عند العمل مع العديد من العملاء في وقت واحد ، يصبح من الضروري تحليل الكثير من المعلومات بسرعة في حسابات وتقارير مختلفة. عندما يكون هناك أكثر من 10 عملاء ، لم يعد لدى المسوق وقت لمراقبة الإحصاءات باستمرار. ولكن هناك طريقة.
في هذه المقالة ، سأتحدث عن كيفية مراقبة حسابات الإعلانات باستخدام API و Python.
عند الخروج ، سوف نتلقى طلبًا إلى Yandex.Direct API ، حيث نتلقى إحصاءات حول الحملات الإعلانية وسنكون قادرين على معالجة هذه البيانات.
لهذا نحتاج:
- احصل على Yandex Direct API Token
- اكتب طلب خادم
- استيراد البيانات إلى DataFrame
استيراد المكتبات
تحتاج إلى استيراد المكتبات المستخدمة في الاستعلام ، وكذلك الباندا و DataFrame.
ستبدو جميع الواردات كما يلي:
import requests from requests.exceptions import ConnectionError from time import sleep import json import pandas as pd import numpy as np from pandas import Series,DataFrame
تلقي الرمز المميز
في هذه اللحظة ، لا يمكنني معرفة أفضل من وثائق واجهة برمجة تطبيقات Direct ، لذلك سأترك رابطًا.
(
تعليمات للحصول على رمز مميز )
نكتب طلبًا إلى خادم واجهة برمجة تطبيقات Yandex.Direct
انسخ الطلب من وثائق APIتغيير الطلب.- يصف الرمز المميز الخاص بك وتسجيل الدخول
رمزية.
الرمز المميز = 'blaBlaBLAblaBLABLABLAblabla'
تسجيل الدخول.
clientLogin = 'e-66666666'
- نحن ضبط الجسم طلب لأنفسنا.
من هذا
body = { "params": { "SelectionCriteria": { "DateFrom": "_", "DateTo": "_" }, "FieldNames": [ "Date", "CampaignName", "LocationOfPresenceName", "Impressions", "Clicks", "Cost" ], "ReportName": u("_"), "ReportType": "CAMPAIGN_PERFORMANCE_REPORT", "DateRangeType": "CUSTOM_DATE", "Format": "TSV", "IncludeVAT": "NO", "IncludeDiscount": "NO"
افعلها
body = { "params": { "SelectionCriteria": { "Filter": [ { "Field": "Clicks", "Operator": "GREATER_THAN", "Values": [ "0" ] }, ] }, "FieldNames": [ "CampaignName", "Impressions", "Clicks", "Ctr", "Cost", "AvgCpc", "BounceRate", "AvgPageviews", "ConversionRate", "CostPerConversion", "Conversions" ], "ReportName": u("Report4"), "ReportType": « ", "DateRangeType": "LAST_5_DAYS", "Format": "TSV", "IncludeVAT": "NO", "IncludeDiscount": "NO" } }
في
SelectionCriteria نكتب كيف سنختار البيانات. بشكل افتراضي ، يتم كتابة تاريخين هناك ، ولكن حتى لا تضطر إلى تغييرها باستمرار ، سنستبدل الفترة الزمنية بـ "آخر 5 أيام".
وضعنا مرشح للبيانات . هذا مطلوب بشكل أساسي حتى لا تحصل على قيم فارغة. المشكلة هي أن Direct يعرض البيانات المفقودة كطرفين ، وبسبب ذلك يتغير نوع بيانات العمود بأكمله ، وبعد ذلك لا يمكنك إجراء عمليات رياضية دون إيماءات غير ضرورية.
FieldNames. نكتب هنا البيانات التي تحتاجها. لقد سجلت الحقول التي أستخدمها للتحليل ، قد تختلف قائمتك.
REPORTTYPE. نوع التقرير مكتوب في هذا الحقل ، أما بالنسبة للحملات التي يحتاج إليها هذا التقرير.
يجب أن تحصل على شيء مثل هذا.
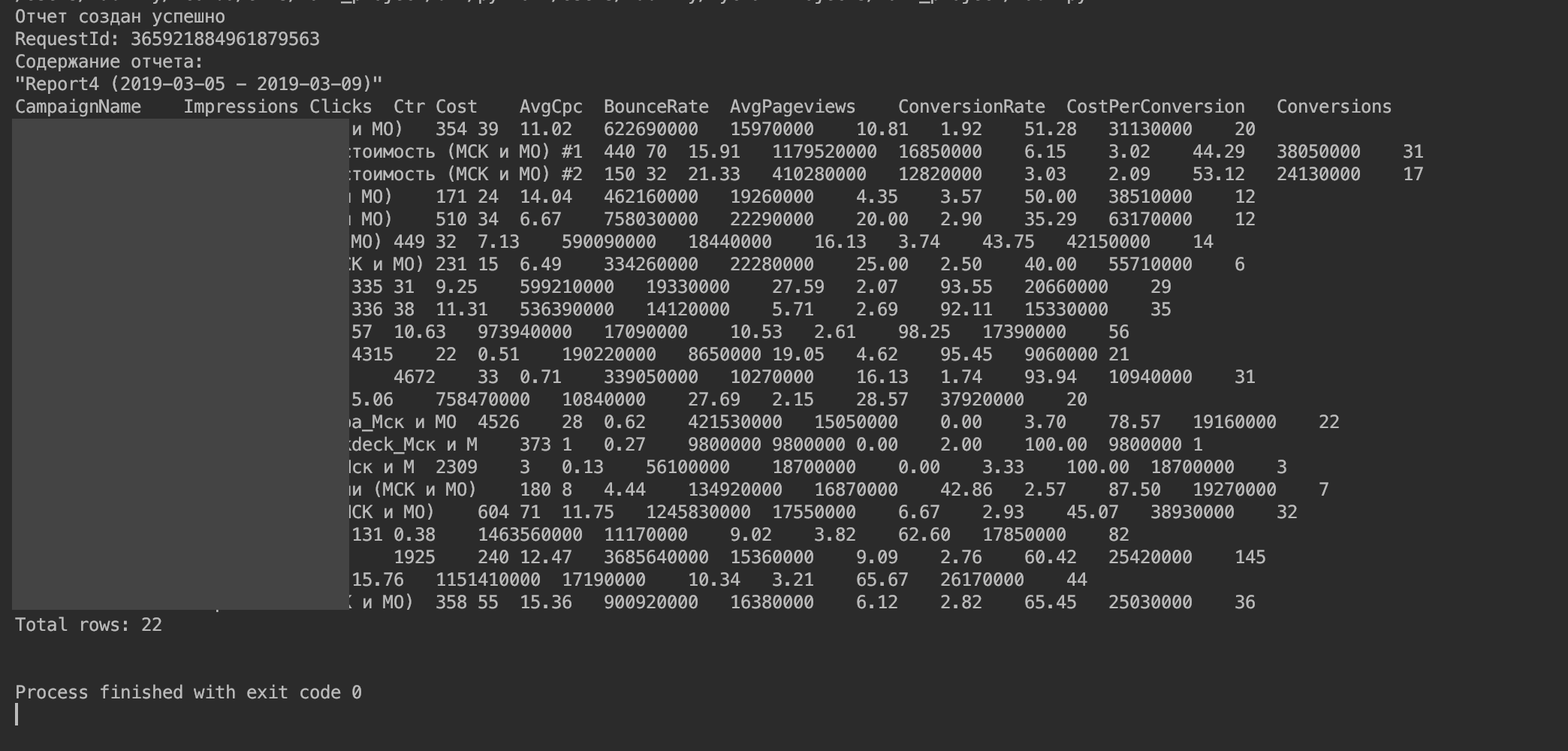
5. استيراد البيانات إلى DataFrame.
(ربما تكون DataFrame هي أنسب طريقة للتعامل مع هذه البيانات.)
كنت قادرا على تنفيذ هذه الوظيفة عن طريق كتابة وقراءة ملف CSV.
نجد في الاستعلام القطعة المسؤولة عن إخراج الإحصاءات - هذا هو "req.text".
نقوم بحذف الإخراج القياسي للبرنامج للكتابة إلى الملف. للقيام بذلك ، قم بتغيير كافة الاستنتاجات في التعليمات البرمجية 200.
print(" ") print("RequestId: {}".format(req.headers.get("RequestId", False))) print(" : \n{}».format(u(req.text)))
إلى:
format(u(req.text))
الآن استيراد استجابة الخادم في DataFrame.
file = open("cashe.csv", "w") file.write(req.text) file.close() f = DataFrame.from_csv("cashe.csv",header=1, sep=' ', index_col=0,)
خطوة بخطوة:
- افتح (وقم بإنشاء ملف cashe.csv تلقائيًا للكتابة)
- نكتب استجابة الخادم في ذلك
- أغلق الملف
- افتح الملف كـ DataFrame (حدد اسم الملف ، في أي صف هي رؤوس الجدول ، ما هو الفاصل بين البيانات ، وفي أي عمود يوجد الفهرس)
اتضح ما يلي:
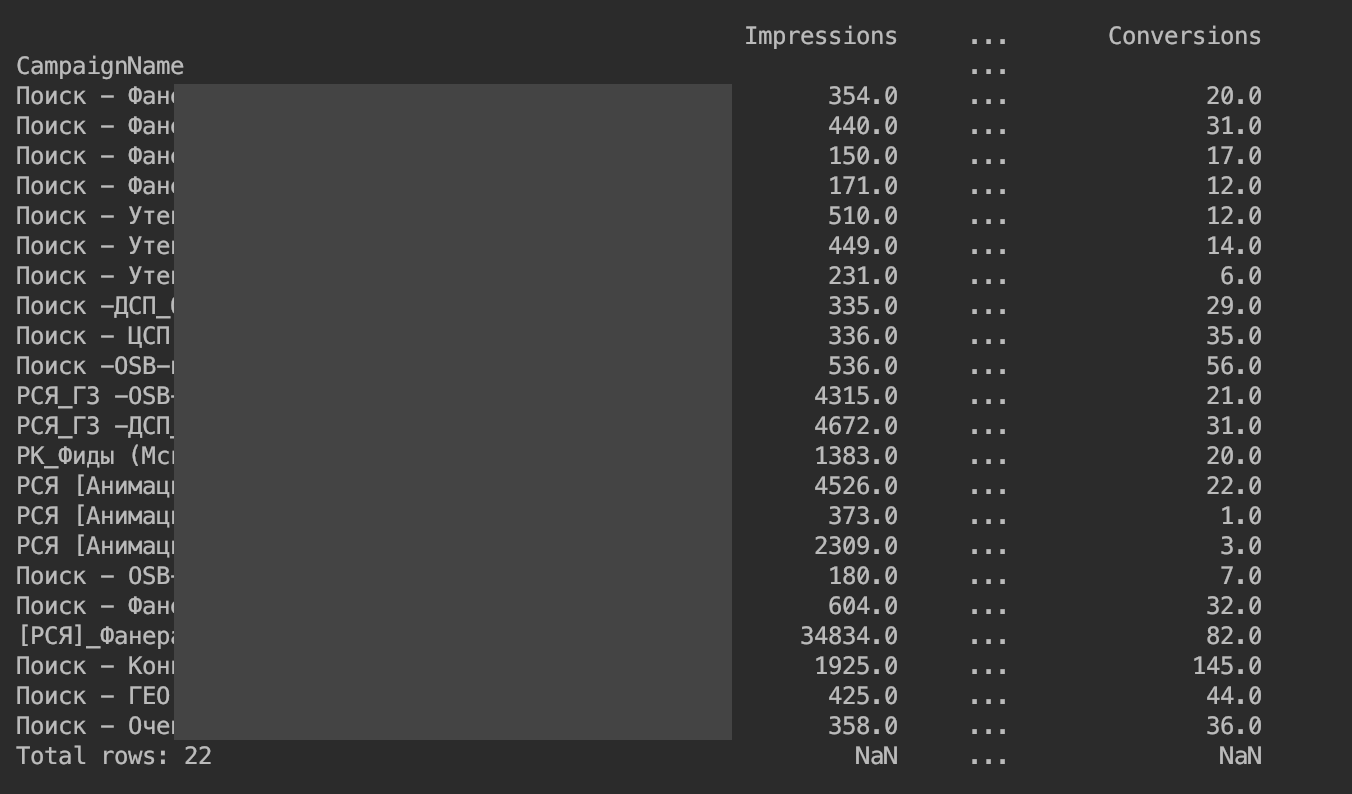
نزيل القيود المفروضة على إخراج الأعمدة:
pd.set_option('display.max_columns', None) pd.set_option('display.expand_frame_repr', False) pd.set_option('max_colwidth', -1)
الآن يظهر كل شيء:
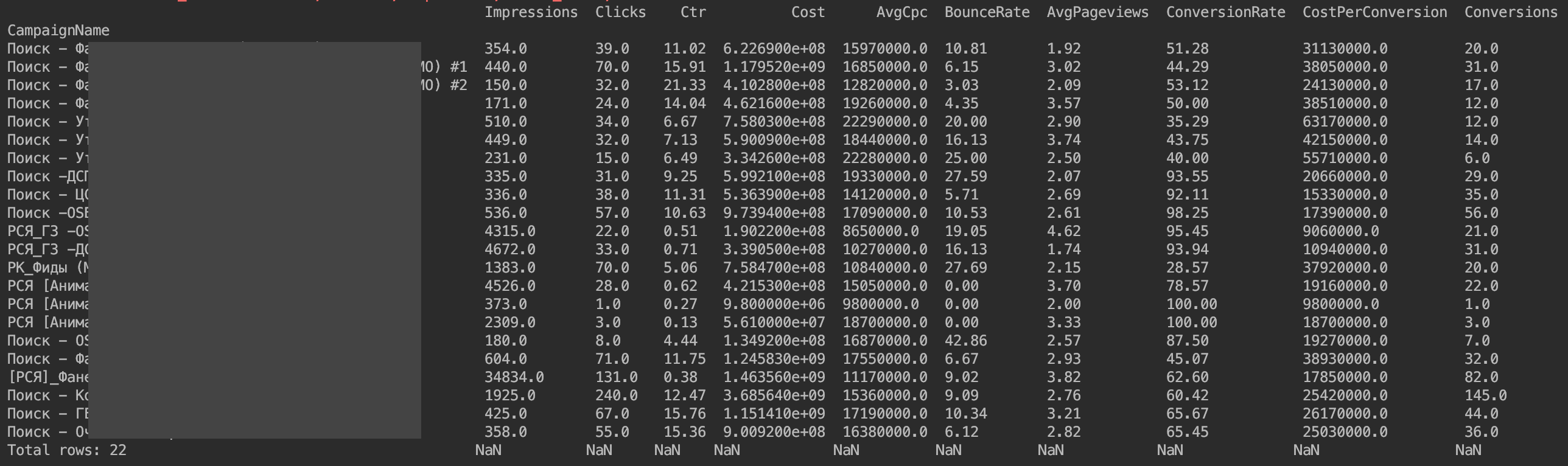
المشكلة الوحيدة هي أن القيم النقدية لا تظهر كما تريد. هذه هي ميزات تطبيق Yandex.Direct API. نحتاج فقط إلى تقسيم القيم النقدية على 1،000،000.
f['Cost'] = f['Cost']/1000000 f['AvgCpc'] = f['AvgCpc']/1000000 f['CostPerConversion'] = f['CostPerConversion']/1000000
أقترح أيضًا الفرز فورًا بعدد النقرات
f=f.sort_values(by=['Clicks'], ascending=False)
لذلك أصبحنا DataFrame جاهزين للتحليل
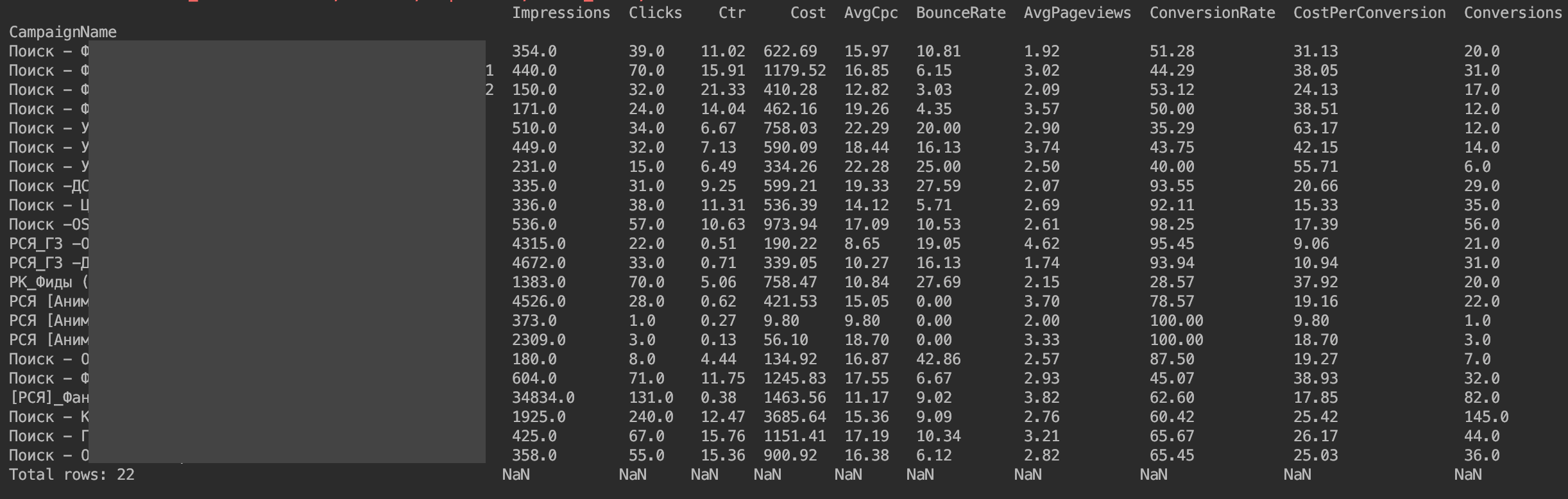
بالنسبة إليّ ، كتبت طلبات مماثلة للإحصائيات كل يوم وحسب الحملة ، حتى أكون دائمًا على دراية بالانحرافات المرورية وفهم مكان حدوث الانحراف.
شكرا لاهتمامكم
كود النهاية: import requests from requests.exceptions import ConnectionError from time import sleep import json import pandas as pd import numpy as np from pandas import Series,DataFrame pd.set_option('display.max_columns', None) pd.set_option('display.expand_frame_repr', False) pd.set_option('max_colwidth', -1) # UTF-8 Python 3, Python 2 import sys if sys.version_info < (3,): def u(x): try: return x.encode("utf8") except UnicodeDecodeError: return x else: def u(x): if type(x) == type(b''): return x.decode('utf8') else: return x # --- --- # Reports JSON- () ReportsURL = 'https://api.direct.yandex.com/json/v5/reports' # OAuth- , token = ' ' # # , clientLogin = ' ' # --- --- # HTTP- headers = { # OAuth-. Bearer "Authorization": "Bearer " + token, # "Client-Login": clientLogin, # "Accept-Language": "ru", # "processingMode": "auto" # # "returnMoneyInMicros": "false", # # "skipReportHeader": "true", # # "skipColumnHeader": "true", # # "skipReportSummary": "true" } # body = { "params": { "SelectionCriteria": { "Filter": [ { "Field": "Clicks", "Operator": "GREATER_THAN", "Values": [ "0" ] }, ] }, "FieldNames": [ "CampaignName", "Impressions", "Clicks", "Ctr", "Cost", "AvgCpc", "BounceRate", "AvgPageviews", "ConversionRate", "CostPerConversion", "Conversions" ], "ReportName": u("Report4"), "ReportType": "CAMPAIGN_PERFORMANCE_REPORT", "DateRangeType": "LAST_5_DAYS", "Format": "TSV", "IncludeVAT": "NO", "IncludeDiscount": "NO" } } # JSON body = json.dumps(body, indent=4) # --- --- # HTTP- 200, # HTTP- 201 202, while True: try: req = requests.post(ReportsURL, body, headers=headers) req.encoding = 'utf-8' # UTF-8 if req.status_code == 400: print(" ") print("RequestId: {}".format(req.headers.get("RequestId", False))) print("JSON- : {}".format(u(body))) print("JSON- : \n{}".format(u(req.json()))) break elif req.status_code == 200: format(u(req.text)) break elif req.status_code == 201: print(" ") retryIn = int(req.headers.get("retryIn", 60)) print(" {} ".format(retryIn)) print("RequestId: {}".format(req.headers.get("RequestId", False))) sleep(retryIn) elif req.status_code == 202: print(" ") retryIn = int(req.headers.get("retryIn", 60)) print(" {} ".format(retryIn)) print("RequestId: {}".format(req.headers.get("RequestId", False))) sleep(retryIn) elif req.status_code == 500: print(" . , ") print("RequestId: {}".format(req.headers.get("RequestId", False))) print("JSON- : \n{}".format(u(req.json()))) break elif req.status_code == 502: print(" .") print(", - .") print("JSON- : {}".format(body)) print("RequestId: {}".format(req.headers.get("RequestId", False))) print("JSON- : \n{}".format(u(req.json()))) break else: print(" ") print("RequestId: {}".format(req.headers.get("RequestId", False))) print("JSON- : {}".format(body)) print("JSON- : \n{}".format(u(req.json()))) break # , API except ConnectionError: # print(" API") # break # - except: # print(" ") # break file = open("cashe.csv", "w") file.write(req.text) file.close() f = DataFrame.from_csv("cashe.csv",header=1, sep=' ', index_col=0,) f['Cost'] = f['Cost']/1000000 f['AvgCpc'] = f['AvgCpc']/1000000 f['CostPerConversion'] = f['CostPerConversion']/1000000 f=f.sort_values(by=['Clicks'], ascending=False) print(f)