
في مشاريعنا نستخدم بنية microservice. في حالة ظهور اختناقات في الأداء ، يتم إنفاق الكثير من الوقت على مراقبة السجلات وتحليلها. عند تسجيل توقيت العمليات الفردية في ملف سجل ، يكون من الصعب عادة فهم ما أدى إلى استدعاء هذه العمليات ، لتتبع تسلسل الإجراءات أو إزاحة الوقت لعملية واحدة بالنسبة إلى أخرى في خدمات مختلفة.
لتقليل العمل اليدوي ، قررنا استخدام إحدى أدوات التتبع. حول كيف ولماذا من الممكن استخدام التتبع وكيف فعلنا ذلك ، وسوف نناقش هذه المقالة.
ما هي المشاكل التي يمكن حلها مع التتبع
- ابحث عن اختناقات الأداء داخل خدمة واحدة وفي شجرة التنفيذ بالكامل بين جميع الخدمات المشاركة. على سبيل المثال:
- العديد من المكالمات القصيرة المتتالية بين الخدمات ، على سبيل المثال ، إلى الترميز الجغرافي أو إلى قاعدة بيانات.
- انتظار طويل لإدخال الإدخال ، على سبيل المثال ، نقل البيانات عبر شبكة أو القراءة من القرص.
- تحليل البيانات الطويلة.
- عمليات طويلة تتطلب وحدة المعالجة المركزية.
- أجزاء من التعليمات البرمجية غير مطلوبة للحصول على النتيجة النهائية ويمكن حذفها أو تأخير تشغيلها.
- فهم بوضوح في تسلسل ما يسمى وما يحدث عندما يتم تنفيذ العملية.
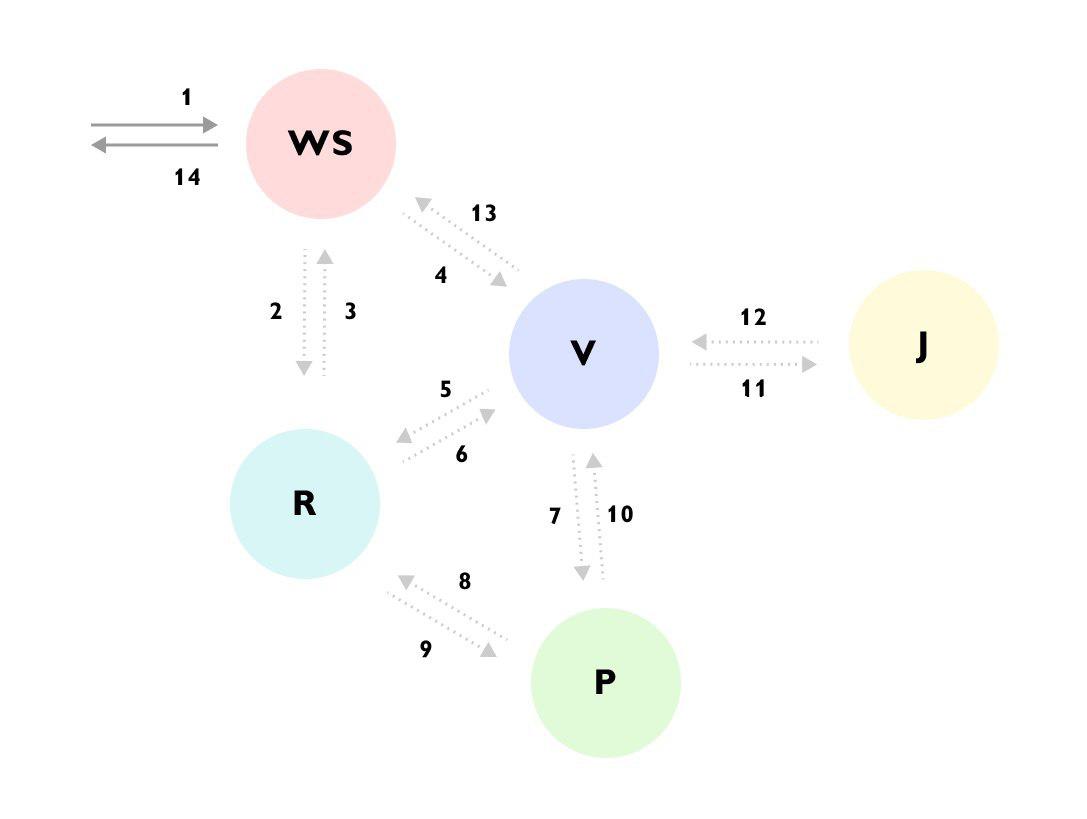
يمكن ملاحظة أنه ، على سبيل المثال ، جاء الطلب إلى خدمة WS -> استكملت خدمة WS البيانات من خلال خدمة R -> ثم أرسلت الطلب إلى خدمة V -> قامت خدمة V بتحميل الكثير من البيانات من خدمة R -> ذهبت إلى خدمة P -> تم إيقاف تشغيل خدمة P مرة أخرى إلى الخدمة R -> تجاهلت الخدمة V النتيجة وذهبت إلى الخدمة J -> وعندها فقط أعادت الإجابة إلى خدمة WS ، مع الاستمرار في حساب شيء آخر في الخلفية.
بدون مثل هذا التتبع أو الوثائق المفصلة للعملية بأكملها ، من الصعب للغاية فهم ما يحدث في المرة الأولى التي تنظر فيها إلى الكود ، وتنتشر الشفرة عبر خدمات مختلفة وتخفي وراءها مجموعة من الصناديق والواجهات.
- مجموعة من المعلومات حول شجرة التنفيذ لتحليلها اللاحق. في كل مرحلة من مراحل التنفيذ ، يمكنك إضافة معلومات إلى التتبع المتاح في هذه المرحلة ثم معرفة المدخلات التي أدت إلى سيناريو مشابه. على سبيل المثال:
- معرف المستخدم
- حقوق
- نوع الطريقة المحددة
- خطأ في السجل أو التنفيذ
- قم بتحويل التتبعات إلى مجموعة فرعية من المقاييس والمزيد من التحليل كمقاييس.
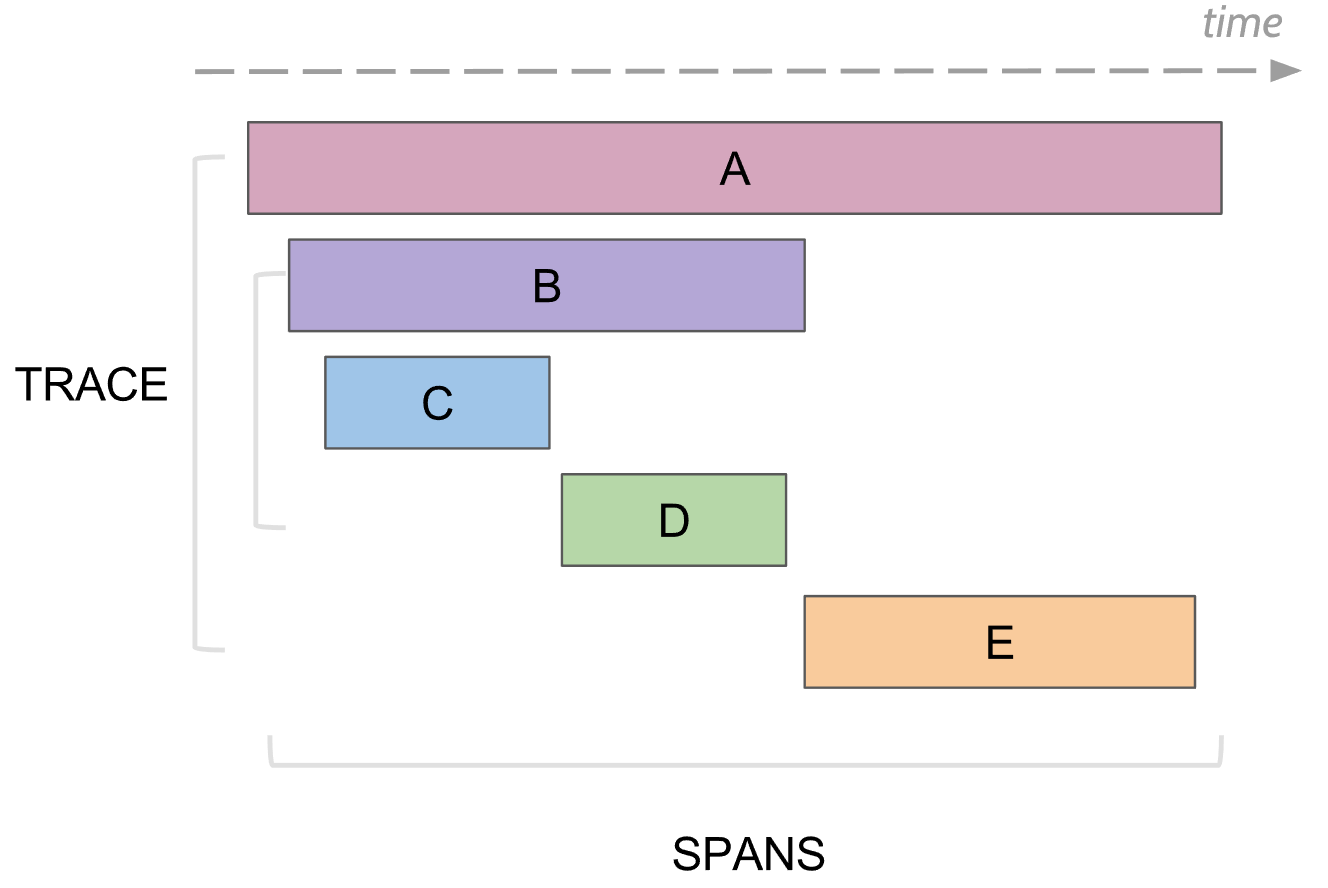
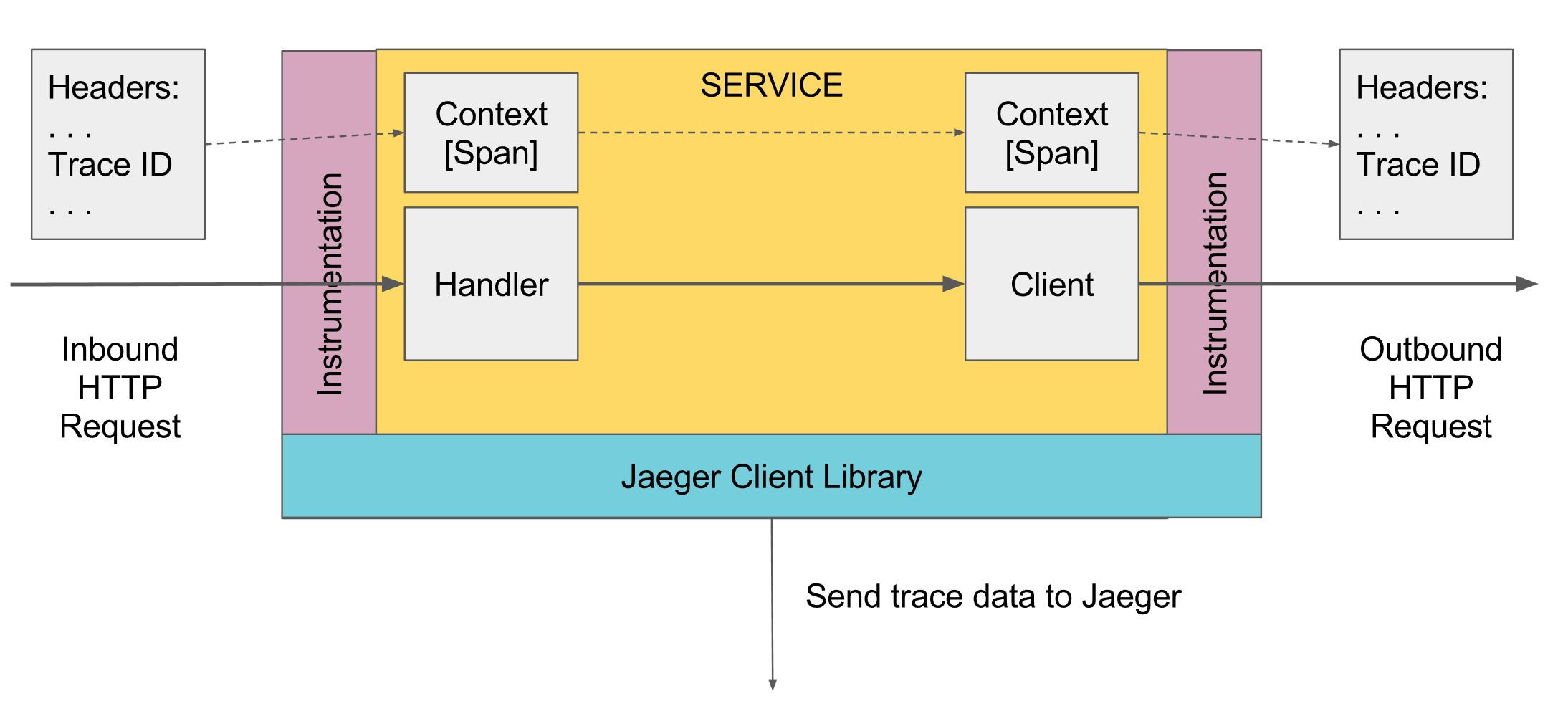
ما يمكن تتبع التسجيل. شبر
في التتبع ، يوجد مفهوم span ، وهو تناظرية لسجل واحد إلى وحدة التحكم. فترة لديه:
- الاسم ، وعادة ما يكون اسم الطريقة التي تم تنفيذها
- اسم الخدمة التي تم إنشاؤها في النطاق
- معرف فريد خاص بك
- بعض المعلومات الوصفية في شكل مفتاح / قيمة ، والتي تم التعهد بها. على سبيل المثال ، انتهت معلمات الطريقة أو الطريقة بخطأ أم لا
- بداية ونهاية أوقات هذا المدى
- معرف فترة الأصل
يتم إرسال كل فترة إلى أداة التجميع span لحفظها في قاعدة البيانات للعرض لاحقًا بمجرد اكتمال تنفيذها. في المستقبل ، يمكنك بناء شجرة من جميع المسافات من خلال الاتصال بمعرف الوالد. في التحليل ، يمكنك أن تجد ، على سبيل المثال ، جميع المسافات في بعض الخدمات التي استغرقت أكثر من بعض الوقت. علاوة على ذلك ، انتقل إلى فترة محددة ، راجع الشجرة بأكملها أعلى وتحت هذه المدة.
Opentracing ، Jagger وكيف قمنا بتنفيذها لمشاريعنا
هناك معيار
Opentracing عام يصف كيف وماذا ينبغي تجميعها دون ربطها بتطبيق معين بأي لغة. على سبيل المثال ، في Java ، يتم كل العمل مع التتبعات من خلال واجهة برمجة تطبيقات Opentracing العامة ، وتحته ، على سبيل المثال ، Jaeger أو تطبيق افتراضي فارغ لا يمكن إخفاءه.
نستخدم
جايجر كتطبيق Opentracing. يتكون من عدة مكونات:
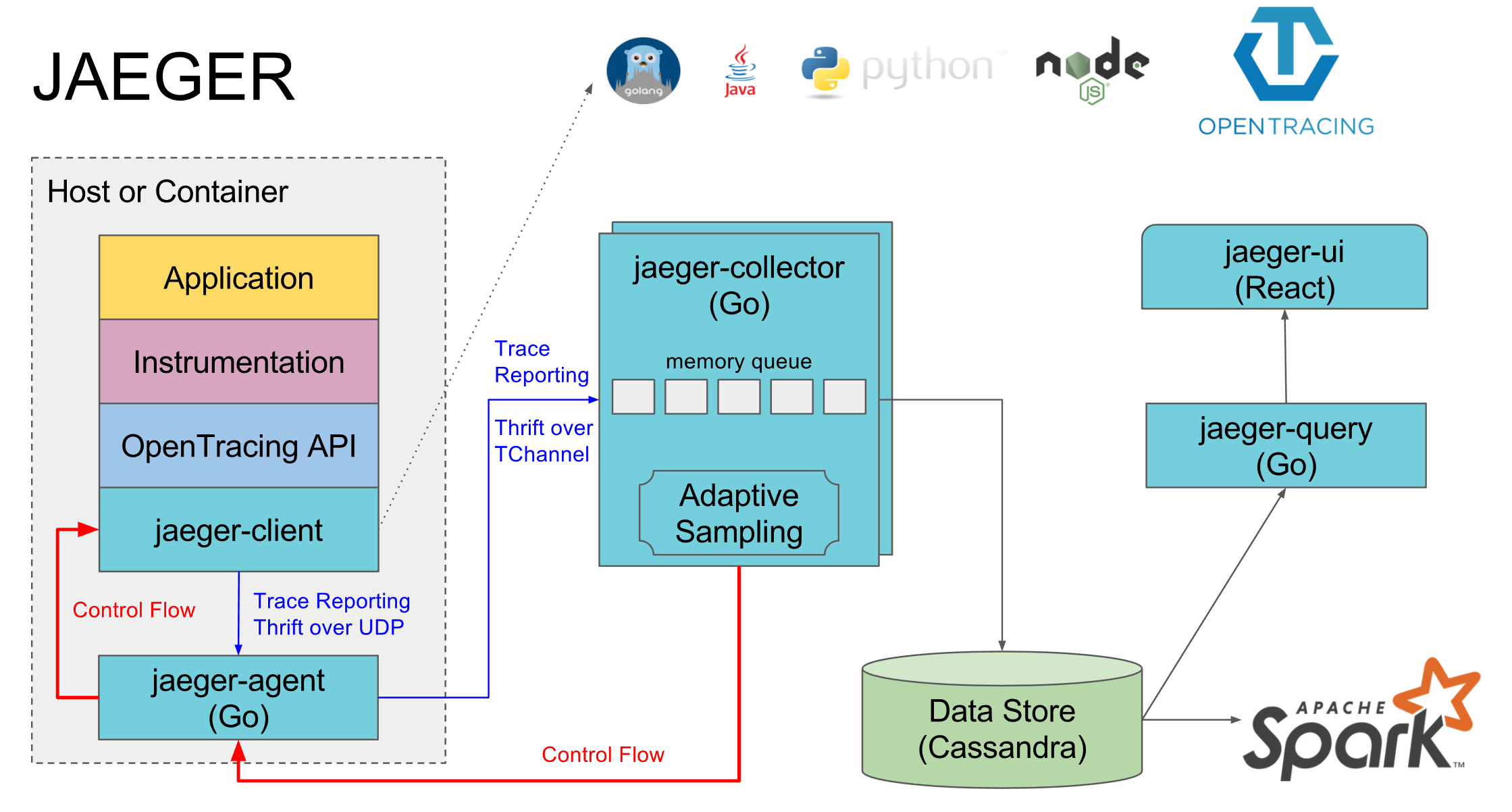
- وكيل Jaeger هو وكيل محلي يقف عادةً على كل جهاز ويتم تسجيل الخدمات فيه على المنفذ الافتراضي المحلي. إذا لم يكن هناك وكيل ، فسيتم إيقاف تشغيل آثار جميع الخدمات على هذا الجهاز
- Jaeger-collector - يقوم كل الوكلاء بإرسال آثار مجمعة إليها ، ويضعها في قاعدة البيانات المحددة
- قاعدة البيانات هي كاساندرا المفضلة لديهم ، لكننا نستخدم elasticsearch ، وهناك تطبيقات لبضع قواعد البيانات الأخرى وفي الذاكرة تطبيق لا يحفظ أي شيء على القرص
- Jaeger-query هي خدمة تنتقل إلى قاعدة البيانات وتعطي آثارًا تم جمعها بالفعل للتحليل
- Jaeger-ui هي واجهة ويب للبحث عن الآثار وعرضها ، وهي تذهب إلى jaeger-query
يتمثل المكون المنفصل في تنفيذ jaeger opentracing للغات معينة ، والتي يتم من خلالها إرسال المسافات إلى وكيل jaeger.
يربط Connecting Jagger في Java بمحاكاة واجهة io.opentracing.Tracer ، وبعد ذلك ستنتقل جميع الآثار من خلالها إلى الوكيل الحقيقي.
يمكنك أيضًا توصيل
opentracing-spring-cloud-starter وتطبيق من Jaeger
opentracing-spring-jaeger-cloud-starter والذي سيقوم تلقائيًا بتكوين التتبع لكل شيء يمر عبر هذه المكونات ، على سبيل المثال ، طلبات HTTP إلى وحدات التحكم ، طلبات قاعدة البيانات عبر jdbc إلخ
تتبع تسجيل الدخول في جافا
في مكان ما في المستوى الأعلى ، يجب إنشاء Span الأولى ، ويمكن القيام بذلك تلقائيًا ، على سبيل المثال ، من خلال وحدة التحكم في الزنبرك عند تلقي طلب ، أو يدويًا في حالة عدم وجود طلب. كذلك ينتقل من خلال النطاق أدناه. إذا أرادت بعض الطرق أدناه إضافة Span ، فإنها تأخذ activeSpan الحالي من Scope ، وتقوم بإنشاء Span جديدة وتقول إن أصلها تلقى activeSpan ، ويجعل Span الجديدة نشطة. عند استدعاء الخدمات الخارجية ، يتم نقل النطاق النشط الحالي إليهم ، وتقوم هذه الخدمات بإنشاء مسافات جديدة بالرجوع إلى هذه الفترة.
كل العمل يمر عبر مثيل Tracer ، يمكنك الحصول عليه من خلال آلية DI ، أو GlobalTracer.get () كمتغير عام إذا لم تنجح آلية DI. بشكل افتراضي ، إذا لم تتم تهيئة التتبع ، فسوف يعود NoopTracer وهو لا يفعل شيئًا.
علاوة على ذلك ، يتم الحصول على النطاق الحالي من التتبع عبر ScopeManager ، يتم إنشاء نطاق جديد من النطاق الحالي بربط النطاق الجديد ، ثم يتم إغلاق النطاق الذي تم إنشاؤه ، والذي يغلق النطاق الذي تم إنشاؤه ويعيد النطاق السابق إلى الحالة النشطة. يرتبط النطاق بتيار ، لذلك عند البرمجة متعددة الخيوط ، يجب ألا تنسَ نقل النطاق النشط إلى دفق آخر ، لمزيد من التنشيط لـ Scope لدفق آخر مع الإشارة إلى هذا النطاق.
io.opentracing.Tracer tracer = ...;
بالنسبة للبرمجة متعددة الخيوط ، هناك أيضًا TracedExecutorService وأغلفة مماثلة تقوم تلقائيًا بإعادة توجيه النطاق الحالي إلى التدفق عند بدء تشغيل المهام غير المتزامنة:
private ExecutorService executor = new TracedExecutorService( Executors.newFixedThreadPool(10), GlobalTracer.get() );
لطلبات HTTP الخارجية ، هناك
TracingHttpClient HttpClient httpClient = new TracingHttpClientBuilder().build();
المشاكل التي نواجهها
- لا يعمل Beans و DI دائمًا إذا لم يتم استخدام tracer في خدمة أو مكون ، ثم قد لا يعمل Autowired Tracer وسيكون عليك استخدام GlobalTracer.get ().
- لا تعمل التعليقات التوضيحية إذا لم تكن مكونًا أو خدمة ، أو إذا كان استدعاء الطريقة يأتي من طريقة مجاورة لنفس الفئة. يجب أن تكون حذراً ، وتحقق مما ينفع ، واستخدم الإنشاء اليدوي للتتبع إذا لم يعملTraced. يمكنك أيضًا تثبيت مترجم إضافي لتعليقات جافا ، ثم يجب أن تعمل في كل مكان.
- في التمهيد الربيعي والربيعي القديم ، لا يعمل التكوين التلقائي لغياب الربيع opentraing بسبب الأخطاء في DI ، ثم إذا كنت تريد أن تعمل آثار المكونات الربيعية تلقائيًا ، فيمكنك القيام بذلك عن طريق القياس مع github.com/opentracing-contrib/java-spring-jaeger/blob/ ماجستير / opentracing-spring-jaeger-star / src / main / java / io / opentracing / المساهمة / java / spring / jaeger / starter / JaegerAutoConfiguration.java
- حاول مع الموارد لا يعمل في رائع ، يجب عليك استخدام المحاولة في النهاية.
- يجب أن يكون لكل خدمة spring.application.name الخاصة به والتي سيتم بموجبها تسجيل الآثار. ماذا اسم منفصل للبيع والاختبار ، حتى لا تتداخل معهم.
- إذا كنت تستخدم GlobalTracer و tomcat ، فكل الخدمات التي تعمل في هذا tomcat لديها GlobalTracer واحدة ، لذلك سيكون لها جميعها اسم الخدمة نفسه.
- عند إضافة آثار إلى طريقة ما ، يجب أن تتأكد من عدم استدعائها في الحلقة عدة مرات. من الضروري إضافة تتبع واحد مشترك لجميع المكالمات ، مما يضمن إجمالي وقت العمل. خلاف ذلك ، سيتم إنشاء الحمل الزائد.
- بمجرد وصولهم إلى jaeger-ui ، قاموا بتقديم طلبات كبيرة جدًا لعدد كبير من الآثار ولأنهم لم ينتظروا إجابة فعلوها مرة أخرى. نتيجة لذلك ، بدأ jaeger-query في تناول الكثير من الذاكرة وإبطاء المرونة. ساعد في إعادة تشغيل jaeger-query
أخذ العينات ، وتخزين وعرض الآثار
هناك ثلاثة أنواع من
عينات التتبع :
- Const الذي يرسل ويحفظ جميع الآثار.
- الاحتمالية التي ترشح آثار مع بعض الاحتمال معين.
- تحديد مما يحد من عدد من آثار في الثانية الواحدة. يمكنك تكوين هذه الخيارات على العميل ، إما على وكيل جايجر أو في المجمع. الآن لدينا const 1 في كومة من المثمنين ، لأنه لا يوجد الكثير من الطلبات ، لكنها تستغرق وقتا طويلا. في المستقبل ، إذا كان هذا سيؤدي إلى زيادة الحمل على النظام ، فيمكنك الحد منه.
إذا كنت تستخدم الكسندرا ، فإنه يقوم بشكل افتراضي بتخزين الآثار في يومين فقط. نحن نستخدم
elasticsearch ويتم تخزين الآثار طوال الوقت ولا يتم حذفها. يتم إنشاء فهرس منفصل لكل يوم ، على سبيل المثال ، jaeger-service-2019-03-04. في المستقبل ، تحتاج إلى تكوين التنظيف التلقائي للآثار القديمة.
من أجل مشاهدة الدورات التدريبية التي تحتاجها:
- اختر خدمة تريد من خلالها تصفية التتبعات ، على سبيل المثال tomcat7-default لخدمة تعمل على طماطم ولا يمكن أن يكون لها اسم.
- بعد ذلك ، حدد العملية والفاصل الزمني والحد الأدنى لوقت التشغيل ، على سبيل المثال من 10 ثوانٍ ، لتستغرق فترات تشغيل طويلة فقط.
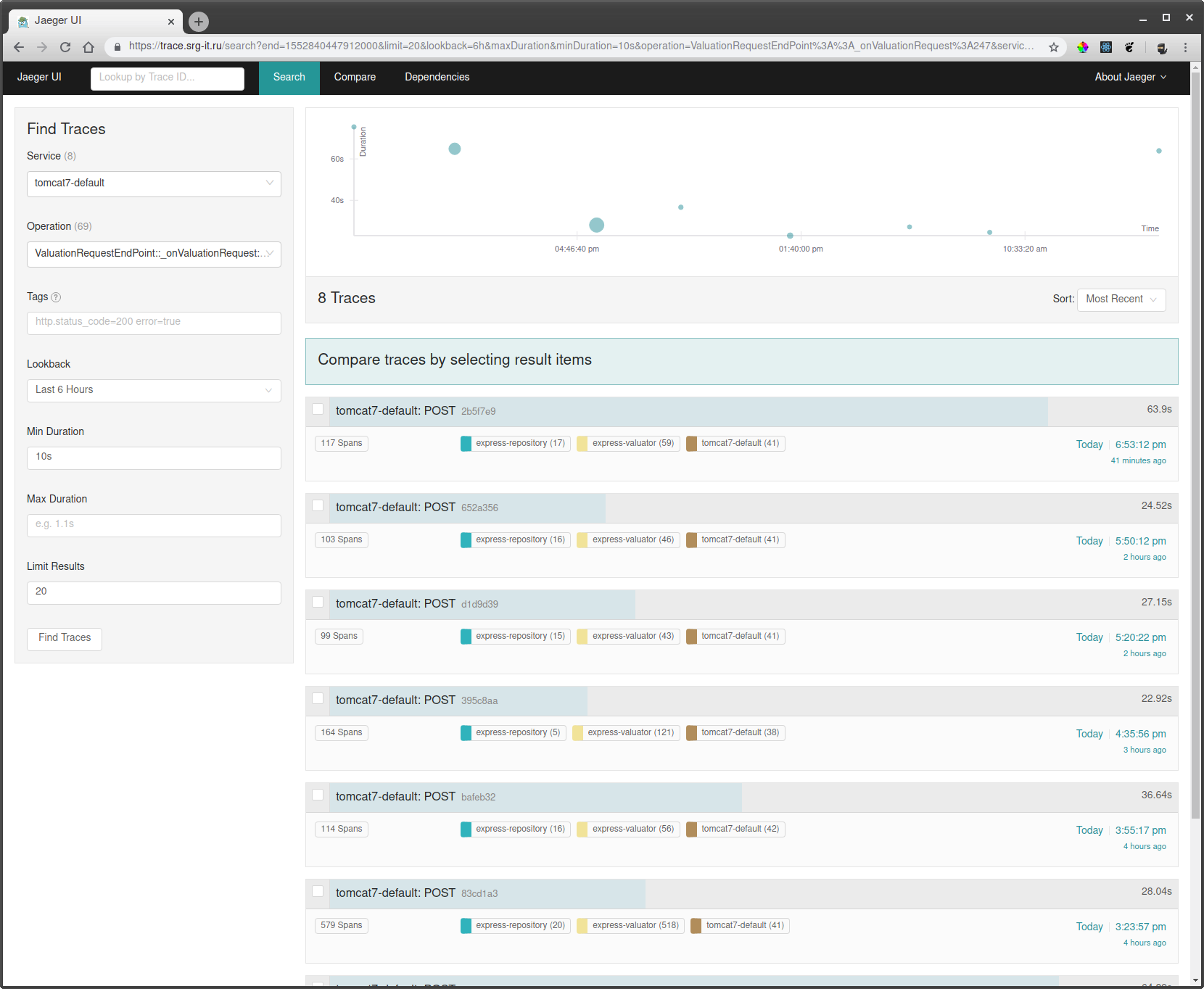
- اذهب إلى أحد المسارات وشاهد ما الذي كان يتباطأ هناك.

أيضًا ، إذا كان معرّف الطلب معروفًا ، يمكنك حينئذٍ العثور على تتبع بهذا المعرف من خلال البحث عن علامات ، إذا تم تسجيل هذا المعرف في فترة التتبع.
الوثائق
مقالات
فيديو