في الولايات المتحدة وحدها ، هناك 3 ملايين شخص ذو إعاقة لا يمكنهم مغادرة منازلهم. الروبوتات المساعدة التي يمكنها التنقل لمسافات طويلة تلقائيًا يمكن أن تجعل هؤلاء الأشخاص أكثر استقلالية من خلال توفير الغذاء والدواء والحزم لهم. تشير الدراسات إلى أن التعلم العميق مع التعزيز (OP) مناسب تمامًا لمقارنة بيانات وإجراءات المدخلات الأولية ، على سبيل المثال ، لتعلم
التقاط الأشياء أو
نقل الروبوتات ، ولكن عادة ما يفتقر
وكلاء OP إلى فهم المساحات المادية الكبيرة اللازمة للتوجيه الآمن إلى المسافات الطويلة مسافات دون مساعدة بشرية والتكيف مع بيئة جديدة.
في ثلاثة أعمال حديثة ، "
التدريب على التوجيه من نقطة الصفر باستخدام AOP " ، "
PRM-RL: تنفيذ التوجيه الآلي على مسافات طويلة باستخدام مزيج من التدريب التعزيز والتخطيط القائم على الأنماط " و "
التوجيه طويل المدى مع PRM-RL " ، ندرس الروبوتات المستقلة التي تتكيف بسهولة مع بيئة جديدة ، وتجمع بين العمليات العميقة والتخطيط طويل الأجل. نحن نعلم وكلاء التخطيط المحليين كيفية تنفيذ الإجراءات الأساسية اللازمة للتوجيه وكيفية تحريك المسافات القصيرة دون تصادم مع الكائنات المتحركة. يقوم المخططون المحليون بإجراء عمليات مراقبة بيئية صاخبة باستخدام أجهزة استشعار مثل الأغطية أحادية البعد التي توفر المسافة إلى العائق وتوفر سرعات خطية وزاوية للتحكم في الروبوت. نقوم بتدريب المخطط المحلي على عمليات المحاكاة باستخدام تعلم التعزيز التلقائي (AOP) ، وهي الطريقة التي تعمل تلقائيًا على البحث عن مكافآت لـ OP وهيكل الشبكة العصبية. على الرغم من النطاق المحدود الذي يتراوح بين 10 و 15 متراً ، فإن المخططين المحليين يتأقلمون جيدًا مع كل من يستخدمون في روبوتات حقيقية وبيئات جديدة لم تكن معروفة من قبل. يتيح لك ذلك استخدامها لبنات بناء للتوجيه في المساحات الكبيرة. ثم نصمم خريطة طريق ، وهي عبارة عن رسم بياني حيث تكون العقد عبارة عن أقسام منفصلة ، وتربط الحواف العقد فقط إذا كان المخططون المحليون ، الذين يقلدون الروبوتات الحقيقية باستخدام أجهزة استشعار وعناصر تحكم صاخبة ، ينتقلون بينهم.
التعلم التعزيز التلقائي (AOP)
في
عملنا الأول ، نقوم بتدريب مخطط محلي في بيئة ثابتة صغيرة. ومع ذلك ، عند التعلم باستخدام خوارزمية OP العميقة القياسية ، على سبيل المثال ، التدرج الحتمية العميقة (
DDPG ) ، هناك العديد من العقبات. على سبيل المثال ، الهدف الحقيقي للمخططين المحليين هو تحقيق هدف معين ، ونتيجة لذلك يحصلون على مكافآت نادرة. في الممارسة العملية ، يتطلب ذلك من الباحثين قضاء وقت كبير في التنفيذ التدريجي للخوارزمية والتعديل اليدوي للجوائز. يتعين على الباحثين أيضًا اتخاذ قرارات بشأن بنية الشبكات العصبية دون أن يكون لديهم وصفات واضحة وناجحة. أخيرًا ، تتعلم الخوارزميات مثل DDPG بشكل غير مستقر وغالبًا ما تظهر
النسيان الكارثي .
للتغلب على هذه العقبات ، نحن الآلي التعلم العميق مع التعزيز. AOP عبارة عن غلاف تلقائي تطوري حول OP عميق ، يبحث عن مكافآت وهندسة الشبكات العصبية من خلال
تحسين مقياس تشعبي واسع النطاق . يعمل على مرحلتين ، البحث عن المكافآت والبحث عن الهندسة المعمارية. أثناء البحث عن المكافآت ، تقوم AOP في وقت واحد بتدريب سكان عملاء DDPG لعدة أجيال ، ولكل واحد وظيفة المكافأة المعدلة قليلاً ، والتي تم تحسينها للمهمة الحقيقية للمخطط المحلي: الوصول إلى نقطة النهاية في المسار. في نهاية مرحلة البحث عن المكافآت ، نختار مرحلة غالباً ما تقود الوكلاء إلى الهدف. في مرحلة البحث في بنية الشبكة العصبية ، نكرر هذه العملية ، باستخدام الجائزة المحددة لهذا السباق وضبط طبقات الشبكة ، وتحسين الجائزة التراكمية.
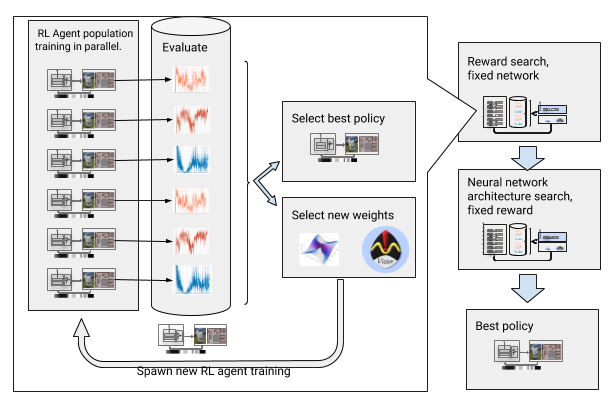 AOP مع البحث عن جائزة والهندسة المعمارية للشبكة العصبية
AOP مع البحث عن جائزة والهندسة المعمارية للشبكة العصبيةومع ذلك ، فإن هذه العملية خطوة بخطوة تجعل AOP غير فعالة من حيث عدد العينات. التدريب AOP مع 10 أجيال من 100 وكيل يتطلب 5 مليارات عينة ، أي ما يعادل 32 سنة من الدراسة! الميزة هي أنه بعد AOP ، تتم عملية التعلم اليدوي تلقائيًا ، وليس لدى DDPG نسيان كارثي. والأهم من ذلك ، أن جودة السياسات النهائية أعلى - فهي مقاومة للضوضاء الصادرة عن المستشعر ، ومحرك الأقراص ، والتعريب ، وهي معممة جيدًا على البيئات الجديدة. أفضل سياستنا هي 26 ٪ أكثر نجاحا من طرق التوجيه الأخرى في مواقع الاختبار لدينا.
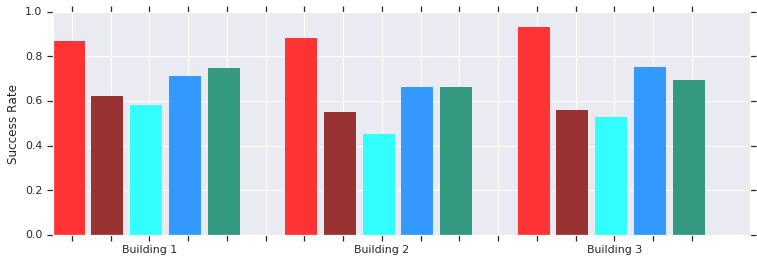 Red - نجاحات AOP على مسافات قصيرة (حتى 10 أمتار) في العديد من المباني غير المعروفة سابقًا. مقارنة مع DDPG المدربين يدويًا (الأحمر الداكن) ، الحقول المحتملة الاصطناعية (الأزرق) ، النافذة الديناميكية (الأزرق) واستنساخ السلوك (الأخضر).تعمل سياسة جدولة AOP المحلية بشكل جيد مع الروبوتات في بيئات غير منظمة حقيقية
Red - نجاحات AOP على مسافات قصيرة (حتى 10 أمتار) في العديد من المباني غير المعروفة سابقًا. مقارنة مع DDPG المدربين يدويًا (الأحمر الداكن) ، الحقول المحتملة الاصطناعية (الأزرق) ، النافذة الديناميكية (الأزرق) واستنساخ السلوك (الأخضر).تعمل سياسة جدولة AOP المحلية بشكل جيد مع الروبوتات في بيئات غير منظمة حقيقيةوعلى الرغم من أن هؤلاء السياسيين قادرون فقط على التوجه المحلي ، إلا أنهم يقاومون تحركات العقبات ويتحملون روبوتات حقيقية في بيئات غير منظمة. وعلى الرغم من تدريبهم على محاكاة الأشياء الثابتة ، إلا أنهم يتعاملون بشكل فعال مع الأشياء المتحركة. والخطوة التالية هي الجمع بين سياسات AOP والتخطيط القائم على العينات لتوسيع مجال عملها وتعليمهم كيفية التنقل لمسافات طويلة.
التوجه لمسافات طويلة مع PRM-RL
يعمل المخططون القائمون على الأنماط بتوجيه طويل المدى ، ويقاربون حركات الروبوت. على سبيل المثال ، يقوم الروبوت بإنشاء
خرائط طريق احتمالية (PRM) عن طريق رسم مسارات الانتقال بين الأقسام. في عملنا
الثاني ، الذي فاز بالجائزة في مؤتمر
ICRA 2018 ، نجمع بين PRM وجداول OP المحلية المضبوطة يدويًا (بدون AOP) لتدريب الروبوتات محليًا ثم تكييفها مع بيئات أخرى.
أولاً ، بالنسبة لكل روبوت ، نقوم بتدريب سياسة الجدولة المحلية في محاكاة معممة. ثم نقوم بإنشاء PRM مع مراعاة هذه السياسة ، ما يسمى PRM-RL ، بناءً على خريطة البيئة التي سيتم استخدامها فيها. يمكن استخدام نفس البطاقة لأي روبوت نرغب في استخدامه في المبنى.
لإنشاء PRM-RL ، نجمع العقد من العينات فقط إذا كان بوسع مجدول OP المحلي التنقل بينها بشكل موثوق ومتكرر. يتم ذلك في محاكاة مونت كارلو. تتكيف الخريطة الناتجة مع إمكانيات وهندسة الروبوت المعين. سيكون لبطاقات الروبوتات التي لها نفس الشكل الهندسي ، ولكن باستخدام أجهزة استشعار ومحركات مختلفة ، اتصال مختلف. نظرًا لأن العامل يمكن أن يدور قاب قوسين أو أدنى ، يمكن أيضًا تشغيل العقد التي ليست في خط الرؤية المباشرة. ومع ذلك ، فإن العقد المجاورة للجدران والعقبات ستكون أقل عرضة لإدراجها في الخريطة بسبب ضوضاء المستشعر. في وقت التشغيل ، ينتقل وكيل OP عبر الخريطة من قسم إلى آخر.
 يتم إنشاء خريطة مع ثلاثة محاكاة مونت كارلو لكل زوج من العقد المحددة عشوائيا
يتم إنشاء خريطة مع ثلاثة محاكاة مونت كارلو لكل زوج من العقد المحددة عشوائيا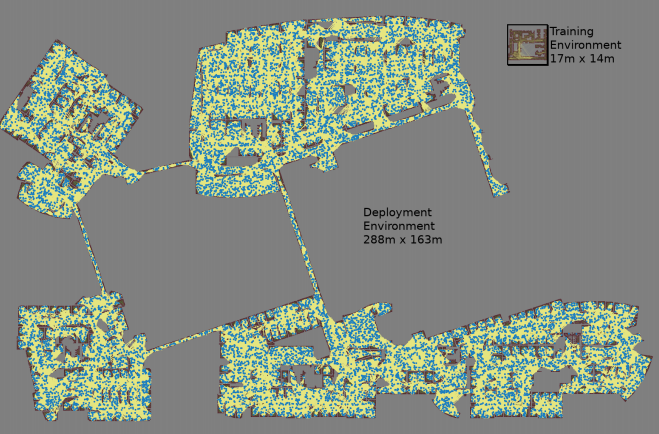 كانت أكبر خريطة مساحتها 288 × 163 مترًا وتضم حوالي 700000 حافة. قام 300 عامل بجمعها لمدة 4 أيام ، بعد إجراء 1.1 مليار فحص تصادم.
كانت أكبر خريطة مساحتها 288 × 163 مترًا وتضم حوالي 700000 حافة. قام 300 عامل بجمعها لمدة 4 أيام ، بعد إجراء 1.1 مليار فحص تصادم.يوفر
العمل الثالث العديد من التحسينات على PRM-RL الأصلي. أولاً ، نقوم باستبدال DDPG المضبوطة يدويًا بجداول AOP المحلية ، مما يعطي تحسينًا في الاتجاه عبر المسافات الطويلة. ثانياً ، يتم إضافة
خرائط التعريب والتمييز في وقت واحد (
SLAM ) ، والتي يستخدمها الروبوتات في وقت التشغيل كمصدر لبناء خرائط الطريق. تخضع بطاقات SLAM للضوضاء ، مما يؤدي إلى إغلاق "الفجوة بين المحاكاة والواقع" ، وهي مشكلة معروفة في مجال الروبوتات ، نظرًا لأن العملاء المدربين على عمليات المحاكاة يتصرفون بشكل أسوأ في العالم الواقعي. يتزامن مستوى نجاحنا في المحاكاة مع مستوى نجاح الروبوتات الحقيقية. وأخيرًا ، أضفنا خرائط بناء موزعة ، حتى نتمكن من إنشاء خرائط كبيرة جدًا تحتوي على 700000 عقدة.
قمنا بتقييم هذه الطريقة باستخدام وكيل AOP لدينا ، الذي وضع خرائط تستند إلى رسومات المباني التي تجاوزت بيئة التدريب بنسبة 200 مرة في المنطقة ، بما في ذلك الأضلاع فقط ، والتي تم إكمالها بنجاح في 90 ٪ من الحالات في 20 محاولة. قارنا PRM-RL بأساليب مختلفة على مسافات تصل إلى 100 متر ، والتي تجاوزت إلى حد كبير نطاق المخطط المحلي. حقق PRM-RL النجاح مرتين إلى أكثر من الطرق التقليدية بسبب الاتصال الصحيح بالعقد ، وهو مناسب لقدرات الروبوت.
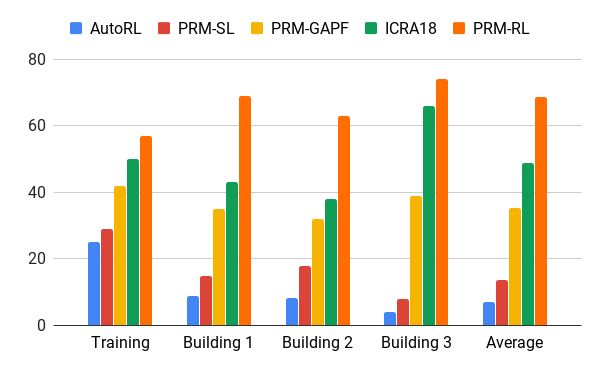 معدل النجاح في تحريك 100 متر في المباني المختلفة. الأزرق - جدولة AOP المحلية ، أول وظيفة ؛ أحمر - PRM الأصلي ؛ حقول الإمكانات الصناعية الصفراء ؛ الأخضر هو الوظيفة الثانية. الأحمر - الوظيفة الثالثة ، PRM مع AOP.
معدل النجاح في تحريك 100 متر في المباني المختلفة. الأزرق - جدولة AOP المحلية ، أول وظيفة ؛ أحمر - PRM الأصلي ؛ حقول الإمكانات الصناعية الصفراء ؛ الأخضر هو الوظيفة الثانية. الأحمر - الوظيفة الثالثة ، PRM مع AOP.اختبرنا PRM-RL على العديد من الروبوتات الحقيقية في العديد من المباني. يوجد أدناه أحد أجنحة الاختبار ؛ ينتقل الروبوت بشكل موثوق في كل مكان تقريبًا ، باستثناء الأماكن الأكثر فوضى والمناطق التي تتجاوز بطاقة SLAM.

استنتاج
يمكن أن يزيد اتجاه الماكينة بشكل كبير من استقلالية الأشخاص الذين يعانون من إعاقات في التنقل. يمكن تحقيق ذلك من خلال تطوير روبوتات مستقلة يمكنها أن تتكيف بسهولة مع البيئة ، والأساليب المتاحة للتنفيذ في البيئة الجديدة بناءً على المعلومات الحالية. يمكن القيام بذلك عن طريق أتمتة التدريب التوجيهي الأساسي للمسافات القصيرة باستخدام AOP ، ثم استخدام المهارات المكتسبة مع بطاقات SLAM لإنشاء خرائط طريق. تتكون خرائط الطرق من عقد متصلة بأضلاع ، والتي يمكن أن تتحرك عليها الروبوتات بشكل موثوق. نتيجة لذلك ، تم تطوير سياسة سلوك الروبوت التي ، بعد تدريب واحد ، يمكن استخدامها في بيئات مختلفة وإصدار خرائط طريق تم تكييفها خصيصًا لروبوت معين.