لا تستخدم معالجة اللغة الطبيعية الآن إلا في القطاعات المحافظة للغاية. في معظم الحلول التكنولوجية ، تم منذ فترة طويلة تقديم التعرف على اللغات "البشرية" ومعالجتها: ولهذا السبب أصبحت تقنية الرد الآلي المعتاد مع خيارات الاستجابة المشفرة تدريجيًا شيئًا من الماضي ، وبدأت برامج الدردشة في التواصل بشكل أكثر ملاءمة دون مشاركة مشغل مباشر ، وعوامل تصفية البريد تعمل مع اثارة ضجة ، إلخ. كيف يتم التعرف على الكلام المسجل ، أي النص؟ أو بالأحرى ، ماذا سيكون أساس تقنيات التعرف والتجهيز الحديثة؟ تستجيب ترجمتنا المُكيَّفة لهذا اليوم جيدًا - في ظل الخفض ، ستجد طريقًا طويلًا يسد الفجوات على أساسيات البرمجة اللغوية العصبية. هل لديك قراءة لطيفة!
ما هي معالجة اللغة الطبيعية؟
معالجة اللغة الطبيعية (المشار إليها فيما يلي - البرمجة اللغوية العصبية) - تعتبر معالجة اللغات الطبيعية جزءًا فرعيًا من علوم الكمبيوتر وتكرس الذكاء الاصطناعي كيفية تحليل أجهزة الكمبيوتر للغات الطبيعية (البشرية). NLP يسمح باستخدام خوارزميات التعلم الآلي للنص والكلام.
على سبيل المثال ، يمكننا استخدام البرمجة اللغوية العصبية (NLP) لإنشاء أنظمة مثل التعرف على الكلام ، وتعميم المستندات ، والترجمة الآلية ، والكشف عن البريد العشوائي ، والتعرف على الكيانات المسماة ، والإجابات على الأسئلة ، والإكمال التلقائي ، وإدخال النص التنبئي ، إلخ.
اليوم ، لدى الكثير منا هواتف ذكية للتعرف على الكلام - يستخدمون البرمجة اللغوية العصبية لفهم خطابنا. أيضًا ، يستخدم العديد من الأشخاص أجهزة الكمبيوتر المحمولة المزودة بنظام التعرف على الكلام في نظام التشغيل.
أمثلة
مايكروسوفت كورتانا
يحتوي Windows على مساعد Cortana الظاهري الذي يتعرف على الكلام. مع Cortana ، يمكنك إنشاء تذكيرات ، وفتح التطبيقات ، وإرسال الرسائل ، وممارسة الألعاب ، ومعرفة الطقس ، إلخ.
سيري
Siri هو مساعد لنظام تشغيل Apple: iOS و watchOS و macOS و HomePod و tvOS. تعمل العديد من الوظائف أيضًا من خلال التحكم الصوتي: الاتصال / الكتابة لشخص ما ، إرسال بريد إلكتروني ، تعيين مؤقت ، التقاط صورة ، إلخ.
جوجل
تعرف خدمة البريد الإلكتروني المعروفة كيفية اكتشاف الرسائل غير المرغوب فيها بحيث لا تدخل في صندوق الوارد الخاص بك.
Dialogflow
نظام أساسي من Google يسمح لك بإنشاء روبوتات البرمجة اللغوية العصبية. على سبيل المثال ، يمكنك إعداد روبوت طلب بيتزا
لا يحتاج إلى الرد الآلي على الطراز القديم لقبول طلبك .
مكتبة بيثون NLTK
NLTK (مجموعة أدوات اللغة الطبيعية) هي منصة رائدة لإنشاء برامج البرمجة اللغوية العصبية في بيثون. يحتوي على واجهات سهلة الاستخدام للعديد من
فيلق اللغات ، فضلاً عن مكتبات لمعالجة الكلمات من أجل التصنيف
والترميز والترميز والترميز والتصفية
والاستدلال المنطقي . حسنًا ، وهذا مشروع مجاني مفتوح المصدر يتم تطويره بمساعدة المجتمع.
سوف نستخدم هذه الأداة لإظهار أساسيات البرمجة اللغوية العصبية. بالنسبة لجميع الأمثلة اللاحقة ، افترض أن NLTK قد تم استيراده بالفعل ؛ يمكن القيام بذلك باستخدام
import nltkأساسيات البرمجة اللغوية العصبية للنص
في هذه المقالة سوف نغطي المواضيع:
- ترقيم بالعروض.
- تشفير بالكلمات.
- Lemmatization وختم النص.
- توقف الكلمات.
- التعبيرات العادية.
- حقيبة الكلمات .
- TF- جيش الدفاع الإسرائيلي .
1. تكويد بالعروض
رمزية (في بعض الأحيان تجزئة) من الجمل هي عملية تقسيم لغة مكتوبة إلى جمل مكونة. الفكرة تبدو بسيطة جدا. في اللغة الإنجليزية وبعض اللغات الأخرى ، يمكننا عزل جملة في كل مرة نجد فيها علامة ترقيم معينة - فترة.
لكن حتى في اللغة الإنجليزية هذه المهمة ليست تافهة ، حيث يتم استخدام النقطة أيضًا في الاختصارات. يمكن أن يساعد جدول الاختصار بشكل كبير أثناء معالجة النصوص لتجنب وضع حدود الجملة بطريقة غير صحيحة. في معظم الحالات ، تستخدم المكتبات لهذا الغرض ، لذلك لا داعي للقلق بشأن تفاصيل التنفيذ.
مثال:خذ نصًا قصيرًا عن لعبة الطاولة:
Backgammon is one of the oldest known board games. Its history can be traced back nearly 5,000 years to archeological discoveries in the Middle East. It is a two player game where each player has fifteen checkers which move between twenty-four points according to the roll of two dice.
لجعل الرمز المميز للعروض باستخدام NLTK ، يمكنك استخدام طريقة
nltk.sent_tokenize | text = "Backgammon is one of the oldest known board games. Its history can be traced back nearly 5,000 years to archeological discoveries in the Middle East. It is a two player game where each player has fifteen checkers which move between twenty-four points according to the roll of two dice." |
| sentences = nltk.sent_tokenize(text) |
| for sentence in sentences: |
| print(sentence) |
| print() |
عند الخروج ، نحصل على 3 جمل منفصلة:
Backgammon is one of the oldest known board games. Its history can be traced back nearly 5,000 years to archeological discoveries in the Middle East. It is a two player game where each player has fifteen checkers which move between twenty-four points according to the roll of two dice.
2. التكويد وفقا للكلمات
رمزية (في بعض الأحيان تجزئة) وفقا للكلمات هي عملية تقسيم الجمل إلى الكلمات المكونة. في اللغة الإنجليزية والعديد من اللغات الأخرى التي تستخدم إصدارًا أو آخر من الحروف الأبجدية اللاتينية ، تُعد المساحة فاصلًا جيدًا للكلمات.
ومع ذلك ، قد تنشأ مشاكل إذا استخدمنا مسافة فقط - باللغة الإنجليزية ، تتم كتابة الأسماء المركبة بطريقة مختلفة وفي بعض الأحيان تكون مفصولة بمسافات. وهنا المكتبات تساعدنا مرة أخرى.
مثال:لنأخذ الجمل من المثال السابق
nltk.word_tokenize طريقة
nltk.word_tokenize عليها
| for sentence in sentences: |
| words = nltk.word_tokenize(sentence) |
| print(words) |
| print() |
الاستنتاج:
['Backgammon', 'is', 'one', 'of', 'the', 'oldest', 'known', 'board', 'games', '.'] ['Its', 'history', 'can', 'be', 'traced', 'back', 'nearly', '5,000', 'years', 'to', 'archeological', 'discoveries', 'in', 'the', 'Middle', 'East', '.'] ['It', 'is', 'a', 'two', 'player', 'game', 'where', 'each', 'player', 'has', 'fifteen', 'checkers', 'which', 'move', 'between', 'twenty-four', 'points', 'according', 'to', 'the', 'roll', 'of', 'two', 'dice', '.']
3. الليمنة وختم النص
عادة ما تحتوي النصوص على أشكال نحوية مختلفة لنفس الكلمة ، وقد تحدث أيضًا كلمات ذات جذر واحد. تهدف Lemmatization و stemming إلى إحضار جميع أشكال الكلمات التي تحدث إلى شكل مفرد مفرد عادي.
الأمثلة على ذلك:إحضار أشكال كلمة مختلفة إلى واحد:
dog, dogs, dog's, dogs' => dog
نفس الشيء ، لكن بالإشارة إلى الجملة بأكملها:
the boy's dogs are different sizes => the boy dog be differ size
الليمنة والجذع هي حالات خاصة للتطبيع وتختلف.
إن عملية الاستنشاق هي عملية ارشادية فجة تقطع "الزائدة" عن جذر الكلمات ، وغالبًا ما يؤدي ذلك إلى فقدان لواحق بناء الكلمات.
Lemmatization هي عملية أكثر دقة تستخدم المفردات والتحليل الصرفي لإحضار الكلمة في نهاية المطاف إلى شكلها القانوني - lemma.
الفرق هو أن stemmer (تطبيق محدد لخوارزمية stemming - تعليق المترجم) يعمل دون معرفة السياق ، وبالتالي ، لا يفهم الفرق بين الكلمات التي لها معان مختلفة اعتمادًا على جزء الكلام. ومع ذلك ، فإن Stemmers لها مزاياها الخاصة: فهي أسهل في التنفيذ وتعمل بشكل أسرع. بالإضافة إلى ذلك ، قد لا تكون "الدقة" الأقل مهمة في بعض الحالات.
الأمثلة على ذلك:- كلمة طيبة هي ليما للكلمة أفضل. لن يرى Stemmer هذا الاتصال ، لأنك هنا تحتاج إلى الرجوع إلى القاموس.
- كلمة اللعب هي الشكل الأساسي للعب الكلمة. هنا سوف تتصدى كل من الجذعية والميمات.
- يمكن أن يكون اجتماع الكلمات إما شكل عادي للاسم أو شكل من أشكال الفعل للقاء ، وفقًا للسياق. على عكس الجذعية ، فإن lemmatization سيحاول اختيار lemma المناسب بناءً على السياق.
الآن بعد أن عرفنا الفرق ، دعونا نلقي نظرة على مثال:
| from nltk.stem import PorterStemmer, WordNetLemmatizer |
| from nltk.corpus import wordnet |
| |
| def compare_stemmer_and_lemmatizer(stemmer, lemmatizer, word, pos): |
| """ |
| Print the results of stemmind and lemmitization using the passed stemmer, lemmatizer, word and pos (part of speech) |
| """ |
| print("Stemmer:", stemmer.stem(word)) |
| print("Lemmatizer:", lemmatizer.lemmatize(word, pos)) |
| print() |
| |
| lemmatizer = WordNetLemmatizer() |
| stemmer = PorterStemmer() |
| compare_stemmer_and_lemmatizer(stemmer, lemmatizer, word = "seen", pos = wordnet.VERB) |
| compare_stemmer_and_lemmatizer(stemmer, lemmatizer, word = "drove", pos = wordnet.VERB) |
الاستنتاج:
Stemmer: seen Lemmatizer: see Stemmer: drove Lemmatizer: drive
4. توقف الكلمات
كلمات التوقف هي الكلمات التي يتم طرحها خارج النص قبل / بعد معالجة النص. عندما نطبق التعلم الآلي على النصوص ، يمكن لهذه الكلمات أن تضيف الكثير من الضوضاء ، لذلك تحتاج إلى التخلص من الكلمات غير ذات الصلة.
عادةً ما يتم فهم الكلمات المتوقفة عن طريق المقالات والتدخلات والنقابات وما إلى ذلك ، والتي لا تحمل عبءًا دلاليًا. يجب أن يكون مفهوما أنه لا توجد قائمة عالمية بكلمات التوقف ، كل هذا يتوقف على الحالة المعينة.
NLTK لديه قائمة محددة مسبقا من الكلمات توقف. قبل الاستخدام لأول مرة ، ستحتاج إلى تنزيله:
nltk.download(“stopwords”) . بعد التنزيل ، يمكنك استيراد حزمة
stopwords وإلقاء نظرة على الكلمات نفسها:
| from nltk.corpus import stopwords |
| print(stopwords.words("english")) |
الاستنتاج:
['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're", "you've", "you'll", "you'd", 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', "she's", 'her', 'hers', 'herself', 'it', "it's", 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this', 'that', "that'll", 'these', 'those', 'am', 'is', 'are', 'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because', 'as', 'until', 'while', 'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into', 'through', 'during', 'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off', 'over', 'under', 'again', 'further', 'then', 'once', 'here', 'there', 'when', 'where', 'why', 'how', 'all', 'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no', 'nor', 'not', 'only', 'own', 'same', 'so', 'than', 'too', 'very', 's', 't', 'can', 'will', 'just', 'don', "don't", 'should', "should've", 'now', 'd', 'll', 'm', 'o', 're', 've', 'y', 'ain', 'aren', "aren't", 'couldn', "couldn't", 'didn', "didn't", 'doesn', "doesn't", 'hadn', "hadn't", 'hasn', "hasn't", 'haven', "haven't", 'isn', "isn't", 'ma', 'mightn', "mightn't", 'mustn', "mustn't", 'needn', "needn't", 'shan', "shan't", 'shouldn', "shouldn't", 'wasn', "wasn't", 'weren', "weren't", 'won', "won't", 'wouldn', "wouldn't"]
فكر في كيفية إزالة كلمات التوقف من جملة:
| stop_words = set(stopwords.words("english")) |
| sentence = "Backgammon is one of the oldest known board games." |
| |
| words = nltk.word_tokenize(sentence) |
| without_stop_words = [word for word in words if not word in stop_words] |
| print(without_stop_words) |
الاستنتاج:
['Backgammon', 'one', 'oldest', 'known', 'board', 'games', '.']
إذا لم تكن معتادًا على فهم القائمة ، يمكنك معرفة المزيد
هنا . إليك طريقة أخرى لتحقيق نفس النتيجة:
| stop_words = set(stopwords.words("english")) |
| sentence = "Backgammon is one of the oldest known board games." |
| |
| words = nltk.word_tokenize(sentence) |
| without_stop_words = [] |
| for word in words: |
| if word not in stop_words: |
| without_stop_words.append(word) |
| |
| print(without_stop_words) |
ومع ذلك ، تذكر أن فهم القائمة أسرع لأنه يتم تحسينها - يكشف المترجم عن وجود نمط تنبؤي أثناء الحلقة.
قد تسأل لماذا قمنا بتحويل القائمة إلى
العديد . المجموعة هي نوع بيانات مجردة يمكنه تخزين قيم فريدة بترتيب غير محدد. البحث بالمجموعة أسرع بكثير من البحث في قائمة. بالنسبة لعدد قليل من الكلمات ، هذا لا يهم ، ولكن إذا كنا نتحدث عن عدد كبير من الكلمات ، فمن المستحسن بشدة استخدام مجموعات. إذا كنت تريد معرفة المزيد حول الوقت الذي تستغرقه في إجراء عمليات متنوعة ،
فراجع ورقة الغش الرائعة هذه .
5. التعبيرات العادية.
التعبير العادي (regex ، regexp ، regex) هو سلسلة من الأحرف التي تحدد نمط البحث. على سبيل المثال:
- . - أي حرف باستثناء تغذية الخط ؛
- \ كلمة واحدة ؛
- \ d - رقم واحد ؛
- - مساحة واحدة ؛
- \ W هو واحد غير كلمة ؛
- \ د - رقم واحد غير أرقام ؛
- \ S - واحد غير الفضاء ؛
- [abc] - يجد أيًا من الأحرف المحددة يطابق أيًا من a أو b أو c ؛
- [^ abc] - يعثر على أي حرف باستثناء الحروف المحددة ؛
- [ag] - يجد شخصية في النطاق من a إلى g.
مقتطف من
وثائق بيثون :
تستخدم التعبيرات العادية خط مائل عكسي (\) للإشارة إلى نماذج خاصة أو للسماح باستخدام أحرف خاصة. هذا يتناقض مع استخدام الخط المائل العكسي في Python: على سبيل المثال ، للإشارة حرفياً إلى الخط المائل العكسي ، يجب عليك كتابة '\\\\' كنموذج بحث ، لأن التعبير العادي يجب أن يبدو مثل \\ ، حيث يجب الهروب من كل شرطة مائلة عكسي.
الحل هو استخدام تدوين السلسلة الخام لأنماط البحث ؛ لن يتم معالجة خطوط مائلة عكسية بشكل خاص إذا تم استخدامها مع البادئة 'r' . وبالتالي ، r”\n” عبارة عن سلسلة مكونة من حرفين ('\' 'n') ، و “\n” عبارة عن سلسلة ذات حرف واحد (موجز السطر).
يمكننا استخدام النظامي لمزيد من تصفية نصنا. على سبيل المثال ، يمكنك إزالة جميع الأحرف التي ليست كلمات. في كثير من الحالات ، ليس هناك حاجة إلى علامات الترقيم ويسهل إزالتها بمساعدة النظامي.
وحدة
إعادة في بيثون تمثل عمليات التعبير العادية. يمكننا استخدام وظيفة
re.sub لاستبدال كل ما يناسب نمط البحث بالسلسلة المحددة. لذلك يمكنك استبدال كل الكلمات غير الكلمات بمسافات:
| import re |
| sentence = "The development of snowboarding was inspired by skateboarding, sledding, surfing and skiing." |
| pattern = r"[^\w]" |
| print(re.sub(pattern, " ", sentence)) |
الاستنتاج:
'The development of snowboarding was inspired by skateboarding sledding surfing and skiing '
Regulars هي أداة قوية يمكن استخدامها لإنشاء أنماط أكثر تعقيدًا. إذا كنت تريد معرفة المزيد حول التعبيرات العادية ،
فبإمكاني أن أوصي بهذين التطبيقين على الويب:
regex ،
regex101 .
6. حقيبة الكلمات
لا يمكن لخوارزميات التعلم الآلي التعامل مباشرة مع النص الخام ، لذلك تحتاج إلى تحويل النص إلى مجموعات من الأرقام (المتجهات). وهذا ما يسمى
استخراج الميزة .
تعد حقيبة الكلمات إحدى تقنيات استخراج الميزات الشائعة والبسيطة المستخدمة عند التعامل مع النصوص. وهو يصف تكرارات كل كلمة في النص.
لاستخدام النموذج ، نحتاج إلى:
- تحديد قاموس للكلمات المعروفة (الرموز).
- اختيار درجة وجود الكلمات الشهيرة.
يتم تجاهل أي معلومات حول ترتيب الكلمات أو هيكلها. هذا هو السبب في أنه يسمى حقيبة الكلمات. يحاول هذا النموذج فهم ما إذا كانت هناك كلمة مألوفة تظهر في المستند ، ولكن لا يعرف مكان حدوثها بالضبط.
الحدس يوحي بأن
الوثائق المماثلة لها
محتوى مماثل . وأيضًا ، بفضل المحتوى ، يمكننا أن نتعلم شيئًا عن معنى المستند.
مثال:النظر في الخطوات اللازمة لإنشاء هذا النموذج. نستخدم 4 جمل فقط لفهم كيفية عمل النموذج. في الحياة الحقيقية ، سوف تواجه المزيد من البيانات.
1. تحميل البيانات
تخيل أن هذه هي بياناتنا ونريد تحميلها كصفيف:
I like this movie, it's funny. I hate this movie. This was awesome! I like it. Nice one. I love it.
للقيام بذلك ، ما عليك سوى قراءة الملف والقسمة على سطر:
| with open("simple movie reviews.txt", "r") as file: |
| documents = file.read().splitlines() |
| |
| print(documents) |
الاستنتاج:
["I like this movie, it's funny.", 'I hate this movie.', 'This was awesome! I like it.', 'Nice one. I love it.']
2. تحديد القاموس
سنقوم بجمع كل الكلمات الفريدة من 4 جمل محملة ، وتجاهل الحالة وعلامات الترقيم والرموز ذات الطابع الفردي. سيكون هذا قاموسنا (الكلمات الشهيرة).
لإنشاء قاموس ، يمكنك استخدام فئة
CountVectorizer من مكتبة sklearn. انتقل إلى الخطوة التالية.
3. إنشاء ناقلات المستند
بعد ذلك ، نحتاج إلى تقييم الكلمات في المستند. في هذه الخطوة ، هدفنا هو تحويل النص الخام إلى مجموعة من الأرقام. بعد ذلك ، نستخدم هذه المجموعات كمدخلات لنموذج التعلم الآلي. إن أبسط طريقة للتسجيل هي ملاحظة وجود الكلمات ، أي 1 في حالة وجود كلمة و 0 إذا كانت غائبة.
الآن يمكننا إنشاء مجموعة من الكلمات باستخدام فئة CountVectorizer المذكورة أعلاه.
| # Import the libraries we need |
| from sklearn.feature_extraction.text import CountVectorizer |
| import pandas as pd |
| |
| # Step 2. Design the Vocabulary |
| # The default token pattern removes tokens of a single character. That's why we don't have the "I" and "s" tokens in the output |
| count_vectorizer = CountVectorizer() |
| |
| # Step 3. Create the Bag-of-Words Model |
| bag_of_words = count_vectorizer.fit_transform(documents) |
| |
| # Show the Bag-of-Words Model as a pandas DataFrame |
| feature_names = count_vectorizer.get_feature_names() |
| pd.DataFrame(bag_of_words.toarray(), columns = feature_names) |
الاستنتاج:
هذه هي اقتراحاتنا. الآن نرى كيف يعمل نموذج "حقيبة الكلمات".
بضع كلمات عن حقيبة الكلمات
تعقيد هذا النموذج هو كيفية تحديد القاموس وكيفية حساب حدوث الكلمات.
عندما يزيد حجم القاموس ، يزداد متجه الوثيقة أيضًا. في المثال أعلاه ، يساوي طول المتجه عدد الكلمات المعروفة.
في بعض الحالات ، يمكن أن يكون لدينا كمية كبيرة بشكل لا يصدق من البيانات ومن ثم يمكن أن يتكون المتجه من آلاف أو ملايين العناصر. علاوة على ذلك ، يمكن أن تحتوي كل وثيقة على جزء صغير فقط من الكلمات من القاموس.
نتيجة لذلك ، سيكون هناك العديد من الأصفار في تمثيل المتجه. تسمى ناقلات العديد من الأصفار ناقلات متفرق ، فإنها تتطلب المزيد من الذاكرة والموارد الحسابية.
ومع ذلك ، يمكننا تقليل عدد الكلمات المعروفة عندما نستخدم هذا النموذج لتقليل الطلبات على موارد الحوسبة. للقيام بذلك ، يمكنك استخدام نفس الأساليب التي درسناها بالفعل قبل إنشاء مجموعة من الكلمات:
- تجاهل حالة الكلمات ؛
- تجاهل علامات الترقيم ؛
- إخراج كلمات التوقف ؛
- اختزال الكلمات إلى أشكالها الأساسية (الاستئصال والتنبؤ) ؛
- تصحيح الكلمات التي بها أخطاء إملائية.
طريقة أخرى أكثر تعقيدًا لإنشاء قاموس هي استخدام الكلمات المجمعة. سيؤدي ذلك إلى تغيير حجم القاموس وإعطاء حقيبة الكلمات مزيدًا من التفاصيل حول المستند. ويسمى هذا النهج "
N-gram ."
N-gram عبارة عن تسلسل لأي كيانات (الكلمات والحروف والأرقام والأرقام وما إلى ذلك). في سياق الهيئات اللغوية ، عادة ما يتم فهم N-gram كسلسلة من الكلمات. unigram هي كلمة واحدة ، bigram هي سلسلة من كلمتين ، trigram هي ثلاث كلمات ، وهلم جرا. يشير الرقم N إلى عدد الكلمات المجمعة التي تم تضمينها في N-gram. لا تقع كل جرام N المحتملة في النموذج ، ولكن فقط تلك التي تظهر في العلبة.
مثال:النظر في الجملة التالية:
The office building is open today
وهنا له bigrams:
- المكتب
- مبنى المكاتب
- البناء هو
- مفتوح
- افتح اليوم
كما ترون ، فإن حقيبة bigrams هي طريقة أكثر فعالية من حقيبة الكلمات.
تقييم (تسجيل) الكلماتعندما يتم إنشاء قاموس ، يجب تقييم وجود الكلمات. لقد فكرنا بالفعل في نهج بسيط ثنائي (1 - هناك كلمة ، 0 - لا توجد كلمة).
هناك طرق أخرى:
- العدد. يتم حساب عدد المرات التي تظهر فيها كل كلمة في المستند.
- تردد. يتم حساب عدد مرات حدوث كل كلمة في النص (بالنسبة إلى إجمالي عدد الكلمات).
7. TF-جيش الدفاع الإسرائيلي
تسجيل الترددات لديه مشكلة: الكلمات ذات أعلى تردد لها ، على التوالي ، أعلى تصنيف. في هذه الكلمات ، قد لا يكون هناك
ربح إعلامي كبير للنموذج كما هو الحال في كلمات أقل تكرارًا. تتمثل إحدى طرق تصحيح الموقف في خفض درجة الكلمات ، والتي غالبًا ما توجد
في جميع المستندات المشابهة . وهذا ما يسمى
TF-IDF .
TF-IDF (تردد قصير المدى - تردد المستند العكسي) هو مقياس إحصائي لتقييم أهمية كلمة في مستند يمثل جزءًا من مجموعة أو مجموعة.
تزداد درجة تسجيل TF-IDF بما يتناسب مع عدد مرات تكرار كلمة ما في مستند ما ، لكن يتم تعويض ذلك بعدد المستندات التي تحتوي على هذه الكلمة.
صيغة تسجيل للكلمة X في المستند Y:
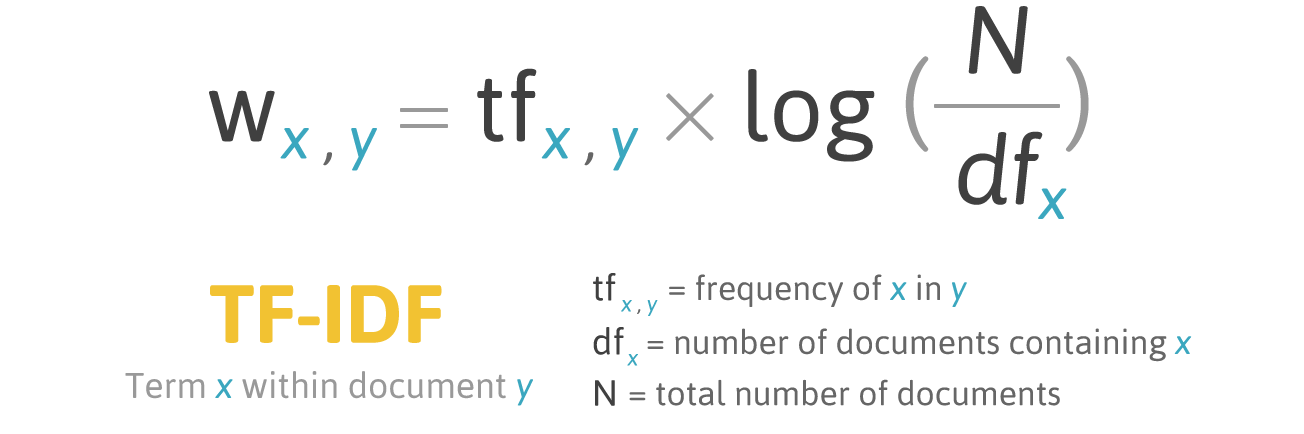 صيغة TF-IDF. المصدر: filotechnologia.blogspot.com/2014/01/a-simple-java-class-for-tfidf-scoring.html
صيغة TF-IDF. المصدر: filotechnologia.blogspot.com/2014/01/a-simple-java-class-for-tfidf-scoring.htmlTF (تردد المصطلح) هي نسبة عدد تكرارات الكلمة إلى إجمالي عدد الكلمات في المستند.
IDF (تردد المستند العكسي) هو معكوس التردد الذي تحدث به كلمة في مستندات التجميع.
نتيجة لذلك ، يمكن حساب TF-IDF لكلمة الكلمة على النحو التالي:
مثال:يمكنك استخدام فئة
TfidfVectorizer من مكتبة sklearn لحساب TF-IDF. لنقم بذلك بنفس الرسائل التي استخدمناها في حقيبة الكلمات.
I like this movie, it's funny. I hate this movie. This was awesome! I like it. Nice one. I love it.
كود:
| from sklearn.feature_extraction.text import TfidfVectorizer |
| import pandas as pd |
| |
| tfidf_vectorizer = TfidfVectorizer() |
| values = tfidf_vectorizer.fit_transform(documents) |
| |
| # Show the Model as a pandas DataFrame |
| feature_names = tfidf_vectorizer.get_feature_names() |
| pd.DataFrame(values.toarray(), columns = feature_names) |
الاستنتاج:
استنتاج
غطت هذه المقالة أساسيات البرمجة اللغوية العصبية للنص ، وهي:
- NLP يسمح باستخدام خوارزميات التعلم الآلي للنص والكلام.
- NLTK (مجموعة أدوات اللغة الطبيعية) - منصة رائدة لإنشاء برامج البرمجة اللغوية العصبية في بيثون ؛
- رمزية الاقتراح هي عملية تقسيم لغة مكتوبة إلى جمل مكونة ؛
- ترميز الكلمات هو عملية تقسيم الجمل إلى كلمات مكونة ؛
- تهدف Lemmatization و stemming إلى إحضار جميع أشكال الكلمات المصادفة إلى شكل مفرد مفرد عادي ؛
- كلمات التوقف هي الكلمات التي يتم طرحها خارج النص قبل / بعد معالجة النص ؛
- regex (regex ، regexp ، regex) عبارة عن سلسلة من الأحرف التي تحدد نمط البحث ؛
- كيس من الكلمات هو تقنية استخراج ميزة شائعة وبسيطة تستخدم عند العمل مع النص. وهو يصف تكرارات كل كلمة في النص.
! ممتاز الآن بعد أن تعرفت أساسيات استخراج الميزات ، يمكنك استخدام الميزات كمدخلات في خوارزميات التعلم الآلي.
إذا كنت تريد رؤية جميع المفاهيم الموضحة في مثال واحد كبير ،
فأنت هنا .