مرحبا يا هبر!
أنا أعمل في شركة ألعاب تقوم بتطوير الألعاب عبر الإنترنت. حاليًا ، تنقسم جميع ألعابنا إلى العديد من "الأسواق" ("سوق" واحد لكل بلد) ، وفي كل "سوق" هناك عشرات العالمات التي يتم توزيع اللاعبين عليها أثناء التسجيل (جيدًا ، أو في بعض الأحيان يمكنهم اختيارها بأنفسهم). يحتوي كل عالم على قاعدة بيانات واحدة وخادم ويب / تطبيق واحد أو أكثر. وبالتالي ، يتم تقسيم الحمل وتوزيعه في جميع أنحاء العالم / الخوادم بالتساوي تقريبًا ونتيجة لذلك ، نحصل على الحد الأقصى عبر الإنترنت من مشغلات 6K-8K (هذا هو الحد الأقصى ، عدة مرات في الغالب أقل) و 200-300 طلب لكل وقت "رئيسي" لعالم واحد.
مثل هذا الهيكل مع تقسيم اللاعبين إلى الأسواق والعوالم أصبح عتيقًا ؛ اللاعبون يريدون شيئًا عالميًا. في الألعاب الأخيرة ، توقفنا عن تقسيم الأشخاص حسب البلد وتركنا سوقًا واحدًا / سوقين فقط (أمريكا وأوروبا) ، ولكن مع وجود العديد من العوالم في كل منهما. ستكون الخطوة التالية هي تطوير الألعاب باستخدام بنية جديدة وتوحيد جميع اللاعبين في عالم واحد مع
قاعدة بيانات واحدة .
أردت اليوم أن أتحدث قليلاً عن كيف تم تكليفي بالتحقق مما إذا كان الكل عبر الإنترنت (وهو ما بين 50 إلى 200 ألف مستخدم في وقت واحد) لإحدى ألعابنا الشهيرة "أرسل" للعب اللعبة التالية المبنية على البنية الجديدة وما إذا كان يمكن للنظام بأكمله ، وخاصة قاعدة البيانات (
PostgreSQL 11 ) ، أن يتحمل عملياً مثل هذا العبء ، وإذا لم يكن بإمكانه ذلك ، اكتشف أين يوجد الحد الأقصى لدينا. سوف أخبركم قليلاً عن المشاكل التي نشأت وقرارات الاستعداد لاختبار العديد من المستخدمين ، والعملية نفسها والقليل عن النتائج.
مقدمة
في الماضي ، في
InnoGames GmbH ، أنشأ كل فريق لعبة مشروع لعبة حسب ذوقهم ولونهم ، وغالبًا ما يستخدم تقنيات مختلفة ولغات البرمجة وقواعد البيانات. بالإضافة إلى ذلك ، لدينا العديد من الأنظمة الخارجية المسؤولة عن المدفوعات ، وإرسال إشعارات الدفع ، والتسويق ، وأكثر من ذلك. للعمل مع هذه الأنظمة ، أنشأ المطورون أيضًا واجهاتهم الفريدة قدر الإمكان.
يوجد حاليًا الكثير من
المال في مجال ألعاب الهاتف المحمول ، وبالتالي منافسة كبيرة. من المهم للغاية هنا استرجاعها من كل دولار يتم إنفاقه على التسويق وأكثر قليلاً من أعلاه ، وبالتالي فإن جميع شركات الألعاب غالباً ما تكون ألعاب "قريبة" حتى في مرحلة الاختبار المغلق ، إذا كانت لا تفي بالتوقعات التحليلية. وفقًا لذلك ، فإن إضاعة الوقت في اختراع العجلة التالية أمر غير مربح ، لذلك تقرر إنشاء منصة موحدة توفر للمطورين حلاً جاهزًا للتكامل مع جميع الأنظمة الخارجية ، وقاعدة بيانات تحتوي على نسخ متماثلة وجميع أفضل الممارسات. كل ما يحتاجه المطورون هو تطوير و "وضع" لعبة جيدة على رأسها وعدم إضاعة الوقت في التطوير غير المتعلق باللعبة نفسها.
تسمى هذه المنصة
GameStarter :

لذلك ، إلى هذه النقطة. سيتم بناء جميع ألعاب InnoGames المستقبلية على هذا النظام الأساسي ، الذي يحتوي على قاعدتي بيانات - الماجستير واللعبة (PostgreSQL 11). يقوم Master بتخزين المعلومات الأساسية عن اللاعبين (تسجيل الدخول وكلمة المرور وما إلى ذلك) ويشارك بشكل أساسي فقط في عملية تسجيل الدخول / التسجيل في اللعبة نفسها. اللعبة - قاعدة بيانات اللعبة نفسها ، حيث يتم تخزين جميع بيانات اللعبة وكياناتها ، والتي هي جوهر اللعبة ، حيث ستذهب العبء بالكامل.
وبالتالي ، فإن السؤال الذي يطرح نفسه هو ما إذا كانت هذه البنية بأكملها يمكن أن تصمد أمام هذا العدد المحتمل من المستخدمين مساوٍ للحد الأقصى عبر الإنترنت في واحدة من أكثر ألعابنا شعبية.
مهمة
كانت المهمة نفسها هي: التحقق مما إذا كانت قاعدة البيانات (PostgreSQL 11) ، مع تمكين النسخ المتماثل ، قادرة على تحمل جميع الأحمال التي نمتلكها حاليًا في اللعبة الأكثر تحميلًا ، مع وجود برنامج PowerEdge M630 hypervisor بالكامل (HV) تحت تصرفها.
سأوضح أن المهمة في الوقت الحالي كانت
فقط للتحقق ، باستخدام تكوينات قاعدة البيانات الحالية ، التي شكلناها مع الأخذ في الاعتبار أفضل الممارسات وتجربتنا الخاصة.
سأقول على الفور قاعدة البيانات ، والنظام بأكمله أظهر نفسه جيدًا ، باستثناء بضع نقاط. ولكن هذا المشروع الخاص بالألعاب كان في مرحلة النموذج الأولي وفي المستقبل ، مع تعقيد ميكانيكا اللعبة ، ستصبح طلبات قاعدة البيانات أكثر تعقيدًا وقد يزيد الحمل نفسه بشكل كبير وقد تتغير طبيعته. لمنع هذا ، من الضروري إجراء اختبار تكراري للمشروع مع كل معلم هام أو أكثر أهمية. أصبحت أتمتة القدرة على إجراء هذه الأنواع من الاختبارات مع مئات الآلاف من المستخدمين هي المهمة الرئيسية في هذه المرحلة.
الملف الشخصي
مثل أي اختبار الحمل ، كل شيء يبدأ مع ملف تعريف الحمل.
القيمة المحتملة CCU60 (CCU هي الحد الأقصى لعدد المستخدمين لفترة معينة من الوقت ، في هذه الحالة 60 دقيقة) تؤخذ إلى
250،000 مستخدم. عدد المستخدمين الظاهري التنافسي (VUs) أقل من CCU60 وقد اقترح المحللون أنه يمكن تقسيمها بأمان إلى قسمين. تقريب وقبول
150،000 VUs تنافسية.
تم أخذ العدد الإجمالي للطلبات في الثانية من لعبة واحدة محملة إلى حد ما:
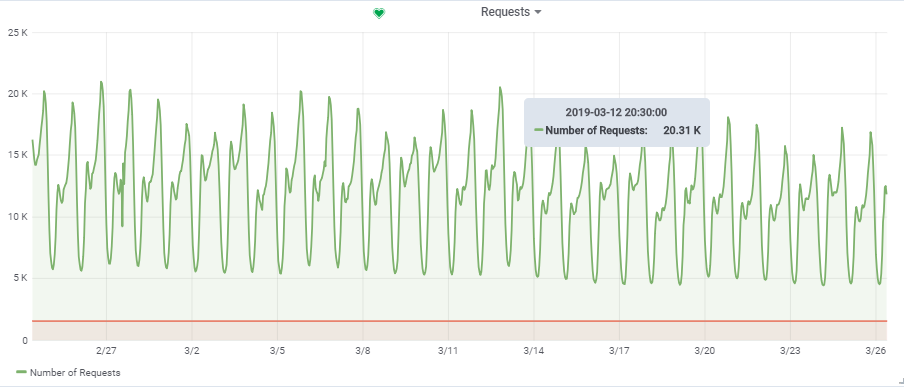
وبالتالي ، فإن حملنا المستهدف هو حوالي
20.000 طلب / ثانية عند
150،000 VU.
هيكل
خصائص "الموقف"
في
مقال سابق
، تحدثت بالفعل عن أتمتة العملية الكاملة لاختبار التحميل. علاوة على ذلك ، قد أكرر نفسي قليلاً ، لكنني سأخبرك ببعض النقاط بمزيد من التفاصيل.

في المخطط ، المربعات الزرقاء هي برامج Hypervisor (HV) الخاصة بنا ، وهي سحابة تتكون من العديد من الخوادم (Dell M620 - M640). على كل جهد عالي ، يتم إطلاق عشرات الأجهزة الظاهرية (VMs) عبر KVM (الويب / التطبيق و ديسيبل في المزيج). عند إنشاء أي VM جديد ، يحدث التوازن والبحث من خلال مجموعة معلمات HV المناسبة وليس معروفًا مبدئيًا أي خادم سيكون عليه.
قاعدة البيانات (لعبة DB):
لكن لغرضنا db1 ، قمنا بحجز جهاز HV
targer_hypervisor منفصل على أساس M630.
خصائص موجزة من targer_hypervisor:
Dell M_630
اسم الموديل: Intel® Xeon® CPU E5-2680 v3 @ 2.50GHz
وحدة المعالجة المركزية (ق): 48
خيط (ق) في الأساسية: 2
الأساسية (ق) في المقبس: 12
المقبس (ق): 2
ذاكرة الوصول العشوائي: 128 جيجابايت
دبيان جنو / لينكس 9 (امتداد)
4.9.0-8-amd64 # 1 SMP Debian 4.9.130-2 (2018-10-27)
المواصفات التفصيليةدبيان جنو / لينكس 9 (امتداد)
4.9.0-8-amd64 # 1 SMP Debian 4.9.130-2 (2018-10-27)
lscpu
العمارة: x86_64
وضع (أوضاع) وحدة المعالجة المركزية: 32 بت ، 64 بت
ترتيب البايت: Little Endian
وحدة المعالجة المركزية (ق): 48
قائمة وحدة المعالجة المركزية (CPU) على الإنترنت: 0-47
خيط (ق) في الأساسية: 2
الأساسية (ق) في المقبس: 12
المقبس (ق): 2
عقدة (NUMA): 2
معرف البائع: GenuineIntel
عائلة وحدة المعالجة المركزية: 6
النموذج: 63
اسم الموديل: Intel® Xeon® CPU E5-2680 v3 @ 2.50GHz
يخطو: 2
وحدة المعالجة المركزية ميغاهيرتز: 1309.356
وحدة المعالجة المركزية ماكس ميغاهيرتز: 3300.0000
وحدة المعالجة المركزية دقيقة ميغاهيرتز: 1200.0000
بوجومبس: 4988.42
الافتراضية: VT-x
ذاكرة التخزين المؤقت L1d: 32 كيلو
ذاكرة التخزين المؤقت L1i: 32 كيلو بايت
ذاكرة التخزين المؤقت L2: 256 كيلو
ذاكرة التخزين المؤقت L3: 30720K
NUMA node0 CPU (s): 0،2،4،6،8،10،12،14،16،18،20،22،24،26،28،30،32،34،36،36،40،42 ، 44.46
NUMA node1 CPU (s): 1،3،5،7،9،11،13،15،17،19،21،23،25،27،29،31،33،35،37،39،41،43 ، 45.47
الأعلام: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscptsts bopts bopts bts SMX بتوقيت شرق الولايات المتحدة TM2 SSSE3 sdbg FMA CX16 xtpr pdcm PCID DCA sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer AES xsave AVX f16c rdrand lahf_lm ABM EPB invpcid_single ssbd ibrs ibpb stibp كايزر tpr_shadow vnmi flexpriority EPT vpid fsgsbase tsc_adjust bmi1 AVX2 smep bmi2 ERMS invpcid CQM xsaveopt cqm_llc cqm_occup_llc dtherm المؤسسة الدولية للتنمية pts arn flush_l1d
/ usr / bin / qemu-system-x86_64 - الإصدار
QEMU emulator version 2.8.1 (Debian 1: 2.8 + dfsg-6 + deb9u5)
حقوق التأليف والنشر © 2003-2016 فابريس بيلارد ومطوري مشروع QEMU
خصائص موجزة من db1:
العمارة: x86_64
وحدة المعالجة المركزية (ق): 48
ذاكرة الوصول العشوائي: 64 جيجابايت
4.9.0-8-amd64 # 1 SMP Debian 4.9.144-3.1 (2019-02-19) x86_64 GNU / Linux
دبيان جنو / لينكس 9 (امتداد)
psql (PostgreSQL) 11.2 (Debian 11.2-1.pgdg90 + 1)
PostgreSQL التكوين مع بعض التفسيراتseq_page_cost = 1.0
random_page_cost = 1.1 # لدينا SSD
تشمل "/etc/postgresql/11/main/extension.conf"
log_line_prefix = '٪ t [٪ p-٪ l]٪ q٪ u @٪ h'
log_checkpoints = على
log_lock_waits = على
log_statement = ddl
log_min_duration_statement = 100
log_temp_files = 0
autov Vacuum_max_workers = 5
autov Vacuum_naptime = 10s
autov Vacuum_vacuum_cost_delay = 20ms
vacuum_cost_limit = 2000
maintenance_work_mem = 128 ميجابايت
التزامن = إيقاف
checkpoint_timeout = 30 دقيقة
listen_addresses = '*'
work_mem = 32 ميغابايت
effect_cache_size = 26214 ميجابايت # 50٪ من الذاكرة المتوفرة
Shared_buffers = 16384 ميجابايت # 25٪ من الذاكرة المتوفرة
max_wal_size = 15GB
min_wal_size = 80 ميغابايت
wal_level = hot_standby
max_wal_senders = 10
wal_compression = على
archive_mode = على
archive_command = '/ bin / true'
archive_timeout = 1800
hot_standby = على
wal_log_hints = على
hot_standby_feedback = على
تم إيقاف
تشغيل الإعدادات الافتراضية لـ
hot_standby_feedback ، ولكن تم تشغيلها لاحقًا ، ولكن في وقت لاحق تم إيقاف تشغيلها لإجراء اختبار ناجح. ساوضح لاحقا لماذا.
يتم تعبئة الجداول النشطة الرئيسية في قاعدة البيانات (الإنشاء ، الإنتاج ، game_entity ، الإنشاء ، core_inventory_player_resource ، الناجي) مسبقًا مع البيانات (حوالي 80 جيجابايت) باستخدام برنامج نصي للباش.
النسخ المتماثل:
SELECT * FROM pg_stat_replication; pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | backend_xmin | state | sent_lsn | write_lsn | flush_lsn | replay_lsn | write_lag | flush_lag | replay_lag | sync_priority | sync_state -----+----------+---------+---------------------+--------------+---------------------+-------------+-------------------------------+--------------+-----------+------------+------------+------------+------------+-----------------+-----------------+-----------------+---------------+------------ 759 | 17035 | repmgr | xl1db2 | xxxx | xl1db2 | 51142 | 2019-01-27 08:56:44.581758+00 | | streaming | 18/424A9F0 | 18/424A9F0 | 18/424A9F0 | 18/424A9F0 | 00:00:00.000393 | 00:00:00.001159 | 00:00:00.001313 | 0 | async 977 | 17035 | repmgr | xl1db3 |xxxxx | xl1db3 | 42888 | 2019-01-27 08:57:03.232969+00 | | streaming | 18/424A9F0 | 18/424A9F0 | 18/424A9F0 | 18/424A9F0 | 00:00:00.000373 | 00:00:00.000798 | 00:00:00.000919 | 0 | async
خادم التطبيق
ثم ، على HV الإنتاجية (prod_hypervisors) من مختلف التكوينات والقدرات ، تم إطلاق 15 خادم تطبيقات: 8 مراكز ، 4 جيجابايت. الشيء الرئيسي الذي يمكن قوله: openjdk 11.0.1 2018-10-16 ، الربيع ، والتفاعل مع قاعدة البيانات عبر
hikari (hikari.maximum-pool-size: 50)
بيئة اختبار الإجهاد
تتكون بيئة اختبار التحميل الكاملة من خادم
admin.loadtest رئيسي واحد ، والعديد من خوادم
generatorN.loadtest (في هذه الحالة كان هناك 14).
generatorN.loadtest - "العارية" VM ديبيان لينكس 9 ، مع تثبيت Java 8. 32 kernels / 32 غيغا بايت. وهي تقع على الجهد العالي "غير المنتج" ، حتى لا تقتل أداء الأجهزة الظاهرية المهمة عن طريق الخطأ.
admin.loadtest -
الجهاز الظاهري لـ Debian Linux 9 و 16
مركزًا / 16 العربات ، ويدير Jenkins و JLTC وغيرها من البرامج غير المهمة.
JLTC -
مركز اختبار تحميل jmeter . نظام في Py / Django يتحكم في تشغيل الاختبارات وأتمتة ، وكذلك تحليل النتائج.
اختبار إطلاق المخطط

تبدو عملية إجراء الاختبار كما يلي:
- تم إطلاق الاختبار من جنكينز . حدد الوظيفة المطلوبة ، ثم تحتاج إلى إدخال معلمات الاختبار المطلوبة:
- المدة - مدة الاختبار
- RAMPUP - وقت "الاحماء"
- THREAD_COUNT_TOTAL - العدد المطلوب من المستخدمين الظاهريين (VU) أو سلاسل الرسائل
- TARGET_RESPONSE_TIME هي معلمة مهمة ، حتى لا نفرط في تحميل النظام برمته بمساعدته ، فقد حددنا وقت الاستجابة المطلوب ، وبناءً على ذلك ، سيبقي الاختبار الحمل على مستوى لا يكون فيه وقت استجابة النظام بأكمله أكثر من المحدد.
- إطلاق
- جينكينز يستنسخ خطة الاختبار من Gitlab ، ويرسلها إلى JLTC.
- تعمل JLTC قليلاً مع خطة اختبار (على سبيل المثال ، إدراج كاتب CSV بسيط).
- يحسب JLTC العدد المطلوب من خوادم Jmeter لتشغيل العدد المرغوب من VUs (THREAD_COUNT_TOTAL).
- JLTC يتصل بكل مولد loadgeneratorN ويبدأ خادم jmeter.
أثناء الاختبار ، يقوم
JMeter-client بإنشاء ملف CSV بالنتائج. لذا أثناء الاختبار يزداد مقدار البيانات وحجم هذا الملف بوتيرة
مجنونة ، ولا يمكن استخدامه للتحليل بعد الاختبار -
تم اختراع البرنامج
الخفي (كتجربة) ، الذي يوزعه
"سريعًا" .
خطة الاختبار
يمكنك تنزيل خطة الاختبار
هنا .
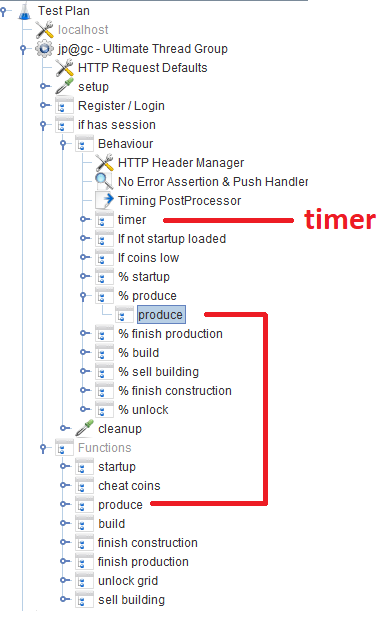
بعد التسجيل / تسجيل الدخول ، يعمل المستخدمون في الوحدة النمطية
للسلوك ، والتي تتكون من عدة
وحدات تحكم في الإنتاجية والتي تحدد احتمال وجود وظيفة لعبة معينة. في كل وحدة تحكم ، يوجد
وحدة تحكم ، والتي تشير إلى الوحدة النمطية المقابلة التي تنفذ الوظيفة.
خارج الموضوع
أثناء تطوير البرنامج النصي ، حاولنا استخدام Groovy على أكمل وجه ، وبفضل مبرمج Java الخاص بنا ، اكتشفت بعض الحيل لنفسي (ربما ستكون مفيدة لشخص ما):
فو / المواضيع
عندما يقوم المستخدم بإدخال العدد المرغوب من VUs باستخدام المعلمة THREAD_COUNT_TOTAL عند تكوين المهمة في جنكينز ، فمن الضروري أن تبدأ بطريقة ما العدد المطلوب من خوادم Jmeter وتوزيع العدد النهائي من VUs بينها. يكمن هذا الجزء في JLTC في الجزء المسمى
تحكم / توفير .
في الجوهر ، الخوارزمية هي كما يلي:
- نقسم العدد المرغوب فيه من مؤشرات ترابط VU Threads_num على 200-300 سلاسل عمليات بناءً على الحجم الملائم أكثر أو أقل -Xmsm -Xmxm تحديد قيمة الذاكرة المطلوبة لكل jmeter-server required_memory_for_jri (JRI - أدعو مثيل Jmeter عن بُعد ، بدلاً من Jmeter-server).
- من Threads_num و required_memory_for_jri ، نجد العدد الإجمالي لخادم jmeter: target_amount_jri والقيمة الإجمالية للذاكرة المطلوبة : required_memory_total .
- نقوم بالفرز بين جميع المولدات loadgeneratorN واحدًا تلو الآخر ونبدأ تشغيل أكبر عدد ممكن من خوادم jmeter استنادًا إلى الذاكرة المتوفرة عليه. طالما أن عدد مثيلات current_amount_jri قيد التشغيل لا يساوي target_amount_jri.
- (إذا كان عدد المولدات وإجمالي الذاكرة غير كافٍ ، فأضف واحدًا جديدًا إلى المجموعة)
- نحن نتصل بكل مولد ، باستخدام نتستت نتذكر جميع المنافذ المزدحمة ، ونعمل على منافذ عشوائية (غير مشغولة) بالعدد المطلوب من خوادم jmeter:
netstat_cmd= 'netstat -tulpn | grep LISTEN' stdin, stdout, stderr = ssh.exec_command(cmd1) used_ports = [] netstat_output = str(stdout.readlines()) ports = re.findall('\d+\.\d+\.\d+\.\d+\:(\d+)', netstat_output) ports_ipv6 = re.findall('\:\:\:(\d+)', netstat_output) p.wait() for port in ports: used_ports.append(int(port)) for port in ports_ipv6: used_ports.append(int(port)) ssh.close() for i in range(1, possible_jris_on_host + 1): port = int(random.randint(10000, 20000)) while port in used_ports: port = int(random.randint(10000, 20000))
- نقوم بتجميع كافة خوادم jmeter قيد التشغيل في وقت واحد في عنوان التنسيق: منفذ ، على سبيل المثال ، مولد 13: 15576 ، مولد 9: 14015 ، مولد 11: 19152 ، مولد 14: 12125 ، مولد 2: 17602
- يتم إرسال القائمة الناتجة و thread_per_host إلى عميل JMeter عند بدء الاختبار:
REMOTE_TESTING_FLAG=" -R $REMOTE_HOSTS_STRING" java -jar -Xms7g -Xmx7g -Xss228k $JMETER_DIR/bin/ApacheJMeter.jar -Jserver.rmi.ssl.disable=true -n -t $TEST_PLAN -j $WORKSPACE/loadtest.log -GTHREAD_COUNT=$THREADS_PER_HOST $OTHER_VARS $REMOTE_TESTING_FLAG -Jjmeter.save.saveservice.default_delimiter=,
في حالتنا ، تم الاختبار في وقت واحد من خوادم Jmeter 300 ، 500 خيط لكل منها ، شكل التنسيق لخادم Jmeter واحد مع معلمات Java كما يلي:
nohup java -server -Xms1200m -Xmx1200m -Xss228k -XX:+DisableExplicitGC -XX:+CMSClassUnloadingEnabled -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70 -XX:+ScavengeBeforeFullGC -XX:+CMSScavengeBeforeRemark -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -Djava.net.preferIPv6Addresses=true -Djava.net.preferIPv4Stack=false -jar "/tmp/jmeter-JwKse5nY/bin/ApacheJMeter.jar" -Jserver.rmi.ssl.disable=true "-Djava.rmi.server.hostname=generator12.loadtest.ig.local" -Duser.dir=/tmp/jmeter-JwKse5nY/bin/ -Dserver_port=13114 -s -Jpoll=49 > /dev/null 2>&1
50ms
تتمثل المهمة في تحديد مقدار قدرة قاعدة البيانات لدينا على الصمود ، بدلاً من التحميل الزائد والنظام بأكمله ككل في حالة حرجة. مع وجود العديد من خوادم Jmeter ، تحتاج إلى الحفاظ على الحمل بطريقة أو بأخرى على مستوى معين وعدم قتل النظام بأكمله. المعلمة
TARGET_RESPONSE_TIME المحددة عند بدء الاختبار مسؤولة عن ذلك. اتفقنا على أن
50 مللي ثانية هي وقت الاستجابة الأمثل الذي يجب أن يكون النظام مسؤولاً عنه.
في JMeter ، بشكل افتراضي ، هناك العديد من أجهزة ضبط الوقت المختلفة التي تسمح لك بالتحكم في الإنتاجية ، ولكن لا يُعرف مكان الحصول عليها في حالتنا. ولكن هناك
JSR223-Timer التي يمكنك من خلالها التوصل إلى شيء باستخدام
وقت استجابة النظام
الحالي . الموقت نفسه في كتلة
السلوك الرئيسية:

تحليل النتائج (الخفي)
بالإضافة إلى الرسوم البيانية في Grafana ، يجب أن يكون لديك أيضًا نتائج اختبار مجمعة بحيث يمكن مقارنة الاختبارات لاحقًا في JLTC.
يولد أحد هذه الاختبارات طلبات تتراوح من 16 إلى 20 كيلو في الثانية ، ومن السهل حساب أنه في غضون 4 ساعات يولد ملف CSV من بضع مئات غيغابايت في الحجم ، لذلك كان من الضروري الخروج بمهمة تقوم بتوزيع البيانات كل دقيقة ، وإرسالها إلى قاعدة البيانات وتنظيف الملف الرئيسي.
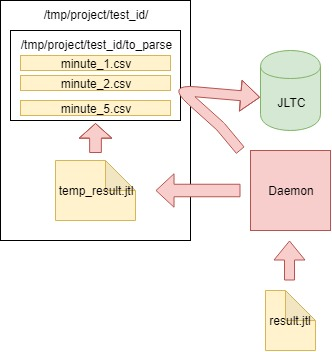
الخوارزمية هي كما يلي:
- نقرأ البيانات من ملف CSV result.jtl الذي تم إنشاؤه بواسطة jmeter-client ، وحفظه وتنظيف الملف (تحتاج إلى تنظيفه بشكل صحيح ، وإلا فإن الملف ذو المظهر الفارغ سيكون له نفس FD بنفس الحجم):
with open(jmeter_results_file, 'r+') as f: rows = f.readlines() f.seek(0) f.truncate(0) f.writelines(rows[-1])
- نكتب بيانات القراءة إلى الملف المؤقت temp_result.jtl :
rows_num = len(rows) open(temp_result_filename, 'w').writelines(rows[0:rows_num])
- نقرأ الملف temp_result.jtl . نوزع بيانات القراءة "بالدقائق":
for r in f.readlines(): row = r.split(',') if len(row[0]) == 13: ts_c = int(row[0]) dt_c = datetime.datetime.fromtimestamp(ts_c/1000) minutes_data.setdefault(dt_c.strftime('%Y_%m_%d_%H_%M'), []).append(r)
- تتم كتابة البيانات لكل دقيقة من minutes_data إلى الملف المقابل في to_parse / folder. (وبالتالي ، في الوقت الحالي ، كل دقيقة من الاختبار لها ملف بيانات خاص بها ، ثم أثناء التجميع ، لن يهم بأي ترتيب جاءت البيانات في كل ملف):
for key, value in minutes_data.iteritems():
- على طول الطريق ، نقوم بتحليل الملفات في مجلد to_parse وإذا لم يتغير أي منها خلال دقيقة واحدة ، فهذا الملف مرشح لتحليل البيانات وتجميعها وإرسالها إلى قاعدة بيانات JLTC:
for filename in os.listdir(temp_to_parse_path): data_file = os.path.join(temp_to_parse_path, filename) file_mod_time = os.stat(data_file).st_mtime last_time = (time.time() - file_mod_time) if last_time > 60: logger.info('[DAEMON] File {} was not modified since 1min, adding to parse list.'.format(data_file)) files_to_parse.append(data_file)
- إذا كان هناك مثل هذه الملفات (واحد أو عدة ملفات) ، فإننا نرسلها محللًا إلى دالة parse_csv_data (كل ملف بالتوازي):
for f in files_to_parse: logger.info('[DAEMON THREAD] Parse {}.'.format(f)) t = threading.Thread( target=parse_csv_data, args=( f, jmeter_results_file_fields, test, data_resolution)) t.start() threads.append(t) for t in threads: t.join()
يبدأ البرنامج الخفي في cron.d كل دقيقة:
يبدأ البرنامج الخفي كل دقيقة باستخدام cron.d:
* * * * * root sleep 21 && /usr/bin/python /var/lib/jltc/manage.py daemon
وبالتالي ، لا يتضخم الملف ذو النتائج إلى أحجام لا يمكن تصوره ، ولكن يتم تحليله
سريعًا وإزالته.
النتائج
التطبيق
لدينا 150،000 لاعب افتراضي:

يحاول الاختبار "مطابقة" زمن الاستجابة البالغ 50 مللي ثانية ، وبالتالي فإن الحمولة نفسها تقفز باستمرار في المنطقة بين 16 إلى 18 ألف طلب / ج:
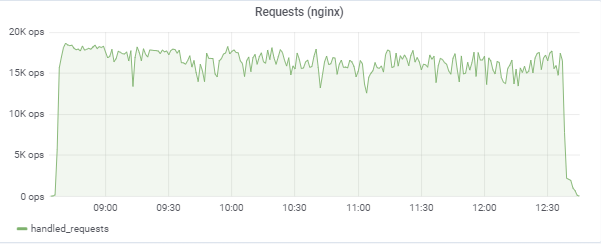
تحميل خادم التطبيق (15 تطبيق). هناك خادمان "سيئ الحظ" ليكونا على M620 أبطأ:
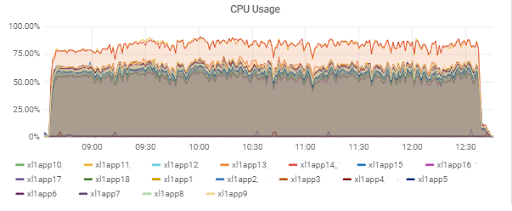
وقت استجابة قاعدة البيانات (لخوادم التطبيقات):

قاعدة بيانات
استخدام وحدة المعالجة المركزية على db1 (VM):
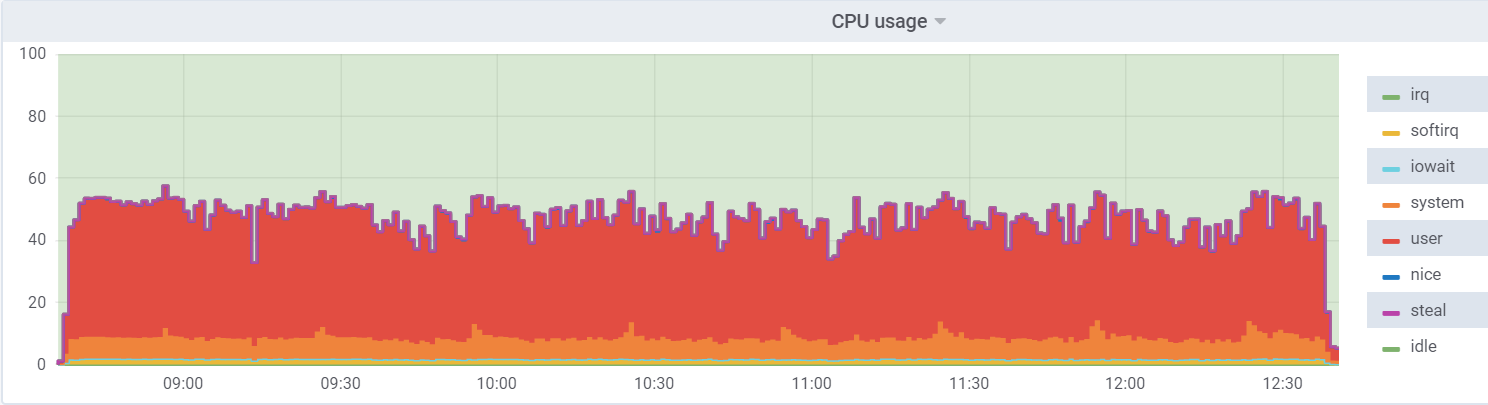
استخدام وحدة المعالجة المركزية على برنامج hypervisor:
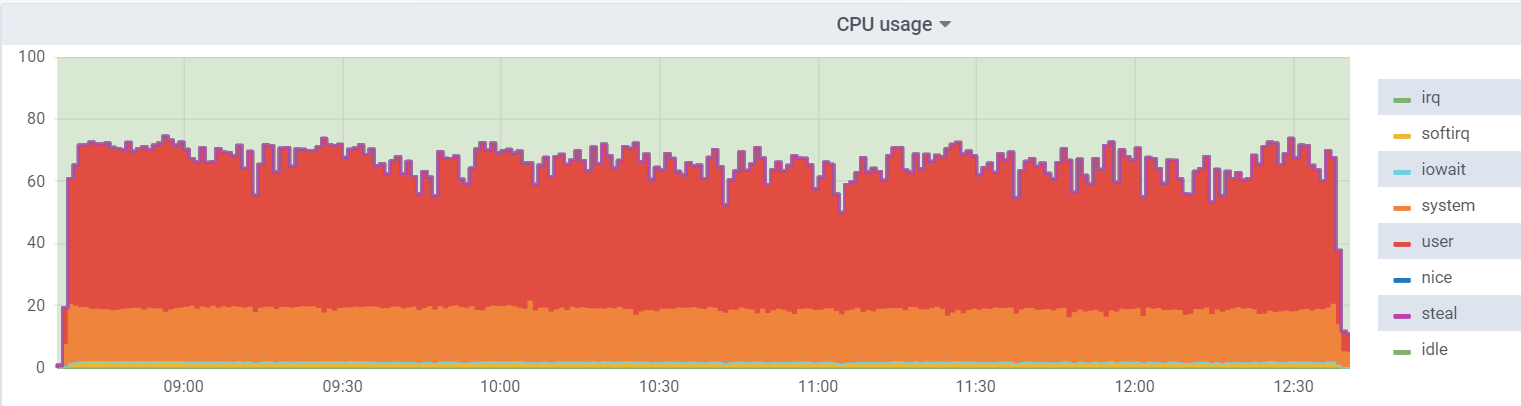
الحمل على الجهاز الظاهري أقل ، لأنه يعتقد أن لديه 48 مركزًا حقيقيًا تحت تصرفه ، في الواقع ، هناك 24
مركزًا في برنامج
hyperthreading على برنامج hypervisor.
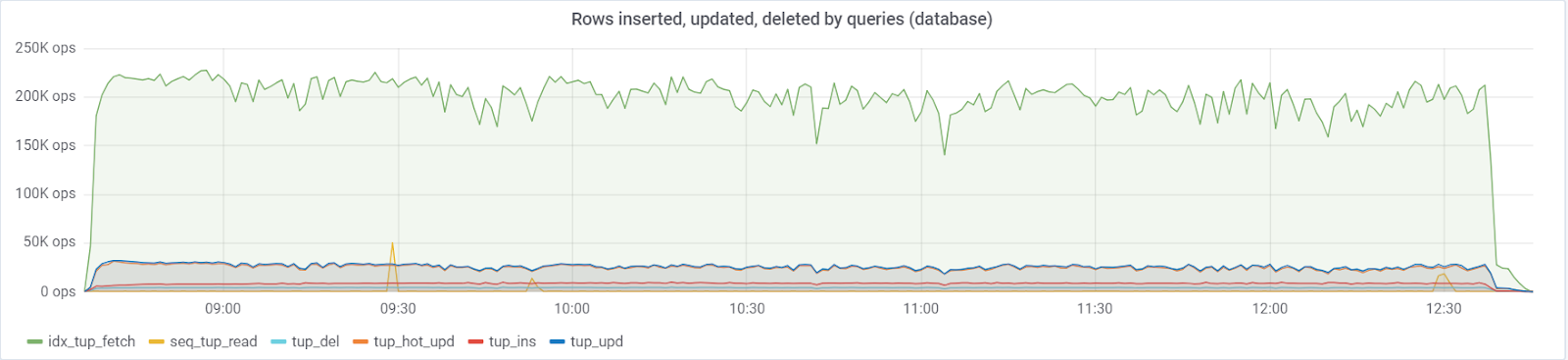
يتم توجيه ما
يصل إلى 250K / استعلامات / ثوانٍ كحد أقصى إلى قاعدة البيانات ، التي تتكون من (تحديد 83٪ ، 3٪ - إدراجات ، 11.6٪ - تحديثات (90٪ HOT) ، حذف 1.6٪):

مع القيمة الافتراضية لـ
autov Vacuum_vacuum_scale_factor = 0.2 ، نما عدد المجموعات الميتة بسرعة كبيرة مع الاختبار (مع زيادة أحجام الجدول) ، مما أدى عدة مرات إلى مشاكل قصيرة في أداء قاعدة البيانات التي دمرت الاختبار بأكمله عدة مرات. اضطررت إلى "ترويض" هذا النمو لبعض الجداول من خلال تعيين قيم شخصية لهذه المعلمة autov Vacuum_v Vacuum_scale_factor:
ALTER TABLE ... SET (autov Vacuum_v Vacuum_scale_factor = ...)ALTER TABLE construction SET (autov Vacuum_vacuum_scale_factor = 0.10)؛
ALTER TABLE production SET (autov Vacuum_vacuum_scale_factor = 0.01)؛
ALTER TABLE game_entity SET (autov Vacuum_v Vacuum_scale_factor = 0.01)؛
ALTER TABLE game_entity SET (autov Vacuum_analyze_scale_factor = 0.01)؛
ALTER TABLE building SET (autov Vacuum_vacuum_scale_factor = 0.01)؛
ALTER TABLE building SET (autov Vacuum_analyze_scale_factor = 0.01)؛
ALTER TABLE core_inventory_player_resource SET (autov Vacuum_v Vacuum_scale_factor = 0.10)؛
ALTER TABLE الناجي SET (autov Vacuum_v Vacuum_scale_factor = 0.01) ؛
ALTER TABLE الناجي SET (autov Vacuum_analyze_scale_factor = 0.01) ؛
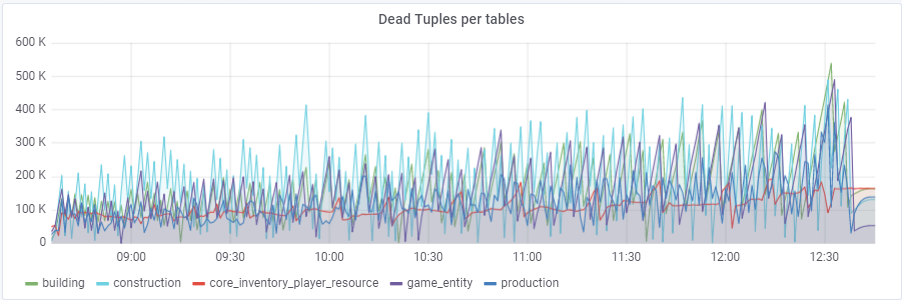
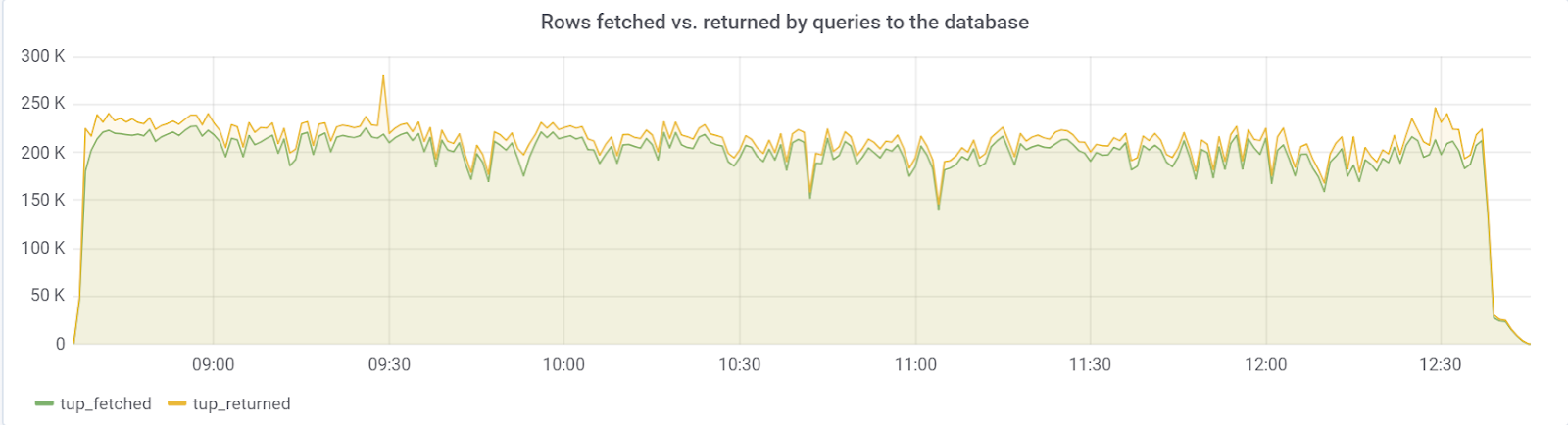
من الناحية المثالية ، يجب أن تكون الصفوف التي يتم جلبها قريبة من الصفوف ، والتي نلاحظها لحسن الحظ:
hot_standby_feedback
كانت المشكلة في المعلمة
hot_standby_feedback ، والتي يمكن أن تؤثر بشكل كبير على أداء الخادم
الرئيسي إذا لم يكن لدى خوادم
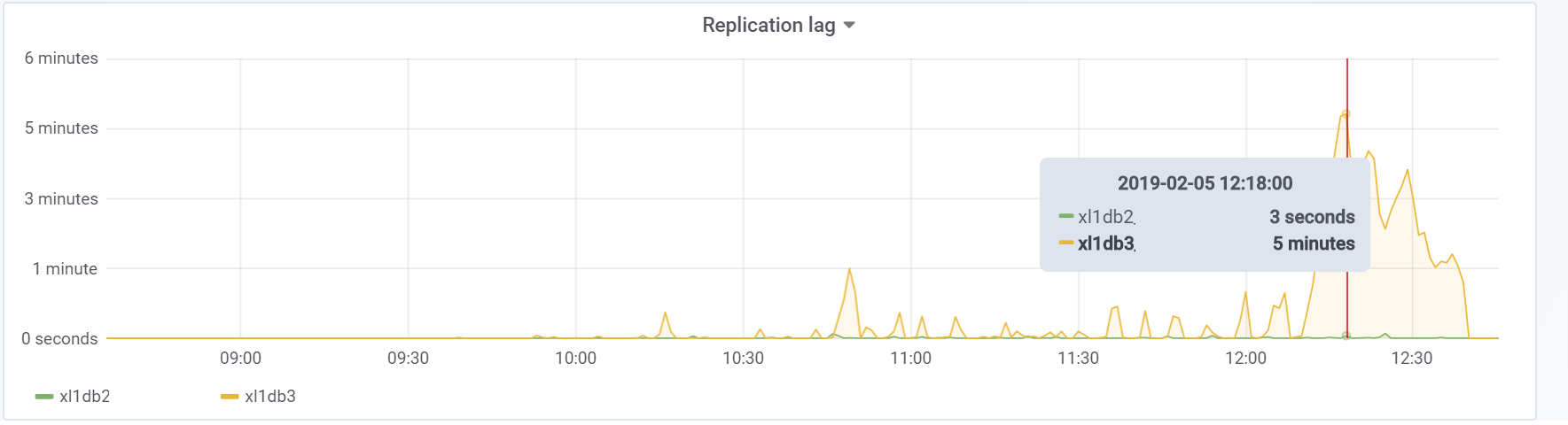
الاستعداد لديها الوقت لتطبيق التغييرات من ملفات WAL. تنص الوثائق (https://postgrespro.ru/docs/postgrespro/11/runtime-config-replication) على أنه "يحدد ما إذا كان خادم الاستعداد السريع سوف يخطر السيد أو العبد المتفوق بالطلبات التي ينفذها حاليًا." بشكل افتراضي ، يتم إيقاف تشغيله ، ولكن تم تشغيله في التكوين الخاص بنا. مما أدى إلى عواقب وخيمة ، إذا كان هناك خادومان احتياطيان وكان تأخر النسخ المتماثل أثناء التحميل يختلف عن الصفر (لأسباب مختلفة) ، يمكنك ملاحظة مثل هذه الصورة ، والتي يمكن أن تؤدي إلى انهيار الاختبار بالكامل:
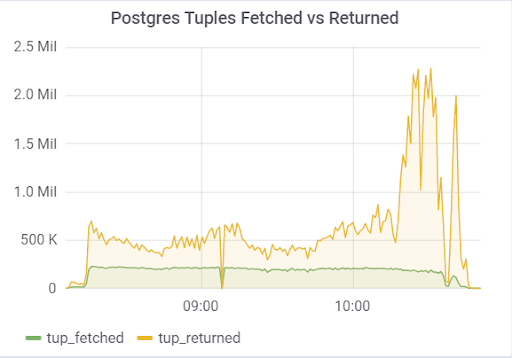

ويرجع ذلك إلى حقيقة أنه عند تمكين hot_standby_feedback ، لا ترغب VACUUM في حذف tuples إذا كانت الخوادم الاحتياطية متأخرة في معرف المعاملة الخاص بها لمنع تعارض النسخ المتماثل. المقالة المفصلة
ما الذي يفعله hot_standby_feedback في PostgreSQL حقًا :
xl1_game=# VACUUM VERBOSE core_inventory_player_resource; INFO: vacuuming "public.core_inventory_player_resource" INFO: scanned index "core_inventory_player_resource_pkey" to remove 62869 row versions DETAIL: CPU: user: 1.37 s, system: 0.58 s, elapsed: 4.20 s ………... INFO: "core_inventory_player_resource": found 13682 removable, 7257082 nonremovable row versions in 71842 out of 650753 pages <b>DETAIL: 3427824 dead row versions cannot be removed yet, oldest xmin: 3810193429</b> There were 1920498 unused item pointers. Skipped 8 pages due to buffer pins, 520953 frozen pages. 0 pages are entirely empty. CPU: user: 4.55 s, system: 1.46 s, elapsed: 11.74 s.
هذا العدد الكبير من tuples الميت يؤدي إلى الصورة الموضحة أعلاه. إليك اختباران ، مع إيقاف تشغيل hot_standby_feedback وإيقافه:
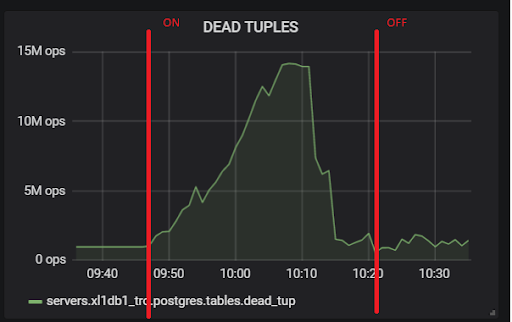
وهذا هو تأخر النسخ المتماثل أثناء الاختبار ، والذي سيكون من الضروري القيام بشيء ما في المستقبل:
استنتاج
أظهر هذا الاختبار ، لحسن الحظ (أو لسوء الحظ لمحتوى المقال) أنه في هذه المرحلة من النموذج الأولي للعبة ، من الممكن تمامًا استيعاب الحمل المرغوب من جانب المستخدمين ، وهو ما يكفي لإعطاء ضوء أخضر لمزيد من النماذج الأولية والتطوير. في المراحل اللاحقة من التطوير ، من الضروري اتباع القواعد الأساسية (للحفاظ على بساطة الاستعلامات المنفذة ، لمنع وفرة كبيرة من الفهارس ، وكذلك القراءات غير المفهرسة ، وما إلى ذلك) والأهم من ذلك ، اختبار المشروع في كل مرحلة من مراحل التطوير المهمة لإيجاد المشكلات وحلها كما يمكن أن يكون في وقت سابق. ربما سأكتب قريبًا مقالًا لأننا حللنا بالفعل مشكلات محددة.
حظا سعيدا للجميع!
لدينا
جيثب فقط في حالة ؛)