باستخدام مثال لوصف تطبيق خوارزمية التشفير وفقًا لمعايير GOST 28147–89 المبنية على شبكة Feistel ، تُظهر المقالة إمكانات المعالج ثنائي النواة BE-T1000 (ويعرف أيضًا باسم Baikal-T1) ويتم إجراء اختبارات مقارنة لتنفيذ الخوارزمية باستخدام حسابات المتجهات مع وبدون SIMD coprocessor. سنبين هنا استخدام كتلة SIMD لمهمة التشفير وفقًا لـ GOST 28147-89 ، وضع ECB.
كُتب هذا المقال العام الماضي لمجلة Electronic Components من تأليف أليكسي كولوتنيكوف ، أحد المبرمجين البارزين في بايكال للإلكترونيات. وبما أنه لا يوجد عدد كبير من القراء في هذه المجلة ، وهذا المقال مفيد لأولئك الذين يشاركون بشكل احترافي في التشفير ، وأنا ، بإذن من المؤلف وإضافاته الصغيرة ، أنشره هنا.
معالج Baikal-T1 وكتلة SIMD بداخله
يشتمل معالج Baikal-T1 على نظام ثنائي النواة متعدد المعالجات لعائلة MIPS32 P5600 ، فضلاً عن مجموعة من الواجهات عالية السرعة لتبادل البيانات والسرعة المنخفضة للتحكم في الأجهزة الطرفية. هنا هو المخطط الهيكلي لهذا المعالج:
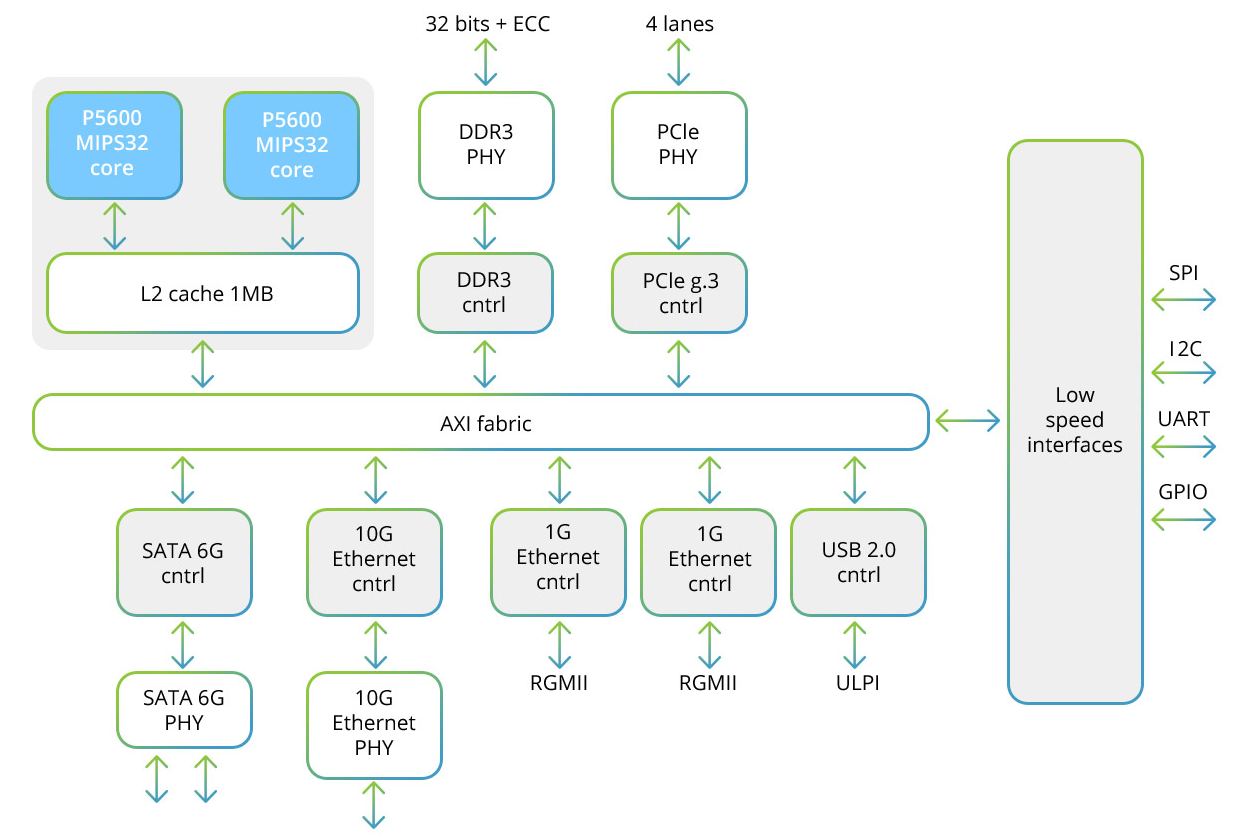
يتضمن كل من النوى اثنين من كتلة SIMD التي تسمح لك بالعمل مع ناقلات 128 بت. عند استخدام طريقة SIMD ، تتم معالجة أكثر من عينة ،
والناقل بأكمله ، والذي يمكن أن يحتوي على عدة عينات ، أي ، يتم تطبيق أمر واحد على الفور على المتجه (صفيف) البيانات بأكمله. وبالتالي ، في دورة قيادة واحدة ، تتم معالجة عدة عينات. يستخدم المعالج MIPS32 SIMD block ، والذي يسمح لك بالعمل مع 32 قطعة من سجلات 128 بت.
يمكن أن يحتوي كل سجل على متجهات ذات الأبعاد التالية: 8 × 16 ؛ 16 × 8 ؛ 4 × 32 أو
2 × 64 بت. من الممكن استخدام أكثر من 150 تعليمات لمعالجة البيانات: عدد صحيح ونقطة الفاصلة ونقطة ثابتة ، بما في ذلك عمليات bitwise ، وعمليات المقارنة ، وعمليات التحويل.
تم وصف تقنية MIPS SIMD المفصلة من قبل SparF في المقالة "MIPS SIMD Technology و Baikal-T1 Processor" .
تقييم فعالية الحوسبة المتجهة
يجمع المعالج الثانوي الحسابي الخاص بنواة المعالج Baikal-T1 بين معالج الفاصلة العائمة التقليدي ومعالج SIMD الموازي ، والذي يركز على المعالجة الفعالة للمتجهات والإشارات الرقمية. تم إجراء تقييم مستقل للأداء لمعالج ناقلات SIMD في عام 2017 بواسطة SparF أثناء كتابة مقال "MIPS SIMD Technology و Baikal-T1 Processor" . إذا رغبت في ذلك ، يمكن تكرار هذه القياسات وتنفيذها بشكل مستقل عن طريق الاتصال بموقف بعيد باستخدام معالج .
ثم كانت مهمة الاختبار هي فك تشفير الفيديو المشفر باستخدام مكتبات x264 المجانية (مقطع عرض تجريبي H.264) و x265 (ملف فيديو HEVC) ، مع لقطات شاشة مأخوذة على فترات منتظمة. كما هو متوقع ، لوحظت زيادة ملحوظة في أداء المعالج الأساسي في مهام FFmpeg باستخدام إمكانيات أجهزة SIMD:

وصف موجز للخوارزمية GOST 28147-89
سنلاحظ هنا الخصائص الرئيسية لفهم الكود والتحسين فقط:
- تم بناء الخوارزمية على شبكة Feistel.

- الخوارزمية تتكون من 32 طلقة.
- تتكون الجولة من مزج مفتاح واستبدال 8 أجزاء من 4 بتات في جدول مع إزاحة 11 بت.
ويرد وصف مفصل لخوارزمية تحويل المعلومات وفقًا لـ GOST 28147-89 في المعيار الرسمي للاتحاد السوفياتي .
تنفيذ خوارزمية GOST 28147-89 دون استخدام كتلة SIMD
لأغراض المقارنة ، تم تنفيذ الخوارزميات مبدئيًا باستخدام أوامر قياسية "غير متجهة".
يسمح لك رمز المجمّع MIPS المقترح هنا بتشفير كتلة واحدة من 64 بت في 450 نانوثانية (أو ~ 150 ميجابايت / ثانية) بتردد معالج اسمي يبلغ 1200 ميجاهرتز. يشارك واحد فقط الأساسية في العمليات الحسابية.
يستلزم إعداد جدول بديل توسيعه ليصبح تمثيلًا 32 بتًا لتسريع عمل الجولة: بدلاً من استبدال وحدات البت الأربعة بأقنعة والتحول مقدمًا
الجدول أعد تحل محل ثمانية بت لكل منهما.
uint8_t sbox_test[8][16] = { {0x9, 0x6, 0x3, 0x2, 0x8, 0xb, 0x1, 0x7, 0xa, 0x4, 0xe, 0xf, 0xc, 0x0, 0xd, 0x5}, {0x3, 0x7, 0xe, 0x9, 0x8, 0xa, 0xf, 0x0, 0x5, 0x2, 0x6, 0xc, 0xb, 0x4, 0xd, 0x1}, {0xe, 0x4, 0x6, 0x2, 0xb, 0x3, 0xd, 0x8, 0xc, 0xf, 0x5, 0xa, 0x0, 0x7, 0x1, 0x9}, {0xe, 0x7, 0xa, 0xc, 0xd, 0x1, 0x3, 0x9, 0x0, 0x2, 0xb, 0x4, 0xf, 0x8, 0x5, 0x6}, {0xb, 0x5, 0x1, 0x9, 0x8, 0xd, 0xf, 0x0, 0xe, 0x4, 0x2, 0x3, 0xc, 0x7, 0xa, 0x6}, {0x3, 0xa, 0xd, 0xc, 0x1, 0x2, 0x0, 0xb, 0x7, 0x5, 0x9, 0x4, 0x8, 0xf, 0xe, 0x6}, {0x1, 0xd, 0x2, 0x9, 0x7, 0xa, 0x6, 0x0, 0x8, 0xc, 0x4, 0x5, 0xf, 0x3, 0xb, 0xe}, {0xb, 0xa, 0xf, 0x5, 0x0, 0xc, 0xe, 0x8, 0x6, 0x2, 0x3, 0x9, 0x1, 0x7, 0xd, 0x4} }; uint32_t sbox_cvt[4*256]; for (i = 0; i < 256; ++i) { uint32_t p; p = sbox[7][i >> 4] << 4 | sbox[6][i & 15]; p = p << 24; p = p << 11 | p >> 21; sbox_cvt[i] = p; // S87 p = sbox[5][i >> 4] << 4 | sbox[4][i & 15]; p = p << 16; p = p << 11 | p >> 21; sbox_cvt[256 + i] = p; // S65 p = sbox[3][i >> 4] << 4 | sbox[2][i & 15]; p = p << 8; p = p << 11 | p >> 21; sbox_cvt[256 * 2 + i] = p; // S43 p = sbox[1][i >> 4] << 4 | sbox[0][i & 15]; p = p << 11 | p >> 21; sbox_cvt[256 * 3 + i] = p; // S21 }
تشفير البلوك هو 32 مرة كرر الجولة باستخدام المفتاح.
// input: a0 - &in, a1 - &out, a2 - &key, a3 - &sbox_cvt LEAF(gost_encrypt_block_asm) .set reorder lw n1, (a0) // n1, IN lw n2, 4(a0) // n2, IN + 4 lw t0, (a2) // key[0] -> t0 gostround n1, n2, 1 gostround n2, n1, 2 gostround n1, n2, 3 gostround n2, n1, 4 gostround n1, n2, 5 gostround n2, n1, 6 gostround n1, n2, 7 gostround n2, n1, 0 gostround n1, n2, 1 gostround n2, n1, 2 gostround n1, n2, 3 gostround n2, n1, 4 gostround n1, n2, 5 gostround n2, n1, 6 gostround n1, n2, 7 gostround n2, n1, 0 gostround n1, n2, 1 gostround n2, n1, 2 gostround n1, n2, 3 gostround n2, n1, 4 gostround n1, n2, 5 gostround n2, n1, 6 gostround n1, n2, 7 gostround n2, n1, 7 gostround n1, n2, 6 gostround n2, n1, 5 gostround n1, n2, 4 gostround n2, n1, 3 gostround n1, n2, 2 gostround n2, n1, 1 gostround n1, n2, 0 gostround n2, n1, 0 1: sw n2, (a1) sw n1, 4(a1) jr ra nop END(gost_encrypt_block_asm)
إن جدول الطاولة المستديرة هو مجرد مبادلة للجدول.
.macro gostround x_in, x_out, rkey addu t8, t0, \x_in /* key[0] + n1 = x */ lw t0, \rkey * 4 (a2) /* next key to t0 */ ext t2, t8, 24, 8 /* get bits [24,31] */ ext t3, t8, 16, 8 /* get bits [16,23] */ ext t4, t8, 8, 8 /* get bits [8,15] */ ext t5, t8, 0, 8 /* get bits [0, 7] */ sll t2, t2, 2 /* convert to dw offset */ sll t3, t3, 2 /* convert to dw offset */ sll t4, t4, 2 /* convert to dw offset */ sll t5, t5, 2 /* convert to dw offset */ addu t2, t2, a3 /* add sbox_cvt */ addu t3, t3, a3 /* add sbox_cvt */ addu t4, t4, a3 /* add sbox_cvt */ addu t5, t5, a3 /* add sbox_cvt */ lw t6, (t2) /* sbox[x[3]] -> t2 */ lw t7, 256*4(t3) /* sbox[256 + x[2]] -> t3 */ lw t9, 256*2*4(t4) /* sbox[256 *2 + x[1]] -> t4 */ lw t1, 256*3*4(t5) /* sbox[256 *3 + x[0]] -> t5 */ or t2, t7, t6 /* | */ or t3, t1, t9 /* | */ or t2, t2, t3 /* | */ xor \x_out, \x_out, t2 /* n2 ^= f(...) */ .endm
تنفيذ خوارزمية GOST 28147-89 باستخدام كتلة SIMD
تسمح لك الشفرة المقترحة أدناه بتشفير أربع كتل من 64 بت لكل 720 ns (أو ~ 350 Mbit / s) في نفس الوقت: تردد المعالج 1200 MHz ، قلب واحد.
يتم الاستبدال في رباعين وعلى الفور في 4 كتل مع تعليمات shuffle وإخفاء الأقنعة التالية.
توسيع جدول الاستبدال
for(i = 0; i < 16; ++i) { sbox_cvt_simd[i] = (sbox[7][i] << 4) | sbox[0][i]; // $w8 [7 0] sbox_cvt_simd[16 + i] = (sbox[1][i] << 4) | sbox[6][i]; // $w9 [6 1] sbox_cvt_simd[32 + i] = (sbox[5][i] << 4) | sbox[2][i]; // $w10[5 2] sbox_cvt_simd[48 + i] = (sbox[3][i] << 4) | sbox[4][i]; // $w11[3 4] }
تهيئة الأقنعة.
l0123: .int 0x0f0f0f0f .int 0xf000000f /* substitute from $w8 [7 0] mask in w12*/ .int 0x0f0000f0 /* substitute from $w9 [6 1] mask in w13*/ .int 0x00f00f00 /* substitute from $w10 [5 2] mask in w14*/ .int 0x000ff000 /* substitute from $w11 [4 3] mask in w15*/ .int 0x000f000f /* mask $w16 x N x N */ .int 0x0f000f00 /* mask $w17 N x N x */ LEAF(gost_prepare_asm) .set reorder .set msa la t1, l0123 /* masks */ lw t2, (t1) lw t3, 4(t1) lw t4, 8(t1) lw t5, 12(t1) lw t6, 16(t1) lw t7, 20(t1) lw t8, 24(t1) fill.w $w2, t2 /* 0f0f0f0f -> w2 */ fill.w $w12, t3 /* f000000f -> w12*/ fill.w $w13, t4 /* 0f0000f0 -> w13*/ fill.w $w14, t5 /* 00f00f00 -> w14*/ fill.w $w15, t6 /* 000ff000 -> w15*/ fill.w $w16, t7 /* 000f000f -> w16*/ fill.w $w17, t8 /* 0f000f00 -> w17*/ ld.b $w8, (a0) /* load sbox */ ld.b $w9, 16(a0) ld.b $w10, 32(a0) ld.b $w11, 48(a0) jr ra nop END(gost_prepare_asm)
4 كتلة التشفير
LEAF(gost_encrypt_4block_asm) .set reorder .set msa lw t1, (a0) // n1, IN lw t2, 4(a0) // n2, IN + 4 lw t3, 8(a0) // n1, IN + 8 lw t4, 12(a0) // n2, IN + 12 lw t5, 16(a0) // n1, IN + 16 lw t6, 20(a0) // n2, IN + 20 lw t7, 24(a0) // n1, IN + 24 lw t8, 28(a0) // n2, IN + 28 lw t0, (a2) // key[0] -> t0 insert.w ns1[0],t1 insert.w ns2[0],t2 insert.w ns1[1],t3 insert.w ns2[1],t4 insert.w ns1[2],t5 insert.w ns2[2],t6 insert.w ns1[3],t7 insert.w ns2[3],t8 gostround4 ns1, ns2, 1 gostround4 ns2, ns1, 2 gostround4 ns1, ns2, 3 gostround4 ns2, ns1, 4 gostround4 ns1, ns2, 5 gostround4 ns2, ns1, 6 gostround4 ns1, ns2, 7 gostround4 ns2, ns1, 0 gostround4 ns1, ns2, 1 gostround4 ns2, ns1, 2 gostround4 ns1, ns2, 3 gostround4 ns2, ns1, 4 gostround4 ns1, ns2, 5 gostround4 ns2, ns1, 6 gostround4 ns1, ns2, 7 gostround4 ns2, ns1, 0 gostround4 ns1, ns2, 1 gostround4 ns2, ns1, 2 gostround4 ns1, ns2, 3 gostround4 ns2, ns1, 4 gostround4 ns1, ns2, 5 gostround4 ns2, ns1, 6 gostround4 ns1, ns2, 7 gostround4 ns2, ns1, 7 gostround4 ns1, ns2, 6 gostround4 ns2, ns1, 5 gostround4 ns1, ns2, 4 gostround4 ns2, ns1, 3 gostround4 ns1, ns2, 2 gostround4 ns2, ns1, 1 gostround4 ns1, ns2, 0 gostround4 ns2, ns1, 0 1: copy_s.w t1,ns2[0] copy_s.w t2,ns1[0] copy_s.w t3,ns2[1] copy_s.w t4,ns1[1] copy_s.w t5,ns2[2] copy_s.w t6,ns1[2] copy_s.w t7,ns2[3] copy_s.w t8,ns1[3] sw t1, (a1) // n2, OUT sw t2, 4(a1) // n1, OUT + 4 sw t3, 8(a1) // n2, OUT + 8 sw t4, 12(a1) // n1, OUT + 12 sw t5, 16(a1) // n2, OUT + 16 sw t6, 20(a1) // n1, OUT + 20 sw t7, 24(a1) // n2, OUT + 24 sw t8, 28(a1) // n1, OUT + 28 jr ra nop END(gost_encrypt_4block_asm)
جولة باستخدام أوامر كتلة SIMD مع حساب 4 كتل في وقت واحد
.macro gostround4 x_in, x_out, rkey fill.w $w0, t0 /* key -> Vi */ addv.w $w1, $w0, \x_in /* key[0] + n1 = x */ srli.b $w3, $w1, 4 /* $w1 >> 4 */ and.v $w4, $w1, $w16 /* x 4 x 0*/ and.v $w5, $w1, $w17 /* 6 x 2 x*/ and.v $w6, $w3, $w17 /* 7 x 3 x */ and.v $w7, $w3, $w16 /* x 5 x 1 */ lw t0, \rkey * 4(a2) /* next key -> t0 */ or.v $w4, $w6, $w4 /* 7 4 3 0 */ or.v $w5, $w5, $w7 /* 6 5 2 1 */ move.v $w6, $w5 /* 6 5 2 1 */ move.v $w7, $w4 /* 7 4 3 0 */ /* 7 xx 0 */ /* 6 xx 1 */ /* x 5 2 x */ /* x 4 3 x */ vshf.b $w4, $w8, $w8 /* substitute $w8 [7 0] */ and.v $w4, $w4, $w12 vshf.b $w5, $w9, $w9 /* substitute $w9 [6 1] */ and.v $w5, $w5, $w13 vshf.b $w6, $w10, $w10 /* substitute $w10 [5 2] */ and.v $w6, $w6, $w14 vshf.b $w7, $w11, $w11 /* substitute $w11 [4 3] */ and.v $w7, $w7, $w15 or.v $w4, $w4, $w5 or.v $w6, $w6, $w7 or.v $w4, $w4, $w6 srli.w $w1, $w4, 21 /* $w4 >> 21 */ slli.w $w3, $w4, 11 /* $w4 << 11 */ or.v $w1, $w1, $w3 xor.v \x_out, \x_out, $w1 .endm
استنتاجات موجزة
يتيح استخدام كتلة SIMD لمعالج Baikal-T1 تحقيق معدل تحويل بيانات يبلغ حوالي 350 ميجابت / ثانية وفقًا لخوارزميات GOST 28147-89 ، وهي أعلى مرتين ونصف (!) من التنفيذ على الأوامر القياسية. نظرًا لأن هذا المعالج يحتوي على اثنين من النوى ، فمن الممكن نظريًا تشفير دفق بسرعة تبلغ 700 ميجابت في الثانية تقريبًا. على الأقل ، أظهر تنفيذ اختبار IPsec ، مع التشفير وفقًا لـ GOST 28147-89 ، قدرة القناة على نقل حوالي 400 ميجابت في الثانية على الوجهين.