
في 28 فبراير ، قدمت عرضًا تقديميًا في SphinxSearch-meetup ، والذي عقد في مكتبنا. تحدث عن الطريقة التي أتينا بها من إعادة البناء الدورية للفهارس للبحث عن النص الكامل وإرسال التحديثات في الكود "في مكانه" إلى فهارس وقت السكك الحديدية والمزامنة التلقائية لحالة الفهرس وقاعدة بيانات MariaDB. يتوفر تسجيل فيديو لتقريري عبر الرابط ، وبالنسبة لأولئك الذين يفضلون القراءة لمشاهدة الفيديو ، كتبت هذا المقال.
سأبدأ بكيفية ترتيب بحثنا ، ولماذا بدأنا كل هذا.
تم تنظيم بحثنا وفقًا لمعايير قياسية تمامًا.
من الواجهة الأمامية ، تأتي طلبات المستخدمين إلى خادم التطبيق المكتوب بلغة PHP ، وهو بدوره يتصل بقاعدة البيانات (لدينا MariaDB). إذا احتجنا إلى إجراء بحث ، يتحول خادم التطبيق إلى الموازن (لدينا haproxy) ، الذي يربطه بأحد الخوادم التي يتم تشغيل searchd فيها ، ويقوم ذلك الخادم بالفعل بإجراء بحث وإرجاع النتيجة.
تقع البيانات من قاعدة البيانات في الفهرس بطريقة تقليدية تمامًا: وفقًا للجدول الزمني ، نقوم بإعادة إنشاء الفهرس كل بضع دقائق باستخدام تلك المستندات التي تم تحديثها مؤخرًا نسبيًا ، وإعادة إنشاء الفهرس باستخدام ما يسمى بالوثائق "المؤرشفة" (أي ، تلك التي لفترة طويلة لم يحدث شيء). هناك جهازان مخصصان للفهرسة ، يتم تشغيل برنامج نصي هناك وفق جدول زمني ، يقوم أولاً ببناء الفهرس ، ثم يعيد تسمية ملفات الفهرس بطريقة خاصة ، ثم يضعه في مجلد منفصل. وعلى كل من الخوادم ذات searchd ، يتم بدء تشغيل rsync مرة واحدة في الدقيقة ، والتي من هذا المجلد تقوم بنسخ الملفات إلى مجلد فهارس searchd ، ومن ثم ، إذا تم نسخ شيء ما ، يتم تنفيذ طلب RELOAD INDEX.
ومع ذلك ، بالنسبة لبعض التغييرات في السير الذاتية والوظائف الشاغرة ، كان مطلوبًا "الوصول" إلى المؤشر في أسرع وقت ممكن. على سبيل المثال ، إذا تمت إزالة وظيفة شاغرة تم نشرها في المجال العام من النشر ، فمن المعقول أن نتوقع من وجهة نظر المستخدم أنه سيختفي من المشكلة في غضون ثوانٍ معدودة ، لا أكثر. لذلك ، يتم إرسال هذه الأنواع من التغييرات مباشرةً عبر searchd باستخدام استعلامات UPDATE. ولكي يتم تطبيق هذه التغييرات على جميع نسخ الفهارس على جميع خوادمنا ، يتم إعداد فهرس موزع على كل searchd ، والذي يرسل تحديثات للسمات إلى جميع مثيلات searchd. لا يزال خادم التطبيق يتصل بالموازن ويرسل طلبًا واحدًا لتحديث الفهرس الموزع ؛ وبالتالي ، فهو لا يحتاج إلى معرفة مقدمًا إما قائمة الخوادم ذات searchd ، ولن يتمكن من الوصول إلى أي خادم مع searchd بالضبط.
كل هذا يعمل بشكل جيد ، ولكن كانت هناك مشاكل.
- كان متوسط التأخير بين إنشاء المستند (لدينا هذه السيرة الذاتية أو الوظيفة الشاغرة) وإدخالها في الفهرس متناسبًا بشكل مباشر مع عددها في قاعدة بياناتنا.
- نظرًا لأننا استخدمنا الفهرس الموزع لتوزيع تحديثات السمات ، فليس لدينا ما يضمن تطبيق هذه التحديثات على جميع نسخ الفهرس.
- تم فقدان التغييرات "العاجلة" التي حدثت أثناء إعادة إنشاء الفهرس عند تنفيذ أمر
RELOAD INDEX (لمجرد أنها لم تكن بعد في الفهرس الذي تم إنشاؤه حديثًا) ، ولم يتم إدخالها إلا في الفهرس بعد إعادة الفهرسة التالية. 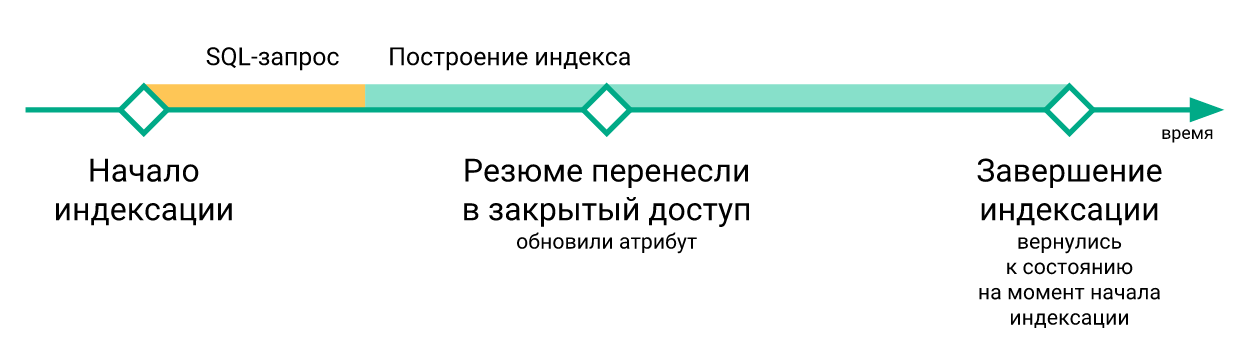
- تم تنفيذ البرامج النصية لتحديث الفهارس على الخوادم مع searchd بشكل مستقل عن بعضها البعض ، لم يكن هناك التزامن بينهما. لهذا السبب ، قد يصل التأخير بين تحديث الفهرس على خوادم مختلفة إلى عدة دقائق.
- إذا كان من الضروري اختبار شيء متعلق بالبحث ، فكان مطلوبًا إعادة إنشاء الفهرس بعد كل تغيير.
لم تكن كل واحدة من هذه المشكلات على حدة تستحق إعادة صياغة أساسية للبنية الأساسية للبحث ، ولكنها مجتمعة كانت تفسد إلى حد كبير الحياة.
قررنا التعامل مع المشكلات المذكورة أعلاه باستخدام فهارس Sphinx الفعلية. علاوة على ذلك ، لم يكن الانتقال إلى مؤشرات RT كافياً بالنسبة لنا. من أجل التخلص أخيرًا من أي سباقات بيانات ، كان من الضروري التأكد من أن جميع التحديثات من التطبيق إلى الفهرس مرت بنفس القناة. بالإضافة إلى ذلك ، كان من الضروري حفظ التغييرات التي تم إجراؤها على قاعدة البيانات في مكان ما أثناء إعادة إنشاء الفهرس (لأنه بعد كل شيء ، يتعين عليك في بعض الأحيان إعادة بنائه ، لكن الإجراء غير فوري).
لقد قررنا إجراء الاتصال باستخدام بروتوكول النسخ المتماثل MySQL مثل قناة نقل البيانات ، ويعتبر MySQL binlog هو المكان المناسب لحفظ التغييرات أثناء إعادة بناء الفهرس. هذا الحل سمح لنا بالتخلص من الكتابة إلى Sphinx من رمز التطبيق. ونظرًا لأننا استخدمنا بالفعل النسخ المتماثل المستند إلى الصف بمعرف معاملة عالمي بحلول ذلك الوقت ، فيمكن إجراء التبديل بين النسخ المتماثلة لقاعدة البيانات بكل بساطة.
فكرة الاتصال مباشرة بقاعدة البيانات من أجل الحصول على تغييرات من هناك لإرسالها إلى الفهرس ، بالطبع ، ليست جديدة: في عام 2016 ، قدم الزملاء من Avito عرضًا تقديميًا حيث وصفوا بالتفصيل كيف قاموا بحل مشكلة مزامنة البيانات في Sphinx مع قاعدة البيانات الرئيسية. قررنا استخدام خبراتهم وعمل نظام مماثل لأنفسنا ، مع اختلاف أننا لم نستخدم PostgreSQL ، ولكن MariaDB ، وفرع Sphinx القديم (أي الإصدار 2.3.2).
لقد أنشأنا خدمة تشترك في التغييرات في MariaDB وتحديث الفهرس في Sphinx. مسؤولياته هي كما يلي:
- الاتصال بخادم MariaDB عبر بروتوكول النسخ المتماثل واستقبال الأحداث من binlog ؛
- تتبع موقع binlog الحالي وعدد آخر صفقة مكتملة ؛
- تصفية الأحداث binlog.
- معرفة المستندات التي يجب إضافتها أو حذفها أو تحديثها في الفهرس ، وكذلك المستندات التي يجب تحديثها ؛
- طلب البيانات المفقودة من MariaDB ؛
- إنشاء وتنفيذ طلبات تحديث الفهرس ؛
- إعادة بناء الفهرس إذا لزم الأمر.
قمنا بإجراء اتصال باستخدام بروتوكول النسخ المتماثل باستخدام مكتبة go-mysql . وهي مسؤولة عن تأسيس اتصال مع MariaDB ، وقراءة أحداث النسخ المتماثل ، ونقلها إلى معالج. يبدأ هذا المعالج في goroutine ، التي تتحكم فيها المكتبة ، لكننا نكتب رمز المعالج بأنفسنا. في رمز المعالج ، يتم التحقق من الأحداث من خلال قائمة الجداول التي تهمنا ، ويتم إرسال التغييرات على هذه الجداول للمعالجة. يقوم معالجنا أيضًا بتخزين حالة المعاملة. هذا يرجع إلى حقيقة أن الأحداث في بروتوكول النسخ المتماثل هي بالترتيب: GTID (بداية المعاملة) -> ROW (تغيير البيانات) -> XID (نهاية المعاملة) ، وأولها فقط يحتوي على معلومات حول رقم المعاملة. من الأسهل بالنسبة لنا نقل رقم المعاملة مع اكتماله من أجل حفظ معلومات حول أي موضع في binlog تم تطبيق التغييرات عليه ، ولهذا علينا أن نتذكر عدد المعاملة الحالية بين بدايتها وإتمامها.
MySQL [(none)]> describe sync_state; +-----------------+--------+ | Field | Type | +-----------------+--------+ | id | bigint | | dummy_field | field | | binlog_position | uint | | binlog_name | string | | gtid | string | | flavor | string | +-----------------+--------+
نقوم بحفظ عدد آخر معاملة مكتملة في فهرس خاص من مستند واحد على كل خادم باستخدام searchd. في بداية الخدمة ، نتحقق من تهيئة الفهارس ولديها الهيكل المتوقع ، بالإضافة إلى أن الموضع المحفوظ على جميع الخوادم موجود وعلى كل الخوادم. بعد ذلك ، إذا كانت هذه الاختبارات ناجحة وتمكنا من بدء قراءة binlog من الموضع المحفوظ ، سنبدأ إجراء المزامنة. إذا فشلت عمليات التحقق ، أو لم يكن من الممكن البدء في قراءة binlog من الموضع المحفوظ ، فسنقوم بإعادة تعيين الموضع المحفوظ إلى الموضع الحالي لخادم MariaDB وإعادة إنشاء الفهرس.
تبدأ معالجة أحداث النسخ المتماثل بتحديد المستندات التي تتأثر بتغيير معين في قاعدة البيانات. للقيام بذلك ، في تهيئة خدمتنا ، فعلنا شيئًا مثل التوجيه لأحداث تغيير الصف في الجداول التي تهمنا ، وهي مجموعة من القواعد لتحديد كيفية فهرسة التغييرات في قاعدة البيانات.
[[ingest]] table = "vacancy" id_field = "id" index = "vacancy" [ingest.column_map] user_id = ["user_id"] edited_at = ["date_edited"] profession = ["profession"] latitude = ["latitude_deg", "latitude_rad"] longitude = ["longitude_deg", "longitude_rad"] [[ingest]] table = "vacancy_language" id_field = "vacancy_id" index = "vacancy" [ingest.column_map] language_id = ["languages"] level = ["languages"] [[ingest]] table = "vacancy_metro_station" id_field = "vacancy_id" index = "vacancy" [ingest.column_map] metro_station_id = ["metro"]
على سبيل المثال ، مع هذه المجموعة من القواعد ، يجب أن تكون vacancy_metro_station vacancy و vacancy و vacancy_metro_station في فهرس vacancy . يمكن أخذ رقم المستند في حقل id لجدول vacancy ، وفي الحقل vacancy_id الآخرين. column_map الحقل column_map جدولًا لاعتماد حقول الفهرس على حقول جداول قاعدة البيانات المختلفة.
علاوة على ذلك ، عندما تلقينا قائمة المستندات المتأثرة بالتغييرات ، نحتاج إلى تحديثها في الفهرس ، لكننا لا نفعل ذلك على الفور. أولاً ، نقوم بتجميع التغييرات لكل مستند ، وإرسال التغييرات إلى الفهرس بمجرد مرور وقت قصير (لدينا 100 ميلي ثانية) من التغيير الأخير في هذا المستند.
قررنا القيام بذلك من أجل تجنب العديد من تحديثات الفهرس غير الضرورية ، لأنه في كثير من الحالات يحدث تغيير منطقي واحد للمستند بمساعدة عدة استعلامات SQL تؤثر على جداول مختلفة ، ويتم تنفيذها في بعض الأحيان في معاملات مختلفة تمامًا.
سأقدم مثال بسيط. لنفترض أن أحد المستخدمين قام بتحرير وظيفة شاغرة. غالبًا ما تتم كتابة التعليمات البرمجية المسؤولة عن حفظ التغييرات من أجل البساطة بهذه الطريقة تقريبًا:
BEGIN; UPDATE vacancy SET edited_at = NOW() WHERE id = 123; DELETE FROM vacancy_language WHERE vacancy_id = 123; INSERT INTO vacancy_language (vacancy_id, language_id, level) VALUES (123, 1, "fluent"), (123, 2, "technical"); DELETE FROM vacancy_metro_station WHERE vacancy_id = 123; INSERT INTO vacancy_metro_station (vacancy_id, metro_station_id) VALUES (123, 55); ... COMMIT;
بمعنى آخر ، أولاً يتم حذف جميع السجلات القديمة من الجداول المرتبطة ، ثم يتم إدراج سجلات جديدة. في الوقت نفسه ، سيظل هناك إدخالات في binlog حول عمليات الحذف والإدراج هذه ، حتى لو لم يتغير شيء في المستند.
من أجل تحديث ما هو مطلوب فقط ، قمنا بما يلي: فرز الأسطر التي تم تغييرها بحيث يمكن استرداد كل التغييرات في ترتيب زمني لكل زوج من الفهرس. بعد ذلك ، يمكننا تطبيقها بدورها لتحديد الحقول التي تغيرت فيها الجداول والتي لا تتغير ، وبعد ذلك يمكننا استخدام جدول column_map للحصول على قائمة الحقول وخصائص الفهرس التي يجب تحديثها لكل وثيقة متأثرة. علاوة على ذلك ، قد لا تصل الأحداث المتعلقة بوثيقة واحدة تلو الأخرى ، ولكن كما لو كانت "مختلفة" إذا تم تنفيذها في معاملات مختلفة. ولكن ، بشأن قدرتنا على تحديد المستندات التي تغيرت ، فإن هذا لن يؤثر.
في نفس الوقت ، سمح لنا هذا النهج بتحديث سمات الفهرس فقط ، إذا لم تكن هناك تغييرات في حقول النص ، بالإضافة إلى الجمع بين إرسال التغييرات إلى Sphinx.
لذلك ، يمكننا الآن معرفة المستندات التي تحتاج إلى تحديث في الفهرس.
في كثير من الحالات ، لا تكفي البيانات من binlog لإنشاء طلب لتحديث الفهرس ، لذلك نحصل على البيانات المفقودة من نفس الخادم من حيث نقرأ binlog. لهذا ، هناك نموذج طلب لاستلام البيانات في تهيئة خدمتنا.
[data_source.vacancy] # # - id parts = 4 query = """ SELECT vacancy.id AS `:id`, vacancy.profession AS `profession_text:field`, GROUP_CONCAT(DISTINCT vacancy_language.language_id) AS `languages:attr_multi`, GROUP_CONCAT(DISTINCT vacancy_metro_station.metro_station_id) AS `metro:attr_multi` FROM vacancy LEFT JOIN vacancy_language ON vacancy_language.vacancy_id = vacancy.id LEFT JOIN vacancy_metro_station ON vacancy_metro_station.vacancy_id = vacancy.id GROUP BY vacancy.id """
في هذا القالب ، يتم تمييز جميع الحقول بأسماء مستعارة خاصة: [___]:___ .
يتم استخدامه في تكوين طلب لتلقي البيانات المفقودة وفي بناء الفهرس (المزيد حول هذا لاحقًا).
نحن نشكل طلبًا من هذا النوع:
SELECT vacancy.id AS `id`, vacancy.profession AS `profession_text`, GROUP_CONCAT(DISTINCT vacancy_language.language_id) AS `languages`, GROUP_CONCAT(DISTINCT vacancy_metro_station.metro_station_id) AS `metro` FROM vacancy LEFT JOIN vacancy_language ON vacancy_language.vacancy_id = vacancy.id LEFT JOIN vacancy_metro_station ON vacancy_metro_station.vacancy_id = vacancy.id WHERE vacancy.id IN (< id , >) GROUP BY vacancy.id
ثم لكل مستند نتحقق مما إذا كان نتيجة لهذا الطلب. إذا لم يكن الأمر كذلك ، فهذا يعني أنه تم حذفه من الجدول الرئيسي ، وبالتالي يمكن أيضًا حذفه من الفهرس (نقوم بتنفيذ استعلام DELETE لهذا المستند). إذا كان الأمر كذلك ، فراجع إذا ما كنا بحاجة إلى تحديث حقول النص لهذا المستند. إذا لم تكن هناك حاجة إلى تحديث الحقول النصية ، فإننا نقوم بإجراء استعلام UPDATE لهذا المستند ، وإلا REPLACE .
تجدر الإشارة إلى أن منطق الحفاظ على الموضع الذي يمكنك من خلاله البدء في قراءة binlog في حالة الإخفاقات يجب أن يكون معقدًا ، لأن الموقف الآن ممكن حيث لا نطبق جميع التغييرات التي تمت قراءتها من binlog.
من أجل استئناف قراءة binlog للعمل بشكل صحيح ، قمنا بما يلي: لكل حدث تغيير صف في قاعدة البيانات ، تذكر معرف آخر معاملة مكتملة في الوقت الذي حدث فيه هذا الحدث. بعد إرسال التغييرات إلى Sphinx ، نقوم بتحديث رقم المعاملة التي يمكنك من خلالها البدء في القراءة بأمان ، على النحو التالي. إذا لم نعالج جميع التغييرات المتراكمة (نظرًا لأن بعض المستندات لم يتم "تعقبها" في قائمة الانتظار) ، فسنأخذ رقم المعاملة الأولى من تلك المتعلقة بالتغييرات التي لم نتمكن من تطبيقها بعد. وإذا حدث أن قمنا بتطبيق جميع التغييرات المتراكمة ، فإننا نأخذ فقط رقم آخر صفقة مكتملة.
ما حدث كنتيجة جيد بالنسبة لنا ، ولكن كانت هناك نقطة أخرى مهمة إلى حد ما: لكي يظل أداء مؤشر الوقت الفعلي عند مستوى مقبول مع مرور الوقت ، كان من الضروري أن يظل حجم وعدد "القطع" من هذا المؤشر صغيرًا. للقيام بذلك ، يحتوي Sphinx على طلب FLUSH RAMCHUNK ، مما يجعل قطعة قرص جديدة ، وطلب OPTIMIZE INDEX ، والذي يدمج جميع قطع القرص في واحدة. في البداية ، اعتقدنا أننا سنؤديها بشكل دوري وهذا كل شيء. لكن ، لسوء الحظ ، اتضح أنه في الإصدار 2.3.2 لا يعمل OPTIMIZE INDEX (مع وجود احتمال كبير إلى حد ما يؤدي إلى انخفاض في searchd). لذلك ، قررنا مرة واحدة يوميًا إعادة إنشاء الفهرس تمامًا ، خاصة وأننا لا نزال نحتاج إلى القيام بذلك من وقت لآخر (على سبيل المثال ، في حالة تغيير نظام الفهرس أو إعدادات الرمز المميز).
يتم إجراء إعادة إنشاء الفهرس على عدة مراحل.
نقوم بتكوين التكوين للمفهرس
كما ذكر أعلاه ، هناك قالب استعلام SQL في تكوين الخدمة. كما انها تستخدم لتشكيل مفهرس التكوين.
أيضا في التكوين هناك الإعدادات الأخرى اللازمة لبناء الفهرس (إعدادات رمزية ، القواميس ، والقيود المختلفة على استهلاك الموارد).
حفظ الموقف الحالي من MariaDB
من هذا الموضع ، سنبدأ في قراءة binlog ، بعد أن يتوفر الفهرس الجديد على جميع الخوادم مع searchd.
نبدأ مفهرس
indexer --config tmp.vacancy.indexer.0.conf --all أوامر indexer --config tmp.vacancy.indexer.0.conf --all النموذج indexer --config tmp.vacancy.indexer.0.conf --all وننتظر استكمالها. علاوة على ذلك ، إذا تم تقسيم المؤشر إلى أجزاء ، فسنبدأ بناء جميع الأجزاء بشكل متوازٍ.
نقوم بتحميل ملفات الفهرس على الخوادم
يحدث التنزيل على كل خادم أيضًا بشكل متوازٍ ، لكننا ننتظر بشكل طبيعي حتى يتم تحميل جميع الملفات على جميع الخوادم. لتنزيل الملفات في تهيئة الخدمة ، يوجد قسم به قالب أوامر لتنزيل الملفات.
[index_uploader] executable = "rsync" arguments = [ "--files-from=-", "--log-file=<<.DataDir>>/rsync.<<.Host>>.log", "--no-relative", "--times", "--delay-updates", ".", "rsync://<<.Host>>/index/vacancy/", ]
لكل خادم ، نقوم ببساطة باستبدال اسمه في المتغير Host وتنفيذ الأمر الناتج. نحن نستخدم rsync للتنزيل ، لكن من حيث المبدأ أي برنامج أو برنامج نصي يقبل قائمة بالملفات في stdin ونقوم بتنزيل هذه الملفات إلى المجلد حيث يتوقع searchd أن يرى ملفات الفهرس ستفعل.
نوقف التزامن
نتوقف عن قراءة binlog ، ووقف goroutine المسؤولة عن تراكم التغييرات.
استبدل الفهرس القديم بآخر جديد
بالنسبة لكل خادم مزود بـ searchd ، نقوم بإجراء استعلامات متسلسلة RELOAD INDEX vacancy_plain و TRUNCATE INDEX vacancy_plain و ATTACH INDEX vacancy_plain TO vacancy . إذا تم تقسيم الفهرس إلى أجزاء ، فسنقوم بتنفيذ هذه الاستعلامات لكل جزء بالتتابع. في الوقت نفسه ، إذا كنا في بيئة إنتاج ، ثم قبل تنفيذ هذه الاستعلامات على أي خادم ، نزيل الحمل منه عبر الموازن (بحيث لا يقوم أحد بإجراء استعلامات SELECT على المؤشرات بين TRUNCATE و ATTACH ) تم إكمال طلب ATTACH الأخير ، نعيد التحميل إلى هذا الخادم.
استئناف المزامنة من موضع محفوظ
بمجرد استبدال جميع فهارس الوقت الفعلي بأخرى تم إنشاؤها حديثًا ، نستأنف القراءة من binlog ومزامنة الأحداث من binlog ، بدءًا من الموضع الذي قمنا بحفظه قبل بدء الفهرسة.
فيما يلي مثال للرسم البياني لتأخر الفهرس من خادم MariaDB.

هنا يمكنك أن ترى أنه على الرغم من عودة حالة المؤشر بعد إعادة البناء في الوقت المناسب ، إلا أن هذا يحدث لفترة قصيرة جدًا.
الآن وبعد أن أصبح كل شيء جاهزًا إلى حد ما ، حان وقت الإصدار. لقد فعلنا ذلك تدريجيا. أولاً ، لقد سكبنا فهرسًا حقيقيًا على خادمين ، والباقي في ذلك الوقت كان يعمل بنفس الطريقة. في الوقت نفسه ، لم تختلف بنية الفهارس على الخوادم "الجديدة" عن الخوادم القديمة ، لذلك لا يزال بإمكان تطبيق PHP الخاص بنا الاتصال بالموازن دون الحاجة إلى القلق بشأن ما إذا كان سيتم معالجة الطلب على فهرس حقيقي أو على فهرس عادي.
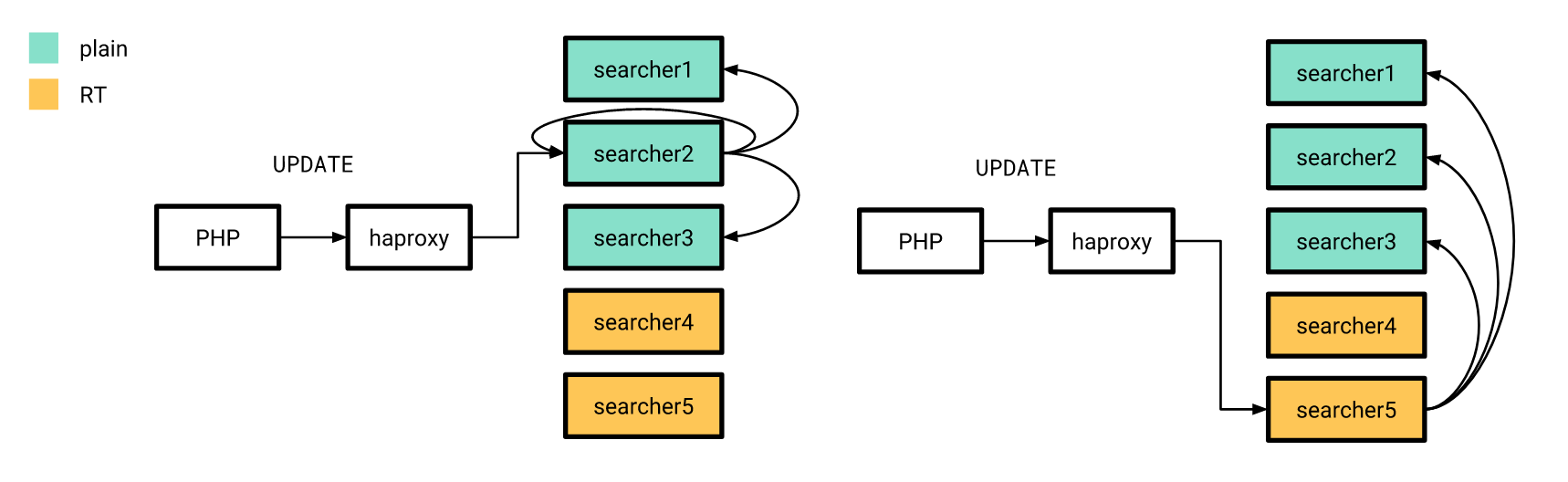
تم إرسال تحديثات السمات ، التي تحدثت عنها سابقًا ، وفقًا للنظام القديم ، مع اختلاف تكوين الفهرس الموزع على جميع الخوادم لإرسال استعلامات UPDATE فقط إلى الخوادم ذات الفهارس العادية. علاوة على ذلك ، إذا وصل طلب UPDATE من التطبيق إلى الخادم بفهارس حقيقية ، فإنه لا ينفذ هذا الطلب في المنزل ، ولكنه يرسله إلى الخوادم التي تم تكوينها بالطريقة القديمة.
بعد الإصدار ، كما كنا نأمل ، اتضح أن هذا يقلل بشكل كبير من التأخير بين كيفية حدوث استئناف أو شغور في قاعدة البيانات وكيف تدخل التغييرات المقابلة في الفهرس.
بعد التبديل إلى فهرس حقيقي ، لم تكن هناك حاجة لإعادة إنشاء الفهرس بعد كل تغيير على خوادم الاختبار. وهكذا أصبح من الممكن كتابة اختبارات تلقائية شاملة بمشاركة البحث بطريقة غير مكلفة نسبيًا. ومع ذلك ، نظرًا لأننا نعالج التغييرات من binlog بشكل غير متزامن (من وجهة نظر العملاء الذين يكتبون إلى قاعدة البيانات) ، كان علينا أن نجعل من الممكن الانتظار حتى تتم معالجة التغييرات المتعلقة بالمستند المشاركة في الاختبار التلقائي بواسطة خدمتنا وإرسالها إلى searchd .
للقيام بذلك ، حققنا نقطة نهاية في خدمتنا ، والتي تفعل ذلك بالضبط ، أي ، تنتظر حتى يتم تطبيق جميع التغييرات على رقم المعاملة المحدد. للقيام بذلك ، فور إجراء التغييرات اللازمة على قاعدة البيانات ، نطلب من @@gtid_current_pos ونقلها إلى نقطة النهاية في خدمتنا. إذا قمنا بالفعل بتطبيق جميع المعاملات على هذا الموقف بحلول هذا الوقت ، فستجيب الخدمة على الفور بأنه يمكننا المتابعة. إذا لم يكن الأمر كذلك ، فعندئذٍ في goroutine المسؤولة عن تطبيق التغييرات ، نقوم بإنشاء اشتراك في GTID ، وبمجرد تطبيقه (أو أي واحد يتبعه) ، نسمح أيضًا للعميل بمتابعة الاختبار التلقائي.
في كود PHP ، يبدو كالتالي:
<?php declare(strict_types=1); use GuzzleHttp\ClientInterface; use GuzzleHttp\RequestOptions; use PDO; class RiverClient { private const REQUEST_METHOD = 'post'; /** * @var ClientInterface */ private $httpClient; public function __construct(ClientInterface $httpClient) { $this->httpClient = $httpClient; } public function waitForSync(PDO $mysqlConnection, PDO $sphinxConnection, string $riverAddr): void { $masterGTID = $mysqlConnection->query('SELECT @@gtid_current_pos')->fetchColumn(); $this->httpClient->request( self::REQUEST_METHOD, "http://{$riverAddr}/wait", [RequestOptions::FORM_PARAMS => ['gtid' => $masterGTID]] ); } }
النتائج
نتيجة لذلك ، تمكنا من تقليل التأخير بين تحديث MariaDB و Sphinx بشكل كبير.


لقد أصبحنا أيضًا أكثر ثقة بأن جميع التحديثات تصل إلى جميع خوادم Sphinx الخاصة بنا في الوقت المحدد.
بالإضافة إلى ذلك ، أصبح اختبار البحث (اليدوي والآلي) أكثر متعة.
لسوء الحظ ، لم يتم منحنا هذا مجانًا: لقد بدا أداء مؤشر الوقت الفعلي مقارنة بالمؤشر العادي أسوأ قليلاً.
يظهر أدناه توزيع وقت معالجة طلبات البحث وفقًا للوقت لفهرس عادي.

وهنا هو نفس الرسم البياني لمؤشر الوقت الحقيقي.

يمكنك أن ترى أن حصة الطلبات "السريعة" قد انخفضت بشكل طفيف ، بينما زادت حصة الطلبات "البطيئة".
بدلا من الاستنتاج
يبقى أن نقول أن رمز الخدمة الموصوفة في هذه المقالة ، نشرنا في المجال العام . لسوء الحظ ، لا توجد وثائق مفصلة حتى الآن ، ولكن إذا كنت ترغب في ذلك ، يمكنك تشغيل مثال لاستخدام هذه الخدمة من خلال docker-compose .
مراجع
- فيديو وتقارير الشرائح
- تقرير فيديو لأندري سميرنوف وفياتشيسلاف كريوكوف على برنامج Highload ++
- الذهاب ماي الخلية المكتبة
- رمز الخدمة مع مثال الاستخدام