في فبراير إلى مارس 2019 ، تم إجراء مسابقة لتصنيف موجز الشبكة الاجتماعية SNA Hackathon 2019 ، حيث احتل فريقنا المركز الأول. سأتحدث في هذا المقال عن تنظيم المسابقة ، والطرق التي جربناها ، وإعدادات catboost للتدريب على البيانات الضخمة.

SNA هاكاثون
يقام hackathon تحت هذا الاسم للمرة الثالثة. يتم تنظيمها بواسطة الشبكة الاجتماعية ok.ru ، على التوالي ، ترتبط المهمة والبيانات مباشرة إلى هذه الشبكة الاجتماعية.
يتم فهم SNA (تحليل الشبكة الاجتماعية) في هذه الحالة بشكل أفضل ، ليس كتحليل للرسم البياني الاجتماعي ، بل كتحليل لشبكة اجتماعية.
- في عام 2014 ، كانت المهمة هي التنبؤ بعدد الإعجابات التي ستحصل عليها المشاركة.
- في عام 2016 ، كان هدف VVZ (ربما كنت معتادًا) ، أقرب إلى تحليل الرسم البياني الاجتماعي.
- في عام 2019 - ترتيب خلاصة المستخدم حسب احتمالية إعجاب المستخدم بالرسالة.
لا أستطيع أن أقول عن عام 2014 ، ولكن في عامي 2016 و 2019 ، بالإضافة إلى القدرة على تحليل البيانات ، كانت هناك حاجة أيضًا إلى مهارات في العمل مع البيانات الضخمة. أعتقد أن الجمع بين التعلم الآلي ومهام معالجة البيانات الكبيرة هو ما جذبني إلى هذه المسابقات ، وقد ساعدت التجربة في هذه المجالات على الفوز.
mlbootcamp
في عام 2019 ، تم تنظيم المسابقة على منصة https://mlbootcamp.ru .
بدأت المسابقة عبر الإنترنت في 7 فبراير وتتألف من 3 مهام. يمكن للجميع التسجيل على الموقع وتنزيل خط الأساس وتحميل سياراتهم لعدة ساعات. في نهاية المرحلة عبر الإنترنت في 15 مارس ، تمت دعوة أفضل 15 عرضًا إلى مكتب Mail.ru للمرحلة غير المتصلة بالإنترنت ، والتي جرت في الفترة من 30 مارس إلى 1 أبريل.
مهمة
توفر البيانات المصدر معرفات المستخدم (userId) ومعرفات النشر (objectId). إذا تم عرض منشور على المستخدم ، فإن البيانات تحتوي على سطر يحتوي على userId ، و objectId ، وردود فعل المستخدم على هذا المنشور (feedback) ومجموعة من العلامات أو الروابط المختلفة للصور والنصوص.
| حاليا | objectId | ownerId | ردود الفعل | صور |
|---|
| 3555 | 22 | 5677 | [أعجبني ، نقر] | [Hash1] |
| 12842 | 55 | 32144 | [كره] | [hash2 ، hash3] |
| 13145 | 35 | 5677 | [نقر ، أعيد مشاركة] | [Hash2] |
تحتوي مجموعة بيانات الاختبار على بنية مشابهة ، لكن حقل الملاحظات مفقود. الهدف من ذلك هو التنبؤ بوجود رد فعل "محبوب" في حقل الملاحظات.
يحتوي ملف الإرسال على البنية التالية:
| حاليا | SortedList [objectId] |
|---|
| 123 | 78،13،54،22 |
| 128 | 35،61،55 |
| 131 | 35،68،129،11 |
متري - متوسط ROC AUC من قبل المستخدمين.
يمكن العثور على وصف أكثر تفصيلاً للبيانات على موقع الكمال . يمكنك أيضًا تنزيل البيانات هناك ، بما في ذلك الاختبارات والصور.
المرحلة على الانترنت
في المرحلة عبر الإنترنت ، تم تقسيم المهمة إلى 3 أجزاء
- نظام تعاوني - يشمل جميع العلامات ، باستثناء الصور والنصوص ؛
- الصور - يتضمن فقط معلومات حول الصور ؛
- النصوص - تتضمن معلومات فقط عن النصوص.
مرحلة حاليا
في المرحلة غير المتصلة بالإنترنت ، شملت البيانات جميع السمات ، في حين كانت النصوص والصور قليلة. كان هناك 1.5 مرة المزيد من الصفوف في مجموعة البيانات ، والتي كان هناك العديد منها بالفعل.
حل المشكلات
منذ أن بدأت سيرتي الذاتية في العمل ، بدأت رحلتي في هذه المسابقة بمهمة "الصور". البيانات التي تم توفيرها هي userId و objectId و ownerId (المجموعة التي تم نشر المنشور فيها) ، طوابع زمنية لإنشاء المنشور وعرضه ، وبالطبع ، صورة المنشور.
بعد توليد العديد من الميزات استنادًا إلى الطابع الزمني ، كانت الفكرة التالية هي أخذ الطبقة قبل الأخيرة من العصبونات المدربة مسبقًا على imagenet وإرسال هذه التضمينات لتعزيزها.
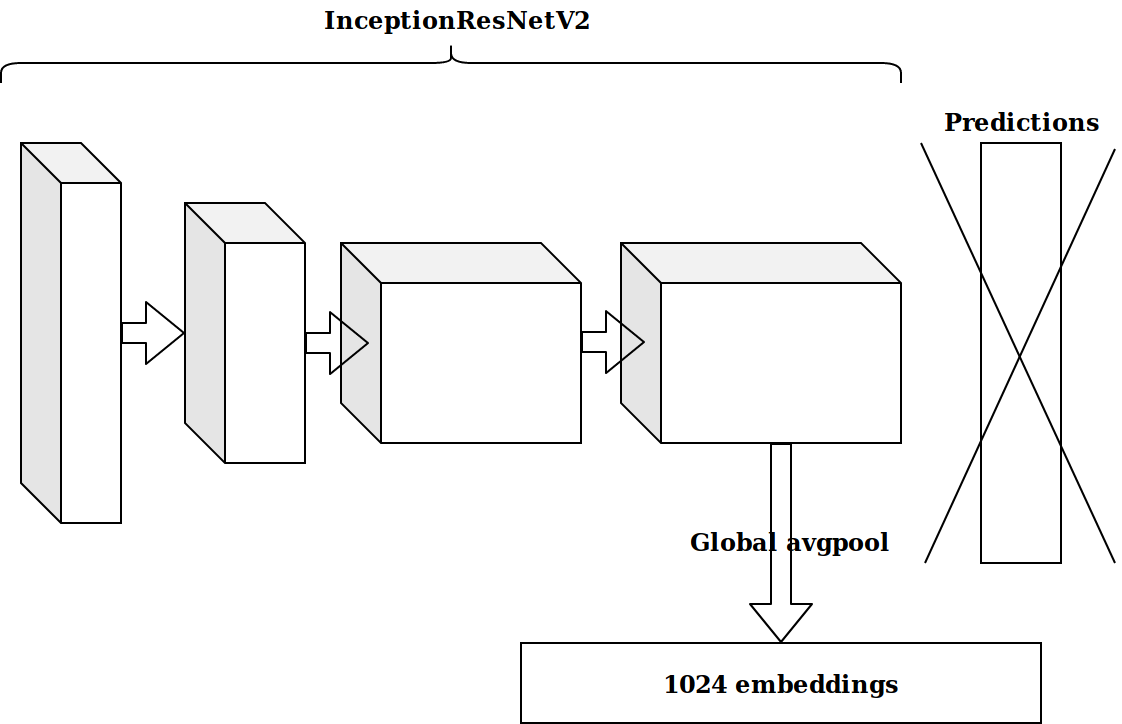
النتائج لم تكن مثيرة للإعجاب. ظننت أن الزخارف من الخلايا العصبية imagenet ليست ذات صلة ، وأنا بحاجة إلى ملف التشفير التلقائي الخاص بي.
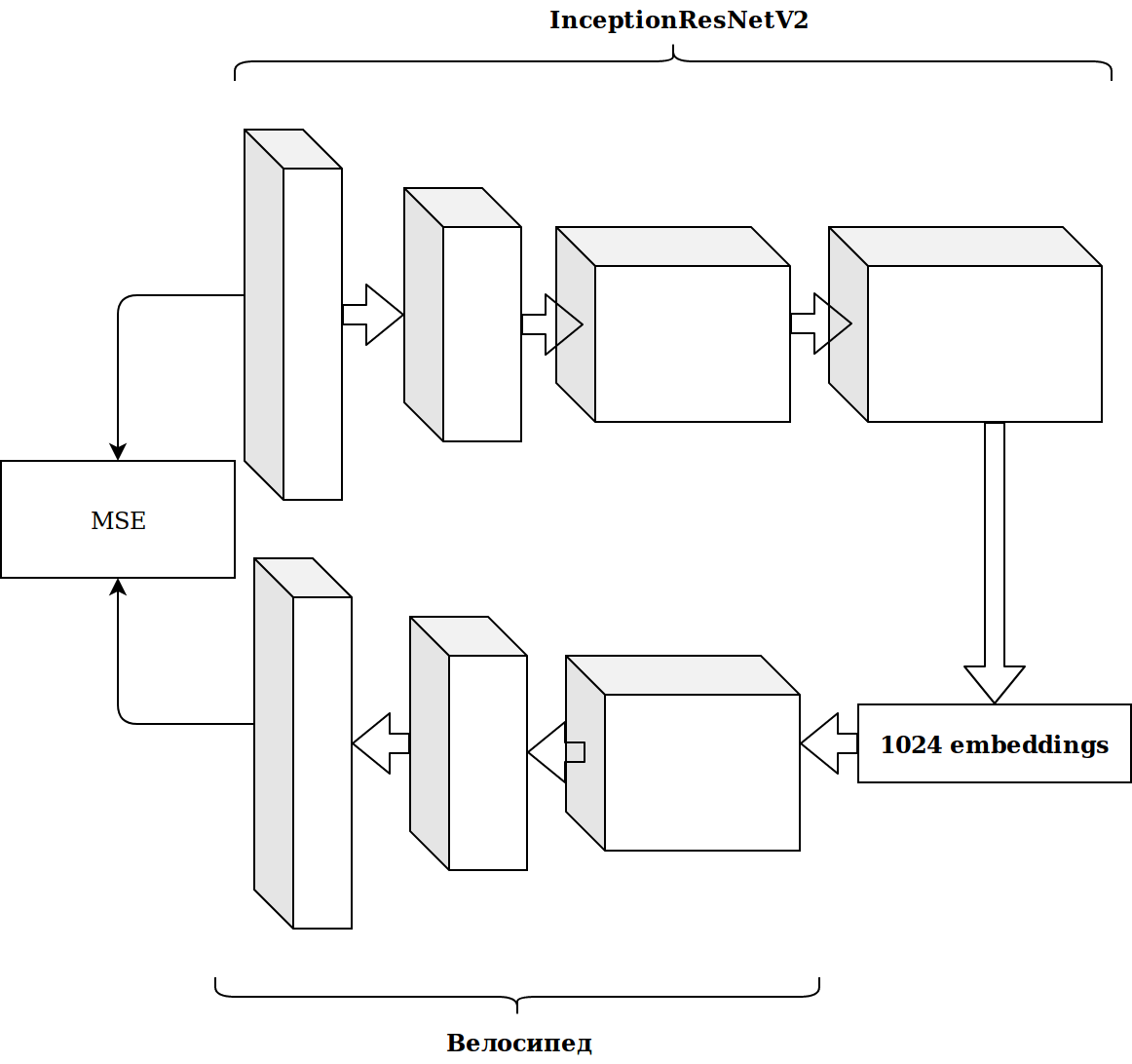
استغرق الأمر الكثير من الوقت والنتيجة لم تتحسن.
ميزة الجيل
يستغرق العمل مع الصور الكثير من الوقت ، وقررت أن أفعل شيئًا أكثر بساطة.
كما ترون على الفور ، هناك العديد من العلامات الفئوية في مجموعة البيانات ، ولكي لا أزعجني كثيرًا ، فقد أخذت للتو مجموعة صغيرة. كان الحل ممتازًا ، دون أي إعدادات ، وصلت على الفور إلى السطر الأول من المتصدرين.
هناك الكثير من البيانات وقد تم وضعها في شكل الباركيه ، لذلك دون التفكير مرتين ، أخذت سكالا وبدأت في كتابة كل شيء في شرارة.
أبسط الميزات ، والتي أعطت مزيدًا من النمو أكثر من زخارف الصور:
- عدد المرات التي اجتمع فيها objectId و userId و ownerId في البيانات (يجب أن ترتبط بالشعبية) ؛
- عدد مشاركات userId التي شاهدها ownerId (يجب أن ترتبط باهتمام المستخدم في المجموعة) ؛
- عدد المستخدمين الفريد الذين شاهدتهم النشرات بواسطة ownerId (يعكس حجم جمهور المجموعة).
من الطوابع الزمنية ، كان من الممكن الحصول على الوقت من اليوم الذي شاهد فيه المستخدم الشريط (الصباح / اليوم / المساء / الليل). من خلال الجمع بين هذه الفئات ، يمكنك الاستمرار في إنشاء ميزات:
- كم مرة userId تسجيل الدخول في المساء ؛
- في أي وقت يظهر هذا المنشور غالبًا (objectId) وما إلى ذلك.
كل هذا تحسنت تدريجيا متري. ولكن حجم مجموعة بيانات التدريب يبلغ حوالي 20 مليون سجل ، لذا فإن إضافة ميزات تباطأ إلى حد كبير في التعلم.
أعدت تعريف طريقة استخدام البيانات. على الرغم من أن البيانات تعتمد على الوقت ، إلا أنني لم أشاهد أي تسربات صريحة للمعلومات في المستقبل ، ومع ذلك ، فقط في حالة كسرها مثل هذا:
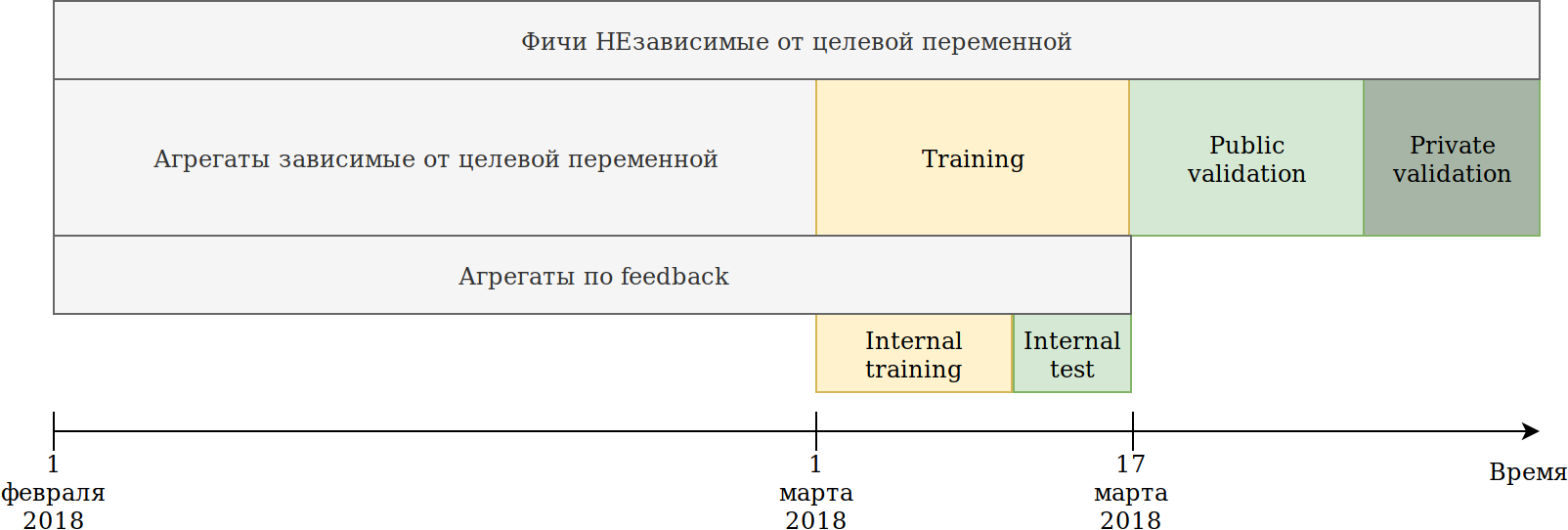
تم تقسيم مجموعة التدريب المقدمة إلينا (فبراير و 2 مارس) إلى قسمين.
على بيانات آخر أيام N قام بتدريب النموذج. المجموعات المبينة أعلاه بنيت على جميع البيانات ، بما في ذلك الاختبار. في الوقت نفسه ، ظهرت بيانات يمكن بناء عليها ترميزات مختلفة للمتغير الهدف. أبسط طريقة هي إعادة استخدام الكود الذي يقوم بالفعل بإنشاء ميزات جديدة ، وتزويده ببساطة بالبيانات التي لن يتم تدريبها والهدف = 1.
وبالتالي ، حصلنا على ميزات مماثلة:
- عدد المرات التي شاهد فيها userId منشورًا في مجموعة ownerId ؛
- كم مرة أحب المستخدم النشر إلى ownerId ؛
- نسبة المشاركات التي أحبها userId.
بمعنى أنه تبين أنه يعني ترميز الهدف من جانب مجموعة البيانات لمجموعات مختلفة من الميزات الفئوية. من حيث المبدأ ، يبني catboost أيضًا ترميزًا مستهدفًا ، ومن وجهة النظر هذه لا توجد فائدة ، ولكن ، على سبيل المثال ، أصبح من الممكن حساب عدد المستخدمين الفريدين الذين يحبون النشرات في هذه المجموعة. في الوقت نفسه ، تم تحقيق الهدف الرئيسي - انخفضت مجموعة البيانات الخاصة بي عدة مرات ، وكان من الممكن الاستمرار في إنشاء الميزات.
على الرغم من أن catboost لا يمكنه إنشاء أجهزة تشفير إلا وفقًا لتفاعلات الإعجابات ، فإن ردود الفعل لها ردود فعل أخرى: تمت إعادة مشاركتها ، أو عدم إعجابها ، أو النقر فوقها ، أو النقر فوقها ، أو تجاهلها ، والتي يمكن إجراؤها يدويًا. لقد قمت بإعادة فرز جميع أنواع المجاميع واستخرجت الميزات ذات الأهمية المنخفضة ، حتى لا تضخيم مجموعة البيانات.
بحلول ذلك الوقت كنت في المقام الأول بهامش واسع. كان الحرج الوحيد هو أن دمج الصور لم يكسب شيئًا تقريبًا. جاءت الفكرة لإعطاء كل شيء ل catboost. الكتلة Kmeans الصور والحصول على ميزة جديدة قطعية imageCat.
فيما يلي بعض الفئات بعد ترشيح ودمج الكتل التي تم الحصول عليها من KMeans يدويًا.

استنادًا إلى imageCat نقوم بإنشاء:
- الميزات الفئوية الجديدة:
- ما imageCat في كثير من الأحيان بدا userId.
- ما هي الصورة التي تظهر غالبًا بواسطة ownerId ؛
- التي imageCat غالبا ما أحب userId.
- عدادات مختلفة:
- كم عدد imageCat الفريد بدا userId ؛
- حوالي 15 ميزات مماثلة بالإضافة إلى ترميز الهدف كما هو موضح أعلاه.
النصوص
كانت النتائج في مسابقة الصور مناسبة لي وقررت أن أجرب نفسي في النصوص. في السابق ، لم أكن أعمل كثيرًا مع النصوص ، وقبل الغباء ، قتلت يوميًا على tf-idf و svd. ثم رأيت خط الأساس مع doc2vec ، والذي يفعل ما أحتاج إليه. بعد أن قمت بضبط معلمات doc2vec قليلاً ، تلقيت زخارف النص.
ثم قام ببساطة بإعادة استخدام الكود الخاص بالصور ، حيث قام باستبدال زخارف الصور بزخارف نصية. نتيجة لذلك ، حصلت على المركز الثاني في مسابقة النص.
النظام التعاوني
كانت هناك منافسة واحدة فقط لم أقم فيها "بأخذ عصا" ، لكن وفقًا للحكم الذي قدمته AUC على لوحة المتصدرين ، كان يجب أن يكون لنتائج هذه المسابقة بالذات التأثير الأكبر على مرحلة عدم الاتصال بالإنترنت.
أخذت جميع العلامات التي كانت موجودة في البيانات المصدر ، وحددت العلامات الفئوية وحسبت نفس المجاميع بالنسبة للصور ، باستثناء الميزات من الصور نفسها. فقط وضعه في catboost ، وصلت إلى المركز الثاني.
الخطوات الأولى لتحسين catboost
يسرني المركزان الأول والثاني ، لكن كان هناك تفهم أنني لم أفعل أي شيء خاص ، مما يعني أنه يمكننا توقع خسارة المركز.
تتمثل مهمة المسابقة في تصنيف المشاركات ضمن إطار المستخدم ، وطوال هذا الوقت كنت أقوم بحل مشكلة التصنيف ، أي أنني قمت بتحسين المقياس الخطأ.
سأقدم مثال بسيط:
| حاليا | objectId | تنبؤ | الحقيقة الأرض |
|---|
| 1 | 10 | 0.9 | 1 |
| 1 | 11 | 0.8 | 1 |
| 1 | 12 | 0.7 | 1 |
| 1 | 13 | 0.6 | 1 |
| 1 | 14 | 0.5 | 0 |
| 2 | 15 | 0.4 | 0 |
| 2 | 16 | 0.3 | 1 |
نفعل التقليب صغير
| حاليا | objectId | تنبؤ | الحقيقة الأرض |
|---|
| 1 | 10 | 0.9 | 1 |
| 1 | 11 | 0.8 | 1 |
| 1 | 12 | 0.7 | 1 |
| 1 | 13 | 0.6 | 0 |
| 2 | 16 | 0.5 | 1 |
| 2 | 15 | 0.4 | 0 |
| 1 | 14 | 0.3 | 1 |
نحصل على النتائج التالية:
| نموذج | AUC | User1 AUC | User2 AUC | يعني الجامعة الأمريكية |
|---|
| الخيار 1 | 0.8 | 1.0 | 0.0 | 0.5 |
| الخيار 2 | 0.7 | 0.75 | 1.0 | 0875 |
كما ترون ، لا يعني تحسين قياس AUC الكلي تحسين قياس AUC المتوسط داخل المستخدم.
Catboost يمكنه تحسين مقاييس الترتيب خارج الصندوق. قرأت عن تصنيف المقاييس وقصص النجاح عند استخدام catboost وتعيين YetiRankPairwise على الدراسة ليلاً. النتيجة لم تكن مثيرة للإعجاب. بعد أن قررت أنني لم أتعلم جيدًا ، قمت بتغيير وظيفة الخطأ إلى QueryRMSE ، والتي ، وفقًا لتوثيق catboost ، تتقارب بشكل أسرع. وكنتيجة لذلك ، حصلت على نفس النتائج التي حصلت عليها أثناء التدريب على التصنيف ، لكن مجموعات هذين النموذجين أعطت زيادة جيدة ، مما جعلني في المركز الأول في جميع المسابقات الثلاثة.
قبل 5 دقائق من انتهاء المرحلة على الإنترنت في مسابقة Collaborative Systems ، نقلني سيرجي شالنوف إلى المركز الثاني. مزيد من الطريق ذهبنا معا.
التحضير للمرحلة حاليا
تم ضمان الفوز في المرحلة عبر الإنترنت لنا على بطاقة الفيديو RTX 2080 TI ، لكن الجائزة الرئيسية التي بلغت 300000 روبل ، بل أجبرتنا في المقام الأول على العمل في هذين الأسبوعين.
كما اتضح ، استخدم سيرجي أيضا catboost. تبادلنا الأفكار والميزات ، واكتشفت تقرير آنا فيرونيكا دوروغوش التي كانت توجد فيها إجابات على العديد من أسئلتي ، وحتى على تلك التي لم أكن قد ظهرت بعد.
قادني مشاهدة التقرير إلى فكرة أنه من الضروري إعادة جميع المعلمات إلى القيمة الافتراضية ، وضبط الإعدادات بعناية فائقة وفقط بعد إصلاح مجموعة من العلامات. الآن ، استغرق تدريب واحد حوالي 15 ساعة ، ولكن نجح نموذج واحد في الحصول على السرعة أفضل مما كانت عليه في المجموعة مع الترتيب.
ميزة الجيل
في المسابقة "الأنظمة التعاونية" ، يتم تقييم عدد كبير من الميزات على أنها مهمة للنموذج. على سبيل المثال ، auditweights_spark_svd هي السمة الأكثر أهمية ، ولا توجد معلومات حول معنى ذلك. اعتقدت أنه كان يستحق حساب الوحدات المختلفة بناءً على علامات مهمة. على سبيل المثال ، متوسط auditweights_spark_svd لكل مستخدم ، لكل مجموعة ، لكل كائن. يمكن حساب الشيء نفسه من البيانات التي لم يتم إجراء التدريب والهدف = 1 ، أي متوسط auditweights_spark_svd لكل مستخدم للكائنات التي يحبها. كانت هناك عدة علامات مهمة ، إلى جانب auditweights_spark_svd . هؤلاء بعض منهم:
- auditweightsCtrGender
- auditweightsCtrHigh
- userOwnerCounterCreateLikes
على سبيل المثال ، تبين أن متوسط قيمة auditweightsCtrGender بواسطة userId يعد ميزة مهمة ، وكذلك متوسط قيمة userOwnerCounterCreateLikes بواسطة userId + ownerId. هذا كان يجب أن يجعلنا نفكر في كيفية فهم معنى الحقول.
الميزات الهامة الأخرى كانت auditweightsLikesCount و auditweightsShowsCount . تقسيم واحد إلى آخر ، تم الحصول على ميزة أكثر أهمية.
تسرب البيانات
نماذج المنافسة والإنتاج هي مهام مختلفة للغاية. عند إعداد البيانات ، من الصعب جدًا مراعاة جميع التفاصيل وعدم نقل بعض المعلومات غير البسيطة حول المتغير الهدف في الاختبار. إذا قمنا بإنشاء حل إنتاج ، فسنحاول تجنب استخدام عمليات تسرب البيانات عند تدريب النموذج. ولكن إذا كنا نريد الفوز بالمسابقة ، فإن تسريبات البيانات هي أفضل الميزات.
بعد فحص البيانات ، يمكنك أن ترى أنه وفقًا للكائن ، فإن قيم AuditweightsLikesCount و auditweightsShowsCount تتغير ، مما يعني أن نسبة الحد الأقصى لقيم هذه العلامات سوف تعكس تحويل المشاركة أفضل بكثير من النسبة في وقت التسليم.
أول تسرب وجدنا هو auditweightsLikesCountMax / auditweightsShowsCountMax .
ولكن ماذا لو نظرت إلى البيانات عن كثب؟ الترتيب حسب تاريخ التسليم واحصل على:
| objectId | حاليا | auditweightsShowsCount | auditweightsLikesCount | الهدف (يحب) |
|---|
| 1 | 1 | 12 | 3 | ربما لا |
| 1 | 2 | 15 | 3 | ربما نعم |
| 1 | 3 | 16 | 4 | |
كان من المدهش عندما وجدت أول مثال من هذا القبيل واتضح أن توقعاتي لم تتحقق. ولكن ، بالنظر إلى حقيقة أن القيم القصوى لهذه العلامات داخل إطار الكائن أعطت زيادة ، لم نكن كسولين للغاية وقررنا العثور على auditweightsShowsCountNext و auditweightsLikesCountNext ، أي القيم في اللحظة التالية من الوقت. إضافة ميزة
(auditweightsShowsCountNext-auditweightsShowsCount) / (auditweightsLikesCount-auditweightsLikesCountNext) لقد حققنا قفزة حادة على مدار الساعة.
يمكن استخدام عمليات تسرب مماثلة إذا تم العثور على القيم التالية لـ userOwnerCounterCreateLikes داخل userId + ownerId ، على سبيل المثال ، auditweightsCtrGender داخل objectId + userGender. وجدنا 6 مجالات مماثلة مع تسرب ومعلومات سحبت منها قدر الإمكان.
بحلول ذلك الوقت ، كنا قد ضغطنا كحد أقصى من المعلومات من الصفات التعاونية ، لكننا لم نرجع إلى مسابقات الصور والنصوص. كانت هناك فكرة رائعة للتحقق: ما مقدار الميزات التي تقدمها مباشرة على الصور أو النصوص في المنافسات المقابلة؟
لم تكن هناك أي تسريبات في المسابقات للصور والنصوص ، لكن بحلول ذلك الوقت كنت قد قمت بإرجاع المعلمات الافتراضية ل catboost ، وتمشيط الرمز وإضافة بعض الميزات. النتيجة الإجمالية:
| قرار | سرعة |
|---|
| الحد الأقصى مع الصور | 0.6411 |
| لا توجد صور كحد أقصى | 0.6297 |
| المركز الثاني نتيجة | 0.6295 |
| قرار | سرعة |
|---|
| الحد الأقصى مع النصوص | 0.666 |
| الحد الأقصى دون النصوص | 0.660 |
| المركز الثاني نتيجة | 0656 |
| قرار | سرعة |
|---|
| الحد الأقصى في التعاونية | 0.745 |
| المركز الثاني نتيجة | 0.723 |
أصبح من الواضح أن الكثير من النصوص والصور من غير المرجح أن يتم الضغط عليها ، وبعد تجربة بعض الأفكار الأكثر إثارة للاهتمام ، توقفنا عن العمل معها.
المزيد من الميزات في الأنظمة التعاونية لم يحقق النمو ، وبدأنا الترتيب. في المرحلة عبر الإنترنت ، أعطتني مجموعة التصنيف والتصنيف زيادة بسيطة ، كما اتضح لأن التصنيف غير متدرب. لم تقدم أي من وظائف الخطأ ، بما في ذلك YetiRanlPairwise ، نتائج وثيقة أعطاها LogLoss (0.745 مقابل 0.725). كان هناك أمل في QueryCrossEntropy التي لا يمكن إطلاقها.
مرحلة حاليا
في المرحلة غير المتصلة بالإنترنت ، ظلت بنية البيانات كما هي ، ولكن كانت هناك تغييرات بسيطة:
- معرفات userId ، objectId ، ownerId تم إعادة توزيعهم بشكل عشوائي ؛
- تمت إزالة عدة علامات وتمت إعادة تسمية العديد منها ؛
- أصبحت البيانات حوالي 1.5 مرة أكثر.
بالإضافة إلى الصعوبات المدرجة ، كان هناك ميزة واحدة كبيرة: تم تخصيص خادم كبير مع RTX 2080TI للفريق. لقد استمتعت htop لفترة طويلة.
كانت الفكرة واحدة - فقط لإعادة إنتاج ما هو موجود بالفعل. بعد قضاء بضع ساعات في إعداد البيئة على الخادم ، بدأنا تدريجياً في التحقق من إعادة إنتاج النتائج. المشكلة الرئيسية التي نواجهها هي زيادة حجم البيانات. قررنا تقليل الحمل قليلاً وتعيين المعلمة catboost ctr_complexity = 1. هذا يقلل من السرعة قليلاً ، لكن نموذجي بدأ العمل ، وكانت النتيجة جيدة - 0.733. لم يقم سيرجي ، بخلافي ، بتقسيم البيانات إلى جزأين وتدريبهم على جميع البيانات ، على الرغم من أن هذا أعطى أفضل نتيجة في المرحلة عبر الإنترنت ، كانت هناك الكثير من الصعوبات في مرحلة عدم الاتصال بالإنترنت. إذا أخذنا جميع الميزات التي أنشأناها وحاولنا وضعها في مجموعة صغيرة "على الجبهة" ، فلن يحدث أي شيء على المسرح عبر الإنترنت. فعل سيرجي نوع التحسين ، على سبيل المثال ، تحويل أنواع float64 إلى float32. في هذه المقالة ، يمكنك العثور على معلومات حول تحسين الذاكرة في حيوانات الباندا. نتيجة لذلك ، تدرب سيرجي على وحدة المعالجة المركزية على جميع البيانات واتضح حول 0.735.
كانت هذه النتائج كافية للفوز ، لكننا أخفينا سرعتنا الحقيقية ولم نكن متأكدين من أن الفرق الأخرى لم تفعل نفس الشيء.
المعركة حتى النهاية
ضبط catboost
لقد تم إعادة إنتاج حلولنا بشكل كامل ، وقمنا بإضافة ميزات البيانات النصية والصور ، لذلك كان كل ما تبقى هو ضبط معلمات catboost. درس سيرجي على وحدة المعالجة المركزية مع عدد قليل من التكرارات ، ودرس مع ctr_complexity = 1. لم يتبق سوى يوم واحد فقط ، وإذا أضفت التكرارات أو زادت ctr_complexity ، فيمكنك في الصباح الحصول على سرعة أفضل والمشي طوال اليوم.
في المرحلة غير المتصلة بالإنترنت ، قد يكون من السهل للغاية إخفاء الدرجات ، وذلك ببساطة عن طريق اختيار ليس الحل الأفضل على الموقع. توقعنا تغييرات حادة في المتصدرين في الدقائق الأخيرة قبل إغلاق التقديمات وقررنا عدم التوقف.
من فيديو آنا ، تعلمت أنه من أجل تحسين جودة النموذج ، من الأفضل اختيار المعلمات التالية:
- learning_rate - يتم حساب القيمة الافتراضية بناءً على حجم مجموعة البيانات. مع انخفاض معدل التعلم ، للحفاظ على الجودة ، من الضروري زيادة عدد التكرارات.
- l2_leaf_reg - معامل التنظيم ، القيمة الافتراضية 3 ، ويفضل أن يكون من 2 إلى 30. يؤدي انخفاض القيمة إلى زيادة التجاوز.
- bagging_temperature - يضيف العشوائية إلى أوزان الكائنات في التحديد. القيمة الافتراضية هي 1 ، حيث يتم تحديد الأوزان من التوزيع الأسي. انخفاض في القيمة يؤدي إلى زيادة في الزي.
- random_strength - يؤثر على اختيار الإنشقاقات لتكرار معين. كلما زادت القوة العشوائية ، زادت فرصة اختيار الانقسام ذي الأهمية المنخفضة. في كل تكرار لاحق ، تنخفض العشوائية. انخفاض في القيمة يؤدي إلى زيادة في الزي.
تؤثر المعلمات الأخرى بشكل كبير على النتيجة النهائية ، لذلك لم أحاول تحديدها. استغرق تكرار واحد من التدريب على مجموعة بيانات GPU الخاصة بي باستخدام ctr_complexity = 1 20 دقيقة ، وكانت المعلمات المحددة في مجموعة البيانات المخفضة مختلفة قليلاً عن تلك المثلى على مجموعة البيانات الكاملة. كنتيجة لذلك ، قمت بحوالي 30 تكرارًا على 10٪ من البيانات ، ثم حوالي 10 تكرارات أخرى على جميع البيانات. اتضح ما يلي تقريبا:
- قمت بزيادة التعلم بنسبة 40٪ من القيمة الافتراضية ؛
- l2_leaf_reg ترك نفسه ؛
- bagging_temperature و random_strength مخفضة إلى 0.8.
يمكننا أن نستنتج أنه مع المعلمات الافتراضية ، فإن النموذج غير مدربين تدريباً كاملاً
لقد فوجئت للغاية عندما رأيت النتيجة على المتصدرين:
| نموذج | نموذج 1 | نموذج 2 | نموذج 3 | طاقم |
|---|
| لا ضبط | 0.7403 | 0.7404 | 0.7404 | 0.7407 |
| مع ضبط | 0.7406 | 0.7405 | 0.7406 | 0.7408 |
خلصت لنفسي إلى أنه إذا كنت لا تحتاج إلى تطبيق سريع للنموذج ، فمن الأفضل استبدال مجموعة المعلمات بمجموعة من النماذج المتعددة على معلمات غير محسّنة.
شارك سيرجي في تحسين حجم مجموعة البيانات لتشغيله على وحدة معالجة الرسومات. — , :
- ( ), ;
- ;
- userId, ;
- userId, .
— .
, 0,742. ctr_complexity=2 30 5 . 4 , , 0,7433.
, , . predict(prediction_type='RawFormulaVal') scale_pos_weight=neg_count/pos_count.
.
. , , , 2 .
استنتاج
:
- , target encoding, catboost.
- , , learning_rate iterations. — .
- GPU. Catboost GPU, .
- rsm~=0.2 (CPU only) ctr_complexity=1.
- , . . , , .
- , .
- , .

, .