في المقالات السابقة ، ناقشنا
محرك فهرسة PostgreSQL
وواجهة طرق الوصول وطريقتي وصول:
فهرس التجزئة و
B-tree . في هذه المقالة ، سنصف فهارس GiST.
جوهر
GiST هو اختصار لـ "شجرة البحث المعممة". هذه شجرة بحث متوازنة ، تمامًا مثل "b-tree" التي نوقشت سابقًا.
ما هو الفرق؟ يرتبط مؤشر "Btree" ارتباطًا وثيقًا بدلالات المقارنة: دعم المشغلين "الأكبر" و "الأقل" و "المتساويين" هو كل ما هو قادر على (ولكنه قادر جدًا!) ومع ذلك ، فإن قواعد البيانات الحديثة تخزن أنواع البيانات التي يقوم هؤلاء المشغلون بتخزينها. لا معنى له: البيانات الجغرافية والمستندات النصية والصور ...
تأتي طريقة فهرس GiST في مساعدتنا لأنواع البيانات هذه. يسمح بتحديد قاعدة لتوزيع البيانات من نوع تعسفي عبر شجرة متوازنة وطريقة لاستخدام هذا التمثيل للوصول من قبل بعض المشغلين. على سبيل المثال ، يمكن لمؤشر GiST أن "يستوعب" R-tree للبيانات المكانية بدعم من مشغلي المواقع النسبية (الموجود على اليسار ، على اليمين ، يحتوي على ، وما إلى ذلك) أو RD-tree للمجموعات التي تدعم مشغلي التقاطع أو التضمين.
بفضل القابلية للتوسعة ، يمكن إنشاء طريقة جديدة تمامًا من البداية في PostgreSQL: تحقيقًا لهذه الغاية ، يجب تنفيذ واجهة مع محرك الفهرسة. ولكن هذا لا يتطلب إجراء تعميق منطق الفهرسة فحسب ، بل يتطلب أيضًا تعيين بنية البيانات على الصفحات ، والتنفيذ الفعال للأقفال ، ودعم سجل الكتابة المسبقة. كل هذا يفترض مهارات المطور عالية وجهد إنساني كبير. تعمل GiST على تبسيط المهمة من خلال التغلب على المشكلات ذات المستوى المنخفض وتقديم واجهة خاصة بها: العديد من الوظائف التي لا تتعلق بالتقنيات ، ولكن بنطاق التطبيق. وبهذا المعنى ، يمكننا اعتبار GiST كإطار لبناء طرق وصول جديدة.
هيكل
GiST هي شجرة متوازنة الارتفاع تتكون من صفحات العقدة. تتكون العقد من صفوف الفهرس.
يحتوي كل صف من عقدة الورقة (صف الورقة) ، بشكل عام ، على بعض
المسند (تعبير منطقي) وإشارة إلى صف جدول (TID). يجب أن تفي البيانات المفهرسة (المفتاح) بهذا المسند.
يحتوي كل صف من العقدة الداخلية (صف داخلي) أيضًا على
مسند وإشارة إلى عقدة تابعة ، ويجب أن تلبي جميع البيانات المفهرسة للشجرة الفرعية هذا المسند. بمعنى آخر ،
تتضمن مسند الصف الداخلي مسندات جميع صفوف الأطفال. هذه السمة المهمة لمؤشر GiST تستبدل الترتيب البسيط لشجرة B.
يستخدم البحث في شجرة GiST
وظيفة تناسق متخصصة ("متسقة") - واحدة من الوظائف المحددة بواسطة الواجهة ويتم تنفيذها بطريقتها الخاصة لكل عائلة مشغل مدعومة.
يتم استدعاء وظيفة التناسق لصف فهرس وتحدد ما إذا كان تقييم هذا الصف متوافقًا مع تقييم البحث (المحدد كـ "
تعبير عامل الحقل المفهرس "). بالنسبة للصف الداخلي ، تحدد هذه الوظيفة في الواقع ما إذا كانت هناك حاجة للإنزال إلى الشجرة الفرعية المقابلة ، وبالنسبة للصف الشجري ، تحدد الوظيفة ما إذا كانت البيانات المفهرسة تفي بالتقييم.
يبدأ البحث بعقدة الجذر ، كبحث شجرة عادي. تسمح وظيفة الاتساق باكتشاف العقد الفرعية التي من المنطقي إدخالها (قد يكون هناك العديد منها) وأيها لا تفعل ذلك. ثم يتم تكرار الخوارزمية لكل عقدة فرعية موجودة. وإذا كانت العقدة ورقة ، فسيتم إرجاع الصف المحدد بواسطة دالة التناسق كأحد النتائج.
البحث في العمق أولاً: تحاول الخوارزمية أولاً الوصول إلى عقدة ورقة. يسمح هذا بإرجاع النتائج الأولى قريبًا كلما كان ذلك ممكنًا (الأمر الذي قد يكون مهمًا إذا كان المستخدم مهتمًا بعدة نتائج فقط وليس كلها).
دعنا نلاحظ مرة أخرى أن وظيفة التناسق لا تحتاج إلى أي علاقة بعوامل تشغيل "أكبر" أو "أقل" أو "متساوية". قد تكون دلالات دالة التناسق مختلفة تمامًا ، وبالتالي ، لا يُفترض أن يُرجع الفهرس قيمًا بترتيب معين.
لن نناقش خوارزميات الإدراج وحذف القيم في GiST: هناك عدد قليل من
وظائف الواجهة تؤدي هذه العمليات. هناك نقطة واحدة مهمة ولكن. عندما يتم إدراج قيمة جديدة في الفهرس ، يتم تحديد موضع هذه القيمة في الشجرة بحيث يتم تمديد مسند الصفوف الرئيسية الخاصة بها بأقل قدر ممكن (من الناحية المثالية ، لا يتم تمديدها على الإطلاق). ولكن عندما يتم حذف القيمة ، لن يتم تخفيض تقييم الصف الأصل. يحدث هذا فقط في مثل هذه الحالات: يتم تقسيم الصفحة إلى حالتين (عندما لا تحتوي الصفحة على مساحة كافية لإدخال صف فهرس جديد) أو يتم إعادة إنشاء الفهرس من البداية (باستخدام أمر REINDEX أو VACUUM FULL). لذلك ، يمكن أن تتحلل كفاءة مؤشر GiST لتغيير البيانات بشكل متكرر بمرور الوقت.
علاوة على ذلك ، سننظر في بعض الأمثلة من الفهارس لأنواع البيانات المختلفة والخصائص المفيدة لـ GiST:
- النقاط (والكيانات الهندسية الأخرى) والبحث عن أقرب الجيران.
- الفواصل الزمنية وقيود الاستبعاد.
- البحث عن النص الكامل.
R- شجرة للحصول على نقاط
سنقوم بتوضيح ما سبق بمثال فهرس للنقاط في المستوى (يمكننا أيضًا إنشاء فهارس متشابهة للكيانات الهندسية الأخرى). B- شجرة عادية لا تتناسب مع هذا النوع من البيانات لأنه لا توجد عوامل مقارنة محددة للنقاط.
فكرة R-tree هي تقسيم الطائرة إلى مستطيلات تغطي جميع النقاط التي تتم فهرستها بشكل إجمالي. يخزن صف الفهرس مستطيلًا ، ويمكن تعريف المسند كما يلي: "تقع النقطة المطلوبة داخل المستطيل المحدد".
سيحتوي جذر شجرة R على عدة مستطيلات أكبر (ربما متقاطعة). ستحتوي العقد الفرعية على مستطيلات أصغر حجمًا مضمّنة في الأصل الأصل وفي تغطية إجمالية جميع النقاط الأساسية.
من الناحية النظرية ، يجب أن تحتوي العقد الورقية على نقاط يتم فهرستها ، ولكن يجب أن يكون نوع البيانات هو نفسه في جميع صفوف الفهرس ، وبالتالي ، يتم تخزين المستطيلات مرة أخرى ، ولكن "تنهار" في نقاط.
لتصور مثل هذا الهيكل ، نحن نوفر صورًا لثلاثة مستويات من شجرة R-. النقاط هي إحداثيات المطارات (على غرار تلك الموجودة في جدول "المطارات" في
قاعدة البيانات التجريبية ، ولكن يتم توفير المزيد من البيانات من
openflights.org ).
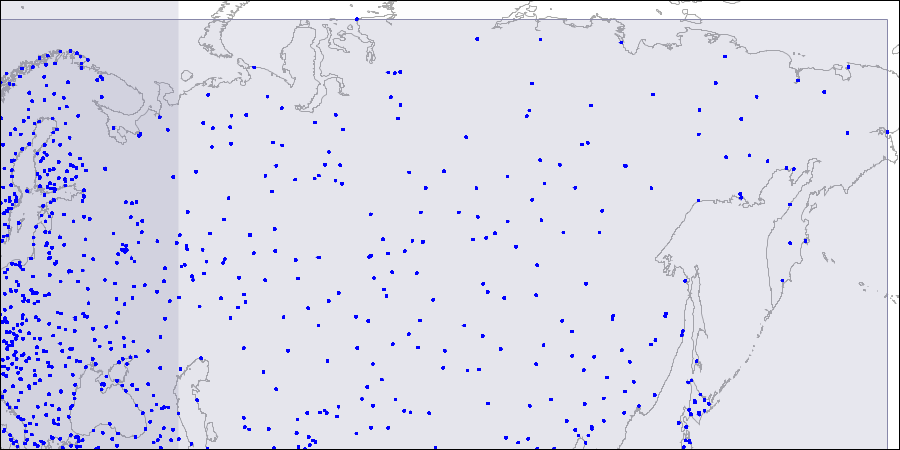 المستوى الأول: مستطيلان كبيران متقاطعان مرئيان.
المستوى الأول: مستطيلان كبيران متقاطعان مرئيان. المستوى الثاني: يتم تقسيم المستطيلات الكبيرة إلى مناطق أصغر.
المستوى الثاني: يتم تقسيم المستطيلات الكبيرة إلى مناطق أصغر.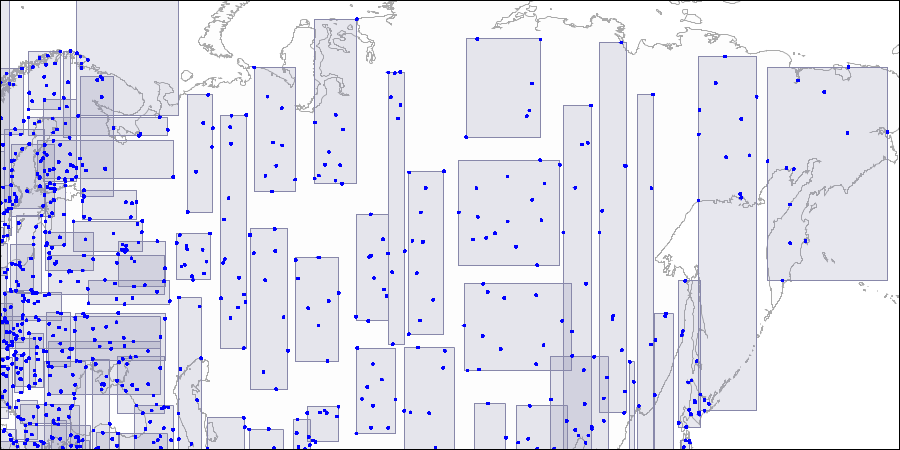 المستوى الثالث: يحتوي كل مستطيل على العديد من النقاط لتناسب صفحة فهرس واحدة.
المستوى الثالث: يحتوي كل مستطيل على العديد من النقاط لتناسب صفحة فهرس واحدة.الآن لننظر في مثال بسيط للغاية من "مستوى واحد":
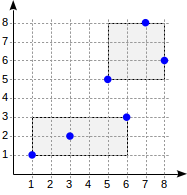
postgres=# create table points(p point); postgres=# insert into points(p) values (point '(1,1)'), (point '(3,2)'), (point '(6,3)'), (point '(5,5)'), (point '(7,8)'), (point '(8,6)'); postgres=# create index on points using gist(p);
مع هذا التقسيم ، سيبدو هيكل الفهرس كما يلي:
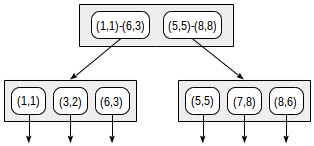
يمكن استخدام الفهرس الذي تم إنشاؤه لتسريع الاستعلام التالي ، على سبيل المثال: "البحث عن جميع النقاط الموجودة في المستطيل المحدد". يمكن إضفاء الطابع الرسمي على هذا الشرط على النحو التالي:
p <@ box '(2,1),(6,3)' (تعني المشغل
<@ من عائلة "points_ops" "الواردة في"):
postgres=# set enable_seqscan = off; postgres=# explain(costs off) select * from points where p <@ box '(2,1),(7,4)';
QUERY PLAN ---------------------------------------------- Index Only Scan using points_p_idx on points Index Cond: (p <@ '(7,4),(2,1)'::box) (2 rows)
يتم تعريف وظيفة التناسق للمشغل ("
الحقل المفهرس <@
تعبير " ، حيث يكون
الحقل المفهرس نقطة
والتعبير مستطيل) كما يلي. بالنسبة للصف الداخلي ، تُرجع "نعم" إذا كان مستطيلها يتقاطع مع المستطيل المحدد
بالتعبير . بالنسبة لصف الورقة ، تُرجع الدالة "نعم" إذا كانت نقطتها (مستطيل "مطوي") مضمنة في المستطيل المحدد بواسطة التعبير.
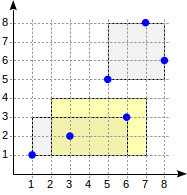
يبدأ البحث بالعقدة الجذرية. يتقاطع المستطيل (2،1) - (7،4) مع (1،1) - (6،3) ، لكنه لا يتقاطع مع (5،5) - (8،8) ، وبالتالي ، ليست هناك حاجة لينزل إلى الشجرة الثانية.
عند الوصول إلى عقدة ورقة ، نذهب إلى النقاط الثلاث الموجودة هناك ونعيد اثنين منهم كنتيجة: (3.2) و (6.3).
postgres=# select * from points where p <@ box '(2,1),(7,4)';
p ------- (3,2) (6,3) (2 rows)
الداخلية
لسوء الحظ ، لا يسمح "pageinspect" العرفي بالبحث في فهرس GiST. ولكن هناك طريقة أخرى متاحة: التمديد "gevel". لا يتم تضمينه في التسليم القياسي ، لذلك راجع
تعليمات التثبيت .
إذا تم كل شيء بشكل صحيح ، فستكون هناك ثلاث وظائف متاحة لك. أولاً ، يمكننا الحصول على بعض الإحصاءات:
postgres=# select * from gist_stat('airports_coordinates_idx');
gist_stat ------------------------------------------ Number of levels: 4 + Number of pages: 690 + Number of leaf pages: 625 + Number of tuples: 7873 + Number of invalid tuples: 0 + Number of leaf tuples: 7184 + Total size of tuples: 354692 bytes + Total size of leaf tuples: 323596 bytes + Total size of index: 5652480 bytes+ (1 row)
من الواضح أن حجم الفهرس على إحداثيات المطار هو 690 صفحة وأن الفهرس يتكون من أربعة مستويات: الجذر والمستوىان الداخليان معروضان في الأشكال أعلاه ، والمستوى الرابع هو الورقة.
في الواقع ، سيكون المؤشر الخاص بثمانية آلاف نقطة أصغر بكثير: هنا تم إنشاؤه باستخدام fillfactor 10 ٪ من أجل الوضوح.
ثانيًا ، يمكننا إخراج شجرة الفهرس:
postgres=# select * from gist_tree('airports_coordinates_idx');
gist_tree ----------------------------------------------------------------------------------------- 0(l:0) blk: 0 numTuple: 5 free: 7928b(2.84%) rightlink:4294967295 (InvalidBlockNumber) + 1(l:1) blk: 335 numTuple: 15 free: 7488b(8.24%) rightlink:220 (OK) + 1(l:2) blk: 128 numTuple: 9 free: 7752b(5.00%) rightlink:49 (OK) + 1(l:3) blk: 57 numTuple: 12 free: 7620b(6.62%) rightlink:35 (OK) + 2(l:3) blk: 62 numTuple: 9 free: 7752b(5.00%) rightlink:57 (OK) + 3(l:3) blk: 72 numTuple: 7 free: 7840b(3.92%) rightlink:23 (OK) + 4(l:3) blk: 115 numTuple: 17 free: 7400b(9.31%) rightlink:33 (OK) + ...
وثالثا ، يمكننا إخراج البيانات المخزنة في صفوف الفهرس. لاحظ الفروق الدقيقة التالية: يجب تحويل نتيجة الوظيفة إلى نوع البيانات المطلوب. في حالتنا ، هذا النوع هو "مربع" (مستطيل محاط). على سبيل المثال ، لاحظ خمسة صفوف في المستوى العلوي:
postgres=# select level, a from gist_print('airports_coordinates_idx') as t(level int, valid bool, a box) where level = 1;
level | a -------+----------------------------------------------------------------------- 1 | (47.663586,80.803207),(-39.2938003540039,-90) 1 | (179.951004028,15.6700000762939),(15.2428998947144,-77.9634017944336) 1 | (177.740997314453,73.5178070068359),(15.0664,10.57970047) 1 | (-77.3191986083984,79.9946975708),(-179.876998901,-43.810001373291) 1 | (-39.864200592041,82.5177993774),(-81.254096984863,-64.2382965088) (5 rows)
في الواقع ، تم إنشاء الأرقام المذكورة أعلاه فقط من هذه البيانات.
مشغلي للبحث والطلب
المشغلين الذين تمت مناقشتهم حتى الآن (مثل
<@ في المسند
p <@ box '(2,1),(7,4)' ) يمكن أن يطلق عليهم مشغلي البحث لأنهم يحددون شروط البحث في استعلام.
هناك أيضًا نوع مشغل آخر: مشغلي الطلب. يتم استخدامها لمواصفات ترتيب الفرز في جملة ORDER BY بدلاً من المواصفات التقليدية لأسماء الأعمدة. فيما يلي مثال على هذا الاستعلام:
postgres=# select * from points order by p <-> point '(4,7)' limit 2;
p ------- (5,5) (7,8) (2 rows)
p <-> point '(4,7)' هنا هي تعبير يستخدم عامل تشغيل
<-> ، والذي يشير إلى المسافة من وسيطة إلى أخرى. معنى الاستعلام هو إرجاع نقطتين الأقرب إلى النقطة (4.7). يُعرف البحث مثل هذا باسم k-NN - بحث أقرب جار.
لدعم الاستعلامات من هذا النوع ، يجب أن تحدد طريقة الوصول
وظيفة مسافة إضافية ، ويجب تضمين عامل الطلب في فئة المشغل المناسبة (على سبيل المثال ، فئة "points_ops" للنقاط). يعرض الاستعلام أدناه العوامل ، إلى جانب أنواعها ("s" - البحث و "o" - الطلب):
postgres=# select amop.amopopr::regoperator, amop.amoppurpose, amop.amopstrategy from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop where opc.opcname = 'point_ops' and opf.oid = opc.opcfamily and am.oid = opf.opfmethod and amop.amopfamily = opc.opcfamily and am.amname = 'gist' and amop.amoplefttype = opc.opcintype;
amopopr | amoppurpose | amopstrategy -------------------+-------------+-------------- <<(point,point) | s | 1 strictly left >>(point,point) | s | 5 strictly right ~=(point,point) | s | 6 coincides <^(point,point) | s | 10 strictly below >^(point,point) | s | 11 strictly above <->(point,point) | o | 15 distance <@(point,box) | s | 28 contained in rectangle <@(point,polygon) | s | 48 contained in polygon <@(point,circle) | s | 68 contained in circle (9 rows)
وتظهر أيضا عدد من الاستراتيجيات ، مع شرح معانيها. من الواضح أن هناك استراتيجيات أكثر بكثير من "btree" ، حيث يتم دعم بعضها فقط للحصول على نقاط. يمكن تعريف استراتيجيات مختلفة لأنواع البيانات الأخرى.
يتم استدعاء وظيفة المسافة لعنصر الفهرس ، ويجب أن تحسب المسافة (مع مراعاة دلالات المشغل) من القيمة المحددة بواسطة التعبير ("
تعبير عامل ترتيب الحقل المفهرس ") إلى العنصر المحدد. بالنسبة لعنصر الورقة ، هذه هي المسافة إلى القيمة المفهرسة. بالنسبة للعنصر الداخلي ، يجب أن تُرجع الدالة الحد الأدنى للمسافات إلى عناصر الورقة الفرعية. نظرًا لأن المرور بجميع الصفوف التابعة سيكون مكلفًا للغاية ، يُسمح للوظيفة بتقليل المسافة بتفاؤل ، ولكن على حساب تقليل كفاءة البحث. ومع ذلك ، لا يُسمح أبدًا للوظيفة بإفراط في تقدير المسافة نظرًا لأن ذلك سيؤدي إلى تعطيل عمل الفهرس.
يمكن أن تقوم دالة المسافة بإرجاع قيم من أي نوع قابل للفرز (لطلب القيم ، سيستخدم PostgreSQL دلالات المقارنة من عائلة المشغل المناسبة لطريقة الوصول "btree" ، كما
هو موضح سابقًا ).
بالنسبة للنقاط في المستوى ، يتم تفسير المسافة بالمعنى المعتاد: قيمة
(x1,y1) <-> (x2,y2) تساوي الجذر التربيعي لمجموع مربعات الاختلافات في الإحداثيات والمخطوطات. يتم أخذ المسافة من نقطة إلى مستطيل محايد لتكون الحد الأدنى للمسافة من النقطة إلى هذا المستطيل أو الصفر إذا كانت النقطة تقع داخل المستطيل. من السهل حساب هذه القيمة دون المرور عبر نقاط تابعة ، ولا تزيد القيمة بالتأكيد عن المسافة إلى أي نقطة فرعية.
لننظر في خوارزمية البحث للاستعلام أعلاه.
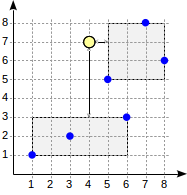
يبدأ البحث بالعقدة الجذرية. تحتوي العقدة على مستطيلين محيطين. المسافة إلى (1،1) - (6،3) هي 4.0 وإلى (5،5) - (8،8) 1.0.
يتم تمرير العقد التابعة بترتيب زيادة المسافة. بهذه الطريقة ، ننزل أولاً إلى أقرب عقدة تابعة ونحسب المسافات إلى النقاط (سنظهر الأرقام في الشكل للرؤية):

هذه المعلومات تكفي لإرجاع أول نقطتين ، (5،5) و (7،8). نظرًا لأننا ندرك أن المسافة إلى النقاط التي تقع داخل المستطيل (1،1) - (6،3) هي 4.0 أو أكبر ، فنحن لسنا بحاجة إلى النزول إلى العقدة الفرعية الأولى.
لكن ماذا لو احتجنا إلى إيجاد النقاط
الثلاث الأولى؟
postgres=# select * from points order by p <-> point '(4,7)' limit 3;
p
على الرغم من أن العقدة الفرعية الثانية تحتوي على كل هذه النقاط ، إلا أنه لا يمكننا إرجاع (8،6) دون النظر إلى العقدة الفرعية الأولى نظرًا لأن هذه العقدة يمكن أن تحتوي على نقاط أقرب (منذ 4.0 <4.1).

بالنسبة للصفوف الداخلية ، يوضح هذا المثال متطلبات وظيفة المسافة. من خلال تحديد مسافة أصغر (4.0 بدلاً من 4.5 الفعلي) للصف الثاني ، قمنا بتقليل الكفاءة (بدأت الخوارزمية دون داع في فحص عقدة إضافية) ، لكننا لم نكسر صحة الخوارزمية.
حتى وقت قريب ، كانت GiST هي طريقة الوصول الوحيدة القادرة على التعامل مع مشغلي الطلبات. لكن الوضع قد تغير: لقد انضمت بالفعل طريقة الوصول إلى RUM (لمزيد من المناقشة) إلى هذه المجموعة من الطرق ، وليس من المرجح أن تنضم B-tree القديمة الجيدة إليهم: يتم تطوير تصحيح قام بوضعه نيكيتا جلوخوف ، زميلنا ، ناقشها المجتمع.
اعتبارًا من مارس 2019 ، تمت إضافة دعم k-NN لـ SP-GiST في PostgreSQL 12 القادم (تأليف Nikita أيضًا). التصحيح لشجرة ب لا يزال قيد التقدم.
R- شجرة لفترات
مثال آخر لاستخدام طريقة الوصول إلى GiST هو فهرسة الفواصل الزمنية ، على سبيل المثال ، الفواصل الزمنية (نوع "tsrange"). كل الاختلاف هو أن العقد الداخلية ستحتوي على فواصل زمنية محددة بدلاً من حدود المستطيلات.
دعنا ننظر مثال بسيط. سنقوم بتأجير فواصل حجز كوخ وتخزينها في جدول:
postgres=# create table reservations(during tsrange); postgres=# insert into reservations(during) values ('[2016-12-30, 2017-01-09)'), ('[2017-02-23, 2017-02-27)'), ('[2017-04-29, 2017-05-02)'); postgres=# create index on reservations using gist(during);
يمكن استخدام الفهرس لتسريع الاستعلام التالي ، على سبيل المثال:
postgres=# select * from reservations where during && '[2017-01-01, 2017-04-01)';
during ----------------------------------------------- ["2016-12-30 00:00:00","2017-01-08 00:00:00") ["2017-02-23 00:00:00","2017-02-26 00:00:00") (2 rows)
postgres=# explain (costs off) select * from reservations where during && '[2017-01-01, 2017-04-01)';
QUERY PLAN ------------------------------------------------------------------------------------ Index Only Scan using reservations_during_idx on reservations Index Cond: (during && '["2017-01-01 00:00:00","2017-04-01 00:00:00")'::tsrange) (2 rows)
&& عامل التشغيل للفواصل يشير إلى التقاطع ؛ لذلك ، يجب أن يُرجع الاستعلام جميع الفواصل الزمنية المتقاطعة مع الفترة المعطاة. بالنسبة إلى هذا المشغل ، تحدد وظيفة التناسق ما إذا كان الفاصل الزمني المحدد يتقاطع مع قيمة في صف داخلي أو ورقة.
لاحظ أن هذا لا يتعلق بالحصول على فترات زمنية بترتيب معين ، على الرغم من أن عوامل المقارنة محددة للفواصل الزمنية. يمكننا استخدام فهرس "btree" للفواصل الزمنية ، ولكن في هذه الحالة ، يتعين علينا الاستغناء عن دعم عمليات مثل هذه:
postgres=# select amop.amopopr::regoperator, amop.amoppurpose, amop.amopstrategy from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop where opc.opcname = 'range_ops' and opf.oid = opc.opcfamily and am.oid = opf.opfmethod and amop.amopfamily = opc.opcfamily and am.amname = 'gist' and amop.amoplefttype = opc.opcintype;
amopopr | amoppurpose | amopstrategy -------------------------+-------------+-------------- @>(anyrange,anyelement) | s | 16 contains element <<(anyrange,anyrange) | s | 1 strictly left &<(anyrange,anyrange) | s | 2 not beyond right boundary &&(anyrange,anyrange) | s | 3 intersects &>(anyrange,anyrange) | s | 4 not beyond left boundary >>(anyrange,anyrange) | s | 5 strictly right -|-(anyrange,anyrange) | s | 6 adjacent @>(anyrange,anyrange) | s | 7 contains interval <@(anyrange,anyrange) | s | 8 contained in interval =(anyrange,anyrange) | s | 18 equals (10 rows)
(باستثناء المساواة ، الموجودة في فئة المشغل لطريقة الوصول "btree".)
الداخلية
يمكننا أن ننظر من الداخل باستخدام نفس التمديد "gevel". نحتاج فقط إلى تذكر تغيير نوع البيانات في المكالمة إلى gist_print:
postgres=# select level, a from gist_print('reservations_during_idx') as t(level int, valid bool, a tsrange);
level | a -------+----------------------------------------------- 1 | ["2016-12-30 00:00:00","2017-01-09 00:00:00") 1 | ["2017-02-23 00:00:00","2017-02-27 00:00:00") 1 | ["2017-04-29 00:00:00","2017-05-02 00:00:00") (3 rows)
قيود الاستبعاد
يمكن استخدام فهرس GiST لدعم قيود الاستبعاد (باستثناء).
يضمن قيد الاستثناء الحقول المعينة لأي من صفوف الجدولين ألا "تتوافق" مع بعضها البعض من حيث بعض العوامل. إذا تم اختيار عامل التشغيل "يساوي" ، فسنحصل بالضبط على القيد الفريد: لا تساوي الحقول المحددة لأي صفين معًا.
يتم دعم قيود الاستبعاد بواسطة الفهرس ، وكذلك القيد الفريد. يمكننا اختيار أي مشغل بحيث:
- يتم دعمه بواسطة طريقة الفهرس - خاصية "can_exclude" (على سبيل المثال ، "btree" أو GiST أو SP-GiST ، ولكن ليس GIN).
- من المنطقي ، وهذا هو ، تم استيفاء الشرط: المشغل ب = ب المشغل أ.
هذه قائمة من الاستراتيجيات والأمثلة المناسبة للمشغلين (كما نذكر ، يمكن أن يكون للمشغلين أسماء مختلفة ولن يكونوا متاحين لجميع أنواع البيانات):
- عن "btree":
- بالنسبة إلى GiST و SP-GiST:
- "تقاطع"
&& - "صدفة"
~= - المجاور
-|-
لاحظ أنه يمكننا استخدام عامل المساواة في قيد الاستبعاد ، ولكنه غير عملي: سيكون القيد الفريد أكثر كفاءة. هذا هو بالضبط السبب في أننا لم نتطرق إلى قيود الاستبعاد عندما ناقشنا الأشجار ب.
دعنا نقدم مثالًا على استخدام قيد الاستثناء. من المعقول عدم السماح بالحجز لفترات متقاطعة.
postgres=# alter table reservations add exclude using gist(during with &&);
بمجرد إنشاء قيد الاستبعاد ، يمكننا إضافة صفوف:
postgres=# insert into reservations(during) values ('[2017-06-10, 2017-06-13)');
لكن محاولة إدراج فاصل زمني متقاطع في الجدول سينتج عنه خطأ:
postgres=# insert into reservations(during) values ('[2017-05-15, 2017-06-15)');
ERROR: conflicting key value violates exclusion constraint "reservations_during_excl" DETAIL: Key (during)=(["2017-05-15 00:00:00","2017-06-15 00:00:00")) conflicts with existing key (during)=(["2017-06-10 00:00:00","2017-06-13 00:00:00")).
ملحق "Btree_gist"
دعونا تعقيد المشكلة. نوسع أعمالنا المتواضعة ، وسنؤجر العديد من المنازل الريفية:
postgres=# alter table reservations add house_no integer default 1;
نحتاج إلى تغيير قيد الاستبعاد حتى يتم أخذ أرقام المنازل في الاعتبار. ومع ذلك ، لا يدعم GiST عملية المساواة للأعداد الصحيحة:
postgres=# alter table reservations drop constraint reservations_during_excl; postgres=# alter table reservations add exclude using gist(during with &&, house_no with =);
ERROR: data type integer has no default operator class for access method "gist" HINT: You must specify an operator class for the index or define a default operator class for the data type.
في هذه الحالة ،
سيساعد التمديد "
btree_gist " ، مما يضيف دعم GiST للعمليات الملازمة لأشجار B. GiST ، في نهاية المطاف ، يمكن أن تدعم أي مشغلين ، فلماذا لا ينبغي لنا أن نعلمه لدعم "أكبر" ، "أقل" ، و "متساوية"؟
postgres=# create extension btree_gist; postgres=# alter table reservations add exclude using gist(during with &&, house_no with =);
الآن ما زلنا لا نستطيع حجز الكوخ الأول لنفس التواريخ:
postgres=# insert into reservations(during, house_no) values ('[2017-05-15, 2017-06-15)', 1);
ERROR: conflicting key value violates exclusion constraint "reservations_during_house_no_excl"
ومع ذلك ، يمكننا حجز الثانية:
postgres=# insert into reservations(during, house_no) values ('[2017-05-15, 2017-06-15)', 2);
لكن عليك أن تدرك أنه على الرغم من أن GiST يمكنها دعم المشغلين "الأعظم" و "الأقل" و "متساوين" بطريقة ما ، إلا أن B-tree ما زال يفعل ذلك بشكل أفضل. لذلك ، لا يجدر استخدام هذه التقنية إلا إذا كان مؤشر GiST ضروريًا بشكل أساسي ، كما في مثالنا.
RD- شجرة للبحث عن النص الكامل
حول البحث عن النص الكامل
لنبدأ بمقدمة بسيطة للبحث في النص الكامل لـ PostgreSQL (إذا كنت تعرف ذلك ، فيمكنك تخطي هذا القسم).
تتمثل مهمة البحث عن النص الكامل في التحديد من مجموعة المستندات تلك المستندات التي
تطابق استعلام البحث. (إذا كان هناك العديد من المستندات المطابقة ، فمن المهم العثور
على أفضل المطابقة ، لكننا لن نقول شيئًا عنها في هذه المرحلة.)
لأغراض البحث ، يتم تحويل المستند إلى نوع متخصص "tsvector" ، والذي يحتوي على lexemes ومواقعها في المستند. Lexemes هي كلمات يتم تحويلها إلى النموذج المناسب للبحث. على سبيل المثال ، يتم عادةً تحويل الكلمات إلى أحرف صغيرة ، ويتم قطع النهايات المتغيرة:
postgres=# select to_tsvector('There was a crooked man, and he walked a crooked mile');
to_tsvector ----------------------------------------- 'crook':4,10 'man':5 'mile':11 'walk':8 (1 row)
يمكننا أيضًا أن نرى أن بعض الكلمات (تسمى
كلمات الإيقاف ) يتم إسقاطها تمامًا ("هناك" ، "كان" ، "أ" ، "و" ، "هو") لأنها من المفترض أن تحدث كثيرًا للبحث عنهم بشكل منطقي. يمكن بالتأكيد تكوين كل هذه التحويلات ، لكن هذه قصة أخرى.
يتم تمثيل استعلام البحث بنوع آخر: "tsquery". بشكل تقريبي ، يتكون الاستعلام من واحدة أو عدة مفصلات مشتركة من خلال الروابط: "و" & "" أو "| ،" لا "! .. يمكننا أيضًا استخدام الأقواس لتوضيح أسبقية العملية.
postgres=# select to_tsquery('man & (walking | running)');
to_tsquery ---------------------------- 'man' & ( 'walk' | 'run' ) (1 row)
يتم استخدام عامل تطابق واحد
@@ عن النص الكامل.
postgres=# select to_tsvector('There was a crooked man, and he walked a crooked mile') @@ to_tsquery('man & (walking | running)');
?column? ---------- t (1 row)
postgres=# select to_tsvector('There was a crooked man, and he walked a crooked mile') @@ to_tsquery('man & (going | running)');
?column? ---------- f (1 row)
هذه المعلومات كافية الآن. سنتعمق قليلاً في البحث عن النص الكامل في مقالة تالية تتضمن فهرس GIN.
RD-الأشجار
للبحث بسرعة النص الكامل ، أولاً ، يحتاج الجدول إلى تخزين عمود من النوع "tsvector" (لتجنب إجراء تحويل مكلف في كل مرة عند البحث) وثانياً ، يجب أن يتم بناء فهرس على هذا العمود. إحدى طرق الوصول الممكنة لهذا هي GiST.
postgres=# create table ts(doc text, doc_tsv tsvector); postgres=# create index on ts using gist(doc_tsv); postgres=# insert into ts(doc) values ('Can a sheet slitter slit sheets?'), ('How many sheets could a sheet slitter slit?'), ('I slit a sheet, a sheet I slit.'), ('Upon a slitted sheet I sit.'), ('Whoever slit the sheets is a good sheet slitter.'), ('I am a sheet slitter.'), ('I slit sheets.'), ('I am the sleekest sheet slitter that ever slit sheets.'), ('She slits the sheet she sits on.'); postgres=# update ts set doc_tsv = to_tsvector(doc);
من المريح ، بالتأكيد ، تكليف أحد المشغلين بالخطوة الأخيرة (تحويل المستند إلى "tsvector").
postgres=# select * from ts;
-[ RECORD 1 ]---------------------------------------------------- doc | Can a sheet slitter slit sheets? doc_tsv | 'sheet':3,6 'slit':5 'slitter':4 -[ RECORD 2 ]---------------------------------------------------- doc | How many sheets could a sheet slitter slit? doc_tsv | 'could':4 'mani':2 'sheet':3,6 'slit':8 'slitter':7 -[ RECORD 3 ]---------------------------------------------------- doc | I slit a sheet, a sheet I slit. doc_tsv | 'sheet':4,6 'slit':2,8 -[ RECORD 4 ]---------------------------------------------------- doc | Upon a slitted sheet I sit. doc_tsv | 'sheet':4 'sit':6 'slit':3 'upon':1 -[ RECORD 5 ]---------------------------------------------------- doc | Whoever slit the sheets is a good sheet slitter. doc_tsv | 'good':7 'sheet':4,8 'slit':2 'slitter':9 'whoever':1 -[ RECORD 6 ]---------------------------------------------------- doc | I am a sheet slitter. doc_tsv | 'sheet':4 'slitter':5 -[ RECORD 7 ]---------------------------------------------------- doc | I slit sheets. doc_tsv | 'sheet':3 'slit':2 -[ RECORD 8 ]---------------------------------------------------- doc | I am the sleekest sheet slitter that ever slit sheets. doc_tsv | 'ever':8 'sheet':5,10 'sleekest':4 'slit':9 'slitter':6 -[ RECORD 9 ]---------------------------------------------------- doc | She slits the sheet she sits on. doc_tsv | 'sheet':4 'sit':6 'slit':2
كيف ينبغي هيكلة الفهرس؟ إن استخدام R-tree مباشرة ليس خيارًا لأنه من غير الواضح كيفية تحديد "مستطيل محاط" للمستندات. ولكن يمكننا تطبيق بعض التعديلات على هذا النهج للمجموعات ، ما يسمى شجرة RD (RD تعني "دمية روسية"). من المفهوم أن المجموعة هي مجموعة من المعجمات في هذه الحالة ، ولكن بشكل عام ، يمكن أن تكون المجموعة موجودة.
تتمثل فكرة أشجار RD في استبدال المستطيل المحيط بمجموعة محيط ، أي مجموعة تحتوي على جميع عناصر مجموعات الأطفال.
يطرح سؤال مهم حول كيفية تمثيل المجموعات في صفوف الفهرس. الطريقة الأكثر وضوحا هي فقط لتعداد جميع عناصر المجموعة. قد يبدو هذا كما يلي:

على سبيل المثال ، للوصول إلى كل حالة على
doc_tsv @@ to_tsquery('sit') يمكننا النزول إلا إلى تلك العقد التي تحتوي على lexeme "sit":
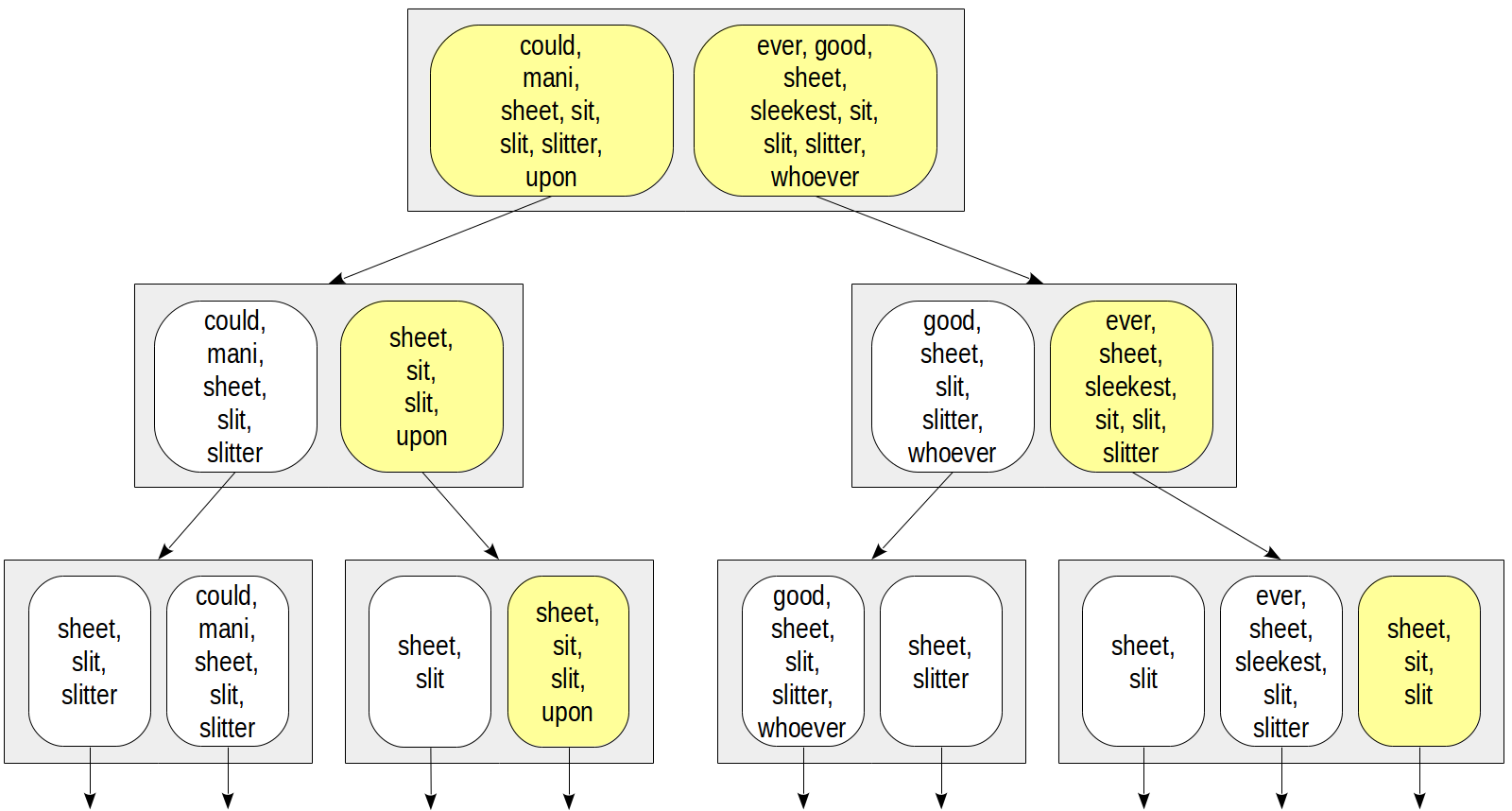
هذا التمثيل لديه قضايا واضحة. يمكن أن يكون عدد الكلمات في المستند كبيرًا جدًا ، لذلك سيكون حجم صفوف الفهرس كبيرًا وسيصل إلى TOAST ، مما يجعل الفهرس أقل كفاءة بكثير. حتى لو كان كل مستند يحتوي على عدد قليل من الكلمات المعجمية الفريدة ، فقد يظل اتحاد المجموعات كبيرًا جدًا: كلما ارتفع مؤشر الفهرس الأكبر إلى الجذر.
يتم استخدام تمثيل مثل هذا في بعض الأحيان ، ولكن لأنواع البيانات الأخرى. ويستخدم البحث عن النص الكامل حلًا آخر أكثر إحكاما ، وهو ما يسمى
شجرة التوقيع . فكرتها مألوفة جدا لجميع الذين تعاملوا مع مرشح بلوم.
يمكن تمثيل كل معجم
بتوقيعه : سلسلة بت ذات طول معين حيث تكون كل البتات باستثناء واحدة. يتم تحديد موضع هذا البت بواسطة قيمة دالة التجزئة في lexeme (ناقشنا الأجزاء الداخلية لوظائف التجزئة
سابقًا ).
توقيع المستند هو bitwise OR للتوقيعات من جميع lexemes المستند.
لنفترض التواقيع التالية من lexemes:
يمكن 1،000،000
من أي وقت مضى 0001000
جيد 0000010
ماني 0000100
ورقة 0000100
أملس 0100000
الجلوس 0010000
شق 0001000
المشقق 0000001
في 0000010
كل من 0010000
ثم تواقيع الوثائق مثل هذه:
يمكن ورقة الشق الشق ورقة؟ 0001101
كم ورقة يمكن شق ورقة شق؟ 1001101
أنا شق ورقة ، أنا شق ورقة. 0001100
على ورقة شق أنا أجلس. 0011110
من شق الأوراق هو شق ورقة جيد. 0011111
أنا المشقق ورقة. 0000101
أنا شق ورقة. 0001100
أنا أكثر أناقة الشق ورقة شقاً من أي وقت مضى. 0101101
انها الشقوق ورقة تجلس عليها. 0011100
يمكن تمثيل شجرة الفهرس على النحو التالي:
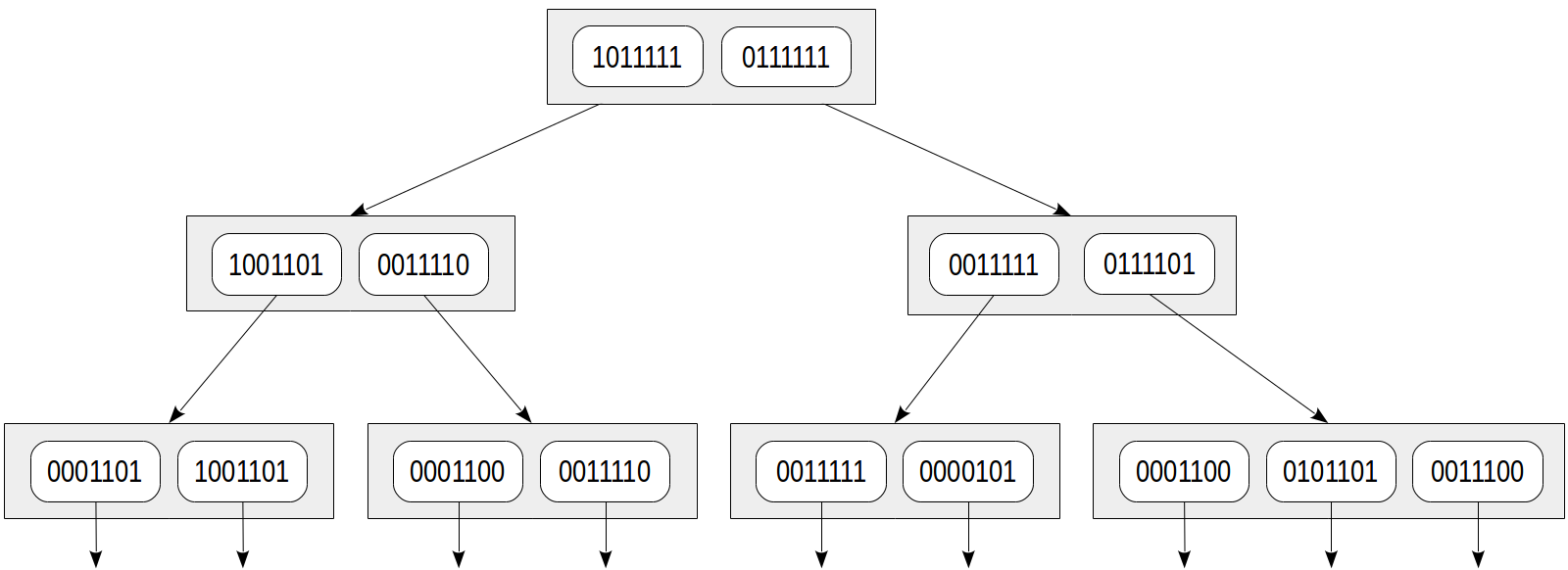
مزايا هذا النهج واضحة: صفوف المؤشر لها أحجام صغيرة متساوية ، وهذا المؤشر مضغوط. لكن العيب واضح أيضًا: يتم التضحية بالدقة من أجل الاكتناز.
دعنا نفكر في نفس الحالة
doc_tsv @@ to_tsquery('sit') . ودعنا نحسب توقيع استعلام البحث بنفس الطريقة بالنسبة للمستند: 0010000 في هذه الحالة. يجب أن تقوم دالة التناسق بإرجاع كافة العقد الفرعية التي تحتوي توقيعاتها على بت واحد على الأقل من توقيع الاستعلام:

قارن مع الشكل أعلاه: يمكننا أن نرى أن الشجرة تحولت إلى اللون الأصفر ، مما يعني حدوث إيجابيات كاذبة وتجاوزت العقد المفرطة أثناء البحث. هنا التقطنا "من" ليكسم ، الذي كان لسوء الحظ نفس توقيع ليكسم. من المهم عدم حدوث أي سلبيات خاطئة في النموذج ، أي أننا على يقين من عدم تفويت القيم المطلوبة.
بالإضافة إلى ذلك ، قد يحدث أن تحصل المستندات المختلفة أيضًا على نفس التواقيع: في المثال الخاص بنا ، المستندات غير المحظوظة هي "لقد قمت بشق ورقة ، وشق أنا شطب" و "أنا شقت ورقة" (وكلاهما يحمل توقيع 0001100). وإذا كان صف فهرس الورقة لا يخزن قيمة "tsvector" ، فإن المؤشر نفسه سوف يعطي إيجابيات خاطئة. بالطبع ، في هذه الحالة ، ستطلب الطريقة من مشغل الفهرسة إعادة فحص النتيجة مع الجدول ، وبالتالي لن يرى المستخدم هذه الإيجابيات الخاطئة. لكن قد تتعرض كفاءة البحث للخطر.
في الواقع ، يكون التوقيع كبيرًا بمقدار 124 بايت في التنفيذ الحالي بدلاً من 7 بتات في الأشكال ، لذلك من غير المحتمل أن تحدث المشكلات المذكورة أعلاه مقارنةً بالمثال. ولكن في الواقع ، يتم فهرسة المزيد من المستندات أيضًا. لتقليل عدد الإيجابيات الخاطئة بطريقة الفهرس بطريقة أو بأخرى ، يصبح التنفيذ صعبًا بعض الشيء: يتم تخزين "tsvector" المفهرسة في صف فهرس الأوراق ، ولكن فقط إذا كان حجمه غير كبير (أقل قليلاً من 1/16 من صفحة ، أي حوالي نصف كيلوبايت لصفحات 8 كيلوبايت).
مثال
لنرى كيف تعمل الفهرسة على البيانات الفعلية ، دعنا نأخذ أرشيف البريد الإلكتروني "pgsql-hackers".
يحتوي الإصدار المستخدم في المثال على 356125 رسالة مع تاريخ الإرسال والموضوع والمؤلف والنص:
fts=# select * from mail_messages order by sent limit 1;
-[ RECORD 1 ]------------------------------------------------------------------------ id | 1572389 parent_id | 1562808 sent | 1997-06-24 11:31:09 subject | Re: [HACKERS] Array bug is still there.... author | "Thomas G. Lockhart" <Thomas.Lockhart@jpl.nasa.gov> body_plain | Andrew Martin wrote: + | > Just run the regression tests on 6.1 and as I suspected the array bug + | > is still there. The regression test passes because the expected output+ | > has been fixed to the *wrong* output. + | + | OK, I think I understand the current array behavior, which is apparently+ | different than the behavior for v1.0x. + ...
إضافة وملء عمود من نوع "tsvector" وبناء الفهرس. سننضم هنا إلى ثلاث قيم في متجه واحد (الموضوع ، المؤلف ، ونص الرسالة) لإظهار أن المستند لا يحتاج إلى حقل واحد ، لكن يمكن أن يتكون من أجزاء تعسفية مختلفة تمامًا.
fts=# alter table mail_messages add column tsv tsvector; fts=# update mail_messages set tsv = to_tsvector(subject||' '||author||' '||body_plain);
NOTICE: word is too long to be indexed DETAIL: Words longer than 2047 characters are ignored. ... UPDATE 356125
fts=# create index on mail_messages using gist(tsv);
كما نرى ، تم إسقاط عدد معين من الكلمات بسبب الحجم الكبير جدًا. ولكن يتم إنشاء الفهرس في النهاية ويمكنه دعم استعلامات البحث:
fts=# explain (analyze, costs off) select * from mail_messages where tsv @@ to_tsquery('magic & value');
QUERY PLAN ---------------------------------------------------------- Index Scan using mail_messages_tsv_idx on mail_messages (actual time=0.998..416.335 rows=898 loops=1) Index Cond: (tsv @@ to_tsquery('magic & value'::text)) Rows Removed by Index Recheck: 7859 Planning time: 0.203 ms Execution time: 416.492 ms (5 rows)
يمكننا أن نرى أنه مع 898 صفًا متطابقًا مع الشرط ، أعادت طريقة الوصول 7859 صفًا إضافيًا تم تصفيتها عن طريق إعادة الفحص باستخدام الجدول. هذا يدل على تأثير سلبي لفقدان الدقة على الكفاءة.
الداخلية
لتحليل محتويات الفهرس ، سنستخدم مرة أخرى ملحق "gevel":
fts=# select level, a from gist_print('mail_messages_tsv_idx') as t(level int, valid bool, a gtsvector) where a is not null;
level | a -------+------------------------------- 1 | 992 true bits, 0 false bits 2 | 988 true bits, 4 false bits 3 | 573 true bits, 419 false bits 4 | 65 unique words 4 | 107 unique words 4 | 64 unique words 4 | 42 unique words ...
قيم النوع المتخصص "gtsvector" المخزّنة في صفوف الفهرس هي في الواقع علامة زائد ، وربما ، مصدر "tsvector". إذا كان المتجه متاحًا ، فإن الإخراج يحتوي على عدد الكلمات (الكلمات الفريدة) ، وإلا ، فإن عدد البتات الصحيحة والخطأ في التوقيع.
من الواضح أنه في العقدة الجذرية ، انحطى التوقيع إلى "الكل" ، أي أن مستوى فهرس واحد أصبح عديم الجدوى على الإطلاق (وأصبح واحد آخر عديم الفائدة تقريبًا ، مع وجود أربعة بتات خاطئة فقط).
خصائص
دعونا نلقي نظرة على خصائص طريقة الوصول إلى GiST (
تم تقديم الاستعلامات مسبقًا):
amname | name | pg_indexam_has_property --------+---------------+------------------------- gist | can_order | f gist | can_unique | f gist | can_multi_col | t gist | can_exclude | t
لا يتم دعم فرز القيم والقيد الفريد. كما رأينا ، يمكن بناء الفهرس على عدة أعمدة واستخدامه في قيود الاستبعاد.
تتوفر خصائص طبقة الفهرس التالية:
name | pg_index_has_property ---------------+----------------------- clusterable | t index_scan | t bitmap_scan | t backward_scan | f
والخواص الأكثر إثارة للاهتمام هي تلك الخاصة بطبقة العمود. بعض الخصائص مستقلة عن فئات المشغلين:
name | pg_index_column_has_property --------------------+------------------------------ asc | f desc | f nulls_first | f nulls_last | f orderable | f search_array | f search_nulls | t
(الفرز غير معتمد ؛ لا يمكن استخدام الفهرس للبحث في صفيف ؛ يتم دعم القيم الخالية).
لكن الخصائص المتبقية اثنين ، "distance_orderable" و "إرجاع" ، سوف تعتمد على فئة المشغل المستخدمة. على سبيل المثال ، بالنسبة للنقاط التي سنحصل عليها:
name | pg_index_column_has_property --------------------+------------------------------ distance_orderable | t returnable | t
تخبر الخاصية الأولى أن المشغل عن بعد متاح للبحث عن أقرب الجيران. ويخبر الثاني أنه يمكن استخدام الفهرس للفحص فقط. على الرغم من أن صفوف فهرس الأوراق تخزن المستطيلات بدلاً من النقاط ، فإن طريقة الوصول يمكنها إرجاع ما هو مطلوب.
فيما يلي خصائص الفواصل الزمنية:
name | pg_index_column_has_property --------------------+------------------------------ distance_orderable | f returnable | t
بالنسبة للفواصل الزمنية ، لم يتم تحديد وظيفة المسافة وبالتالي ، فإن البحث عن أقرب الجيران غير ممكن.
وللبحث عن النص الكامل ، نحصل على:
name | pg_index_column_has_property --------------------+------------------------------ distance_orderable | f returnable | f
تم فقد دعم المسح الضوئي فقط حيث يمكن أن تحتوي صفوف الأوراق على التوقيع فقط بدون البيانات نفسها. ومع ذلك ، فهذه خسارة بسيطة نظرًا لعدم اهتمام أي أحد بقيمة نوع "tsvector" على أي حال: يتم استخدام هذه القيمة لتحديد الصفوف ، في حين أن النص المصدر يجب أن يظهر ، لكنه مفقود من الفهرس على أي حال.
أنواع البيانات الأخرى
أخيرًا ، سوف نذكر بعض الأنواع الأخرى التي يتم دعمها حاليًا بواسطة طريقة الوصول إلى GiST بالإضافة إلى الأنواع الهندسية التي تمت مناقشتها بالفعل (على سبيل المثال من النقاط) والفواصل الزمنية وأنواع البحث عن النص الكامل.
من الأنواع القياسية ، وهذا هو نوع "
آينت " لعناوين IP. تتم إضافة كل الباقي من خلال الامتدادات:
- يوفر cube نوع بيانات "cube" للمكعبات متعددة الأبعاد. بالنسبة لهذا النوع ، كما هو الحال بالنسبة للأنواع الهندسية في المستوى ، يتم تعريف فئة مشغل GiST: R-tree ، البحث الداعم عن أقرب الجيران.
- يوفر seg نوع البيانات "seg" للفواصل الزمنية ذات الحدود المحددة لدقة معينة ويضيف دعمًا لمؤشر GiST لنوع البيانات هذا (R-tree).
- يعمل intraray على توسيع وظائف الصفيف الصحيح ويضيف دعم GiST لهم. يتم تطبيق فئتين من عوامل التشغيل: "gist__int_ops" (شجرة RD مع تمثيل كامل للمفاتيح في صفوف الفهرس) و "gist__bigint_ops" (توقيع RD- شجرة). يمكن استخدام الطبقة الأولى للصفائف الصغيرة ، والثانية - للأحجام الكبيرة.
- يضيف ltree نوع البيانات "ltree" للهياكل الشبيهة بالدعم ودعم GiST لنوع البيانات هذا (RD-tree).
- تضيف pg_trgm فئة المشغلين المتخصصة "gist_trgm_ops" لاستخدام البرامج ثلاثية الأبعاد في البحث عن النص الكامل. ولكن هذا سوف يتم مناقشته أكثر ، مع مؤشر GIN.
اقرأ على .