في هذه المقالة ، أود أن أتحدث عن ميزات صفائف All Flash AccelStor التي تعمل مع واحدة من أكثر أنظمة المحاكاة الافتراضية شيوعًا - VMware vSphere. على وجه الخصوص ، للتركيز على تلك المعلمات التي ستساعد في الحصول على أقصى تأثير من استخدام أداة قوية مثل All Flash.
تعد جميع صفائف Flash AccelStor NeoSapphire ™ واحدة أو اثنتين من أجهزة العقدة تعتمد على محركات أقراص الحالة الثابتة مع اتباع نهج مختلف اختلافًا جوهريًا في تطبيق مفهوم تخزين البيانات وتنظيم الوصول إليها باستخدام تقنية FlexiRemap® الخاصة بها بدلاً من خوارزميات RAID الشائعة جدًا. توفر المصفوفات وصول كتلة للمضيفين من خلال واجهات القناة الليفية أو iSCSI. في الإنصاف ، نلاحظ أن الطرز المزودة بواجهة ISCSI تتمتع أيضًا بوصول إلى الملفات كمكافأة لطيفة. ولكن في هذه المقالة ، سوف نركز على استخدام بروتوكولات الكتلة باعتبارها الأكثر إنتاجية لـ All Flash.
يمكن تقسيم العملية بأكملها للنشر ثم إعداد التعاون بين صفيف AccelStor ونظام المحاكاة الافتراضية VMware vSphere إلى عدة مراحل:
- تنفيذ طوبولوجيا الاتصال وتكوين شبكة SAN ؛
- إعداد جميع مجموعة فلاش.
- تكوين المضيفين ESXi.
- تكوين الأجهزة الافتراضية.
تم استخدام صفائف AccelStor NeoSapphire ™ مع قناة ليفية و iSCSI كأمثلة للمعدات. البرنامج الأساسي هو برنامج VMware vSphere 6.7U1.
قبل نشر الأنظمة الموضحة في هذه المقالة ، يوصى بشدة أن تتعرف على الوثائق من VMware فيما يتعلق بمشكلات الأداء ( أفضل ممارسات الأداء لـ VMware vSphere 6.7 ) وإعدادات iSCSI ( أفضل الممارسات لتشغيل VMware vSphere On iSCSI )
طوبولوجيا الاتصال وتكوين SAN
المكونات الرئيسية لشبكة SAN هي HBAs على مضيفات ESXi ، ومفاتيح SAN ، وعقد الصفيف. تبدو البنية النموذجية لهذه الشبكة كما يلي:
يشير المصطلح Switch هنا إلى رمز تبديل فعلي واحد أو مجموعة مفاتيح (Fabric) أو جهاز مشترك بين خدمات مختلفة (VSAN في حالة Fiber Channel و VLAN في حالة iSCSI). باستخدام مفتاحين مستقلين / نسيج يلغي نقطة الفشل المحتملة.
لا يتم تشجيع الاتصال المباشر للمضيفين بالصفيف ، على الرغم من أنه مدعوم ، بشكل كبير. أداء جميع صفائف فلاش عالية جدا. وللحصول على أقصى سرعة ، تحتاج إلى استخدام جميع منافذ الصفيف. لذلك ، يلزم وجود مفتاح واحد على الأقل بين المضيفين و NeoSapphire ™.
يعد وجود منفذين على مضيف HBA شرطًا أساسيًا لتحقيق أقصى درجات الأداء والتسامح مع الأعطال.
إذا كنت تستخدم واجهة القناة الليفية ، فأنت بحاجة إلى تكوين تقسيم المناطق لتجنب التعارضات المحتملة بين المبادرين والأهداف. المناطق مبنية على مبدأ "منفذ بادئ واحد - منفذ صفيف واحد أو أكثر".
إذا كنت تستخدم اتصال iSCSI إذا كنت تستخدم مفتاحًا مشتركًا مع خدمات أخرى ، فعليك عزل حركة مرور iSCSI داخل شبكة محلية ظاهرية منفصلة. يوصى بشدة بتمكين دعم Jumbo Frames (MTU = 9000) لزيادة حجم الحزم على الشبكة وبالتالي تقليل مقدار الحمل أثناء الإرسال. ومع ذلك ، تجدر الإشارة إلى أنه من أجل التشغيل الصحيح ، يلزم تغيير معلمة وحدة الإرسال الكبرى على جميع مكونات الشبكة على طول سلسلة الهدف بادئ التبديل.
إعداد جميع صفائف الفلاش
يتم تسليم المجموعة للعملاء مع مجموعات FlexiRemap® المشكلة بالفعل. لذلك ، لا يلزم اتخاذ أي إجراء لدمج محركات الأقراص في بنية واحدة. يكفي إنشاء وحدات تخزين بالحجم المطلوب وبالكمية المطلوبة.
للراحة ، هناك وظيفة لإنشاء مجموعة من عدة مجلدات من وحدة تخزين معينة في وقت واحد. يتم إنشاء وحدات التخزين "الرقيقة" افتراضيًا ، حيث يتيح ذلك استخدامًا أكثر منطقية لمساحة التخزين المتاحة (بما في ذلك بفضل دعم Space Reclamation). من حيث الأداء ، لا يتجاوز الفرق بين الأحجام الرفيعة والسميكة 1٪. ومع ذلك ، إذا كنت ترغب في "الضغط على جميع العصائر" من المصفوفة ، يمكنك دائمًا تحويل أي حجم "رفيع" إلى "كثيف". ولكن يجب أن نتذكر أن مثل هذه العملية لا رجعة فيها.
ثم يبقى "نشر" وحدات التخزين التي تم إنشاؤها وتعيين حقوق الوصول إليها من المضيفين باستخدام ACL (عناوين IP لـ iSCSI و WWPN for FC) والفصل الفعلي للمنافذ على الصفيف. بالنسبة لنماذج iSCSI ، يتم ذلك من خلال إنشاء Target.
بالنسبة إلى طرز FC ، يحدث النشر من خلال إنشاء LUN لكل منفذ في الصفيف.
لتسريع عملية التكوين ، يمكن تجميع المضيفين. علاوة على ذلك ، إذا كان المضيف يستخدم FC HBA متعدد المنافذ (والذي يحدث غالبًا في الممارسة العملية) ، يحدد النظام تلقائيًا أن منافذ HBA تنتمي إلى مضيف واحد بسبب WWPN ، والتي تختلف بواحد. أيضا ، يتم إنشاء إنشاء دفعة من الهدف / LUN لكلا الواجهات.
تتمثل إحدى النقاط المهمة عند استخدام واجهة iSCSI في إنشاء أهداف متعددة لوحدات التخزين في وقت واحد لزيادة الأداء ، نظرًا لأنه لا يمكن تغيير قائمة الانتظار المستهدفة ، وستكون بالفعل عنق الزجاجة.
تكوين المضيفين ESXi
على الجانب ESXi ، يتم التكوين الأساسي وفقًا للسيناريو المتوقع تمامًا. إجراء اتصال iSCSI:
- إضافة برنامج iSCSI Adapter (غير مطلوب إذا تمت إضافته بالفعل ، أو إذا كان يستخدم Hardware iSCSI Adapter) ؛
- إنشاء vSwitch ، والتي ستذهب من خلالها حركة مرور iSCSI ، وإضافة وصلة فعلية و VMkernal إليها ؛
- إضافة عناوين مجموعة إلى اكتشاف ديناميكي ؛
- إنشاء مخزن البيانات
بعض الملاحظات المهمة:
- في الحالة العامة ، بالطبع ، يمكنك استخدام vSwitch الحالي ، ولكن في حالة وجود vSwitch منفصل ، ستكون إدارة إعدادات المضيف أسهل بكثير.
- من الضروري فصل حركة مرور الإدارة و iSCSI إلى روابط فعلية منفصلة و / أو شبكات محلية ظاهرية لتفادي مشاكل الأداء.
- يجب أن تكون عناوين IP الخاصة بـ VMkernal والمنافذ المقابلة لصفيف All Flash على نفس الشبكة الفرعية ، مرة أخرى بسبب مشكلات في الأداء.
- لضمان التسامح مع الخطأ VMware ، يجب أن يكون vSwitch اثنين على الأقل من الصعود المادي
- إذا كنت تستخدم Jumbo Frames ، فيجب عليك تغيير MTU لكل من vSwitch و VMkernal
- لن يكون من الخطأ التذكير أنه وفقًا لتوصيات VMware الخاصة بالمحولات المادية التي سيتم استخدامها للعمل مع حركة مرور iSCSI ، من الضروري تكوين Teaming و Failover. على وجه الخصوص ، يجب أن يعمل كل VMkernal فقط من خلال وصلة صاعدة واحدة ، ويجب تحويل الوصلة الصاعدة الثانية إلى الوضع غير المستخدم. من أجل التسامح مع الخطأ ، تحتاج إلى إضافة جهازي VMkernal ، يعمل كل منهما عبر الوصلة الصاعدة.
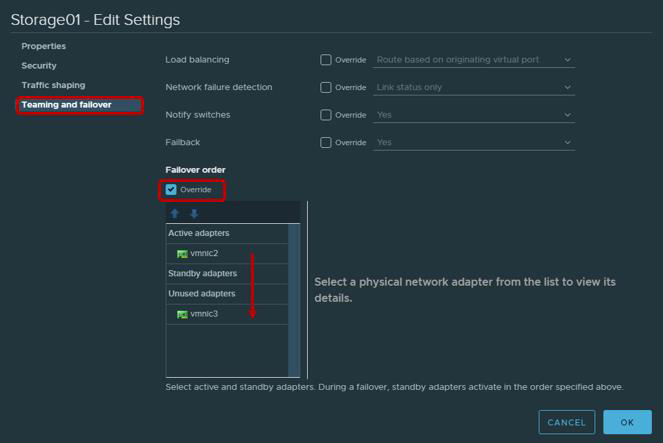
| محول VMkernel (vmk #) | محول الشبكة الفعلي (vmnic #) |
|---|
| vmk1 (Storage01) | محولات نشطة
vmnic2
محولات غير المستخدمة
vmnic3
|
| vmk2 (Storage02) | محولات نشطة
vmnic3
محولات غير المستخدمة
vmnic2
|
لا يوجد اتصال القناة الليفية المطلوبة. يمكنك على الفور إنشاء مخزن بيانات.
بعد إنشاء Datastore ، تحتاج إلى التأكد من استخدام سياسة Round Robin للمسارات إلى Target / LUN باعتبارها الأكثر إنتاجية.
بشكل افتراضي ، تنص إعدادات VMware على استخدام هذه السياسة وفقًا للمخطط: 1000 طلب خلال المسار الأول ، 1000 طلب خلال المسار الثاني ، إلخ. سيكون تفاعل المضيف هذا مع صفيف تحكم مزدوج غير متوازن. لذلك ، نوصي بتعيين سياسة Round Robin = معلمة واحدة من خلال Esxcli / PowerCLI.
المعلماتل Esxcli:
تخزين الجهاز esxcli قائمة الجهاز
- نسخ اسم الجهاز
- تغيير جولة روبن السياسة
esxcli storage nmp psp roundrobin deviceconfig set - النوع = iops - iops = 1 --device = "Device_ID"
تم تصميم معظم التطبيقات الحديثة لتبادل حزم البيانات الكبيرة من أجل زيادة استخدام عرض النطاق الترددي وتقليل تحميل وحدة المعالجة المركزية. لذلك ، ESXi بشكل افتراضي ينقل طلبات الإدخال / الإخراج إلى جهاز التخزين على دفعات تصل إلى 32767 كيلو بايت. ومع ذلك ، بالنسبة لعدد من السيناريوهات ، فإن تبادل الأجزاء الأصغر سيكون أكثر إنتاجية. بالنسبة لصفائف AccelStor ، هذه هي السيناريوهات التالية:
- يستخدم الجهاز الظاهري UEFI بدلاً من BIOS القديمة
- المستخدمة من قبل vSphere النسخ المتماثل
بالنسبة لمثل هذه السيناريوهات ، يوصى بتغيير قيمة المعلمة Disk.DiskMaxIOSize إلى 4096.
بالنسبة لاتصالات iSCSI ، يوصى بتغيير معلمة "مهلة تسجيل الدخول" إلى 30 (الافتراضي 5) لزيادة ثبات الاتصال وإيقاف تأخير إقرار حزم DelayedAck المعاد توجيهها. كلا الخيارين موجودان في برنامج vSphere Client: المضيف → تهيئة → التخزين ← محولات التخزين ← الخيارات المتقدمة لمحول iSCSI
نقطة خفية إلى حد ما هو عدد وحدات التخزين المستخدمة لمخزن البيانات. من الواضح أنه لسهولة الإدارة ، هناك رغبة في إنشاء وحدة تخزين واحدة كبيرة لكامل حجم المجموعة. ومع ذلك ، فإن وجود عدة مجلدات ، وبناءً على ذلك ، يكون لمخزن البيانات تأثير مفيد على الأداء الكلي (المزيد في قوائم الانتظار لاحقًا في النص). لذلك ، نوصي بإنشاء مجلدين على الأقل.
في الآونة الأخيرة ، نصحت VMware بالحد من عدد الأجهزة الظاهرية في مخزن بيانات واحد ، مرة أخرى من أجل الحصول على أفضل أداء ممكن. ومع ذلك ، الآن ، لا سيما مع انتشار VDI ، هذه المشكلة لم تعد حادة. لكن هذا لا يلغي القاعدة الطويلة الأمد - لتوزيع الأجهزة الافتراضية التي تتطلب IO مكثفة على مخزن بيانات مختلف. لا يوجد شيء أفضل لتحديد العدد الأمثل للأجهزة الافتراضية لكل وحدة تخزين من تحميل مجموعة AccelStor's All Flash للاختبار داخل بنيتها التحتية.
تكوين الأجهزة الافتراضية
لا توجد متطلبات خاصة عند إعداد الأجهزة الافتراضية ، أو بالأحرى ، فهي عادية تمامًا:
- باستخدام أعلى إصدار ممكن من VM (التوافق)
- يعد ضبط حجم ذاكرة الوصول العشوائي أكثر دقة عندما يتم وضع الأجهزة الظاهرية بكثافة ، على سبيل المثال ، في VDI (لأنه بشكل افتراضي ، عند بدء التشغيل ، يتم إنشاء ملف ترحيل صفحات مماثل لحجم ذاكرة الوصول العشوائي ، والذي يستهلك سعة مفيدة وله تأثير على الأداء النهائي)
- استخدم أكثر إصدارات محولات IO كفاءة: نوع الشبكة VMXNET 3 و SCSI نوع PVSCSI
- استخدم نوع محرك Thick Provision Eager Zeroed للحصول على أقصى أداء وأداء رفيع لتوفير أقصى استخدام للتخزين
- إن أمكن ، قم بتقييد عمل أجهزة الإدخال / الإخراج غير الحرجة باستخدام حد القرص الظاهري
- تأكد من تثبيت أدوات VMware
قائمة انتظار الملاحظات
قائمة الانتظار (أو الإدخال / الإخراج المتميز) هي رقم طلبات الإدخال / الإخراج (أوامر SCSI) التي تنتظر المعالجة في أي وقت محدد من جهاز / تطبيق معين. في حالة تجاوز سعة قائمة انتظار ، يتم إنشاء أخطاء QFULL ، مما يؤدي في النهاية إلى زيادة في المعلمة زمن الوصول. عند استخدام أنظمة تخزين القرص (المغزل) ، من الناحية النظرية ، كلما كانت قائمة الانتظار أعلى ، كلما كان الأداء أعلى. ومع ذلك ، يجب عدم إساءة استخدامه ، لأنه من السهل الركض إلى QFULL. في حالة جميع أنظمة Flash ، من ناحية ، كل شيء أبسط إلى حد ما: يؤدي المصفوفة إلى تأخير عدة أوامر من حيث الحجم وبالتالي لا يلزم في الغالب ضبط حجم قوائم الانتظار بشكل منفصل. ولكن من ناحية أخرى ، في بعض حالات الاستخدام (وجود تحيز قوي في متطلبات IO لأجهزة افتراضية محددة ، واختبارات لأداء أقصى ، إلخ) ، إذا لم تقم بتغيير معلمات قائمة الانتظار ، ففهم على الأقل ما هي المؤشرات التي يمكن تحقيقها ، و الأهم من ذلك ، ما هي الطرق.
لا توجد قيود على وحدات التخزين أو منافذ الإدخال / الإخراج في AccelStor All Flash Array نفسها. إذا لزم الأمر ، حتى وحدة تخزين واحدة يمكنها الحصول على جميع موارد المصفوفة. تقييد قائمة الانتظار الوحيد هو مع أهداف iSCSI. ولهذا السبب تم توضيح الحاجة إلى إنشاء عدة أهداف (من الناحية المثالية تصل إلى 8 قطع) لكل مجلد للتغلب على هذا الحد أعلاه. أيضا ، صفائف AccelStor هي حلول مثمرة للغاية. لذلك ، يجب عليك استخدام جميع منافذ واجهة النظام لتحقيق أقصى سرعة.
على الجانب ESXi من المضيف ، الوضع مختلف تمامًا. يطبق المضيف نفسه ممارسة المساواة في الوصول إلى الموارد لجميع المشاركين. لذلك ، هناك قوائم انتظار IO منفصلة لنظام التشغيل الضيف و HBA. يتم دمج قوائم الانتظار إلى نظام التشغيل الضيف من قوائم الانتظار إلى محول SCSI الظاهري والقرص الظاهري:
تعتمد قائمة انتظار HBA على النوع / البائع المحدد:
سيتم تحديد الأداء النهائي للجهاز الظاهري من خلال الحد الأدنى لعمق قائمة الانتظار بين مكونات المضيف.
بفضل هذه القيم ، يمكنك تقييم مؤشرات الأداء التي يمكننا الحصول عليها في تكوين واحد أو آخر. على سبيل المثال ، نريد أن نعرف الأداء النظري لجهاز ظاهري (دون الربط إلى كتلة) مع 0.5ms زمن الوصول. ثم IOPS = (1،000 / زمن انتقال) * I / Os المتميز (حد عمق قائمة الانتظار)
أمثلةمثال 1
- FC Emulex HBA محول
- واحد VM على مخزن البيانات
- برنامج VMware Paravirtual SCSI Adapter
هنا يتم تحديد حد عمق قائمة الانتظار بواسطة Emulex HBA. لذلك ، IOPS = (1000 / 0.5) * 32 = 64 كيلو بايت
مثال 2
- برنامج VMware iSCSI محول البرمجيات
- واحد VM على مخزن البيانات
- برنامج VMware Paravirtual SCSI Adapter
هنا يتم تعريف حد عمق قائمة الانتظار بالفعل بواسطة محول SCSI Paravirtual. لذلك ، IOPS = (1000 / 0.5) * 64 = 128 كيلو بايت
أعلى صفيفات جميع AccelStor All Flash (مثل P710 ) قادرة على تقديم أداء IOPS 700K للتسجيل في كتلة 4K. مع حجم الكتلة هذا ، من الواضح أن جهازًا ظاهريًا واحدًا غير قادر على تحميل هذا الصفيف. للقيام بذلك ، ستحتاج إلى 11 (على سبيل المثال 1) أو 6 (على سبيل المثال 2) أجهزة افتراضية.
نتيجة لذلك ، مع التكوين الصحيح لجميع المكونات الموصوفة في مركز البيانات الافتراضي ، يمكنك الحصول على نتائج رائعة للغاية من حيث الأداء.
4K عشوائية ، قراءة 70 ٪ / 30 ٪ الكتابة
في الواقع ، يصعب وصف العالم الحقيقي بصيغة بسيطة. يحتوي المضيف الفردي دائمًا على العديد من الأجهزة الافتراضية ذات التكوينات المختلفة ومتطلبات الإدخال / الإخراج. نعم ، والمعالج المضيف ، الذي لا تتعدى طاقته ، يشارك في معالجة I / O. لذلك ، لإطلاق الإمكانات الكاملة للنموذج نفسه ، سيحتاج هاتف P710 في الواقع إلى ثلاثة مضيفين. بالإضافة إلى ذلك ، تقوم التطبيقات التي تعمل داخل الأجهزة الافتراضية بإجراء التعديلات. لذلك ، من أجل التحجيم الدقيق ، نقترح استخدام اختبار في حالة نماذج الاختبار الخاصة بمصفوفات All Flash AccelStor داخل بنية العميل الأساسية للمهام الحالية الواقعية.