
تباطأت التحسينات في سرعة وحدة المعالجة المركزية ، ونحن نشهد تحول صناعة أشباه الموصلات إلى بطاقات تسريع بحيث تستمر النتائج في التحسن بشكل ملحوظ. لقد استفادت Nvidia أكثر من هذا الانتقال ، ومع ذلك ، فهي جزء من نفس الاتجاه ، تغذي البحث في مسرعات الشبكات العصبية ، و FPGA ، ومنتجات مثل TPUs من Google. لقد أدت هذه المعجلات إلى زيادة سرعة الإلكترونيات بشكل لا يصدق في السنوات الأخيرة ، وبدأ الكثيرون يأملون في أن يمثلوا طريقًا جديدًا للتنمية ، فيما يتعلق بتباطؤ قانون مور. لكن العمل العلمي الجديد يشير إلى أن كل شيء في الواقع ليس وردياً كما يود البعض.
لا تزال الهياكل الخاصة مثل GPUs و TPUs و FPGAs و ASIC ، حتى لو كانت تعمل بشكل مختلف تمامًا عن وحدات المعالجة المركزية للأغراض العامة ، تستخدم نفس العقد الوظيفية مثل معالجات x86 أو ARM أو POWER. وهذا يعني أن الزيادة في سرعة هذه المعجلات تعتمد إلى حد ما على التحسينات المرتبطة بتدريج الترانزستورات. ولكن ما هي نسبة هذه التحسينات التي تعتمد على تحسين تقنيات الإنتاج والزيادة في الكثافة المرتبطة بقانون مور ، وأي جزء من التحسينات في المجالات المستهدفة التي تهدف هذه المعالجات لها؟ ما هي النسبة المئوية للتحسينات التي تتعلق فقط الترانزستورات؟
ابتكر ديفيد وينزلاف ، أستاذ مشارك في الهندسة الكهربائية بجامعة برينستون وطالب الدراسات العليا عدي فوشز ، نموذجًا يتيح لهم قياس سرعة التحسن. يستخدم طرازهم خصائص 1612 وحدة المعالجة المركزية و 1001 وحدة معالجة الرسومات ذات السعات المختلفة ، المصنوعة على أساس وحدات وظيفية مختلفة ، لتقييم عددي الفوائد المرتبطة التحسينات على الوحدات. قام كل من Wenzlaf و Fuchs بإنشاء
مقياس لتحسين الأداء المتعلق بتقدم CMOS (CMOS) ، والذي يمكن مقارنته بالتحسينات التي تم الحصول عليها من خلال إرجاع التخصص في الرقاقة (CSR).
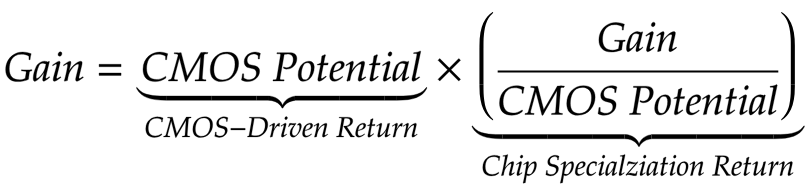
جاء الفريق إلى نتيجة مشجعة. ترتبط المزايا التي تم الحصول عليها بسبب تخصص الرقائق بشكل أساسي بعدد الترانزستورات الموضوعة في ملليمتر من السيليكون على المدى الطويل ، وكذلك تحسينات هذه الترانزستورات المرتبطة بكل وحدة وظيفية جديدة. الأسوأ من ذلك ، هناك قيود أساسية على مقدار السرعة التي يمكننا استخراجها من تحسين دائرة التسريع دون تحسين مقياس CMOS.
من المهم أن يتم تطبيق كل ما سبق على المدى الطويل. أظهرت دراسة أجرتها Wenzlaf و Fuchs أن السرعة غالباً ما تزيد بشكل كبير عندما يتم تشغيل المعجلات لأول مرة. بمرور الوقت ، عندما تتضح طرق التسريع المثلى ، ويوصف أفضل الممارسات ، يأتي الباحثون إلى الطريقة المثلى. علاوة على ذلك ، في المسرعات ، يتم حل المهام المحددة جيدًا من منطقة مدروسة جيدًا يمكن موازنتها (GPU). ومع ذلك ، فإن هذا يعني أيضًا أن نفس الخصائص ، والتي يمكن من خلالها تكييف المهمة من أجل المعجلات ، تحد من الميزة المكتسبة من هذا التسارع على المدى الطويل. ودعا الفريق هذه المشكلة "مسرعات الجمود".
وربما شعرت سوق الحوسبة عالية الأداء بهذا لبعض الوقت. في عام 2013 ، كتبنا عن
الطريق الصعب إلى أجهزة الكمبيوتر العملاقة السابقة. وحتى مع ذلك ، توقعت Top500 أن تسرع المسرعات قفزة لمرة واحدة في تصنيفات الأداء ، ولكنها لن تزيد من سرعة زيادة السرعة.

ومع ذلك ، فإن عواقب هذه الاكتشافات تتجاوز سوق الحوسبة عالية الأداء. على سبيل المثال ، بعد دراسة GPU ، وجد Wenzlaf و Fuchs أن الفوائد التي لا يمكن عزوها إلى تحسين CMOS كانت صغيرة جدًا.
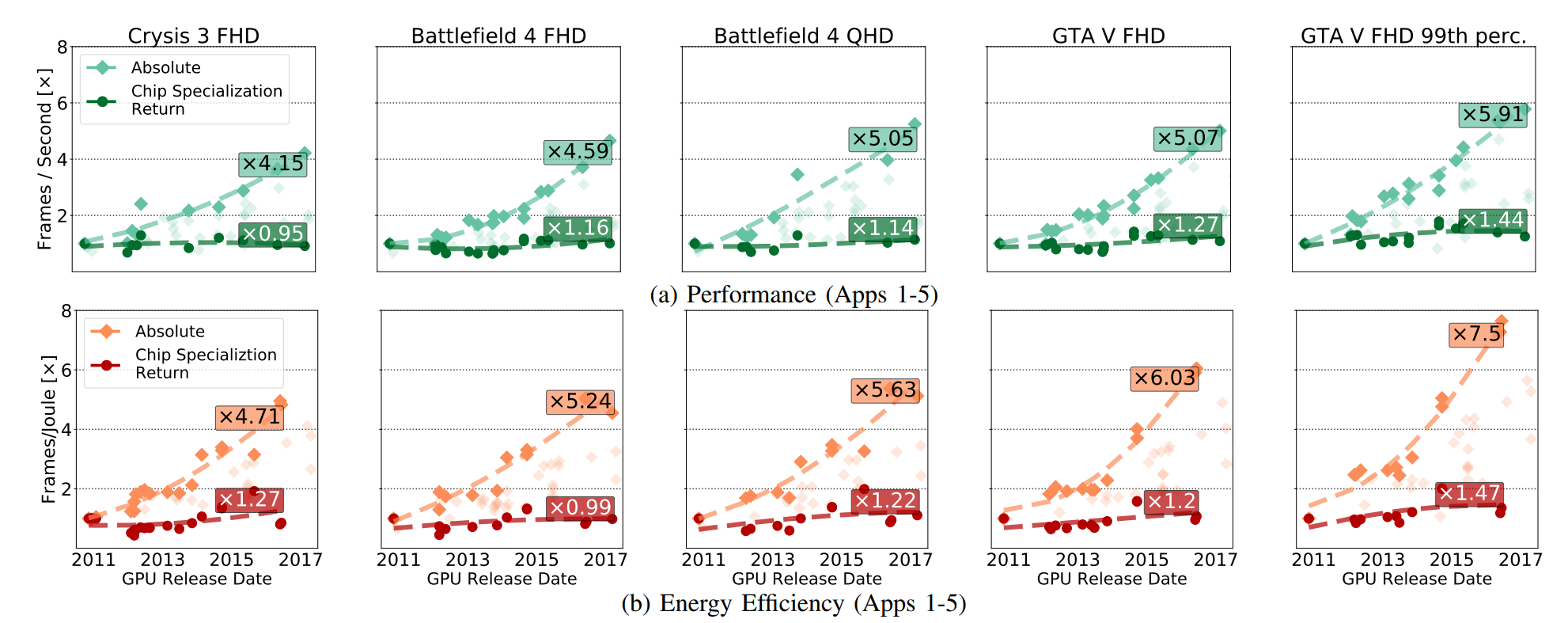
في التين. لقد تم عرض النمو المطلق لأداء GPU (بما في ذلك الفوائد المكتسبة من تطوير CMOS) ، وقد ظهرت هذه الفوائد فقط من تطوير المسؤولية الاجتماعية للشركات. تتعلق CSRs بالتحسينات المتبقية إذا قمت بإزالة كافة الاختراقات في تقنية CMOS من دائرة GPU.
يوضح الشكل التالي علاقة الكميات:
إن تخفيض المسؤولية الاجتماعية للشركات لا يعني إبطاء وحدة معالجة الرسومات بالأرقام المطلقة. كما كتب فوكس:
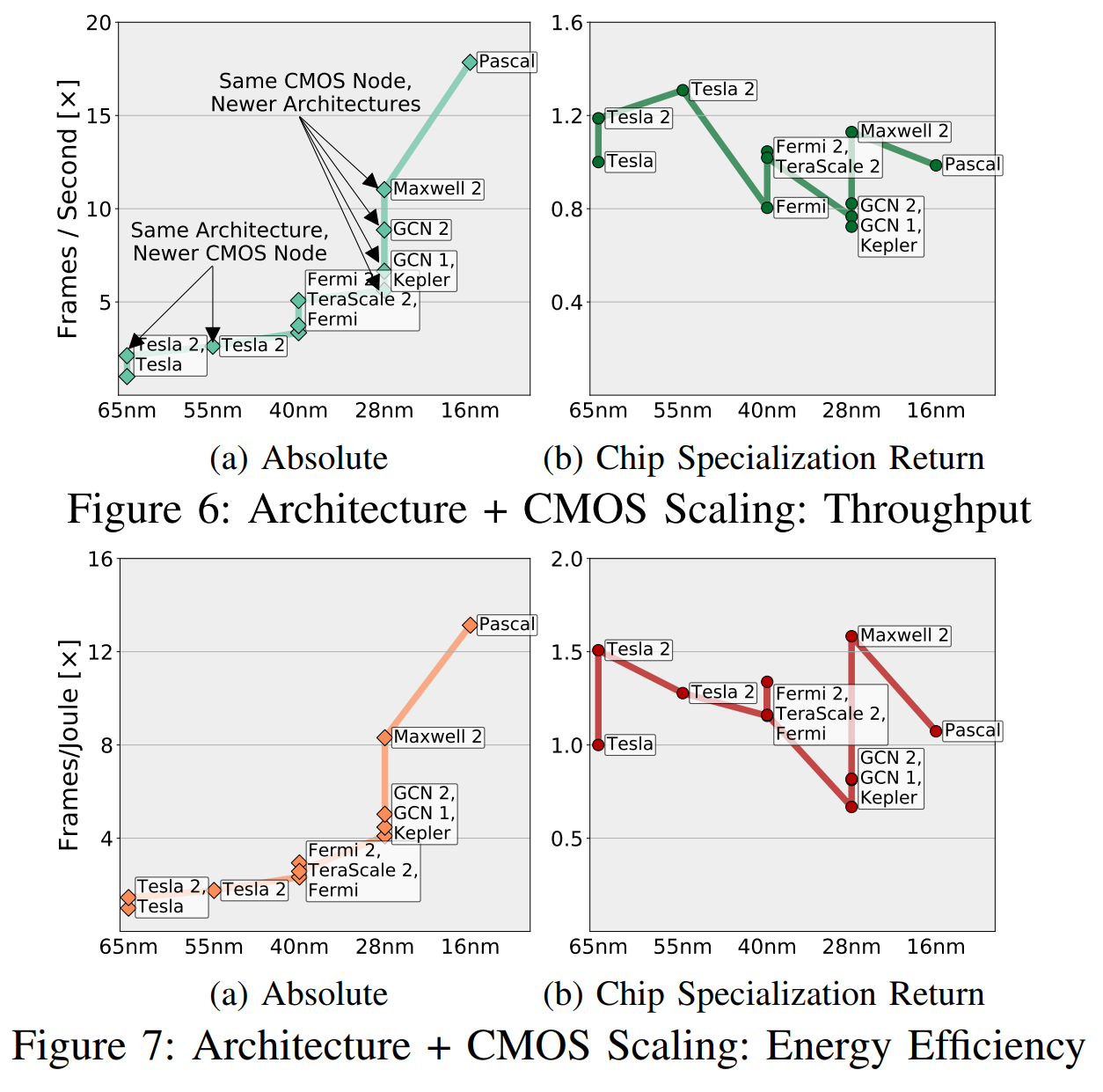
المسؤولية الاجتماعية للشركات تطبيع الربح "بناءً على إمكانات CMOS" ، وهذه "المحتملة" تأخذ في الاعتبار عدد الترانزستورات والفرق في السرعة والكفاءة في استخدام الطاقة ، والمنطقة ، إلخ. (في أجيال مختلفة من CMOS). في التين. 6 ، قدمنا مقارنة تقريبية لمجموعات "architecture + CMOS" ، من خلال تثليث السرعات المقاسة لجميع التطبيقات على توليفات مختلفة ، وباستخدام علاقات متعدية بين تلك المجموعات التي ليس لديها تطبيقات مشتركة كافية (أقل من خمسة).
حدسي ، يمكن فهم هذه الرسوم البيانية كما في الشكل. يوضح الشكل 6 أ ما يراه المهندسون والمديرون والتين. 6b هو "ما نراه ، باستثناء إمكانات CMOS." سأغامر بالاقتراح بأنك مهتم أكثر بما إذا كانت الشريحة الجديدة أعلى من الشريحة السابقة مما إذا كانت تفعل ذلك بسبب ترانزستورات أفضل أو بسبب تخصص أفضل.
إن سوق GPU مُعرَّف جيدًا ومصمم ومتخصص ، ولكل من AMD و Nvidia كل الأسباب للتقدم في تحسين الدوائر. ولكن على الرغم من ذلك ، نرى أن التسارع يرجع في معظمه إلى عوامل متعلقة بـ CMOS ، وليس بسبب CSR.
درس العلماء أيضًا FPGAs واللوحات الأم الخاصة لمعالجة برامج ترميز الفيديو التي تندرج تحت هذه الخصائص ، حتى لو أصبح التحسن النسبي بمرور الوقت أكثر أو أقل بسبب السوق المتنامية. نفس الخصائص التي تسمح لك بالاستجابة الفعالة للتسارع ، تحد في النهاية من قدرة المعجلات على تحسين كفاءتها. يكتب Fuchs و Wenzlaf عن GPU: "على الرغم من أن معدل الإطارات لرسومات GPU قد زاد بنسبة 16 مرة ، إلا أننا نفترض أن المزيد من التحسينات في السرعة وكفاءة الطاقة ستتبع 1.4 إلى 2.4 مرة و1.4 إلى 1.7 مرة على التوالي" . لا تملك AMD و Nvidia مساحة خاصة للمناورة حيث يمكنك زيادة السرعة من خلال تحسين CMOS.
الآثار المترتبة على هذا العمل مهمة. وهي تقول إن مجالات الهندسة المعمارية الخاصة بها لن تقدم تحسينات كبيرة في السرعة عندما يتوقف قانون مور عن العمل. وحتى إذا كان بإمكان مصممي الرقائق التركيز على تحسين الأداء في عدد ثابت من الترانزستورات ، فستكون هذه التحسينات مقيدة بحقيقة أن العمليات المدروسة جيدًا ليس لديها أي مكان للتحسين.
يشير العمل إلى الحاجة إلى تطوير نهج جديد بشكل أساسي للحوسبة. أحد البدائل المحتملة هو
بنية Intel Meso .
اقترح Fuchs و Wenzlaf أيضًا استخدام مواد بديلة وغيرها من الحلول التي تتجاوز نطاق CMOS ، بما في ذلك البحث في إمكانية استخدام الذاكرة غير المتطايرة كمسرعات.