 أرسلت بواسطة دينيس تسيبلاكوف ، مهندس حلول ، DataArt
أرسلت بواسطة دينيس تسيبلاكوف ، مهندس حلول ، DataArtبيان المشكلة
واحدة من المشاكل عند بناء أبنية microservice وخاصة عند نقل بنية متجانسة إلى microservices غالباً ما تكون المعاملات. كل microservice مسؤولة عن مجموعة الوظائف الخاصة بها ، وربما تدير البيانات المرتبطة بهذه المجموعة ، ويمكن أن تخدم طلبات المستخدمين إما بشكل مستقل أو عن طريق إرسال طلبات إلى خدمات micros أخرى. كل هذا يعمل بشكل جيد ، حتى نحتاج إلى التأكد من اتساق البيانات التي يتم التحكم فيها بواسطة خدمات ميكروية مختلفة.
على سبيل المثال ، يعمل تطبيقنا في بعض المتاجر الكبيرة عبر الإنترنت. من بين أمور أخرى ، لدينا ثلاثة مجالات منفصلة للأعمال مترابطة ضعيفة:
- المستودع - ماذا ، وأين ، وكيف وإلى متى تم تخزينه ، وعدد البضائع من نوع معين الموجودة حاليًا ، وما إلى ذلك.
- إرسال البضائع - التغليف ، الشحن ، تتبع التسليم ، تحليل الشكاوى حول تأخيرها ، إلخ.
- الحفاظ على التقارير الجمركية حول حركة البضائع إذا تم إرسال البضائع إلى الخارج (في الواقع ، لا أعرف ما إذا كان من الضروري في هذه الحالة إعداد شيء خاص ، ولكن ما زلت سأربط خدمات الدولة بعملية إضافة الدراما).
يتضمن كل من هذه المجالات الثلاثة العديد من الوظائف المفككة ويمكن تمثيله على أنه العديد من الخدمات المصغرة.
هناك مشكلة واحدة. لنفترض أن شخصًا اشترى منتجًا ، وعبأه وأرسله عن طريق البريد. من بين أشياء أخرى ، نحتاج إلى الإشارة إلى أن هناك وحدة واحدة أقل من البضائع في المستودع ، ولاحظ أن عملية تسليم البضائع قد بدأت ، وإذا تم إرسال البضاعة ، على سبيل المثال ، إلى الصين ، لرعاية الأوراق للجمارك. في حالة تعطل التطبيق (على سبيل المثال ، تعطل العقدة) في المرحلة الثانية أو الثالثة من العملية ، ستصل بياناتنا إلى حالة غير متناسقة ، ويمكن أن يؤدي عدد قليل فقط من هذه الإخفاقات إلى مشاكل غير سارة تمامًا للشركة (على سبيل المثال ، زيارة مسؤولي الجمارك).
في بنية كلاسيكية متجانسة من هذا النوع ، يتم حل المشكلة ببساطة وأنيق عن طريق المعاملات في قاعدة البيانات. لكن ماذا لو استخدمنا خدمات ميكروية؟ حتى لو استخدمنا قاعدة بيانات واحدة من جميع الخدمات (وهي ليست أنيقة للغاية ، ولكن من الممكن في حالتنا) ، فإن العمل باستخدام قاعدة البيانات هذه يأتي من عمليات مختلفة ، ولن نتمكن من تمديد المعاملة بين العمليات.
حلول
المشكلة لها عدة حلول:
- الغريب ، يمكن في بعض الأحيان تجاهل المشكلة. إذا علمنا أن الفشل لا يحدث أكثر من مرة واحدة في الشهر ، والتخلص اليدوي من العواقب يكلف الأموال المقبولة للشركة ، لا يمكنك الانتباه إلى المشكلة ، بغض النظر عن مدى قبيحتها. لا أعرف ما إذا كان من الممكن تجاهل مطالبات دائرة الجمارك ، ولكن يمكن افتراض أنه حتى في بعض الظروف يكون ذلك ممكنًا.
- التعويض (هذا لا يتعلق بالتعويض النقدي للجمارك ، على سبيل المثال ، دفعت غرامة) هو مجموعة من الأنواع المختلفة من الخطوات التي تعقد تسلسل المعالجة ، ولكنها تسمح لك باكتشاف عملية فاشلة ومعالجتها. على سبيل المثال ، قبل بدء العملية ، نكتب إلى خدمة خاصة بأننا نبدأ عملية الشحن ، وفي النهاية نحتفل بأن كل شيء قد انتهى بشكل جيد. ثم نتحقق بشكل دوري لمعرفة ما إذا كان هناك أي عمليات معلقة ، وإذا كانت هناك أية عمليات ، وننظر في جميع قواعد البيانات الثلاث ، نحاول نقل البيانات إلى حالة متسقة. هذه طريقة فعالة تمامًا ، لكنها تُعقِّد منطق المعالجة إلى حد كبير ، ويؤدي القيام بذلك لكل عملية مؤلمة جدًا.
- المعاملات ثنائية الطور ، بالمعنى الدقيق للكلمة ، تعتبر مواصفات XA + ، التي تتيح لك إنشاء معاملات موزعة بالنسبة للتطبيقات ، آلية ثقيلة الوزن للغاية يحبها عدد قليل من الأشخاص ، والأهم من ذلك ، يمكن لعدد قليل من الأشخاص تكوينها. بالإضافة إلى ذلك ، مع خدمات مايكروسفت خفيفة الوزن ، فهي متوافقة إيديولوجياً بشكل ضعيف.
- من حيث المبدأ ، تعتبر المعاملة حالة خاصة لمشكلة الإجماع ، ويمكن استخدام العديد من أنظمة الإجماع الموزعة لحل المشكلة (بشكل عام ، كل ما هو google باستخدام الكلمات الأساسية paxos و raft و zookeeper و etcd و القنصل). لكن في التطبيق العملي للبيانات الواسعة والمتشعبة لنشاط المستودع ، يبدو كل هذا أكثر تعقيدًا من المعاملات ثنائية الطور.
- قوائم الانتظار والاتساق النهائي (الاتساق على المدى الطويل) - نقسم المهمة إلى ثلاث مهام غير متزامنة ، ونعالج البيانات بالتسلسل ، ونمررها بين الخدمات من قائمة الانتظار إلى قائمة الانتظار ، ونستخدم آلية تأكيد التسليم. في هذه الحالة ، الكود ليس معقدًا للغاية ، ولكن هناك بعض النقاط التي يجب وضعها في الاعتبار:
- تضمن قائمة الانتظار التسليم "مرة واحدة أو أكثر" ، أي عند إعادة تسليم الرسالة نفسها ، يجب على الخدمة التعامل مع هذا الموقف بشكل صحيح ، وليس شحن البضائع مرتين. يمكن القيام بذلك ، على سبيل المثال ، من خلال UUID الفريد للنظام.
- ستكون البيانات في أي وقت غير متسقة بعض الشيء. أي أن البضاعة ستختفي أولاً من المستودع وعندها فقط ، مع تأخير بسيط ، سيتم إنشاء أمر لإرساله. في وقت لاحق ، سيتم معالجة البيانات الجمركية. في المثال الخاص بنا ، هذا أمر طبيعي تمامًا ولا يسبب مشاكل للعمل ، ولكن هناك حالات قد يكون فيها سلوك البيانات هذا غير سارة للغاية.
- نتيجة لذلك ، إذا كان على الخدمة الأولى أن تعيد بعض البيانات إلى المستخدم ، فإن تسلسل المكالمات التي تسلم البيانات في النهاية إلى متصفح المستخدم يمكن أن يكون غير تافه تمامًا. المشكلة الرئيسية هي أن المتصفح يرسل الطلبات بشكل متزامن ويتوقع عادة استجابة متزامنة. إذا قمت بمعالجة طلب غير متزامن ، فأنت بحاجة إلى إنشاء تسليم غير متزامن للاستجابة للمتصفح. كلاسيكيًا ، يتم ذلك إما من خلال مآخذ الويب ، أو من خلال الطلبات الدورية لأحداث جديدة من المتصفح إلى الخادم. هناك آليات ، مثل SocksJS ، على سبيل المثال ، تعمل على تبسيط بعض جوانب بناء هذا الرابط ، ولكن سيظل هناك تعقيد إضافي.
في معظم الحالات ، يكون الخيار الأخير أكثر قبولًا. لا يؤدي إلى تعقيد طلب المعالجة إلى حد كبير ، على الرغم من أنه يعمل عدة مرات أطول ، ولكن كقاعدة عامة ، يكون هذا مقبولًا لهذا النوع من العمليات. يتطلب أيضًا تنظيم بيانات أكثر تعقيدًا بقليل لقطع الطلبات المتكررة ، لكن لا يوجد شيء معقد للغاية حول هذا الأمر.
بشكل تخطيطي ، قد يبدو أحد خيارات معالجة المعاملات باستخدام قوائم الانتظار والاتساق النهائي كما يلي:
- قام المستخدم بعملية شراء ، يتم إرسال رسالة حول هذا الأمر إلى قائمة الانتظار (على سبيل المثال ، مجموعة RabbitMQ أو ، إذا كنا نعمل في Google Cloud Platform - Pub / Sub). قائمة الانتظار ثابتة ، وتضمن التسليم مرة واحدة أو أكثر ، وتكون معاملات ، أي إذا سقطت الخدمة التي تعالج الرسالة فجأة ، فلن تضيع الرسالة ، ولكن سيتم تسليمها إلى مثيل جديد للخدمة مرة أخرى.
- تصل الرسالة إلى الخدمة ، التي تحدد البضائع الموجودة في المستودع على أنها معدة للشحن وترسل بدورها الرسالة "البضائع جاهزة للشحن" إلى قائمة الانتظار.
- في الخطوة التالية ، تتلقى الخدمة المسؤولة عن الإرسال رسالة حول الاستعداد للإرسال ، وتقوم بإنشاء مهمة إرسال ، ثم تقوم بإرسال رسالة "من المخطط إرسال البضائع".
- الخدمة التالية ، بعد تلقي رسالة مفادها أن عملية الإرسال مخطط لها ، تبدأ عملية الأعمال الورقية للجمارك.
علاوة على ذلك ، يتم فحص كل رسالة يتم تلقيها بواسطة الخدمة للتأكد من تفردها ، وإذا تم بالفعل معالجة رسالة بمثل UUID ، فسيتم تجاهلها.
هنا ، تكون قاعدة (قواعد) قاعدة البيانات في كل لحظة من الوقت في حالة غير متناسقة بعض الشيء ، أي أن البضائع الموجودة في المستودع قد تم تحديدها بالفعل على أنها في عملية التسليم ، ولكن مهمة التسليم نفسها ليست موجودة بعد ، وستظهر في ثانية أو اثنتين. ولكن في الوقت نفسه ، لدينا 99.999 ٪ (في الواقع ، هذا الرقم يساوي مستوى موثوقية خدمة قائمة الانتظار) يضمن أن تظهر مهمة الإرسال. بالنسبة لمعظم الشركات ، هذا مقبول.
ما هو المقال عن ذلك الحين؟
في المقالة ، أود التحدث عن طريقة أخرى لحل مشكلة المعاملات في تطبيقات الخدمات المصغرة. على الرغم من أن خدمات microservices تعمل بشكل أفضل عندما يكون لكل خدمة قاعدة بيانات خاصة بها ، للأنظمة الصغيرة والمتوسطة الحجم ، فإن جميع البيانات ، كقاعدة عامة ، تتناسب بسهولة مع قاعدة بيانات علائقية حديثة. هذا صحيح بالنسبة لأي نظام مؤسسة داخلي تقريبًا. وهذا يعني أننا لا نحتاج غالبًا إلى مشاركة البيانات بين الأجهزة المادية المختلفة. يمكننا تخزين البيانات من خدمات micros مختلفة في مجموعات غير مرتبطة بجداول من نفس قاعدة البيانات. يعتبر هذا مناسبًا بشكل خاص إذا كنت تقوم بتقسيم تطبيق قديم ومتجانس إلى خدمات وقمت بالفعل بتقسيم الرمز ، لكن البيانات لا تزال موجودة في نفس قاعدة البيانات. ومع ذلك ، لا تزال مشكلة تقسيم المعاملة قائمة - ترتبط المعاملة بشكل صارم باتصال الشبكة ، وبالتالي العملية التي فتحت هذا الاتصال ، ولدينا عمليات منفصلة. كيف تكون
أعلاه ، لقد وصفت العديد من الطرق الشائعة لحل المشكلة ، لكنني أريد كذلك تقديم طريقة أخرى لحالة خاصة ، عندما تكون جميع البيانات في نفس قاعدة البيانات.
لا أوصي بمحاولة تنفيذ هذه الطريقة
في هذا المشروع ، لكن من الغريب
أن أقدمها في المقالة. حسنًا ، فجأة سيكون مفيدًا في بعض الحالات الخاصة.
جوهرها بسيط جدا. ترتبط المعاملة باتصال الشبكة ، ولا تعرف قاعدة البيانات حقًا من يجلس على هذه النهاية من اتصال الشبكة المفتوحة. إنها لا تهتم ، الشيء الرئيسي هو أن الأوامر الصحيحة تصل إلى المقبس. من الواضح أن مأخذ التوصيل ينتمي عادةً إلى عملية واحدة من جانب العميل ، ولكن أرى ثلاث طرق على الأقل للتغلب على ذلك.
1. تغيير رمز قاعدة البيانات
على مستوى رمز قاعدة البيانات لقواعد البيانات ، والتي يمكننا تغيير الكود الخاص بها ، مما يجعل تجميع قاعدة البيانات الخاصة بنا ، نطبق آلية نقل المعاملات بين الاتصالات. كيف يمكن أن تعمل من وجهة نظر العميل:
- نبدأ المعاملة ، ونجري بعض التغييرات ، فقد حان الوقت لنقل المعاملة إلى الخدمة التالية.
- نقول لقاعدة البيانات أن تقدم لنا UUID للمعاملة وانتظر N ثانية. إذا لم يكن هناك اتصال آخر بهذا UUID خلال هذا الوقت ، فقم بإعادة المعاملة ، وإذا حدث ذلك ، فقم بنقل جميع هياكل البيانات المرتبطة بالمعاملة إلى الاتصال الجديد واستمر في العمل معها.
- نقوم بتمرير UUID إلى الخدمة التالية (أي إلى عملية أخرى ، وربما إلى VM آخر).
- في ذلك ، افتح اتصال ومنح الأمر DB - متابعة المعاملة مع UUID المحدد.
- نواصل العمل مع قاعدة البيانات كجزء من معاملة بدأت بواسطة عملية أخرى.
هذه الطريقة هي الأكثر خفيفة الوزن للاستخدام ، ولكنها تتطلب تعديل رمز قاعدة البيانات ، وعادة ما لا يقوم مبرمجو التطبيق بذلك ، فهو يتطلب الكثير من المهارات الخاصة. على الأرجح ، سيكون من الضروري نقل البيانات بين عمليات قاعدة البيانات ، وقواعد البيانات ، والتي يمكننا تغيير رمزها بأمان إلى حد كبير - PostgreSQL. بالإضافة إلى ذلك ، لن يعمل هذا إلا مع الخوادم غير المُدارة ، ولن تذهب معه في RDS أو Cloud SQL.
بشكل تخطيطي ، يبدو كما يلي:

2. التلاعب في مآخذ
الشيء الثاني الذي يتبادر إلى الذهن هو التلاعب الخفي باتصالات قاعدة البيانات عن طريق مآخذ. يمكننا أن نجعل بعض "الوكيل عكس مأخذ التوصيل" ، الذي يوجه الأوامر القادمة من عدة عملاء إلى منفذ معين في تيار قيادة واحد إلى قاعدة البيانات.
في الواقع ، يشبه هذا التطبيق إلى حد كبير pgBouncer ، فقط ، بالإضافة إلى وظائفه القياسية ، القيام ببعض التلاعب مع دفق البايت من العملاء والقدرة على استبدال عميل بآخر عند الأمر.
لا أحب هذه الطريقة بشدة ، فمن الضروري لتنظيف الحزم الثنائية المتداولة بين الخادم والعملاء لتنفيذه. ولا يزال يتطلب الكثير من برمجة النظام. أحضرت ذلك فقط من أجل اكتماله.
3. بوابة JDBC
يمكننا أن نجعل برنامج تشغيل بوابة JDBC - نأخذ برنامج تشغيل JDBC القياسي لقاعدة بيانات محددة ، فليكن PostgreSQL. نحن نلتف الطبقة ونصنع واجهات HTTP لجميع طرقها الخارجية (وليس HTTP ، لكن الفرق صغير). بعد ذلك ، نقوم بإنشاء برنامج تشغيل JDBC آخر - واجهة تعيد توجيه جميع استدعاءات الطرق إلى بوابة JDBC. وهذا هو ، في الواقع ، نحن نشهد برنامج التشغيل الحالي في نصفين وربط هذه النصفين عبر الشبكة. نحصل على مخطط المكون التالي:
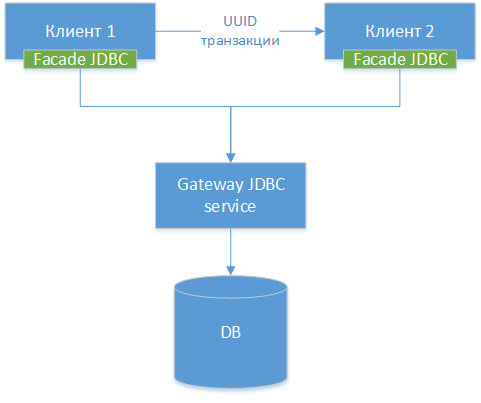 ملاحظة: كما نرى ، فإن الخيارات الثلاثة متشابهة ، والفرق الوحيد هو في أي مستوى ننقل الاتصال والأدوات التي نستخدمها لهذا الغرض.
ملاحظة: كما نرى ، فإن الخيارات الثلاثة متشابهة ، والفرق الوحيد هو في أي مستوى ننقل الاتصال والأدوات التي نستخدمها لهذا الغرض.
بعد ذلك ، نعلم سائقنا القيام بنفس الخدعة بشكل أساسي من خلال معاملة UUID الموضحة في الطريقة الأولى.
في كود تطبيق Java ، قد يبدو استخدام هذه الطريقة بهذا الشكل.
الخدمة أ - بدء المعاملة
يوجد أدناه رمز لبعض الخدمات التي تبدأ معاملة ، وتجري تغييرات على قاعدة البيانات وتنقلها إلى خدمة أخرى لإكمالها. في الكود ، نستخدم العمل المباشر مع فئات JDBC. بالطبع ، لا أحد يفعل هذا في عام 2019 ، ولكن من أجل البساطة ، تم تبسيط الكود.
خدمة B - إكمال المعاملة
التفاعل مع المكونات والأطر الأخرى
النظر في الآثار الجانبية المحتملة لمثل هذا الحل المعماري.
تجمع اتصال
نظرًا لأن لدينا في الواقع تجمع اتصال حقيقي داخل بوابة JDBC - من الأفضل إيقاف تشغيل تجمعات الاتصال في الخدمات ، لأنهم سيحصلون على اتصال داخل الخدمة ويمكن استخدامه بواسطة خدمة أخرى.
بالإضافة إلى ذلك ، بعد تلقي UUID وانتظار النقل إلى عملية أخرى ، يصبح الاتصال غير فعال بشكل أساسي ، ومن وجهة نظر الواجهة الأمامية JDBC ، يتم إغلاقه تلقائيًا ، ومن وجهة نظر البوابة JDBC ، يجب أن يتم الاحتفاظ به دون إعطاء أي شخص آخر غير من سوف يأتي مع UUID المطلوب.
بمعنى آخر ، يمكن أن تؤدي الإدارة المزدوجة لتجمع الاتصال في Gateway JDBC وداخل كل خدمة إلى حدوث أخطاء دقيقة وغير سارة.
نقابة الصحفيين
مع JPA ، أرى مشكلتين محتملتين:
- إدارة المعاملات. عند ارتكاب JPA ، قد يفكر المحرك في أنه قد حفظ جميع البيانات ، بينما لم يتم حفظها. على الأرجح ، يجب أن تحل الإدارة اليدوية للمعاملات و flush () قبل نقل المعاملة المشكلة.
- من المحتمل أن تعمل ذاكرة التخزين المؤقت من المستوى الثاني بشكل غير صحيح ، ولكن في الأنظمة الموزعة يكون استخدامها محدودًا على أي حال.
المعاملات الربيع
ربما لا يمكن تنشيط آلية إدارة المعاملات Spring ، وسيكون عليك إدارتها يدويًا. أنا متأكد تقريبًا من إمكانية توسيعه - على سبيل المثال ، لكتابة نطاق مخصص - ولكن للتأكيد على وجه اليقين ، نحتاج إلى دراسة كيفية ترتيب تمديد معاملات Spring هناك ، لكنني لم أنظر هناك بعد.
إيجابيات وسلبيات
الأشياء الجيدة
- عمليا لا يتطلب تعديل الكود المتجانسة الموجود عند النشر.
- يمكنك كتابة المعاملات المعقدة عبر الخادم دون أي تعقيد رمز تقريبًا.
- يسمح لك بالقيام بعملية التتبع عبر الخدمة لتنفيذ المعاملة.
- الحل مرن للغاية ، يمكنك استخدام المعاملات الكلاسيكية حيث لا يكون التوزيع مطلوبًا ومشاركة المعاملة فقط لتلك العمليات التي تتطلب التفاعل عبر الخدمة.
- ليس مطلوبًا من فريق المشروع إتقان التقنيات الجديدة بالقوة. التقنيات الحديثة جيدة بالطبع ، لكن المهمة - من الضروري والعاجل (حتى الأمس!) لتعليم 20 مطورًا مفهوم بناء أنظمة تفاعلية - أن تكون غير بديهية للغاية. ومع ذلك ، ليس هناك ما يضمن أن جميع الأشخاص العشرين سيكملون التدريب في الوقت المحدد.
سلبيات
- غير قابل للتحجيم ، وفي الواقع ، غير معياري على مستوى قاعدة البيانات ، على عكس حل في قائمة الانتظار. لا يزال لديك قاعدة بيانات واحدة تتلاقى فيها جميع الاستعلامات وتحميل كامل. بهذا المعنى ، يكون الحل مسدودًا: إذا كنت تريد لاحقًا زيادة الحمل أو جعل الحل معياريًا وفقًا للبيانات ، فسيتعين عليك إعادة كل شيء.
- يجب أن تكون حذراً للغاية في نقل معاملة بين العمليات ، وخاصة العمليات المكتوبة في أطر العمل. تحتوي الجلسات على إعداداتها الخاصة ، وبالنسبة للعديد من الأطر ، يمكن أن يؤدي التغيير المفاجئ في اتصال قاعدة البيانات إلى عملية غير صحيحة. انظر ، على سبيل المثال ، إعدادات الجلسة ومعاملات PostgreSQL.
- عندما أخبرت الفكرة في دردشة المهندس المعماري المحلي لدينا على DataArt ، أول ما سألني زملائي هو ما إذا كنت أشرب الخمر (لا ، لا أشرب الخمر!). لكنني أعترف أن الفكرة ، ولنقل ، ليست هي الأكثر انتشارًا ، وإذا قمت بتنفيذها في مشروعك ، فستبدو غير عادية بالنسبة للمشاركين الآخرين.
- يتطلب برنامج تشغيل JDBC مخصص. الكتابة يستغرق وقتًا ، يجب عليك تصحيحها ، والبحث عن الأخطاء فيها ، بما في ذلك تلك التي تسببها أخطاء اتصال الشبكة ، إلخ.
تحذير
لقد حذرتك مرة أخرى:
لا تحاول تكرار هذه الخدعة في المنزل في هذا المشروع ، إلا إذا كان لديك تفسير واضح للغاية لسبب حاجتك إليها ، وإثبات دليل مقنع على أنه لا توجد طريقة أخرى على الإطلاق.
كل ذلك من الأول من أبريل!