هذا هو الجزء الثاني من سلسلة من المقالات حول النظم التحليلية (
رابط إلى الجزء 1 ).

اليوم ليس هناك شك في أن المعالجة الدقيقة للبيانات وتفسير النتائج يمكن أن تساعد أي نوع من الأعمال تقريبًا. في هذا الصدد ، أصبحت الأنظمة التحليلية محملة على نحو متزايد بالمعلمات ، ويتزايد عدد المشغلات وأحداث المستخدمين في التطبيقات.
ولهذا السبب ، تقدم الشركات لمحلليها المزيد والمزيد من المعلومات "الخام" لتحليلها وتحويلها إلى القرارات الصحيحة. لا ينبغي التقليل من أهمية نظام التحليلات بالنسبة للشركة ، ويجب أن يكون النظام نفسه موثوقًا به ومستدامًا.
تحليلات العملاء
تحليلات العملاء هي خدمة تتصل بها الشركة على موقع الويب أو التطبيق من خلال SDK الرسمي ، وتندمج في قاعدة الكود الخاصة بها وتختار مشغلات الأحداث. هذا النهج له عيب واضح: لا يمكن معالجة جميع البيانات التي تم جمعها بالكامل كما تريد ، بسبب قيود أي خدمة محددة. على سبيل المثال ، في نظام ما ، لن يكون من السهل تشغيل مهام MapReduce ، وفي نظام آخر لن تتمكن من تشغيل النموذج الخاص بك. سيكون العيب الآخر فاتورة عادية (رائعة) للخدمات.
هناك العديد من حلول تحليلات العملاء في السوق ، ولكن عاجلاً أم آجلاً ، يواجه المحللون حقيقة أنه لا توجد خدمة عالمية واحدة مناسبة لأي مهمة (في حين أن أسعار جميع هذه الخدمات تنمو باستمرار). في هذه الحالة ، غالبًا ما تقرر الشركات إنشاء نظام تحليلات خاص بها مع كل الإعدادات والإمكانيات المخصصة الضرورية.
تحليلات الخادم
تحليلات الخادم هي خدمة يمكن نشرها داخليًا في شركة ما على خوادمها الخاصة (عادةً) بجهودها الخاصة. في هذا النموذج ، يتم تخزين جميع أحداث المستخدم على خوادم داخلية ، مما يسمح للمطورين بتجربة قواعد بيانات مختلفة للتخزين واختيار الهيكل الأكثر ملاءمة. وحتى إذا كنت لا تزال ترغب في استخدام تحليلات عملاء لجهة خارجية لبعض المهام ، فسيظل ذلك ممكنًا.
يمكن نشر تحليلات الخادم بطريقتين. أولاً: حدد بعض الأدوات المساعدة مفتوحة المصدر ، ونشرها على أجهزتك وتطوير منطق العمل.
| الأشياء الجيدة | سلبيات |
| يمكنك تخصيص أي شيء | في كثير من الأحيان يكون من الصعب للغاية وهناك حاجة للمطورين الفردية |
ثانياً: خذ خدمات SaaS (Amazon ، Google ، Azure) بدلاً من نشرها بنفسك. حول ادارة العلاقات مع مزيد من التفاصيل سنقول في الجزء الثالث.
| الأشياء الجيدة | سلبيات |
| قد يكون أرخص على وحدات التخزين المتوسطة ، ولكن مع نمو كبير فإنه سيظل باهظ الثمن | لا يمكن التحكم في جميع المعلمات |
| يتم نقل الإدارة بالكامل إلى أكتاف مزود الخدمة | ليس من المعروف دائمًا ما هو داخل الخدمة (قد لا تكون هناك حاجة) |
كيفية جمع تحليلات الخادم
إذا كنا نريد الابتعاد عن استخدام تحليلات العملاء وتجميع تحليلاتنا الخاصة ، فيجب أولاً وقبل كل شيء التفكير في بنية النظام الجديد. فيما يلي ، سأخبرك خطوة بخطوة بما يجب مراعاته ولماذا يلزم كل خطوة من الخطوات والأدوات التي يمكنك استخدامها.
1. الحصول على البيانات
كما في حالة تحليلات العملاء ، أولاً وقبل كل شيء ، يختار محللو الشركة أنواع الأحداث التي يرغبون في دراستها في المستقبل ويجمعونها في قائمة. عادة ، تحدث هذه الأحداث في ترتيب معين ، والذي يسمى "نمط الحدث".
بعد ذلك ، تخيل أن تطبيق الهاتف المحمول (موقع الويب) يحتوي على مستخدمين عاديين (أجهزة) والعديد من الخوادم. لنقل الأحداث بشكل آمن من الأجهزة إلى الخوادم ، هناك حاجة إلى طبقة وسيطة. اعتمادًا على البنية ، قد تحدث عدة قوائم انتظار أحداث مختلفة.
Apache Kafka عبارة عن
قائمة انتظار حانة / فرعية يتم استخدامها كقائمة انتظار لجمع الأحداث.
وفقًا لموضوع نشر على Kvor في عام 2014 ، قرر مُصمم Apache Kafka تسمية البرنامج باسم Franz Kafka لأنه "نظام مُحسن للتسجيل" ولأنه أحب أعمال Kafka. - ويكيبيديا
في مثالنا ، يوجد العديد من منتجي البيانات ومستهلكيهم (الأجهزة والخوادم) ، ويساعد تطبيق كافكا في توصيلهم ببعضهم البعض. سيتم وصف المستهلكين بمزيد من التفصيل في الخطوات التالية ، حيث سيكونون الممثلين الرئيسيين. الآن سوف ننظر فقط منتجي البيانات (الأحداث).
تتضمن كافكا مفاهيم قائمة الانتظار والقسم ؛ وبشكل أكثر تحديدًا ، من الأفضل أن تقرأ عنها في مكان آخر (على سبيل المثال ، في
الوثائق ). دون الخوض في التفاصيل ، تخيل أنه يتم تشغيل تطبيق جوال لنظامي تشغيل مختلفين. ثم يقوم كل إصدار بإنشاء دفق أحداث منفصل خاص به. يرسل المنتجون الأحداث إلى كافكا ، ويتم تسجيلهم في قائمة انتظار مناسبة.
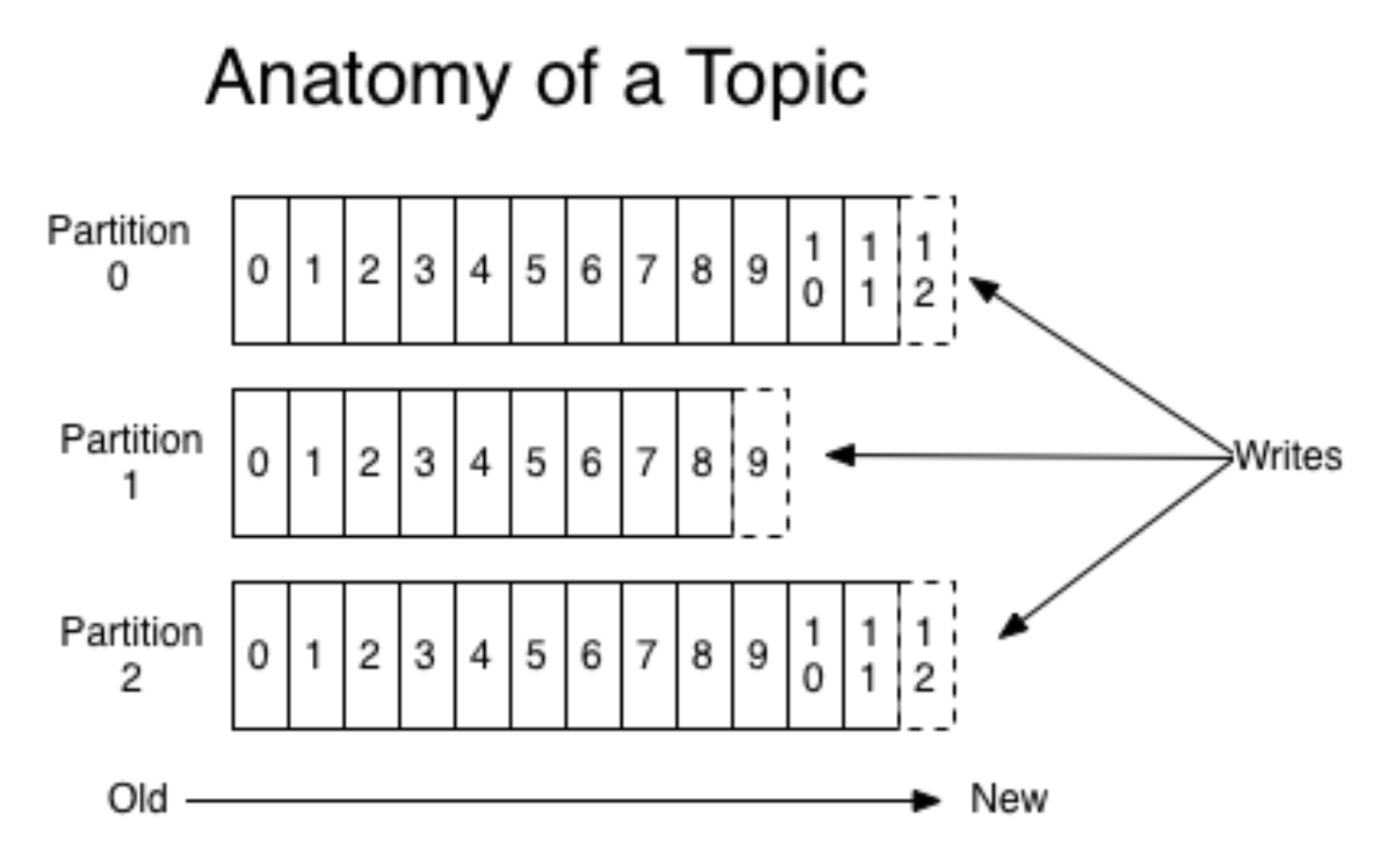
(الصورة
من هنا )
في نفس الوقت ، يسمح لك Kafka بقراءة الأجزاء ومعالجة تدفق الأحداث باستخدام الخفافيش الصغيرة. يعتبر Kafka أداة مريحة للغاية تتناسب بشكل جيد مع الاحتياجات المتزايدة (على سبيل المثال ، عن طريق تحديد الموقع الجغرافي للأحداث).
عادةً ما تكون قشرة واحدة كافية ، لكن الأمور تصبح أكثر صعوبة بسبب التحجيم (كما هو الحال دائمًا). ربما لن يرغب أحد في استخدام قشرة فعلية واحدة فقط في الإنتاج ، حيث يجب أن تكون البنية متسامحة مع الخطأ. بالإضافة إلى كافكا ، هناك حل آخر معروف - RabbitMQ. لم نستخدمها في الإنتاج كقائمة انتظار لتحليل الأحداث (إذا كان لديك مثل هذه التجربة ، فأخبرنا عنها في التعليقات!). ومع ذلك ، استخدموا AWS Kinesis.
قبل الانتقال إلى الخطوة التالية ، نحتاج إلى ذكر طبقة إضافية أخرى من النظام - تخزين السجلات الأولية. هذه ليست طبقة مطلوبة ، ولكنها ستكون مفيدة إذا حدث خطأ ما وتم إعادة ضبط قوائم انتظار الأحداث في كافكا. لا يتطلب تخزين السجلات الأولية حلاً معقدًا ومكلفًا ؛ يمكنك ببساطة تسجيلها في مكان ما بالترتيب الصحيح (حتى على محرك الأقراص الثابتة).

2. معالجة تيارات الحدث
بعد أن أعددنا جميع الأحداث ووضعناها في طوابير مناسبة ، ننتقل إلى خطوة المعالجة. هنا سأتحدث عن خياري المعالجة الأكثر شيوعًا.
الخيار الأول هو تمكين Spark Streaming على نظام Apache. تعيش جميع منتجات Apache في HDFS ، وهو نظام ملفات متماثلة آمن للملفات. Spark Streaming هي أداة سهلة الاستخدام تقوم بمعالجة تدفق البيانات وقياسها جيدًا. ومع ذلك ، يمكن أن يكون من الصعب قليلا الحفاظ عليها.
خيار آخر هو بناء معالج الأحداث الخاص بك. للقيام بذلك ، على سبيل المثال ، تحتاج إلى كتابة تطبيق Python ، وإنشاءه في عامل ميناء والاشتراك في قائمة انتظار كافكا. عندما تصل المشغلات إلى المعالجات في عامل الميناء ، ستبدأ المعالجة. مع هذه الطريقة ، تحتاج إلى الاستمرار في تشغيل التطبيقات باستمرار.
افترض أننا اخترنا أحد الخيارات الموضحة أعلاه والمضي قدمًا في المعالجة نفسها. يجب أن تبدأ المعالجات بالتحقق من صلاحية البيانات وتصفية البيانات المهملة والأحداث "المعطلة". للتحقق من الصحة نستخدم عادة
Cerberus . بعد ذلك ، يمكنك إجراء مناظرة للبيانات: تطبيع البيانات من مصادر مختلفة وتوحيدها لإضافتها إلى التصنيف العام.
3. قاعدة البيانات
الخطوة الثالثة هي الحفاظ على الأحداث الطبيعية. عند العمل بنظام تحليلي جاهز ، سيتعين علينا الاتصال بهم في كثير من الأحيان ، لذلك من المهم اختيار قاعدة بيانات ملائمة.
إذا كانت البيانات تتلاءم جيدًا مع مخطط ثابت ، يمكنك اختيار
Clickhouse أو قاعدة بيانات عمود أخرى. لذلك ستعمل المجموعات بسرعة كبيرة. الجانب السلبي هو أن المخطط ثابت بشكل صارم وبالتالي فإن الكائنات التعسفية القابلة للطي دون صقل ستفشل (على سبيل المثال ، عند حدوث حدث غير قياسي). ولكن يمكنك الاعتماد بسرعة حقا.
بالنسبة للبيانات غير المنظمة ، يمكنك استخدام NoSQL ، على سبيل المثال ،
Apache Cassandra . كان يعمل على HDFS ، يتم نسخها بشكل جيد ، يمكنك رفع العديد من الحالات ، خطأ التسامح.
يمكنك التقاط شيء أكثر بساطة ، على سبيل المثال ،
MongoDB . انها بطيئة جدا وبالنسبة للكميات الصغيرة. لكن الإيجابيات هي أنها بسيطة للغاية وبالتالي مناسبة للبدء.
4. التجميعات
بعد حفظ جميع الأحداث بعناية ، نريد جمع جميع المعلومات المهمة من المجموعة التي جاءت وتحديث قاعدة البيانات. على المستوى العالمي ، نريد الحصول على لوحات المعلومات والمقاييس ذات الصلة. على سبيل المثال ، من الأحداث إلى جمع ملف تعريف المستخدم وقياس السلوك بطريقة أو بأخرى. يتم تجميع الأحداث وتجميعها وحفظها مرة أخرى (موجودة بالفعل في جداول المستخدمين). في الوقت نفسه ، يمكنك إنشاء النظام بحيث يمكنك أيضًا توصيل عامل تصفية بمنسق المجمع: لا تجمع المستخدمين إلا من نوع معين من الأحداث.
بعد ذلك ، إذا كان شخص ما في الفريق يحتاج فقط إلى تحليلات عالية المستوى ، يمكنك توصيل أنظمة التحليل الخارجية. يمكنك أن تأخذ Mixpanel مرة أخرى. ولكن نظرًا لأنه مكلف للغاية ، فلا يتم إرسال جميع أحداث المستخدم إلى هناك ، ولكن فقط ما هو مطلوب. للقيام بذلك ، تحتاج إلى إنشاء منسق يقوم بنقل بعض الأحداث الأولية أو أي شيء قمنا بتجميعه مسبقًا إلى أنظمة خارجية أو واجهات برمجة التطبيقات أو منصات الإعلان.
5. الواجهة الأمامية
تحتاج إلى توصيل الواجهة الأمامية بالنظام الذي تم إنشاؤه. ومن الأمثلة الجيدة على
ذلك خدمة
redash ، وهي واجهة المستخدم الرسومية لقواعد البيانات التي تساعد في إنشاء اللوحات. كيف يعمل التفاعل:
- يقوم المستخدم بإجراء استعلام SQL.
- ردا على ذلك ، يتلقى الكمبيوتر اللوحي.
- بالنسبة لها ، تصنع "تصوراً جديداً" وتحصل على جدول جميل يمكن حفظه بالفعل لنفسها.
يتم تحديث المرئيات في الخدمة تلقائيًا ، ويمكنك تكوين وتتبع المراقبة الخاصة بك. Redash مجاني ، في حالة الاستضافة الذاتية ، وكيف ستكلف SaaS 50 دولارًا شهريًا.

استنتاج
بعد الانتهاء من جميع الخطوات المذكورة أعلاه ، ستقوم بإنشاء تحليلات الخادم الخاص بك. يرجى ملاحظة أن هذه ليست طريقة سهلة مثل مجرد ربط تحليلات العملاء ، لأن كل شيء يحتاج إلى تكوين مستقل. لذلك ، قبل إنشاء نظامك الخاص ، يجدر بمقارنة الحاجة إلى نظام تحليلات جاد بالموارد التي أنت مستعد لتخصيصها لها.
إذا قمت بحساب كل شيء وتوصلت إلى أن التكاليف مرتفعة للغاية ، فسأتحدث في الجزء التالي عن كيفية إنشاء نسخة أرخص من تحليلات الخادم.
شكرا للقراءة! سأكون سعيدًا للأسئلة الواردة في التعليقات.