أي عملية مع البيانات الكبيرة يتطلب الكثير من قوة الحوسبة. قد يستغرق نقل البيانات نموذجيًا من قاعدة بيانات إلى Hadoop أسابيع أو تكلفة مثل جناح الطائرة. لا تريد الانتظار وتفاخر؟ موازنة الحمل على منصات مختلفة. طريقة واحدة هي تحسين القائمة المنسدلة.
لقد طلبت من أليكسي أنانييف ، وهو مدرب روسي رائد في تطوير وإدارة منتجات Informatica ، التحدث عن وظيفة تحسين الوظائف في Informatica Big Data Management (BDM). هل تعلمت من قبل العمل مع منتجات Informatica؟ على الأرجح ، كان أليكس هو الذي أخبرك عن أساسيات PowerCenter وشرح كيفية إنشاء التعيينات.
أليكسي أنانييف ، رئيس التدريب في مجموعة DIS
ما هو قائمة منسدلة؟
الكثير منكم على دراية بـ Informatica Big Data Management (BDM). يمكن للمنتج دمج البيانات الكبيرة من مصادر مختلفة ، ونقلها بين أنظمة مختلفة ، ويوفر سهولة الوصول إليها ، ويسمح لك بملف تعريفها وغير ذلك الكثير.
في الأيدي الماهرة ، يمكن أن يعمل BDM على العجائب: سيتم الانتهاء من المهام بسرعة وبأقل موارد الحوسبة.
تريد ذلك أيضا؟ تعرف على كيفية استخدام ميزة القائمة المنسدلة في BDM لتوزيع تحميل الحوسبة عبر الأنظمة الأساسية. تتيح لك تقنية Pushdown تحويل التعيين إلى برنامج نصي واختيار البيئة التي سيتم تشغيل هذا البرنامج النصي فيها. تتيح لك إمكانية هذا الاختيار الجمع بين نقاط القوة في الأنظمة الأساسية المختلفة وتحقيق أقصى درجات الأداء.
لتكوين وقت تشغيل البرنامج النصي ، حدد نوع القائمة المنسدلة. يمكن تشغيل البرنامج النصي بالكامل على Hadoop أو توزيعه جزئيًا بين المصدر والمستقبل. هناك 4 أنواع محتملة من القائمة المنسدلة. لا يمكن أن تتحول رسم الخرائط إلى برنامج نصي (أصلي). يمكن إجراء التعيين قدر الإمكان في المصدر (المصدر) أو بالكامل في المصدر (ممتلئ). يمكن أيضًا تحويل التعيين إلى برنامج Hadoop (بلا).
تحسين القائمة المنسدلة
يمكن دمج الأنواع الأربعة المدرجة في القائمة بطرق مختلفة - تحسين القائمة المنسدلة لتلبية الاحتياجات المحددة للنظام. على سبيل المثال ، غالبًا ما يكون من المستحسن استخراج البيانات من قاعدة بيانات باستخدام قدراتها الخاصة. ولتحويل البيانات - بواسطة Hadoop ، بحيث لا يتم تحميل قاعدة البيانات نفسها.
دعنا ننظر إلى الحالة عندما يكون كل من المصدر والمستقبل في قاعدة البيانات ، ويمكن تحديد منصة تنفيذ التحويل: وفقًا للإعدادات ، سيكون Informatica أو خادم قاعدة بيانات أو Hadoop. مثل هذا المثال سوف يجعل من الممكن فهم الجانب الفني لهذه الآلية بشكل أكثر دقة. بطبيعة الحال ، في الحياة الواقعية ، لا ينشأ هذا الموقف ، ولكن من الأنسب إظهار الوظيفة.
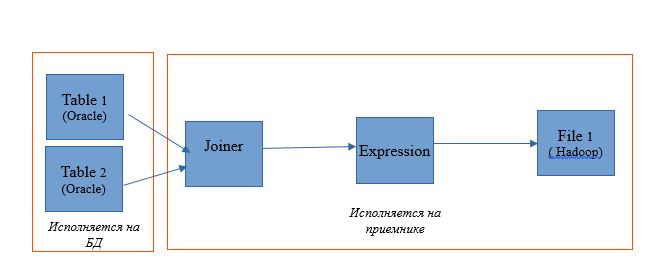
قم بإجراء التعيين لقراءة جدولين في قاعدة بيانات Oracle واحدة. ودع نتائج القراءة تكتب إلى جدول في نفس قاعدة البيانات. سيكون مخطط التعيين كما يلي:

في شكل تعيين على Informatica BDM 10.2.1 ، يبدو كما يلي:
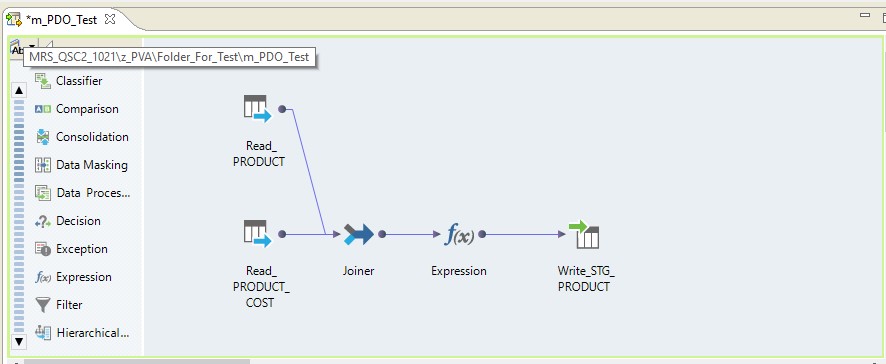
اكتب القائمة المنسدلة - الأصلي
إذا اخترنا النوع الأصلي من القائمة المنسدلة ، فسيتم إجراء التعيين على خادم Informatica. سيتم قراءة البيانات من خادم أوراكل ، ونقلها إلى خادم إنفورماتيكا ، وتحويلها إلى هناك ونقلها إلى Hadoop. بمعنى آخر ، نحصل على عملية ETL منتظمة.
اكتب القائمة المنسدلة
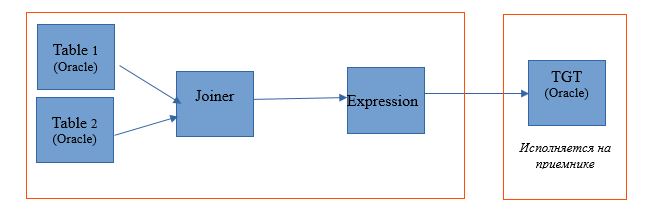
عند اختيار مصدر الكتابة ، سنحصل على فرصة لتوزيع عمليتنا بين خادم قاعدة البيانات (DB) و Hadoop. عند تنفيذ عملية باستخدام هذا الإعداد ، ستنتقل طلبات تحديد البيانات من الجداول إلى قاعدة البيانات. وسيتم الباقي في شكل خطوات على Hadoop.
سيبدو مخطط التنفيذ كما يلي:
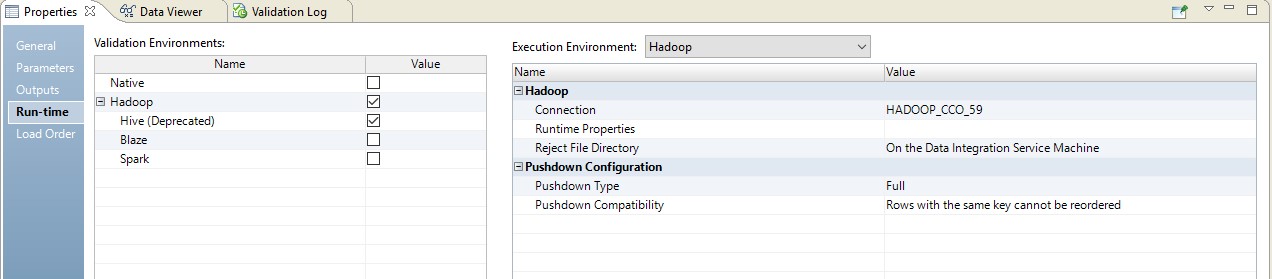
فيما يلي مثال لإعداد وقت التشغيل.
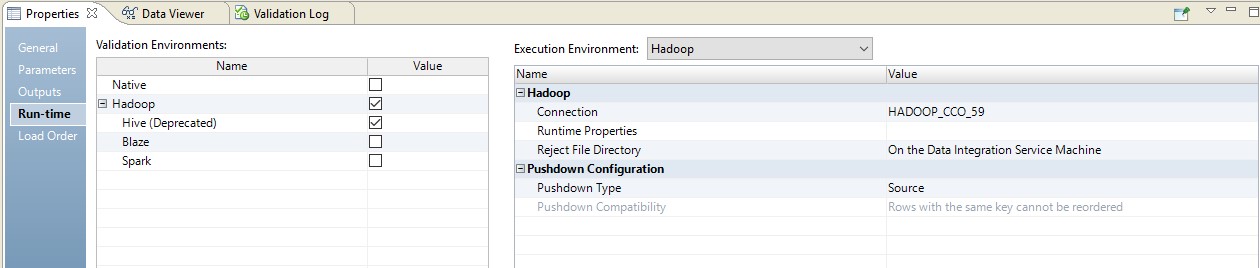
في هذه الحالة ، سيتم إجراء التعيين في خطوتين. في إعداداته ، سنرى أنه تحول إلى برنامج نصي سيتم إرساله إلى المصدر. علاوة على ذلك ، سيتم تنفيذ مجموعة الجداول وتحويل البيانات في شكل استعلام تم تجاوزه في المصدر.
في الصورة أدناه ، نرى تعيينًا محسنًا على BDM ، وعلى المصدر - طلبًا تم تجاوزه.
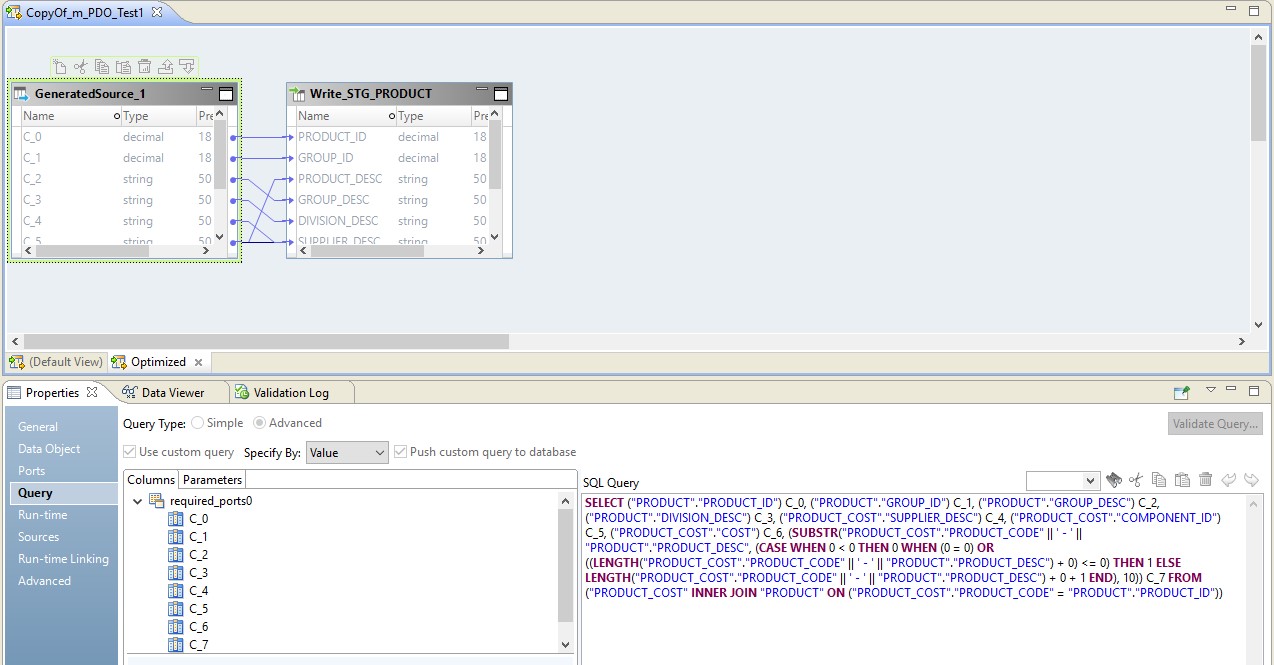
يعود دور Hadoop في هذا التكوين إلى إدارة تدفق البيانات - إجراء ذلك. سيتم إرسال نتيجة الطلب إلى Hadoop. بعد القراءة ، سيتم كتابة الملف من Hadoop إلى المتلقي.
اكتب القائمة المنسدلة - كامل
عند اختيار النوع الكامل ، سيتحول التعيين بالكامل إلى طلب قاعدة بيانات. وسيتم توجيه نتيجة الاستعلام إلى Hadoop. ويرد أدناه مخطط لهذه العملية.
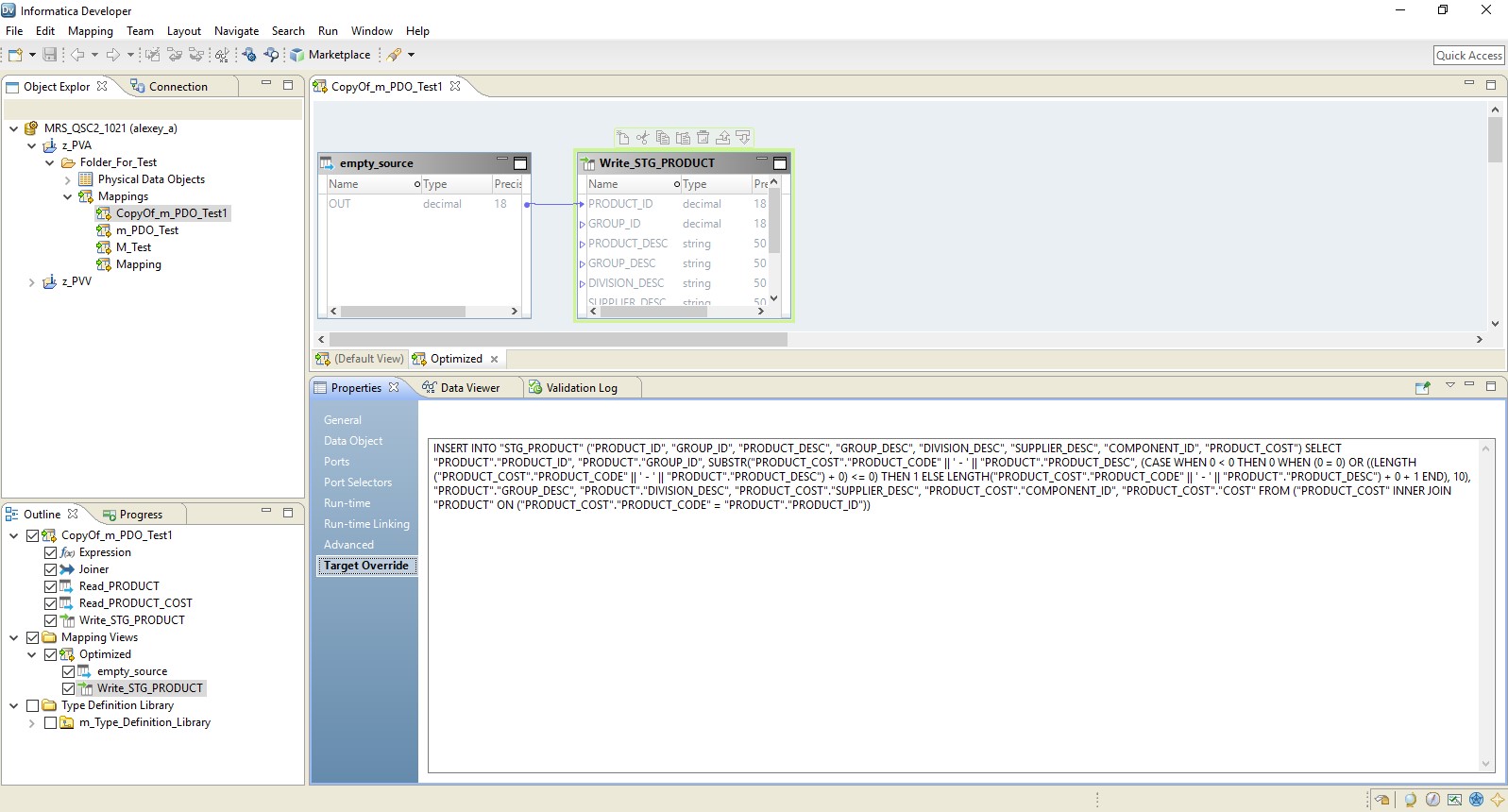
ويرد مثال الإعداد أدناه.
نتيجة لذلك ، حصلنا على تخطيط محسن مماثل للخريطة السابقة. الفرق الوحيد هو أن كل المنطق يتم نقله إلى المتلقي في شكل تجاوز لإدراجه. ويرد أدناه مثال عن التعيين المحسن.
هنا ، كما في الحالة السابقة ، يعمل Hadoop كقائد. ولكن هنا تتم قراءة المصدر بالكامل ، ثم على مستوى المتلقي يتم تنفيذ منطق معالجة البيانات.
اكتب القائمة المنسدلة - فارغة
حسنًا ، الخيار الأخير هو نوع القائمة المنسدلة ، حيث سيتحول مناظيرنا إلى نص Hadoop.
سيبدو الآن التعيين المحسن كما يلي:
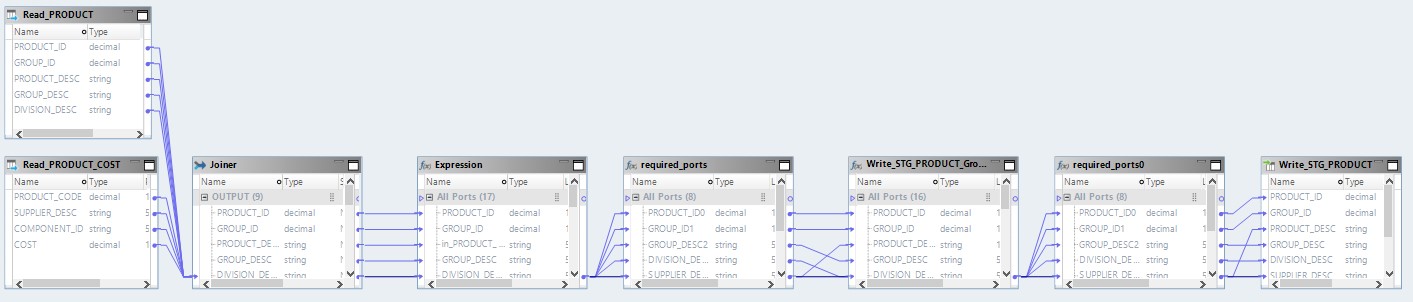
هنا ، سيتم أولاً قراءة البيانات من الملفات المصدر على Hadoop. ثم ، بوسائله الخاصة ، سيتم دمج هذين الملفين. بعد ذلك ، سيتم تحويل البيانات وتحميلها إلى قاعدة البيانات.
من خلال فهم مبادئ تحسين عملية الدفع إلى أسفل ، يمكنك تنظيم العديد من العمليات بشكل فعال للعمل مع البيانات الضخمة. لذا ، مؤخرًا ، قامت شركة كبيرة في غضون أسابيع قليلة بتحميل بيانات كبيرة من التخزين إلى Hadoop ، والتي كانت تجمعها منذ عدة سنوات.