
كود برنامج تعلم الآلة غالبًا ما يكون معقدًا ومربكًا إلى حد ما. إن الكشف عن الأخطاء والقضاء عليها يعد مهمة كثيفة الاستخدام للموارد. حتى أبسط
الشبكات العصبية المتصلة مباشرة تتطلب نهجا جادا لهندسة الشبكات ، وتهيئة الأوزان ، وتحسين الشبكة. خطأ صغير يمكن أن يؤدي إلى مشاكل غير سارة.
تتناول هذه المقالة خوارزمية تصحيح الشبكات العصبية لديك.
توصي Skillbox بما يلي: مطور Python بالطبع العملي من البداية .
نذكرك: لجميع قراء "Habr" - خصم بقيمة 10،000 روبل عند التسجيل في أي دورة تدريبية في Skillbox باستخدام الرمز الترويجي "Habr".
تتكون الخوارزمية من خمس مراحل:
- بداية بسيطة
- تأكيد الخسائر ؛
- التحقق من النتائج والمركبات الوسيطة ؛
- تشخيص المعلمات.
- مراقبة العمل.
إذا بدا لك شيئًا ما أكثر إثارة للاهتمام من الآخرين ، فيمكنك الانتقال مباشرةً إلى هذه الأقسام.
بداية سهلة
إن الشبكة العصبية ذات البنية المعقدة ، والتنظيم ، ومخطط سرعة التعلم يصعب ظهورها لأول مرة من شبكة عادية. نحن صعبون بعض الشيء ، نظرًا لأن العنصر نفسه له علاقة غير مباشرة بالتصحيح ، لكن هذه التوصية لا تزال مهمة.
البداية البسيطة هي إنشاء نموذج مبسط وتدريبه على مجموعة بيانات واحدة (نقطة).
أولاً نقوم بإنشاء نموذج مبسطلبداية سريعة ، قم بإنشاء شبكة صغيرة بطبقة واحدة مخفية وتحقق من أن كل شيء يعمل بشكل صحيح. ثم نعقد النموذج تدريجياً ، ونفحص كل جانب جديد من بنيته (طبقة إضافية ، معلمة ، وما إلى ذلك) ، والمضي قدمًا.
نقوم بتدريب النموذج على مجموعة بيانات واحدة (نقطة)كاختبار سريع لصحة مشروعك ، يمكنك استخدام نقطة أو نقطتي بيانات للتدريب لتأكيد ما إذا كان النظام يعمل بشكل صحيح. يجب أن تُظهر الشبكة العصبية دقة بنسبة 100٪ في التدريب والتحقق. إذا لم يكن الأمر كذلك ، فإما أن يكون النموذج صغيرًا جدًا أو لديك بالفعل خلل.
حتى لو كان كل شيء على ما يرام ، قم بإعداد النموذج لمرور واحد أو أكثر من العصور قبل الانتقال.
تقدير الخسارة
تقدير الخسارة هو الطريقة الرئيسية لتحسين أداء النموذج. تحتاج إلى التأكد من أن الخسارة تتوافق مع المهمة ، وأن وظائف الخسارة يتم تقييمها بالمقياس الصحيح. إذا كنت تستخدم أكثر من نوع واحد من الخسائر ، فتأكد من أنها كلها بنفس الترتيب وقياسها بشكل صحيح.
من المهم أن تكون منتبهاً للخسائر الأولية. تحقق من مدى قرب النتيجة الحقيقية من المتوقع إذا بدأ النموذج بافتراض عشوائي.
يقترح عمل Andrei Karpati ما يلي : "تأكد من حصولك على النتيجة المتوقعة عند بدء العمل باستخدام عدد صغير من المعلمات. من الأفضل التحقق على الفور من فقدان البيانات (مع ضبط درجة التنظيم على الصفر). على سبيل المثال ، بالنسبة إلى CIFAR-10 مع مصنف Softmax ، نتوقع أن تكون الخسارة المبدئية 2.302 ، لأن احتمال الانتشار المنتشر هو 0.1 لكل فئة (نظرًا لوجود 10 فصول) ، وفقدان Softmax هو الاحتمال السلبي لوغاريتمي للفئة الصحيحة كـ - ln (0.1) = 2.302. "
على سبيل المثال الثنائي ، يتم ببساطة إجراء حساب مماثل لكل فئة من الفئات. هنا ، على سبيل المثال ، البيانات: 20٪ 0 و 80٪ 1. سوف تصل الخسارة الأولية المتوقعة إلى -0.2ln (0.5) -0.8ln (0.5) = 0.693147. إذا كانت النتيجة أكبر من 1 ، فقد يشير ذلك إلى أن أوزان الشبكة العصبية غير متوازنة بشكل صحيح أو أن البيانات غير طبيعية.
التحقق من النتائج المتوسطة والاتصالات
لتصحيح الشبكة العصبية ، من الضروري فهم ديناميات العمليات داخل الشبكة ودور الطبقات الوسيطة الفردية ، حيث إنها متصلة. إليك بعض الأخطاء الشائعة التي قد تواجهها:
- التعبيرات غير الصحيحة للحصول على تحديثات التدرج
- تحديثات الوزن لا تنطبق ؛
- تختفي أو تنفجر التدرجات.
إذا كانت قيم التدرج هي صفر ، فهذا يعني أن سرعة التعلم في المحسن تكون بطيئة جدًا ، أو أنك واجهت تعبيرًا غير صحيح لتحديث التدرج اللوني.
بالإضافة إلى ذلك ، من الضروري مراقبة قيم وظائف التنشيط والأوزان والتحديثات لكل طبقة. على سبيل المثال ،
يجب أن تكون قيمة تحديثات المعلمات (الأوزان والإزاحة)
1-e3 .
هناك ظاهرة تسمى "Dying ReLU" أو "Disapp
تختفي مشكلة التدرج" عندما تنتج الخلايا العصبية ReLU صفرًا بعد دراسة قيمة التحيز السلبي الكبيرة لأوزانها. لا يتم تنشيط هذه الخلايا العصبية مرة أخرى في أي مكان بيانات.
يمكنك استخدام اختبار التدرج للكشف عن هذه الأخطاء عن طريق تقريب التدرج اللوني باستخدام نهج رقمي. إذا كان قريبًا من التدرجات المحسوبة ، فسيتم تنفيذ الانتشار الخلفي بشكل صحيح. لإنشاء فحص تدرج ، تحقق من موارد CS231 الرائعة
هنا وهنا ، بالإضافة إلى البرنامج التعليمي الخاص بـ Andrew Nga حول هذا الموضوع.
يشير فايزان شيخ إلى ثلاث طرق رئيسية لتصور الشبكة العصبية:
- تمهيدي - الأساليب البسيطة التي تبين لنا الهيكل العام للنموذج المدربين. وهي تشمل إخراج النماذج أو المرشحات من الطبقات الفردية للشبكة العصبية والمعلمات في كل طبقة.
- بناء على التنشيط. في نفوسهم ، نقوم بفك تشفير تنشيط الخلايا العصبية الفردية أو مجموعات الخلايا العصبية من أجل فهم وظائفها.
- التدرج القائم. تميل هذه الطرق إلى التعامل مع التدرجات التي تتشكل من المقطع ذهابًا وإيابًا عند تدريب النموذج (بما في ذلك خرائط الأهمية وخرائط تنشيط الفصل).
هناك العديد من الأدوات المفيدة لتصور عمليات التنشيط واتصالات الطبقات الفردية ، على سبيل المثال ،
ConX و
Tensorboard .
المعلمة التشخيص
الشبكات العصبية لديها الكثير من المعلمات التي تتفاعل مع بعضها البعض ، مما يعقد عملية التحسين. في الواقع ، هذا القسم هو موضوع البحث النشط من قبل المتخصصين ، لذلك ينبغي النظر في المقترحات أدناه فقط على أنها نصيحة ، ونقطة البداية التي يمكنك الاعتماد عليها.
حجم الدُفعة - إذا كنت تريد أن يكون حجم الرزمة كبيرًا بدرجة كافية لتوفير تقديرات دقيقة لتدرج الخطأ ، ولكنه صغير بما يكفي بحيث يمكن أن ينحدر منحدر الانحدار العشوائي (SGD) شبكتك. سيؤدي الحجم الصغير للحزم إلى تقارب سريع بسبب الضوضاء في عملية التعلم وفي المستقبل إلى صعوبات التحسين. يوصف هذا بمزيد من التفاصيل
هنا .
سرعة التعلم - بطيئة للغاية سيؤدي إلى تقارب بطيء أو خطر الوقوع في أدنى المستويات المحلية. في الوقت نفسه ، ستتسبب سرعة التعلم العالية في حدوث تباين في التحسين ، نظرًا لأنك تخاطر "بالقفز" في العمق ، ولكن في الوقت نفسه جزء ضيق من وظيفة الخسارة. حاول استخدام تخطيط السرعة لتقليله أثناء تدريب الشبكة العصبية. CS231n
يحتوي على قسم كبير حول هذه المشكلة .
لقطة متدرجة - تقليم تدرجات المعلمات أثناء الانتشار الخلفي عند الحد الأقصى للقيمة أو حد الحد. مفيد لحل المشاكل مع أي تدرجات تنفجر قد تواجهها في الفقرة الثالثة.
تطبيع الدُفعة - يستخدم لتطبيع بيانات الإدخال لكل طبقة ، مما يسمح بحل مشكلة التحول الداخلي المتغير. إذا كنت تستخدم Dropout و Batch Norma معًا ،
فراجع هذه المقالة .
نزول الانحدار العشوائي (SGD) - هناك عدة أنواع من SGD تستخدم الزخم ، وسرعات التعلم التكيفية ، وطريقة Nesterov. في الوقت نفسه ، لا يتمتع أي منهم بميزة واضحة سواء من حيث كفاءة التدريب والتعميم (
التفاصيل هنا ).
التنظيم - ضروري لبناء نموذج عام ، لأنه يضيف عقوبة لتعقيد النموذج أو قيم المعلمة القصوى. هذه طريقة للحد من تباين النموذج دون زيادة كبيرة في إزاحته. مزيد من
المعلومات هنا .
من أجل تقييم كل شيء بنفسك ، تحتاج إلى تعطيل التنظيم والتحقق من تدرج فقدان البيانات بنفسك.
التسرب هو طريقة أخرى لتبسيط شبكتك لمنع الازدحام. أثناء التدريب ، يحدث الفقد فقط من خلال الحفاظ على نشاط الخلايا العصبية ذات الاحتمال المعين p (hyperparameter) أو ضبطه على الصفر في الحالة المقابلة. نتيجةً لذلك ، يجب أن تستخدم الشبكة مجموعة فرعية مختلفة من المعلمات لكل فريق تدريب ، مما يقلل من التغييرات في بعض المعلمات التي أصبحت مسيطرة.
هام: إذا كنت تستخدم كلا التسرب من التسرب والدُفعات ، فاحرص على ترتيب هذه العمليات أو حتى مع استخدامها المشترك. كل هذا لا يزال يناقش بنشاط وتستكمل. فيما يلي
نقاشان مهمان حول هذا الموضوع
في Stackoverflow و
Arxiv .
مراقبة العمل
إنه يتعلق بتوثيق سير العمل والتجارب. إذا لم تقم بتوثيق أي شيء ، يمكنك أن تنسى ، على سبيل المثال ، نوع سرعة التدريب أو وزن الفصل المستخدم. بفضل عنصر التحكم ، يمكنك بسهولة عرض وإعادة إنتاج التجارب السابقة. هذا يقلل من عدد التجارب المكررة.
صحيح أن الوثائق اليدوية يمكن أن تكون صعبة في حالة وجود قدر كبير من العمل. تساعدك أدوات هنا مثل Comet.ml على تسجيل مجموعات البيانات تلقائيًا ، وتغييرات التعليمات البرمجية ، وسجل التجربة ، ونماذج الإنتاج ، بما في ذلك المعلومات الأساسية عن النموذج الخاص بك (المعلمات الفوقية ، ومؤشرات أداء النموذج ، والمعلومات البيئية).
يمكن أن تكون الشبكة العصبية حساسة للغاية للتغييرات الصغيرة ، وسيؤدي ذلك إلى انخفاض في أداء النموذج. يعد تتبع العمل وتوثيقه الخطوة الأولى التي يجب اتخاذها لتوحيد البيئة والنمذجة.
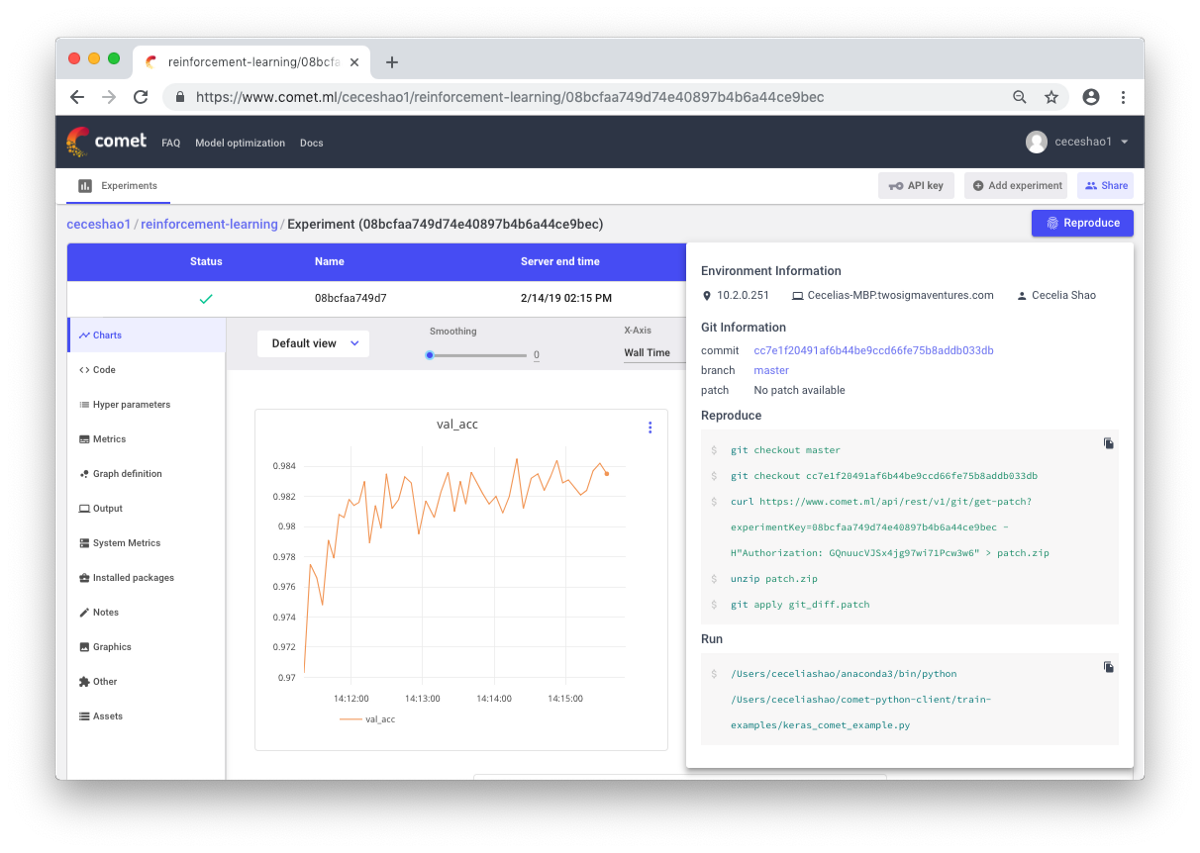
آمل أن يصبح هذا المنشور نقطة البداية التي ستبدأ منها في تصحيح أخطاء الشبكة العصبية.
توصي Skillbox بما يلي: