مرحبا. في نهاية العام الماضي ، بدأنا في إخفاء أرقام لوحات الترخيص تلقائيًا على الصور الفوتوغرافية في بطاقات إعلان Avito. حول سبب قيامنا بهذا ، وما هي طرق حل هذه المشكلات ، اقرأ المقال.

مهمة
في Avito في عام 2018 ، تم بيع 2.5 مليون سيارة. هذا هو تقريبا 7000 في اليوم. جميع الإعلانات المعروضة للبيع بحاجة إلى توضيح - صورة لسيارة. ولكن من خلال رقم الدولة على ذلك ، يمكنك العثور على الكثير من المعلومات الإضافية حول السيارة. ويحاول بعض مستخدمينا إغلاق لوحة الترخيص بمفردهم.
قد تختلف الأسباب وراء رغبة المستخدمين في إخفاء رقم لوحة الترخيص. من جانبنا ، نريد مساعدتهم في حماية بياناتهم. ونحن نحاول تحسين عمليات البيع والشراء للمستخدمين. على سبيل المثال ، تعمل خدمة الأرقام المجهولة معنا منذ فترة طويلة: عندما تبيع سيارة ، يتم إنشاء رقم خليوي مؤقت لك. حسنًا ، لحماية البيانات الموجودة على لوحات الترخيص ، نقوم بإخفاء هوية الصور.

نظرة عامة على الحل
لأتمتة عملية حماية صور المستخدم ، يمكنك استخدام الشبكات العصبية التلافيفية لاكتشاف مضلع باستخدام لوحة ترخيص.
الآن ، لاكتشاف الكائنات ، تُستخدم معماريات مجموعتين: شبكات من مرحلتين ، على سبيل المثال ، Faster RCNN و Mask RCNN ؛ مرحلة واحدة (فردي) - SSD ، YOLO ، RetinaNet. اكتشاف كائن ما هو اشتقاق الإحداثيات الأربعة للمستطيل التي تم إدراج كائن الفائدة فيها.
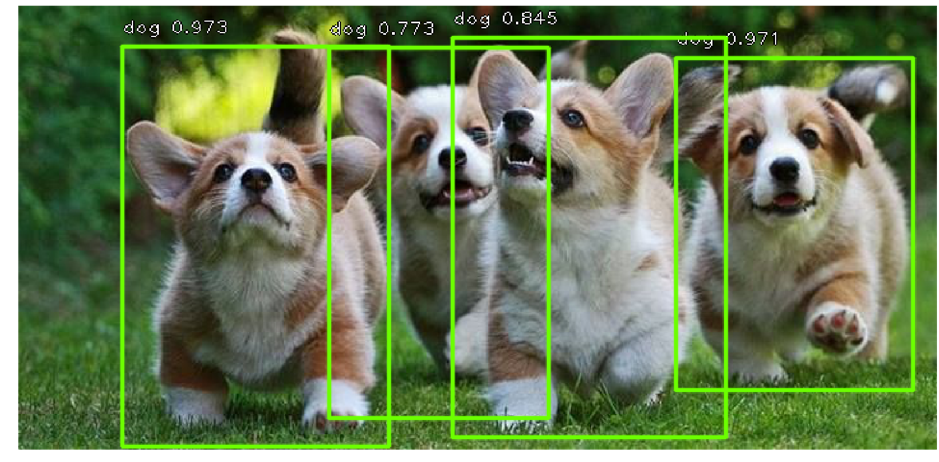
تستطيع الشبكات المذكورة أعلاه العثور على الكثير من الكائنات من فئات مختلفة في الصور ، والتي تعد ضرورية بالفعل لحل مشكلة البحث عن لوحة الترخيص ، لأنه عادة ما يكون لدينا سيارة واحدة فقط في الصور (هناك استثناءات عندما يلتقط الأشخاص صور لسيارتهم المباعة وجارها العشوائي ، لكن هذا نادرًا ما يحدث ، لذلك يمكن إهمال ذلك).
ميزة أخرى لهذه الشبكات هي أنها تنتج افتراضيًا مربعًا محاطًا به جوانب موازية لمحاور الإحداثيات. يحدث هذا بسبب استخدام مجموعة من الأنواع المحددة مسبقًا من الإطارات المستطيلة والتي تسمى مربعات التثبيت للكشف. بتعبير أدق ، أولاً باستخدام شبكة تلافيفية (على سبيل المثال ، resnet34) ، يتم الحصول على مصفوفة من السمات من الصورة. ثم ، لكل فئة فرعية من السمات التي يتم الحصول عليها باستخدام النافذة المنزلق ، يحدث تصنيف: هل هناك كائن لصندوق المرساة k أم لا ، ويتم إجراء الانحدار في الإحداثيات الأربعة للإطار ، والتي تقوم بضبط موضعها.
اقرأ المزيد عن هذا
هنا .
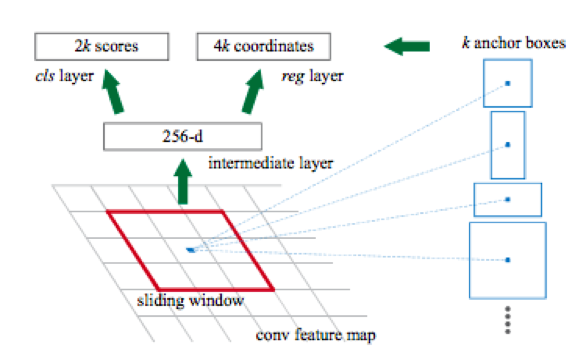
بعد ذلك ، هناك رئيسان آخران:
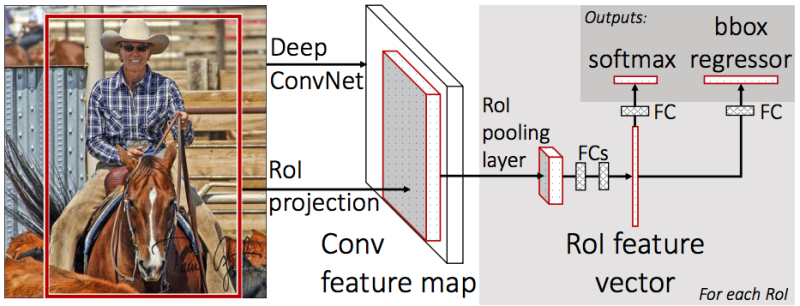
واحد لتصنيف الكائن (الكلب / القط / النبات ، وما إلى ذلك) ،
الثانية (bbox regressor) - لتراجع إحداثيات الإطار الذي تم الحصول عليه في الخطوة السابقة من أجل زيادة نسبة مساحة الكائن إلى مساحة الإطار.
من أجل التنبؤ بإطار الملاكمة المدور ، تحتاج إلى تغيير regressor bbox بحيث يمكنك أيضًا الحصول على زاوية تدوير الإطار. إذا لم يتم ذلك ، فسوف يتحول بطريقة ما.

بالإضافة إلى مرحلتين Faster R-CNN على مرحلتين ، هناك كاشفات من مرحلة واحدة ، مثل RetinaNet. إنه يختلف عن الهيكل السابق في أنه يتنبأ على الفور بالفئة والإطار ، دون المرحلة الأولية من اقتراح أقسام من الصورة التي قد تحتوي على كائنات. للتنبؤ بالأقنعة الدوارة ، يجب عليك أيضًا تغيير رأس الشبكة الفرعية للمربع.
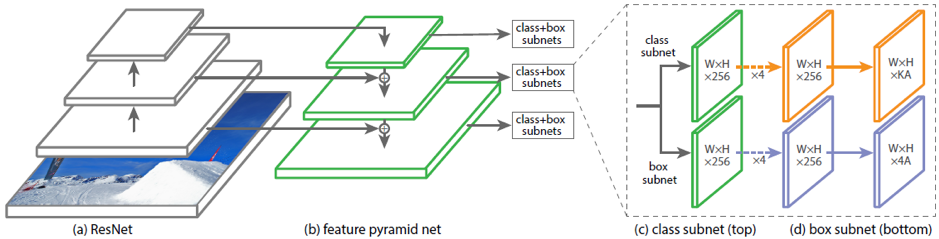
أحد الأمثلة على البنى الحالية للتنبؤ بصناديق الإحاطة الدوارة هي DRBOX. لا تستخدم هذه الشبكة المرحلة الأولية لاقتراح المنطقة ، كما هو الحال في Faster RCNN ، وبالتالي فهي تعدل من أساليب المرحلة الواحدة. لتدريب هذه الشبكة ، يتم استخدام K بالتناوب عند زوايا معينة مربعة (rbox). تتوقع الشبكة احتمالات احتواء كل من K rbox على الكائن الهدف والإحداثيات وحجم bbox وزاوية الدوران.

يعد تعديل البنية وإعادة تدريب إحدى الشبكات التي تم النظر فيها على البيانات باستخدام مربعات ربط مستديرة مهمة قابلة للتحقيق. لكن هدفنا يمكن تحقيقه بسهولة أكبر ، لأن نطاق الشبكة لدينا أضيق بكثير - فقط لإخفاء لوحات الترخيص.
لذلك ، قررنا البدء بشبكة بسيطة للتنبؤ بالنقاط الأربع للرقم ، وبالتالي سيكون من الممكن تعقيد البنية.
معطيات
ينقسم تجميع مجموعة البيانات إلى خطوتين: جمع صور للسيارات ووضع علامة على المنطقة عليها لوحة ترخيص. تم حل المهمة الأولى بالفعل في البنية التحتية لدينا: نقوم بتخزين جميع الإعلانات التي تم وضعها على Avito بعناية. لحل المشكلة الثانية ، نستخدم Toloka. على
toloka.yandex.ru/requester نقوم بإنشاء مهمة:
المهمة تعطى صورة للسيارة. من الضروري تسليط الضوء على لوحة ترخيص السيارة باستخدام رباعي الزوايا. في هذه الحالة ، يجب تخصيص رقم الولاية بأكبر قدر ممكن من الدقة.

باستخدام Toloka ، يمكنك إنشاء مهام لترميز البيانات. على سبيل المثال ، قم بتقييم جودة نتائج البحث ، وحدد فئات مختلفة من الكائنات (النصوص والصور) ، وشفر مقاطع الفيديو ، إلخ. سيتم تنفيذها بواسطة مستخدمي Toloka ، مقابل الرسوم التي تتقاضاها. على سبيل المثال ، في حالتنا ، يجب على مستخدمي tolok تسليط الضوء على المكب مع رقم لوحة ترخيص السيارة في الصورة. بشكل عام ، إنها مريحة جدًا لترميز مجموعة بيانات كبيرة ، لكن الحصول على جودة عالية أمر صعب للغاية. هناك الكثير من برامج الروبوت في الحشد ، تتمثل مهمتها في الحصول على أموال منك عن طريق إعطاء إجابات بشكل عشوائي أو باستخدام نوع من الاستراتيجية. لمواجهة هذه الروبوتات هناك نظام من القواعد والشيكات. الاختيار الرئيسي هو خلط أسئلة التحكم: تقوم يدويًا بترميز جزء من المهام باستخدام واجهة Toloki ، ثم دمجها في المهمة الرئيسية. إذا كان هناك خطأ غالبًا في الترميز في أسئلة التحكم ، فأنت تحظره ولا تأخذ في الاعتبار الترميز.
بالنسبة لمهمة التصنيف ، من السهل جدًا تحديد ما إذا كانت العلامة خاطئة أم لا ، وبالنسبة لمشكلة تمييز منطقة ما ، فإنها ليست بهذه البساطة. الطريقة الكلاسيكية هي لحساب IoU.
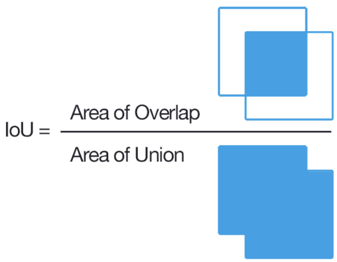
إذا كانت هذه النسبة أقل من حد معين لعدة مهام ، فسيتم حظر هذا المستخدم. ومع ذلك ، بالنسبة إلى رباعيتين تعسفيين ، فإن حساب IoU ليس بهذه السهولة ، خاصة أنه في Tolok ، من الضروري تنفيذ ذلك في JavaScript. لقد اخترقنا اختراقًا صغيرًا ، ونعتقد أن المستخدم لم يكن مخطئًا إذا كانت هناك نقطة تحمل علامة على كل نقطة من مصدر المضلع في حي صغير. هناك أيضًا قاعدة استجابة سريعة لحظر استجابة المستخدمين بسرعة كبيرة ، أو اختبار captcha ، أو تناقض مع رأي الأغلبية ، إلخ. بعد إعداد هذه القواعد ، يمكنك توقع علامات جيدة جدًا ، ولكن إذا كنت حقًا بحاجة إلى علامات عالية الجودة ومعقدة ، فأنت بحاجة إلى استئجار كتابات لحسابهم الخاص على وجه التحديد. نتيجةً لذلك ، بلغت مجموعة البيانات الخاصة بنا صورًا بعلامة 4K ، وكل ذلك يكلف 28 دولارًا في Tolok.
نموذج
الآن لنقم بإنشاء شبكة للتنبؤ بالنقاط الأربع في المنطقة. سنحصل على العلامات باستخدام resnet18 (معلمات 11.7M مقابل 21.8M معلمات resnet34) ، ثم نضع رأسًا للانحدار إلى أربع نقاط (ثمانية إحداثيات) ورأس التصنيف سواء كانت هناك لوحة ترخيص في الصورة أم لا. هناك حاجة إلى الرأس الثاني ، لأنه في الإعلانات لبيع السيارات ، وليس كل الصور مع السيارات. قد تكون الصورة تفاصيل السيارة.

على غرارنا ، بالطبع ، ليس من الضروري اكتشافه.
نقوم بتدريب هدفين في نفس الوقت عن طريق إضافة صورة إلى مجموعة البيانات بدون لوحة ترخيص مع صندوق محيط (0،0،0،0،0،0،0،0) هدف وقيمة المصنف "صورة مع / بدون لوحة ترخيص" - (0 ، 1).
ثم يمكنك إنشاء دالة خسارة واحدة لكلا الهدفين كمجموع للخسائر التالية. للتراجع إلى إحداثيات مضلع لوحة الترخيص ، نستخدم خسارة L1 سلسة.
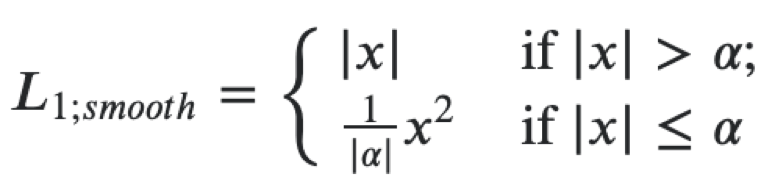
يمكن تفسيره على أنه مزيج من L1 و L2 ، والذي يتصرف مثل L1 عندما تكون القيمة المطلقة للوسيطة كبيرة و L2 عندما تكون قيمة الوسيطة قريبة من الصفر. للتصنيف ، ونحن نستخدم softmax وفقدان crossentropy. مستخرج الميزات هو resnet18 ، نستخدم الأوزان المدربة مسبقًا على ImageNet ، ثم سنقوم بتدريب النازع والرؤوس على مجموعة البيانات الخاصة بنا. في هذه المشكلة ، استخدمنا إطار عمل mxnet ، لأنه الإطار الرئيسي لرؤية الكمبيوتر في Avito. بشكل عام ، تسمح لك بنية الخدمة microservice بعدم الارتباط بإطار عمل محدد ، لكن عندما يكون لديك قاعدة كبيرة للشفرة ، من الأفضل استخدامها وعدم كتابة نفس الكود مرة أخرى.
بعد أن حصلنا على جودة مقبولة في مجموعة البيانات الخاصة بنا ، لجأنا إلى المصممين لتزويدنا بلوحة ترخيص تحمل شعار Avito. في البداية حاولنا القيام بذلك بأنفسنا ، بالطبع ، لكنها لم تبدو جميلة جدًا. بعد ذلك ، تحتاج إلى تغيير سطوع لوحة ترخيص Avito إلى سطوع المنطقة الأصلية باستخدام لوحة الترخيص ويمكنك تراكب الشعار على الصورة.

إطلاق في همز
لا تزال مشكلة استنساخ النتائج ودعم وتطوير المشروعات ، التي يتم حلها مع وجود بعض الأخطاء في عالم تطوير الواجهة الخلفية وتطوير الواجهة ، مفتوحة حيث يلزم استخدام نماذج التعلم الآلي. ربما كان عليك فهم نموذج الكود القديم. من الجيد أن يكون لدى الملف التمهيدي روابط لمقالات أو مستودعات مفتوحة المصدر يعتمد عليها الحل. قد يفشل البرنامج النصي لبدء إعادة التدريب مع وجود أخطاء ، على سبيل المثال ، تم تغيير إصدار cudnn ، ولم يعد إصدار tensorflow يعمل مع هذا الإصدار من cudnn بعد الآن ، ولا يعمل cudnn مع هذا الإصدار من برامج تشغيل nvidia. ربما للتدريب استخدمنا مكررًا واحدًا وفقًا للبيانات ، وللاختبار في الإنتاج آخر. هذا يمكن أن يستمر لبعض الوقت. بشكل عام ، توجد مشاكل استنساخ.
نحاول إزالتها باستخدام بيئة nvidia-docker لنماذج التدريب ، ولديها جميع التبعيات اللازمة لـ cuda ، ونقوم أيضًا بتثبيت التبعيات للثعبان هناك. يعد إصدار المكتبة الذي يحتوي على مكرر وفقًا للبيانات والتكبير ونماذج الاستدلال شائعًا في مرحلة التدريب / التجربة والإنتاج. وبالتالي ، من أجل تدريب النموذج على البيانات الجديدة ، تحتاج إلى ضخ مستودع التخزين إلى الخادم ، وتشغيل البرنامج النصي shell الذي سيجمع بيئة عامل الميناء ، والتي سيظهر داخلها دفتر jupyter. في الداخل ، سيكون لديك جميع أجهزة الكمبيوتر المحمولة للتدريب والاختبار ، والتي بالتأكيد لن تفشل مع وجود خطأ بسبب البيئة. من الأفضل ، بطبيعة الحال ، أن يكون لديك ملف train.py واحد ، لكن الممارسة تدل على أنك تحتاج دائمًا إلى النظر بعين الاعتبار إلى ما يقدمه النموذج ويغير شيئًا في عملية التعلم ، لذلك في النهاية سوف تستمر في تشغيل برنامج jupyter.
يتم تخزين أوزان النماذج في git lfs - إنها تقنية خاصة لتخزين الملفات الكبيرة في git. وقبل ذلك ، استخدمنا المصنوعات اليدوية ، ولكن استخدام git lfs هو أكثر ملاءمة ، لأن تنزيل المخزون مع الخدمة ، ستحصل على الإصدار الحالي من المقاييس على الفور ، كما هو الحال في الإنتاج. تتم كتابة الاختبارات التلقائية للاستدلال على النموذج ، لذلك لن تتمكن من طرح خدمة بأوزان لا تتجاوزها. يتم إطلاق الخدمة نفسها في عامل الميناء داخل البنية التحتية للخدمات الميكروية على نظام kubernetes. لمراقبة الأداء ، نستخدم grafana. بعد التدحرج ، نقوم بزيادة الحمل على مثيلات الخدمة تدريجياً باستخدام نموذج جديد. عند طرح ميزة جديدة ، نقوم بإنشاء اختبارات / b وإصدار حكم بشأن مصير الميزة في المستقبل ، استنادًا إلى الاختبارات الإحصائية.
ونتيجة لذلك: أطلقنا عملية تلميع الأرقام على الإعلانات في الفئة التلقائية للتجار من القطاع الخاص ، والنسبة المئوية 95 لوقت معالجة صورة واحدة لإخفاء الرقم هي 250 مللي ثانية.