
هذا هو استمرار لقصة طويلة حول طريقنا الشائك إلى إنشاء نظام قوي ومحمّل بدرجة كبيرة يضمن تشغيل البورصة.
الجزء الأول هنا .
خطأ غامض
بعد العديد من الاختبارات ، تم تشغيل نظام التداول والمقاصة المحدّث ، وواجهنا مشكلة كان من الصواب أن نكتب قصة تحريرية صوفية فيها.
بعد وقت قصير من البدء على الخادم الرئيسي ، تمت معالجة إحدى المعاملات بخطأ. في الوقت نفسه ، كان كل شيء بالترتيب على خادم النسخ الاحتياطي. اتضح أن العملية الحسابية البسيطة لحساب الأس على الخادم الرئيسي أعطت نتيجة سلبية من حجة صالحة! استمرت عمليات المسح ، وفي سجل SSE2 وجدوا فرقًا في وحدة البت الواحدة ، وهي المسؤولة عن التقريب عند العمل بأرقام الفاصلة العائمة.
لقد كتبوا أداة اختبار بسيطة لحساب الأس مع مجموعة تقريب البتات. اتضح أنه في إصدار RedHat Linux الذي استخدمناه ، كان هناك خلل في العمل مع دالة رياضية عندما تم إدراج البت الخاطئ. أبلغنا بذلك إلى RedHat ، بعد فترة من الوقت تلقينا رقعة منها ولفناها. لم يعد الخطأ قد حدث ، لكن لم يتضح من أين أتت هذه القطعة؟ كانت وظيفة
fesetround من C هي المسؤولة عنها ، وقد قمنا بتحليل الكود الخاص بنا بعناية بحثًا عن الخطأ المزعوم: فحص جميع الحالات المحتملة ؛ النظر في جميع الوظائف التي تستخدم التقريب ؛ حاول لعب جلسة فاشلة ؛ تستخدم مترجمين مختلفين مع خيارات مختلفة ؛ يستخدم تحليل ثابت وديناميكي.
لا يمكن العثور على سبب الخطأ.
ثم بدأوا في التحقق من الأجهزة: لقد أجروا اختبارات تحميل المعالجات ؛ فحص ذاكرة الوصول العشوائي. حتى ركض الاختبارات لسيناريو من غير المرجح للغاية لخطأ متعدد بت في خلية واحدة. ولكن دون جدوى.
في النهاية ، استقروا على نظريات عالم الفيزياء عالية الطاقة: طار بعض الجسيمات عالية الطاقة إلى مركز البيانات الخاص بنا ، واخترق جدار الجسم ، وضرب المعالج وتسبب في مزلاج الزناد في نفس الوقت. هذه النظرية السخيفة كانت تسمى "النيوترينو". إذا كنت بعيدًا عن فيزياء الجسيمات الأولية: بالكاد تتفاعل النيوتريونات مع العالم الخارجي ، وبالتأكيد لن تكون قادرة على التأثير على المعالج.
نظرًا لأنه لم يكن من الممكن العثور على سبب الفشل ، فقط في حالة استبعاد الخادم "المتأخر" عن التشغيل.
بعد مرور بعض الوقت ، بدأنا في تحسين نظام الاستعداد الساخن: قدمنا ما يسمى "الاحتياطيات الدافئة" (النسخ المتماثلة غير المتزامنة). لقد تلقوا مجموعة من المعاملات التي قد تكون في مراكز بيانات مختلفة ، ولكن دافئ لا يدعم التفاعل النشط مع خوادم أخرى.
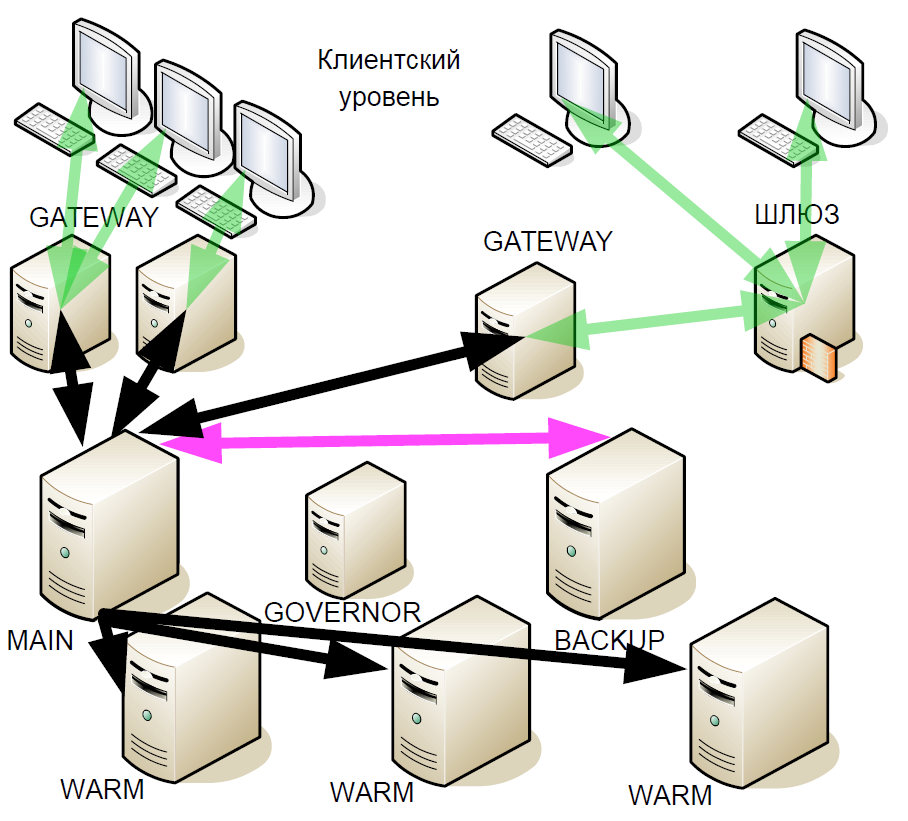
لماذا تم ذلك؟ في حالة فشل خادم النسخ الاحتياطي ، يصبح الربط الحار بالخادم الرئيسي هو النسخة الاحتياطية الجديدة. هذا ، بعد الفشل ، لا يبقى النظام حتى نهاية جلسة التداول مع خادم رئيسي واحد.
وعندما تم اختبار الإصدار الجديد من النظام ودخوله حيز التنفيذ ، حدث خطأ في التقريب مرة أخرى. علاوة على ذلك ، مع زيادة عدد الخوادم الدافئة ، بدأ الخطأ في الظهور مرات أكثر. في هذه الحالة ، لم يكن لدى البائع أي شيء ، حيث لا يوجد دليل ملموس.
أثناء التحليل التالي للوضع ، نشأت النظرية أن المشكلة يمكن أن تكون مرتبطة بنظام التشغيل. لقد كتبنا برنامجًا بسيطًا يستدعي الدالة
fesetround في حلقة لا نهاية لها ، يتذكر الحالة الحالية
fesetround أثناء النوم ، ويتم ذلك في العديد من الخيوط المتنافسة. بعد تحديد معلمات السكون وعدد الخيوط ، بدأنا في إعادة إنتاج فشل البت بشكل مستقر بعد حوالي 5 دقائق من الأداة. ومع ذلك ، كان ريد هات الدعم غير قادر على إنتاجه. أظهر اختبار خوادمنا الأخرى أن الخوادم التي لها معالجات معينة فقط هي التي تتأثر. في الوقت نفسه ، حل الانتقال إلى نواة جديدة المشكلة. في النهاية ، استبدلنا نظام التشغيل فقط ، وظل السبب الحقيقي لهذا الخطأ غير واضح.
وفجأة ، ظهرت مقالة في العام الماضي عن حبري بعنوان "
كيف وجدت خللًا في معالجات Intel Skylake ". كان الموقف الموصوف فيه مشابهاً للغاية لحالنا ، لكن المؤلف تقدم أكثر في التحقيق وقدم نظرية مفادها أن الخطأ كان في الرمز الصغير. وعند تحديث نواة Linux ، يقوم المصنعون أيضًا بتحديث الرمز الصغير.
مزيد من التطوير للنظام
على الرغم من أننا تخلصنا من الخطأ ، إلا أن هذه القصة جعلتنا نعيد النظر في بنية النظام مرة أخرى. بعد كل شيء ، لم نكن محمية من تكرار هذه الأخطاء.
شكلت المبادئ التالية الأساس لمزيد من التحسينات لنظام النسخ الاحتياطي:
- لا يمكنك الوثوق بأي شخص. خوادم قد لا تعمل بشكل صحيح.
- أغلبية التكرار.
- بناء التوافق. كمكمل منطقي لتكرار الأغلبية.
- الفشل المزدوج ممكن.
- حيوية. يجب ألا يكون مخطط قطع الغيار الساخن الجديد أسوأ من المخطط السابق. يجب أن تتم التجارة بسلاسة حتى آخر خادم.
- زيادة طفيفة في التأخير. أي توقف يستتبع خسائر مالية ضخمة.
- الحد الأدنى من تفاعل الشبكة بحيث يكون التأخير منخفضًا قدر الإمكان.
- حدد خادم رئيسي جديد في ثوان.
لم يناسبنا أي من الحلول المتاحة في السوق ، ولم يكن بروتوكول Raft في بدايته ، لذا قمنا بإنشاء الحل الخاص بنا.

اتصال الشبكة
بالإضافة إلى نظام النسخ الاحتياطي ، بدأنا في تحديث اتصال الشبكة. كان نظام الإدخال / الإخراج الفرعي العديد من العمليات ، والتي أثرت في أسوأ الأحوال على الارتعاش والتأخير. نظرًا لوجود مئات العمليات التي تعالج اتصالات TCP ، فقد اضطررنا إلى التبديل بينها باستمرار ، وعلى نطاق القياس الجزئي ، هذه عملية طويلة إلى حد ما. ولكن الجزء الأسوأ هو أنه عندما تتلقى عملية ما حزمة من أجل المعالجة ، فقد أرسلتها إلى قائمة انتظار SystemV واحدة ، ثم انتظرت الأحداث من قائمة انتظار SystemV أخرى. ومع ذلك ، مع وجود عدد كبير من العقد ، يمثل وصول حزمة TCP جديدة في عملية واحدة واستلام البيانات في قائمة انتظار في حدثين آخرين منافسين لنظام التشغيل. في هذه الحالة ، إذا لم تكن هناك معالجات فعلية متاحة لكلتا المهمتين ، فستتم معالجة واحدة ، والثاني في قائمة انتظار الانتظار. من المستحيل التنبؤ بالعواقب.
في مثل هذه الحالات ، يمكنك تطبيق التحكم في أولوية العمليات الديناميكية ، ولكن هذا سيتطلب استخدام مكالمات النظام كثيفة الاستخدام للموارد. نتيجة لذلك ، تحولنا إلى مؤشر ترابط واحد باستخدام epoll الكلاسيكية ، مما أدى إلى زيادة كبيرة في السرعة وتقليل وقت معالجة المعاملة. لقد تخلصنا أيضًا من بعض عمليات تفاعل الشبكة والتفاعل من خلال SystemV ، حيث قللنا كثيرًا من عدد مكالمات النظام وبدأنا نتحكم في أولويات العمليات. باستخدام نظام إدخال / إخراج فرعي واحد فقط ، كان من الممكن حفظ حوالي 8-17 ميكروثانية ، اعتمادًا على السيناريو. منذ ذلك الحين تم تطبيق هذا المخطط المفرد بدون تغيير ، دفق epoll واحد بهامش يكفي لخدمة جميع الاتصالات.
معالجة المعاملات
يتطلب الحمل المتزايد على نظامنا تحديث جميع مكوناته تقريبًا. ولكن لسوء الحظ ، فإن الركود في الزيادة في سرعة ساعة المعالج في السنوات الأخيرة لم يعد يسمح لنا بتوسيع نطاق العمليات "المباشرة". لذلك ، قررنا تقسيم عملية Engine إلى ثلاثة مستويات ، أكثرها تحميلًا هو نظام التحقق من المخاطر ، الذي يقيم مدى توفر الأموال في الحسابات وإنشاء المعاملات بنفسها. لكن يمكن أن يكون المال بعملات مختلفة ، وكان من الضروري معرفة مبدأ تقسيم معالجة الطلبات.
الحل المنطقي هو تقسيم العملة: يتاجر خادم واحد بالدولار ، وآخر بالجنيه ، ويورو ثالث. ولكن إذا تم ، مع مثل هذا المخطط ، إرسال معاملتين لشراء عملات مختلفة ، فستكون هناك مشكلة في محافظ غير متزامنة. والمزامنة صعبة ومكلفة. لذلك ، سيكون من الصحيح أن تتقاسم بشكل منفصل على محافظ وبشكل منفصل على الأدوات. بالمناسبة ، في معظم التبادلات الغربية ، مهمة التحقق من المخاطر ليست حادة مثل مهمتنا ، لذلك يتم ذلك في أغلب الأحيان دون اتصال بالإنترنت. نحن بحاجة لتنفيذ فحص عبر الإنترنت.
دعونا توضيح مع مثال. يريد التاجر شراء 30 دولارًا ، ويذهب الطلب للتحقق من صحة المعاملة: نتحقق مما إذا كان هذا التاجر مسموحًا به في وضع التداول هذا ، وما إذا كان لديه الحقوق اللازمة. إذا كان كل شيء على ما يرام ، فسيذهب الطلب إلى نظام التحقق من المخاطر ، أي للتحقق من كفاية الأموال لإتمام الصفقة. هناك ملاحظة أن المبلغ المطلوب محظور حاليًا. علاوة على ذلك ، يتم إعادة توجيه الطلب إلى نظام التداول ، الذي يوافق أو لا يوافق على هذه الصفقة. دعنا نقول الموافقة على الصفقة - ثم يشير نظام التحقق من المخاطر إلى أن الأموال قد تم فتحها وأن الروبل يتم تحويلها إلى دولارات.
بشكل عام ، يحتوي نظام التحقق من المخاطر على خوارزميات معقدة وينفذ عددًا كبيرًا من العمليات الحسابية الكثيفة الاستخدام للموارد ، ولا يتحقق فقط من "رصيد الحساب" ، كما قد يبدو للوهلة الأولى.
عندما بدأنا تقسيم عملية Engine إلى مستويات ، واجهنا مشكلة: الشفرة التي كانت متاحة في ذلك الوقت في مراحل التحقق والتحقق تستخدم بنشاط نفس صفيف البيانات ، الأمر الذي تطلب إعادة كتابة قاعدة الشفرة بأكملها. نتيجة لذلك ، استعارنا منهجية لمعالجة الإرشادات من المعالجات الحديثة: يتم تقسيم كل منها إلى مراحل صغيرة ويتم تنفيذ العديد من الإجراءات بشكل متوازٍ في دورة واحدة.
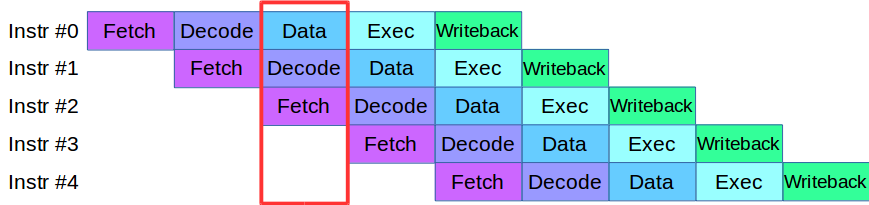
بعد تعديل بسيط للشفرة ، أنشأنا خط أنابيب للمعالجة المتوازية للمعاملات ، حيث تم تقسيم المعاملة إلى 4 مراحل من خط الأنابيب: تفاعل الشبكة ، والتحقق من صحة ، وتنفيذ ، ونشر النتيجة

النظر في مثال. لدينا نظامين للمعالجة ، مسلسل ومتوازي. تصل المعاملة الأولى ، وفي كلا النظامين ، يتم التحقق من الصحة. ثم تصل المعاملة الثانية: في نظام مواز ، يتم نقلها على الفور إلى العمل ، وفي نظام متسلسل يتم وضعها في قائمة الانتظار في انتظار أول معاملة تمر بمرحلة المعالجة الحالية. أي أن الميزة الرئيسية لخطوط الأنابيب هي أننا نقوم بمعالجة قائمة انتظار المعاملات بشكل أسرع.
لذلك حصلنا على نظام ASTS +.
صحيح ، مع الناقلات ، أيضا ، ليس كل شيء على نحو سلس جدا. لنفترض أن لدينا معاملة تؤثر على صفائف البيانات في معاملة مجاورة ، فهذا موقف مثالي للتبادل. لا يمكن تنفيذ هذه المعاملة في خط الأنابيب ، لأنها يمكن أن تؤثر على الآخرين. يُطلق على هذا الموقف "خطر البيانات" ، وتتم معالجة هذه المعاملات ببساطة بشكل منفصل: عندما تتوقف المعاملات "السريعة" في نهاية قائمة الانتظار ، يعالج خط الأنابيب ، ويقوم النظام بمعالجة المعاملة "البطيئة" ثم يبدأ تشغيل خط الأنابيب مرة أخرى. لحسن الحظ ، فإن حصة هذه المعاملات في إجمالي التدفق صغيرة جدًا ، لذا فإن خط الأنابيب نادراً ما يتوقف بحيث لا يؤثر على الأداء الكلي.

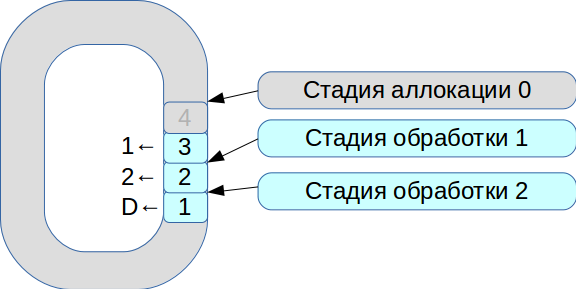
ثم بدأنا في حل مشكلة مزامنة ثلاثة خيوط للتنفيذ. نتيجة لذلك ، تم إنشاء نظام يعتمد على مخزن مؤقت دائري مع خلايا ذات حجم ثابت. في هذا النظام ، كل شيء يخضع لسرعة المعالجة ، لا يتم نسخ البيانات.
- جميع حزم الشبكة الواردة تدخل في مرحلة التخصيص.
- نضعها في صفيف ونضع علامة على أنها متاحة للمرحلة الأولى.
- وجاءت الصفقة الثانية ، وهي متاحة مرة أخرى للمرحلة رقم 1.
- يشاهد تدفق المعالجة الأول المعاملات المتوفرة ، ويقوم بمعالجتها ، وينقلها إلى المرحلة التالية من تدفق المعالجة الثاني.
- ثم تقوم بمعالجة المعاملة الأولى وتحديد الخلية المقابلة بالعلامة
deleted - وهي الآن متوفرة للاستخدام الجديد.
وبالتالي ، تتم معالجة قائمة الانتظار بأكملها.
معالجة كل مرحلة تأخذ وحدات أو عشرات من ميكروثانية. وإذا كنت تستخدم أنظمة مزامنة نظام التشغيل القياسية ، فسوف نفقد المزيد من الوقت في المزامنة نفسها. لذلك ، بدأنا في استخدام spinlock. ومع ذلك ، هذه نغمة سيئة للغاية في نظام الوقت الفعلي ، وتوصي RedHat بشدة بعدم القيام بذلك ، لذلك نستخدم spinlock لمدة 100 مللي ثانية ، ثم ننتقل إلى وضع إشارة لاستبعاد احتمال حدوث حالة توقف تام.
نتيجة لذلك ، حققنا أداءً بلغ حوالي 8 ملايين معاملة في الثانية. وبعد شهرين فقط ، في
مقال حول LMAX Disruptor ، رأوا وصفًا لدائرة لها نفس الوظيفة.
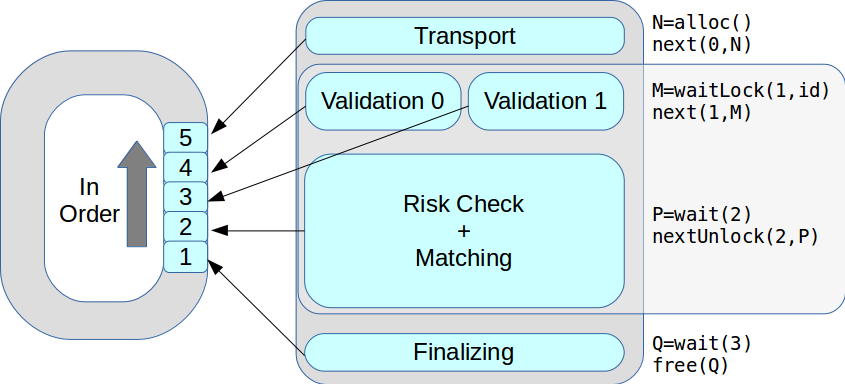
الآن في مرحلة واحدة يمكن أن يكون هناك العديد من خيوط التنفيذ. تمت معالجة جميع المعاملات بدورها ، بالترتيب المستلم. ونتيجة لذلك ، ارتفع أداء الذروة من 18 ألف إلى 50 ألف معاملة في الثانية.
نظام إدارة مخاطر الصرف
لا يوجد حد للكمال ، وسرعان ما بدأنا في التحديث مرة أخرى: في إطار ASTS + ، بدأنا في نقل أنظمة إدارة المخاطر وعمليات التسوية إلى مكونات مستقلة. قمنا بتطوير بنية حديثة مرنة ونموذج خطر هرمي جديد ، حاولنا حيثما أمكن استخدام فئة
fixed_point بدلاً من
double .
ولكن على الفور نشأت المشكلة: كيفية مزامنة كل منطق العمل الذي كان يعمل لسنوات عديدة ونقله إلى النظام الجديد؟ نتيجة لذلك ، كان يجب التخلي عن النسخة الأولى من النموذج الأولي للنظام الجديد. تعتمد النسخة الثانية ، التي تعمل حاليًا في الإنتاج ، على نفس الكود الذي يعمل في جزء التداول وفي المخاطرة. أثناء التطوير ، كان أصعب شيء هو دمج git بين الإصدارين. يقوم زميلنا Evgeny Mazurenok بإجراء هذه العملية كل أسبوع ولعن لفترة طويلة جدًا في كل مرة.
عند اختيار نظام جديد ، كان علينا على الفور حل مشكلة التفاعل. عند اختيار ناقل البيانات ، كان من الضروري ضمان غضب مستقر والحد الأدنى من التأخير. لهذا ، فإن شبكة InfiniBand RDMA هي الأنسب: متوسط وقت المعالجة أقل 4 مرات من شبكات Ethernet ذات 10 جيجا. لكن الفرق الحقيقي كان في النسب المئوية - 99 و 99.9.
بالطبع ، لدى InfiniBand صعوباتها الخاصة. أولاً ، API آخر هو ibverbs بدلاً من المقابس. ثانياً ، لا توجد حلول المراسلة مفتوحة المصدر على نطاق واسع تقريبًا. لقد حاولنا إنشاء النموذج الأولي الخاص بنا ، ولكن تبين أنه صعب للغاية ، لذلك اخترنا حلاً تجاريًا - Confinity Low Latency Messaging (المعروف سابقًا باسم IBM MQ LLM).
ثم نشأت مشكلة الفصل الصحيح لنظام المخاطر. إذا قمت فقط بإخراج محرك المخاطر ولم تقم بإنشاء عقدة وسيطة ، فيمكن خلط المعاملات من مصدرين.
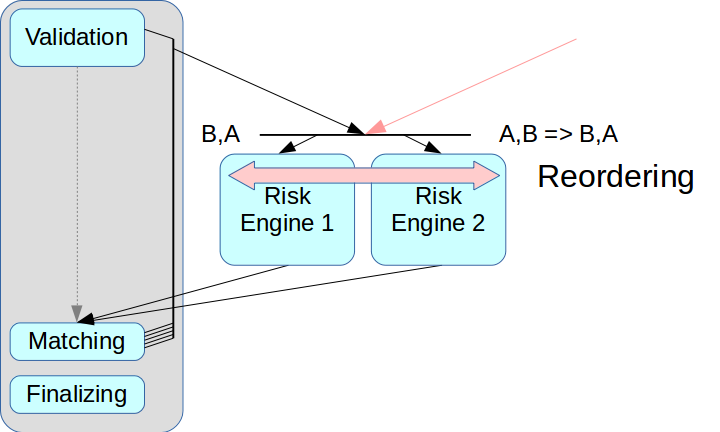
تشتمل حلول Ultra Low Latency المزعومة على وضع إعادة ترتيب: يمكن ترتيب المعاملات من مصدرين بالترتيب الصحيح عند الاستلام ، ويتحقق ذلك باستخدام قناة منفصلة لتبادل المعلومات حول التسلسل. لكننا لا نطبق هذا الوضع بعد: إنه يعقد العملية برمتها ، وفي بعض الحلول لا يتم دعمه على الإطلاق. بالإضافة إلى ذلك ، يجب تعيين كل معاملة الطوابع الزمنية المناسبة ، وفي مخططنا يصعب للغاية تنفيذ هذه الآلية بشكل صحيح. لذلك ، استخدمنا المخطط الكلاسيكي مع وسيط الرسائل ، أي مع موزع يقوم بتوزيع الرسائل بين Risk Engine.
كانت المشكلة الثانية متعلقة بوصول العميل: إذا كان هناك العديد من بوابات المخاطرة ، فيجب على العميل الاتصال بكل منها ، ولهذا يتعين عليك إجراء تغييرات على طبقة العميل. لقد أردنا الابتعاد عن هذا في هذه المرحلة ، لذلك في خطة بوابة المخاطر الحالية يعالجون دفق البيانات بأكمله. هذا يحد بشدة من الحد الأقصى للإنتاجية ، ولكن يبسط تكامل النظام إلى حد كبير.
تكرار
لا ينبغي أن يكون لنظامنا نقطة فشل واحدة ، أي أنه يجب تكرار جميع المكونات ، بما في ذلك وسيط الرسائل. لقد قمنا بحل هذه المشكلة باستخدام نظام CLLM: فهو يحتوي على مجموعة RCMS يمكن أن يعمل فيها مرسلان في وضع السيد والعبد ، وعندما يفشل أحدهما ، ينتقل النظام تلقائيًا إلى الآخر.
العمل مع مركز بيانات النسخ الاحتياطي
تم تحسين InfiniBand للعمل كشبكة محلية ، أي لتوصيل معدات تركيب الحامل ، وليس هناك طريقة لوضع شبكة InfiniBand بين مركزين للبيانات موزعين جغرافياً. لذلك ، قمنا بتطبيق جسر / مرسل يصل إلى مخزن الرسائل عبر شبكات إيثرنت العادية وينقل جميع المعاملات إلى شبكة IB الثانية. عندما تحتاج إلى ترحيل من مركز البيانات ، يمكننا اختيار مركز البيانات الذي سيعمل معه الآن.
النتائج
كل ما سبق لم يتم في وقت واحد ، فقد تطلب الأمر عدة تكرارات لتطوير بنية جديدة. لقد أنشأنا النموذج الأولي خلال شهر واحد ، لكن الأمر استغرق أكثر من عامين لإنهاء حالة العمل. لقد حاولنا تحقيق أفضل حل وسط بين زيادة مدة معالجة المعاملات وزيادة موثوقية النظام.
منذ أن تم تحديث النظام بشكل كبير ، قمنا بتنفيذ استعادة البيانات من مصدرين مستقلين. إذا لم يعمل مخزن الرسائل لسبب ما بشكل صحيح ، فيمكنك أخذ سجل المعاملات من مصدر ثانٍ - من Risk Engine. يتم احترام هذا المبدأ في جميع أنحاء النظام.
من بين أشياء أخرى ، تمكنا من الحفاظ على واجهة برمجة تطبيقات العميل بحيث لا يحتاج الوسطاء أو أي شخص آخر إلى تغيير كبير في الهيكل الجديد. اضطررت إلى تغيير بعض الواجهات ، لكنني لم أكن بحاجة إلى إجراء تغييرات كبيرة على نموذج العمل.
أطلقنا على الإصدار الحالي من برنامجنا Rebus - كاختصار لاثنين من أبرز الابتكارات في الهندسة المعمارية ، و Risk Engine و BUS.
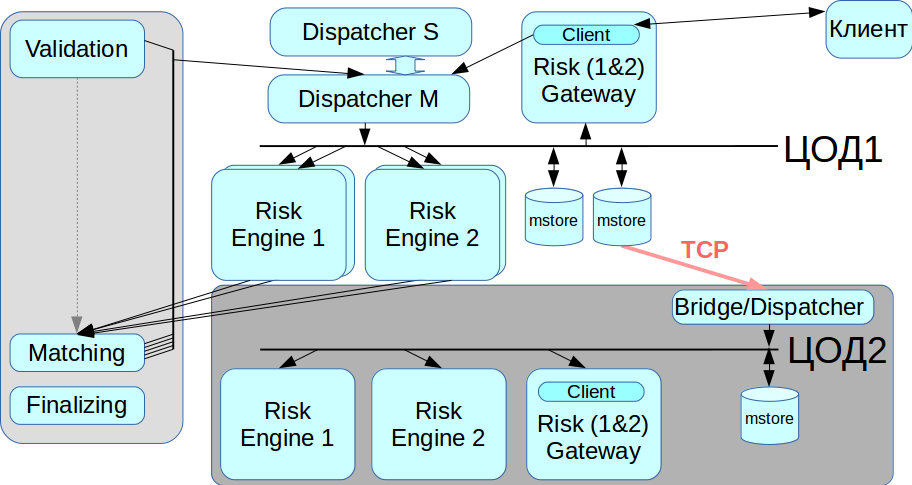
في البداية ، أردنا إبراز جزء المقاصة فقط ، لكن النتيجة كانت نظام توزيع ضخم. الآن يمكن للعملاء التفاعل مع بوابة التجارة ، أو مع المقاصة ، أو مع الاثنين معا.
ما حققناه في النهاية:

انخفاض مستوى التأخير. مع حجم صغير من المعاملات ، يعمل النظام بنفس الطريقة التي يعمل بها الإصدار السابق ، ولكن في نفس الوقت يتحمل عبء أعلى بكثير.
زادت ذروة الإنتاجية من 50 ألف إلى 180 ألف معاملة في الثانية. هناك دفق إضافي من المعلومات يعيق المزيد من النمو.
هناك طريقتان لمزيد من التحسين: مطابقة التوازي وتغيير مخطط العمل مع Gateway. تعمل جميع العبّارات الآن وفقًا لنظام النسخ المتماثل ، والذي يتوقف عند هذا التحميل عن العمل بشكل طبيعي.في النهاية ، يمكنني تقديم بعض النصائح لأولئك الذين يطورون أنظمة المؤسسة:- كن مستعدا للأسوأ في كل وقت. المشاكل تأتي دائما بشكل غير متوقع.
- من المستحيل عادة إعادة إنشاء العمارة بسرعة. خاصة إذا كنت بحاجة إلى تحقيق أقصى قدر من الموثوقية في مجموعة متنوعة من المؤشرات. لمزيد من العقد ، هناك حاجة إلى مزيد من الموارد للحصول على الدعم.
- جميع الحلول الخاصة والملكية تتطلب موارد إضافية للبحث والدعم والدعم.
- , .