يتم نشر المقال نيابة عن جون أخالتسيف ، جيجا
Tinkoff.ru اليوم ليس مجرد بنك ، بل هو شركة تكنولوجيا المعلومات. إنه لا يوفر الخدمات المصرفية فحسب ، بل يبني أيضًا نظامًا بيئيًا من حولهم.
نحن في Tinkoff.ru ندخل في شراكة مع مختلف الخدمات لتحسين جودة خدمة العملاء ، والمساعدة في أن نصبح خدمات أفضل. على سبيل المثال ، أجرينا اختبار الحمل وتحليل الأداء لأحد هذه الخدمات التي ساعدت في العثور على الاختناقات في النظام - وشملت صفحات ضخمة شفافة في تكوين نظام التشغيل.
إذا كنت ترغب في معرفة كيفية إجراء تحليل لأداء النظام وماذا جاء معنا ، فمرحباً بك في cat.
وصف المشكلة
في الوقت الحالي ، بنية الخدمة هي:
- خادم الويب Nginx لمعالجة اتصالات HTTP
- php-fpm للتحكم في عملية php
- Redis للتخزين المؤقت
- PostgreSQL لتخزين البيانات
- حل التسوق وقفة واحدة
كانت المشكلة الرئيسية التي وجدناها أثناء عملية البيع التالية تحت الحمل الكبير هي الاستخدام العالي لوحدة المعالجة المركزية ، بينما زاد وقت المعالج في وضع kernel (وقت النظام) وكان أطول من الوقت في وضع المستخدم (وقت المستخدم).
- وقت المستخدم - الوقت الذي يقضيه المعالج في مهام المستخدم. هذا هو الشيء الرئيسي الذي تدفعه مقابل شراء معالج.
- وقت النظام - مقدار الوقت الذي يقضيه النظام في الترحيل وتغيير السياقات وتشغيل المهام المجدولة ومهام النظام الأخرى.
تحديد الخصائص الأساسية للنظام
بادئ ذي بدء ، جمعنا دائرة تحميل بموارد قريبة من الإنتاجية ، وقمنا بتجميع ملف تعريف تحميل مطابق للتحميل العادي في يوم عادي.
تم اختيار Gatling الإصدار 3 كأداة للقصف ، وتم تنفيذ القصف نفسه داخل الشبكة المحلية عبر عداء gitlab. يرجع موقع الوكلاء والأهداف في نفس الشبكة المحلية إلى انخفاض تكاليف الشبكة ، لذلك نحن نركز على التحقق من تنفيذ التعليمات البرمجية نفسها ، وليس على أداء البنية التحتية التي تم نشر النظام فيها.
عند تحديد الخصائص الأساسية للنظام ، يكون سيناريو مع زيادة الحمل الخطي بتكوين http مناسبًا:
val httpConfig: HttpProtocolBuilder = http .baseUrl("https://test.host.ru") .inferHtmlResources()
في هذه المرحلة ، قمنا بتنفيذ برنامج نصي لفتح الصفحة الرئيسية وتنزيل جميع الموارد

أظهرت نتائج هذا الاختبار أقصى أداء قدره 1500 دورة في الثانية ، مما أدى إلى زيادة شدة الحمل إلى تدهور النظام المرتبط بزيادة وقت softirq.


Softirq هي آلية مقاطعة مؤجلة ويتم وصفها في ملف kernel / softirq.s. في الوقت نفسه ، يقررون قائمة الإرشادات إلى المعالج ، مما يمنعهم من إجراء حسابات مفيدة في وضع المستخدم. يمكن لمعالجات المقاطعة أيضًا تأخير العمل الإضافي مع حزم الشبكة في مؤشرات ترابط نظام التشغيل (وقت النظام). باختصار حول عمل مكدس الشبكة والتحسينات يمكن العثور عليها في مقالة منفصلة .
لم يتم تأكيد الشكوك حول المشكلة الرئيسية ، لأنه كان هناك وقت أطول بكثير على النظام مع نشاط أقل على الشبكة.
نصوص المستخدم
كانت الخطوة التالية هي تطوير برامج نصية مخصصة وإضافة شيء أكثر من مجرد فتح صفحة بها صور. يتضمن ملف التعريف عمليات ثقيلة ، تتضمن بشكل كامل رمز الموقع وقاعدة البيانات ، وليس خادم ويب يوفر موارد ثابتة.
تم إطلاق اختبار الحمل المستقر بكثافة أقل من الحد الأقصى ، وتمت إضافة انتقال إعادة التوجيه إلى التكوين:
val httpConfig: HttpProtocolBuilder = http .baseUrl("https://test.host.ru") .inferHtmlResources()
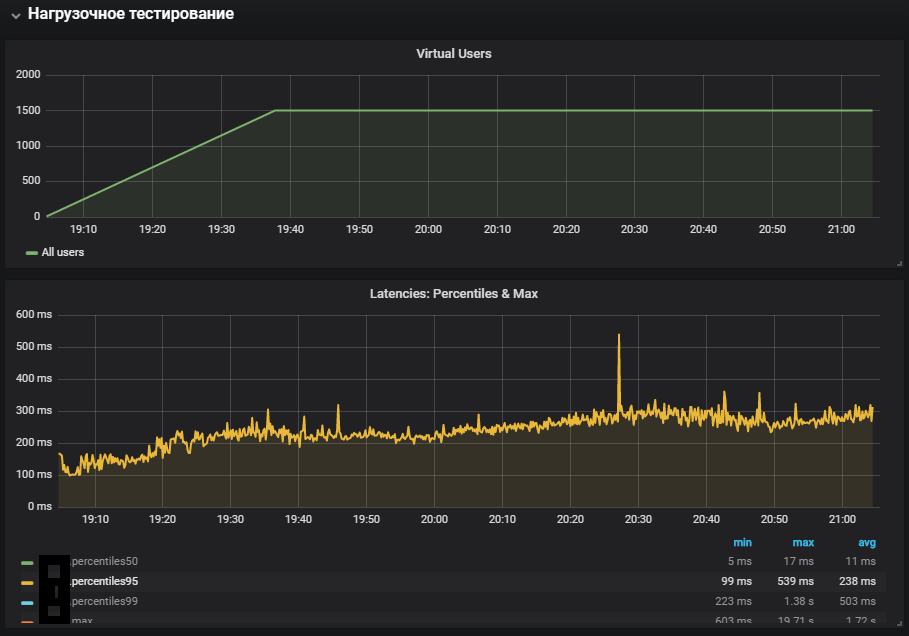

أظهر الاستخدام الأكثر اكتمالا للأنظمة زيادة في قياس وقت النظام ، وكذلك نموه خلال اختبار الاستقرار. تم تكرار المشكلة المتعلقة ببيئة الإنتاج.
التواصل مع Redis
عند تحليل المشكلات ، من المهم جدًا مراقبة جميع مكونات النظام لفهم كيفية عمله وتأثير الحمل الموفر عليه.
مع ظهور مراقبة Redis ، أصبح من الممكن عدم النظر إلى المقاييس العامة للنظام ، ولكن إلى مكوناته المحددة. تم تغيير سيناريو اختبار الإجهاد ، مما ساعد ، إلى جانب المراقبة الإضافية ، على معالجة مشكلة توطين المشكلة.

في المراقبة ، رأى Redis صورة مماثلة باستخدام وحدة المعالجة المركزية ، أو بالأحرى ، وقت النظام أطول بكثير من وقت المستخدم ، في حين أن الاستخدام الرئيسي لوحدة المعالجة المركزية كان في عملية SET ، أي تخصيص ذاكرة الوصول العشوائي لتخزين القيمة.

للقضاء على تأثير تفاعل الشبكة مع Redis ، تقرر اختبار الفرضية وتحويل Redis إلى مقبس UNIX بدلاً من مقبس tcp. تم ذلك في الإطار الذي يتم من خلاله ربط php-fpm بقاعدة البيانات. في الملف / yiisoft/yii/framework/caching/CRedisCache.php ، استبدلنا السطر من host: port بـ redis.sock hardode. اقرأ المزيد عن أداء المقبس في المقالة .
protected function connect() { $this->_socket=@stream_socket_client(
لسوء الحظ ، لم يكن لهذا تأثير كبير. استقر استخدام وحدة المعالجة المركزية قليلاً ، لكنه لم يحل مشكلتنا - كان معظم استخدام وحدة المعالجة المركزية في الحوسبة في وضع kernel.
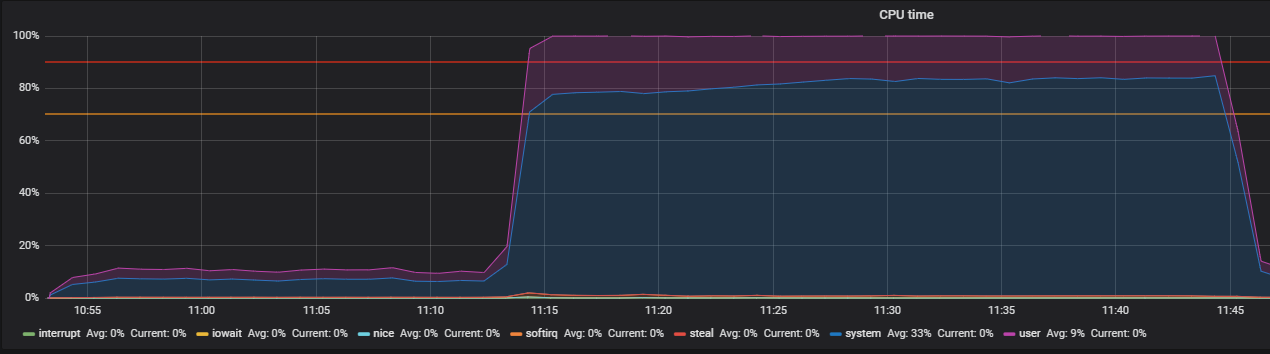
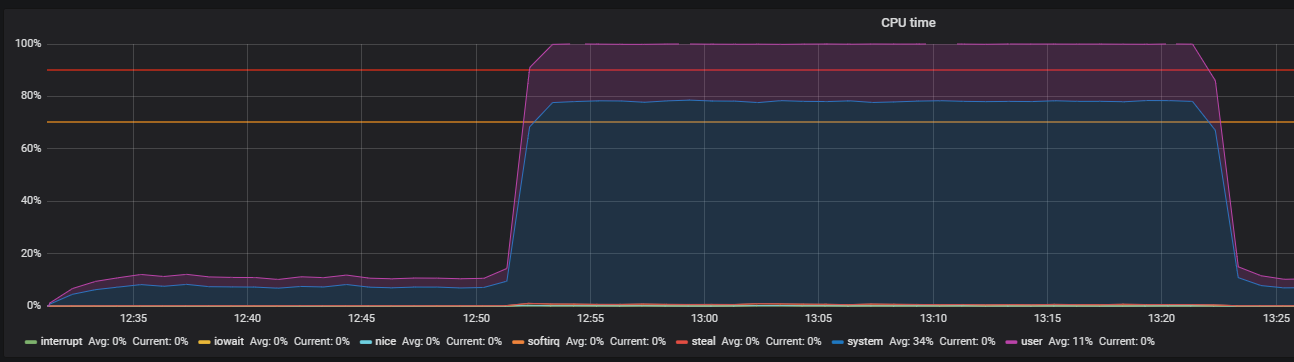
المعيار باستخدام الإجهاد وتحديد مشاكل THP
ساعدت أداة الإجهاد في توطين المشكلة - مولد عبء عمل بسيط لأنظمة POSIX ، والذي يمكن تحميل مكونات النظام الفردية ، على سبيل المثال ، وحدة المعالجة المركزية والذاكرة و IO.
يفترض الاختبار على إصدار الأجهزة ونظام التشغيل:
أوبونتو 18.04.1 LTS
12 وحدة المعالجة المركزية Intel® Xeon®
يتم تثبيت الأداة المساعدة باستخدام الأمر:
sudo apt-get install stress
ننظر إلى كيفية استخدام وحدة المعالجة المركزية تحت الحمل ، ونجري اختبارًا يخلق عمالًا لحساب الجذور التربيعية لمدة 300 ثانية:
-c, --cpu N spawn N workers spinning on sqrt() > stress --cpu 12 --timeout 300s stress: info: [39881] dispatching hogs: 12 cpu, 0 io, 0 vm, 0 hdd
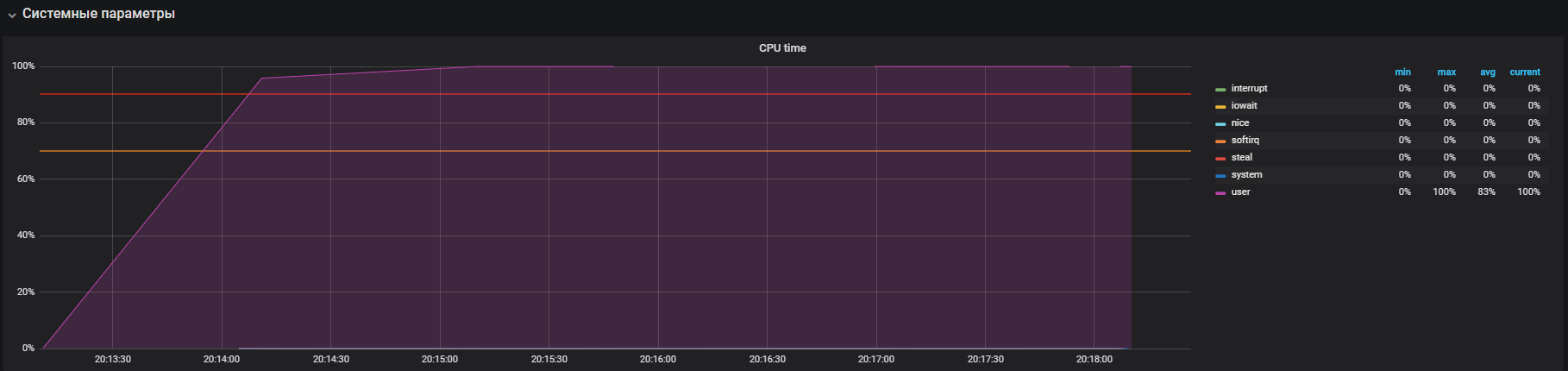
يوضح الرسم البياني الاستخدام الكامل في وضع المستخدم - وهذا يعني أن جميع مراكز المعالج يتم تحميلها وإجراء حسابات مفيدة ، وليس مكالمات خدمة النظام.
والخطوة التالية هي استخدام الموارد عند العمل بشكل مكثف مع io. قم بإجراء الاختبار لمدة 300 ثانية مع إنشاء 12 عاملاً يقومون بتنفيذ المزامنة (). يكتب أمر المزامنة البيانات المخزنة مؤقتًا في الذاكرة على القرص. يقوم kernel بتخزين البيانات في الذاكرة لتجنب عمليات قراءة وكتابة القرص (عادةً ما تكون بطيئة). يضمن الأمر sync () كتابة كل شيء مخزّن في الذاكرة على القرص.
-i, --io N spawn N workers spinning on sync() > stress --io 12 --timeout 300s stress: info: [39907] dispatching hogs: 0 cpu, 0 io, 0 vm, 12 hdd

نرى أن المعالج يعمل بشكل رئيسي في معالجة المكالمات في وضع kernel وقليلا في iowait ، يمكنك أيضًا رؤية> 35k ops يكتب على القرص. يشبه هذا السلوك مشكلة ارتفاع وقت النظام ، حيث نحلل أسبابه. ولكن هنا توجد عدة اختلافات: هذه iowait و iops أكبر من تلك الموجودة في الدائرة الإنتاجية ، على التوالي ، وهذا لا يناسب حالتنا.
لقد حان الوقت للتحقق من ذاكرتك. نطلق 20 عاملاً يقومون بتخصيص ذاكرة مجانية لمدة 300 ثانية باستخدام الأمر:
-m, --vm N spawn N workers spinning on malloc()/free() > stress -m 20 --timeout 300s stress: info: [39954] dispatching hogs: 0 cpu, 0 io, 20 vm, 0 hdd
نرى على الفور الاستخدام العالي لوحدة المعالجة المركزية في وضع النظام والقليل في وضع المستخدم ، وكذلك استخدام ذاكرة الوصول العشوائي بأكثر من 2 جيجابايت.
تشبه هذه الحالة إلى حد كبير مشكلة prod ، والتي تؤكدها الاستخدام الكبير للذاكرة في اختبارات الحمل. لذلك ، يجب البحث عن المشكلة في عملية الذاكرة. يحدث تخصيص الذاكرة وتحريرها بمساعدة malloc والمكالمات المجانية ، على التوالي ، والتي ستتم معالجتها في النهاية بواسطة مكالمات نظام kernel ، مما يعني أنه سيتم عرضها في استخدام وحدة المعالجة المركزية (CPU) كوقت للنظام.
في معظم أنظمة التشغيل الحديثة ، يتم تنظيم الذاكرة الظاهرية باستخدام الترحيل ، مع هذا النهج ، تنقسم مساحة الذاكرة بأكملها إلى صفحات بطول ثابت ، على سبيل المثال 4096 بايت (افتراضي للعديد من الأنظمة الأساسية) ، وعند تخصيص ، على سبيل المثال ، 2 غيغابايت من الذاكرة ، سيتعين على مدير الذاكرة العمل أكثر من 500000 صفحة. في هذا النهج ، توجد حملات إدارة كبيرة وصفحات ضخمة وقد تم اختراع تقنيات صفحات الشفافية الضخمة لتقليلها ، بمساعدتهم يمكنك زيادة حجم الصفحة ، على سبيل المثال ، إلى 2 ميغابايت ، مما سيؤدي إلى تقليل عدد الصفحات في كومة الذاكرة بشكل كبير. الفرق في التكنولوجيا هو أنه بالنسبة للصفحات الضخمة ، يجب علينا تهيئة البيئة بشكل صريح وتعليم البرنامج كيفية التعامل معها ، بينما تعمل شفرات الصفحات الضخمة "بشفافية" للبرامج.
THP وحل المشكلات
إذا كنت تمتلك معلومات حول صفحات Huge الشفافة ، فيمكنك أن ترى في نتائج البحث عددًا كبيرًا من الصفحات مع الأسئلة "كيفية إيقاف تشغيل THP".
كما اتضح فيما بعد ، تم تقديم هذه الميزة "اللطيفة" بواسطة شركة ريد هات في نواة لينكس ، وجوهر هذه الميزة هو أن التطبيقات يمكن أن تعمل بشفافية مع الذاكرة ، كما لو كانت تعمل مع صفحة ضخمة حقيقية. وفقًا للمعايير ، تسرع THP التطبيق التجريدي بنسبة 10٪ ، ويمكنك رؤية المزيد من التفاصيل في العرض التقديمي ، ولكن في الواقع كل شيء مختلف. في بعض الحالات ، يتسبب THP في زيادة غير معقولة في استهلاك وحدة المعالجة المركزية في الأنظمة. لمزيد من المعلومات ، راجع توصيات Oracle.
نذهب والتحقق من المعلمة لدينا. عند تشغيله ، يتم تشغيل THP افتراضيًا ، فنحن نطفئه باستخدام الأمر:
echo never > /sys/kernel/mm/transparent_hugepage/enabled
نؤكد مع الاختبار قبل إيقاف تشغيل THP وبعد ذلك ، في ملف تعريف التحميل:
setUp( MainScenario.inject( rampUsers(150) during (200 seconds)), Peak.inject( nothingFor(20 minutes), rampUsers(5000) during (30 minutes)) ).protocols(httpConfig)

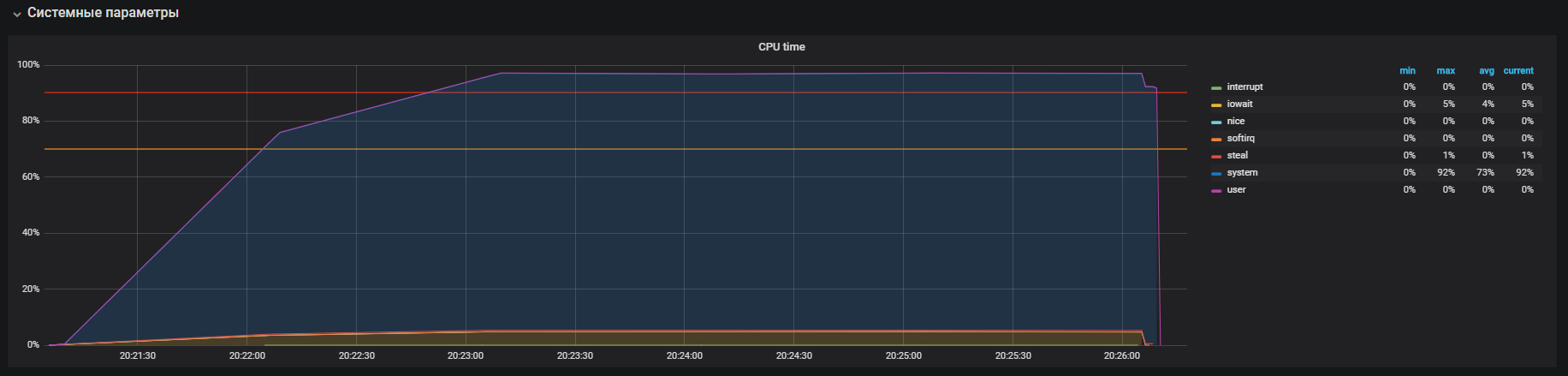
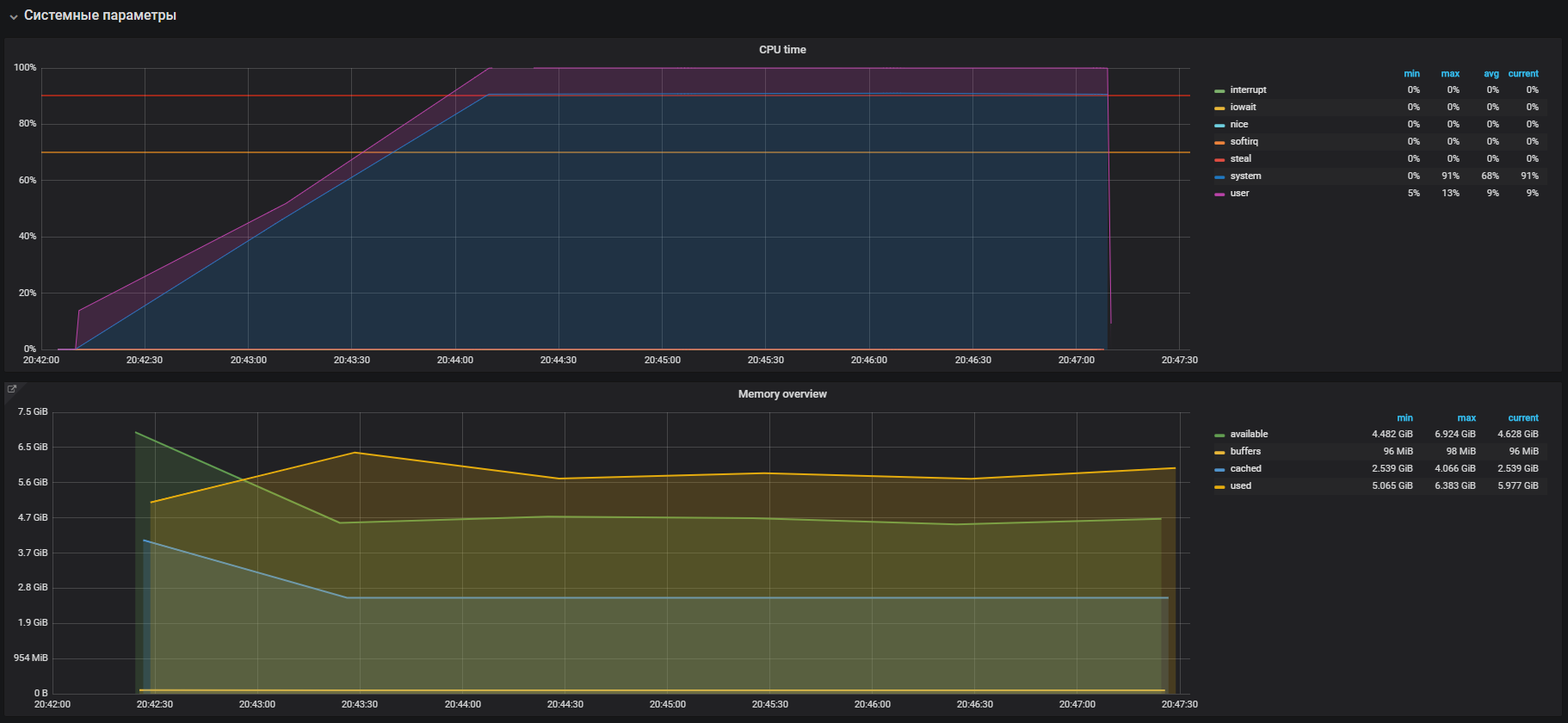
شاهدنا هذه الصورة قبل إيقاف تشغيل THP

بعد إيقاف تشغيل THP ، يمكننا مراقبة استخدام الموارد المخفض بالفعل.
المشكلة الرئيسية كانت محلية. تم تمكين السبب بشكل افتراضي في نظام التشغيل
آلية صفحات كبيرة شفافة. بعد تعطيل خيار THP ، انخفض استخدام وحدة المعالجة المركزية في وضع النظام مرتين على الأقل ، مما أدى إلى توفير الموارد لوضع المستخدم. أثناء تحليل المشكلة الرئيسية ، تم العثور على "اختناقات" التفاعل مع مكدس الشبكة لنظام التشغيل و Redis ، وهذا هو السبب وراء دراسة أعمق. لكن هذه قصة مختلفة تماما.
استنتاج
في الختام ، أود أن أقدم بعض النصائح للبحث بنجاح عن مشاكل الأداء:
- قبل البحث عن أداء النظام ، تفهم بنية تفاعلاته ومكوناته بعناية.
- قم بتكوين المراقبة لجميع مكونات النظام والمسار ، إذا لم تكن هناك قياسات قياسية كافية ، فانتقل إلى أعمق وتوسع.
- قراءة الأدلة على النظم المستخدمة.
- تحقق من الإعدادات الافتراضية في ملفات التكوين الخاصة بنظام التشغيل ومكونات النظام.