
أصبحت العلوم الشعبية وحتى وسائل الترفيه غارقة في الأخبار حول نجاح مشاريع الذكاء الاصطناعى. إما أن يهزم الذكاء الاصطناعي شخصًا في طريقه ، ثم يتعلم لعب StarCraft ويخرج منتصراً من معركة مع أبطال معترف بهم. وهذا ليس سوى جزء صغير من الإنجازات ، في الواقع ، هناك الكثير. قد يعتقد شخص عادي (بمعنى ما لا يرتبط بمجال تكنولوجيا المعلومات) أن ذكاء اصطناعيًا حقيقيًا "كبيرًا" على وشك الظهور ، حيث أكتب عن الخيال العلمي وأنتج الأفلام.
لكن كل شيء أبعد ما يكون عن الوردية. على سبيل المثال ، في اليوم الآخر ، كانت هناك معلومات تفيد بأن منظمة العفو الدولية حاولت اجتياز الاختبار في الرياضيات العليا (اختبار مدرسي ، معيار في المملكة المتحدة) ولم تستطع القيام بذلك.
من حيث المبدأ ، يمكن تفسير أسباب الفشل دون صعوبة كبيرة. لذلك ، فإن أي شخص في حل المشكلات الرياضية يتضمن القدرات والقدرات التالية.
يعدل في جوهره الرموز في جوهرها ، مثل الأرقام ، العوامل الحسابية ، المتغيرات (التي تشكل وظائف في مجمع) والكلمات (تحديد سؤال ، معنى المهمة ، وما إلى ذلك).
- التخطيط (على سبيل المثال ، ترتيب الوظائف بالترتيب الضروري لحل مشكلة رياضية).
- استخدام خوارزميات مساعدة لتكوين وظائف (الجمع والضرب).
- استخدام ذاكرة قصيرة الأجل لتخزين القيم الوسيطة (مثل h (f (x))).
- تم تطبيق المعرفة المكتسبة سابقًا حول القواعد والتحولات والعمليات والبديهيات.
تم تدريب DeepMind واختبارها على مجموعة من أنواع مختلفة من المشكلات والمشاكل الرياضية. لم يستخدم المطورون التعهيد الجماعي ، بل قاموا بتجميع مجموعة بيانات لإنشاء عدد كبير من مهام الاختبار ، والتحكم في تعقيدها ، إلخ. استخدم فريق التطوير تنسيق بيانات النص "شكل حر".
استندت البيانات الأولية إلى مهام من مجموعة من المهام للطلاب في مدارس المملكة المتحدة (أقل من 16 عامًا). أخذت المهام من اتجاهات مثل الحساب والجبر ونظرية الاحتمالات ، إلخ.
استقر فريق DeepMind ، الذي اختار بنية الشبكة العصبية لحل المشكلات الرياضية ، على LSTM (
ذاكرة قصيرة المدى طويلة المدى )
ومحول (بنية شبكة عصبية للعمل مع التسلسلات).
قام DeepMind باختبار نموذجين من LSTM للتعامل مع مشكلات الرياضيات: LSTM و Attensive LSTM البسيط الذي يظهر مخطط التشغيل الخاص به في الشكل أدناه.
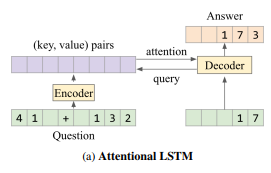
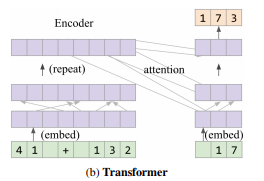
أدناه هو مخطط لنموذج المحولات.
وكانت النتيجة ليست جيدة جدا. 35٪ فقط من إجابات منظمة العفو الدولية كانت صحيحة ، وهذا تقييم غير مرضٍ وفقًا لمعايير أي مدرسة.
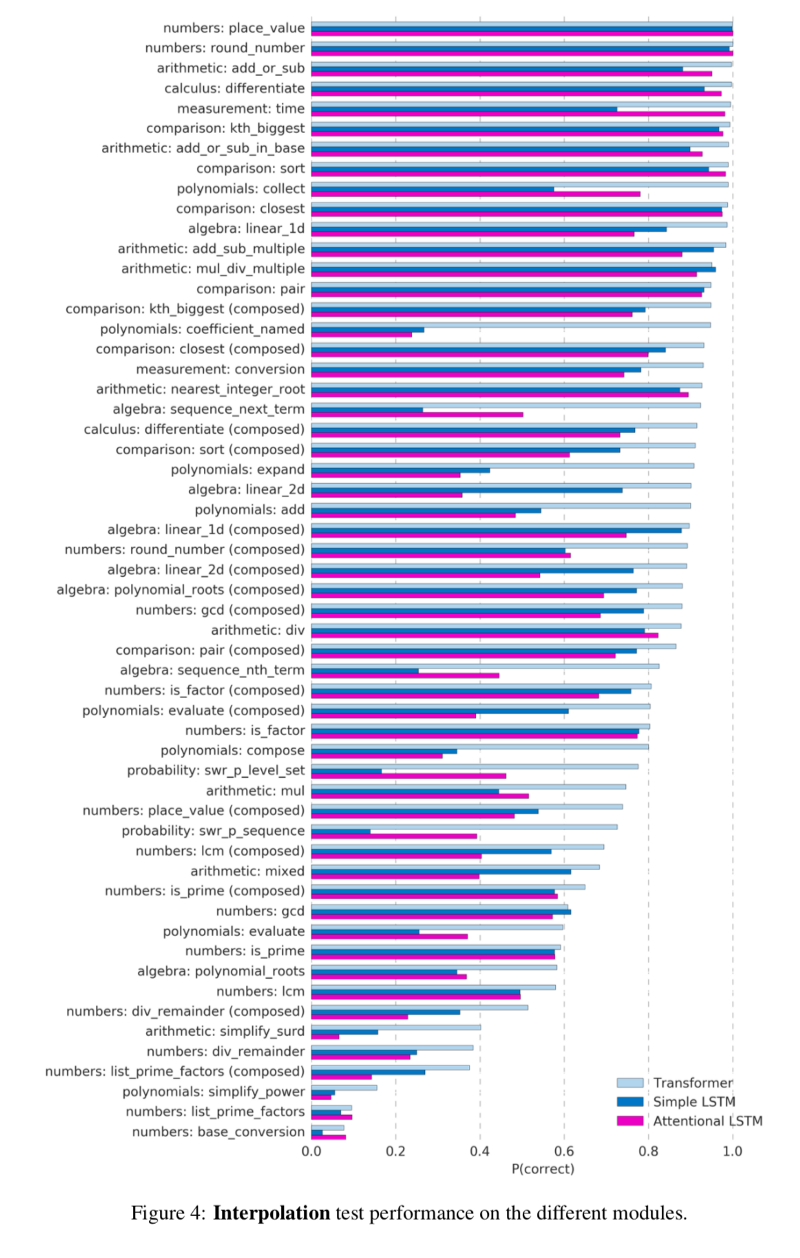
بالطبع ، بدأ الباحثون من DeepMind للتو العمل مع الرياضيات ومنظمة العفو الدولية. في المستقبل ، يمكن توقع نجاح أكبر ، كما كان الحال مع نفس AlphaGo.
يمكن الاطلاع على بيانات الدراسة الكاملة على
هذا الرابط .

