مع التقدم الأخير في الشبكات العصبية بشكل عام والتعرف على الصور بشكل خاص ، قد يبدو أن إنشاء تطبيق يستند إلى NN للتعرف على الصور هو عملية روتينية بسيطة. حسنًا ، هذا صحيح إلى حد ما: إذا كان بإمكانك تخيل تطبيق التعرف على الصور ، فمن المحتمل أن يكون شخص ما قد فعل شيئًا مماثلاً. كل ما عليك فعله هو تشغيل Google وتكرارها.
ومع ذلك ، لا يزال هناك القليل من التفاصيل التي لا تعد ولا تحصى والتي لا يمكن حلها ، لا. إنها ببساطة تأخذ الكثير من وقتك ، خاصةً إذا كنت مبتدئًا. ما قد يكون مفيدًا هو مشروع تدريجي ، يتم تنفيذه أمامك مباشرةً ، ونبدأ في النهاية. مشروع لا يحتوي على "هذا الجزء واضح ، لذا دعنا نتخطاه" حسنا ، تقريبا :)
سنقوم في هذا البرنامج التعليمي بالتجول عبر مُعرّف سلالة الكلاب: سننشئ وتعلِّم شبكة عصبية ، ثم سننقلها إلى Java لنظام Android وننشرها على Google Play.
لأولئك منكم الذين يرغبون في رؤية نتيجة
نهائية ، هنا هو الرابط
لتطبيق NeuroDog على Google Play.
موقع على شبكة الإنترنت مع بلدي الروبوتات:
robotics.snowcron.com .
موقع على شبكة الإنترنت مع:
دليل المستخدم NeuroDog .
فيما يلي لقطة شاشة للبرنامج:
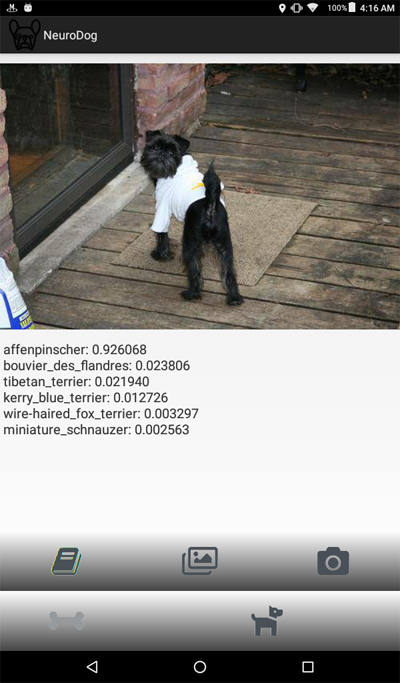
نظرة عامة
سنستخدم Keras: مكتبة Google للعمل مع الشبكات العصبية. إنه مستوى رفيع ، مما يعني أن منحنى التعلم سيكون حادًا ، وبالتأكيد أسرع من المكتبات الأخرى التي أعرفها. اجعل نفسك على دراية به: هناك العديد من البرامج التعليمية عالية الجودة على الإنترنت.
سوف نستخدم شبكات CNN - الشبكات العصبية التلافيفية. تعد شبكات CNN (والشبكات الأكثر تقدماً القائمة عليها) معيارًا فعليًا في التعرف على الصور. ومع ذلك ، قد يصبح تدريس واحد بشكل صحيح مهمة هائلة: هيكل الشبكة ، ومعلمات التعلم (كل تلك معدلات التعلم ، والزخم ، L1 و L2 وما إلى ذلك) ينبغي تعديلها بعناية ، وبما أن المهمة تتطلب الكثير من الموارد الحسابية ، فإننا لا يمكن ببساطة محاولة جميع المجموعات الممكنة.
هذا أحد الأسباب القليلة وراء تفضيلنا في معظم الحالات استخدام "نقل المعرفة" لما يسمى بنهج "الفانيليا". يستخدم Transfer Knowlege شبكة عصبية تم تدريبها من قِبل شخص آخر (فكر في Google) للقيام بمهمة أخرى. ثم نزيل الطبقات القليلة الأخيرة منه ، ونضيف طبقات خاصة بنا ... وتعمل معجزات.
قد يبدو غريباً: لقد أخذنا شبكة Google مدربة على التعرف على القطط والزهور والأثاث ، والآن تحدد سلالة الكلاب! لفهم كيفية عمله ، دعونا نلقي نظرة على الطريقة التي تعمل بها الشبكات العصبية العميقة ، بما في ذلك الشبكات المستخدمة للتعرف على الصور ، والعمل.
نحن نطعمها صورة كمدخل. تحلل الطبقة الأولى من الشبكة الصورة بحثًا عن أنماط بسيطة ، مثل "الخط الأفقي القصير" و "القوس" وما إلى ذلك. تأخذ الطبقة التالية هذه الأنماط (ومكان وجودها على الصورة) وتنتج أنماطًا ذات مستوى أعلى ، مثل "fur" ، و "Corner of a eye" ، إلخ. في النهاية ، لدينا لغز يمكن دمجه في وصف للكلب: فرو وعينان وساق بشري في الفم وما إلى ذلك.
الآن ، كل هذا تم بواسطة مجموعة من الطبقات المدربة مسبقًا التي حصلنا عليها (من Google أو من لاعب كبير آخر). أخيرًا ، نضيف طبقاتنا فوقها ونعلّمها العمل مع تلك الأنماط للتعرف على سلالات الكلاب. يبدو منطقيا.
للتلخيص ، سننشئ في هذا البرنامج التعليمي شبكة CNN "vanilla" وشبكتي "نقل التعلم" من أنواع مختلفة. بالنسبة إلى "الفانيليا": سأستخدمها فقط كمثال على كيفية القيام بذلك ، لكنني لن أضبطه ، لأن الشبكات "المدربة مسبقًا" أسهل في الاستخدام. يأتي Keras مزودًا بعدد قليل من الشبكات المدربة مسبقًا ، وسأختار اثنين من التكوينات وأقارنها.
بما أننا نريد أن تكون شبكتنا العصبية قادرة على التعرف على سلالات الكلاب ، فإننا نحتاج إلى "إظهار" صور العينات لسلالات مختلفة. لحسن الحظ ، هناك
مجموعة بيانات كبيرة تم إنشاؤها لمهمة مماثلة (
الأصل هنا ). في هذه المقالة ،
سأستخدم الإصدار من Kaggleثم سأنقل "الفائز" إلى Android. يعد Porting Keras NN إلى Android أمرًا سهلًا نسبيًا ، وسنتعرف على جميع الخطوات المطلوبة.
ثم سننشره على Google Play. كما يجب أن يتوقع المرء ، لن تتعاون Google ، لذا ستكون هناك حاجة إلى عدد قليل من الحيل الإضافية. على سبيل المثال ، تتجاوز شبكتنا العصبية حجم Android APK المسموح به: سيتعين علينا استخدام الحزمة. أيضًا ، لن تعرض Google تطبيقنا في نتائج البحث ، إلا إذا قمنا ببعض الأشياء السحرية.
في النهاية ، سيكون لدينا تطبيق "تجاري" يعمل بشكل كامل (في علامات اقتباس ، لأنه مجاني مع أنه جاهز للسوق) تطبيق Android NN الممكّن.
بيئة التطوير
هناك بعض الطرق المختلفة لبرمجة Keras ، اعتمادًا على نظام التشغيل الذي تستخدمه (يوصى باستخدام Ubuntu) وبطاقة الفيديو التي لديك (أو لا) وما إلى ذلك. لا حرج في تكوين بيئة التطوير على جهاز الكمبيوتر المحلي الخاص بك وتثبيت جميع المكتبات اللازمة وما إلى ذلك. باستثناء ... هناك طريقة أسهل.
أولاً ، يستغرق تثبيت أدوات تطوير متعددة وتكوينها بعض الوقت ، وسيتعين عليك قضاء بعض الوقت مرة أخرى عندما تتوفر إصدارات جديدة. ثانياً ، يتطلب تدريب الشبكات العصبية الكثير من القوة الحسابية. يمكنك تسريع جهاز الكمبيوتر الخاص بك عن طريق استخدام GPU ... في لحظة كتابة هذا التقرير ، تبلغ تكلفة وحدة معالجة الرسومات (GPU) الخاصة بحساب NN الأعلى 2000 - 7000 دولار. وتكوينه يستغرق بعض الوقت أيضًا.
لذلك سوف نستخدم طريقة مختلفة. انظر ، تسمح Google للناس باستخدام وحدات معالجة الرسومات الخاصة به مجانًا لإجراء الحسابات المتعلقة بالأنظمة NN ، كما أنها قد أوجدت بيئة مكوّنة بالكامل ؛ كل ذلك معا يطلق عليه جوجل كولاب. تمنحك الخدمة الوصول إلى دفتر Jupiter مع Python و Keras وأطنان من المكتبات الإضافية المثبتة بالفعل. كل ما عليك القيام به هو الحصول على حساب Google (الحصول على حساب Gmail ، وسيكون لديك الوصول إلى كل شيء آخر) وهذا كل شيء.
في لحظة كتابة هذا التقرير ، يمكن الوصول إلى Colab عن
طريق هذا الرابط ، لكن يمكن أن يتغير. مجرد جوجل حتى "جوجل كولاب".
مشكلة واضحة في Colab هي أنها خدمة WEB. كيف ستصل إلى ملفاتك؟ حفظ الشبكات العصبية بعد اكتمال التدريب ، وتحميل البيانات الخاصة بمهمتك وهلم جرا؟
هناك عدد قليل (في لحظة كتابة هذا التقرير - ثلاثة) مناهج مختلفة ؛ سنستخدم ما أعتقد أنه الأفضل: استخدام Google Drive.
Google Drive عبارة عن وحدة تخزين سحابية تعمل بشكل كبير كقرص صلب ، ويمكن تعيينها إلى Google Colab (انظر الكود أدناه). ثم تعمل معها كما تفعل مع محرك الأقراص الثابت المحلي. لذلك ، على سبيل المثال ، إذا كنت ترغب في الوصول إلى صور الكلاب من الشبكة العصبية التي أنشأتها في كولاب ، فعليك تحميل هذه الصور على Google Drive ، كل هذا.
إنشاء وتدريب NN
أدناه ، سوف أتجول في كود Python ، كتلة واحدة من التعليمات البرمجية من Jupiter Notebook بعد الآخر. يمكنك نسخ هذا الرمز إلى الكمبيوتر المحمول وتشغيله ، حيث يمكن تنفيذ الكتل بشكل مستقل عن بعضها البعض.
التهيئة
بادئ ذي بدء ، لنقم بتنزيل Google Drive. فقط سطرين من التعليمات البرمجية. يجب تنفيذ هذا الرمز مرة واحدة فقط في كل جلسة Colab (على سبيل المثال ، مرة واحدة كل ست ساعات من العمل). إذا قمت بتشغيلها في المرة الثانية ، فسيتم تخطيها لأن محرك الأقراص مثبت بالفعل.
from google.colab import drive drive.mount('/content/drive/')
في المرة الأولى سيُطلب منك تأكيد التثبيت - لا يوجد شيء معقد هنا. يبدو مثل هذا:
>>> Go to this URL in a browser: ... >>> Enter your authorization code: >>> ·········· >>> Mounted at /content/drive/
وتشمل معيار جميلة القسم. على الأرجح بعض من غير مطلوبة. أيضًا ، بينما سأقوم باختبار تكوينات NN مختلفة ، سيتعين عليك تعليق / إلغاء تثبيت بعضها لنوع معين من NNs: على سبيل المثال ، استخدام InceptionV3 type NN ، و Unceptionment InceptionV3 ، والتعليق ، على سبيل المثال ، ResNet50. أم لا: يمكنك الاحتفاظ بما يتضمنه غير كامل ، وسوف يستخدم ذاكرة أكثر ، لكن هذا كل شيء.
import datetime as dt import pandas as pd import seaborn as sns import matplotlib.pyplot as plt from tqdm import tqdm import cv2 import numpy as np import os import sys import random import warnings from sklearn.model_selection import train_test_split import keras from keras import backend as K from keras import regularizers from keras.models import Sequential from keras.models import Model from keras.layers import Dense, Dropout, Activation from keras.layers import Flatten, Conv2D from keras.layers import MaxPooling2D from keras.layers import BatchNormalization, Input from keras.layers import Dropout, GlobalAveragePooling2D from keras.callbacks import Callback, EarlyStopping from keras.callbacks import ReduceLROnPlateau from keras.callbacks import ModelCheckpoint import shutil from keras.applications.vgg16 import preprocess_input from keras.preprocessing import image from keras.preprocessing.image import ImageDataGenerator from keras.models import load_model from keras.applications.resnet50 import ResNet50 from keras.applications.resnet50 import preprocess_input from keras.applications.resnet50 import decode_predictions from keras.applications import inception_v3 from keras.applications.inception_v3 import InceptionV3 from keras.applications.inception_v3 import preprocess_input as inception_v3_preprocessor from keras.applications.mobilenetv2 import MobileNetV2 from keras.applications.nasnet import NASNetMobile
على Google Drive ، سنقوم بإنشاء مجلد لملفاتنا. يعرض السطر الثاني محتواه:
working_path = "/content/drive/My Drive/DeepDogBreed/data/" !ls "/content/drive/My Drive/DeepDogBreed/data" >>> all_images labels.csv models test train valid
كما ترون ، يتم تخزين صور الكلاب (تلك التي تم نسخها من مجموعة بيانات Stanford (انظر أعلاه) إلى Google Drive ، مبدئيًا في مجلد
all_images . في وقت لاحق سنقوم بنسخها
لتدريب المجلدات
الصالحة واختبارها . سنقوم بحفظ النماذج المدربة في مجلد
الطرز ، أما بالنسبة إلى ملف labels.csv ، فهو جزء من مجموعة البيانات ، حيث يقوم بتعيين خرائط للصور لسلالات الكلاب.
هناك العديد من الاختبارات التي يمكنك إجراؤها لمعرفة ما لديك ، دعنا نجري اختبارًا واحدًا فقط:
حسنا ، GPU متصل. إذا لم يكن كذلك ، فابحث عن ذلك في إعدادات Jupiter Notebook وقم بتشغيله.
نحتاج الآن إلى الإعلان عن بعض الثوابت التي سنستخدمها ، مثل حجم الصورة التي يجب أن تتوقعها الشبكة العصبية وما إلى ذلك. لاحظ أننا نستخدم صورة بحجم 256 × 256 نظرًا لأن حجمها كبير بدرجة كافية على جانب واحد ويناسب الذاكرة في الجانب الآخر. ومع ذلك ، تتوقع بعض أنواع الشبكات العصبية التي نوشك استخدامها استخدام صورة بحجم 224 × 224. للتعامل مع هذا ، عند الضرورة ، قم بتعليق حجم الصورة القديمة وإلغاء تثبيت حجم جديد.
ينطبق نفس الأسلوب (تعليق واحد - عدم التعليق على الآخر) على أسماء النماذج التي نقوم بحفظها ، وذلك ببساطة لأننا لا نريد الكتابة فوق نتيجة الاختبار السابق عندما نجرب تهيئة جديدة.
warnings.filterwarnings("ignore") os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' np.random.seed(7) start = dt.datetime.now() BATCH_SIZE = 16 EPOCHS = 15 TESTING_SPLIT=0.3
تحميل البيانات
أولاً ، دعونا
نقوم بتحميل ملف
labels.csv وتقسيم محتواه إلى أجزاء التدريب والتحقق من الصحة. لاحظ أنه لا يوجد جزء اختبار حتى الآن ، لأنني سأغش قليلاً ، من أجل الحصول على مزيد من البيانات للتدريب.
labels = pd.read_csv(working_path + 'labels.csv') print(labels.head()) train_ids, valid_ids = train_test_split(labels, test_size = TESTING_SPLIT) print(len(train_ids), 'train ids', len(valid_ids), 'validation ids') print('Total', len(labels), 'testing images') >>> id breed >>> 0 000bec180eb18c7604dcecc8fe0dba07 boston_bull >>> 1 001513dfcb2ffafc82cccf4d8bbaba97 dingo >>> 2 001cdf01b096e06d78e9e5112d419397 pekinese >>> 3 00214f311d5d2247d5dfe4fe24b2303d bluetick >>> 4 0021f9ceb3235effd7fcde7f7538ed62 golden_retriever >>> 7155 train ids 3067 validation ids >>> Total 10222 testing images
الشيء التالي ، نحن بحاجة إلى نسخ ملفات الصور الفعلية إلى مجلدات التدريب / التحقق من الصحة / الاختبار ، وفقًا لمجموعة من أسماء الملفات التي نمررها. تقوم الوظيفة التالية بنسخ الملفات مع الأسماء المقدمة إلى مجلد محدد.
def copyFileSet(strDirFrom, strDirTo, arrFileNames): arrBreeds = np.asarray(arrFileNames['breed']) arrFileNames = np.asarray(arrFileNames['id']) if not os.path.exists(strDirTo): os.makedirs(strDirTo) for i in tqdm(range(len(arrFileNames))): strFileNameFrom = strDirFrom + arrFileNames[i] + ".jpg" strFileNameTo = strDirTo + arrBreeds[i] + "/" + arrFileNames[i] + ".jpg" if not os.path.exists(strDirTo + arrBreeds[i] + "/"): os.makedirs(strDirTo + arrBreeds[i] + "/")
كما ترون ، نقوم بنسخ ملف واحد فقط لكل سلالة من الكلاب إلى مجلد
اختبار . أثناء نسخ الملفات ، نقوم أيضًا بإنشاء مجلدات فرعية - مجلد فرعي واحد لكل سلالة من الكلاب. يتم نسخ الصور لكل سلالة معينة في مجلده الفرعي.
والسبب هو أنه يمكن لـ Keras العمل باستخدام بنية دليل منظمة بهذه الطريقة ، وتحميل ملفات الصور حسب الحاجة ، مما يوفر الذاكرة. سيكون من الجيد جدًا تحميل جميع الصور البالغ عددها 15000 صورة في الذاكرة مرة واحدة.
استدعاء هذه الوظيفة في كل مرة نقوم فيها بتشغيل الكود الخاص بنا سيكون مبالغة: يتم نسخ الصور بالفعل ، لماذا يجب علينا نسخها مرة أخرى. لذلك ، علقها بعد الاستخدام الأول:
بالإضافة إلى ذلك ، نحن بحاجة إلى قائمة سلالات الكلاب:
breeds = np.unique(labels['breed']) map_characters = {}
معالجة الصور
سنستخدم ميزة Keras التي تسمى ImageDataGenerators. يمكن لـ ImageDataGenerator معالجة صورة وتغيير حجمها وتدويرها وما إلى ذلك. يمكن أن يستغرق أيضًا وظيفة
معالجة تقوم بمعالجة الصور المخصصة.
def preprocess(img): img = cv2.resize(img, (IMAGE_SIZE, IMAGE_SIZE), interpolation = cv2.INTER_AREA)
لاحظ السطر التالي:
يمكننا إجراء التطبيع (تركيب نطاق قناة الصورة من 0-255 إلى 0-1) في ImageDataGenerator نفسه. فلماذا نحتاج قبل المعالج؟ على سبيل المثال ، لقد قدمت وظيفة (علق بها)
طمس : هذا هو معالجة صورة مخصصة. يمكنك استخدام أي شيء من التوضيح إلى HDR هنا.
سوف نستخدم اثنين من ImageDataGenerators ، واحد للتدريب والآخر للتحقق من الصحة. الفرق هو أننا نحتاج إلى دورات وتدوير للتدريب ، لجعل الصور أكثر "تنوعًا" ، لكننا لا نحتاجها للتحقق من الصحة (ليس في هذه المهمة).
train_datagen = ImageDataGenerator( preprocessing_function=preprocess,
إنشاء شبكة عصبية
كما ذكر أعلاه ، سنقوم بإنشاء أنواع قليلة من الشبكات العصبية. في كل مرة نستخدم فيها وظيفة مختلفة ، تتضمن مكتبة مختلفة وفي بعض الحالات أحجام صور مختلفة. لذلك للتبديل من نوع واحد من الشبكة العصبية إلى أخرى ، تحتاج إلى تعليق / إلغاء فك شفرة المقابلة.
أولاً ، دعنا ننشئ قناة CNN. يعمل هذا النظام بشكل سيئ ، حيث أنني لم أقوم بتحسينه ، ولكنه على الأقل يوفر إطارًا يمكنك استخدامه لإنشاء شبكة خاصة بك (بشكل عام ، إنها فكرة سيئة ، حيث تتوفر شبكات مدربة مسبقًا).
def createModelVanilla(): model = Sequential()
عندما ننشئ الشبكة العصبية باستخدام
تعلم النقل ، يتغير الإجراء:
def createModelMobileNetV2():
إنشاء أنواع أخرى من NNs المدربين مسبقًا مشابه جدًا:
def createModelResNet50(): base_model = ResNet50(weights='imagenet', include_top=False, pooling='avg', input_shape=(IMAGE_SIZE, IMAGE_SIZE, 3)) x = base_model.output x = Dense(512)(x) x = Activation('relu')(x) x = Dropout(0.5)(x) predictions = Dense(NUM_CLASSES, activation='softmax')(x) model = Model(inputs=base_model.input, outputs=predictions)
عناية: الفائز! أظهر هذا NN أفضل النتائج:
def createModelInceptionV3():
أكثر واحد:
def createModelNASNetMobile():
يتم استخدام أنواع مختلفة من NNs في مواقف مختلفة. بالإضافة إلى المشكلات المتعلقة بالدقة ، تعد أبعاد الحجم (المحمول NN أصغر بمقدار 5 مرات من Inception one) والسرعة (إذا احتجنا إلى تحليل في الوقت الفعلي لدفق الفيديو ، فقد يتعين علينا التضحية بالدقة).
تدريب الشبكة العصبية
بادئ ذي بدء ، نحن نجري
تجارب ، لذلك نحتاج إلى أن نكون قادرين على حذف أسماء NN التي قمنا بحفظها من قبل ، لكننا لسنا بحاجة بعد الآن. الوظيفة التالية تحذف NN في حالة وجود الملف:
طريقة إنشاء وحذف NNs واضحة. أولا ، نحذف. الآن ، إذا لم تكن ترغب في
حذف الاتصال ، فقط تذكر أن Jupiter Notebook لديه وظيفة "اختيار التشغيل" - حدد فقط ما تحتاجه ، وقم بتشغيله.
ثم نقوم بإنشاء NN إذا كان الملف الخاص به غير موجود أو
تحميله إذا كان الملف موجودًا: بالطبع ، لا يمكننا استدعاء "حذف" ومن ثم نتوقع وجود NN ، لذلك لاستخدام الشبكة المحفوظة مسبقًا ، لا تتصل
بالحذف .
بمعنى آخر ، يمكننا إنشاء NN جديد أو استخدام واحد موجود ، اعتمادًا على ما نجربه الآن. سيناريو بسيط: لقد قمنا بتدريب NN ، ثم غادرنا لقضاء عطلة. قام Google بتسجيل خروجنا ، لذلك نحتاج إلى إعادة تحميل NN: قم بالتعليق على الجزء "حذف" وإلغاء uncomment الجزء "تحميل".
deleteSavedNet(working_path + strModelFileName)
نقاط التفتيش مهمة جدًا عند تدريس NNs. يمكنك إنشاء مجموعة من الوظائف ليتم استدعاؤها في نهاية كل فترة تدريب ، على سبيل المثال ، يمكنك حفظ NN إذا أظهرت نتائج أفضل من آخر تم حفظه.
checkpoint = ModelCheckpoint(working_path + strModelFileName, monitor='val_acc', verbose=1, save_best_only=True, mode='auto', save_weights_only=False) callbacks_list = [ checkpoint ]
أخيرًا ، سنقوم بتعليم NN الخاص بنا باستخدام مجموعة التدريب:
فيما يلي مخططات الدقة والخسارة للفائز NN:
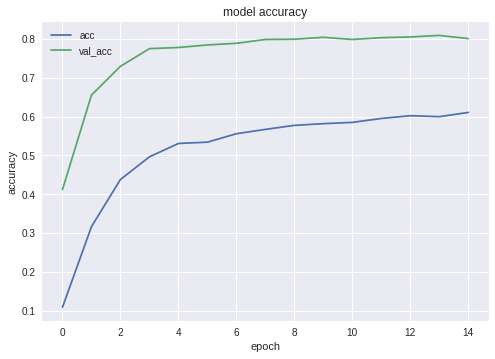

كما ترون ، فإن الشبكة تتعلم جيدًا.
اختبار الشبكة العصبية
بعد اكتمال مرحلة التدريب ، نحتاج إلى إجراء الاختبار ؛ للقيام بذلك ، يتم تقديم NN مع الصور التي لم يسبق له مثيل. تتذكر ، لقد وضعنا جانبا صورة واحدة لكل نوع من أنواع الكلاب.
تصدير NN إلى جافا
أولا ، نحن بحاجة إلى تحميل NN. السبب هو أن التصدير عبارة عن كتلة منفصلة من التعليمات البرمجية ، لذلك من المحتمل أن نقوم بتشغيلها بشكل منفصل ، دون إعادة تدريب NN. أثناء استخدام الكود الخاص بي ، أنت لا تهتم حقًا ، ولكن إذا قمت بالتطوير الخاص بك ، فستحاول تجنب إعادة تدريب
نفس الشبكة مرة واحدة تلو الأخرى.
للسبب نفسه - هذا مقطع منفصل من الشفرة بطريقة ما - نحن نستخدم معلومات إضافية هنا. لا شيء يمنعنا من رفعها ، بالطبع:
from keras.models import Model from keras.models import load_model from keras.layers import * import os import sys import tensorflow as tf
القليل من الاختبارات ، فقط للتأكد من أننا قمنا بتحميل كل شيء بشكل صحيح:
img = image.load_img(working_path + "test/affenpinscher.jpg")

الشيء التالي ، نحن بحاجة إلى الحصول على أسماء طبقات المدخلات والمخرجات لشبكتنا (ما لم نستخدم معلمة "الاسم" عند إنشاء الشبكة ، والتي لم نستخدمها).
model.summary() >>> Layer (type) >>> ====================== >>> input_7 (InputLayer) >>> ______________________ >>> conv2d_283 (Conv2D) >>> ______________________ >>> ... >>> dense_14 (Dense) >>> ====================== >>> Total params: 22,913,432 >>> Trainable params: 1,110,648 >>> Non-trainable params: 21,802,784
سنستخدم أسماء طبقة الإدخال والإخراج لاحقًا ، عند استيراد NN في تطبيق Android Java.
يمكننا أيضًا استخدام الكود التالي للحصول على هذه المعلومات:
def print_graph_nodes(filename): g = tf.GraphDef() g.ParseFromString(open(filename, 'rb').read()) print() print(filename) print("=======================INPUT===================") print([n for n in g.node if n.name.find('input') != -1]) print("=======================OUTPUT==================") print([n for n in g.node if n.name.find('output') != -1]) print("===================KERAS_LEARNING==============") print([n for n in g.node if n.name.find('keras_learning_phase') != -1]) print("===============================================") print()
ومع ذلك ، النهج الأول هو المفضل.
تقوم الوظيفة التالية بتصدير Keras Neural Network إلى تنسيق
pb ، واحد سنستخدمه في Android.
def keras_to_tensorflow(keras_model, output_dir, model_name,out_prefix="output_", log_tensorboard=True): if os.path.exists(output_dir) == False: os.mkdir(output_dir) out_nodes = [] for i in range(len(keras_model.outputs)): out_nodes.append(out_prefix + str(i + 1)) tf.identity(keras_model.output[i], out_prefix + str(i + 1)) sess = K.get_session() from tensorflow.python.framework import graph_util from tensorflow.python.framework graph_io init_graph = sess.graph.as_graph_def() main_graph = graph_util.convert_variables_to_constants( sess, init_graph, out_nodes) graph_io.write_graph(main_graph, output_dir, name=model_name, as_text=False) if log_tensorboard: from tensorflow.python.tools import import_pb_to_tensorboard import_pb_to_tensorboard.import_to_tensorboard( os.path.join(output_dir, model_name), output_dir)
دعنا نستخدم هذه الوظائف لإنشاء تصدير NN:
model = load_model(working_path + strModelFileName) keras_to_tensorflow(model, output_dir=working_path + strModelFileName, model_name=working_path + "models/dogs.pb") print_graph_nodes(working_path + "models/dogs.pb")
يطبع السطر الأخير هيكل NN الخاص بنا.
إنشاء تطبيق Android يعمل بتقنية NN
تصدير NN إلى تطبيق Android. هو رسمي بشكل جيد ويجب أن لا تشكل أي صعوبات. هناك ، كالعادة ، أكثر من طريقة واحدة للقيام بذلك ؛ سنستخدم الأكثر شعبية (على الأقل ، في الوقت الحالي).
بادئ ذي بدء ، استخدم Android Studio لإنشاء مشروع جديد. سنقوم بقطع الزوايا قليلاً ، لذلك سوف يحتوي فقط على نشاط واحد.

كما ترون ، قمنا بإضافة مجلد "الأصول" ونسخ ملف الشبكة العصبية الخاص بنا هناك.
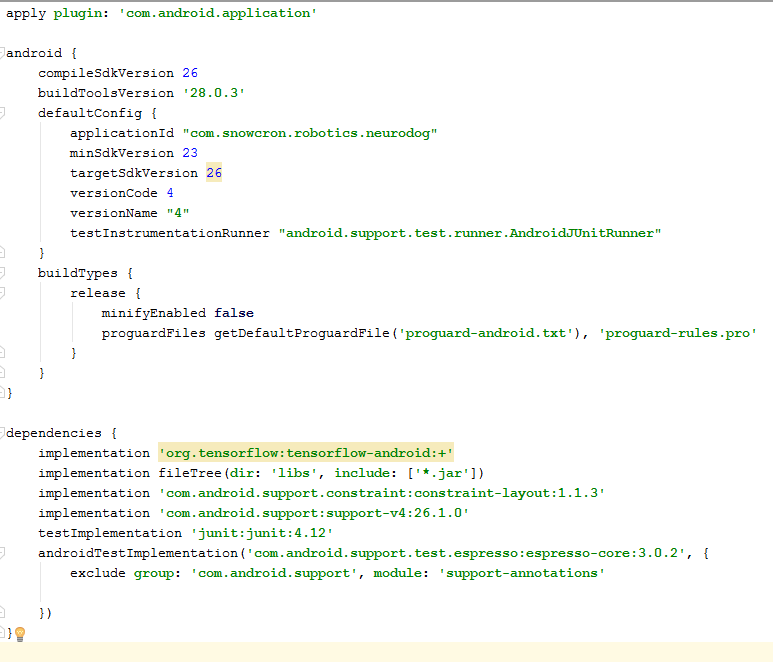
ملف الدرج
هناك بعض التغييرات التي يتعين علينا القيام بها لملف التعريف.
بادئ ذي بدء ، علينا استيراد مكتبة
tensorflow-android . يتم استخدامه للتعامل مع Tensorflow (و Keras ، وفقًا لذلك) من Java:
 كتفاصيل
كتفاصيل إضافية "يصعب العثور عليها" ، لاحظ الإصدارات:
versionCode و
versionName . أثناء العمل على تطبيقك ، ستحتاج إلى تحميل إصدارات جديدة إلى Google Play. بدون تحديث الإصدارات (شيء مثل 1 -> 2 -> 3 ...) لن تتمكن من القيام بذلك.
واضح
بادئ ذي بدء ، لدينا التطبيق. ستكون "ثقيلة" - شبكة العصبية بسعة 100 ميجا بايت تتلاءم بسهولة مع ذاكرة الهواتف الحديثة ، ولكن فتح مثيل منفصل لها في كل مرة يقوم المستخدم "بمشاركة" صورة من Facebook ليس بالتأكيد فكرة جيدة.
لذلك سنتأكد من وجود مثيل واحد فقط لتطبيقنا:
<activity android:name=".MainActivity" android:launchMode="singleTask">
بإضافة
android: launchMode = "singleTask" إلى MainActivity ، نطلب إلى Android فتح تطبيق موجود بدلاً من تشغيل مثيل آخر.
ثم نتأكد من التطبيق لدينا. يظهر في قائمة التطبيقات القادرة على التعامل مع الصور
المشتركة :
<intent-filter> <action android:name="android.intent.action.SEND" /> <category android:name="android.intent.category.DEFAULT" /> <data android:mimeType="image/*" /> </intent-filter>
أخيرًا ، نحتاج إلى طلب ميزات وأذونات ، حتى يتمكن التطبيق من الوصول إلى وظائف النظام التي يتطلبها:
<uses-feature android:name="android.hardware.camera" android:required="true" /> <uses-permission android:name= "android.permission.WRITE_EXTERNAL_STORAGE" /> <uses-permission android:name="android.permission.READ_PHONE_STATE" tools:node="remove" />
إذا كنت معتادًا على برمجة Android ، فلن يثير هذا الجزء أية أسئلة.
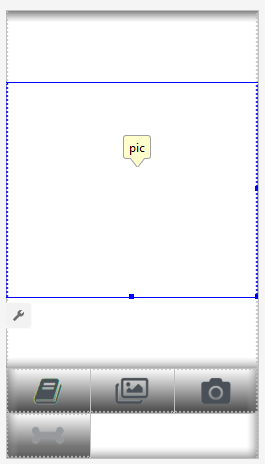
تخطيط التطبيق.
سنقوم بإنشاء تخطيطين ، أحدهما لـ Portrait والآخر لوضع أفقي. هنا هو
تخطيط بورتريه .
ما لدينا هنا: منظر كبير لإظهار صورة ، وقائمة مزعجة إلى حد ما من الإعلانات التجارية (تظهر عند الضغط على زر "العظم") ، أزرار "مساعدة" ، أزرار لتحميل صورة من ملف / معرض ومن الكاميرا ، و أخيرًا ، زر (معالجة في البداية) "عملية".
في النشاط نفسه ، سنقوم بتنفيذ بعض أزرار إظهار / إخفاء / تمكين / تعطيل المنطق وفقًا لحالة التطبيق.
النشاط الرئيسي
يمتد النشاط إلى نشاط Android قياسي:
public class MainActivity extends Activity
دعونا نلقي نظرة على رمز مسؤولة عن عمليات NN.
بادئ ذي بدء ، يقبل NN صورة نقطية. في الأصل ، توجد صورة نقطية كبيرة من ملف أو كاميرا (m_bitmap) ، ثم نقوم بتحويلها إلى صورة نقطية قياسية 256 × 256 (m_bitmapForNn). نحتفظ أيضًا بأبعاد الصورة (256) بشكل ثابت:
static Bitmap m_bitmap = null; static Bitmap m_bitmapForNn = null; private int m_nImageSize = 256;
نحن بحاجة إلى إخبار NN ما هي أسماء طبقات المدخلات والمخرجات ؛ إذا استشرت القائمة أعلاه ، ستجد أن الأسماء (في حالتنا! قضيتك يمكن أن تكون مختلفة!):
private String INPUT_NAME = "input_7_1"; private String OUTPUT_NAME = "output_1";
ثم نعلن المتغير لعقد كائن TensofFlow. أيضًا ، نقوم بتخزين المسار إلى ملف NN في الأصول:
TensorFlowInferenceInterface tf الخاص ؛
سلسلة خاصة MODEL_PATH =
"file: ///android_asset/dogs.pb"؛
سلالات الكلاب ، لتزويد المستخدم بمعلومات مفيدة ، بدلاً من الفهارس في الصفيف:
private String[] m_arrBreedsArray;
في البداية ، نقوم بتحميل صورة نقطية. ومع ذلك ، تتوقع NN نفسها مجموعة من قيم RGB ، وإخراجها هو مجموعة من الاحتمالات في الصورة المقدمة كونها تولد معين. لذلك نحتاج إلى إضافة صفيفين آخرين (لاحظ أن 120 عبارة عن عدد من السلالات في مجموعة بيانات التدريب الخاصة بنا):
private float[] m_arrPrediction = new float[120]; private float[] m_arrInput = null;
قم بتحميل مكتبة الاستدلال tensorflow
static { System.loadLibrary("tensorflow_inference"); }
نظرًا لأن عملية NN طويلة ، فإننا نحتاج إلى تنفيذها في خيط منفصل ، وإلا فهناك فرصة جيدة لضرب تطبيق "النظام". لا يستجيب "تحذير ، ناهيك عن تدمير تجربة المستخدم.
class PredictionTask extends AsyncTask<Void, Void, Void> { @Override protected void onPreExecute() { super.onPreExecute(); }
في onCreate () من MainActivity ، نحتاج إلى إضافة onClickListener لزر "Process": m_btn_process.setOnClickListener(new View.OnClickListener() { @Override public void onClick(View v) { processImage(); } });
ما تقوم به processImage () هو ببساطة استدعاء سلسلة الرسائل التي رأيناها أعلاه: private void processImage() { try { enableControls(false);
تفاصيل إضافية
لن نناقش التعليمات البرمجية المتعلقة بـ UI في هذا البرنامج التعليمي ، لأنه تافه وبالتأكيد ليس جزءًا من مهمة "porting NN". ومع ذلك ، هناك القليل من الأشياء التي يجب توضيحها.عندما كنا prevemted التطبيق لدينا. من تشغيل مثيلات متعددة ، فقد منعنا ، في الوقت نفسه ، التدفق الطبيعي للتحكم: إذا كنت تشارك صورة من Facebook ، ثم تشارك واحدة أخرى ، فلن تتم إعادة تشغيل التطبيق. هذا يعني أن الطريقة "التقليدية" للتعامل مع البيانات المشتركة من خلال التقاطها في onCreate ليست كافية في حالتنا ، حيث لا يتم استدعاء onCreate في سيناريو أنشأناه للتو.فيما يلي طريقة للتعامل مع الموقف:1. في onCreate of MainActivity ، اتصل بوظيفة onSharedIntent: protected void onCreate( Bundle savedInstanceState) { super.onCreate(savedInstanceState); .... onSharedIntent(); ....
أيضًا ، أضف معالجًا لـ onNewIntent: @Override protected void onNewIntent(Intent intent) { super.onNewIntent(intent); setIntent(intent); onSharedIntent(); }
وظيفة onSharedIntent نفسها: private void onSharedIntent() { Intent receivedIntent = getIntent(); String receivedAction = receivedIntent.getAction(); String receivedType = receivedIntent.getType(); if (receivedAction.equals(Intent.ACTION_SEND)) {
نحن الآن نعالج الصورة المشتركة من onCreate (إذا كان التطبيق قد بدأ للتو) أو من onNewIntent إذا تم العثور على مثيل في الذاكرة.حظا سعيدا
إذا أعجبك هذا المقال ، فيرجى "إعجابه" في الشبكات الاجتماعية ، كما توجد أزرار اجتماعية على الموقع نفسه.