حزمة tidyr هي جزء من جوهر إحدى المكتبات الأكثر شعبية في اللغة R - tidyverse .
الغرض الرئيسي من الحزمة هو جلب البيانات إلى مظهر أنيق.
يوجد على Habré منشور مخصص لهذه الحزمة ، ولكنه يعود إلى عام 2015. وأريد أن أخبركم عن أهم التغييرات ذات الصلة التي أعلن عنها مؤلفها هادلي ويكهام قبل بضعة أيام.
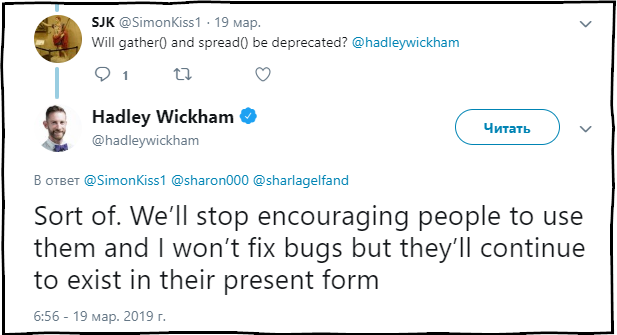
SJK : هل سيتم إهمال وظائف التجميع () والانتشار ()؟
هادلي ويكهام : إلى حد ما. سنتوقف عن التوصية باستخدام هذه الوظائف ، وتصحيح الأخطاء فيها ، لكنها ستظل موجودة في الحزمة في الحالة الحالية.
محتوى
مفهوم TidyData
الغرض من tidyr هو مساعدتك في جلب البيانات إلى مظهر أنيق يسمى. البيانات الدقيقة هي البيانات حيث:
- كل متغير في عمود.
- كل ملاحظة هي خط.
- كل قيمة هي خلية.
البيانات التي يتم تقديمها إلى البيانات مرتبة أسهل بكثير وأكثر ملاءمة للعمل أثناء التحليل.
المهام الرئيسية المدرجة في حزمة tidyr
يحتوي tidyr على مجموعة من الوظائف لتحويل الجداول:
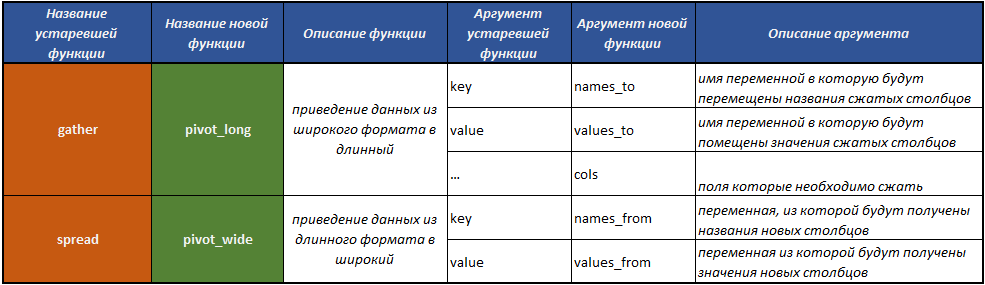
fill() - ملء القيم المفقودة في العمود مع القيم السابقة ؛separate() - تقسيم حقل واحد إلى عدة من خلال فاصل ؛unite() - ينفذ عملية الجمع بين عدة حقول في واحد ، معكوس الدالة separate() ؛pivot_longer() - دالة تقوم بتحويل البيانات من تنسيق واسع إلى تنسيق طويل ؛pivot_wider() - دالة تقوم بتحويل البيانات من تنسيق طويل إلى تنسيق واسع. العملية هي عكس تلك التي يتم تنفيذها بواسطة الدالة pivot_longer() .gather() مهملة - دالة تقوم بتحويل البيانات من تنسيق واسع إلى تنسيق طويل ؛spread() مهملة - دالة تقوم بتحويل البيانات من تنسيق طويل إلى تنسيق واسع. العملية هي عكس العملية التي تقوم بها الدالة collect gather() .
سابقًا ، تم استخدام الدالتين gather() و spread() لهذا النوع من التحول. على مدار سنوات من وجود هذه الوظائف ، أصبح من الواضح أنه بالنسبة لمعظم المستخدمين ، بما في ذلك مؤلف الحزمة ، فإن أسماء هذه الوظائف وحججهم لم تكن واضحة تمامًا وتسببت في صعوبات في العثور عليها وفهم أي من هذه الوظائف يجلب إطار التاريخ من واسع إلى طويل شكل والعكس بالعكس.
في هذا الصدد ، تم إضافة وظيفتين جديدتين مهمتين إلى tidyr ، والتي تم تصميمها لتحويل إطارات التاريخ.
تم pivot_longer() الدالتين pivot_longer() و pivot_wider() من بعض الوظائف في حزمة cdata التي أنشأها John Mount و Nina Zumel.
تثبيت أحدث إصدار من tidyr 0.8.3.9000
لتثبيت الإصدار الجديد الأحدث من حزمة tidyr 0.8.3.9000 ، التي تتوفر فيها وظائف جديدة ، استخدم الكود التالي.
devtools::install_github("tidyverse/tidyr")
في وقت كتابة هذا التقرير ، تتوفر هذه الوظائف فقط في إصدار dev من الحزمة على GitHub.
التبديل إلى ميزات جديدة
في الواقع ، ليس من الصعب نقل البرامج النصية القديمة للعمل مع وظائف جديدة ، لفهم أفضل ، سأأخذ مثالاً من وثائق الوظائف القديمة وأظهر كيف يتم تنفيذ هذه العمليات نفسها باستخدام الوظائف pivot_*() الجديدة pivot_*() .
تحويل واسعة إلى تنسيق طويل.
رمز عينة من وثائق جمع الوثائق # example library(dplyr) stocks <- data.frame( time = as.Date('2009-01-01') + 0:9, X = rnorm(10, 0, 1), Y = rnorm(10, 0, 2), Z = rnorm(10, 0, 4) ) # old stocks_gather <- stocks %>% gather(key = stock, value = price, -time) # new stocks_long <- stocks %>% pivot_longer(cols = -time, names_to = "stock", values_to = "price")
تحويل تنسيق طويل إلى واسع.
رمز عينة من وثائق وظيفة الانتشار # old stocks_spread <- stocks_gather %>% spread(key = stock, value = price) # new stock_wide <- stocks_long %>% pivot_wider(names_from = "stock", values_from = "price")
لأن في الأمثلة المذكورة أعلاه للعمل مع pivot_longer() و pivot_wider() ، في مخزون الجدول المصدر لا توجد أعمدة مدرجة في names_to والوسيطات value_to ، يجب الإشارة إلى أسمائهم في علامات اقتباس.
الجدول بمساعدة من الذي سوف تكتشف بسهولة أكثر كيفية التبديل إلى العمل مع مفهوم جديد tidyr .
ملاحظة من المؤلف
كل النص أدناه قابل للتكيف ، وأود أن أقول ترجمة مجانية للمصغر من الموقع الرسمي للمكتبة الحديثة.
pivot_longer () - يجعل مجموعات البيانات أطول من خلال تقليل عدد الأعمدة وزيادة عدد الصفوف.

لتشغيل الأمثلة المقدمة في المقالة ، يجب أولاً توصيل الحزم اللازمة:
library(tidyr) library(dplyr) library(readr)
لنفترض أن لدينا جدولًا يحتوي على نتائج الاستبيان الذي سُئل فيه (من بين أشياء أخرى) عن دينهم ودخلهم السنوي:
#> # A tibble: 18 x 11 #> religion `<$10k` `$10-20k` `$20-30k` `$30-40k` `$40-50k` `$50-75k` #> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> #> 1 Agnostic 27 34 60 81 76 137 #> 2 Atheist 12 27 37 52 35 70 #> 3 Buddhist 27 21 30 34 33 58 #> 4 Catholic 418 617 732 670 638 1116 #> 5 Don't k… 15 14 15 11 10 35 #> 6 Evangel… 575 869 1064 982 881 1486 #> 7 Hindu 1 9 7 9 11 34 #> 8 Histori… 228 244 236 238 197 223 #> 9 Jehovah… 20 27 24 24 21 30 #> 10 Jewish 19 19 25 25 30 95 #> # … with 8 more rows, and 4 more variables: `$75-100k` <dbl>, #> # `$100-150k` <dbl>, `>150k` <dbl>, `Don't know/refused` <dbl>
يحتوي هذا الجدول على بيانات دين المستفتى في الصفوف ، وتنتشر مستويات الدخل عبر أسماء الأعمدة. يتم تخزين عدد المستجيبين من كل فئة في قيم الخلايا عند تقاطع الدين ومستوى الدخل. لإحضار الجدول إلى تنسيق أنيق وصحيح ، ما pivot_longer() سوى استخدام pivot_longer() :
pew %>% pivot_longer(cols = -religion, names_to = "income", values_to = "count")
pew %>% pivot_longer(cols = -religion, names_to = "income", values_to = "count") #> # A tibble: 180 x 3 #> religion income count #> <chr> <chr> <dbl> #> 1 Agnostic <$10k 27 #> 2 Agnostic $10-20k 34 #> 3 Agnostic $20-30k 60 #> 4 Agnostic $30-40k 81 #> 5 Agnostic $40-50k 76 #> 6 Agnostic $50-75k 137 #> 7 Agnostic $75-100k 122 #> 8 Agnostic $100-150k 109 #> 9 Agnostic >150k 84 #> 10 Agnostic Don't know/refused 96 #> # … with 170 more rows
وسيطات إلى pivot_longer()
- الوسيطة الأولى ، cols ، تصف الأعمدة المراد دمجها. في هذه الحالة ، جميع الأعمدة باستثناء الوقت .
- تعطي الوسيطة names_to اسم المتغير الذي سيتم إنشاؤه من أسماء الأعمدة التي جمعناها .
- تعطى value_to اسم المتغير الذي سيتم إنشاؤه من البيانات المخزنة في قيم خلايا الأعمدة المرتبطة.
مواصفة
هذه هي الوظيفة الجديدة لحزمة tidyr ، والتي لم تكن متوفرة سابقًا عند العمل مع الوظائف القديمة.
المواصفات هي إطار بيانات ، يتوافق كل صف مع عمود واحد في إطار تاريخ إخراج جديد ، وعمودين خاصين يبدأان بما يلي:
- .name يحتوي على الاسم الأصلي للعمود.
- .value يحتوي على اسم العمود الذي ستذهب إليه قيم الخلية.
تعكس الأعمدة المتبقية من المواصفات كيف سيتم عرض اسم الأعمدة القابلة للضغط من .name في العمود الجديد.
توضح المواصفات البيانات الأولية المخزنة في اسم العمود ، مع وجود صف واحد لكل عمود وعمود واحد لكل متغير مقترن باسم العمود ، وربما يبدو هذا التعريف مربكًا الآن ، ولكن بعد النظر في بعض الأمثلة ، يصبح كل شيء أكثر وضوحًا.
معنى المواصفات هو أنه يمكنك استرجاع وتعديل وتعيين بيانات تعريف جديدة لإطار البيانات المحول.
يتم pivot_longer_spec() وظيفة pivot_longer_spec() للعمل مع المواصفات عند تحويل جدول من تنسيق واسع إلى تنسيق طويل.
كيف تعمل هذه الوظيفة ، فإنها تأخذ أي إطار تاريخ ، وتقوم بإنشاء بيانات التعريف الخاصة بها كما هو موضح أعلاه.
على سبيل المثال ، دعنا نأخذ مجموعة البيانات من الذي يأتي مع حزمة tidyr . تحتوي مجموعة البيانات هذه على معلومات مقدمة من المنظمة الصحية الدولية حول حالات الإصابة بالسل.
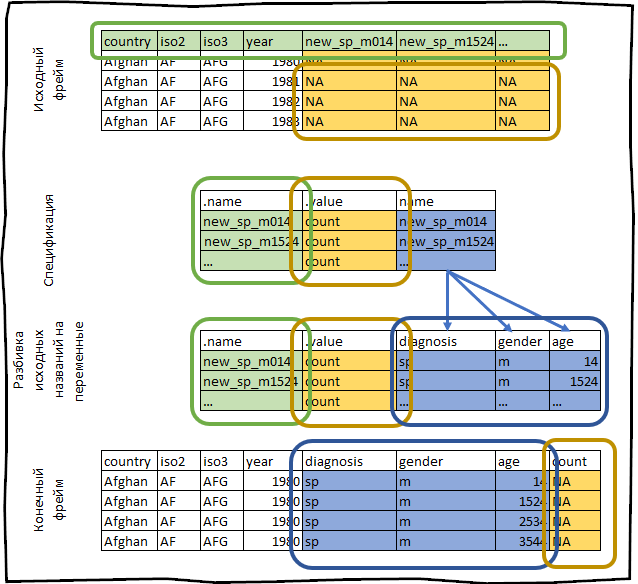
who #> # A tibble: 7,240 x 60 #> country iso2 iso3 year new_sp_m014 new_sp_m1524 new_sp_m2534 #> <chr> <chr> <chr> <int> <int> <int> <int> #> 1 Afghan… AF AFG 1980 NA NA NA #> 2 Afghan… AF AFG 1981 NA NA NA #> 3 Afghan… AF AFG 1982 NA NA NA #> 4 Afghan… AF AFG 1983 NA NA NA #> 5 Afghan… AF AFG 1984 NA NA NA #> 6 Afghan… AF AFG 1985 NA NA NA #> 7 Afghan… AF AFG 1986 NA NA NA #> 8 Afghan… AF AFG 1987 NA NA NA #> 9 Afghan… AF AFG 1988 NA NA NA #> 10 Afghan… AF AFG 1989 NA NA NA #> # … with 7,230 more rows, and 53 more variables
نحن نبني مواصفاتها.
spec <- who %>% pivot_longer_spec(new_sp_m014:newrel_f65, values_to = "count")
#> # A tibble: 56 x 3 #> .name .value name #> <chr> <chr> <chr> #> 1 new_sp_m014 count new_sp_m014 #> 2 new_sp_m1524 count new_sp_m1524 #> 3 new_sp_m2534 count new_sp_m2534 #> 4 new_sp_m3544 count new_sp_m3544 #> 5 new_sp_m4554 count new_sp_m4554 #> 6 new_sp_m5564 count new_sp_m5564 #> 7 new_sp_m65 count new_sp_m65 #> 8 new_sp_f014 count new_sp_f014 #> 9 new_sp_f1524 count new_sp_f1524 #> 10 new_sp_f2534 count new_sp_f2534 #> # … with 46 more rows
الحقول البلد ، iso2 ، iso3 هي بالفعل متغيرات. مهمتنا هي قلب الأعمدة من new_sp_m014 إلى newrel_f65 .
تخزن أسماء هذه الأعمدة المعلومات التالية:
- تشير البادئة
new_ إلى أن العمود يحتوي على بيانات عن الحالات الجديدة لمرض السل ، وأن إطار التاريخ الحالي يحتوي على معلومات فقط عن الأمراض الجديدة ، وبالتالي فإن هذه البادئة في السياق الحالي لا تحمل أي معنى. - يصف
sp / rel / sp / ep طريقة لتشخيص المرض. m / f جنس المريض.014 الفئة العمرية للمريض.
يمكننا فصل هذه الأعمدة باستخدام دالة extract() باستخدام تعبير عادي.
spec <- spec %>% extract(name, c("diagnosis", "gender", "age"), "new_?(.*)_(.)(.*)")
#> # A tibble: 56 x 5 #> .name .value diagnosis gender age #> <chr> <chr> <chr> <chr> <chr> #> 1 new_sp_m014 count sp m 014 #> 2 new_sp_m1524 count sp m 1524 #> 3 new_sp_m2534 count sp m 2534 #> 4 new_sp_m3544 count sp m 3544 #> 5 new_sp_m4554 count sp m 4554 #> 6 new_sp_m5564 count sp m 5564 #> 7 new_sp_m65 count sp m 65 #> 8 new_sp_f014 count sp f 014 #> 9 new_sp_f1524 count sp f 1524 #> 10 new_sp_f2534 count sp f 2534 #> # … with 46 more rows
لاحظ أنه يجب أن يظل عمود .name بدون تغيير ، لأن هذا هو فهرسنا في أسماء أعمدة مجموعة البيانات المصدر.
للجنس والعمر (أعمدة الجنس والعمر ) قيم ثابتة ومعروفة ، لذلك يوصى بتحويل هذه الأعمدة إلى عوامل:
spec <- spec %>% mutate( gender = factor(gender, levels = c("f", "m")), age = factor(age, levels = unique(age), ordered = TRUE) )
أخيرًا ، من أجل تطبيق المواصفات التي أنشأناها على التاريخ الأصلي لإطار who ، نحتاج إلى استخدام وسيطة spec في pivot_longer() .
who %>% pivot_longer(spec = spec)
#> # A tibble: 405,440 x 8 #> country iso2 iso3 year diagnosis gender age count #> <chr> <chr> <chr> <int> <chr> <fct> <ord> <int> #> 1 Afghanistan AF AFG 1980 sp m 014 NA #> 2 Afghanistan AF AFG 1980 sp m 1524 NA #> 3 Afghanistan AF AFG 1980 sp m 2534 NA #> 4 Afghanistan AF AFG 1980 sp m 3544 NA #> 5 Afghanistan AF AFG 1980 sp m 4554 NA #> 6 Afghanistan AF AFG 1980 sp m 5564 NA #> 7 Afghanistan AF AFG 1980 sp m 65 NA #> 8 Afghanistan AF AFG 1980 sp f 014 NA #> 9 Afghanistan AF AFG 1980 sp f 1524 NA #> 10 Afghanistan AF AFG 1980 sp f 2534 NA #> # … with 405,430 more rows
كل ما فعلناه للتو يمكن تصويره بشكل تخطيطي على النحو التالي:
المواصفات باستخدام قيم متعددة (القيمة.)
في المثال أعلاه ، تضمن عمود مواصفات القيمة. قيمة واحدة فقط ، ويحدث هذا في معظم الحالات.
ولكن في بعض الأحيان قد تنشأ حالة عندما تحتاج إلى جمع البيانات من الأعمدة مع أنواع البيانات المختلفة في القيم. باستخدام دالة spread() المهملة ، سيكون ذلك صعبًا للغاية.
يتم استعارة المثال التالي من المقالة القصيرة لحزمة data.table .
دعونا إنشاء إطار بيانات التدريب.
family <- tibble::tribble( ~family, ~dob_child1, ~dob_child2, ~gender_child1, ~gender_child2, 1L, "1998-11-26", "2000-01-29", 1L, 2L, 2L, "1996-06-22", NA, 2L, NA, 3L, "2002-07-11", "2004-04-05", 2L, 2L, 4L, "2004-10-10", "2009-08-27", 1L, 1L, 5L, "2000-12-05", "2005-02-28", 2L, 1L, ) family <- family %>% mutate_at(vars(starts_with("dob")), parse_date)
#> # A tibble: 5 x 5 #> family dob_child1 dob_child2 gender_child1 gender_child2 #> <int> <date> <date> <int> <int> #> 1 1 1998-11-26 2000-01-29 1 2 #> 2 2 1996-06-22 NA 2 NA #> 3 3 2002-07-11 2004-04-05 2 2 #> 4 4 2004-10-10 2009-08-27 1 1 #> 5 5 2000-12-05 2005-02-28 2 1
يحتوي إطار التاريخ الذي تم إنشاؤه في كل صف على بيانات عن أطفال أسرة واحدة. يمكن للعائلات أن تنجب طفلاً أو طفلين. بالنسبة لكل طفل ، يتم توفير بيانات عن تاريخ الميلاد والجنس ، والبيانات الخاصة بكل طفل في أعمدة منفصلة ، ومهمتنا هي جلب هذه البيانات إلى التنسيق الصحيح للتحليل.
يرجى ملاحظة أن لدينا اثنين من المتغيرات مع معلومات حول كل طفل: جنسه وتاريخ الميلاد (الأعمدة مع البادئة dop تحتوي على تاريخ الميلاد ، والأعمدة مع البادئة بين الجنسين تحتوي على جنس الطفل). في النتيجة المتوقعة ، يجب أن يذهبوا في أعمدة منفصلة. يمكننا القيام بذلك عن طريق إنشاء مواصفات يكون لعمود .value قيمتان مختلفتان.
spec <- family %>% pivot_longer_spec(-family) %>% separate(col = name, into = c(".value", "child"))%>% mutate(child = parse_number(child))
#> # A tibble: 4 x 3 #> .name .value child #> <chr> <chr> <dbl> #> 1 dob_child1 dob 1 #> 2 dob_child2 dob 2 #> 3 gender_child1 gender 1 #> 4 gender_child2 gender 2
لذلك ، دعنا نخطو في الخطوات التي يتم تنفيذها بواسطة الكود أعلاه.
pivot_longer_spec(-family) - قم بإنشاء مواصفات تضغط على كل الأعمدة المتاحة باستثناء عمود العائلة.separate(col = name, into = c(".value", "child")) - افصل عمود .name ، الذي يحتوي على أسماء الحقول المصدر ، وتم وضع علامات تحت القيم ووضعها في الأعمدة الفرعية .val و التابعة.mutate(child = parse_number(child)) - تحويل قيم الحقل mutate(child = parse_number(child)) من نص إلى نوع بيانات رقمي.
الآن يمكننا تطبيق المواصفات المستلمة على إطار البيانات الأولي ، وإحضار الجدول إلى النموذج المطلوب.
family %>% pivot_longer(spec = spec, na.rm = T)
#> # A tibble: 9 x 4 #> family child dob gender #> <int> <dbl> <date> <int> #> 1 1 1 1998-11-26 1 #> 2 1 2 2000-01-29 2 #> 3 2 1 1996-06-22 2 #> 4 3 1 2002-07-11 2 #> 5 3 2 2004-04-05 2 #> 6 4 1 2004-10-10 1 #> 7 4 2 2009-08-27 1 #> 8 5 1 2000-12-05 2 #> 9 5 2 2005-02-28 1
نحن نستخدم الوسيطة na.rm = TRUE ، لأن نموذج البيانات الحالي يفرض علينا إنشاء صفوف إضافية للرصدات غير الموجودة. لأن عائلة 2 لديها طفل واحد فقط ، na.rm = TRUE تضمن أن العائلة 2 سيكون لها سطر واحد في الإخراج.
pivot_wider() - هو التحول العكسي ، والعكس بالعكس يزيد عدد الأعمدة في تاريخ الإطار عن طريق تقليل عدد الصفوف.
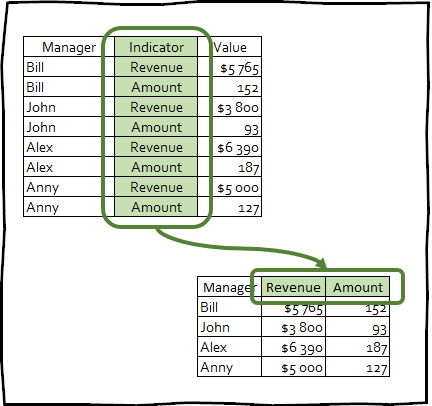
نادرًا ما يستخدم هذا النوع من التحويل لإحضار البيانات إلى مظهر أنيق ، ومع ذلك ، يمكن أن تكون هذه التقنية مفيدة لإنشاء الجداول المحورية المستخدمة في العروض التقديمية ، أو للتكامل مع أي أدوات أخرى.
في الحقيقة ، فإن الدالتين pivot_longer() و pivot_wider() ، وهما يؤديان إجراءات معاكسة ، أي: df %>% pivot_longer(spec = spec) %>% pivot_wider(spec = spec) و df %>% pivot_wider(spec = spec) %>% pivot_longer(spec = spec) إلى df الأصلي.
لإثبات تشغيل وظيفة pivot_wider() ، سنستخدم مجموعة بيانات fish_encounters ، التي تخزن معلومات حول كيفية تسجيل المحطات المختلفة لحركة الأسماك على طول النهر.
#> # A tibble: 114 x 3 #> fish station seen #> <fct> <fct> <int> #> 1 4842 Release 1 #> 2 4842 I80_1 1 #> 3 4842 Lisbon 1 #> 4 4842 Rstr 1 #> 5 4842 Base_TD 1 #> 6 4842 BCE 1 #> 7 4842 BCW 1 #> 8 4842 BCE2 1 #> 9 4842 BCW2 1 #> 10 4842 MAE 1 #> # … with 104 more rows
في معظم الحالات ، سيكون هذا الجدول أكثر إفادة وملاءمة للاستخدام إذا قدمت معلومات لكل محطة في عمود منفصل.
fish_encounters %>% pivot_wider(names_from = station, values_from = seen)
fish_encounters %>% pivot_wider(names_from = station, values_from = seen) #> # A tibble: 19 x 12 #> fish Release I80_1 Lisbon Rstr Base_TD BCE BCW BCE2 BCW2 MAE #> <fct> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int> #> 1 4842 1 1 1 1 1 1 1 1 1 1 #> 2 4843 1 1 1 1 1 1 1 1 1 1 #> 3 4844 1 1 1 1 1 1 1 1 1 1 #> 4 4845 1 1 1 1 1 NA NA NA NA NA #> 5 4847 1 1 1 NA NA NA NA NA NA NA #> 6 4848 1 1 1 1 NA NA NA NA NA NA #> 7 4849 1 1 NA NA NA NA NA NA NA NA #> 8 4850 1 1 NA 1 1 1 1 NA NA NA #> 9 4851 1 1 NA NA NA NA NA NA NA NA #> 10 4854 1 1 NA NA NA NA NA NA NA NA #> # … with 9 more rows, and 1 more variable: MAW <int>
تسجل مجموعة البيانات هذه المعلومات فقط عندما يتم الكشف عن الأسماك بواسطة المحطة ، أي إذا لم يتم إصلاح أي سمكة بواسطة محطة ما ، فلن تكون هذه البيانات في الجدول. هذا يعني أنه سيتم ملؤها الإخراج بواسطة NA.
ومع ذلك ، في هذه الحالة ، نعلم أن عدم وجود سجل يعني أنه لم يتم ملاحظة السمك ، لذلك يمكننا استخدام وسيطة value_fill في pivot_wider() وملء هذه القيم المفقودة pivot_wider() :
fish_encounters %>% pivot_wider( names_from = station, values_from = seen, values_fill = list(seen = 0) )
#> # A tibble: 19 x 12 #> fish Release I80_1 Lisbon Rstr Base_TD BCE BCW BCE2 BCW2 MAE #> <fct> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int> #> 1 4842 1 1 1 1 1 1 1 1 1 1 #> 2 4843 1 1 1 1 1 1 1 1 1 1 #> 3 4844 1 1 1 1 1 1 1 1 1 1 #> 4 4845 1 1 1 1 1 0 0 0 0 0 #> 5 4847 1 1 1 0 0 0 0 0 0 0 #> 6 4848 1 1 1 1 0 0 0 0 0 0 #> 7 4849 1 1 0 0 0 0 0 0 0 0 #> 8 4850 1 1 0 1 1 1 1 0 0 0 #> 9 4851 1 1 0 0 0 0 0 0 0 0 #> 10 4854 1 1 0 0 0 0 0 0 0 0 #> # … with 9 more rows, and 1 more variable: MAW <int>
توليد اسم عمود من متغيرات مصدر متعددة
تخيل أن لدينا جدول يحتوي على مزيج من المنتج والبلد والسنة. لإنشاء تاريخ إطار اختبار ، يمكنك تشغيل التعليمات البرمجية التالية:
df <- expand_grid( product = c("A", "B"), country = c("AI", "EI"), year = 2000:2014 ) %>% filter((product == "A" & country == "AI") | product == "B") %>% mutate(value = rnorm(nrow(.)))
#> # A tibble: 45 x 4 #> product country year value #> <chr> <chr> <int> <dbl> #> 1 A AI 2000 -2.05 #> 2 A AI 2001 -0.676 #> 3 A AI 2002 1.60 #> 4 A AI 2003 -0.353 #> 5 A AI 2004 -0.00530 #> 6 A AI 2005 0.442 #> 7 A AI 2006 -0.610 #> 8 A AI 2007 -2.77 #> 9 A AI 2008 0.899 #> 10 A AI 2009 -0.106 #> # … with 35 more rows
مهمتنا هي توسيع إطار التاريخ بحيث يحتوي عمود واحد على بيانات لكل مجموعة من المنتجات والدولة. للقيام بذلك ، ما عليك سوى تمرير المتجه الذي يحتوي على أسماء الحقول المراد ضمها إلى وسيطة names_from .
df %>% pivot_wider(names_from = c(product, country), values_from = "value")
#> # A tibble: 15 x 4 #> year A_AI B_AI B_EI #> <int> <dbl> <dbl> <dbl> #> 1 2000 -2.05 0.607 1.20 #> 2 2001 -0.676 1.65 -0.114 #> 3 2002 1.60 -0.0245 0.501 #> 4 2003 -0.353 1.30 -0.459 #> 5 2004 -0.00530 0.921 -0.0589 #> 6 2005 0.442 -1.55 0.594 #> 7 2006 -0.610 0.380 -1.28 #> 8 2007 -2.77 0.830 0.637 #> 9 2008 0.899 0.0175 -1.30 #> 10 2009 -0.106 -0.195 1.03 #> # … with 5 more rows
يمكنك أيضًا تطبيق المواصفات على وظيفة pivot_wider() . ولكن عندما يتم توفيرها إلى pivot_wider() المواصفات تقوم بعكس pivot_longer() : يتم إنشاء الأعمدة المحددة في .name باستخدام قيم من .value والأعمدة الأخرى.
بالنسبة إلى مجموعة البيانات هذه ، يمكنك إنشاء مواصفات مستخدم إذا كنت تريد أن يكون لكل مجموعة ممكنة من البلد والمنتج عمود خاص بها ، وليس فقط تلك الموجودة في البيانات:
spec <- df %>% expand(product, country, .value = "value") %>% unite(".name", product, country, remove = FALSE)
#> # A tibble: 4 x 4 #> .name product country .value #> <chr> <chr> <chr> <chr> #> 1 A_AI A AI value #> 2 A_EI A EI value #> 3 B_AI B AI value #> 4 B_EI B EI value
df %>% pivot_wider(spec = spec) %>% head()
#> # A tibble: 6 x 5 #> year A_AI A_EI B_AI B_EI #> <int> <dbl> <dbl> <dbl> <dbl> #> 1 2000 -2.05 NA 0.607 1.20 #> 2 2001 -0.676 NA 1.65 -0.114 #> 3 2002 1.60 NA -0.0245 0.501 #> 4 2003 -0.353 NA 1.30 -0.459 #> 5 2004 -0.00530 NA 0.921 -0.0589 #> 6 2005 0.442 NA -1.55 0.594
بعض الأمثلة المتقدمة على العمل مع مفهوم جديد للعبة
جلب البيانات إلى مظهر أنيق باستخدام مجموعة بيانات إيرادات الولايات المتحدة وتعداد الإيجار كمثال
تحتوي مجموعة بيانات us_rent_income على معلومات حول متوسط الدخل والإيجار لكل ولاية في الولايات المتحدة الأمريكية لعام 2017 (تتوفر مجموعة البيانات في حزمة tidycensus ).
us_rent_income #> # A tibble: 104 x 5 #> GEOID NAME variable estimate moe #> <chr> <chr> <chr> <dbl> <dbl> #> 1 01 Alabama income 24476 136 #> 2 01 Alabama rent 747 3 #> 3 02 Alaska income 32940 508 #> 4 02 Alaska rent 1200 13 #> 5 04 Arizona income 27517 148 #> 6 04 Arizona rent 972 4 #> 7 05 Arkansas income 23789 165 #> 8 05 Arkansas rent 709 5 #> 9 06 California income 29454 109 #> 10 06 California rent 1358 3 #> # … with 94 more rows
في النموذج الذي يتم به تخزين البيانات في مجموعة بيانات us_rent_income ، فإن العمل معهم غير مريح للغاية ، لذلك نود إنشاء مجموعة بيانات تحتوي على أعمدة: الإيجار ، الإيجار ، المجيء ، إيراد_ الدخل . هناك العديد من الطرق لإنشاء هذه المواصفات ، ولكن الشيء الرئيسي هو أننا نحتاج إلى إنشاء كل مجموعة من القيم المتغيرة وتقدير / وزارة الخارجية ، ثم إنشاء اسم العمود.
spec <- us_rent_income %>% expand(variable, .value = c("estimate", "moe")) %>% mutate( .name = paste0(variable, ifelse(.value == "moe", "_moe", "")) )
#> # A tibble: 4 x 3 #> variable .value .name #> <chr> <chr> <chr> #> 1 income estimate income #> 2 income moe income_moe #> 3 rent estimate rent #> 4 rent moe rent_moe
توفير هذه المواصفات إلى pivot_wider() يعطينا النتيجة التي نبحث عنها:
us_rent_income %>% pivot_wider(spec = spec)
#> # A tibble: 52 x 6 #> GEOID NAME income income_moe rent rent_moe #> <chr> <chr> <dbl> <dbl> <dbl> <dbl> #> 1 01 Alabama 24476 136 747 3 #> 2 02 Alaska 32940 508 1200 13 #> 3 04 Arizona 27517 148 972 4 #> 4 05 Arkansas 23789 165 709 5 #> 5 06 California 29454 109 1358 3 #> 6 08 Colorado 32401 109 1125 5 #> 7 09 Connecticut 35326 195 1123 5 #> 8 10 Delaware 31560 247 1076 10 #> 9 11 District of Columbia 43198 681 1424 17 #> 10 12 Florida 25952 70 1077 3 #> # … with 42 more rows
البنك الدولي
في بعض الأحيان ، يتطلب إحضار مجموعة البيانات إلى النموذج الصحيح عدة خطوات.
تحتوي مجموعة بيانات world_bank_pop على بيانات من البنك الدولي حول عدد سكان كل بلد من 2000 إلى 2018.
#> # A tibble: 1,056 x 20 #> country indicator `2000` `2001` `2002` `2003` `2004` `2005` `2006` #> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> #> 1 ABW SP.URB.T… 4.24e4 4.30e4 4.37e4 4.42e4 4.47e+4 4.49e+4 4.49e+4 #> 2 ABW SP.URB.G… 1.18e0 1.41e0 1.43e0 1.31e0 9.51e-1 4.91e-1 -1.78e-2 #> 3 ABW SP.POP.T… 9.09e4 9.29e4 9.50e4 9.70e4 9.87e+4 1.00e+5 1.01e+5 #> 4 ABW SP.POP.G… 2.06e0 2.23e0 2.23e0 2.11e0 1.76e+0 1.30e+0 7.98e-1 #> 5 AFG SP.URB.T… 4.44e6 4.65e6 4.89e6 5.16e6 5.43e+6 5.69e+6 5.93e+6 #> 6 AFG SP.URB.G… 3.91e0 4.66e0 5.13e0 5.23e0 5.12e+0 4.77e+0 4.12e+0 #> 7 AFG SP.POP.T… 2.01e7 2.10e7 2.20e7 2.31e7 2.41e+7 2.51e+7 2.59e+7 #> 8 AFG SP.POP.G… 3.49e0 4.25e0 4.72e0 4.82e0 4.47e+0 3.87e+0 3.23e+0 #> 9 AGO SP.URB.T… 8.23e6 8.71e6 9.22e6 9.77e6 1.03e+7 1.09e+7 1.15e+7 #> 10 AGO SP.URB.G… 5.44e0 5.59e0 5.70e0 5.76e0 5.75e+0 5.69e+0 4.92e+0 #> # … with 1,046 more rows, and 11 more variables: `2007` <dbl>, #> # `2008` <dbl>, `2009` <dbl>, `2010` <dbl>, `2011` <dbl>, `2012` <dbl>, #> # `2013` <dbl>, `2014` <dbl>, `2015` <dbl>, `2016` <dbl>, `2017` <dbl>
هدفنا هو إنشاء مجموعة بيانات أنيقة حيث يكون كل متغير في عمود منفصل. لم يتضح بعد الخطوات الضرورية ، لكننا سنبدأ مع المشكلة الأكثر وضوحًا: يتم توزيع السنة على عدة أعمدة.
لإصلاح هذا الأمر ، يجب عليك استخدام الدالة pivot_longer() .
pop2 <- world_bank_pop %>% pivot_longer(`2000`:`2017`, names_to = "year")
#> # A tibble: 19,008 x 4 #> country indicator year value #> <chr> <chr> <chr> <dbl> #> 1 ABW SP.URB.TOTL 2000 42444 #> 2 ABW SP.URB.TOTL 2001 43048 #> 3 ABW SP.URB.TOTL 2002 43670 #> 4 ABW SP.URB.TOTL 2003 44246 #> 5 ABW SP.URB.TOTL 2004 44669 #> 6 ABW SP.URB.TOTL 2005 44889 #> 7 ABW SP.URB.TOTL 2006 44881 #> 8 ABW SP.URB.TOTL 2007 44686 #> 9 ABW SP.URB.TOTL 2008 44375 #> 10 ABW SP.URB.TOTL 2009 44052 #> # … with 18,998 more rows
— indicator.
pop2 %>% count(indicator)
#> # A tibble: 4 x 2 #> indicator n #> <chr> <int> #> 1 SP.POP.GROW 4752 #> 2 SP.POP.TOTL 4752 #> 3 SP.URB.GROW 4752 #> 4 SP.URB.TOTL 4752
SP.POP.GROW — , SP.POP.TOTL — , SP.URB. * , . : area — (total urban) (population growth):
pop3 <- pop2 %>% separate(indicator, c(NA, "area", "variable"))
#> # A tibble: 19,008 x 5 #> country area variable year value #> <chr> <chr> <chr> <chr> <dbl> #> 1 ABW URB TOTL 2000 42444 #> 2 ABW URB TOTL 2001 43048 #> 3 ABW URB TOTL 2002 43670 #> 4 ABW URB TOTL 2003 44246 #> 5 ABW URB TOTL 2004 44669 #> 6 ABW URB TOTL 2005 44889 #> 7 ABW URB TOTL 2006 44881 #> 8 ABW URB TOTL 2007 44686 #> 9 ABW URB TOTL 2008 44375 #> 10 ABW URB TOTL 2009 44052 #> # … with 18,998 more rows
variable :
pop3 %>% pivot_wider(names_from = variable, values_from = value)
#> # A tibble: 9,504 x 5 #> country area year TOTL GROW #> <chr> <chr> <chr> <dbl> <dbl> #> 1 ABW URB 2000 42444 1.18 #> 2 ABW URB 2001 43048 1.41 #> 3 ABW URB 2002 43670 1.43 #> 4 ABW URB 2003 44246 1.31 #> 5 ABW URB 2004 44669 0.951 #> 6 ABW URB 2005 44889 0.491 #> 7 ABW URB 2006 44881 -0.0178 #> 8 ABW URB 2007 44686 -0.435 #> 9 ABW URB 2008 44375 -0.698 #> 10 ABW URB 2009 44052 -0.731 #> # … with 9,494 more rows
, , , -:
contacts <- tribble( ~field, ~value, "name", "Jiena McLellan", "company", "Toyota", "name", "John Smith", "company", "google", "email", "john@google.com", "name", "Huxley Ratcliffe" )
, , , . , , ("name"), , , field “name”:
contacts <- contacts %>% mutate( person_id = cumsum(field == "name") ) contacts
#> # A tibble: 6 x 3 #> field value person_id #> <chr> <chr> <int> #> 1 name Jiena McLellan 1 #> 2 company Toyota 1 #> 3 name John Smith 2 #> 4 company google 2 #> 5 email john@google.com 2 #> 6 name Huxley Ratcliffe 3
, , :
contacts %>% pivot_wider(names_from = field, values_from = value)
#> # A tibble: 3 x 4 #> person_id name company email #> <int> <chr> <chr> <chr> #> 1 1 Jiena McLellan Toyota <NA> #> 2 2 John Smith google john@google.com #> 3 3 Huxley Ratcliffe <NA> <NA>
استنتاج
, tidyr , spread() gather() . pivot_longer() pivot_wider() .