار.
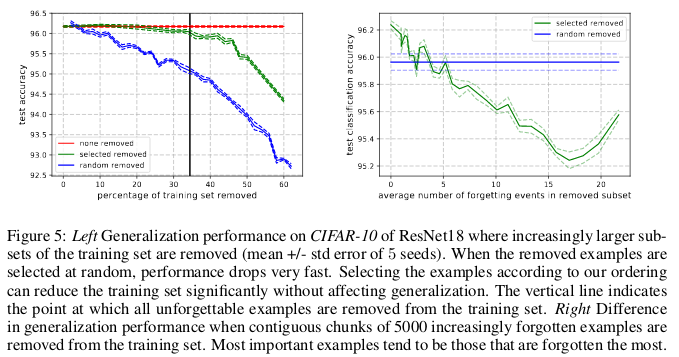
الأمثلة التي لا تنسى ، بدورها ، ترميز المعلومات الزائدة في الغالب. إذا قمنا بفرز الأمثلة حسب درجة عدم نسيانها ، فيمكننا ضغط مجموعة البيانات عن طريق حذف أكثرها لا تنسى.
يمكن حذف 30٪ من بيانات CIFAR-10 دون التأثير على دقة عمليات الفحص ، ويؤدي حذف 35٪ من البيانات إلى انخفاض طفيف في دقة الاختبارات بنسبة 0.2٪. إذا قمت بتحديد 30 ٪ من البيانات بشكل عشوائي ، فإن حذفها سيؤدي إلى خسارة كبيرة في دقة التحقق من 1 ٪.
وبالمثل ، يمكن إزالة 8 ٪ من البيانات من CIFAR-100 دون انخفاض دقة التحقق من الصحة.
توضح هذه النتائج أن هناك الكثير من التكرار في البيانات الخاصة بتدريب الشبكات العصبية ، على غرار تدريب SVM ، حيث يمكن إزالة المتجهات غير الداعمة دون التأثير على القرار النموذجي.
العواقب:إذا استطعنا تحديد أي من البيانات لا يُنسى قبل البدء في التدريب ، فيمكننا توفير مساحة بحذفها والوقت دون استخدامها عند تدريب شبكة عصبية.
الأسطورة 5: تطبيع الدُفعة مطلوب لتدريب الشبكات المتبقية العميقة جدًا.
لفترة طويلة ، كان يعتقد أن "تدريب شبكة عصبية عميقة للتحسين المباشر فقط لغرض متحكم به (على سبيل المثال ، الاحتمال اللوغاريتمي للتصنيف الصحيح) باستخدام النسب التدرج اللوني ، بدءاً بمعلمات عشوائية ، لا يعمل بشكل جيد."
كومة من الأساليب المبدعة للتهيئة العشوائية ، ووظائف التنشيط ، وتقنيات التحسين ، وغيرها من الابتكارات ، مثل الاتصالات المتبقية ، والتي ظهرت منذ ذلك الحين سهلت تدريب الشبكات العصبية العميقة باستخدام طريقة النسب التدرج.
ولكن حدث تقدم حقيقي بعد إدخال تطبيع الدُفعة (وتقنيات التطبيع المتسلسلة الأخرى) ، مما يحد من حجم عمليات التنشيط لكل طبقة من الشبكة من أجل القضاء على مشكلة التدرجات المختفية والانفجارية.
في عمل حديث ،
إصلاح التهيئة: التعلم المتبقي بدون التطبيع. تشانغ وآخرون. أظهر ICLR 2019 أنه من الممكن تدريب شبكة تضم 10 آلاف طبقة باستخدام SGD خالص دون تطبيق أي تطبيع.

قارن المؤلفون بين التدريب الشبكي العصبي المتبقي والأعماق المختلفة على CIFAR-10 ووجدوا أنه على الرغم من أن طرق التهيئة القياسية لم تنجح مع 100 طبقة ، فقد نجحت طرق التطبيع وإصلاح الدُفعات مع 10000 طبقة.

لقد أجروا تحليلًا نظريًا وأظهروا أن "تطبيع التدرج لطبقات معينة يقتصر على العدد المتزايد بلا حدود من شبكة عميقة" ، وهي مشكلة التدرجات المتفجرة. لمنع هذا ، يتم استخدام Foxup ، والفكرة الرئيسية في ذلك هو قياس الأوزان في طبقات m لكل فرع من الفروع المتبقية L بعدد المرات التي تعتمد على m و L.

ساعد Fixup في تدريب شبكة عميقة متبقية تحتوي على 110 طبقات على CIFAR-10 مع سرعة تعلم عالية مماثلة لسلوك شبكة ذات بنية مماثلة تم تدريبها باستخدام تسوية الدُفعات.
أظهر المؤلفون نتائج اختبار مماثلة باستخدام Fixup على الشبكة دون أي تطبيع ، والعمل مع قاعدة بيانات ImageNet وترجمات من الإنجليزية إلى الألمانية.
الأسطورة 6: الشبكات التي تحظى بالاهتمام أفضل من الشبكات التلافيفية.
فكرة أن آليات "الاهتمام" تفوق على الشبكات العصبية التلافيفية تكتسب شعبية في مجتمع الباحثين MO. في أعمال
Vaswani وزملاؤه ، لوحظ أن "التكلفة الحسابية للتلفيفات القابلة للفصل تساوي مزيج طبقة الانتباه الذاتي وطبقة التغذية الأمامية ذات النقاط الحساسة."
تُظهر الشبكات التنافسية التناسلية المتقدمة ميزة الاهتمام الذاتي بالالتفاف القياسي عند تصميم التبعيات طويلة المدى.
يولي المساهمون
اهتمامًا أقل من خلال تلطيفات خفيفة وديناميكية. وو وآخرون. ICLR 2019 يلقي ظلالا من الشك على الكفاءة والفعالية
حدية من الاهتمام الذاتي عند نمذجة التبعيات طويلة المدى ، وتقديم خيارات جديدة للالتفاف ، مستوحاة جزئيا من الاهتمام الذاتي ، وأكثر فعالية من حيث المعلمات.
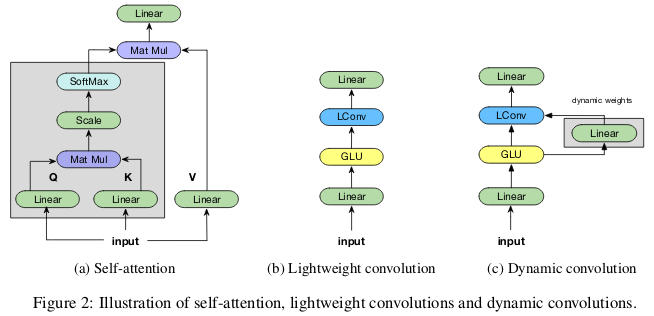
يمكن فصل التلفيفات "خفيفة الوزن" في العمق ، وتطبيعها في softmax في البعد الزمني ، مفصولة بالوزن في بعد القناة ، وإعادة استخدام نفس الأوزان في كل خطوة زمنية (مثل الشبكات العصبية المتكررة). تلوينات ديناميكية هي تلافيف خفيفة الوزن تستخدم أوزان مختلفة في كل خطوة زمنية.
هذه الحيل تجعل تلافيفات خفيفة الوزن وديناميكية عدة أوامر من حجم أكثر فعالية من تلافيف القياسية غير القابلة للتجزئة.

يوضح المؤلفون أن هذه التلفيقات الجديدة تتوافق مع شبكات الامتصاص الذاتي أو تتجاوزها في الترجمة الآلية ، ونمذجة اللغة ، ومشاكل الجمع المجردة ، باستخدام نفس المعلمات أو أقل منها.
الأسطورة 7: بطاقات الأهمية - طريقة موثوقة لتفسير الشبكات العصبية
على الرغم من وجود رأي مفاده أن الشبكات العصبية مربعات سوداء ، إلا أنه كانت هناك محاولات عديدة لتفسيرها. الأكثر شعبية من هذه الخرائط أهمية ، أو غيرها من الأساليب المماثلة التي تسند تقييمات الأهمية إلى ميزات أو أمثلة التدريب.
من المغري أن نكون قادرين على استنتاج أن صورة معينة قد تم تصنيفها بطريقة معينة بسبب بعض أجزاء الصورة المهمة للشبكة العصبية. لحساب خرائط الأهمية ، هناك العديد من الطرق التي تستخدم غالبًا تنشيط الشبكات العصبية في صورة معينة والتدرجات التي تمر عبر الشبكة.
في
تفسير الشبكات العصبية هشة. غرباني وآخرون. يُظهر مؤلفو
AAAI 2019 أنهم يمكنهم إدخال تغيير بعيد المنال في الصورة ، إلا أنه سيؤدي إلى تشويه خريطة أهميتها.

لا تحدد الشبكة العصبية فراشة العاهل حسب النمط الموجود على أجنحتها ، ولكن بسبب وجود أوراق خضراء غير مهمة على خلفية الصورة.

غالبًا ما تكون الصور متعددة الأبعاد أقرب إلى حدود القرارات التي تصنعها الشبكات العصبية العميقة ، ومن ثم فهي حساسة للهجمات العدائية. وإذا قامت الهجمات التنافسية بنقل الصور إلى ما وراء حدود الحل ، فإن الهجمات التفسيرية التنافسية تحولها على طول حدود الحل دون مغادرة أراضي الحل نفسه.
الطريقة الأساسية التي طورها المؤلفون هي تعديل طريقة Goodfello لوضع علامات التدرج السريع ، والتي كانت واحدة من أولى الطرق الناجحة للهجمات التنافسية. يمكن افتراض أنه يمكن أيضًا استخدام هجمات أخرى أحدث وأكثر تعقيدًا للهجمات على تفسير الشبكات العصبية.
العواقب:بسبب الانتشار المتزايد للتعلم العميق في مجالات التطبيق المهمة مثل التصوير الطبي ، من المهم أن نتبع بعناية تفسير القرارات التي تتخذها الشبكات العصبية. على سبيل المثال ، على الرغم من أنه سيكون من الرائع أن تتعرف الشبكة العصبية التلافيفية على البقعة الموجودة على صورة التصوير بالرنين المغناطيسي كورم خبيث ، إلا أنه لا ينبغي الوثوق بهذه النتائج إذا كانت تستند إلى طرق تفسير غير موثوقة.