
في هذه المقالة ، سوف أتحدث عن حل بلدي للجزء النص من مهمة
SNA Hackathon 2019 . ستكون بعض الأفكار المقترحة مفيدة للمشاركين في الجزء المتفرغ من hackathon ، والذي سيعقد في مكتب مجموعة Mail.ru في موسكو من 30 مارس إلى 1 أبريل. بالإضافة إلى ذلك ، قد تكون هذه القصة ذات أهمية للقراء لحل المشاكل العملية للتعلم الآلي. نظرًا لأنني لا أستطيع المطالبة بجوائز (أعمل في Odnoklassniki) ، فقد حاولت أن أقدم الحل الأكثر بساطة ، ولكنه في الوقت نفسه فعال ومثير للاهتمام.
عند قراءة نماذج جديدة للتعلم الآلي ، أريد أن أفهم كيف فكر المؤلف أثناء العمل في مهمة. لذلك ، سأحاول في هذه المقالة إثبات جميع مكونات حل بلدي بالتفصيل. في الجزء الأول سأتحدث عن بيان المشكلة والقيود. في الثانية - حول تطور النموذج. الجزء الثالث مكرس لنتائج وتحليل النموذج. أخيرًا ، في التعليقات سأحاول الإجابة على أي أسئلة نشأت. يمكن للقراء بفارغ الصبر إلقاء نظرة على
البنية النهائية على الفور.
مهمة
اقترح منظمو Hackathon أننا نحل مشكلة تشكيل شريط ذكي. لكل مستخدم ، من الضروري فرز مجموعة المنشورات بحيث يكون الحد الأقصى لعدد المنشورات التي يحددها المستخدم "الفئة" في أعلى القائمة. لتكوين خوارزمية الترتيب ، كان من المفترض أن تستخدم البيانات التاريخية للنموذج (المستخدم ، النشر ، التعليقات). يقدم الجدول وصفًا موجزًا للبيانات من جزء النص والترميز الذي سأستخدمه في هذه المقالة.
مصدر
| تعيين
| نوع
| وصف
|
|---|
المستخدم
| USER_ID
| قاطع
| معرف المستخدم
|
بعد
| POST_ID
| قاطع
| معرف الوظيفة
|
بعد
| نص
| القائمة الفئوية
| قائمة الكلمات تطبيعها
|
بعد
| ملامح
| قاطع
| مجموعة من خصائص المنشور (المؤلف ، اللغة ، إلخ)
|
ردود الفعل
| ردود الفعل
| قائمة ثنائية
| العديد من الإجراءات التي يمكن للمستخدم تنفيذها مع المنشور (العرض ، الفصل ، التعليق ، إلخ.)
|
قبل البدء في بناء النموذج ، قدمت عدة قيود على الحل المستقبلي. كان هذا ضروريًا من أجل تلبية متطلبات البساطة والتطبيق العملي واهتماماتي وتقليل عدد الخيارات الممكنة. فيما يلي أهم هذه القيود.
التنبؤ باحتمال "الطبقة" . قررت على الفور أنني سأحل هذه المشكلة كمشكلة تصنيف. يمكن للمرء تطبيق الأساليب المستخدمة في الترتيب ، على سبيل المثال ، للتنبؤ بالترتيب في أزواج من المشاركات. لكنني استقرت على صيغة أبسط ، حيث يتم فرز المشاركات وفقًا للاحتمال المتوقع للحصول على "فئة". تجدر الإشارة إلى أنه يمكن توسيع النهج الموضح أدناه لصياغة الترتيب.
نموذج متجانسة . على الرغم من حقيقة أن مجموعات النماذج تميل إلى الفوز بالمسابقات ، فإن الحفاظ على مجموعة على نظام قتالي أصعب من نموذج واحد. بالإضافة إلى ذلك ، كنت أرغب في امتلاك بعض إمكانات الترجمة الفورية غير الصندوق الأسود على الأقل.
الرسم البياني الحسابي التفاضلية . أولاً ، تحدد نماذج هذه الفئة (الشبكات العصبية) أحدث ما توصلت إليه في العديد من المهام ، بما في ذلك تلك المتعلقة
بتحليل البيانات النصية . ثانياً ، الأطر الحديثة ، في حالتي
Apache MXNet ، تسمح لك بتنفيذ
تصميمات متنوعة للغاية. لذلك ، يمكنك تجربة نماذج مختلفة عن طريق تغيير بضعة أسطر من التعليمات البرمجية.
الحد الأدنى من العمل مع علامات . كنت أرغب في توسيع النموذج بسهولة باستخدام بيانات جديدة. قد تكون هناك حاجة لذلك في الجزء بدوام كامل ، حيث سيكون هناك القليل من الوقت لإعداد علامات. لذلك ، استقرت على أبسط طريقة لتحديد السمات:
- يتم تمثيل البيانات الثنائية بواسطة علامة بقيمة 1 أو 0 ؛
- تبقى البيانات الرقمية كما هي أو يتم تقديرها في فئات ؛
- يتم تقديم البيانات الفئوية من قبل حفلات الزفاف.
بعد أن قررت الاستراتيجية العامة ، بدأت في تجربة نماذج مختلفة.
تطور النموذج
كانت نقطة الانطلاق هي نهج عامل المصفوفة ، وغالبًا ما تستخدم في مهام التوصية:
pi،j= sigma(ui cdotvj)

في لغة الرسوم البيانية الحسابية ، هذا يعني أن تقدير احتمال أن المستخدم سوف أضع "فئة" على المنشور
j هو السيني من المنتج القياسي لتضمين معرف المستخدم ومعرف النشر. يمكن التعبير عن نفس الشيء من خلال مخطط:

هذا النموذج ليس مثيرا للاهتمام: فهو لا يستخدم جميع الميزات ، وهو غير مفيد للغاية بالنسبة لمعرفات التردد المنخفض ، ويعاني من مشكلة البداية الباردة. ولكن ، بعد صياغة المهمة في شكل رسم بياني حسابي ، فإننا "نربط أيدينا" ويمكننا الآن حل المشكلات على مراحل. بادئ ذي بدء ، بالنسبة لقيم التردد المنخفض ،
سننشئ التضمين الوحيد
خارج المفردات . بعد ذلك ، تخلص من الحاجة إلى حفلات زفاف من نفس البعد. للقيام بذلك ، نستبدل المنتج القياسي بمدرك ضحل ، يتلقى ميزات متسلسلة كمدخلات. يتم تقديم النتيجة في الرسم البياني:

بمجرد التخلص من البعد الثابت ، لا شيء يمنعنا من البدء في إضافة سمات جديدة. تمثل المنشور مع كل أنواع الخصائص (اللغة ، المؤلف ، النص ، ...) ، سنحل مشكلة البداية البارد للوظائف. سوف يتعلم النموذج ، على سبيل المثال ، أن مستخدمًا له
user_id = 42 يضع "فصول" في مشاركات باللغة الروسية تحتوي على كلمة "سجادة". في المستقبل ، سنكون قادرين على أن نوصي هذا المستخدم بجميع منشورات اللغة الروسية حول السجاد ، حتى لو لم تظهر في بيانات التدريب. بالنسبة لتضمين النص ، في الوقت الحالي ، سنقوم ببساطة بتضمين زخارف الكلمات المدرجة فيه. نتيجة لذلك ، يبدو النموذج كما يلي:
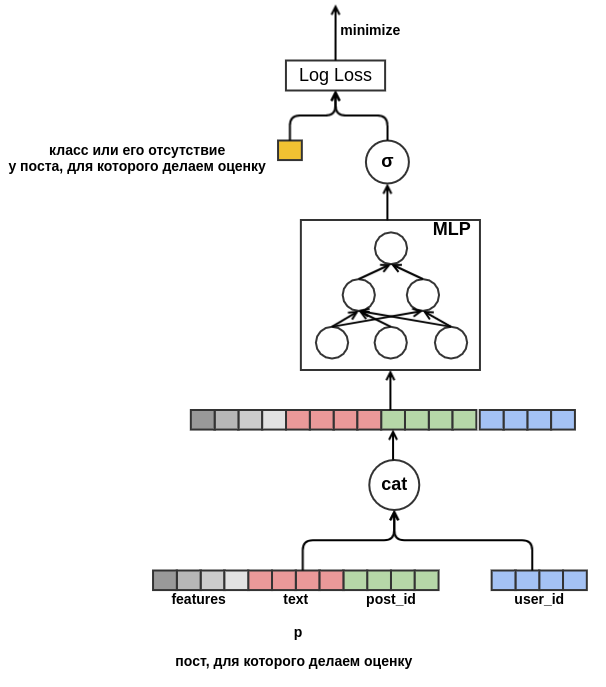
أخيرًا ، أود التعامل مع البداية الباردة للمستخدمين. سيكون من الممكن بناء ميزات من البيانات التاريخية على مشاهدات المستخدم للوظائف. هذا النهج لا يلبي الإستراتيجية المختارة: قررنا تقليل الإنشاء اليدوي للسمات. لذلك ، أتاحت للنموذج فرصة لتعلم العرض التقديمي للمستخدم بشكل مستقل من تسلسل المشاركات التي تم عرضها قبل تلك المشاركة التي يتم تقييم احتمال "الفصل" بها. على عكس المنشور الجاري تقييمه ، تُعرف كل التعليقات لكل منشور بالتسلسل. هذا يعني أن النموذج سيكون له حق الوصول إلى المعلومات حول ما إذا كان المستخدم قد قام بتعيين "النشرات" على المشاركات السابقة أو ، على العكس من ذلك ، حذفها من الخلاصة.

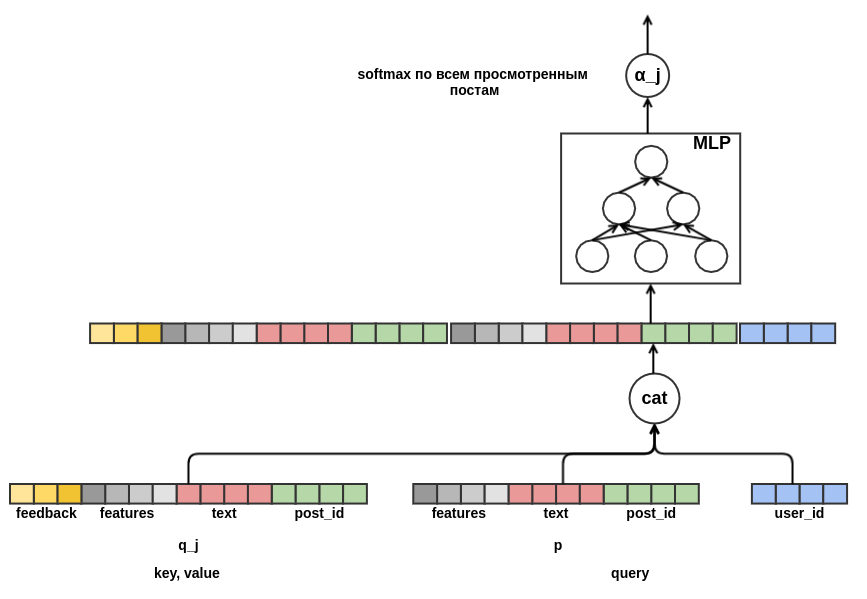
يبقى أن تقرر كيفية دمج تسلسل المشاركات ذات أطوال مختلفة في تمثيل ذي عرض ثابت. على هذا المزيج ، استخدمت المبلغ المرجح من تمثيل كل وظيفة. على الرسم البياني ،
يتم الإشارة إلى وزن
المنشور j بواسطة
α_j . تم حساب الأوزان باستخدام آلية اهتمام قيمة الاستعلام ، على غرار تلك المستخدمة في
المحول أو
NMT . وبالتالي ، يتم أيضًا تكوين العرض التقديمي الذي يتعلمه المستخدم للنشر الذي يتم إجراء التقييم من أجله. في ما يلي جزء من الرسم البياني المسؤول عن حساب
α_j :
بعد أن
شعرت بلهجة غاضبة ، أصبحت مقتنعًا بفعالية نهج الاهتمام ، فقد تقرر استخدام الانتباه في عرض النصوص. من أجل توفير الوقت والحديد ، قررت عدم استخدام الاهتمام الذاتي كما هو الحال في نفس المحول ، لكنني أتدرب بشكل مباشر على كلمة الأوزان في النص ، مثل هذا:
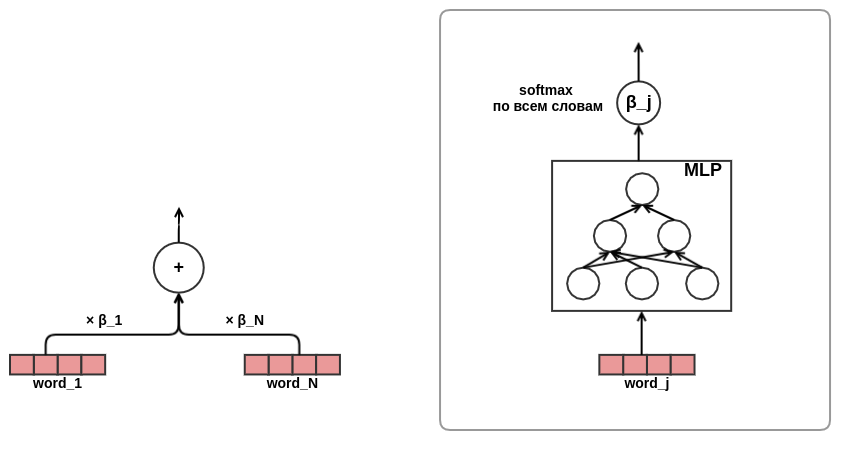
على هذا ، تم الانتهاء من تطوير بنية النموذج. نتيجة لذلك ، انتقلت من عامل المصفوفة الكلاسيكية إلى نموذج تسلسل معقد إلى حد ما.
النتائج والتحليل
قمت بتطوير وتصحيح حل بلدي على سُبع البيانات الموجودة على جهاز كمبيوتر محمول مزود بذاكرة تبلغ سعتها 16 جيجابايت وبطاقة رسومات GeForce 930MX. تم إجراء تجارب البيانات الكاملة على خادم مخصص مع 256 جيجابايت من الذاكرة وبطاقة Tesla T4. للتحسين ، تم استخدام خوارزمية Adam مع المعلمات الافتراضية من MXNet. يوضح الجدول نتائج نموذج تم تجريده - كان طول تسلسل المنشورات محدودًا بعشرة. في المسابقة تقدم ، اعتدت تسلسل طولها خمسون.
نموذج
| سجل الخسارة
| تحسن من السطر السابق
| وقت التدريب
|
|---|
راند
| 0.4374 ± 0.0009
| | |
المستقبلات
| 0.4330 ± 0.0010
| 0.0043 ± 0.0002
| 7 دقائق
|
Perceptron مع علامات
| 0.4119 ± 0.0008
| 0.0212 ± 0.0003
| 44 دقيقة
|
Perceptron مع سلسلة من المشاركات
| 0.3873 ± 0.0008
| 0.0247 ± 0.0003
| 4 ساعات و 16 دقيقة
|
Perceptron مع سلسلة من المشاركات والاهتمام في النصوص
| 0.3874 ± 0.0008
| 0.0001 ± 0.0001
| 4 ساعات 43 دقيقة
|
تبين أن السطر الأخير هو الأكثر توقعًا بالنسبة لي: استخدام الانتباه في عرض النصوص لا يعطي تحسينًا ملحوظًا في النتيجة. كنت أتوقع أن تتعلم شبكة الاهتمام أوزان الكلمات في النصوص ، شيء مثل
idf . ربما لم يحدث هذا ، لأن المنظمين أزالوا كلمات التوقف مقدمًا والكلمات ذات الأهمية نفسها ظلت في القوائم المعدة. لذلك ، لم يعطي الميزان "الذكي" ميزة ملموسة مقارنةً بالمتوسط البسيط. سبب آخر محتمل هو أن شبكة الاهتمام للكلمات كانت صغيرة جدًا: كانت تحتوي على طبقة خفية ضيقة واحدة فقط. ربما كانت تفتقر إلى القدرة على التمثيل لتعلم شيء مفيد.
تتيح لك آلية الاهتمام بقيمة مفتاح الاستعلام النظر داخل النموذج ومعرفة ما "يلفت الانتباه" عند اتخاذ قرار. لتوضيح هذا ،
اخترت بعض الأمثلة:
, http://ollston.ru/2018/02/10/uznajte-kakogo-cveta-vasha - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.16] 2016 2016 GZ8btjgY_Q0 https: - [0.16] . Nike http://ollston.ru/2018/02/04/istorii-yspeha-nike/ - : - [0.09] - 5 - 5 O3qAop0A5Qs https://ww - [0.09] ... , - [0.22] Microsoft Windows — http://ollston.ru/2018/02/06/microsoft-windows-istoriia-yspeha/ - [0.20] , 6 . , ? http://ollston.ru/2018/02/08/buddisty-g
يعرض السطر الأول نص المنشور الذي يجب تقييمه ، ثم المشاركات التي سبق عرضها ودرجة الاهتمام المقابلة. مع الارتياح ، لاحظنا أن النموذج تعلم تجاهل الحشوة. اعتبر النموذج المشاركات الأكثر أهمية في أنواع النفوس وحول Windows. يجب أن يؤخذ في الاعتبار أن الانتباه يمكن أن يكون إما إيجابيًا (المستخدم سوف يستجيب إلى منشور حول هالة بنفس طريقة النشر حول أنواع النفوس) أو سلبي (نقوم بتقييم منشور حول هالة - لذلك ، لن يكون رد الفعل هو نفسه رد الفعل على المنشور حول التكنولوجيا). المثال التالي هو الاهتمام "بكل مجده":
- [0.20] 2018 (), , . - [0.08] ... !!! - [0.04] ))) - [0.18] ! , . 10 - [0.18] 2- , 5 , , 2 , . . - [0.07] ! - () - [0.03] "". . - [0.13] , - [0.05] , ... - [0.05] ...
هنا ، رأى النموذج بوضوح موضوع العطلة الصيفية. حتى الأطفال والقطط ذهبوا على جانب الطريق. يوضح المثال التالي أن تفسير الانتباه غير ممكن دائمًا. أحيانًا لا يوجد شيء واضح على الإطلاق:
! - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.15] , ! !!! - [0.16] ! http://gifok.ru/dobryj-vecher/ - [0.20] http://gifq.ru/aforizmy/ - [0.25] . . - [0.15] , . : 800 250-300
بعد النظر في عدد من هذه القوائم ، خلصت إلى أن النموذج كان قادرًا على معرفة ما كنت أتوقعه. والشيء التالي الذي فعلته هو النظر في تضمين الكلمات. في مشكلتنا ، لا يمكننا أن نتوقع أن تكون حفلات الزفاف جميلة مثلما هو الحال عند تعلم
نموذج اللغة : نحاول أن نتوقع متغيرًا صاخبًا إلى حد ما ، بالإضافة إلى ذلك ، ليس لدينا نافذة صغيرة للسياق - يتم ببساطة حساب متوسطات كل الكلمات دون مراعاة ترتيبها في النص. أمثلة على الرموز وأقرب جيرانها في مساحة التضمين:
- : , , , , - : , , , , - : , , , , - : , , , , - : , , , ,
من السهل شرح بعض هذه القائمة (program - bl) ، هناك شيء محير (iPhone - youki) ، ولكن بشكل عام ، كانت النتيجة مرة أخرى قد حققت توقعاتي.
استنتاج
يعجبني أسلوب بناء النماذج استنادًا إلى الرسوم البيانية القابلة للتمييز (
يوافق الكثيرون ). إنها تتيح لك الابتعاد عن الاختيار اليدوي الشاق للميزات والتركيز على الصياغة الصحيحة للمشكلة وتصميم البنى المثيرة للاهتمام. وعلى الرغم من احتلال نموذجي في المركز الثاني فقط في مهمة النص SNA Hackathon 2019 ، إلا أنني مسرور جدًا بهذه النتيجة ، نظرًا لبساطتها وخيارات التوسع غير المحدودة تقريبًا. أنا متأكد من أنه في المستقبل سيكون هناك نماذج أكثر إثارة للاهتمام وقابلة للتطبيق في أنظمة القتال على أساس أفكار مماثلة.