مقدمة
هذه المقالة لا تشبه إلى حد بعيد تلك التي نشرت في وقت سابق حول مسح الإنترنت في بعض البلدان ، لأنني لم أتابع أهداف المسح الشامل لجزء معين من الإنترنت بحثًا عن منافذ مفتوحة ووجود نقاط الضعف الأكثر شيوعًا لأنها تتعارض مع القانون.
لقد كان لدي اهتمام مختلف بعض الشيء - محاولة تحديد جميع المواقع ذات الصلة في منطقة المجال BY باستخدام طرق مختلفة ، لتحديد كومة من التقنيات المستخدمة ، من خلال خدمات مثل Shodan ، VirusTotal ، إلخ. لإجراء استطلاع سلبي على IP والمنافذ المفتوحة ، وجمع الملحق مختلف قليلاً معلومات لتشكيل بعض الإحصاءات العامة على مستوى الأمان فيما يتعلق بالمواقع والمستخدمين.
تمهيدية ومجموعة أدوات لدينا
كانت الخطة في البداية بسيطة - اتصل بالمسجل المحلي للحصول على قائمة بالمجالات المسجلة الحالية ، ثم تحقق من كل شيء للتأكد من توفرها وبدء استكشاف المواقع العاملة. في الواقع ، تبين أن كل شيء كان أكثر تعقيدًا - كان هذا النوع من المعلومات طبيعيًا ، لم يكن أحد يريد تقديمه ، باستثناء صفحة الإحصائيات الرسمية لأسماء النطاقات المسجلة الفعلية في منطقة BY (حوالي 130 ألف مجال). إذا لم يكن هناك مثل هذه المعلومات ، فعليك أن تجمعها بنفسك.
فيما يتعلق بالأدوات ، في الواقع ، كل شيء بسيط للغاية - نتطلع إلى المصدر المفتوح ، يمكنك دائمًا إضافة شيء ما ، وإنهاء بعض العكازات الدنيا. من الأكثر شعبية ، تم استخدام الأدوات التالية:
بداية الأنشطة: نقطة البداية
كمقدمة ، كما قلت من قبل ، كانت أسماء النطاقات مناسبة ، لكن من أين يمكنني الحصول عليها؟ نحتاج أن نبدأ من شيء أكثر بساطة ، في هذه الحالة تكون عناوين IP مناسبة لنا ، ولكن مرة أخرى - مع عمليات البحث العكسي ، لا يمكن دائمًا التقاط جميع المجالات ، وعند جمع أسماء المضيفين - لا يكون ذلك دائمًا هو المجال الصحيح. في هذه المرحلة ، بدأت أفكر في السيناريوهات المحتملة لجمع هذا النوع من المعلومات ، مرة أخرى - تم أخذ حقيقة أن ميزانيتنا تبلغ 5 دولارات لتأجير VPS ، يجب أن يكون كل شيء آخر مجانيًا.
مصادرنا المحتملة للمعلومات:
- عناوين IP (موقع ip2location )
- ابحث في المجال عن طريق الجزء الثاني من عنوان البريد الإلكتروني (ولكن من أين يمكن الحصول عليها؟ دعنا نتعرف عليه قليلاً أدناه)
- قد يوفر لنا بعض المسجلين / مزودي الاستضافة هذه المعلومات في شكل نطاقات فرعية
- النطاقات الفرعية وعكسها اللاحق (يمكن أن يساعدك Sublist3r و Aquatone هنا)
- بروتيفورسي والإدخال اليدوي (طويل ، كئيب ، لكن ممكن ، على الرغم من أنني لم استخدم هذا الخيار)
سأجري قليلاً وأقول أنني تمكنت من خلال هذا النهج من تجميع حوالي 50 ألف من المجالات والمواقع الفريدة ، على التوالي (لم أتمكن من معالجة كل شيء). إذا استمر في جمع المعلومات بشكل نشط ، فمن المؤكد أنه خلال أقل من شهر من العمل ، كان الناقل الخاص بي سيتقن قاعدة البيانات بأكملها ، أو معظمها.
هيا بنا إلى العمل
في المقالات السابقة ، تم الحصول على معلومات حول عناوين IP من موقع IP2LOCATION ، لأسباب واضحة ، لم أجد هذه المقالات (نظرًا لأن جميع الإجراءات قد تمت قبل ذلك كثيرًا) ، لكنني أتيت أيضًا إلى هذا المورد. صحيح ، في حالتي ، كان النهج مختلفًا - قررت عدم نقل قاعدة البيانات محليًا إلى نفسي وعدم استخراج المعلومات من ملف CSV ، لكنني قررت مراقبة التغييرات مباشرةً على الموقع ، بصفة مستمرة وكقاعدة رئيسية من حيث ستأخذ جميع البرامج النصية اللاحقة الأهداف - أعدت جدولًا يحتوي على عناوين IP بتنسيقات مختلفة: CIDR ، "من" و "إلى" ، علامة البلد (فقط في حالة) ، رقم AS ، AS الوصف.
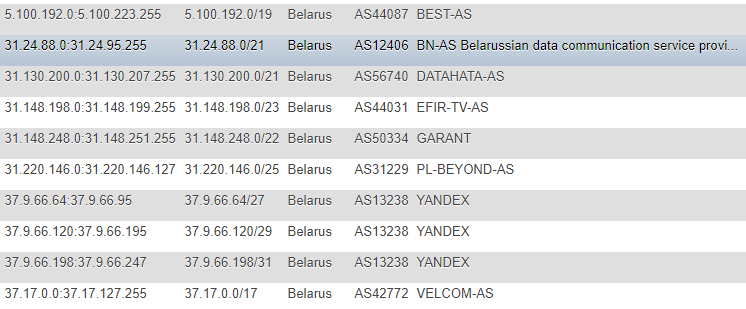
التنسيق ليس هو الأفضل ، لكنني كنت سعيدًا جدًا بالعرض التوضيحي والترويج لمرة واحدة ، ولكي لا أطلب باستمرار معلومات إضافية مثل ASN ، قررت تسجيله بالإضافة إلى ذلك بمفردي. للحصول على هذه المعلومات ، التفتت إلى خدمة
IpToASN ، ولديهم واجهة برمجة تطبيقات ملائمة (مع قيود) ، والتي في الواقع تحتاج فقط إلى الاندماج في نفسك.
تحليل رمز IPfunction ipList() { $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, "https://lite.ip2location.com/belarus-ip-address-ranges"); curl_setopt($ch, CURLOPT_HEADER, 0); curl_setopt($ch, CURLOPT_USERAGENT,'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.13) Gecko/20080311 Firefox/2.0.0.13'); curl_setopt($ch, CURLOPT_RETURNTRANSFER, true); curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false); curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false); $ipList = curl_exec($ch); curl_close ($ch); preg_match_all("/(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\<\/td\>\s+\<td\>\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})/", $ipList, $matches); return $matches[0]; } function iprange2cidr($ipStart, $ipEnd){ if (is_string($ipStart) || is_string($ipEnd)){ $start = ip2long($ipStart); $end = ip2long($ipEnd); } else{ $start = $ipStart; $end = $ipEnd; } $result = array(); while($end >= $start){ $maxSize = 32; while ($maxSize > 0){ $mask = hexdec(iMask($maxSize - 1)); $maskBase = $start & $mask; if($maskBase != $start) break; $maxSize--; } $x = log($end - $start + 1)/log(2); $maxDiff = floor(32 - floor($x)); if($maxSize < $maxDiff){ $maxSize = $maxDiff; } $ip = long2ip($start); array_push($result, "$ip/$maxSize"); $start += pow(2, (32-$maxSize)); } return $result; } $getIpList = ipList(); foreach($getIpList as $item) { $cidr = iprange2cidr($ip[0], $ip[1]); }
بعد أن اكتشفنا IP ، نحتاج إلى تشغيل قاعدة بياناتنا بالكامل من خلال خدمات البحث العكسي ، للأسف ، دون أي قيود - هذا مستحيل ، باستثناء الأموال.
من الخدمات الرائعة لهذا الاستخدام ومريحة ، أود أن أذكر اثنين:
- VirusTotal - الحد من وتيرة المكالمات من مفتاح API واحد
- Hackertarget.com (API الخاصة بهم) - الحد من عدد الزيارات من IP واحد
بتجاوز الحدود ، تم الحصول على الخيارات التالية:
- في الحالة الأولى ، يتمثل أحد السيناريوهات في مقاومة مهل 15 ثانية ، وإجمالًا سيكون لدينا 4 مكالمات في الدقيقة ، مما قد يؤثر بشكل كبير على سرعتنا ، وفي هذه الحالة سيكون من المفيد استخدام 2-3 من هذه المفاتيح ، وأوصي باللجوء إلى نفس إلى الوكيل وتغيير وكيل المستخدم.
- في الحالة الثانية ، كتبت نصًا للتحليل التلقائي لقاعدة بيانات الوكيل استنادًا إلى المعلومات المتاحة للجمهور ، والتحقق من صحتها واستخدامها اللاحق (ولكن في وقت لاحق تركت هذا الخيار لأن VirusTotal كان أيضًا كافٍ في جوهره)
نذهب أبعد من ذلك ونذهب بسلاسة إلى عناوين البريد الإلكتروني. يمكن أن تكون أيضًا مصدرًا للمعلومات المفيدة ، ولكن من أين نجمعها؟ لم أضطر إلى البحث عن حل لفترة طويلة ، لأن يحتفظ المستخدمون قليلاً في قسمنا من المواقع الشخصية ، ومعظمهم من المؤسسات - مواقع الويب الشخصية مثل دلائل المتجر على الإنترنت والمنتديات والأسواق الشرطية ستناسبنا.
على سبيل المثال ، أظهر الفحص السريع لأحد هذه المواقع أن الكثير من المستخدمين يضيفون بريدهم الإلكتروني مباشرةً إلى ملفهم الشخصي العام ، وبالتالي ، يمكن تحليل هذا العمل بعناية لاستخدامه في المستقبل.
لن أخوض في تفاصيل تحليل كل موقع ، في مكان أكثر ملاءمة لتخمين معرف المستخدم بالقوة الغاشمة ، في مكان ما من الأسهل تحليل خريطة الموقع ، والحصول على معلومات حول صفحات الشركة منه ، ثم جمع العناوين منها. بعد جمع العناوين ، يبقى لنا أن نقوم بالعديد من العمليات البسيطة التي تقوم بترتيبها فورًا حسب مجال المجال ، مع الحفاظ على "ذيول" وتشغيلها لاستبعاد التكرارات من قاعدة البيانات الحالية.
في هذه المرحلة ، أعتقد أنه مع تشكيل النطاق ، يمكننا أن ننتقل وننتقل إلى الذكاء. الذكاء ، كما نعلم بالفعل ، يمكن أن يكون من نوعين - نشيطين وسلبيين ، في حالتنا - سيكون النهج السلبي هو الأكثر أهمية. ولكن مرة أخرى ، مجرد الوصول إلى الموقع على المنفذ 80 أو 443 دون تحميل ضار واستغلال الثغرات الأمنية يعد إجراءً مشروعًا تمامًا. اهتمامنا هو استجابة الخادم لطلب واحد ، وفي بعض الحالات يمكن أن يكون هناك طلبان (إعادة التوجيه من http إلى https) ، وفي حالات نادرة ، يصل عددها إلى ثلاثة (عند استخدام www).
استكشاف
باستخدام هذه المعلومات كنطاق ، يمكننا جمع البيانات التالية:
- سجلات DNS (NS ، MX ، TXT)
- إجابة الرؤوس
- تحديد كومة التكنولوجيا المستخدمة
- نفهم ما بروتوكول يعمل الموقع.
- حاول تحديد المنافذ المفتوحة (بناءً على قاعدة بيانات Shodan / Censys) دون المسح المباشر
- حاول تحديد نقاط الضعف بناءً على ارتباط المعلومات من Shodan / Censys بقاعدة بيانات Vulners
- هل هو في قاعدة بيانات Google Safe Browse البرامج الضارة
- اجمع عناوين البريد الإلكتروني حسب النطاق ، بالإضافة إلى التطابق الذي تم العثور عليه بالفعل وتحقق منه بواسطة Have I Been Pwned ، بالإضافة إلى الارتباط بالشبكات الاجتماعية
- لا يمثل النطاق في بعض الحالات وجه الشركة فحسب ، بل هو أيضًا منتج أنشطتها وعناوين البريد الإلكتروني للتسجيل في الخدمات ، وما إلى ذلك ، على التوالي - يمكنك البحث عن المعلومات المرتبطة بها على موارد مثل GitHub و Pastebin و Google Dorks (Google CSE )
يمكنك دائمًا المضي قدمًا واستخدام masscan أو nmap ، zmap كخيار ، إعدادهما أولاً عبر Tor مع الإطلاق في وقت عشوائي أو حتى من عدة حالات ، لكن لدينا أهداف أخرى ، والاسم يعني أنني لم أقوم بإجراء عمليات مسح مباشرة.
نحن نجمع سجلات DNS ، ونتحقق من إمكانية تضخيم الطلبات وأخطاء التكوين مثل AXFR:
مثال على جمع سجلات خادم NS dig ns +short $domain | sed 's/\.$//g' | awk '{print $1}'
مثال على مجموعة سجلات MX (انظر NS ، ما عليك سوى استبدال "ns" بـ "mx"
تحقق من وجود AXFR (هناك العديد من الحلول هنا ، إليك عكاز آخر ، ولكن ليس الأمان ، يستخدم لعرض المخرجات) $digNs = trim(shell_exec("dig ns +short $domain | sed 's/\.$//g' | awk '{print $1}'")); $ns = explode("\n", $digNs); foreach($ns as $target) { $axfr = trim(shell_exec("dig -t axfr $domain @$target | awk '{print $1}' | sed 's/\.$//g'")); $axfr = preg_replace("/\;/", "", $axfr); if(!empty(trim($axfr))) { $axfr = preg_replace("/\;/", "", $axfr); $res = json_encode(explode("\n", trim($axfr)));
تحقق من تضخيم DNS dig +short test.openresolver.com TXT @$dns
في حالتي ، تم أخذ خوادم NS من قاعدة البيانات ، لذلك في نهاية المتغير ، يمكنك استبدال أي خادم في الواقع. فيما يتعلق بصحة نتائج هذه الخدمة ، لا يمكنني التأكد من أن كل شيء يعمل بشكل سلس هناك وأن النتائج صالحة دائمًا ، لكنني آمل أن تكون معظم النتائج حقيقية.
إذا احتجنا لأي سبب من الأغراض إلى الاحتفاظ بعنوان URL نهائي كامل للموقع ، فقد استخدمت cURL لهذا الغرض:
curl -I -L $target | awk '/Location/{print $2}'
هو نفسه سيخضع لعملية إعادة التوجيه بأكملها ويعرض النهائي ، أي عنوان الموقع الحالي. في حالتي ، كان مفيدًا للغاية للاستخدام اللاحق لأدوات مثل WhatWeb.
لماذا يجب أن نستخدمها؟ من أجل تحديد نظام التشغيل ، خادم الويب ، موقع CMS المستخدم ، بعض الرؤوس ، وحدات إضافية مثل مكتبات / أطر عمل JS / HTML ، بالإضافة إلى عنوان الموقع الذي يمكنك من خلاله محاولة التصفية حسب مجال النشاط نفسه.
خيار مناسب جدًا في هذه الحالة هو تصدير نتائج تشغيل الأداة بتنسيق XML للتحليل اللاحق والاستيراد إلى قاعدة البيانات إذا كان هناك هدف لمعالجتها جميعًا في وقت لاحق.
whatweb --no-errors https://www.mywebsite.com --log-xml=results.xml
بنفسي ، قمت بعمل JSON كنتيجة للمخرجات وقمت بالفعل بوضعه في قاعدة البيانات.
عند الحديث عن الرؤوس ، يمكنك فعل الشيء نفسه تقريبًا باستخدام cURL العادي من خلال تنفيذ استعلام من النموذج:
curl -I https://www.mywebsite.com
في الرؤوس ، يمكنك التقاط المعلومات على CMS وخوادم الويب باستخدام التعبيرات العادية ، على سبيل المثال.
بالإضافة إلى الأداة المفيدة ، يمكننا أيضًا تسليط الضوء على إمكانية جمع المعلومات حول المنافذ المفتوحة باستخدام Shodan ثم استخدام البيانات التي تم الحصول عليها بالفعل ، وإجراء فحص على قاعدة بيانات Vulners باستخدام واجهة برمجة التطبيقات (يتم توفير روابط الخدمات في الرأس). بالطبع ، قد تكون هناك مشكلات تتعلق بالدقة في هذا السيناريو ، لكن هذا ليس مسحًا مباشرًا مع التحقق اليدوي ، ولكنه "شغب" عادي للبيانات من مصادر خارجية ، ولكنه على الأقل أفضل من لا شيء على الإطلاق.
وظيفة PHP لشودان function shodanHost($host) { $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, "https://api.shodan.io/shodan/host/".$host."?key=<YOUR_API_KEY>"); curl_setopt($ch, CURLOPT_HEADER, 0); curl_setopt($ch, CURLOPT_USERAGENT,'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.13) Gecko/20080311 Firefox/2.0.0.13'); curl_setopt($ch, CURLOPT_RETURNTRANSFER, true); curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false); curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false); $shodanResponse = curl_exec($ch); curl_close ($ch); return json_decode($shodanResponse); }
مثال على مثل هذا التحليل المقارن # 1 نعم ، نظرًا لأنهم بدأوا يتحدثون عن واجهة برمجة التطبيقات (API) ، فإن لدى Vulners قيودًا وأن الحل الأمثل هو استخدام برنامج Python الخاص بهم ، كل شيء سوف يعمل بشكل جيد دون الالتواءات ، في حالة PHP ، واجهت بعض الصعوبات الصغيرة (مرة أخرى ، الإضافة. مهلات حفظ الوضع).
أحد أحدث الاختبارات - سنقوم بدراسة المعلومات الموجودة على جدار الحماية المستخدم مع برنامج نصي مثل "wafw00f". عند اختبار هذه الأداة الرائعة ، لاحظت شيئًا مثيرًا للاهتمام: لم تكن دائمًا المرة الأولى التي كان من الممكن فيها تحديد نوع جدار الحماية المستخدم.
لمعرفة أنواع جدران الحماية wafw00f المحتمل اكتشافها ، يمكنك إدخال الأمر التالي:
wafw00f -l
لتحديد نوع جدار الحماية ، يقوم wafw00f بتحليل رؤوس استجابة الخادم بعد إرسال طلب قياسي إلى الموقع ، وإذا لم تكن هذه المحاولة كافية ، فسيتم إنشاء طلب اختبار بسيط إضافي جيدًا ، وإذا لم تكن هذه كافية مرة أخرى ، فإن الطريقة الثالثة تعمل على البيانات بعد المحاولتين الأوليين .
لأن للحصول على إحصائيات ، في الواقع ، لسنا بحاجة إلى إجابة كاملة ، لقد قطعنا كل الزائد بتعبير منتظم ولم نترك سوى اسم جدار الحماية:
/is\sbehind\sa\s(.+?)\n/
حسنًا ، كما كتبت في وقت سابق - بالإضافة إلى معلومات حول المجال والموقع ، تم أيضًا تحديث معلومات حول عناوين البريد الإلكتروني والشبكات الاجتماعية في الوضع السلبي:
احصائيات عن طريق البريد الإلكتروني المعرفة على أساس المجال مثال على تحديد ربط الشبكات الاجتماعية بعنوان البريد الإلكتروني كانت أسهل طريقة للتعامل مع التحقق من صحة العنوان على Twitter (طريقتان) ، مع أن Facebook (طريقة واحدة) في هذا الصدد اتضح أنها أكثر تعقيدًا قليلاً بسبب وجود نظام أكثر تعقيدًا قليلاً لإنشاء جلسة مستخدم حقيقية.
دعنا ننتقل إلى الإحصاءات الجافة.
إحصائيات DNS
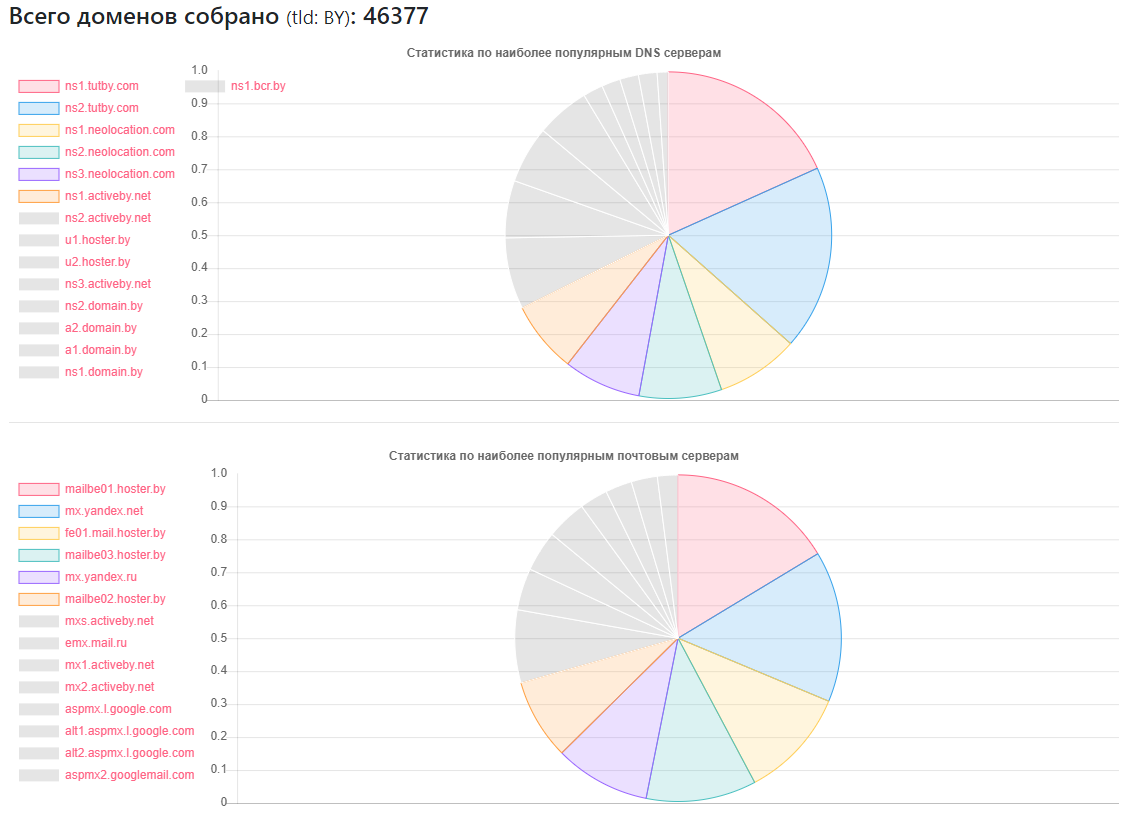 مزود - كم عدد المواقع
مزود - كم عدد المواقعns1.tutby.com: 10899
ns2.tutby.com: 10899
ns1.neolocation.com: 4877
ns2.neolocation.com: 4873
ns3.neolocation.com: 4572
ns1.activeby.net: 4231
ns2.activeby.net: 4229
u1.hoster.by: 3382
u2.hoster.by: 3378
تم العثور على DNS الفريد: 2462
خوادم MX الفريدة (البريد): 9175 (بالإضافة إلى الخدمات الشائعة ، يوجد عدد كاف من المسؤولين الذين يستخدمون خدمات البريد الخاصة بهم)
تتأثر بنقل منطقة DNS: 1011
تتأثر تضخيم DNS: 531
عدد قليل من مراوح CloudFlare: 375 (استنادًا إلى سجلات NS المستخدمة)
إحصاءات CMS
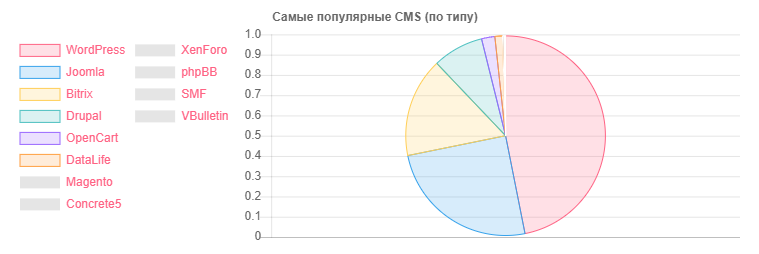 CMS - الكمية
CMS - الكميةوورد: 5118
جملة: 2722
Bitrix: 1757
دروبال: 898
OpenCart: 235
داتا لايف: 133
ماجينتو: 32
- المنشآت التي يحتمل أن تكون عرضة لـ WordPress: 2977
- المنشآت التي يحتمل أن تكون معرضة لجملة: 212
- باستخدام خدمة Google SafeBrowsing ، كان من الممكن تحديد المواقع التي يحتمل أن تكون خطرة أو مصابة: حوالي 10000 (في أوقات مختلفة ، شخص ثابت ، شخص ما على ما يبدو ، والإحصاءات ليست موضوعية بالكامل)
- حول HTTP و HTTPS - أقل من نصف مواقع وحدة التخزين التي تم العثور عليها تستخدم الأخير ، ولكن مع الأخذ بعين الاعتبار حقيقة أن قاعدة البيانات الخاصة بي ليست كاملة ، ولكن 40 ٪ فقط من العدد الإجمالي ، فمن الممكن أن معظم النصف الثاني من المواقع يمكن والتواصل عبر HTTPS .
إحصائيات جدار الحماية:
 جدار الحماية - رقم
جدار الحماية - رقمModSecurity: 4354
أمان تطبيق ويب IBM: 126
أفضل WP الأمن: 110
CloudFlare: 104
Imperva SecureSphere: 45
Juniper WebApp Secure: 45
إحصائيات خادم الويب
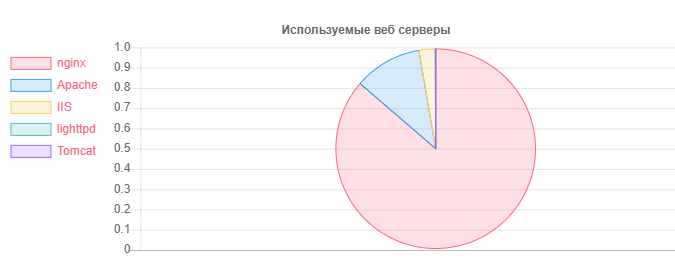 خادم الويب - رقم
خادم الويب - رقمNginx: 31752
اباتشي: 4042
معهد الدراسات الإسماعيلية: 959
المنشآت التي عفا عليها الزمن والتي يحتمل أن تكون معرضة للخطر من Nginx: 20966
إهمال ومن المحتمل أن تكون عرضة للخطر من أباتشي: 995
على الرغم من أن hoster.by هو الرائد في المجالات والاستضافة ، على سبيل المثال ، بشكل عام ، تم تمييز Open Contact أيضًا ، ولكن الحقيقة هي في عدد المواقع على IP واحد:
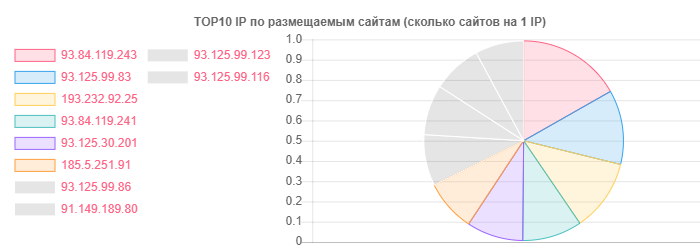 IP - المواقع
IP - المواقع93.84.119.243: 556
93.125.99.83: 399
193.232.92.25: 386
عبر البريد الإلكتروني ، قررت الإحصائيات المفصلة حقًا عدم سحبها أو فرزها حسب منطقة المجال ، بدلاً من ذلك ، كان من المثير رؤية موقع المستخدمين لبائعين محددين:
- على خدمة TUT.BY: 38282
- على خدمة ياندكس (بواسطة | رو): 28127
- على خدمة Gmail: 33452
- تعادل على الفيسبوك: 866
- تعادل تويتر: 652
- ظهرت في تسرب وفقا ل HIBP: 7844
- ساعد الذكاء السلبي في تحديد أكثر من 13 ألف عنوان بريد إلكتروني
كما ترون ، فإن الصورة العامة إيجابية جدًا ، خاصةً الاستخدام الفعال لـ nginx من جانب مزودي الاستضافة. ربما هذا يرجع إلى حد كبير إلى شعبية بين المستخدمين العاديين - نوع الاستضافة المشتركة.
من حقيقة أنني لم يعجبني حقًا - يوجد عدد كافٍ من مزودي الاستضافة من اليد الوسطى الذين لاحظوا أخطاء مثل AXFR ، واستخدموا إصدارات قديمة من SSH و Apache وبعض المشاكل الصغيرة الأخرى. هنا ، بالطبع ، يمكن إلقاء مزيد من الضوء على الوضع من خلال المرحلة النشطة ، ولكن في الوقت الحالي ، يبدو الأمر مستحيلًا بموجب تشريعاتنا ، ولا أود حقًا الانضمام إلى صفوف الآفات لمثل هذه الأمور.
صورة البريد الإلكتروني وردية بشكل عام ، إذا كان يمكنك تسمية ذلك. أوه نعم ، حيث يشار إلى مزود TUT.BY - هذا يعني استخدام المجال ، لأن هذه الخدمة تعمل على أساس ياندكس.
استنتاج
في الختام ، أستطيع أن أقول شيئًا واحدًا - حتى مع النتائج المتاحة ، يمكنك أن تفهم بسرعة أن هناك قدرًا كبيرًا من العمل للمتخصصين الذين يشاركون في تنظيف المواقع من الفيروسات ، وإعداد WAF ، وتكوين / إضافة CMS مختلفة.
حسنًا ، بجدية ، كما في المادتين السابقتين ، نرى أن المشاكل موجودة على مستويات مختلفة تمامًا في جميع قطاعات الإنترنت والبلدان ، وقد توصل بعضها إلى دراسة عن بُعد لهذه المشكلة ، دون استخدام أساليب هجومية ، إلخ. ه. استخدام المعلومات المتاحة للجمهور لجمع المهارات الخاصة التي ليست مطلوبة.