لدى Yandex خدمة تطوير مكونات البحث التي تبني قاعدة بحث على MapReduce ، وتوفر بيانات عن التنضيد لتقديمها ، وتُنشئ الخوارزميات وهياكل البيانات ، وتحل مهام ML الخاصة بنمو الجودة. يشرح Alexey Shlyunkin ، رئيس إحدى المجموعات داخل هذه الخدمة ، ماهية وقت تشغيل البحث وكيفية إدارته.
تريد أن تتلوى في ML - كزة حولها. تريد فقط MapReduce - حسنا. نريد وقت التشغيل - وقت التشغيل.
- ما هو البحث اليوم؟ بدأت ياندكس بالبحث وتطويره. لقد مرت 20 سنة. لدينا قاعدة بحث لمئات المليارات من الوثائق.
نحن نسمي وثيقة أي صفحة على الإنترنت ، ولكن في الواقع ، ليس فقط. لا يزال - محتوياته ، إحصائيات مختلفة حول المستخدمين الذين يحبون الذهاب إليها ، وكم منهم. بالإضافة إلى البيانات التي حسبناها.
إنها أيضًا عشرات الآلاف من الحالات التي ، استجابة لكل طلب ، تقوم بمعالجة البيانات ، والبحث عن شيء ما ، وإثراء استجابة البحث. تبحث بعض الحالات عن الصور ، والبعض الآخر عن المستندات النصية العادية ، والبعض الآخر للفيديو ، إلخ. أي ، يتم تنشيط عشرات الآلاف من الأجهزة لكل طلب. يحاولون جميعًا العثور على شيء وتحسين النتيجة التي تظهر لك. وفقًا لذلك ، تقدم عشرات الآلاف من الآلات آلاف الطلبات في الثانية. يتم دمج عشرات الآلاف من الحالات في مئات الخدمات المصممة لحل المشكلة.

هناك جوهر البحث - خدمة البحث على شبكة الإنترنت. وهناك خدمة بحث فيديو ، إلخ. وفقًا لذلك ، هناك شيء يجمع بين إجابات عمليات البحث المختلفة ويحاول اختيار ما وبأية ترتيب من الأفضل إظهار المستخدم. إذا كان هذا طلبًا ما حول الموسيقى ، فمن الأفضل عرض Yandex.Music أولاً ، ثم ، على سبيل المثال ، صفحة حول هذه المجموعة الموسيقية. وهذا ما يسمى الخلاط. هناك بالفعل مئات من هذه الخدمات ، كما أنها تفعل شيئًا لكل طلب وتحاول مساعدة المستخدمين بطريقة أو بأخرى. وبالطبع ، كل هذا يستخدم التعلم الآلي لجميع الأنواع فقط ، من بعض الإحصاءات البسيطة ، النماذج الخطية ، إلى التدرجات المتدرجة ، الشبكات العصبية وما إلى ذلك.
سأتحدث عن البنية التحتية و ML في الوقت الحالي.
تسمى مجموعتي مجموعة تطوير وقت التشغيل الجديدة ، وهي جزء من خدمة تطوير مكون البحث. بحيث يكون لديك فكرة ، سوف أخبرك قليلاً بما تفعله خدمتنا.

في الواقع ، للجميع. إذا قمت بتقديم بحث ، فقمنا بأيدينا تقريبًا في كل شيء تقريبًا ، بدءًا من بناء قاعدة بحث. بمعنى ، لدينا MapReduce ، نجمع كل البيانات حول المستندات هناك ، ونغليها ، ونبني جميع أنواع هياكل البيانات ، بحيث عندما نطلب منها ، يمكننا حساب شيء ما بكفاءة. وفقًا لذلك ، نحن نعمل من الأسفل عندما تصل إلينا الوثيقة فقط ، من المرحلة الأولى ، عندما تحصل هذه المستندات على شيء وترتيبها ، وإلى الأعلى ، حيث يستقبل التخطيط JSON الشرطي ويرسمه بكل الصور والأشياء الجميلة. من الأسفل إلى الأعلى ، نقوم بتطوير شيء ما على المكدس بالكامل.
لكننا لا نكتب الرمز فحسب ، وبالتالي نقوم بكل هذا في البنية التحتية. نحن في الواقع تدريب الشبكات العصبية ، CatBoost. وغيرها من الأشياء التي يمكنك تخيلها وحرقها ، نعلمها أيضًا. أيضًا ، نظرًا لأن لدينا كميات كبيرة وبيانات كبيرة ، فإننا ، بالطبع ، نتفحص الخوارزميات وهياكل البيانات ولا نمنع أنفسنا من تقديمها في مكان ما. على سبيل المثال ، في العديد من الأماكن نستخدم أشجار قطعة. لدينا ضغطنا الخاص للمؤشرات التي تبني البورون ووفقًا لذلك ، عليك التفكير في ديناميكيات أفضل طريقة لبناء القواميس.
بشكل عام ، في التعامل مع مثل هذا العملاق الكبير كبحث ، كنا مشبعين بمثل هذه المهام البسيطة. لذلك ، بالطبع ، نحن نعشق شيئًا معقدًا ، جديدًا ، شيئًا يتحدىنا. ولم نذهب ونكتب ، كالعادة ، عشرة سطور من الكود. نحن بحاجة إلى التفكير في بعض التجارب. بشكل عام ، فإن المهام التي وضعناها لأنفسنا غالبًا ما تكون على وشك الخيال. في بعض الأحيان تفكر: ربما لا يكون ذلك ممكنًا. ولكن بعد ذلك ، ربما ، لقد جربت بطريقة ما - يمكن أن تستغرق التجارب عامًا كاملاً - ولكن في النهاية ، يظهر شيء ما. ثم نبدأ في تقديم شيء جديد.
وإلى جانب أي مشاريع ، ومهارات ، وما إلى ذلك ، بشكل عام ، نحن واحدة من أكثر الفرق طموحًا وسرعة النمو في ياندكس. على سبيل المثال ، لقد جئت قبل عامين ، وكان الشخص التاسع في خدمتنا. الآن لدينا خدمة ما يقرب من 60 شخصا. هذا ، في الواقع ، مع المتدربين ، ولكن بشكل عام ، نمت أربع مرات بالضبط في غضون عامين. هذا هو إعطائك فكرة عما تقوم به خدمتنا.
الآن أريد أن أخبركم قليلاً عن الجزء العلوي حول مهامنا والاتجاه الذي يبدو لي أنه في المستقبل القريب سوف نكون أكثر أهمية. ولكن لهذا ، يجب أولاً أن تصف بإيجاز كيف تعمل طبقة البحث الأساسية.
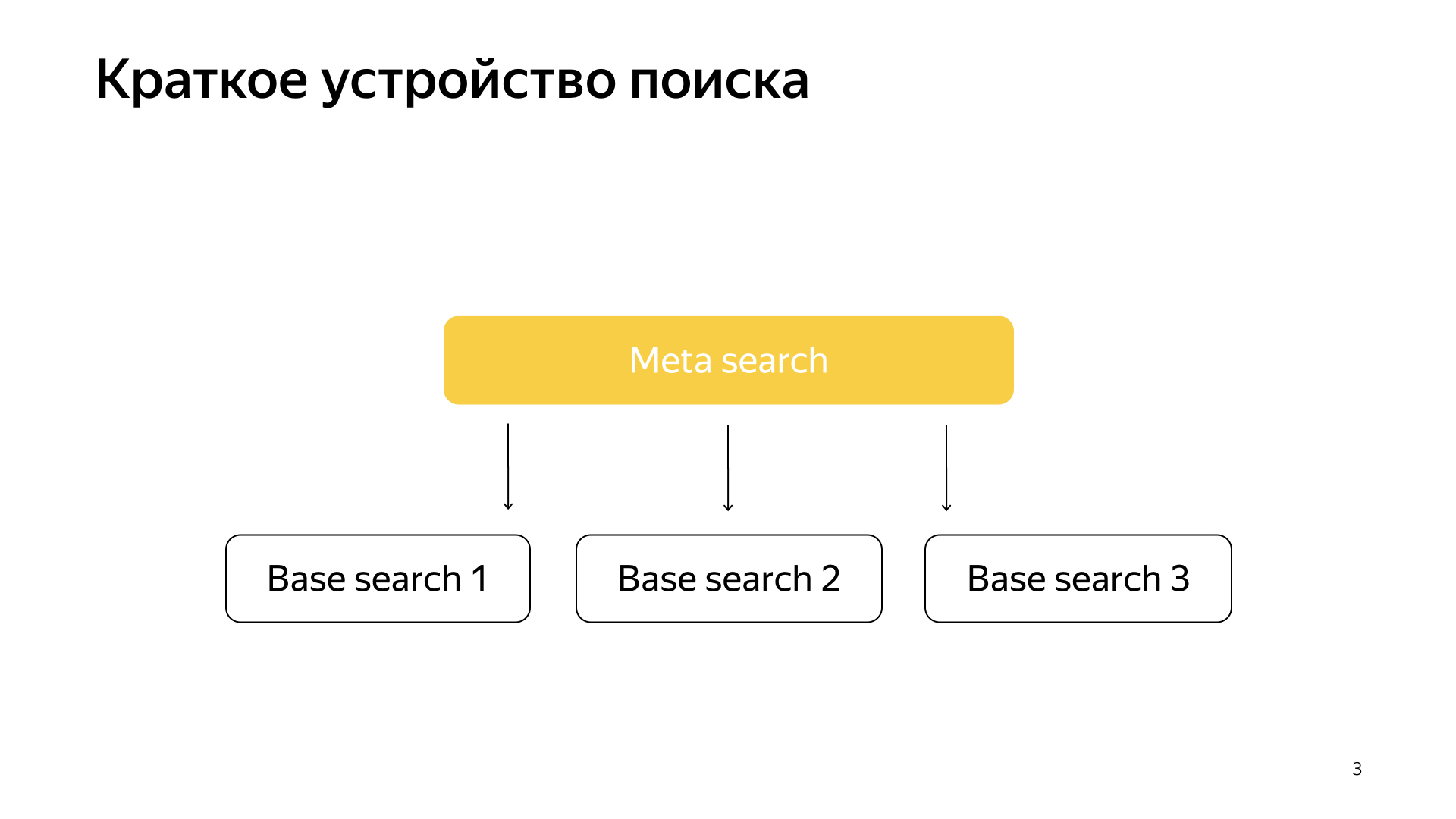
بشكل عام ، كل شيء يعمل بكل بساطة. لدينا قاعدة البحث لدينا ، لدينا جميع الوثائق ، ونحن نقسم كل هذه الوثائق بشكل أو بآخر بالتساوي إلى أجزاء N. يطلق عليهم شظايا. ويتم إطلاق برنامج يسمى "البحث الأساسي" على القشرة. وتتمثل مهمتها في البحث ، بناءً على ذلك ، على هذا الجزء من الإنترنت. أي أنها تعرف كيفية البحث عنها ولا تعرف أكثر عن الإنترنت الآخر. ولدينا شظايا N مثل هذا. يتم إجراء عمليات البحث الأساسية فوقها ، وبالتالي ، هناك بحث تعريف حول هذا. يقع طلب المستخدم فيه ، وبالتالي ، يذهب ببساطة إلى كل القطع ، ويقوم كل سهم بإجراء بحث ، ثم يعرض كل نتيجة ، ويقوم بإجراء نوع من الدمج ويعطي إجابة.
هكذا تم ترتيب عملية البحث لمدة 20 عامًا تقريبًا ، وبشكل عام ، اعتقدوا لفترة طويلة أن هذا سيظل كذلك ، ولا يمكن القيام بأي شيء أفضل. ولكن كل شيء يتغير ، والتقنيات الجديدة آخذة في الظهور ، والتعلم الآلي الآن لا يسمح لك فقط بزيادة الجودة ، ولكن يسمح لك أيضًا بحل نوع من مشاكل البنية الأساسية. في الآونة الأخيرة ، في بحثنا ، تم إطلاق النار على المشاريع كثيرًا ، عند تقاطع البنية الأساسية والتعلم الآلي. عند دمج اثنين من هذه الصناديق ، يتم الحصول على نتائج ممتعة للغاية.

في الآونة الأخيرة ، ظهرت الشبكات العصبية. لدينا نص الطلب ، هناك نص المستند. نرغب في الحصول على بعض متجه الأرقام من الطلب ، للحصول على متجه للأرقام من المستند حتى يتنبأ المنتج العددي بالقيمة التي نريدها. على سبيل المثال ، نريد تدريب المنتج القياسي للتنبؤ باحتمال قيام أحد المستخدمين بالنقر فوق هذا المستند. شيء مفهوم تماما.
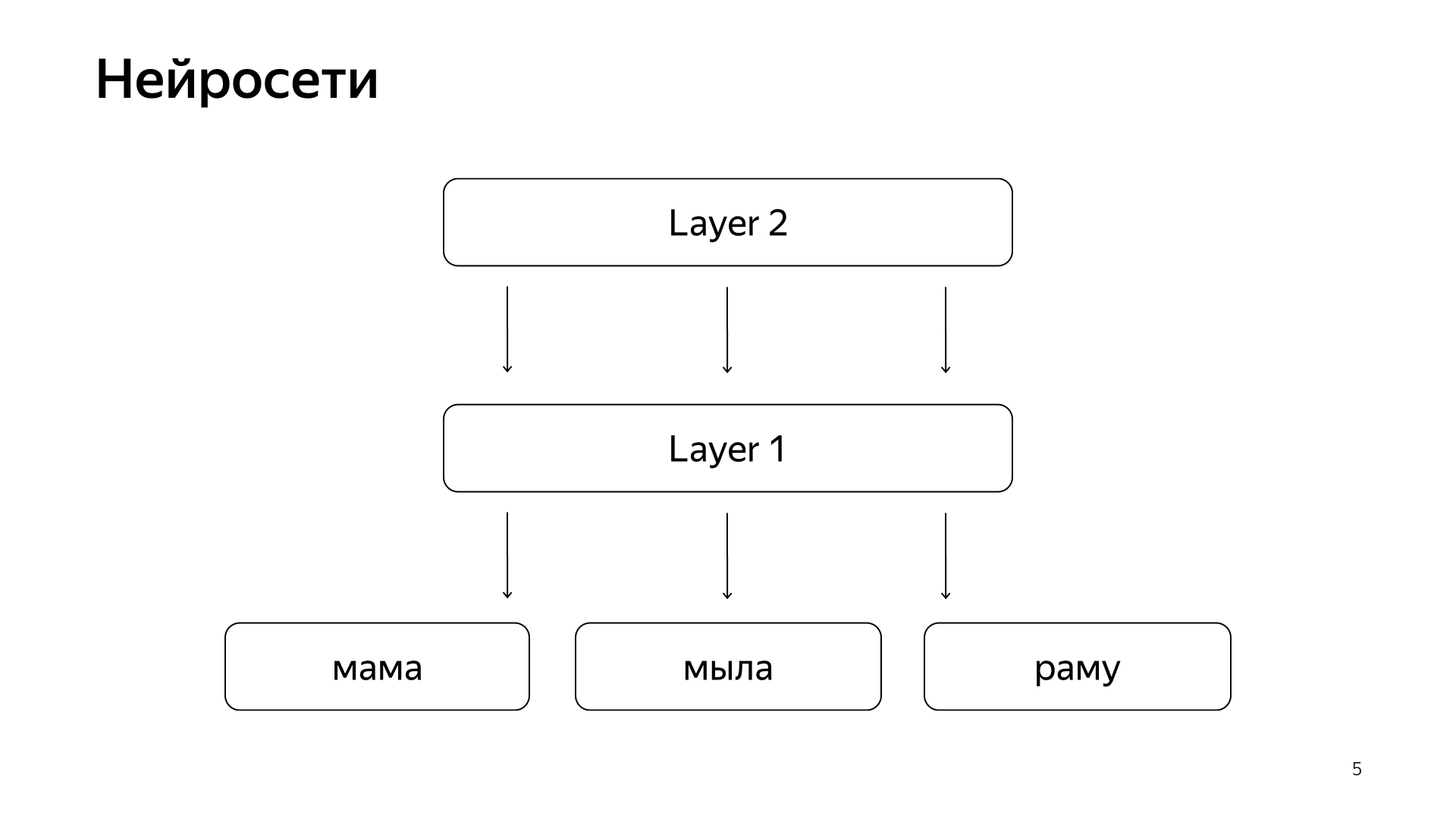
يتم ترتيبها تقريبا مثل هذا. إذا كانت وقحة جدًا ، فحينئذٍ لدينا بعض الكلمات في الطبقة السفلية ، ثم هناك عدة طبقات من الشبكة. في الواقع ، تأخذ كل طبقة المتجه كمدخلات. أي أن الطبقة السفلية عبارة عن ناقل متفرق ، حيث تكون كل كلمة طلبًا. تضربها بمصفوفة ، وتحصل على نوع من المتجهات ، ومن ثم ، تطبق بعض اللاخطية على كل مكون ، وتقوم بذلك عدة مرات. والطبقة الأخيرة ، تسمى هذه فقط المتجه الذي أخذناه للتو ، وطبقت هذه الطبقات ، وهنا الطبقة الأخيرة هي متجه الطلب ذاته.
وفقا لذلك ، تم إدخال هذه الشبكات العصبية بنشاط في البحث في السنوات الأخيرة ، وجلبت الكثير من الفوائد للجودة. لكن لديهم مشكلة واحدة وهي أن جميع الكميات التي نريد أن نتنبأ بها جيدة ، لكنها تقريبية بما يكفي ، لأنه لتدريب هذه الشبكة العصبية ، تكون الطبقة السفلية كبيرة جدًا - كل الكلمات من عشرات الملايين من الكلمات ، لذلك يجب أن تكون قادرًا على الكتابة لها إدخال عدة مليارات البيانات.
على سبيل المثال ، يمكننا تدريب بعض نقرات المستخدمين وما إلى ذلك. لكن الإشارة الرئيسية التي تعتبر الأكثر أهمية في بحثنا هي العلامات اليدوية من قبل الأشخاص الخاصين. يأخذون الطلب ويأخذون المستند ويقرأوه ويفهمون مدى جودته ويضعون علامة ، أي مقدار هذا المستند الذي يناسب هذا الطلب. لفترة طويلة ، لم نتمكن من التنبؤ بهذه الضخامة من قبل الشبكات العصبية ، لأنه لا يزال لدينا بعض الملايين من التقديرات ، لأن استئجار الكوكب بأسره لوضع علامة عليه باستمرار أمر مكلف للغاية. لذلك ، قدمنا بعض الاختراق.
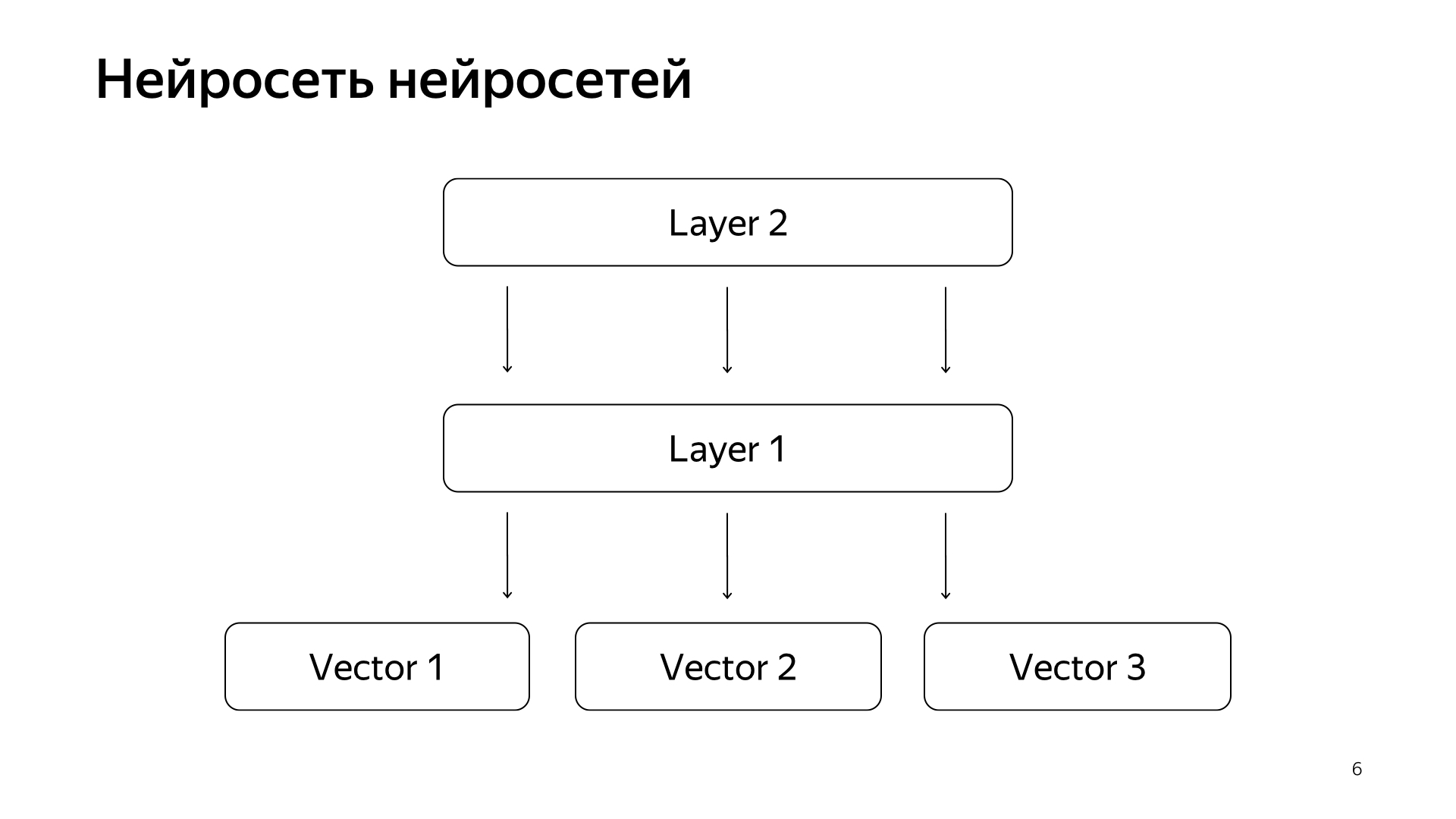
الشبكة العصبية للشبكات العصبية. على مدار السنوات الماضية ، جمعنا الكثير من الشبكات العصبية التي تتنبأ بالإشارات الجيدة ، ولكن أقسى قليلاً من تقييم الأشخاص الخاصين. وفقًا لذلك ، قررنا أن نرسل الموجهات الجاهزة لهذه الشبكات إلى الطبقة السفلى ، ومن ثم سنقوم بتدريب الشبكة العصبية للتنبؤ بأهمية بحثنا على شبكة البيانات الأصغر فقط.
وكانت النتيجة نموذج جيد للغاية. إنها تنقل طلبات المستندات إلى متجه ، ويتوقع منتجها القياسي مباشرة الأهمية الحقيقية التي طالما أردنا التنبؤ بها.
علاوة على ذلك ، كان لدينا فكرة عن كيفية إعادة البحث قليلاً. يُطلق على المشروع قاعدة KNN (طريقة الجيران الإنجليزية k-kest ، طريقة الجوار k -est).

الفكرة الأساسية هي هذا. لدينا متجه الاستعلام ومتجه الوثيقة. نحن بحاجة للعثور على أقرب واحد. لدينا كل وثيقة يمثلها ناقل. دعنا نسلط الضوء على مجموعات N ، تلك التي تميز مساحة الوثيقة بأكملها. تحدث تقريبا. أصغر بقوة من عدد الوثائق ، ولكن على سبيل المثال ، فإنها تميز الموضوعات. بعبارات بسيطة ، هناك مجموعة من القطط ومجموعة من محلات البقالة ومجموعة من البرمجة وما إلى ذلك.
بناءً على ذلك ، لن نوزع المستندات بشكل عشوائي على شكل شظايا ، كما كان من قبل ، ولكننا سنضع المستند في تلك القطعة ، أي أن النقطة الوسطى هي الأقرب إلى المستند. وفقًا لذلك ، سيكون لدينا مثل هذه الوثائق مجمعة حسب الموضوع على شكل قشرة.
وعلاوة على ذلك ، فقط لطلب ، الآن لا يمكننا الذهاب إلى جميع القطع ، ولكن فقط للذهاب إلى مجموعة فرعية صغيرة من أولئك الأقرب إلى هذا الطلب.
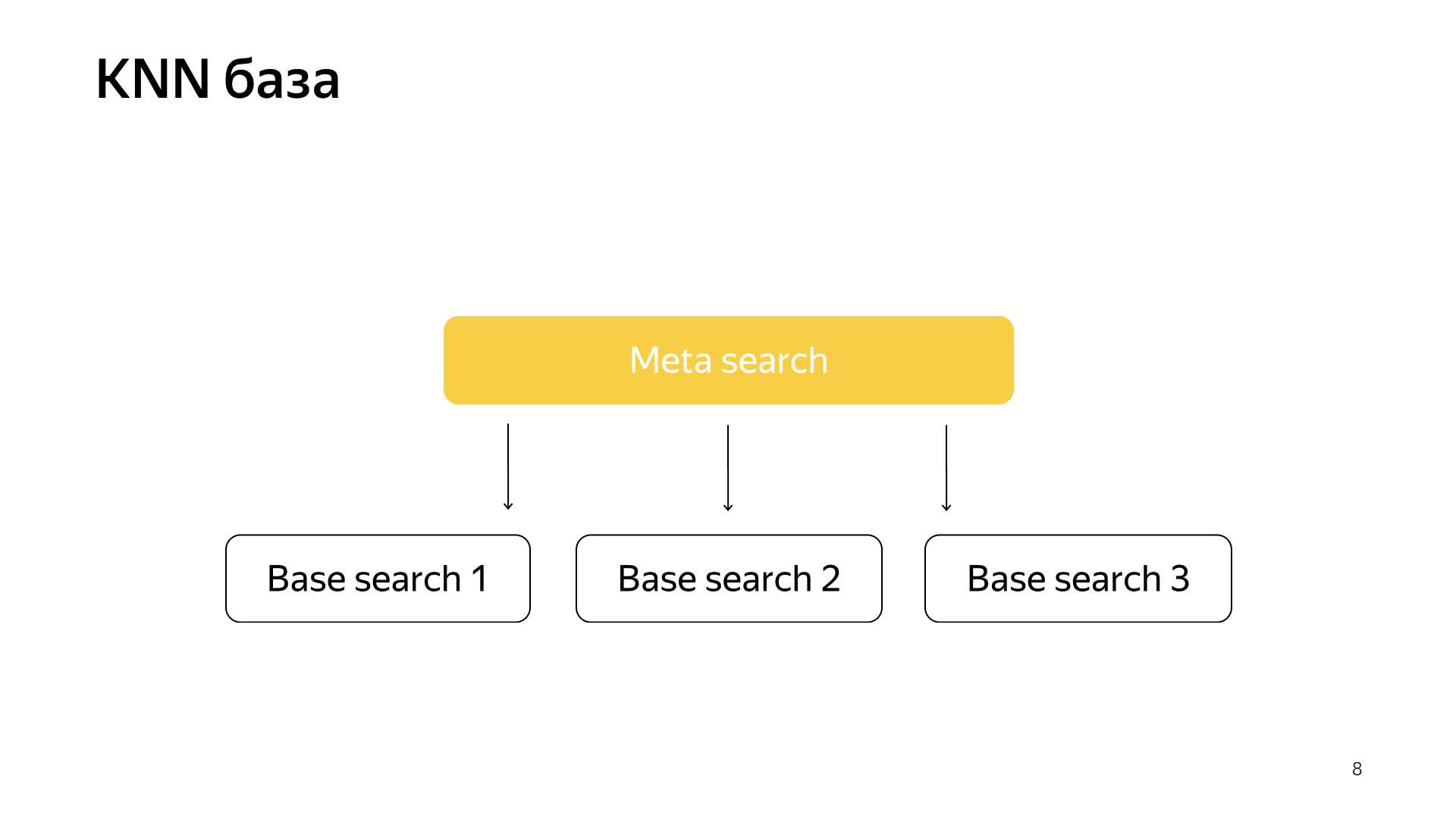
وفقا لذلك ، كان لدينا مثل هذا المخطط ، يتم تضمين البحث التلوي في جميع القطع. والآن يحتاج إلى الانتقال إلى رقم أصغر بكثير ، وفي نفس الوقت سنظل نبحث عن أقرب المستندات.
ما الذي نحصل عليه بالفعل من هذا التصميم؟ إنه يقلل بشكل كبير من استهلاك موارد الحوسبة ، وذلك ببساطة لأننا نذهب إلى مجموعات أقل. هذا ، كما قلت بالفعل ، أنا أعتبر واحدة من أبرز خدماتنا ، هذه هي سبيكة البنية التحتية والتعلم الآلي الذي يعطي مثل هذه النتائج التي لا يمكن لأحد التفكير فيها من قبل.

وفي النهاية ، إنه أمر مضحك تمامًا ، لأنك حصلت على النماذج هنا ، ثم ذهبت ، وأعدت البحث بالكامل ، وأوقفت وحدات البايت بايت من البيانات ، وأعمال البحث ، فهي تحرق موارد أقل بعشرة أضعاف. لقد وفرت مليار دولار للشركة ، الجميع سعداء.

تحدثت عن أحد المشاريع التي تظهر في بحثنا والتي يتم تنفيذها وتنفيذها مع جميع التجارب لمدة عام مع وقف التنفيذ. تتمثل مهامنا النموذجية الأخرى في مضاعفة قاعدة البحث ، لأن الإنترنت ينمو باستمرار ونريد اللحاق به والبحث في جميع الصفحات على الإنترنت. وبالطبع ، هذا هو تسارع الطبقة الأساسية ، حيث توجد معظم الحالات ، معظمها من الحديد. على سبيل المثال ، تسريع عملية البحث الأساسية بنسبة واحد في المائة يعني توفير حوالي مليون دولار.
ونحن نشارك أيضا في البحث كحاضنة بدء التشغيل. ساوضح. تم البحث لمدة 20 عامًا. لقد فعلت الكثير من الأشياء بالفعل ، وفي كثير من الأحيان صعدنا إلى طريق مسدود ، واعتقدنا أنه لا يمكن فعل المزيد. ثم كانت هناك سلسلة طويلة من التجارب. لقد كسرنا مرة أخرى هذا الطريق المسدود. وخلال هذا الوقت تراكمت لدينا الكثير من الخبرة في كيفية القيام بأشياء كبيرة وباردة. وفقًا لذلك ، فإن معظم الاتجاهات الجديدة في Yandex تتم في البحث ، لأن الأشخاص في البحث يعرفون بالفعل كيفية القيام بكل هذا ، ومن المنطقي أن يطلب منهم تصميم نظام جديد على الأقل. وكحد أقصى - اذهب وافعل ذلك بنفسك.
الآن ، آمل أن يكون لديك فكرة صغيرة عن عملنا. سأحكي بسرعة الجزء الموضوعي من قصتي حول المتدربين في خدمتنا. نحن نحبهم كثيرا لدينا الكثير منهم ، في الصيف الماضي فقط في مجموعتي كان هناك 20 متدربًا ، وأعتقد أن هذا جيد. عندما تأخذ واحدًا أو ثلاثة من المتدربين ، يشعرون بالوحدة قليلاً ، وأحيانًا يخشون أن يطلبوا من الرفاق الأكبر سنًا. وعندما يكون هناك الكثير منهم ، يتواصلون مع بعضهم البعض كرفاق في محنة. إذا كانوا يخشون أن يسألوا المطورين شيئًا ما ، فسوف يذهبون ، وسوف يهمسون في الزاوية. مثل هذا الجو يساعد على فعل كل شيء بكفاءة.
لدينا مليون مهمة ، والفريق ليس كبيرًا جدًا ، لذلك يتم تدريب المتدربين لدينا بالكامل. لا نطلب من المتدرب الجلوس في السجل طوال الوقت ، وكتابة الاختبارات ، وإعادة تشكيل الكود ، ولكن على الفور إعطاء نوع من مهمة الإنتاج المعقدة: تسريع البحث ، وتحسين ضغط الفهرس. بالطبع نحن نساعد. نحن نعلم أن هذا كله يؤتي ثماره ، لذلك نحن سعداء لتبادل خبرتنا. نظرًا لأن مجال نشاطنا واسع جدًا ، سيجد كل واحد منا مهمة تروق له. تريد أن تتلوى في ML - كزة حولها. تريد فقط MapReduce - حسنا. نريد وقت التشغيل - وقت التشغيل. يوجد شيء
ماذا تحتاج للوصول إلينا؟ نحن نفعل كل شيء بشكل رئيسي في C ++ و Python. ليس من الضروري معرفة الاثنين معا ، يمكن للمرء معرفة شيء واحد. نحن نرحب بمعرفة الخوارزميات. إنه يشكل نمطًا معينًا من التفكير ، ويساعد كثيرًا. لكن هذا ليس ضروريًا أيضًا: مرة أخرى ، نحن على استعداد لتدريس كل شيء ، ونحن على استعداد لاستثمار وقتنا ، لأننا نعلم أن ذلك يؤتي ثماره. الشرط الأكثر أهمية الذي نصنعه ، شعارنا ، هو ألا نخاف من أي شيء والكثير من الشخصيات. لا تخف من انخفاض الإنتاج ، فلا تخف من البدء في القيام بشيء معقد. لذلك ، نحن بحاجة إلى أشخاص لا يخافون أيضًا من أي شيء والذين هم أيضًا على استعداد لتحويل الجبال. شكرا جزيلا