لقد ناقشنا بالفعل
محرك فهرسة PostgreSQL ،
وواجهة طرق الوصول ، وثلاث طرق:
فهرس التجزئة ، و
B-tree ، و
GiST . في هذه المقالة ، سنصف SP-GiST.
SP-GIST
أولاً ، بضع كلمات حول هذا الاسم. يلمح الجزء "GiST" إلى بعض التشابه مع طريقة الوصول التي تحمل الاسم نفسه. التشابه موجود: كلاهما أشجار بحث معممة توفر إطارًا لإنشاء طرق وصول مختلفة.
"SP" تعني تقسيم الفضاء. غالبًا ما يكون الفضاء هنا هو ما نستخدمه لاستدعاء مساحة ، على سبيل المثال ، طائرة ثنائية الأبعاد. لكننا سنرى أن أي مساحة بحث تعني أي مجال قيمة بالفعل.
SP-GiST مناسب للهياكل حيث يمكن تقسيم المساحة بشكل متكرر إلى مناطق
غير متقاطعة . تتكون هذه الفئة من الأرباع والأشجار ثلاثية الأبعاد (أشجار kD) وأشجار الجذر.
هيكل
لذلك ، تتمثل فكرة طريقة الوصول إلى SP-GiST في تقسيم مجال القيمة إلى نطاقات فرعية
غير متداخلة يمكن تقسيم كل منها بدوره. تقسيم مثل هذا يدفع الأشجار
غير متوازنة (على عكس الأشجار B و GiST العادية).
تعمل ميزة عدم التقاطع على تبسيط عملية صنع القرار أثناء الإدراج والبحث. من ناحية أخرى ، وكقاعدة عامة ، فإن الأشجار المستحثة تكون متفرعة بشكل منخفض. على سبيل المثال ، عادةً ما تحتوي عقدة العقدة الرباعية على أربعة عُقَد فرعية (على عكس الأشجار B ، حيث تبلغ العُقد المئات) وعمقًا أكبر. الأشجار مثل هذه تتناسب بشكل جيد مع العمل في ذاكرة الوصول العشوائي ، ولكن الفهرس مخزّن على قرص وبالتالي ، لتقليل عدد عمليات الإدخال / الإخراج ، يجب أن يتم تجميع العقد في صفحات ، وليس من السهل القيام بذلك بكفاءة. بالإضافة إلى ذلك ، قد يختلف الوقت الذي يستغرقه البحث عن قيم مختلفة في الفهرس بسبب الاختلافات في أعماق الفروع.
تهتم طريقة الوصول هذه ، شأنها في ذلك شأن GiST ، بالمهام ذات المستوى المنخفض (الوصول المتزامن والأقفال والتسجيل وخوارزمية البحث الخالصة) وتوفر واجهة مبسطة متخصصة لتمكين إضافة دعم لأنواع البيانات الجديدة ولخوارزميات التقسيم الجديدة.
عقدة داخلية من شجرة SP-GiST بتخزين الإشارات إلى العقد التابعة؛ يمكن تعريف
التسمية لكل مرجع. الى جانب ذلك ، يمكن للعقدة الداخلية تخزين قيمة تسمى
البادئة . في الواقع هذه القيمة ليست إلزامية بادئة. يمكن اعتباره مسند تعسفي يتم استيفائه لكل العقد الفرعية.
تحتوي العقد الورقية لـ SP-GiST على قيمة من النوع المفهرس ومرجع إلى صف جدول (TID). يمكن استخدام البيانات المفهرسة نفسها (مفتاح البحث) كقيمة ، ولكنها ليست إلزامية: يمكن تخزين قيمة مختصرة.
بالإضافة إلى ذلك ، يمكن تجميع العقد الورقية في القوائم. لذلك ، يمكن أن تشير العقدة الداخلية ليس فقط إلى قيمة واحدة ، ولكن إلى قائمة كاملة.
لاحظ أن البادئات والتسميات والقيم في العقد الورقية لها أنواع بيانات خاصة بها ، مستقلة عن بعضها البعض.
بنفس الطريقة الموجودة في GiST ، فإن الوظيفة الرئيسية لتحديد البحث هي
وظيفة الاتساق . تسمى هذه الوظيفة عقدة شجرة وتقوم بإرجاع مجموعة من العقد الفرعية التي تكون قيمها "متسقة" مع توقع البحث (كالمعتاد ، في النموذج "
تعبير عامل الحقل المفهرس "). بالنسبة لعقدة الأوراق ، تحدد وظيفة التناسق ما إذا كانت القيمة المفهرسة في هذه العقدة تتوافق مع توقع البحث.
يبدأ البحث بالعقدة الجذرية. تسمح وظيفة الاتساق بمعرفة العقد الفرعية التي من المنطقي زيارتها. تتكرر الخوارزمية لكل من العقد التي تم العثور عليها. البحث في العمق الأول.
على المستوى الفعلي ، يتم تجميع عقد الفهرس في صفحات لجعل العمل مع العقد فعالة من وجهة نظر عمليات الإدخال / الإخراج. لاحظ أن الصفحة الواحدة يمكن أن تحتوي على عقد داخلي أو ورقي ، ولكن ليس كلاهما.
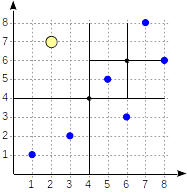
مثال: quadtree
يتم استخدام quadtree لفهرسة النقاط في الطائرة. تتمثل الفكرة في تقسيم المناطق بشكل متكرر إلى أربعة أجزاء (الأرباع) فيما يتعلق
بالنقطة المركزية . يمكن أن يختلف عمق الفروع في هذه الشجرة ويعتمد على كثافة النقاط في الأرباع المناسبة.
هذا ما يبدو في الأشكال ، على سبيل المثال من
قاعدة البيانات التجريبية المعززة بالمطارات من موقع
openflights.org . بالمناسبة ، أصدرنا مؤخرًا إصدارًا جديدًا من قاعدة البيانات ، استبدلنا فيه بين خطوط الطول والعرض بمجال واحد من النوع "point" بين البقية.
 أولاً ، قسمنا الطائرة إلى أربعة أرباع ...
أولاً ، قسمنا الطائرة إلى أربعة أرباع ...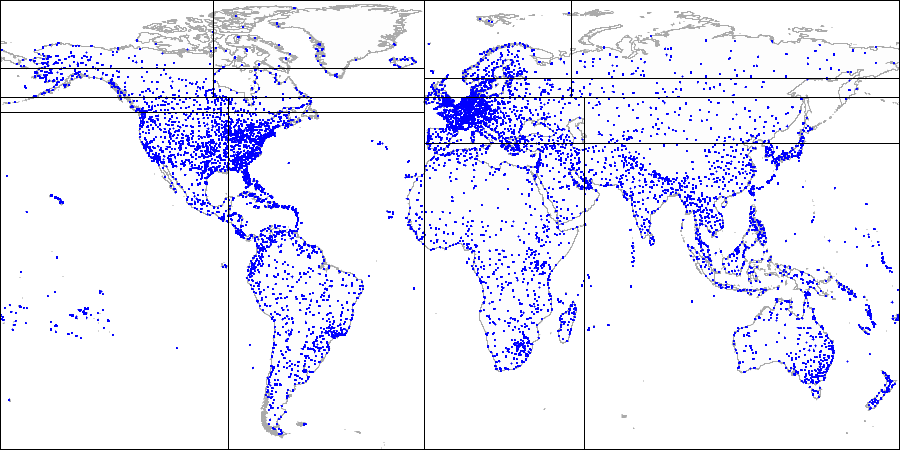 ثم قمنا بتقسيم كل من الأرباع ...
ثم قمنا بتقسيم كل من الأرباع ...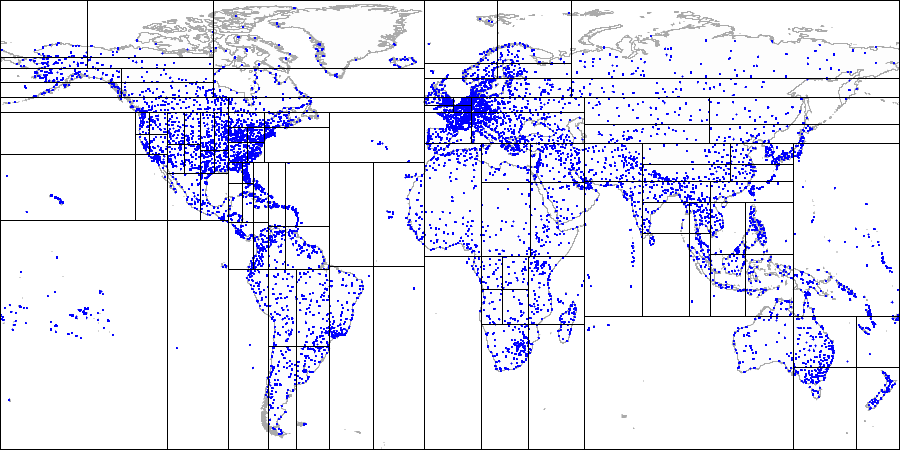 وهكذا حتى نحصل على التقسيم النهائي.
وهكذا حتى نحصل على التقسيم النهائي.دعنا نقدم مزيدًا من التفاصيل حول مثال بسيط
درسناه بالفعل في
المقالة المتعلقة بـ GiST . تعرف على شكل التقسيم في هذه الحالة:
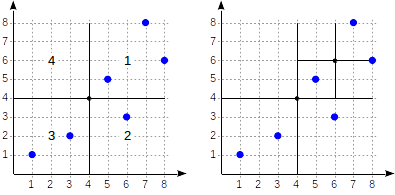
يتم ترقيم الأرباع كما هو موضح في الشكل الأول. من أجل الدقة ، لنضع العقد الفرعية من اليسار إلى اليمين بنفس التسلسل. يظهر هيكل الفهرس المحتمل في هذه الحالة في الشكل أدناه. تشير كل عقدة داخلية إلى أربعة عقد فرعية كحد أقصى. يمكن تسمية كل مرجع برقم رباعي ، كما في الشكل. ولكن لا يوجد أي تسمية في التطبيق لأنه أكثر ملاءمة لتخزين مجموعة ثابتة من أربعة مراجع يمكن أن يكون بعضها فارغًا.
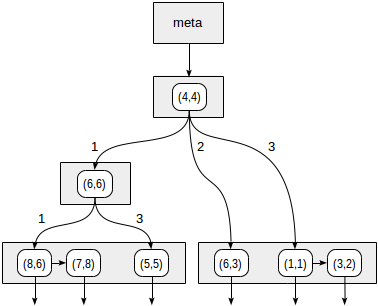
النقاط التي تقع على الحدود تتعلق بالرباط ذي العدد الأصغر.
postgres=# create table points(p point); postgres=# insert into points(p) values (point '(1,1)'), (point '(3,2)'), (point '(6,3)'), (point '(5,5)'), (point '(7,8)'), (point '(8,6)'); postgres=# create index points_quad_idx on points using spgist(p);
في هذه الحالة ، يتم استخدام فئة عامل التشغيل "quad_point_ops" افتراضيًا ، والتي تحتوي على العوامل التالية:
postgres=# select amop.amopopr::regoperator, amop.amopstrategy from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop where opc.opcname = 'quad_point_ops' and opf.oid = opc.opcfamily and am.oid = opf.opfmethod and amop.amopfamily = opc.opcfamily and am.amname = 'spgist' and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy -----------------+-------------- <<(point,point) | 1 strictly left >>(point,point) | 5 strictly right ~=(point,point) | 6 coincides <^(point,point) | 10 strictly below >^(point,point) | 11 strictly above <@(point,box) | 8 contained in rectangle (6 rows)
على سبيل المثال ، دعونا نلقي نظرة على كيفية
select * from points where p >^ point '(2,7)' الاستعلام
select * from points where p >^ point '(2,7)' (ابحث عن جميع النقاط الموجودة أعلى النقطة المحددة).
نبدأ بالعقدة الجذرية ونستخدم وظيفة التناسق لتحديد أي العقد الفرعية ستنزل. بالنسبة للمشغل
>^ ، تقارن هذه الوظيفة النقطة (2،7) بالنقطة المركزية للعقدة (4،4) وتحدد الأرباع التي قد تحتوي على النقاط المطلوبة ، في هذه الحالة ، الربعان الأول والرابع.
في العقدة المقابلة للربع الأول ، نحدد مرة أخرى العقد الفرعية باستخدام دالة التناسق. النقطة المركزية هي (6،6) ، ونحن بحاجة مرة أخرى للنظر من خلال الربعين الأول والرابع.
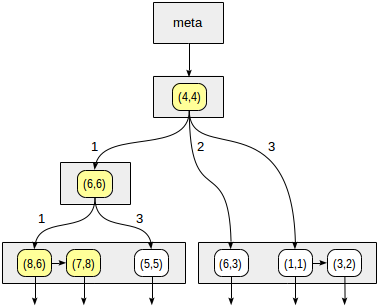
تتوافق قائمة العقد الورقية (8.6) و (7.8) مع الربع الأول ، منها النقطة (7.8) التي تفي بشرط الاستعلام. الإشارة إلى الربع الرابع فارغ.
في العقدة الداخلية (4.4) ، تكون الإشارة إلى الربع الرابع فارغة أيضًا ، مما يكمل عملية البحث.
postgres=# set enable_seqscan = off; postgres=# explain (costs off) select * from points where p >^ point '(2,7)';
QUERY PLAN ------------------------------------------------ Index Only Scan using points_quad_idx on points Index Cond: (p >^ '(2,7)'::point) (2 rows)
الداخلية
يمكننا استكشاف البنية الداخلية لفهارس SP-GiST باستخدام الامتداد "
gevel " ، والذي تم ذكره مسبقًا. الأخبار السيئة هي أنه بسبب وجود خطأ ، هذا الملحق يعمل بشكل غير صحيح مع الإصدارات الحديثة من PostgreSQL. الخبر السار هو أننا نخطط لزيادة "pageinspect" مع وظيفة "gevel" (
مناقشة ). وقد تم بالفعل إصلاح الخلل في "pageinspect".
مرة أخرى ، الأخبار السيئة هي أن التصحيح قد توقف دون أي تقدم.
على سبيل المثال ، دعنا نأخذ قاعدة البيانات التجريبية الموسعة ، التي كانت تستخدم لرسم الصور مع خريطة العالم.
demo=# create index airports_coordinates_quad_idx on airports_ml using spgist(coordinates);
أولاً ، يمكننا الحصول على بعض الإحصاءات للمؤشر:
demo=# select * from spgist_stats('airports_coordinates_quad_idx');
spgist_stats ---------------------------------- totalPages: 33 + deletedPages: 0 + innerPages: 3 + leafPages: 30 + emptyPages: 2 + usedSpace: 201.53 kbytes+ usedInnerSpace: 2.17 kbytes + usedLeafSpace: 199.36 kbytes+ freeSpace: 61.44 kbytes + fillRatio: 76.64% + leafTuples: 5993 + innerTuples: 37 + innerAllTheSame: 0 + leafPlaceholders: 725 + innerPlaceholders: 0 + leafRedirects: 0 + innerRedirects: 0 (1 row)
وثانيا ، يمكننا إخراج شجرة الفهرس نفسها:
demo=# select tid, n, level, tid_ptr, prefix, leaf_value from spgist_print('airports_coordinates_quad_idx') as t( tid tid, allthesame bool, n int, level int, tid_ptr tid, prefix point,
tid | n | level | tid_ptr | prefix | leaf_value ---------+---+-------+---------+------------------+------------------ (1,1) | 0 | 1 | (5,3) | (-10.220,53.588) | (1,1) | 1 | 1 | (5,2) | (-10.220,53.588) | (1,1) | 2 | 1 | (5,1) | (-10.220,53.588) | (1,1) | 3 | 1 | (5,14) | (-10.220,53.588) | (3,68) | | 3 | | | (86.107,55.270) (3,70) | | 3 | | | (129.771,62.093) (3,85) | | 4 | | | (57.684,-20.430) (3,122) | | 4 | | | (107.438,51.808) (3,154) | | 3 | | | (-51.678,64.191) (5,1) | 0 | 2 | (24,27) | (-88.680,48.638) | (5,1) | 1 | 2 | (5,7) | (-88.680,48.638) | ...
لكن ضع في اعتبارك أن "spgist_print" لا يقوم بإخراج جميع قيم الأوراق ، ولكن فقط القيم الأولى من القائمة ، وبالتالي يوضح بنية الفهرس بدلاً من محتوياته الكاملة.
مثال: أشجار الأبعاد ك
بالنسبة للنقاط نفسها في الطائرة ، يمكننا أيضًا اقتراح طريقة أخرى لتقسيم المساحة.
لنرسم خطًا أفقيًا من خلال النقطة الأولى التي يتم فهرستها. يقسم الطائرة إلى قسمين: العلوي والسفلي. النقطة الثانية المراد فهرستها تقع في أحد هذه الأجزاء. من خلال هذه النقطة ،
لنرسم خطًا رأسيًا يقسم هذا الجزء إلى قسمين: اليمين واليسار. نرسم مرة أخرى خطًا أفقيًا من خلال النقطة التالية وخطًا رأسيًا من خلال النقطة التالية وما إلى ذلك.
سيكون لكل العقد الداخلية للشجرة المبنية بهذه الطريقة عقدتان فرعيتان فقط. يمكن أن يؤدي كل من المراجعين إما إلى العقدة الداخلية التالية في التسلسل الهرمي أو إلى قائمة العقد الورقية.
يمكن تعميم هذه الطريقة بسهولة على المساحات k- الأبعاد ، وبالتالي ، تسمى الأشجار أيضًا k-dimensional (أشجار kD) في الأدب.
شرح الطريقة عن طريق المطارات:
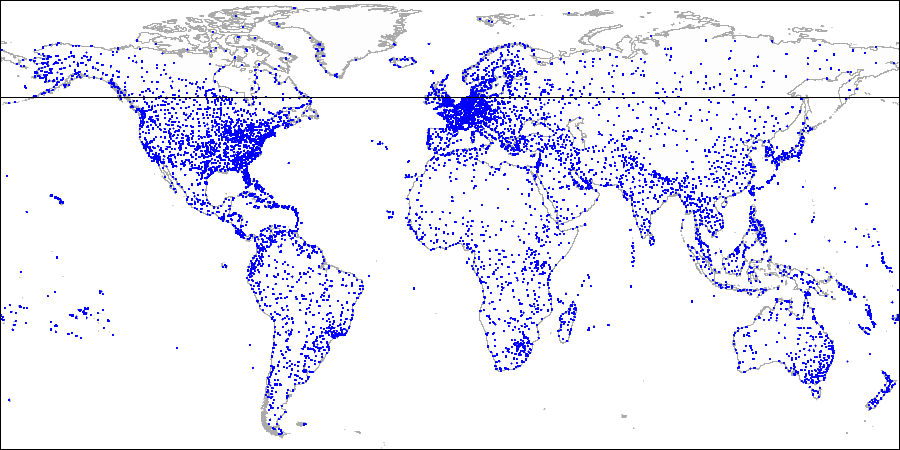 أولاً ، قمنا بتقسيم الطائرة إلى الأجزاء العلوية والسفلية ...
أولاً ، قمنا بتقسيم الطائرة إلى الأجزاء العلوية والسفلية ...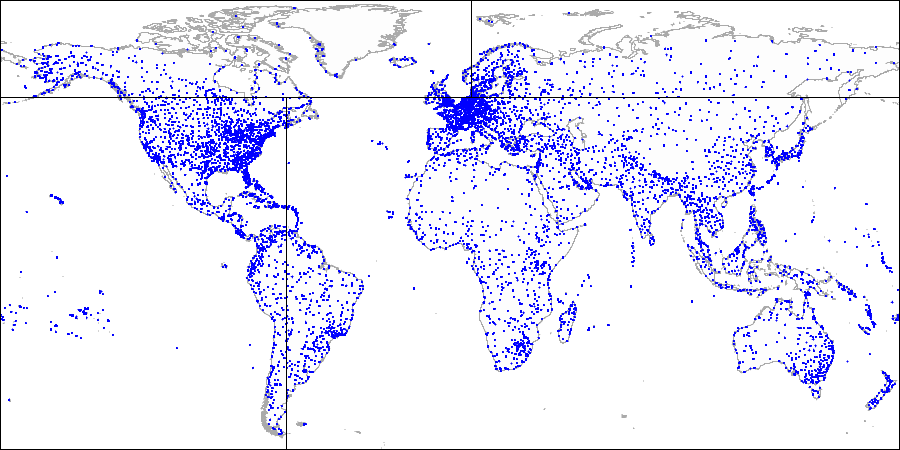 ثم نقسم كل جزء إلى الأجزاء اليمنى واليسرى ...
ثم نقسم كل جزء إلى الأجزاء اليمنى واليسرى ... وهكذا حتى نحصل على التقسيم النهائي.
وهكذا حتى نحصل على التقسيم النهائي.لاستخدام قسم مثل هذا ، نحتاج إلى تحديد فئة المشغل
"kd_point_ops" بشكل صريح عند إنشاء فهرس.
postgres=# create index points_kd_idx on points using spgist(p kd_point_ops);
تتضمن هذه الفئة نفس العوامل التي تشغلها الفئة "الافتراضية" "quad_point_ops".
الداخلية
عند النظر في بنية الشجرة ، نحتاج إلى مراعاة أن البادئة في هذه الحالة هي إحداثية واحدة فقط وليست نقطة:
demo=# select tid, n, level, tid_ptr, prefix, leaf_value from spgist_print('airports_coordinates_kd_idx') as t( tid tid, allthesame bool, n int, level int, tid_ptr tid, prefix float,
tid | n | level | tid_ptr | prefix | leaf_value ---------+---+-------+---------+------------+------------------ (1,1) | 0 | 1 | (5,1) | 53.740 | (1,1) | 1 | 1 | (5,4) | 53.740 | (3,113) | | 6 | | | (-7.277,62.064) (3,114) | | 6 | | | (-85.033,73.006) (5,1) | 0 | 2 | (5,12) | -65.449 | (5,1) | 1 | 2 | (5,2) | -65.449 | (5,2) | 0 | 3 | (5,6) | 35.624 | (5,2) | 1 | 3 | (5,3) | 35.624 | ...
مثال: شجرة جذرية
يمكننا أيضًا استخدام SP-GiST لتنفيذ شجرة جذرية للسلاسل. تتمثل فكرة شجرة الأساس في أن السلسلة المراد فهرستها لا يتم تخزينها بالكامل في عقدة ورقة ، ولكن يتم الحصول عليها عن طريق وصل القيم المخزنة في العقد أعلى هذه السلسلة حتى الجذر.
لنفترض ، نحن بحاجة إلى فهرسة عناوين URL للموقع: "postgrespro.ru" ، "postgrespro.com" ، "postgresql.org" ، و "planet.postgresql.org".
postgres=# create table sites(url text); postgres=# insert into sites values ('postgrespro.ru'),('postgrespro.com'),('postgresql.org'),('planet.postgresql.org'); postgres=# create index on sites using spgist(url);
ستبدو الشجرة كما يلي:
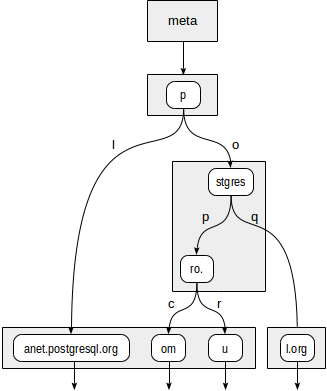
إن العقد الداخلية لمتجر الشجرة تكون بادئات مشتركة لكل العقد الفرعية. على سبيل المثال ، في العقد الفرعية لـ "stgres" ، تبدأ القيم بـ "p" + "o" + "stgres".
على عكس المربعات الرباعية ، يتم تمييز كل مؤشر إلى عقدة تابعة بحرف واحد (بشكل أكثر دقة ، مع وحدتي بايت ، لكن هذا ليس مهمًا جدًا).
تدعم فئة مشغل "Text_ops" عوامل التشغيل الشبيهة بـ B: "متساوية" و "أكبر" و "أقل":
postgres=# select amop.amopopr::regoperator, amop.amopstrategy from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop where opc.opcname = 'text_ops' and opf.oid = opc.opcfamily and am.oid = opf.opfmethod and amop.amopfamily = opc.opcfamily and am.amname = 'spgist' and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy -----------------+-------------- ~<~(text,text) | 1 ~<=~(text,text) | 2 =(text,text) | 3 ~>=~(text,text) | 4 ~>~(text,text) | 5 <(text,text) | 11 <=(text,text) | 12 >=(text,text) | 14 >(text,text) | 15 (9 rows)
تميز العوامل مع التلدة هو أنها تتعامل مع
البايتات بدلاً من
الحروف .
في بعض الأحيان ، قد يكون التمثيل في شكل شجرة جذرية أكثر إحكاما من B-tree لأن القيم ليست مخزنة بالكامل ، ولكن يتم إعادة بنائها كلما دعت الحاجة إلى ذلك أثناء تنازلها عبر الشجرة.
النظر في استعلام:
select * from sites where url like 'postgresp%ru' . يمكن تنفيذه باستخدام الفهرس:
postgres=# explain (costs off) select * from sites where url like 'postgresp%ru';
QUERY PLAN ------------------------------------------------------------------------------ Index Only Scan using sites_url_idx on sites Index Cond: ((url ~>=~ 'postgresp'::text) AND (url ~<~ 'postgresq'::text)) Filter: (url ~~ 'postgresp%ru'::text) (3 rows)
في الواقع ، يتم استخدام الفهرس للعثور على قيم أكبر أو مساوية لـ "postgresp" ، ولكن أقل من "postgresq" (Index Cond) ، ثم يتم اختيار القيم المطابقة من النتيجة (Filter).
أولاً ، يجب أن تحدد وظيفة التناسق العقد الفرعية للجذر "p" التي نحتاج إلى النزول إليها. يتوفر خياران: "p" + "l" (لا حاجة إلى الهبوط ، وهو أمر واضح حتى بدون الغوص أعمق) و "p" + "o" + "stgres" (تابع النزول).
بالنسبة لعقدة "stgres" ، يلزم استدعاء وظيفة التناسق مرة أخرى للتحقق من "postgres" + "p" + "ro." (تابع النزول) و "postgres" + "q" (لا داعي للتنازل).
ل "ريال عماني" العقدة وجميع العقد الورقية التابعة لها ، سوف تستجيب وظيفة التناسق "نعم" ، وبالتالي فإن طريقة الفهرس ستُرجع قيمتين: "postgrespro.com" و "postgrespro.ru". سيتم اختيار قيمة مطابقة واحدة منهم في مرحلة التصفية.
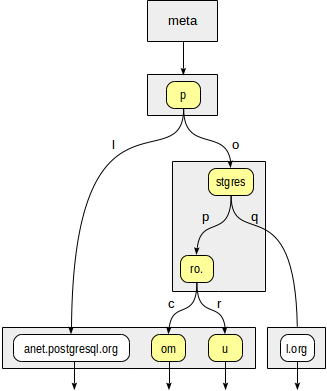
الداخلية
عند النظر في بنية الشجرة ، نحتاج إلى أخذ أنواع البيانات في الاعتبار:
postgres=# select * from spgist_print('sites_url_idx') as t( tid tid, allthesame bool, n int, level int, tid_ptr tid, prefix text,
خصائص
دعونا نلقي نظرة على خصائص طريقة الوصول إلى SP-GiST (
تم تقديم الاستعلامات مسبقًا):
amname | name | pg_indexam_has_property --------+---------------+------------------------- spgist | can_order | f spgist | can_unique | f spgist | can_multi_col | f spgist | can_exclude | t
لا يمكن استخدام فهارس SP-GiST للفرز ولدعم القيد الفريد. بالإضافة إلى ذلك ، لا يمكن إنشاء فهارس مثل هذه على عدة أعمدة (على عكس GiST). لكن يُسمح باستخدام هذه الفهارس لدعم قيود الاستبعاد.
تتوفر خصائص طبقة الفهرس التالية:
name | pg_index_has_property ---------------+----------------------- clusterable | f index_scan | t bitmap_scan | t backward_scan | f
الفرق من GiST هنا هو أن التجميع أمر مستحيل.
وأخيرًا فيما يلي خصائص طبقة العمود:
name | pg_index_column_has_property --------------------+------------------------------ asc | f desc | f nulls_first | f nulls_last | f orderable | f distance_orderable | f returnable | t search_array | f search_nulls | t
الفرز غير مدعوم ، وهو أمر يمكن التنبؤ به. لا تتوفر عوامل التشغيل عن بعد للبحث عن أقرب الجيران في SP-GiST حتى الآن. على الأرجح ، سيتم دعم هذه الميزة في المستقبل.
يتم دعمه في برنامج PostgreSQL 12 القادم ، وهو التصحيح الذي كتبه نيكيتا جلوخوف.
يمكن استخدام SP-GiST للمسح الضوئي فقط ، على الأقل لفئات المشغل التي تمت مناقشتها. كما رأينا ، في بعض الحالات ، يتم تخزين القيم المفهرسة بشكل صريح في العقد الورقية ، بينما في القيم الأخرى ، يتم إعادة بناء القيم جزئيًا خلال نزول الأشجار.
القيم الخالية
ليس لتعقيد الصورة ، نحن لم نذكر الصفات الفارغة حتى الآن. يتضح من خصائص الفهرس أنه يتم دعم NULLs. حقا:
postgres=# explain (costs off) select * from sites where url is null;
QUERY PLAN ---------------------------------------------- Index Only Scan using sites_url_idx on sites Index Cond: (url IS NULL) (2 rows)
ومع ذلك ، NULL شيء غريب لـ SP-GiST. يجب أن تكون جميع المشغلين من فئة مشغل "spgist" صارمة: يجب أن يرجع المشغل NULL كلما كانت أي من معلماته خالية. يضمن الأسلوب نفسه هذا: فقط لا يتم تمرير NULLs إلى عوامل التشغيل.
ولكن لاستخدام طريقة الوصول للفحص فقط ، يجب تخزين NULLs في الفهرس على أي حال. ويتم تخزينها ، ولكن في شجرة منفصلة مع جذرها الخاص.
أنواع البيانات الأخرى
بالإضافة إلى نقاط وأشجار الجذر للسلاسل ، يتم أيضًا تطبيق طرق أخرى تعتمد على SP-GiST.
- توفر فئة مشغل Box_ops رباعي المستطيلات.
يتم تمثيل كل مستطيل بنقطة في فضاء رباعي الأبعاد ، وبالتالي فإن عدد الأرباع يساوي 16. يمكن لمؤشر مثل هذا التغلب على GiST في الأداء عندما يكون هناك الكثير من التقاطعات للمستطيلات: في GiST ، من المستحيل رسم حدود وذلك لفصل الكائنات المتقاطعة عن بعضها البعض ، في حين لا توجد مثل هذه المشكلات بالنقاط (حتى ثلاثية الأبعاد).
- توفر فئة عامل التشغيل "Range_ops" رباعيًا للفواصل الزمنية.
يتم تمثيل الفاصل الزمني بنقطة ثنائية الأبعاد : الحد الأدنى يصبح الحد الأقصى ، والحدود العليا تصبح الإحداثي.
اقرأ على .