سأخبرك اليوم كيف تمكنا من حل مشكلة نقل
تطبيقات Spark Structured Streaming إلى
Kubernetes (K8s) وتنفيذ تدفق CI.
كيف بدأ كل شيء؟
يعد البث أحد المكونات الرئيسية لمنصة FASTEN RUS BI. يتم استخدام البيانات في الوقت الفعلي بواسطة فريق تحليل التاريخ لإنشاء تقارير تشغيلية.
يتم تنفيذ تطبيقات البث باستخدام
Spark Structured Streaming . يوفر هذا الإطار واجهة برمجة تطبيقات ملائمة لتحويل البيانات تلبي احتياجاتنا من حيث سرعة التحسينات.
تيارات ارتفع أنفسهم على الكتلة
AWS EMR . وبالتالي ، عند رفع دفق جديد إلى المجموعة ، تم وضع برنامج نصي ssh لتقديم وظيفة Spark ، وبعد ذلك تم إطلاق التطبيق. وفي البداية بدا أن كل شيء يناسبنا. ولكن مع تزايد عدد التدفقات ، أصبحت الحاجة إلى تنفيذ تدفق CI أكثر وضوحًا ، مما سيزيد من استقلالية أمر تاريخ التحليل عند بدء تشغيل التطبيقات لتقديم البيانات على كيانات جديدة.
والآن سننظر في كيفية تمكننا من حل هذه المشكلة عن طريق نقل البث إلى Kubernetes.
لماذا Kubernetes؟
Kubernetes ، كمدير للموارد ، هو الأنسب لاحتياجاتنا. هذا هو نشر دون توقف ، ومجموعة واسعة من أدوات تنفيذ CI على Kubernetes ، بما في ذلك هيلم. بالإضافة إلى ذلك ، كان لدى فريقنا خبرة كافية في تنفيذ خطوط أنابيب CI على K8s. لذلك ، كان الاختيار واضحًا.
كيف يتم تنظيم نموذج إدارة تطبيقات Spark المستندة إلى Kubernetes؟

يدير العميل شرارة الإرسال على K8s. يتم إنشاء جراب برنامج تشغيل التطبيق. جدولة Kubernetes بربط قرنة إلى عقدة كتلة. ثم يرسل برنامج التشغيل طلبًا لإنشاء ملفات pod لتشغيل المديرين التنفيذيين ، يتم إنشاء القرون وإرفاقها بعقد نظام المجموعة. بعد ذلك ، يتم تنفيذ مجموعة قياسية من العمليات مع التحويل اللاحق لرمز التطبيق إلى DAG ، والتحلل إلى مراحل ، وتقسيم المهام وإطلاقها على الملفات التنفيذية.
يعمل هذا النموذج بنجاح كبير عند بدء تشغيل تطبيقات Spark يدويًا. ومع ذلك ، فإن نهج إطلاق شرارة إرسال خارج الكتلة لا يناسبنا من حيث تنفيذ CI. كان من الضروري العثور على حل يتيح لـ Spark تشغيل (تنفيذ spark-submit) مباشرة على عقد المجموعة. وهنا يلبي نموذج مشغل Kubernetes متطلباتنا بالكامل.
مشغل Kubernetes كنموذج لإدارة دورة حياة تطبيق Spark
Kubernetes Operator هو مفهوم لإدارة التطبيقات الكاملة في Kubernetes ، التي اقترحها
CoreOS ، والتي تنطوي على أتمتة المهام التشغيلية ، مثل نشر التطبيقات ،
وإعادة تشغيل التطبيقات في حالة الملفات ، وتحديث تكوين التطبيقات. أحد أنماط Kubernetes Operator الرئيسية هو CRD (
CustomResourceDefinitions ) ، والتي تتضمن إضافة موارد مخصصة إلى مجموعة K8 ، والتي بدورها تسمح لك بالعمل مع هذه الموارد كما هو الحال مع كائنات Kubernetes الأصلية.
المشغل هو البرنامج الخفي الذي يعيش في جراب الكتلة ويستجيب لإنشاء / تغيير حالة مورد مخصص.
النظر في هذا المفهوم لإدارة دورة حياة التطبيق سبارك.
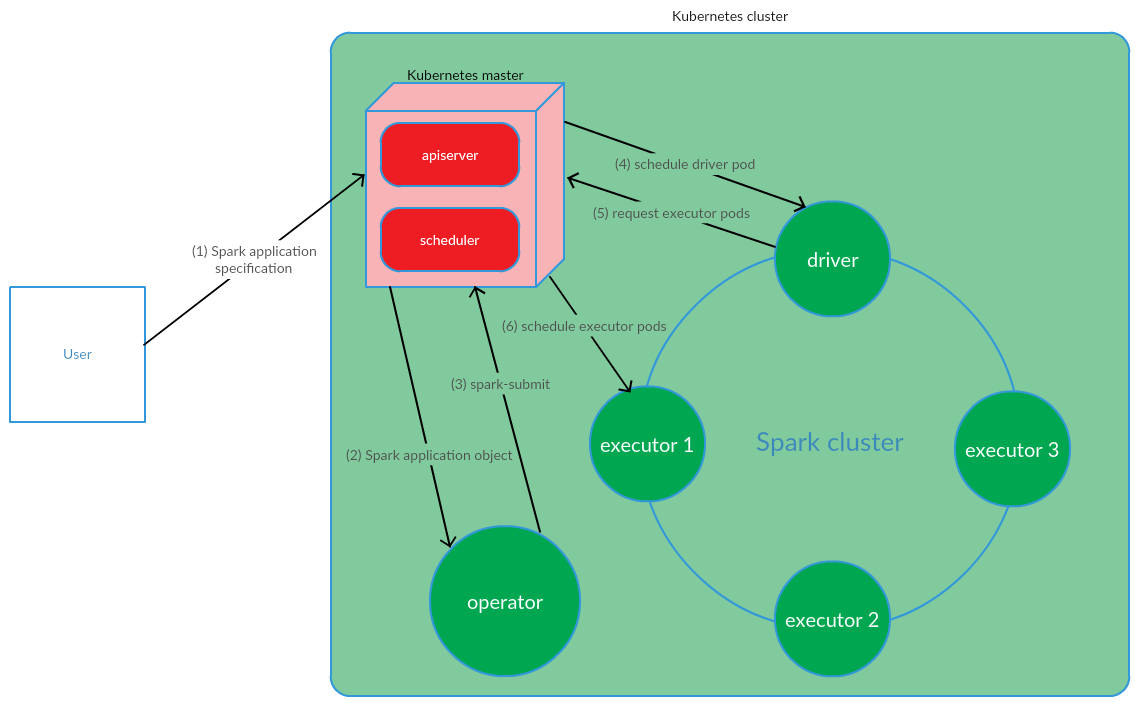
يقوم المستخدم بتشغيل الأمر kubectl application -f spark-application.yaml ، حيث يمثل spark-application.yaml مواصفات تطبيق Spark. يستقبل المشغل كائن تطبيق Spark وينفذ شرارة الإرسال.
كما نرى ، يشتمل نموذج مشغل Kubernetes على إدارة دورة حياة تطبيق Spark مباشرةً في مجموعة Kubernetes ، والتي كانت حجة خطيرة لصالح هذا النموذج في سياق حل مشكلاتنا.
باعتبارك مشغل Kubernetes لإدارة تطبيقات البث ، فقد تقرر استخدام
مشغل spark-on-k8s . يوفر هذا المشغل واجهة برمجة تطبيقات ملائمة إلى حد ما ، بالإضافة إلى مرونة في تكوين سياسة إعادة تشغيل تطبيقات Spark (وهو أمر مهم للغاية في سياق دعم تطبيقات البث).
تنفيذ CI
لتنفيذ تدفق CI ،
تم استخدام GitLab CI / CD . تم تنفيذ تطبيقات Spark على K8s باستخدام أدوات
Helm .
يشمل خط الأنابيب نفسه مرحلتين:
- اختبار - يتم إجراء اختبار بناء الجملة ، وكذلك تقديم قوالب Helm ؛
- نشر - نشر تطبيقات التدفق على بيئات الاختبار (مطور) والمنتج (prod).
دعونا نفكر في هذه المراحل بمزيد من التفصيل.
في مرحلة الاختبار ، يتم تقديم قالب Helm الخاص بتطبيق Spark (CRD -
SparkApplication ) بقيم خاصة بالبيئة.
الأقسام الرئيسية لقالب هيلم هي:
- شرارة:
- الإصدار - إصدار أباتشي سبارك
- صورة - صورة عامل الميناء المستخدمة
- nodeSelector - يحتوي على قائمة (مفتاح → قيمة) تقابل تسميات الموقد.
- التحمل - يشير إلى قائمة التحمل لتطبيق Spark.
- mainClass - فئة تطبيق Spark
- applicationFile - المسار المحلي حيث توجد جرة تطبيق Spark
- restartPolicy - سياسة إعادة تشغيل تطبيق Spark
- أبدًا - لا يتم إعادة تشغيل تطبيق Spark المكتمل
- دائمًا - يتم إعادة تشغيل تطبيق Spark المكتمل بغض النظر عن سبب التوقف.
- إعادة تشغيل تطبيق OnFailure - Spark فقط في حالة وجود ملف
- maxSubmissionRetries - الحد الأقصى لعدد عمليات إرسال تطبيق Spark
- سائق / المنفذ:
- النوى - عدد النوى المخصصة للسائق / المنفذ
- حالات (تستخدم فقط لتكوين المديرين التنفيذيين) - عدد المسؤولين التنفيذيين
- الذاكرة - مقدار الذاكرة المخصصة لعملية برنامج التشغيل / المنفذ
- memoryOverhead - مقدار ذاكرة إيقاف التشغيل المخصصة لبرنامج التشغيل / المنفذ
- تيارات:
- اسم - اسم تطبيق الدفق
- الوسائط - الوسائط إلى تطبيق الدفق
- بالوعة - المسار إلى مجموعات البيانات بحيرة البيانات على S3
بعد تقديم القالب ، يتم نشر التطبيقات في بيئة اختبار dev باستخدام Helm.
عملت على خط أنابيب CI.
ثم نطلق مهمة نشر برود - إطلاق التطبيقات في الإنتاج.
نحن مقتنعون بالأداء الناجح للوظيفة.
كما نرى أدناه ، يتم تشغيل التطبيقات ، والقرون في حالة تشغيل.

استنتاج
أتاحت لنا تطبيقات Porting Spark للتدفق المهيكل إلى K8s والتنفيذ اللاحق لـ CI أتمتة إطلاق التدفقات لتقديم البيانات إلى كيانات جديدة. لرفع الدفق التالي ، يكفي تحضير طلب دمج مع وصف لتكوين تطبيق Spark في ملف yaml للقيم وعند بدء مهمة النشر - prod ، سيتم بدء تسليم البيانات إلى بحيرة البيانات (S3). كفل هذا الحل استقلال أمر تاريخ التحليل عند تنفيذ المهام المتعلقة بإضافة كيانات جديدة إلى المستودع. بالإضافة إلى ذلك ، أدى نقل البث إلى K8s ، وعلى وجه الخصوص إدارة تطبيقات Spark باستخدام مشغل Kubernetes Operator spark-on-k8s ، إلى زيادة كبيرة في مرونة البث. ولكن المزيد عن ذلك في المقال التالي.