
مصدر الصورة: www.nikonsmallworld.com
مكافحة الانتحال هو محرك بحث متخصص ، والذي سبق أن كتب عنه سابقًا . وأي محرك بحث ، مهما قال أحدهم ، للعمل بسرعة ، يحتاج إلى فهرسه الخاص ، والذي يأخذ في الاعتبار جميع ميزات منطقة البحث. في مقالتي الأولى عن هبر ، سأتحدث عن التنفيذ الحالي لمؤشر البحث الخاص بنا وتاريخ تطويره وأسباب اختيار حل أو آخر. خوارزميات .NET الفعالة ليست أسطورة ، ولكنها حقيقة صعبة ومثمرة. سوف نغرق في عالم التجزئة ، وضغط bitwise ، وذاكرة التخزين المؤقت ذات الأولوية متعددة المستويات. ماذا لو كنت بحاجة إلى بحث أسرع من O (1) ؟
إذا كان شخص آخر لا يعرف مكان وجود القوباء المنطقية في هذه الصورة ، فمرحبا بك ...
القوباء المنطقية ، مؤشر ولماذا تبحث عنها
لوحة خشبية هي جزء من النص بضع كلمات في الحجم. تتداخل القوباء المنطقية مع بعضها البعض ، ومن هنا جاء الاسم (الإنجليزية ، القوباء المنطقية - المقاييس ، التبليط). حجمها المحدد هو سر مفتوح - 4 كلمات. أو 5؟ حسنا ، هذا يعتمد. ومع ذلك ، حتى هذه القيمة لا تعطي إلا القليل وتعتمد على تكوين كلمات الإيقاف والخوارزمية لتطبيع الكلمات والتفاصيل الأخرى غير المهمة في إطار هذه المقالة. في النهاية ، نحسب التجزئة 64 بت على أساس هذا القوباء المنطقية ، والتي سوف نسميها القوباء المنطقية في المستقبل.
وفقًا لنص المستند ، يمكنك إنشاء العديد من القوباء المنطقية ، التي يمكن مقارنتها بعدد الكلمات في المستند:
النص: سلسلة → القوباء المنطقية: uint64 []
إذا تزامنت عدة ألواح خشبية في وثيقتين ، فإننا نفترض أن المستندات تتقاطع. كلما تطابقت القوباء المنطقية ، زاد النص المطابق في هذا الزوج من المستندات. يبحث الفهرس عن المستندات التي تحتوي على أكبر عدد من التقاطعات مع التحقق من المستند.

مصدر الصورة: ويكيبيديا
يتيح لك مؤشر القوباء المنطقية إجراء عمليتين رئيسيتين:
فهرسة القوباء المنطقية الوثائق مع معرفاتها:
index.Add (docId ، القوباء المنطقية)
بحث وعرض قائمة مرتبة من المعرفات للمستندات المتداخلة:
index.Search (القوباء المنطقية) → (docId ، النتيجة) []
أعتقد أن خوارزمية الترتيب تستحق مقالة منفصلة بشكل عام ، لذلك لن نكتب عنها هنا.
يختلف فهرس القوباء المنطقية تمامًا عن الإخوة النص الكامل المعروفين ، مثل Sphinx أو Elastic أو أكبر: Google و Yandex وما إلى ذلك ... من ناحية ، لا يتطلب أي NLP أو أفراح الحياة الأخرى. يتم إخراج معالجة النصوص بالكامل ولا تؤثر على العملية ، وكذلك تسلسل القوباء المنطقية في النص. من ناحية أخرى ، لا يمثل استعلام البحث كلمة أو عبارة من عدة كلمات ، ولكنه يصل إلى عدة مئات من آلاف التجزئة ، والتي تهم جميعها بشكل إجمالي وليس بشكل منفصل.
من الناحية الافتراضية ، يمكنك استخدام فهرس النص الكامل كبديل لمؤشر القوباء المنطقية ، لكن الاختلافات كبيرة جدًا. أسهل طريقة لاستخدام بعض مفاتيح التخزين ذات القيمة المعروفة ، سيتم ذكر ذلك أدناه. نحن نشهد تنفيذ الدراجة لدينا ، والذي يسمى - ShingleIndex.
لماذا نهتم بذلك؟ لكن لماذا.
- المجلدات :
- هناك الكثير من الوثائق. لدينا الآن حوالي 650 مليون منهم ، ومن الواضح أنه سيكون هناك المزيد منهم ؛
- ينمو عدد القوباء المنطقية الفريدة على قدم وساق ويصل بالفعل إلى مئات المليارات. نحن ننتظر تريليون دولار.
- السرعة :
- خلال اليوم ، خلال الجلسة الصيفية ، يتم فحص أكثر من 300 ألف وثيقة من خلال نظام مكافحة الانتحال . هذا قليلًا حسب معايير محركات البحث الشائعة ، لكنه يظل متناسقًا ؛
- للتحقق الناجح من الوثائق للتفرد ، يجب أن يكون عدد المستندات المفهرسة بأحجام أكبر من المستندات التي يتم فحصها. يمكن أن تملأ النسخة الحالية من فهرسنا في المتوسط بسرعة تزيد عن 4000 وثيقة متوسطة في الثانية.
وكل ذلك على جهاز واحد! نعم ، يمكننا تكرار ذلك ، فنحن نقترب تدريجياً من المشاركة الديناميكية على مجموعة ، لكن من عام 2005 إلى يومنا هذا ، تمكن المؤشر الموجود على جهاز واحد بعناية فائقة من مواجهة جميع الصعوبات المذكورة أعلاه.
تجربة غريبة
ومع ذلك ، الآن نحن من ذوي الخبرة للغاية. شئنا أم أبينا ، لكننا ، أيضًا ، نشأنا وجربنا أشياء مختلفة في سياق النمو ، وهو أمر ممتع أن نتذكره الآن.
مصدر الصورة: ويكيبيديا
بادئ ذي بدء ، قد يرغب قارئ عديم الخبرة في استخدام قاعدة بيانات SQL. أنت لست الوحيدين الذين يعتقدون ذلك ، فإن تطبيق SQL قد خدمنا جيدًا لعدة سنوات لتنفيذ مجموعات صغيرة جدًا. ومع ذلك ، كان التركيز على الفور على ملايين الوثائق ، لذلك اضطررت للذهاب أبعد من ذلك.
كما تعلمون ، لا أحد يحب الدراجات ، ولم يكن LevelDB في المجال العام ، لذلك في عام 2010 سقطت أعيننا على BerkeleyDB. كل شيء رائع - قاعدة قيمة مدمجة ثابتة مع طرق وصول btree وتجزئة مناسبة وتاريخ طويل. كان كل شيء معها رائعًا ، لكن:
- في حالة تطبيق التجزئة ، عندما وصل حجمه إلى 2 جيجابايت ، انخفض ببساطة. نعم ، ما زلنا نعمل في وضع 32 بت ؛
- لقد نجح تطبيق شجرة B + بشكل مستقر ، ولكن مع وجود وحدات تخزين تزيد عن بضع غيغا بايت ، بدأت سرعة البحث في الانخفاض بشكل كبير.
علينا أن نعترف أننا لم نعثر أبدًا على طريقة لضبطها على مهمتنا. ربما تكمن المشكلة في الارتباطات .net ، والتي لا يزال يتعين الانتهاء منها. تم استخدام تطبيق BDB في نهاية المطاف كبديل لـ SQL كمؤشر وسيط قبل ملء المؤشر الرئيسي.
مر الوقت. في عام 2014 ، جربوا LMDB و LevelDB ، لكنهم لم يطبقوه. استخدم الرجال من قسم أبحاث مكافحة الانتحال RocksDB كمؤشر لهم. للوهلة الأولى ، كان اكتشاف. لكن بطء التجديد وسرعة البحث المتوسط حتى في أحجام صغيرة جلبت كل شيء إلى شيء.
لقد فعلنا كل ما سبق ، مع تطوير فهرسنا المخصص. ونتيجة لذلك ، أصبح جيدًا في حل مشكلاتنا لدرجة أننا تخلينا عن "المقابس" السابقة وركزنا على تحسينها ، والتي نستخدمها الآن في الإنتاج في كل مكان.
طبقات الفهرس
في النهاية ، ماذا لدينا الآن؟ في الواقع ، يتكون فهرس القوباء المنطقية من عدة طبقات (صفائف) بعناصر بطول ثابت - من 0 إلى 128 بت - والتي لا تعتمد فقط على الطبقة وليست بالضرورة مضاعفات ثمانية.
كل طبقة تلعب دورا. البعض يجعل البحث أسرع ، والبعض الآخر يوفر المساحة ، والبعض الآخر لا يستخدم ، ولكن هناك حاجة حقيقية. سنحاول وصفها من أجل زيادة كفاءتها الكلية في البحث.

مصدر الصورة: ويكيبيديا
1. مؤشر الفهرس
دون فقدان العمومية ، سنعتبر الآن أنه تم تعيين لوحة خشبية واحدة للمستند ،
(docId → لوحة خشبية)
سنقوم بتبديل عناصر الزوج (عكس ، لأن الفهرس "مقلوب" بالفعل!) ،
(لوحة خشبية → docId)
فرز حسب قيم القوباء المنطقية وتشكيل طبقة. لأن تعد أحجام الوصلة المعرفية ومعرف المستند ثابتة ، والآن يمكن لأي شخص يفهم البحث الثنائي أن يجد زوجًا يتجاوز قراءات O (logn) للملف. يا له من جحيم كثير. ولكن هذا أفضل من مجرد O (n) .
إذا كان المستند يحتوي على العديد من القوباء المنطقية ، فسيكون هناك عدة أزواج من المستند. إذا كانت هناك عدة مستندات لها نفس القوباء المنطقية ، فلن يتغير هذا أيضًا كثيرًا - سيكون هناك عدة أزواج متتالية مع نفس القوباء المنطقية. في كلتا هاتين الحالتين ، سيتم البحث عن وقت مماثل.
2. مجموعة من المجموعات
نقسم عناصر الفهرس بعناية من الخطوة السابقة إلى مجموعات بأي طريقة ملائمة. على سبيل المثال ، بحيث تتلاءم مع قطاع الكتلة ، ستشكل كتلة وحدة التخصيص (قراءة ، 4096 بايت) ، مع مراعاة عدد البتات والحيل الأخرى ، قاموسًا فعالًا. نحصل على مجموعة بسيطة من مواقف مثل هذه المجموعات:
group_map (تجزئة (لوحة خشبية)) -> group_position.
عند البحث عن لوحة خشبية ، سنبحث أولاً عن موضع المجموعة في هذا القاموس ، ثم نفرغ المجموعة ونبحث مباشرة في الذاكرة. العملية كلها تتطلب قراءتين.
يأخذ قاموس مواضع المجموعة عدة أوامر بحجم أقل من الفهرس نفسه ، وغالبًا ما يمكن تفريغه ببساطة في الذاكرة. وبالتالي ، لن يكون هناك قراءتان ، ولكن واحدة. المجموع ، يا (1) .
3. بلوم تصفية
في المقابلات ، غالبًا ما يحل المرشحون المشكلات عن طريق إصدار حلول فريدة مع O (n ^ 2) أو حتى O (2 ^ n) . لكننا لا نفعل أشياء غبية. هل هناك يا (0) في العالم ، هذا هو السؤال؟ دعونا نحاول دون أمل كبير في نتيجة ...
دعنا ننتقل إلى موضوع الموضوع. إذا قام الطالب بعمل جيد وكتب العمل بنفسه ، أو ببساطة لم يكن هناك نص ، ولكن قمامة ، فسيكون جزء كبير من القوباء المنطقية الخاصة به فريدًا ولن يتم العثور عليه في الفهرس. إن بنية البيانات مثل مرشح Bloom معروفة جيدًا في العالم. قبل البحث ، تحقق من لوحة خشبية على ذلك. إذا لم يكن هناك لوحة خشبية في الفهرس ، فلن تتمكن من النظر إلى أبعد من ذلك ، وإلا انتقل أبعد من ذلك.
مرشح بلوم نفسه بسيط للغاية ، ولكن لا معنى لاستخدام ناقل تجزئة مع مجلداتنا. يكفي استخدام واحد: قراءة +1 من مرشح Bloom. هذا يعطي -1 أو -2 قراءات من المراحل اللاحقة ، في حالة أن لوحة خشبية فريدة من نوعها ، ولم يكن هناك إيجابية كاذبة في المرشح. راقب يديك!
يتم تعيين احتمال حدوث خطأ في مرشح Bloom أثناء الإنشاء ؛ يتم تحديد احتمال وجود لوحة خشبية غير معروفة من خلال أمانة الطالب. يمكن أن تأتي العمليات الحسابية البسيطة إلى الاعتماد التالي:
- إذا كنا نثق في صدق الأشخاص (بمعنى أن المستند أصلي) ، فستقل سرعة البحث ؛
- إذا تم خياطة المستند بوضوح ، فستزداد سرعة البحث ، لكننا نحتاج إلى الكثير من الذاكرة.
مع الثقة في الطلاب ، لدينا مبدأ "الثقة ، ولكن التحقق" ، والممارسة تبين أنه لا يزال هناك ربح من مرشح بلوم.
نظرًا لأن بنية البيانات هذه أصغر أيضًا من الفهرس نفسه ويمكن تخزينها في ذاكرة التخزين المؤقت ، فهي في أفضل الأحوال تسمح لك بإسقاط لوحة التحكم دون الوصول إلى أي قرص على الإطلاق.
4. ذيول الثقيلة
هناك القوباء المنطقية التي توجد في كل مكان تقريبا. حصتها في العدد الإجمالي ضئيلة ، ولكن عند إنشاء الفهرس في الخطوة الأولى ، في الثانية ، يمكن الحصول على مجموعات من عشرات ومئات ميغابايت في الحجم. سنتذكرها بشكل منفصل وسنتجاهلها على الفور من استعلام البحث.
عندما تم استخدام هذه الخطوة البسيطة في عام 2011 ، انخفض حجم الفهرس إلى النصف ، وتم تسريع عملية البحث نفسها.
5. ذيول أخرى
ومع ذلك ، يمكن أن يكون للقوباء المنطقية العديد من الوثائق وهذا طبيعي. عشرات ، المئات ، الآلاف ... إبقائهم داخل الفهرس الرئيسي يصبح غير مربح ، قد لا يتناسب أيضًا مع المجموعة ، مما يجعل حجم قاموس مواقع المجموعة مضخمًا. وضعها في تسلسل منفصل مع تخزين أكثر كفاءة. وفقا للاحصاءات ، مثل هذا القرار هو أكثر من مبرر. علاوة على ذلك ، يمكن لحزم bitwise المختلفة تقليل عدد عمليات الوصول إلى القرص وتقليل حجم الفهرس.
نتيجة لذلك ، لسهولة الصيانة ، نقوم بطباعة كل هذه الطبقات في ملف واحد كبير - قطعة. هناك عشر طبقات من هذا القبيل. ولكن لا يتم استخدام جزء في البحث ، جزء صغير جدًا ويتم تخزينه دائمًا في الذاكرة ، يتم تخزين جزء نشط مؤقتًا حسب الضرورة / ممكن.
في المعركة ، غالبًا ما يكون البحث عن القوباء المنطقية هو واحد أو اثنين من قراءات الملفات العشوائية. في أسوأ الحالات ، عليك أن تفعل ثلاثة. جميع الطبقات تكون (في بعض الأحيان في بعض الأحيان) صفائف معبأة من عناصر ذات طول ثابت. هذا هو التطبيع. إن وقت تفريغ العبوة ضئيل بالمقارنة مع سعر الحجم الإجمالي أثناء التخزين والقدرة على التخزين المؤقت بشكل أفضل.
عند الإنشاء ، يتم احتساب أحجام الطبقات مسبقًا مقدمًا ، مكتوبة بالتسلسل ، لذلك هذا الإجراء سريع جدًا.
كيف وصلت إلى هناك ، لم تكن تعرف أين
2010 , . , . , .

مصدر الصورة: ويكيبيديا
في البداية ، يتكون فهرسنا من جزأين - ثابت ، موصوف أعلاه ، وآخر مؤقت ، كان دورهما إما SQL أو BDB أو سجل التحديث الخاص بها. في بعض الأحيان ، على سبيل المثال ، مرة واحدة شهريًا (وأحيانًا كل عام) ، يتم فرز وتصفية ودمج المؤقت المؤقت مع الرئيسي. وكانت النتيجة واحدة موحدة ، وتمت إزالة اثنين من القديمة. إذا تعذر احتواء المؤقت على ذاكرة الوصول العشوائي (RAM) ، فسيذهب الإجراء عبر فرز خارجي.
كان هذا الإجراء مزعجًا إلى حد ما ، فقد بدأ في الوضع شبه اليدوي وتطلب إعادة كتابة ملف الفهرس بالكامل من البداية. إعادة كتابة مئات غيغا بايت لبضعة ملايين من الوثائق - حسناً ، من دواعي سروري ، أقول لك ...
ذكريات من الماضي ...SSD. , 31 SSD wcf- . , . , .
بحيث لا يتم توتر SSD بشكل خاص ، ويتم تحديث الفهرس أكثر من مرة ، في عام 2012 ، شاركنا في سلسلة من القطع المتعددة ، وفقًا للمخطط التالي:

هنا يتكون الفهرس من سلسلة من نفس النوع من القطع ، باستثناء الأول. الأول ، الملحق ، كان سجل إلحاقي فقط به فهرس في ذاكرة الوصول العشوائي. زادت القطع اللاحقة في الحجم (والعمر) حتى آخرها (صفر ، رئيسي ، الجذر ، ...).
ملاحظة لراكبي الدراجات ...في بعض الأحيان يجب ألا تكون في حيرة لكتابة التعليمات البرمجية ولا حتى التفكير ، ولكن مجرد google أكثر شمولاً. حتى التدوين ، يشبه الرسم التخطيطي هذا المخطط من مقالة 1996
"شجرة الدمج المهيكلة بالسجل" :
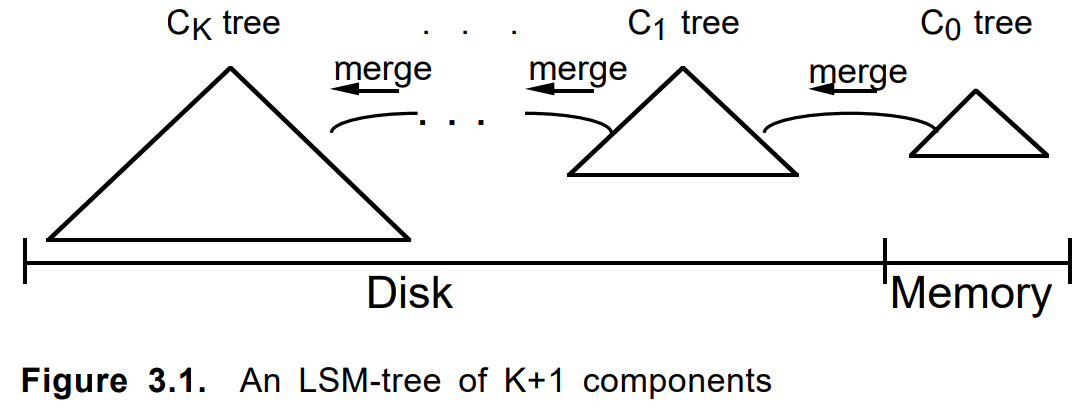
عند إضافة مستند ، تم طيه أولاً في ملحق. عندما كانت ممتلئة أو وفقًا لمعايير أخرى ، تم بناء قطعة دائمة عليها. تم دمج الأجزاء العديدة المجاورة ، إذا لزم الأمر ، في واحدة جديدة ، وتم حذف القطع الأصلية. تحديث وثيقة أو حذفها عملت بنفس الطريقة.
دمج المعايير ، طول السلسلة ، خوارزمية الالتفافية ، المحاسبة عن العناصر المحذوفة والتحديثات ، تم ضبط المعلمات الأخرى. شارك النهج نفسه في العديد من المهام المتشابهة واتخذ شكلًا كإطار LSM داخلي منفصل على شبكة .net نظيفة. في الوقت نفسه تقريبا ، أصبح LevelDB مشهورًا.
ملاحظة صغيرة حول شجرة LSMLSM- شجرة هو خوارزمية مثيرة للاهتمام إلى حد ما ، مع تبرير جيد. ولكن ، IMHO ، كان هناك بعض عدم وضوح معنى مصطلح شجرة. في
المقال الأصلي
، كان حول سلسلة من الأشجار مع القدرة على نقل الفروع. في التطبيقات الحديثة ، ليس هذا هو الحال دائمًا. لذلك تم تسمية إطار عملنا في النهاية باسم LsmChain ، أي سلسلة lsm من القطع.
تحتوي خوارزمية LSM في حالتنا على ميزات مناسبة للغاية:
- إدراج فوري / حذف / تحديث ،
- انخفاض الحمل على محركات الأقراص الصلبة أثناء التحديث ،
- شكل قطع مبسطة ،
- البحث الانتقائي فقط على القطع القديمة / الجديدة ،
- احتياطية تافهة
- ماذا تريد الروح.
- ...
بشكل عام ، من المفيد في بعض الأحيان اختراع الدراجات من أجل التنمية الذاتية.
ماكرو ، الدقيقة ، نانو الأمثل
وأخيرًا ، سوف نشارك النصائح الفنية حول كيفية قيامنا في Antiplagiarism بمثل هذه الأشياء على .Net (وليس فقط على ذلك).
لاحظ مقدمًا أن كل شيء يعتمد كثيرًا على الأجهزة أو البيانات أو وضع الاستخدام الخاص بك. بعد الالتواء في مكان واحد ، ننتقل من ذاكرة التخزين المؤقت لوحدة المعالجة المركزية ، في مكان آخر - نواجه عرض النطاق الترددي لواجهة SATA ، في الحالة الثالثة - نبدأ في التعليق في GC. وفي مكان ما في عدم كفاءة تنفيذ استدعاء نظام معين.

مصدر الصورة: ويكيبيديا
العمل مع الملف
مشكلة الوصول إلى الملف ليست فريدة من نوعها معنا. يوجد ملف كبير بحجم تيرابايت ، حجمه أكبر من ذاكرة الوصول العشوائي. المهمة هي قراءة المليون المنتشرة حوله لبعض القيم العشوائية الصغيرة. وللقيام بذلك بسرعة وكفاءة وغير مكلفة. علينا أن نضغط ونفكر كثيرا.
لنبدأ مع واحد بسيط. لقراءة البايت العزيزة التي تحتاجها:
- فتح ملف (FileStream الجديد) ؛
- الانتقال إلى الموضع المطلوب (الموضع أو البحث ، لا فرق) ؛
- قراءة صفيف البايت المطلوب (قراءة) ؛
- أغلق الملف (تخلص).
وهذا سيء ، لأنه طويل وكئيب. من خلال التجربة والخطأ والدخول المتكرر على أشعل النار ، حددنا خوارزمية الإجراءات التالية:
واحد مفتوح ، قراءة متعددة
إذا تم هذا التسلسل في الجبهة ، ولكل طلب على القرص ، فإننا سوف ينحني بسرعة. كل عنصر من هذه العناصر يذهب إلى طلب إلى OS kernel ، وهو مكلف.
من الواضح أنك يجب أن تفتح الملف مرة واحدة وتقرأ منه بالتتابع كل ملايين قيمنا ، وهو ما نقوم به
لا شيء إضافي
الحصول على حجم الملف ، والموقف الحالي فيه هو أيضا عمليات صعبة للغاية. حتى لو لم يتغير الملف.
يجب تجنب أي استفسارات مثل الحصول على حجم الملف أو الموضع الحالي فيه.
FileStreamPool
التالي. للأسف ، FileStream هو في الأساس واحد مترابطة. إذا كنت ترغب في قراءة ملف بالتوازي ، فسيتعين عليك إنشاء / إغلاق تدفقات الملفات الجديدة.
حتى تقوم بإنشاء شيء مثل aiosync ، يجب عليك اختراع الدراجات الخاصة بك.
نصيحتي هي إنشاء مجموعة من تدفقات الملفات لكل ملف. هذا سوف يتجنب تضييع الوقت في فتح / إغلاق الملف. وإذا قمت بدمجها مع ThreadPool وأخذت في الاعتبار أن SSD تصدر megaIOPS الخاص به مع تعدد قوي ... حسنا ، أنت تفهمني.
وحدة التخصيص
التالي. تعمل أجهزة التخزين (HDD ، SSD ، Optane) ونظام الملفات مع الملفات على مستوى الكتلة (الكتلة ، القطاع ، وحدة التخصيص). قد لا تتطابق مع ذلك ، لكنها الآن دائمًا 4096 بايت. قراءة واحد أو اثنين بايت على حدود اثنين من هذه الكتل في SSD حوالي واحد ونصف مرة أبطأ من داخل الكتلة نفسها.
يجب عليك تنظيم البيانات الخاصة بك بحيث تكون العناصر المخصومة ضمن حدود كتلة قطاع الكتلة.
لا عازلة.
التالي. يستخدم FileStream افتراضيًا مخزن مؤقت 4096 بايت. والخبر السيئ هو أنه لا يمكنك إيقاف تشغيله. ومع ذلك ، إذا كنت تقرأ بيانات أكثر من حجم المخزن المؤقت ، فسيتم تجاهل هذا الأخير.
بالنسبة للقراءة العشوائية ، يجب عليك تعيين المخزن المؤقت على بايت واحد (لن يعمل أقل من ذلك) ثم تفكر في عدم استخدامه.
استخدام العازلة.
بالإضافة إلى القراءات العشوائية ، هناك أيضًا قراءات متسلسلة. هنا يمكن أن يصبح المخزن المؤقت مفيدًا بالفعل إذا كنت لا ترغب في قراءة كل شيء مرة واحدة. أنصحك أن تبدأ مع هذا المقال . يعتمد حجم المخزن المؤقت المراد تعيينه على ما إذا كان الملف موجودًا على محرك الأقراص الثابتة أو محرك أقراص الحالة الصلبة. في الحالة الأولى ، سيكون 1 ميجابايت هو الأمثل ؛ وفي الحالة الثانية ، سيكون 4 كيلوبايت القياسي كافيًا. إذا كان حجم منطقة البيانات المراد قراءتها مشابهًا لهذه القيم ، فمن الأفضل طرحها في وقت واحد ، وتخطي المخزن المؤقت ، كما في حالة القراءة العشوائية. المخازن المؤقتة الكبيرة لن تحقق الربح في السرعة ، ولكنها ستبدأ في الوصول إلى GC.
عند قراءة أجزاء كبيرة من الملف بالتسلسل ، يجب عليك تعيين المخزن المؤقت على 1 ميغابايت للأقراص الصلبة و 4 كيلوبايت ل SSD. حسنا ، هذا يعتمد.
MMF مقابل FileStream
في عام 2011 ، جاءت نصيحة إلى MemoryMappedFile ، حيث تم تنفيذ هذه الآلية منذ .Net Framework v4.0. أولاً ، استخدموها عند التخزين المؤقت لمرشح Bloom ، والذي كان غير مريح بالفعل في وضع 32 بت بسبب قيود 4 جيجابايت. ولكن عندما انتقلت إلى عالم 64 بت ، أردت أكثر. كانت الاختبارات الأولى مثيرة للإعجاب. التخزين المؤقت الحرة ، وسرعة غريب ، واجهة مريحة هيكل القراءة. ولكن كانت هناك مشاكل:
- أولاً ، السرعة الغريبة. إذا كانت البيانات مخزنة مؤقتًا بالفعل ، فكل شيء على ما يرام. لكن إذا لم يكن الأمر كذلك ، فإن قراءة بايت واحد من الملف كان مصحوبًا بـ "رفع" كمية أكبر بكثير من البيانات مقارنة بقراءة منتظمة.
- ثانيا ، الغريب ، والذاكرة. عند تسخينها ، تنمو الذاكرة المشتركة ، مجموعة العمل - لا ، وهو أمر منطقي. ولكن بعد ذلك تبدأ العمليات المجاورة في التصرف بشكل غير جيد. يمكن أن يذهبوا إلى المبادلة ، أو يسقطون بطريق الخطأ من OoM. لا يمكن التحكم في وحدة التخزين التي تشغلها MMF في RAM. والربح من ذاكرة التخزين المؤقت في الحالة عندما يكون الملف القابل للقراءة بضعة أوامر بحجم أكبر من الذاكرة تصبح بلا معنى.
لا يزال من الممكن محاربة المشكلة الثانية. يختفي إذا كان الفهرس يعمل في عامل ميناء أو على جهاز ظاهري مخصص. لكن مشكلة السرعة كانت قاتلة.
ونتيجة لذلك ، تم التخلي عن MMF أكثر بقليل من تماما. بدأ التخزين المؤقت في مكافحة الانتحال في شكل واضح ، إذا أمكن ذلك في الذاكرة الطبقات الأكثر استخداما في الأولويات والحدود المحددة.

مصدر الصورة: ويكيبيديا
بت / بايت
لا بايت العالم واحد. في بعض الأحيان تحتاج إلى النزول إلى مستوى بت.
على سبيل المثال: افترض أن لديك تريليون رقمًا تم طلبه جزئيًا ، وحريصًا على التوفير والقراءة بشكل متكرر. كيف تعمل مع كل هذا؟
- BinaryWriter.Write بسيط؟ - سريع لكن بطيئ. الحجم لا يهم. القراءة الباردة تعتمد في المقام الأول على حجم الملف.
- اختلاف آخر من VarInt؟ - سريع لكن بطيئ. مسائل الاتساق. يبدأ مستوى الصوت في الاعتماد على البيانات ، مما يتطلب ذاكرة إضافية لتحديد المواقع.
- التعبئة قليلا؟ - سريع لكن بطيئ. يجب عليك التحكم بعناية أكبر في يديك.
لا يوجد حل مثالي ، لكن في حالة معينة ، ببساطة ضغط النطاق من 32 بت إلى الضروري لتخزين ذيول حفظ أكثر 12٪ (عشرات غيغابايت!) Than VarInt (حفظ فقط الفرق من المجاورين ، بالطبع) ، وهذا عدة مرات الخيار الأساسي.
مثال آخر لديك رابط في ملف إلى مجموعة من الأرقام. ربط 64 بت ، ملف لكل تيرابايت. كل شيء يبدو على ما يرام. في بعض الأحيان هناك العديد من الأرقام في الصفيف ، في بعض الأحيان قليلة. في كثير من الأحيان قليلا. في كثير من الأحيان. ثم خذ فقط وتخزين مجموعة كاملة في الرابط نفسه. الربح. حزمة بعناية ولكن لا تنسى.
هيكل ، غير آمنة ، الخلط ، opts الصغيرة
حسنا و microoptimization الأخرى. لن أكتب هنا عن المبتذلة "هل يستحق إنقاذ طول المصفوفة في حلقة" أم "أسرع ، أم لأجل أو متوقعة".
هناك قاعدتان بسيطتان ، وسنلتزم بهما: 1. "قياس كل شيء" ، 2. "مزيد من المعايير".
الهيكل تستخدم في كل مكان. لا تشحن GC. ولأنه من المألوف اليوم ، لدينا أيضًا قائمة القيمة الضخمة الخاصة بنا.
غير آمن . يسمح بنيات mapit (و unmap) لمجموعة من وحدات البايت عند استخدامها. وبالتالي ، نحن لسنا بحاجة إلى وسائل منفصلة للتسلسل. صحيح أن هناك أسئلة لتثبيت الكومة وإلغاء تجزئتها ، لكن حتى الآن لم يتم عرضها. حسنا ، هذا يعتمد.
الخلط . يجب أن يكون العمل مع العديد من العناصر من خلال حزم / مجموعات / كتل. قراءة / كتابة الملف ، ونقل بين وظائف. مشكلة منفصلة هي حجم هذه الحزم. عادة ما يكون هناك الأمثل ، وغالبا ما يكون حجمها في حدود 1 كيلو بايت إلى 8 ميغابايت (حجم ذاكرة التخزين المؤقت وحدة المعالجة المركزية وحجم الكتلة وحجم الصفحة وحجم شيء آخر). حاول ضخ خلال <nate> أو IEnumerable <بايت [1024]> وظيفة IEnumerable وشعر الفرق.
تجمع . في كل مرة تكتب فيها كلمة "جديد" ، تموت قط صغير في مكان ما. مرة واحدة جديدة [ 85000 ] - وركب جرار طن من الأوز. إذا لم يكن من الممكن استخدام stackalloc ، فقم بإنشاء تجمع لأي كائنات وإعادة استخدامه مرة أخرى.
مضمنة . كيفية إنشاء وظيفتين بدلا من واحدة يمكن تسريع كل شيء عشر مرات؟ فقط. كلما كان حجم نص الدالة (الطريقة) أصغر ، فستكون على الأرجح مضمنة. لسوء الحظ ، في عالم dotnet ، لا توجد طريقة للقيام بتضمين جزئي ، لذلك إذا كان لديك وظيفة حارة في 99 ٪ من الحالات تخرج بعد معالجة الأسطر القليلة الأولى ، وتذهب المئات المتبقية من الخطوط لمعالجة 1 ٪ المتبقية ، ثم تقسمها بأمان إلى اثنان (أو ثلاثة) ، يحمل الذيل الثقيل في وظيفة منفصلة.
ماذا بعد؟
تمتد <T> ، الذاكرة <T> - واعدة. سيكون الرمز أكثر بساطة وربما أسرع قليلاً. نحن في انتظار إصدار .Net Core v3.0 و Std v2.1 للتبديل إليهما ، لأن نواة لدينا على .Net Std v2.0 ، والتي عادة لا تدعم المسافات.
المتزامن / تنتظر - حتى الآن مثيرة للجدل. أظهرت أبسط معايير القراءة العشوائية أن استهلاك وحدة المعالجة المركزية يتراجع بالفعل ، ولكن سرعة القراءة تتناقص أيضًا. يجب أن تشاهد. نحن لا نستخدمه داخل الفهرس حتى الآن.
استنتاج
آمل أن يمنحك بُعد عني من فهم جمال بعض القرارات. نحن حقا نحب فهرسنا. أنها فعالة ، رمز جميل ، يعمل بشكل رائع. إن الحل المتخصص للغاية في قلب النظام ، والمكان الحرج لعمله ، أفضل من الحل العام. يتذكر نظام التحكم في الإصدار الخاص بنا إدراج أداة التجميع في رمز C ++. الآن هناك أربعة إيجابيات - فقط نقية C # ، فقط. على ذلك نكتب حتى خوارزميات البحث الأكثر تعقيدًا ولا نندم على الإطلاق. مع ظهور .Net Core ، والانتقال إلى Docker ، أصبح الطريق إلى مستقبل DevOps مشرق أسهل وأكثر وضوحًا. إلى الأمام هو الحل لمشكلة التباين الديناميكي والتكرار دون تقليل فعالية وجمال الحل.
شكرا لكل من قرأ حتى النهاية. لجميع التناقضات والتناقضات الأخرى ، يرجى كتابة التعليقات. سأكون سعيدًا بأي نصيحة معقولة ودحض في التعليقات.