
تعد قاعدة بيانات السلاسل الزمنية (TSDB) في Prometheus 2 مثالًا رائعًا للحل الهندسي الذي يوفر تحسينات كبيرة على تخزين v2 في Prometheus 1 من حيث سرعة تخزين البيانات وتنفيذ الاستعلام ، وكفاءة الموارد. قمنا بتطبيق Prometheus 2 في Percona Monitoring and Management (PMM) ، وأتيحت لي الفرصة لفهم أداء Prometheus 2 TSDB. في هذه المقالة سأتحدث عن نتائج هذه الملاحظات.
بروميثيوس متوسط عبء العمل
بالنسبة لأولئك الذين اعتادوا على التعامل مع قواعد البيانات الأساسية ، فإن عبء العمل المعتاد في بروميثيوس فضولي للغاية. تميل سرعة تراكم البيانات إلى قيمة ثابتة: عادةً ما ترسل الخدمات التي تراقبها نفس عدد المقاييس تقريبًا ، وتتغير البنية الأساسية ببطء نسبيًا.
قد تأتي طلبات المعلومات من مصادر مختلفة. البعض منهم ، مثل التنبيهات ، يسعون أيضًا للحصول على قيمة مستقرة ويمكن التنبؤ بها. قد يتسبب آخرون ، مثل استعلامات المستخدم ، في حدوث طفرات ، على الرغم من أن هذا ليس نموذجيًا لمعظم الحمل.
اختبار الحمل
أثناء الاختبار ، ركزت على القدرة على تجميع البيانات. قمت بنشر الإصدار 2.3.2 من بروميثيوس المترجم مع Go 1.10.1 (كجزء من PMM 1.14) على خدمة Linode باستخدام هذا البرنامج النصي:
StackScript . من أجل توليد الحمل الأكثر واقعية ، باستخدام
StackScript ، أطلقت العديد من عقد MySQL مع تحميل حقيقي (Sysbench TPC-C Test) ، كل منها كان يحتذى بعقد 10 Linux / MySQL.
تم إجراء جميع الاختبارات التالية على خادم Linode بثمانية نوى افتراضية و 32 جيجا بايت من الذاكرة ، حيث تم إطلاق 20 عملية محاكاة لتحميل مائتي مثيل MySQL. أو ، وفقًا لشروط بروميثيوس ، 800 هدفًا و 440 ورقة في الثانية و 380 ألف عينة في الثانية و 1.7 مليون سلسلة زمنية نشطة.
تصميم
النهج المعتاد لقواعد البيانات التقليدية ، بما في ذلك تلك المستخدمة من قبل بروميثيوس 1.x ، هو
الحد من الذاكرة . إذا لم تكن كافية لتحمل الحمل ، فسوف تواجه تأخيرات كبيرة ولن يتم الوفاء ببعض الطلبات.
تم تكوين استخدام الذاكرة في بروميثيوس 2 باستخدام مفتاح
storage.tsdb.min-block-duration التخزين
storage.tsdb.min-block-duration ، والذي يحدد مدة تخزين السجلات في الذاكرة قبل التنظيف على القرص (بشكل افتراضي ، هذه هي ساعتان). تعتمد كمية الذاكرة المطلوبة على عدد السلاسل الزمنية والتسميات وكثافة جمع البيانات (القصاصات) إجمالاً مع دفق الإدخال الصافي. فيما يتعلق بمساحة القرص ، يهدف Prometheus إلى استخدام 3 بايت لكل سجل (نموذج). من ناحية أخرى ، متطلبات الذاكرة أعلى من ذلك بكثير.
على الرغم من أنه من الممكن تكوين حجم الكتلة ، إلا أنه لا يوصى بتكوينه يدويًا ، لذلك تواجهك الحاجة إلى إعطاء Prometheus أكبر قدر ممكن من الذاكرة التي تطلبها للتحميل.
إذا لم تكن هناك ذاكرة كافية لدعم دفق المقاييس الواردة ، فسوف تسقط بروميثيوس من نفاد الذاكرة أو سيصل قاتل OOM إليها.
لا تساعد إضافة مبادلة لتأخير التعطل عند نفاد ذاكرة بروميثيوس حقًا ، لأن استخدام هذه الميزة يؤدي إلى استهلاك ذاكرة متفجر. أعتقد أن الشيء هو Go ، جامع القمامة الخاص به وكيف يعمل مع المبادلة.
هناك طريقة أخرى مثيرة للاهتمام وهي تعيين كتلة الرأس لإعادة تعيينها على القرص في وقت محدد ، بدلاً من حسابها من بداية العملية.
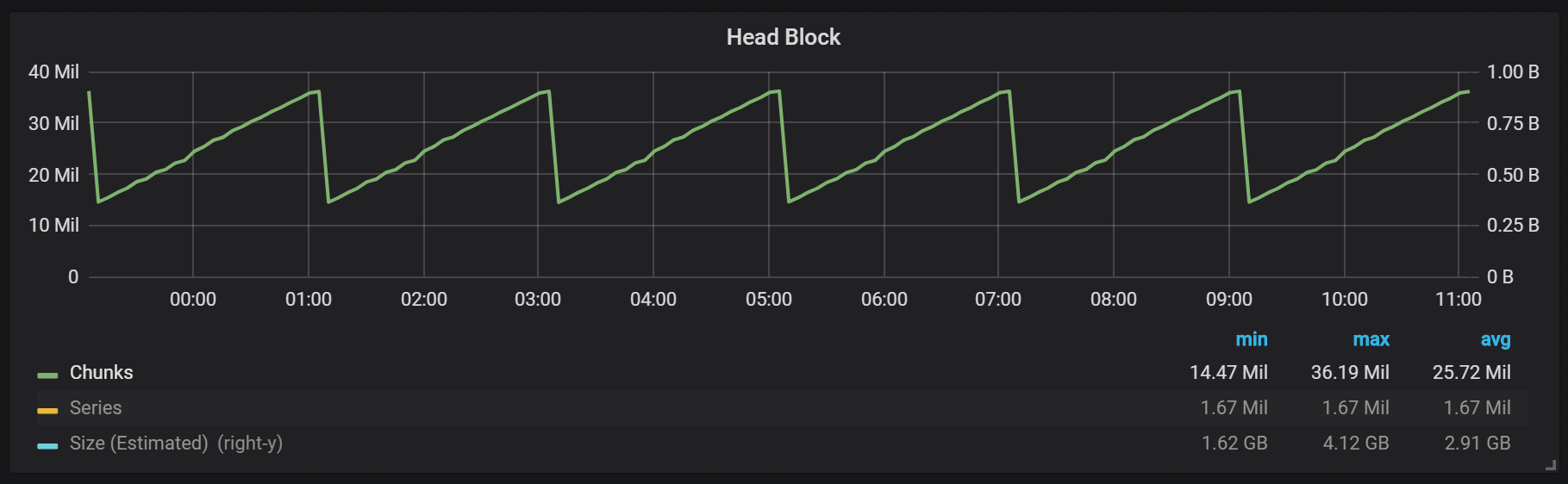
كما ترون من الرسم البياني ، يحدث تدفق القرص كل ساعتين. إذا قمت بتغيير المعلمة min-block-hour إلى ساعة واحدة ، فستحدث هذه التصريفات كل ساعة ، بدءًا من نصف ساعة.
إذا كنت تريد استخدام هذا والرسومات الأخرى في تثبيت Prometheus الخاص بك ، يمكنك استخدام لوحة القيادة هذه. تم تطويره من أجل PMM ، ولكن ، مع تعديلات طفيفة ، مناسب لأي تثبيت لـ Prometheus.لدينا كتلة نشطة تسمى كتلة الرأس ، والتي يتم تخزينها في الذاكرة. يمكن الوصول إلى كتل البيانات القديمة من خلال
mmap() . هذا يلغي الحاجة إلى تكوين ذاكرة التخزين المؤقت بشكل منفصل ، ولكن يعني أيضًا أنك بحاجة إلى ترك مساحة كافية لذاكرة التخزين المؤقت لنظام التشغيل إذا كنت تريد تقديم طلبات للبيانات أقدم من كتلة الرأس.
هذا يعني أيضًا أن استهلاك الذاكرة الظاهرية من بروميثيوس سيبدو مرتفعًا جدًا ، وهذا لا يستحق القلق.

نقطة تصميم أخرى مثيرة للاهتمام هي استخدام WAL (الكتابة قبل التسجيل). كما ترى من وثائق التخزين ، يستخدم Prometheus WAL لتجنب الخسارة بسبب السقوط. آليات محددة لضمان بقاء البيانات ، للأسف ، ليست موثقة جيدا. يقوم الإصدار 2.3.2 من بروميثيوس بمسح WAL إلى القرص كل 10 ثوانٍ ، وهذه المعلمة غير قابلة للتكوين بواسطة المستخدم.
الأختام (ضغط)
تم تصميم Prometheus TSDB في صورة مستودع LSM (Log Structured merge - شجرة بنية مهيكلة مع دمج): يتم إزاحة كتلة الرأس بشكل دوري إلى القرص ، بينما تجمع آلية الضغط عدة كتل معًا لمنع مسح الكثير من الكتل أثناء الطلبات. هنا يمكنك رؤية عدد القطع التي لاحظتها على نظام الاختبار بعد يوم عمل.
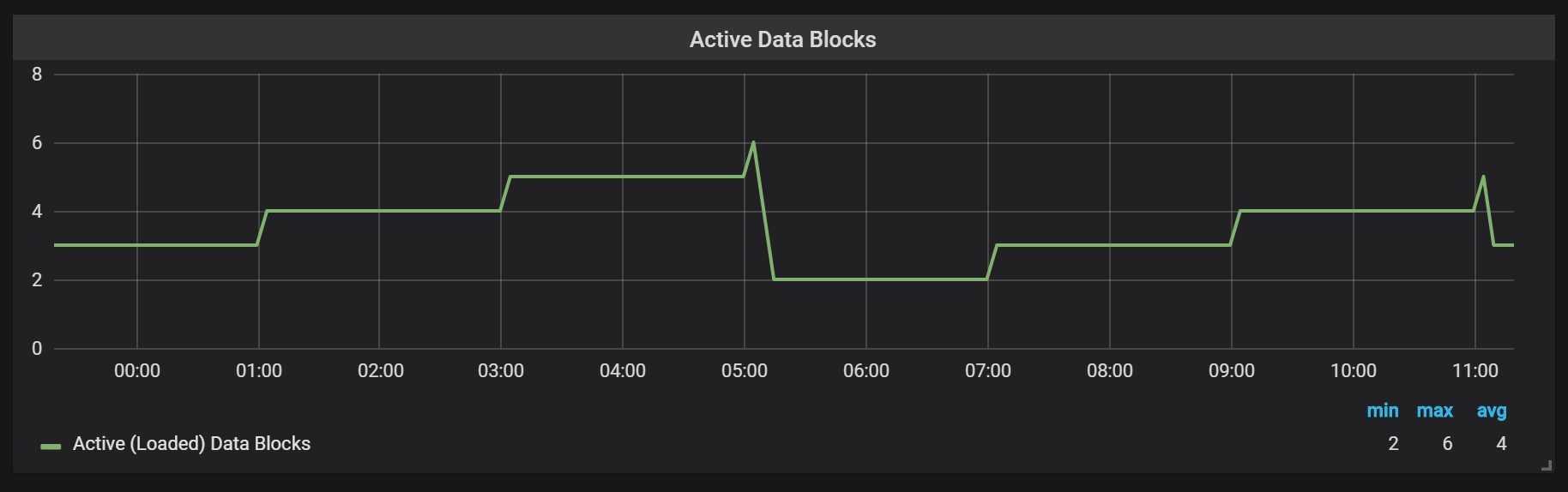
إذا كنت تريد معرفة المزيد عن المستودع ، فيمكنك دراسة ملف meta.json ، الذي يحتوي على معلومات حول الكتل المتاحة وكيفية ظهورها.
{ "ulid": "01CPZDPD1D9R019JS87TPV5MPE", "minTime": 1536472800000, "maxTime": 1536494400000, "stats": { "numSamples": 8292128378, "numSeries": 1673622, "numChunks": 69528220 }, "compaction": { "level": 2, "sources": [ "01CPYRY9MS465Y5ETM3SXFBV7X", "01CPYZT0WRJ1JB1P0DP80VY5KJ", "01CPZ6NR4Q3PDP3E57HEH760XS" ], "parents": [ { "ulid": "01CPYRY9MS465Y5ETM3SXFBV7X", "minTime": 1536472800000, "maxTime": 1536480000000 }, { "ulid": "01CPYZT0WRJ1JB1P0DP80VY5KJ", "minTime": 1536480000000, "maxTime": 1536487200000 }, { "ulid": "01CPZ6NR4Q3PDP3E57HEH760XS", "minTime": 1536487200000, "maxTime": 1536494400000 } ] }, "version": 1 }
الأختام في بروميثيوس مرتبطة بالوقت الذي تم فيه طرد كتلة الرأس إلى القرص. في هذه المرحلة ، قد يتم تنفيذ العديد من هذه العمليات.
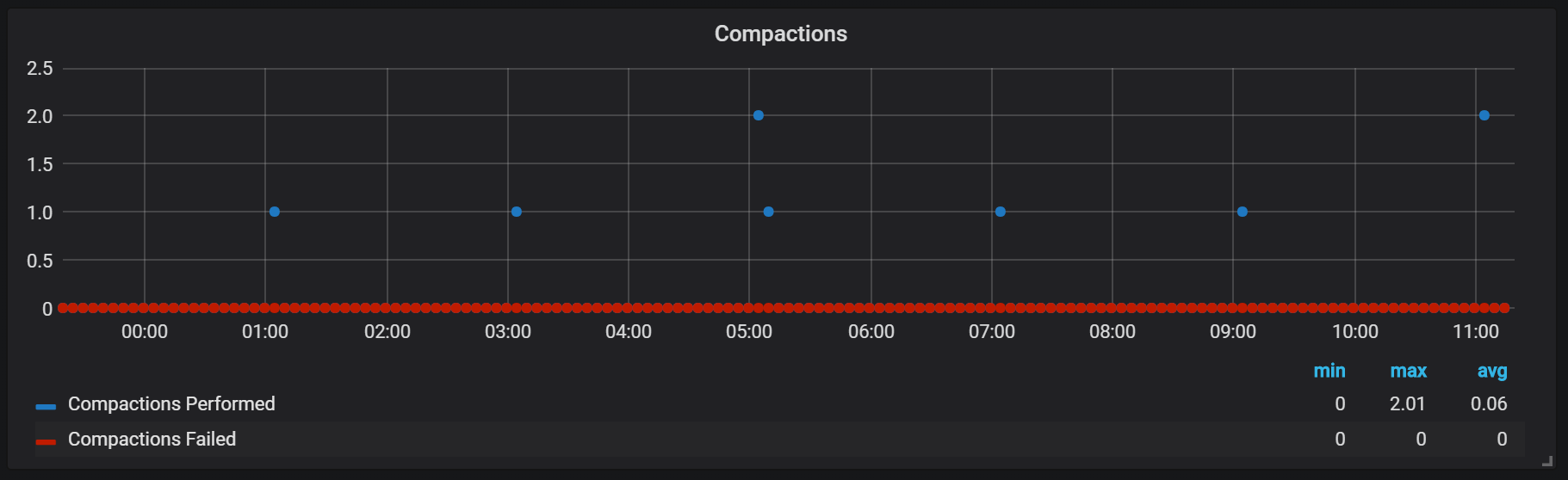
من الواضح أن الأختام غير محدودة بأي شكل من الأشكال ويمكن أن تتسبب في حدوث قفزات كبيرة في إدخال / إخراج القرص في وقت التشغيل.

وحدة المعالجة المركزية تحميل المسامير

بالطبع ، يؤثر هذا سلبًا على سرعة النظام ، كما أنه يمثل تحديًا خطيرًا لتخزين LSM: كيفية عمل أختام لدعم سرعات الاستعلام العالية وعدم التسبب في الكثير من النفقات العامة؟
استخدام الذاكرة في عملية الضغط يبدو أيضًا مثيرًا للاهتمام.

يمكننا أن نرى كيف ، بعد الضغط ، تحدث معظم التغييرات في الذاكرة من نسخة مخبأة إلى حرة: وهذا يعني أنه قد تمت إزالة المعلومات ذات القيمة المحتملة من هناك. من الغريب أن يتم استخدام
fadvice() أو بعض أساليب
fadvice() الأخرى هنا ، أم أنه ناتج عن حقيقة أن ذاكرة التخزين المؤقت قد تم تحريرها من كتل تم تدميرها أثناء الضغط؟
تحطم الانتعاش
يستغرق التعافي من الكوارث وقتًا ، وهو أمر مبرر. لدفق وارد من مليون سجل في الثانية الواحدة ، اضطررت إلى الانتظار حوالي 25 دقيقة أثناء إجراء الاسترداد مع مراعاة محرك SSD.
level=info ts=2018-09-13T13:38:14.09650965Z caller=main.go:222 msg="Starting Prometheus" version="(version=2.3.2, branch=v2.3.2, revision=71af5e29e815795e9dd14742ee7725682fa14b7b)" level=info ts=2018-09-13T13:38:14.096599879Z caller=main.go:223 build_context="(go=go1.10.1, user=Jenkins, date=20180725-08:58:13OURCE)" level=info ts=2018-09-13T13:38:14.096624109Z caller=main.go:224 host_details="(Linux 4.15.0-32-generic #35-Ubuntu SMP Fri Aug 10 17:58:07 UTC 2018 x86_64 1bee9e9b78cf (none))" level=info ts=2018-09-13T13:38:14.096641396Z caller=main.go:225 fd_limits="(soft=1048576, hard=1048576)" level=info ts=2018-09-13T13:38:14.097715256Z caller=web.go:415 component=web msg="Start listening for connections" address=:9090 level=info ts=2018-09-13T13:38:14.097400393Z caller=main.go:533 msg="Starting TSDB ..." level=info ts=2018-09-13T13:38:14.098718401Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536530400000 maxt=1536537600000 ulid=01CQ0FW3ME8Q5W2AN5F9CB7R0R level=info ts=2018-09-13T13:38:14.100315658Z caller=web.go:467 component=web msg="router prefix" prefix=/prometheus level=info ts=2018-09-13T13:38:14.101793727Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536732000000 maxt=1536753600000 ulid=01CQ78486TNX5QZTBF049PQHSM level=info ts=2018-09-13T13:38:14.102267346Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536537600000 maxt=1536732000000 ulid=01CQ78DE7HSQK0C0F5AZ46YGF0 level=info ts=2018-09-13T13:38:14.102660295Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536775200000 maxt=1536782400000 ulid=01CQ7SAT4RM21Y0PT5GNSS146Q level=info ts=2018-09-13T13:38:14.103075885Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536753600000 maxt=1536775200000 ulid=01CQ7SV8WJ3C2W5S3RTAHC2GHB level=error ts=2018-09-13T14:05:18.208469169Z caller=wal.go:275 component=tsdb msg="WAL corruption detected; truncating" err="unexpected CRC32 checksum d0465484, want 0" file=/opt/prometheus/data/.prom2-data/wal/007357 pos=15504363 level=info ts=2018-09-13T14:05:19.471459777Z caller=main.go:543 msg="TSDB started" level=info ts=2018-09-13T14:05:19.471604598Z caller=main.go:603 msg="Loading configuration file" filename=/etc/prometheus.yml level=info ts=2018-09-13T14:05:19.499156711Z caller=main.go:629 msg="Completed loading of configuration file" filename=/etc/prometheus.yml level=info ts=2018-09-13T14:05:19.499228186Z caller=main.go:502 msg="Server is ready to receive web requests."
المشكلة الرئيسية في عملية الاسترداد هي ارتفاع استهلاك الذاكرة. على الرغم من حقيقة أنه في الحالة العادية ، يمكن أن يعمل الخادم بثبات مع نفس مقدار الذاكرة ، وعندما يتعطل ، قد لا يرتفع بسبب OOM. كان الحل الوحيد الذي وجدته هو تعطيل جمع البيانات ، ورفع الخادم ، والسماح له بالتعافي وإعادة التشغيل باستخدام المجموعة الموجودة بالفعل.
الاحماء
السلوك الآخر الذي يجب تذكره أثناء عملية الاحماء هو نسبة الإنتاجية المنخفضة واستهلاك الموارد المرتفع مباشرة بعد البداية. خلال بعض ، ولكن ليس كل شيء يبدأ ، لاحظت حمولة خطيرة على وحدة المعالجة المركزية والذاكرة.
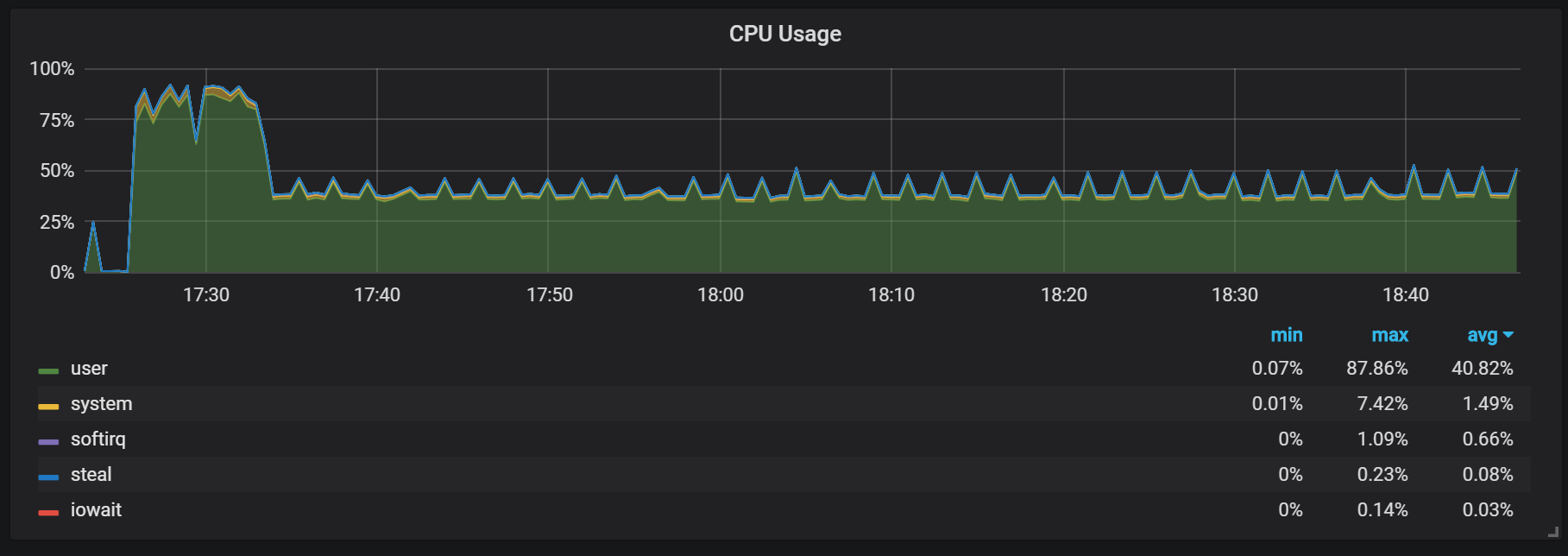

تشير الهفوات في الذاكرة إلى أن بروميثيوس لا يمكنه تكوين جميع الرسوم من البداية ، وأنه يتم فقد بعض المعلومات.
لم أجد الأسباب الدقيقة للتحميل الكبير على المعالج والذاكرة. أظن أن هذا يرجع إلى إنشاء سلسلة زمنية جديدة في كتلة الرأس بتردد عالٍ.
المسامير تحميل وحدة المعالجة المركزية
بالإضافة إلى الأختام ، التي تنشئ حمولة إدخال / إخراج عالية إلى حد ما ، لاحظت قفزات خطيرة في الحمل على المعالج كل دقيقتين. تستمر الانفجارات لفترة أطول مع تدفق وارد عالي ويبدو أنها ناتجة عن أداة تجميع مجمعي البيانات المهملة Go ، على الأقل يتم تحميل بعض النواة بالكامل.

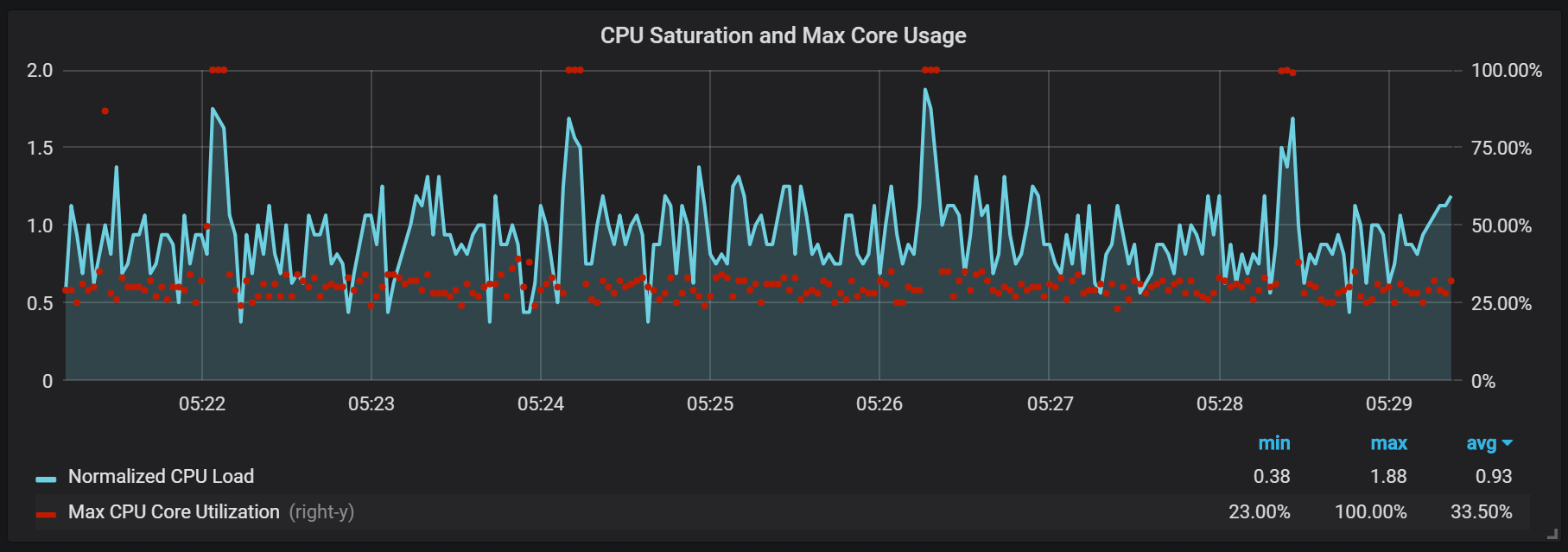
هذه القفزات ليست ذات أهمية كبيرة. يبدو أنه عند حدوثها ، يتعذر الوصول إلى نقطة الإدخال الداخلية ومقاييس Prometheus ، مما يؤدي إلى حدوث فجوات في البيانات في الفواصل الزمنية نفسها.
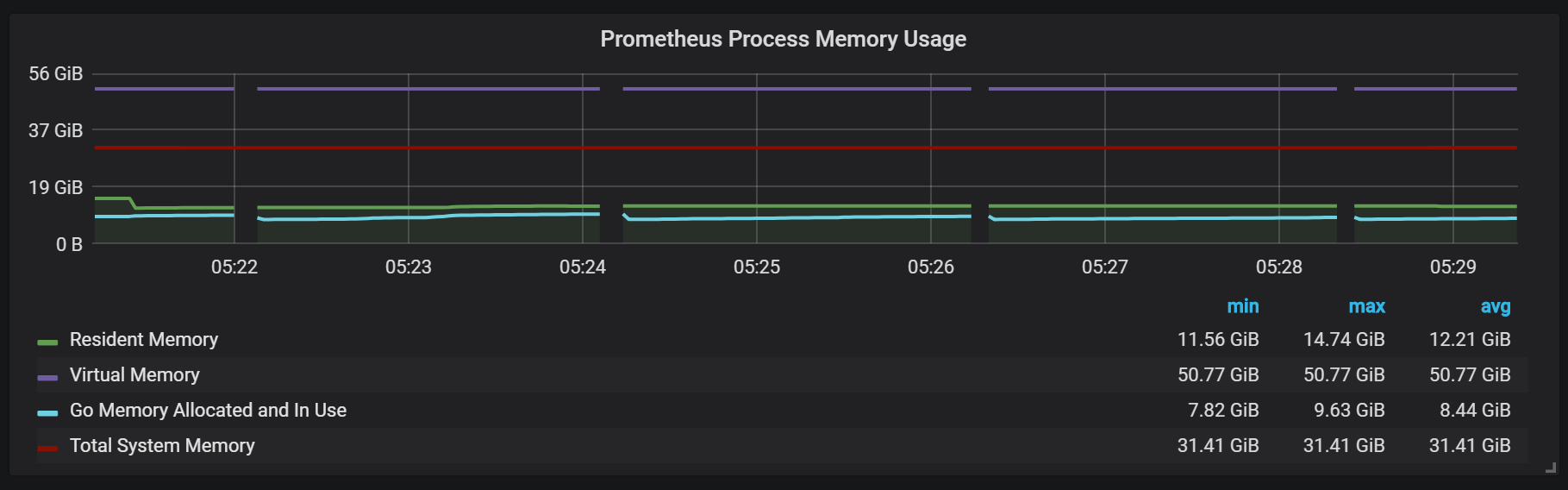
يمكنك أيضًا ملاحظة أن مصدر Prometheus يغلق لمدة ثانية واحدة.
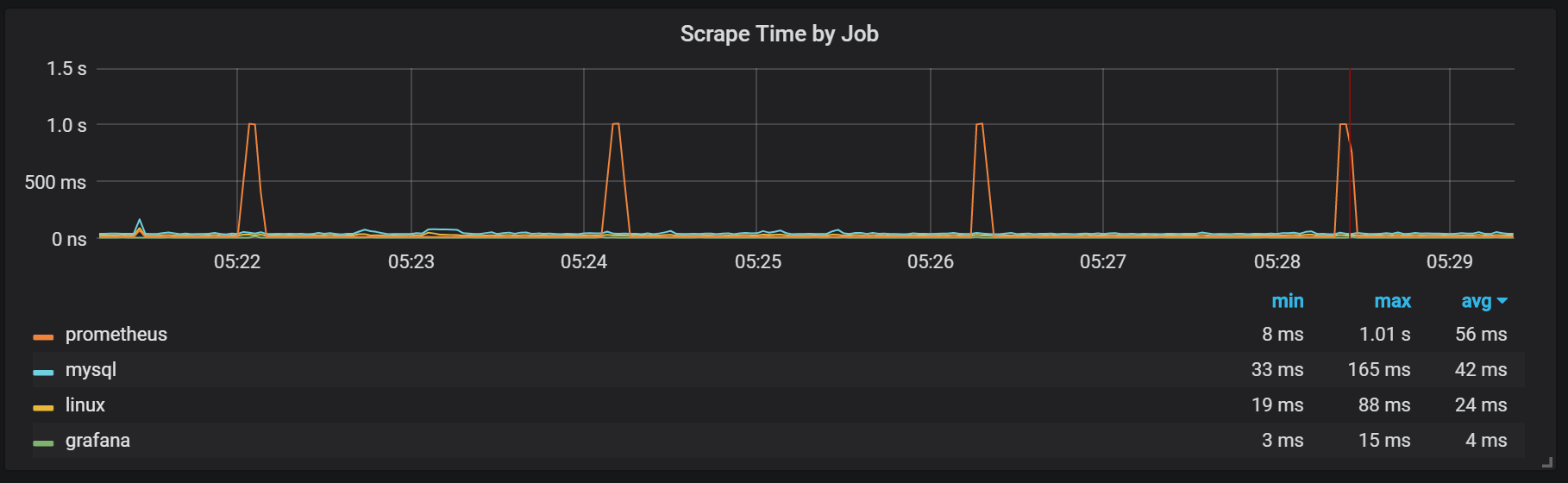
يمكننا أن نرى العلاقات مع جمع القمامة (GC).

استنتاج
TSDB في بروميثيوس 2 سريع وقادر على التعامل مع الملايين من السلاسل الزمنية وفي الوقت نفسه مع الآلاف من التسجيلات في الثانية باستخدام أجهزة متواضعة إلى حد ما. استخدام وحدة المعالجة المركزية والقرص I / O مثير للإعجاب أيضا. المثال الخاص بي أظهر ما يصل إلى 200000 مقاييس في الثانية لكل نواة مستخدمة.
للتخطيط للامتداد ، يجب أن تتذكر ما يكفي من وحدات تخزين الذاكرة ، وينبغي أن تكون هذه ذاكرة حقيقية. كان مقدار الذاكرة المستخدمة التي لاحظتها حوالي 5 غيغابايت لكل 100000 إدخال في الثانية من الدفق الوارد ، والذي تم دمجه مع ذاكرة التخزين المؤقت لنظام التشغيل حوالي 8 غيغابايت من الذاكرة المشغولة.
بالطبع ، لا يزال هناك الكثير من العمل لترويض رشقات وحدة المعالجة المركزية والقرص I / O ، وهذا ليس مفاجئًا بالنظر إلى كيفية مقارنة TSDB Prometheus 2 مع InnoDB و TokuDB و RocksDB و WiredTiger ، لكنهم جميعًا واجهوا مشكلات مماثلة في بداية دورة الحياة.