عادةً ما تستخدم Nginx منتجات تجارية أو بدائل مفتوحة المصدر ، مثل Prometheus + Grafana ، لمراقبة أداء Nginx وتحليله. يعد هذا خيارًا جيدًا للمراقبة أو التحليلات في الوقت الفعلي ، ولكنه ليس مناسبًا للتحليل التاريخي. على أي مورد شائع ، تنمو كمية البيانات من سجلات nginx بسرعة ، ومن المنطقي استخدام شيء أكثر تخصصًا لتحليل كمية كبيرة من البيانات.
في هذه المقالة ، سأخبرك بكيفية استخدام Athena لتحليل السجلات باستخدام Nginx كمثال ، وإظهار كيفية تجميع لوحة معلومات تحليلية من هذه البيانات باستخدام إطار عمل cube.js مفتوح المصدر. هنا هي بنية الحل الكامل:

TL: DR ؛
رابط إلى لوحة القيادة النهائية .
نستخدم Fluentd لجمع المعلومات و AWS Kinesis Data Firehose و AWS Glue للمعالجة ، و AWS S3 للتخزين. باستخدام هذه الحزمة ، لا يمكنك تخزين سجلات nginx فقط ، ولكن أيضًا أحداث أخرى ، وكذلك سجلات الخدمات الأخرى. يمكنك استبدال بعض الأجزاء بأجزاء متشابهة للمكدس الخاص بك ، على سبيل المثال ، يمكنك كتابة سجلات إلى kinesis مباشرةً من nginx ، أو تجاوز fluentd ، أو استخدام logstash للقيام بذلك.
جمع سجلات Nginx
بشكل افتراضي ، تبدو سجلات Nginx كما يلي:
4/9/2019 12:58:17 PM1.1.1.1 - - [09/Apr/2019:09:58:17 +0000] "GET /sign-up HTTP/2.0" 200 9168 "https://example.com/sign-in" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36" "-" 4/9/2019 12:58:17 PM1.1.1.1 - - [09/Apr/2019:09:58:17 +0000] "GET /sign-in HTTP/2.0" 200 9168 "https://example.com/sign-up" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36" "-"
يمكن تحليلها ، ولكن من الأسهل بكثير إصلاح تكوين Nginx بحيث يعرض السجلات في JSON:
log_format json_combined escape=json '{ "created_at": "$msec", ' '"remote_addr": "$remote_addr", ' '"remote_user": "$remote_user", ' '"request": "$request", ' '"status": $status, ' '"bytes_sent": $bytes_sent, ' '"request_length": $request_length, ' '"request_time": $request_time, ' '"http_referrer": "$http_referer", ' '"http_x_forwarded_for": "$http_x_forwarded_for", ' '"http_user_agent": "$http_user_agent" }'; access_log /var/log/nginx/access.log json_combined;
S3 للتخزين
لتخزين السجلات ، سوف نستخدم S3. يتيح لك ذلك تخزين السجلات وتحليلها في مكان واحد ، حيث يمكن لبرنامج Athena التعامل مع البيانات في S3 مباشرة. في وقت لاحق من هذا المقال ، سوف أخبرك بكيفية طي السجلات ومعالجتها بشكل صحيح ، لكن أولاً نحتاج إلى دلو نظيف في S3 ، حيث لن يتم تخزين أي شيء آخر. من المفيد التفكير مقدمًا في المنطقة التي ستنشئ فيها المجموعة ، لأن أثينا غير متوفرة في جميع المناطق.
إنشاء مخطط في وحدة أثينا
إنشاء جدول في أثينا للسجلات. هناك حاجة لكل من الكتابة والقراءة ، إذا كنت تخطط لاستخدام Kinesis Firehose. افتح وحدة Athena وقم بإنشاء جدول:
إنشاء جدول SQL CREATE EXTERNAL TABLE `kinesis_logs_nginx`( `created_at` double, `remote_addr` string, `remote_user` string, `request` string, `status` int, `bytes_sent` int, `request_length` int, `request_time` double, `http_referrer` string, `http_x_forwarded_for` string, `http_user_agent` string) ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.orc.OrcSerde' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat' LOCATION 's3://<YOUR-S3-BUCKET>' TBLPROPERTIES ('has_encrypted_data'='false');
إنشاء Kinesis Firehose تيار
سوف Kinesis Firehose كتابة البيانات الواردة من Nginx إلى S3 بالتنسيق المحدد ، مقسمة إلى أدلة بالتنسيق YYYY / MM / DD / HH. هذا مفيد عند قراءة البيانات. يمكنك بطبيعة الحال الكتابة مباشرة إلى S3 من fluentd ، ولكن في هذه الحالة يجب عليك كتابة JSON ، وهو غير فعال بسبب حجم الملف الكبير. بالإضافة إلى ذلك ، عند استخدام PrestoDB أو Athena ، JSON هو أبطأ تنسيق بيانات. لذا افتح وحدة التحكم Kinesis Firehose ، انقر فوق "إنشاء تدفق التسليم" ، حدد "direct PUT" في حقل "delivery":
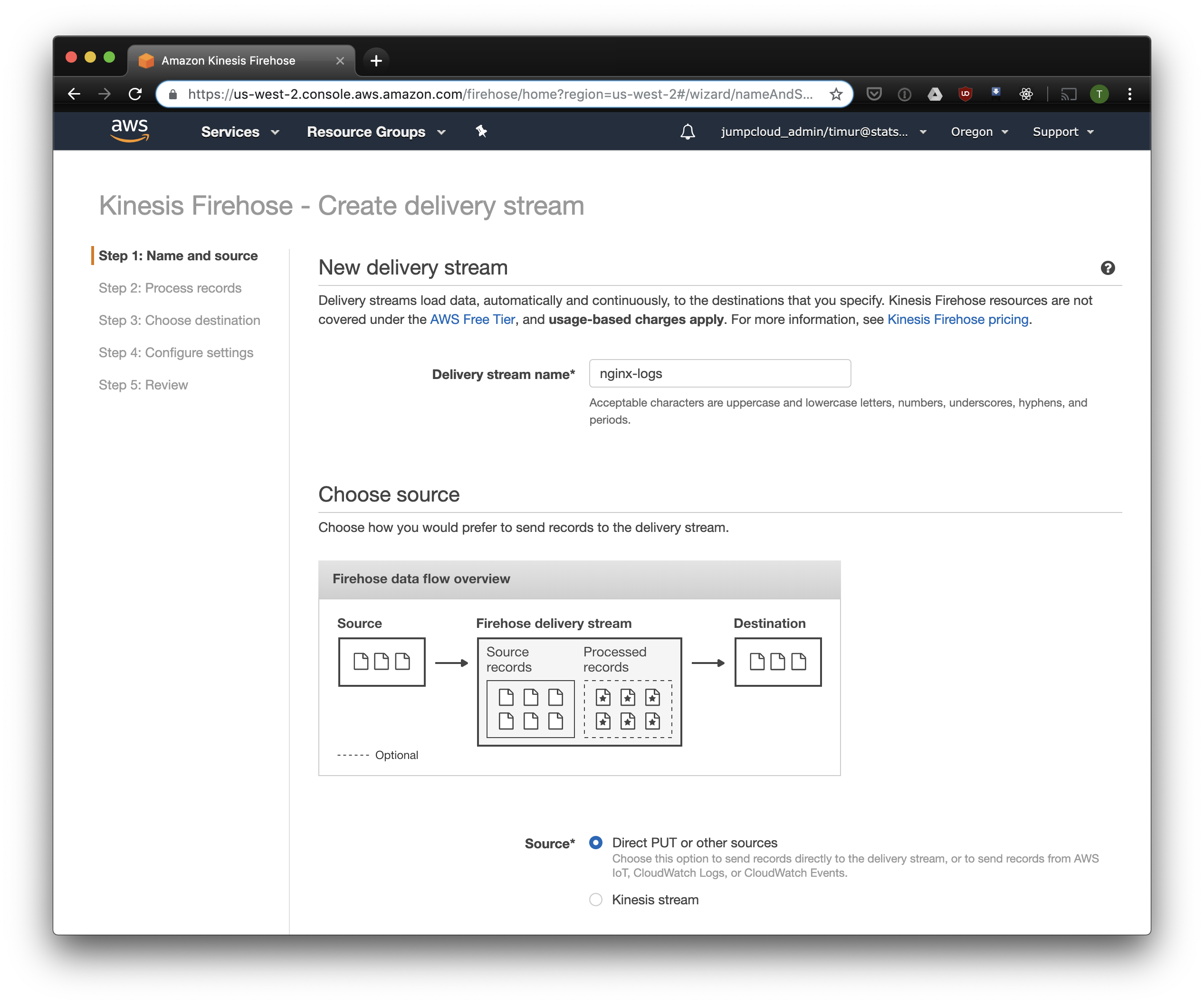
في علامة التبويب التالية ، حدد "تحويل تنسيق السجل" - "ممكّن" وحدد "Apache ORC" كتنسيق للتسجيل. وفقًا لبعض أوين أومالي ، هذا هو التنسيق الأمثل لبريستود وأثينا. كمخطط ، فإننا نشير إلى الجدول الذي أنشأناه أعلاه. يرجى ملاحظة أنه يمكنك تحديد أي موقع S3 في kinesis ، يتم استخدام المخطط فقط من الجدول. ولكن إذا حددت موقعًا آخر S3 ، فلن تعمل قراءة هذه السجلات من هذا الجدول.
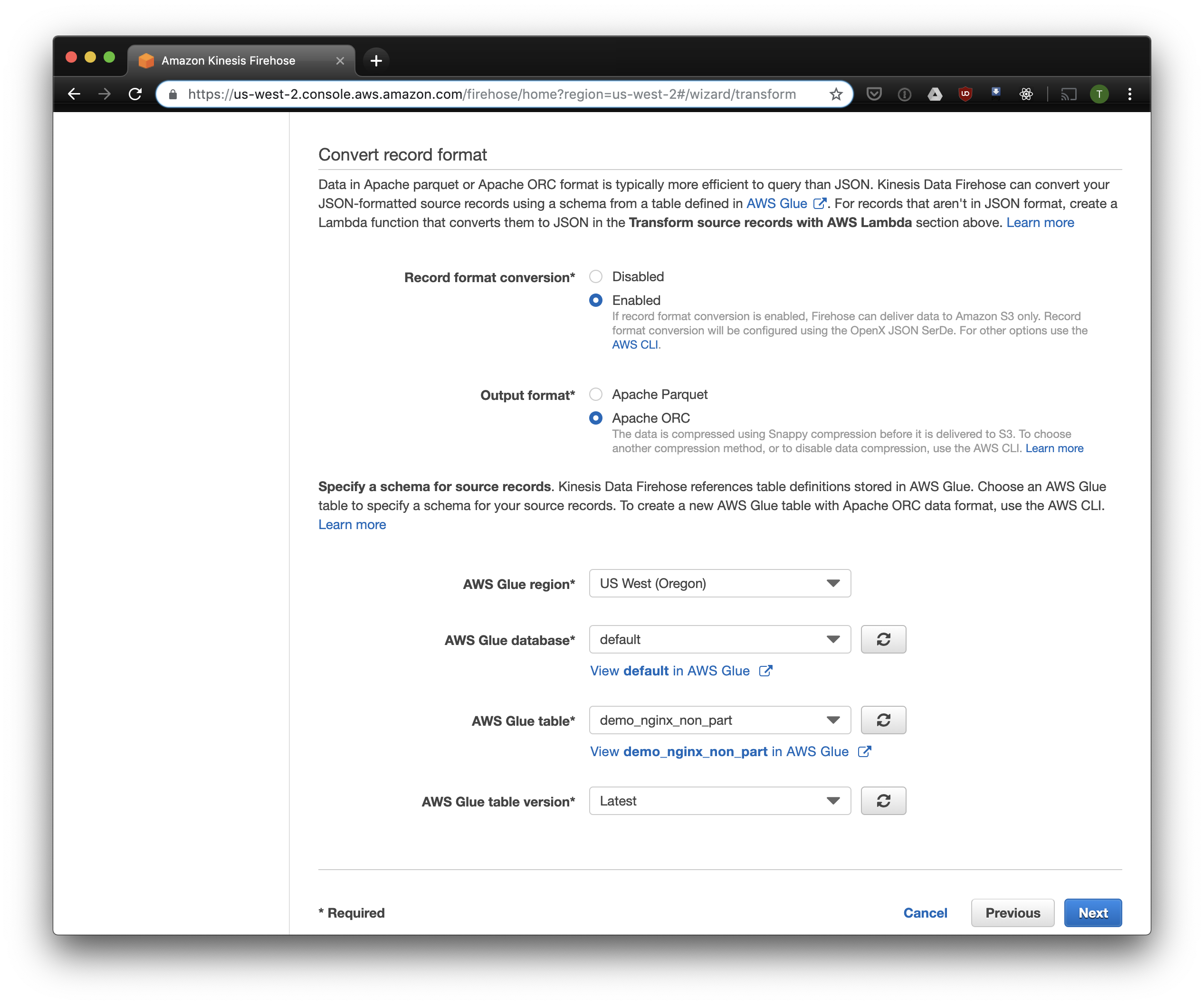
نختار S3 للتخزين والجرافة التي أنشأناها في وقت سابق. لا يعرف Aws Glue Crawler ، الذي سأتحدث عنه لاحقًا ، كيفية التعامل مع البادئات في دلو S3 ، لذلك من المهم تركه فارغًا.

يمكن تغيير الخيارات المتبقية حسب حملك ، وعادة ما أستخدم الخيارات الافتراضية. لاحظ أن ضغط S3 غير متوفر ، لكن ORC يستخدم الضغط الأصلي افتراضيًا.
Fluentd
الآن بعد أن قمنا بتهيئة تخزين واستلام السجلات ، تحتاج إلى تكوين إرسال. سوف نستخدم Fluentd لأني أحب روبي ، لكن يمكنك استخدام Logstash أو إرسال سجلات إلى kinesis مباشرة. يمكنك بدء تشغيل خادم Fluentd بعدة طرق ، سأتحدث عن عامل ميناء ، لأنه بسيط ومريح.
أولاً ، نحن بحاجة إلى ملف التكوين fluent.conf. قم بإنشائه وإضافة مصدر:
اكتب إلى الأمام
ميناء 24224
ربط 0.0.0.0
الآن يمكنك بدء خادم Fluentd. إذا كنت بحاجة إلى تكوين أكثر تقدمًا ، فإن Docker Hub لديه دليل مفصل ، بما في ذلك كيفية تجميع صورتك.
$ docker run \ -d \ -p 24224:24224 \ -p 24224:24224/udp \ -v /data:/fluentd/log \ -v <PATH-TO-FLUENT-CONF>:/fluentd/etc fluentd \ -c /fluentd/etc/fluent.conf fluent/fluentd:stable
يستخدم هذا التكوين مسار /fluentd/log المؤقت للسجلات قبل الإرسال. يمكنك الاستغناء عن هذا ، ولكن عند إعادة التشغيل ، يمكنك أن تخسر كل شيء في ذاكرة التخزين المؤقت. يمكن أيضًا استخدام أي منفذ ، 24224 هو منفذ Fluentd الافتراضي.
الآن بعد أن أصبح Fluentd يعمل ، يمكننا إرسال سجلات Nginx إلى هناك. عادةً ما نقوم بتشغيل Nginx في حاوية Docker ، وفي هذه الحالة يكون لدى Docker برنامج تشغيل سجل أصلي لـ Fluentd:
$ docker run \ --log-driver=fluentd \ --log-opt fluentd-address=<FLUENTD-SERVER-ADDRESS>\ --log-opt tag=\"{{.Name}}\" \ -v /some/content:/usr/share/nginx/html:ro \ -d \ nginx
إذا قمت بتشغيل Nginx بشكل مختلف ، يمكنك استخدام ملفات السجل ، فلويند لديها ملحق إضافي للملف .
أضف تحليل السجل المكوّن أعلاه إلى تكوين Fluent:
<filter YOUR-NGINX-TAG.*> @type parser key_name log emit_invalid_record_to_error false <parse> @type json </parse> </filter>
وإرسال سجلات إلى Kinesis باستخدام البرنامج المساعد kinesis firehose :
<match YOUR-NGINX-TAG.*> @type kinesis_firehose region region delivery_stream_name <YOUR-KINESIS-STREAM-NAME> aws_key_id <YOUR-AWS-KEY-ID> aws_sec_key <YOUR_AWS-SEC_KEY> </match>
أثينا
إذا قمت بتكوين كل شيء بشكل صحيح ، فبعد فترة من الوقت (بشكل افتراضي ، يكتب Kinesis البيانات المستلمة كل 10 دقائق) سترى ملفات السجل في S3. في قائمة مراقبة Kinesis Firehose ، يمكنك معرفة مقدار البيانات التي تتم كتابتها إلى S3 ، وكذلك الأخطاء. لا تنسَ منح حق الوصول للكتابة إلى S3 Bucket لدور Kinesis. إذا لم يتمكن Kinesis من تحليل شيء ما ، فسيضيف أخطاء في المجموعة نفسها.
الآن يمكنك رؤية البيانات في أثينا. دعنا نعثر على بعض الاستعلامات الجديدة التي قدمنا أخطاء لـ:
SELECT * FROM "db_name"."table_name" WHERE status > 499 ORDER BY created_at DESC limit 10;
مسح جميع السجلات لكل طلب
الآن تتم معالجة سجلاتنا ومكدستها في S3 في ORC ، مضغوطة وجاهزة للتحليل. Kinesis Firehose حتى وضعها في الدلائل لكل ساعة. ومع ذلك ، على الرغم من عدم تقسيم الجدول ، فإن أثينا ستقوم بتحميل بيانات طوال الوقت لكل استعلام ، مع استثناءات نادرة. هذه مشكلة كبيرة لسببين:
- يتزايد حجم البيانات باستمرار ، مما يؤدي إلى إبطاء الاستعلامات ؛
- يتم إعداد فواتير أثينا بناءً على كمية البيانات الممسوحة ضوئيًا ، بحد أدنى 10 ميغابايت لكل طلب.
لإصلاح ذلك ، نستخدم AWS Glue Crawler ، والذي سيقوم بمسح البيانات في S3 وتسجيل معلومات القسم في Glast Metastore. سيتيح لنا ذلك استخدام الأقسام كعامل تصفية للطلبات في أثينا ، وسيقوم فقط بفحص الأدلة المحددة في الطلب.
تخصيص الامازون الغراء الزاحف
يقوم Amazon Glue Crawler بفحص جميع البيانات الموجودة في دلو S3 وإنشاء جداول القسم. قم بإنشاء Glue Crawler من وحدة التحكم AWS Glue وأضف الدلو الذي تخزن فيه البيانات. يمكنك استخدام متتبع ارتباطات واحد لعدة مجموعات ، وفي هذه الحالة ، سيتم إنشاء جداول في قاعدة البيانات المحددة بأسماء تطابق أسماء المجموعات. إذا كنت تخطط لاستخدام هذه البيانات طوال الوقت ، فتأكد من ضبط جدول إطلاق Crawler ليناسب احتياجاتك. نحن نستخدم زاحف واحد لجميع الجداول ، والذي يعمل كل ساعة.
الجداول المقسمة
بعد بدء أول الزاحف ، يجب أن تظهر الجداول لكل مجموعة ممسوحة ضوئيًا في قاعدة البيانات المحددة في الإعدادات. افتح وحدة Athena وابحث عن الجدول باستخدام سجلات Nginx. دعنا نحاول قراءة شيء ما:
SELECT * FROM "default"."part_demo_kinesis_bucket" WHERE( partition_0 = '2019' AND partition_1 = '04' AND partition_2 = '08' AND partition_3 = '06' );
سيحدد هذا الاستعلام جميع السجلات التي تم استلامها من 6 صباحًا إلى 7 صباحًا في 8 أبريل 2019. ولكن كم أكثر فعالية من مجرد القراءة من جدول غير مقسم؟ دعنا نكتشف ونحدد نفس السجلات عن طريق ترشيحها حسب الطابع الزمني:
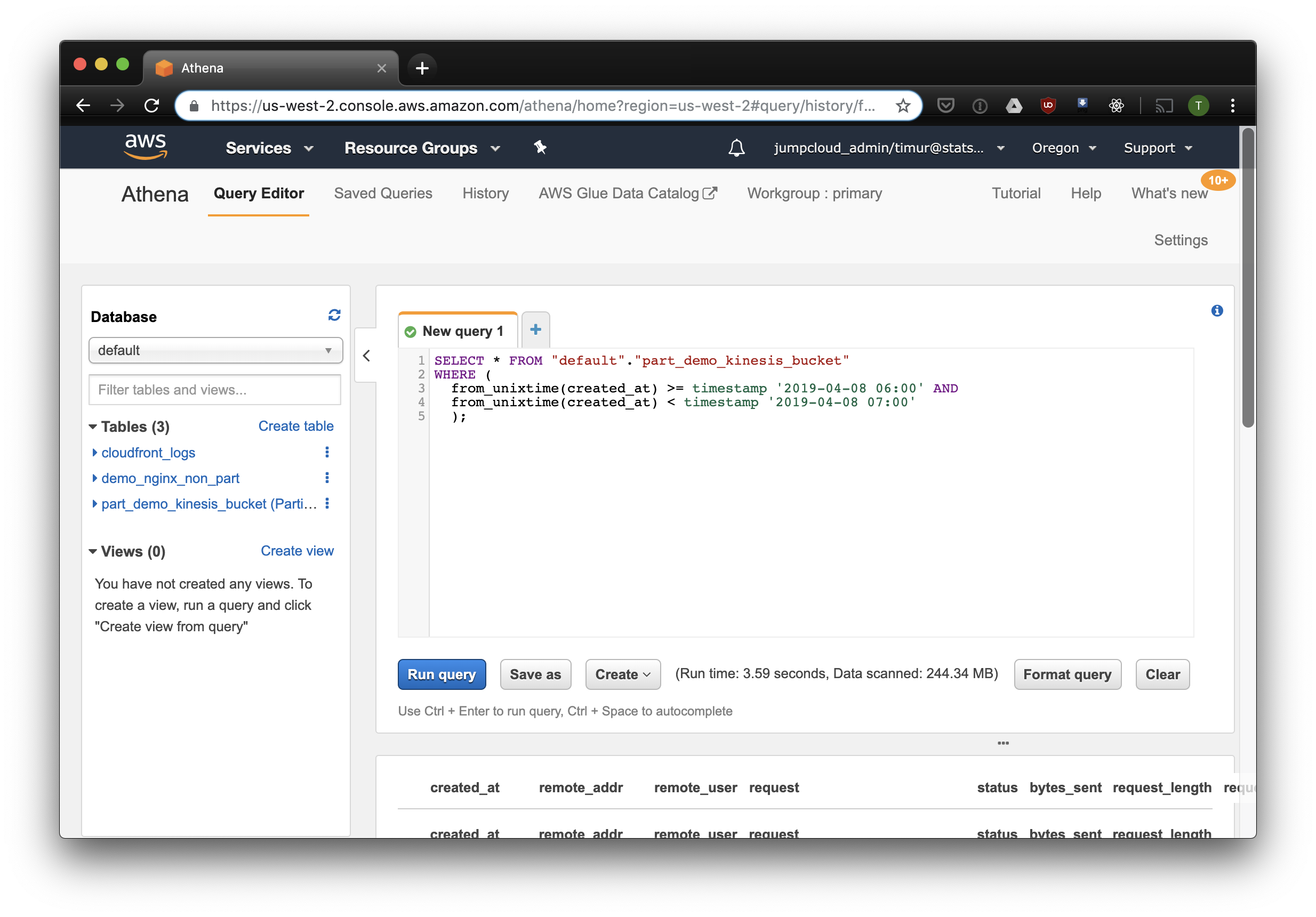
3.59 ثانية و 244.34 ميغابايت من البيانات على مجموعة البيانات ، حيث لا يوجد سوى أسبوع من السجلات. دعنا نحاول التصفية حسب الأقسام:
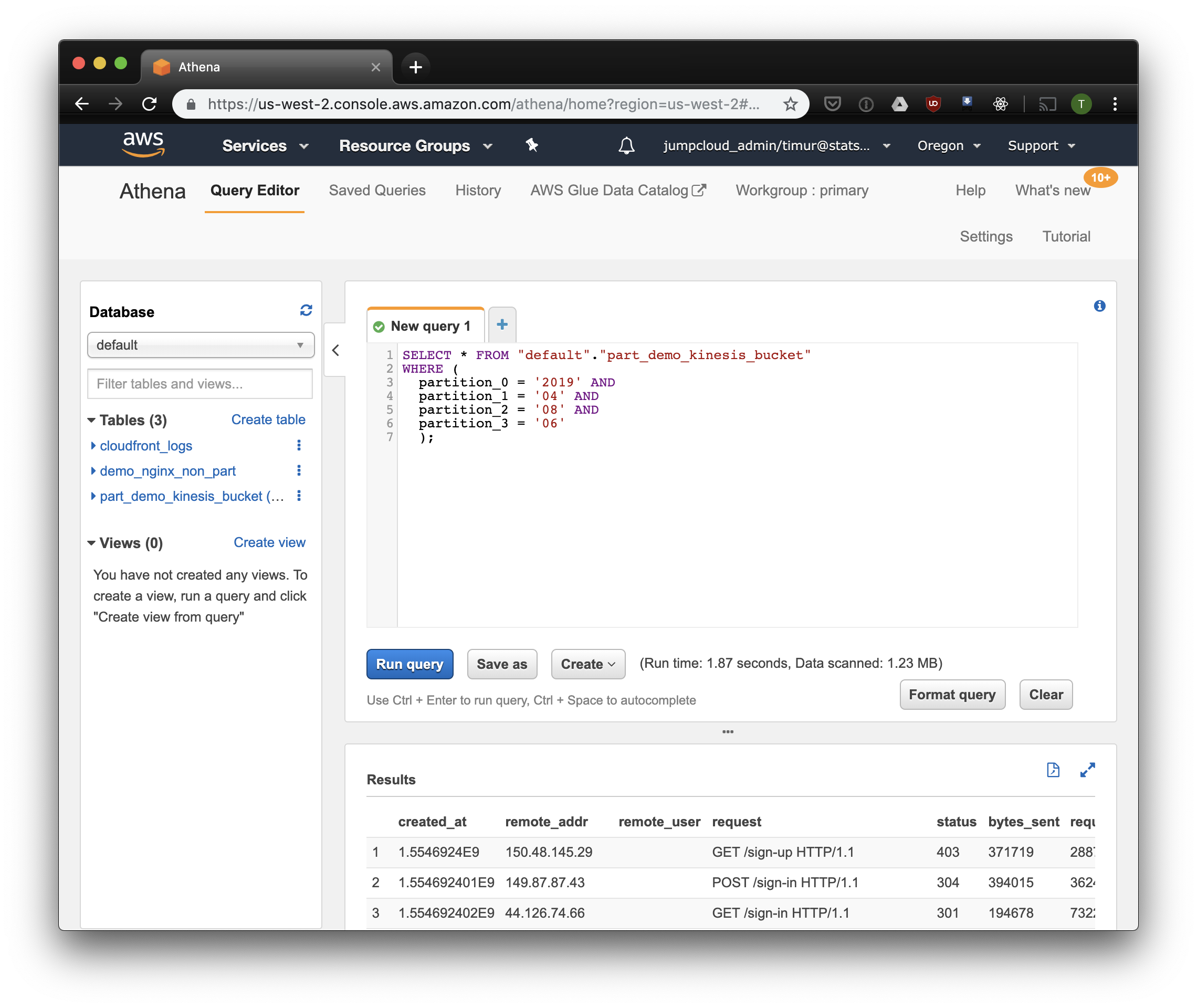
أسرع قليلاً ، لكن الأهم من ذلك - 1.23 ميغابايت فقط من البيانات! سيكون أرخص بكثير إذا لم يكن الحد الأدنى 10 ميغابايت لكل طلب في التسعير. لكن هذا أفضل بكثير على أي حال ، وفي مجموعات البيانات الكبيرة سيكون الفرق أكثر إثارة للإعجاب.
بناء لوحة القيادة باستخدام Cube.js
لإنشاء لوحة معلومات ، نستخدم إطار التحليل التحليلي Cube.js. له وظائف قليلة ، لكننا مهتمون بوظيفتين: القدرة على استخدام المرشحات تلقائيًا على الأقسام وتجميع البيانات مسبقًا. يستخدم مخطط البيانات المكتوب في Javascript لإنشاء SQL وتنفيذ استعلام قاعدة البيانات. كل ما هو مطلوب منا هو الإشارة إلى كيفية استخدام عامل تصفية القسم في مخطط البيانات.
دعونا إنشاء تطبيق جديد Cube.js. نظرًا لأننا نستخدم بالفعل AWS-stack ، فمن المنطقي استخدام Lambda للنشر. يمكنك استخدام القالب السريع للتوليد إذا كنت تخطط لاستضافة الواجهة الخلفية لـ Cube.js في Heroku أو Docker. تصف الوثائق طرق الاستضافة الأخرى.
$ npm install -g cubejs-cli $ cubejs create nginx-log-analytics -t serverless -d athena
تستخدم متغيرات البيئة لتكوين الوصول إلى قاعدة البيانات في cube.js. سيقوم المولد بإنشاء ملف .env يمكنك من خلاله تحديد المفاتيح الخاصة بـ Athena .
نحتاج الآن إلى نظام بيانات نوضح فيه كيفية تخزين سجلاتنا. هناك يمكنك تحديد كيفية قراءة مقاييس لوحات المعلومات.
في دليل schema ، قم بإنشاء ملف Logs.js فيما يلي مثال لنموذج البيانات لـ nginx:
رمز النموذج const partitionFilter = (from, to) => ` date(from_iso8601_timestamp(${from})) <= date_parse(partition_0 || partition_1 || partition_2, '%Y%m%d') AND date(from_iso8601_timestamp(${to})) >= date_parse(partition_0 || partition_1 || partition_2, '%Y%m%d') ` cube(`Logs`, { sql: ` select * from part_demo_kinesis_bucket WHERE ${FILTER_PARAMS.Logs.createdAt.filter(partitionFilter)} `, measures: { count: { type: `count`, }, errorCount: { type: `count`, filters: [ { sql: `${CUBE.isError} = 'Yes'` } ] }, errorRate: { type: `number`, sql: `100.0 * ${errorCount} / ${count}`, format: `percent` } }, dimensions: { status: { sql: `status`, type: `number` }, isError: { type: `string`, case: { when: [{ sql: `${CUBE}.status >= 400`, label: `Yes` }], else: { label: `No` } } }, createdAt: { sql: `from_unixtime(created_at)`, type: `time` } } });
نحن هنا نستخدم متغير FILTER_PARAMS لإنشاء استعلام SQL مع عامل تصفية القسم.
نحدد أيضًا المقاييس والمعلمات التي نريد عرضها على لوحة المعلومات ، ونحدد المجموعات المسبقة. ستنشئ Cube.js جداول إضافية تحتوي على بيانات مجمعة مسبقًا وستقوم تلقائيًا بتحديث البيانات فور توفرها. هذا لا يسرع الطلبات فحسب ، بل يقلل أيضًا من تكلفة استخدام Athena.
أضف هذه المعلومات إلى ملف مخطط البيانات:
preAggregations: { main: { type: `rollup`, measureReferences: [count, errorCount], dimensionReferences: [isError, status], timeDimensionReference: createdAt, granularity: `day`, partitionGranularity: `month`, refreshKey: { sql: FILTER_PARAMS.Logs.createdAt.filter((from, to) => `select CASE WHEN from_iso8601_timestamp(${to}) + interval '3' day > now() THEN date_trunc('hour', now()) END` ) } } }
في هذا النموذج ، نشير إلى أنه من الضروري تجميع البيانات مسبقًا لجميع المقاييس المستخدمة ، واستخدام التقسيم الشهري. يمكن التقسيم المسبق للتجميعات بشكل ملحوظ تسريع جمع البيانات وتحديثها.
الآن يمكننا وضع لوحة القيادة!
توفر الواجهة الخلفية Cube.js واجهة برمجة تطبيقات REST ومجموعة من مكتبات العملاء لأطر الواجهة الأمامية الشائعة. سوف نستخدم نسخة React من العميل لبناء لوحة القيادة. يوفر Cube.js البيانات فقط ، لذلك نحن بحاجة إلى مكتبة لتصورات - أنا أحب recharts ، ولكن يمكنك استخدام أي.
يقبل خادم Cube.js الطلب بتنسيق JSON ، مما يشير إلى المقاييس اللازمة. على سبيل المثال ، لحساب عدد الأخطاء التي قدمها Nginx في اليوم ، تحتاج إلى إرسال الطلب التالي:
{ "measures": ["Logs.errorCount"], "timeDimensions": [ { "dimension": "Logs.createdAt", "dateRange": ["2019-01-01", "2019-01-07"], "granularity": "day" } ] }
تثبيت عميل Cube.js ومكتبة مكون React عبر NPM:
$ npm i --save @cubejs-client/core @cubejs-client/react
نحن نستورد مكونات cubejs و QueryRenderer لتفريغ البيانات ، وجمع لوحة المعلومات:
رمز لوحة القيادة import React from 'react'; import { LineChart, Line, XAxis, YAxis } from 'recharts'; import cubejs from '@cubejs-client/core'; import { QueryRenderer } from '@cubejs-client/react'; const cubejsApi = cubejs( 'YOUR-CUBEJS-API-TOKEN', { apiUrl: 'http://localhost:4000/cubejs-api/v1' }, ); export default () => { return ( <QueryRenderer query={{ measures: ['Logs.errorCount'], timeDimensions: [{ dimension: 'Logs.createdAt', dateRange: ['2019-01-01', '2019-01-07'], granularity: 'day' }] }} cubejsApi={cubejsApi} render={({ resultSet }) => { if (!resultSet) { return 'Loading...'; } return ( <LineChart data={resultSet.rawData()}> <XAxis dataKey="Logs.createdAt"/> <YAxis/> <Line type="monotone" dataKey="Logs.errorCount" stroke="#8884d8"/> </LineChart> ); }} /> ) } ، import React from 'react'; import { LineChart, Line, XAxis, YAxis } from 'recharts'; import cubejs from '@cubejs-client/core'; import { QueryRenderer } from '@cubejs-client/react'; const cubejsApi = cubejs( 'YOUR-CUBEJS-API-TOKEN', { apiUrl: 'http://localhost:4000/cubejs-api/v1' }, ); export default () => { return ( <QueryRenderer query={{ measures: ['Logs.errorCount'], timeDimensions: [{ dimension: 'Logs.createdAt', dateRange: ['2019-01-01', '2019-01-07'], granularity: 'day' }] }} cubejsApi={cubejsApi} render={({ resultSet }) => { if (!resultSet) { return 'Loading...'; } return ( <LineChart data={resultSet.rawData()}> <XAxis dataKey="Logs.createdAt"/> <YAxis/> <Line type="monotone" dataKey="Logs.errorCount" stroke="#8884d8"/> </LineChart> ); }} /> ) }
تتوفر مصادر لوحة المعلومات على CodeSandbox .