في الشهر الماضي في NVIDIA GTC 2019 ، قدمت NVIDIA تطبيقًا جديدًا يحول الكرات الملونة البسيطة التي رسمها المستخدم إلى صور مذهلة واقعية.
تم بناء التطبيق على تقنية
الشبكات التنافسية التوليدية (GAN) ، والتي تعتمد على التعلم العميق. نفيديا نفسها يطلق عليها GauGAN - التورية تهدف إلى الإشارة إلى الفنان بول غوغان. تعتمد وظيفة GauGAN على خوارزمية SPADE الجديدة.
في هذه المقالة ، سأشرح كيف تعمل هذه التحفة الهندسية. ولجذب أكبر عدد ممكن من القراء المهتمين ، سأحاول تقديم وصف مفصل لكيفية عمل الشبكات العصبية التلافيفية. نظرًا لأن SPADE شبكة منافسة للجيل ، سأخبرك المزيد عنها. ولكن إذا كنت معتادًا بالفعل على هذا المصطلح ، يمكنك الانتقال على الفور إلى قسم "إرسال الصور إلى صورة".
جيل الصورة
دعنا نبدأ في فهم: في معظم تطبيقات التعليم العميق الحديثة ، يتم استخدام النوع التمييز العصبي (التمييز) ، و SPADE عبارة عن شبكة عصبية عامة (مولد).
تمارس التمييز
المصنف يصنف بيانات الإدخال. على سبيل المثال ، مصنف الصور هو أداة تمييز تقوم بالتقاط صورة وتحديد تسمية فئة مناسبة ، على سبيل المثال ، تعرف الصورة على أنها "كلب" أو "سيارة" أو "إشارة مرور" ، أي تحدد تسمية تصف الصورة بأكملها. عادة ما يتم تقديم الإخراج الذي حصل عليه المصنف على أنه ناقل للأرقام
حيث
هو رقم من 0 إلى 1 ، معربًا عن ثقة الشبكة في أن الصورة تنتمي إلى المحدد
الدرجة.
يمكن للمتميز أيضًا تجميع قائمة بالتصنيفات. يمكنه تصنيف كل بكسل من الصورة على أنها تنتمي إلى فئة "الأشخاص" أو "الآلات" (ما يسمى "التجزئة الدلالية").
 يأخذ المصنف صورة بثلاث قنوات (الأحمر والأخضر والأزرق) ويقارنها مع متجه الثقة في كل فئة ممكنة يمكن أن تمثلها الصورة.
يأخذ المصنف صورة بثلاث قنوات (الأحمر والأخضر والأزرق) ويقارنها مع متجه الثقة في كل فئة ممكنة يمكن أن تمثلها الصورة.نظرًا لأن الارتباط بين الصورة وفصلها معقد للغاية ، فإن الشبكات العصبية تمر به عبر مجموعة من الطبقات العديدة ، كل منها يعالجها "قليلاً" وينقل إخراجها إلى المستوى التالي من التفسير.
مولدات
تتلقى شبكة توليد مثل SPADE مجموعة بيانات وتسعى لإنشاء بيانات أصلية جديدة تبدو كما لو كانت تنتمي إلى فئة البيانات هذه. في الوقت نفسه ، يمكن أن تكون البيانات أي شيء: الأصوات أو اللغة أو أي شيء آخر ، لكننا سنركز على الصور. بشكل عام ، يعد إدخال البيانات في هذه الشبكة مجرد ناقل للأرقام العشوائية ، حيث تقوم كل مجموعة من مجموعات بيانات الإدخال بإنشاء صورتها الخاصة.
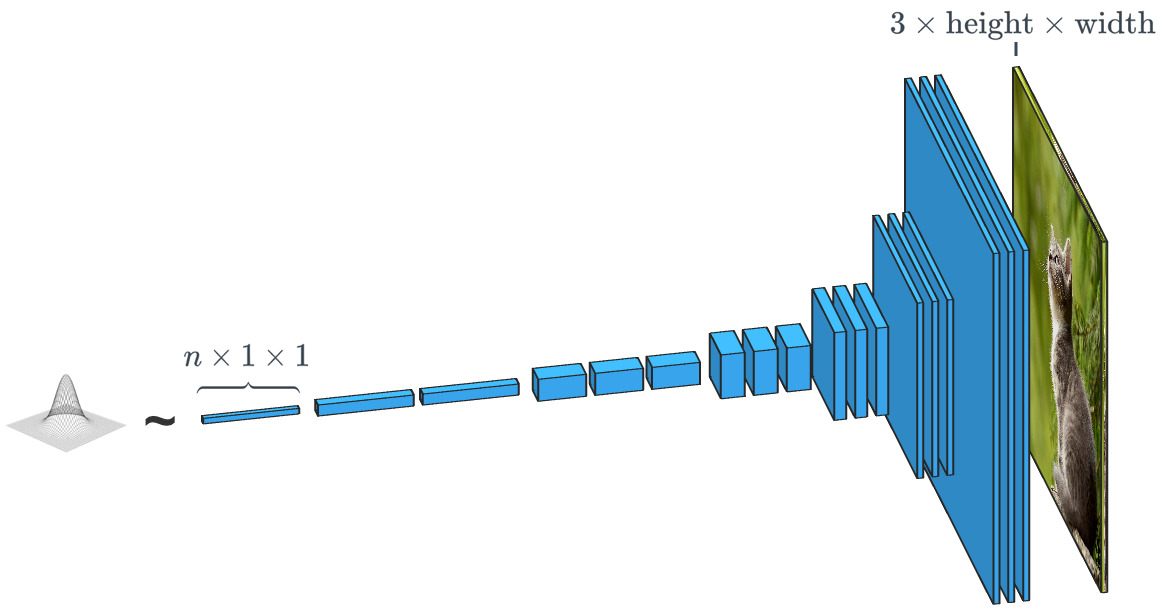 يعمل المولد استنادًا إلى ناقل إدخال عشوائي تقريبًا في مقابل مصنف الصورة. في مولدات "الفئة الشرطية" ، يكون ناقل الإدخال ، في الواقع ، هو ناقل فئة البيانات بأكملها.
يعمل المولد استنادًا إلى ناقل إدخال عشوائي تقريبًا في مقابل مصنف الصورة. في مولدات "الفئة الشرطية" ، يكون ناقل الإدخال ، في الواقع ، هو ناقل فئة البيانات بأكملها.كما رأينا بالفعل ، يستخدم SPADE أكثر بكثير من مجرد "ناقل عشوائي". يسترشد النظام بنوع من الرسم يسمى "خريطة تجزئة". هذا الأخير يشير إلى ما وأين للنشر. تجري SPADE العملية المقابلة للتجزئة الدلالية التي ذكرناها أعلاه. بشكل عام ، فإن المهمة التمييزية التي تحول نوع بيانات إلى آخر لها مهمة مشابهة ، ولكنها تأخذ مسارًا مختلفًا وغير عادي.
عادةً ما يستخدم المولدون والمميزون الحديثون شبكات تلافيفية لمعالجة بياناتهم. للحصول على مقدمة أكثر اكتمالا للشبكات العصبية التلافيفية (CNNs) ، راجع
منشور مضغ على كارنا أو
عمل أندريه كارباتي .
هناك اختلاف مهم واحد بين المصنف ومولد الصور ، وهو يكمن في كيفية تغيير حجم الصورة بالضبط أثناء معالجتها. يجب أن يقلل مصنف الصور إلى أن تفقد الصورة جميع المعلومات المكانية وتبقى الفئات فقط. يمكن تحقيق ذلك من خلال الجمع بين الطبقات ، أو من خلال استخدام الشبكات التلافيفية التي يتم من خلالها تمرير وحدات البكسل الفردية. المولد ، من ناحية أخرى ، يخلق صورة باستخدام العملية العكسية لـ "الالتواء" ، والتي تسمى النقل التلافيفي. غالبًا ما يكون مرتبكًا مع "فك
الارتباط" أو
"الإلتواء العكسي" .
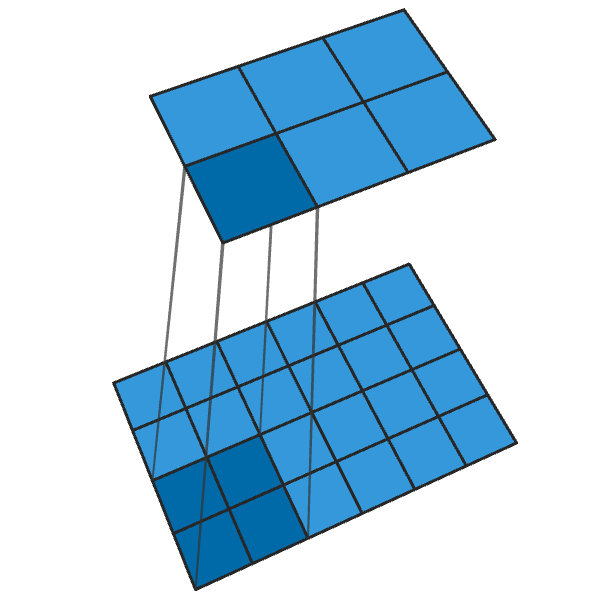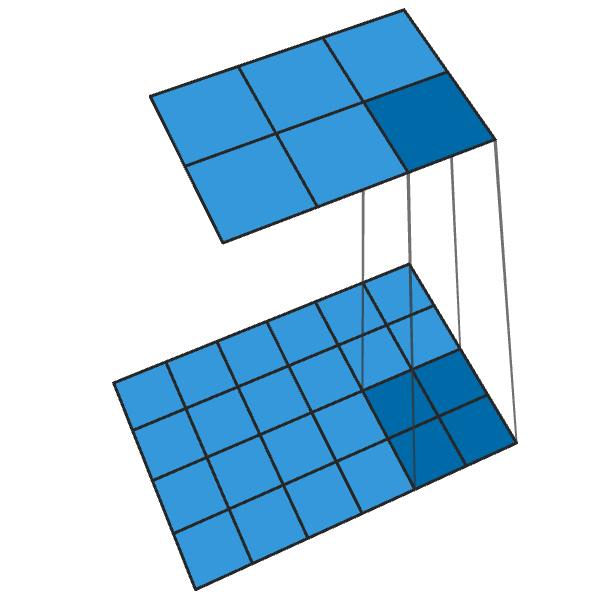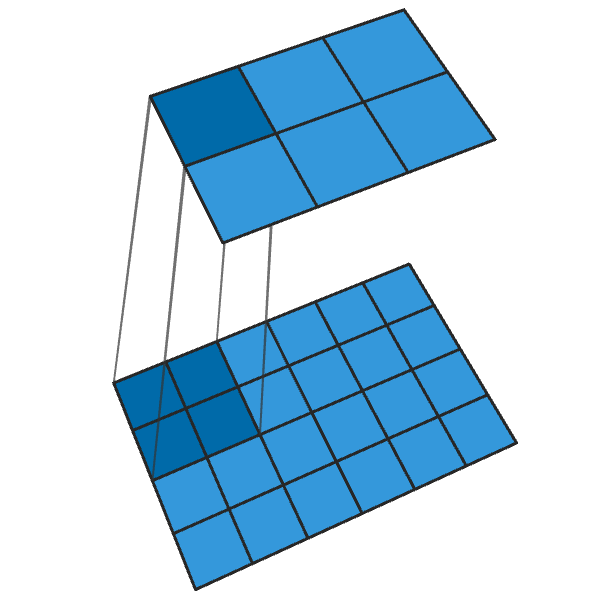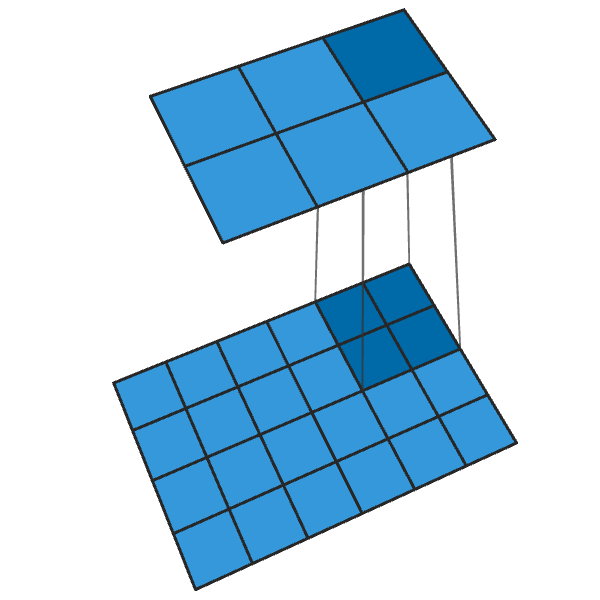
يحول الإلتواء التقليدي 2x2 مع خطوة "2" كل كتلة 2x2 إلى نقطة واحدة ، مما يقلل من حجم الإخراج بمقدار 1/2.

يقوم الإلتواء 2x2 المنقول مع خطوة "2" بإنشاء كتلة 2x2 من كل نقطة ، مما يزيد من حجم الخرج بمقدار 2 مرات.
مولد التدريب
من الناحية النظرية ، يمكن لشبكة العصبية التلافيفية توليد الصور كما هو موضح أعلاه. ولكن كيف ندربها؟ أي إذا أخذنا في الاعتبار مجموعة بيانات الصور المدخلة ، كيف يمكننا ضبط معلمات المولد (في حالتنا ، SPADE) بحيث ينشئ صورًا جديدة تبدو كما لو كانت تتوافق مع مجموعة البيانات المقترحة؟
للقيام بذلك ، تحتاج إلى مقارنة مع مصنفات الصور ، حيث يكون لكل منهم التسمية الصحيحة للفئة. معرفة متجه التنبؤ بالشبكة والفئة الصحيحة ، يمكننا استخدام خوارزمية backpropagation لتحديد معلمات تحديث الشبكة. هذا ضروري لزيادة دقته في تحديد الفئة المطلوبة وتقليل تأثير الفئات الأخرى.
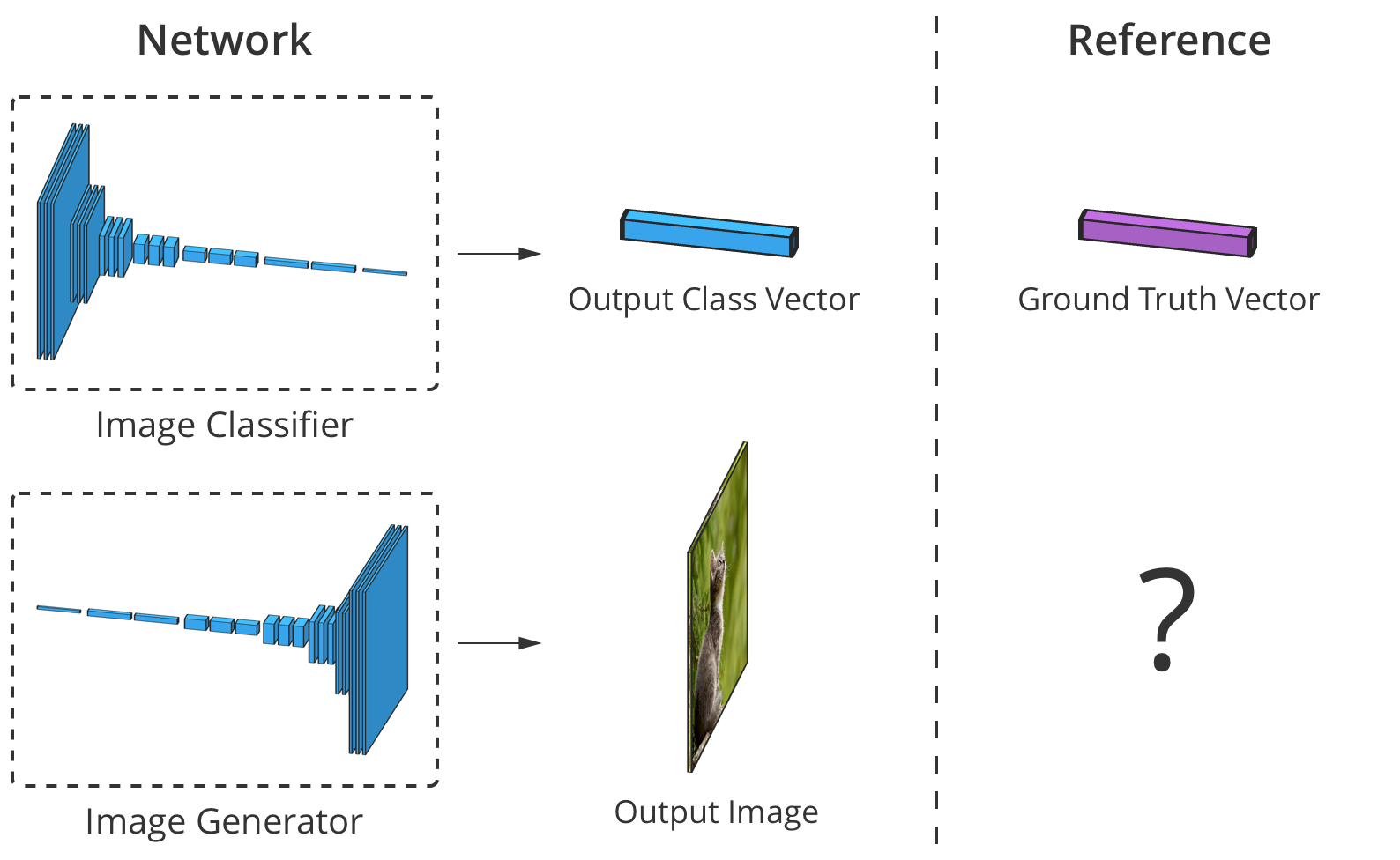 يمكن تقدير دقة مصنف الصور عن طريق مقارنة عنصر المخرجات حسب العنصر مع متجه الفئة الصحيح. لكن بالنسبة للمولدات ، لا توجد صورة إخراج "صحيحة".
يمكن تقدير دقة مصنف الصور عن طريق مقارنة عنصر المخرجات حسب العنصر مع متجه الفئة الصحيح. لكن بالنسبة للمولدات ، لا توجد صورة إخراج "صحيحة".تكمن المشكلة في أنه عندما ينشئ المولد صورة ، لا توجد قيم "صحيحة" لكل بكسل (لا يمكننا مقارنة النتيجة ، كما في حالة المصنف استنادًا إلى قاعدة تم إعدادها مسبقًا ، تقريبًا Trans.). من الناحية النظرية ، فإن أي صورة تبدو قابلة للتصديق وتشبه البيانات المستهدفة صالحة ، حتى لو كانت قيم البكسل فيها مختلفة تمامًا عن الصور الحقيقية.
لذا ، كيف يمكننا إخبار المولد بأي بيكسلات يجب أن يغير إنتاجها وكيف يمكنه إنشاء صور أكثر واقعية (أي كيفية إعطاء "إشارة خطأ")؟ لقد فكر الباحثون في هذا السؤال كثيرًا ، وفي الحقيقة كان الأمر صعبًا للغاية. معظم الأفكار ، مثل حساب متوسط "المسافة" للصور الحقيقية ، تنتج ضبابية ، وصور ذات جودة رديئة.
من الناحية المثالية ، يمكننا "قياس" مدى واقعية الصور التي يتم إنشاؤها من خلال استخدام مفهوم "رفيع المستوى" ، مثل "ما مدى صعوبة تمييز هذه الصورة عن الصورة الحقيقية؟" ...
شبكات الخصومة التوليدية
هذا هو بالضبط ما تم تنفيذه كجزء من
Goodfellow et al. ، 2014 . تتمثل الفكرة في إنشاء الصور باستخدام شبكتين عصبيتين بدلاً من واحدة: شبكة واحدة -
مولد ، والثاني هو مصنف الصورة (التمييز). تتمثل مهمة أداة التمييز في التمييز بين الصور الناتجة للمولد وبين الصور الحقيقية ومجموعة البيانات الأولية (يتم تصنيف فئات هذه الصور على أنها "وهمية" و "حقيقية"). مهمة المولد هي خداع المُميّز عن طريق إنشاء صور تشبه قدر الإمكان الصور الموجودة في مجموعة البيانات. يمكننا أن نقول أن المولد والمميز هم معارضون في هذه العملية. ومن هنا جاءت تسميته:
شبكة الخصومة التوليدية .
كيف يساعدنا هذا؟ الآن يمكننا استخدام رسالة خطأ تعتمد فقط على تنبؤ المُميِّز: قيمة من 0 ("خطأ") إلى 1 ("حقيقي"). نظرًا لأن أداة التمييز هي شبكة عصبية ، يمكننا مشاركة استنتاجاتها حول الأخطاء مع منشئ الصور. بمعنى أنه يمكن للمميز أن يخبر المولد أين وكيف يجب أن يعدل صوره من أجل تحسين "خداع" المُميّز (أي ، كيفية زيادة واقعية صوره).
في عملية تعلم كيفية العثور على صور مزيفة ، يعطي المُميِّز المولد تعليقات أفضل وأفضل على الطريقة التي يمكن بها للأخيرة تحسين عملها. وبالتالي ، يقوم المُميِّز
بوظيفة "تعلم الخسارة" للمولد.
جان الصغيرة المجيدة
تتبع GAN التي نظرنا فيها في عملها المنطق الموصوف أعلاه. له تمييز
يحلل الصورة
ويحصل على القيمة
من 0 إلى 1 ، مما يعكس درجة ثقته في أن الصورة حقيقية أو مزيفة من قبل المولد. مولده
يحصل على ناقل عشوائي للأرقام الموزعة بشكل طبيعي
ويعرض الصورة
التي يمكن أن يخدعها التمييز (في الواقع ، هذه الصورة
)
إحدى المشكلات التي لم نناقشها هي كيفية تدريب شبكة GAN وما هي
وظيفة خسارة المطورين التي تستخدمها لقياس أداء الشبكة. بشكل عام ، يجب زيادة وظيفة الخسارة حيث يتم تدريب المميّز وتناقصه أثناء تدريب المولد. تستخدم وظيفة الفقد للمصدر GAN المعلمتين التاليتين. الأول هو
يمثل الدرجة التي يصنف بها المُميِّز الصور الحقيقية على أنها حقيقية. والثاني هو مدى اكتشاف المُميّز للصور المزيفة:
$ inline $ \ start {equation *} \ mathcal {L} _ \ text {GAN} (D، G) = \ underbrace {E _ {\ vec {x} \ sim p_ \ text {data}} [\ log D ( \ vec {x})]} _ {\ text {دقة في الصور الحقيقية}} + \ underbrace {E _ {\ vec {z} \ sim \ mathcal {N}} [\ log (1 - D (G (\ vec {z}))]} _ {\ text {precision on fakes}} \ end {equation *} $ inline $
الممي
يستمد ادعائه بأن الصورة حقيقية. فمن المنطقي منذ ذلك الحين
يزيد عندما يعتبر المميّز x حقيقي. عندما يكتشف المُميّز الصور المزيفة بشكل أفضل ، تزداد أيضًا قيمة التعبير.
(يبدأ في السعي ل 1) ، منذ ذلك الحين
سوف تميل إلى 0.
في الممارسة العملية ، نقوم بتقييم الدقة باستخدام مجموعات كاملة من الصور. نحن نأخذ الكثير (ولكن ليس بأي حال من الأحوال) من الصور الحقيقية
والعديد من المتجهات العشوائية
للحصول على المتوسطات وفقًا للصيغة أعلاه. ثم نختار الأخطاء الشائعة ومجموعة البيانات.
بمرور الوقت ، يؤدي هذا إلى نتائج مثيرة للاهتمام:
 Goodfellow GAN محاكاة مجموعات البيانات MNIST و TFD و CIFAR-10. تعد صور الكنتور هي الأقرب في مجموعة البيانات للمزيفات المجاورة.
Goodfellow GAN محاكاة مجموعات البيانات MNIST و TFD و CIFAR-10. تعد صور الكنتور هي الأقرب في مجموعة البيانات للمزيفات المجاورة.كل هذا كان رائعا قبل 4.5 سنوات. لحسن الحظ ، كما يظهر SPADE والشبكات الأخرى ، يستمر التعلم الآلي في التقدم بسرعة.
مشاكل التدريب
الشبكات التنافسية التوليدية تشتهر بتعقيدها في الإعداد وعدم استقرار العمل. تتمثل إحدى المشكلات في أنه إذا كان المولد متقدمًا جدًا عن المميّز في وتيرة التدريب ، فسيتم تضييق اختياره للصور على تلك التي تساعده على خداع المميّز. في الواقع ، نتيجة لذلك ، يأتي تدريب المولد لإنشاء صورة واحدة عالمية لخداع المميّز. وتسمى هذه المشكلة "وضع الانهيار".

وضع انهيار GAN مشابه لوضع Goodfellow. يرجى ملاحظة أن العديد من صور غرفة النوم هذه تشبه إلى حد كبير بعضها البعض.
مصدرمشكلة أخرى هي أنه عندما يخدع المولد التمييز بشكل فعال
، وهو يعمل مع التدرج صغير جدا ، لذلك
لا يمكن الحصول على بيانات كافية للعثور على الإجابة الحقيقية ، والتي تبدو فيها هذه الصورة أكثر واقعية.
كانت جهود الباحثين لحل هذه المشكلات تهدف أساسًا إلى تغيير هيكل وظيفة الخسارة. أحد التغييرات البسيطة التي اقترحها
Xudong Mao et al. ، 2016 هو استبدال وظيفة الخسارة
لبضع وظائف بسيطة
، والتي تستند إلى المربعات من مساحة أصغر. وهذا يؤدي إلى تحقيق الاستقرار في عملية التدريب ، والحصول على صور أفضل وفرصة أقل للانهيار باستخدام تدرجات غير مخمد.
مشكلة أخرى واجهها الباحثون هي صعوبة الحصول على صور عالية الدقة ، جزئياً لأن صورة أكثر تفصيلًا تمنح المُميِّز مزيدًا من المعلومات لاكتشاف الصور المزيفة. تبدأ شبكات GAN الحديثة في تدريب الشبكة باستخدام صور منخفضة الدقة وإضافة طبقات أكثر وأكثر تدريجية حتى يتم الوصول إلى حجم الصورة المطلوب.
 تزيد الإضافة التدريجية للطبقات ذات الدقة العالية أثناء تدريب GAN بشكل كبير من ثبات العملية بأكملها ، وكذلك سرعة وجودة الصورة الناتجة.
تزيد الإضافة التدريجية للطبقات ذات الدقة العالية أثناء تدريب GAN بشكل كبير من ثبات العملية بأكملها ، وكذلك سرعة وجودة الصورة الناتجة.بث صورة إلى صورة
لقد تحدثنا حتى الآن عن كيفية إنشاء صور من مجموعات عشوائية من بيانات الإدخال. لكن SPADE لا يستخدم فقط البيانات العشوائية. تستخدم هذه الشبكة صورة تسمى خريطة التقسيم: تقوم بتعيين فئة مادة لكل بكسل (على سبيل المثال ، العشب ، الخشب ، الماء ، الحجر ، السماء). من هذه الصورة ، تكون البطاقة SPADE وتقوم بإنشاء ما يشبه الصورة. وهذا ما يسمى "صورة لصورة البث".
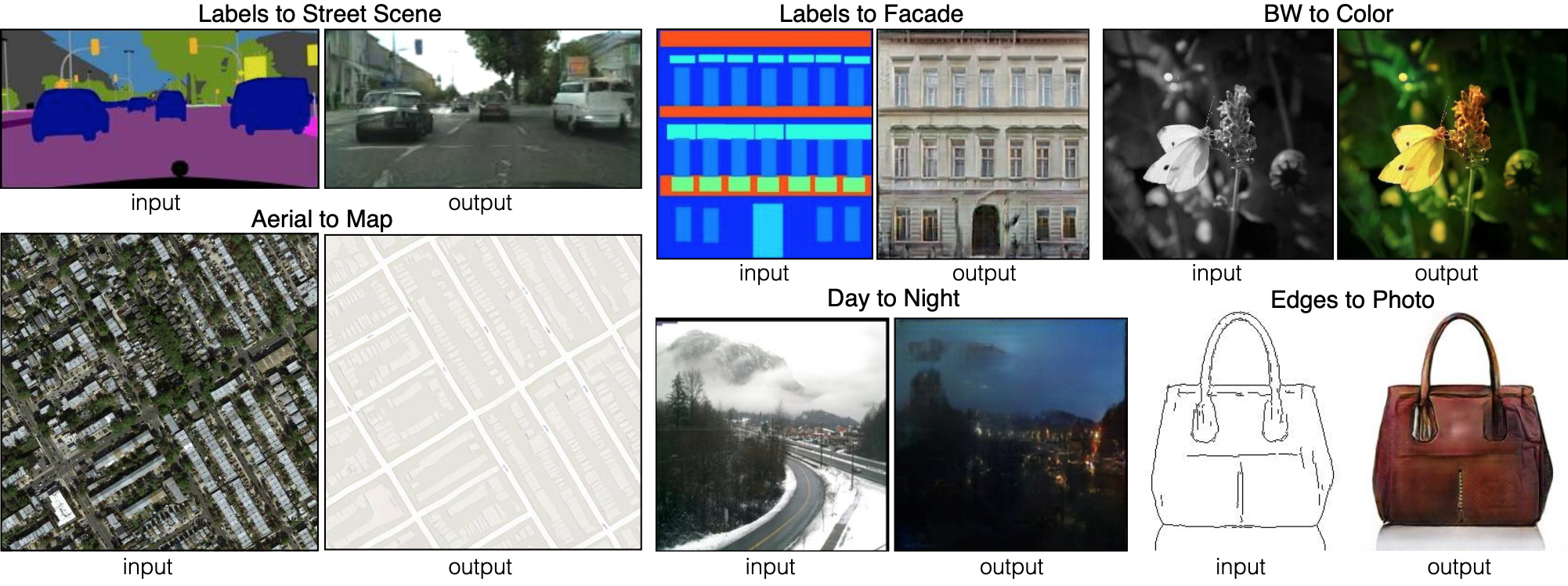 ستة أنواع مختلفة من عمليات البث من صورة إلى صورة التي أظهرتها pix2pix. Pix2pix هو سلف الشبكتين ، والتي سنناقشها أكثر: pix2pixHD و SPADE.
ستة أنواع مختلفة من عمليات البث من صورة إلى صورة التي أظهرتها pix2pix. Pix2pix هو سلف الشبكتين ، والتي سنناقشها أكثر: pix2pixHD و SPADE.لكي يتعلم المولد هذا النهج ، فإنه يحتاج إلى مجموعة من خرائط التقسيم والصور المقابلة. نحن نقوم بتعديل بنية GAN بحيث يحصل كل من المولد والمميز على خريطة تجزئة. المولد ، بالطبع ، يحتاج إلى خريطة من أجل معرفة "طريقة الرسم". يحتاج المُميّز أيضًا إلى التأكد من أن المولد يضع الأشياء الصحيحة في الأماكن الصحيحة.
أثناء التدريب ، يتعلم المولد عدم وضع العشب حيث يتم الإشارة إلى "السماء" على خريطة التقسيم ، لأنه بخلاف ذلك يمكن للمميّز اكتشاف صورة مزيفة بسهولة ، وهكذا.
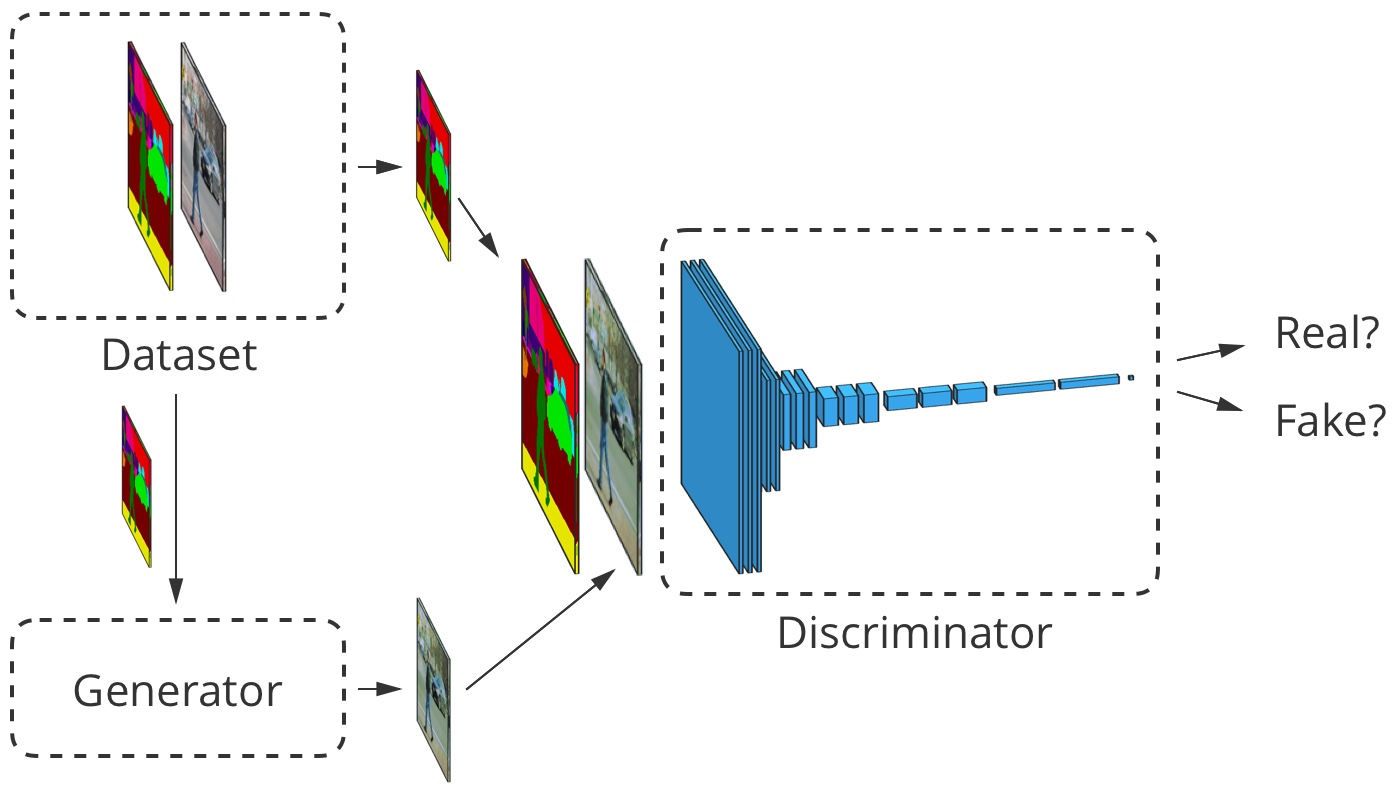 بالنسبة للترجمة من صورة إلى صورة ، يتم قبول صورة الإدخال من قِبل كل من المولد والمميز. يتلقى المُميِّز بالإضافة إلى ذلك إخراج المولد أو المخرج الحقيقي من مجموعة بيانات التدريب. مثال
بالنسبة للترجمة من صورة إلى صورة ، يتم قبول صورة الإدخال من قِبل كل من المولد والمميز. يتلقى المُميِّز بالإضافة إلى ذلك إخراج المولد أو المخرج الحقيقي من مجموعة بيانات التدريب. مثالصورة المترجم التنمية
دعونا نلقي نظرة على مترجم حقيقي لصورة إلى صورة:
pix2pixHD . بالمناسبة ، تم تصميم SPADE للجزء الأكبر في صورة ومثال pix2pixHD.
بالنسبة لمترجم صورة إلى صورة ، يقوم مولدنا بإنشاء صورة ويقبلها كمدخل. يمكننا فقط استخدام خريطة طبقة تلافيفية ، لكن بما أن الطبقات التلافيفية تجمع القيم في المساحات الصغيرة فقط ، نحتاج إلى طبقات كثيرة جدًا لنقل معلومات الصورة عالية الدقة.
pix2pixHD يحل هذه المشكلة بشكل أكثر كفاءة بمساعدة "Encoder" ، مما يقلل من حجم الصورة المدخلة ، تليها "Decoder" ، مما يزيد من الحجم للحصول على صورة الإخراج. كما سنرى قريبًا ، يتمتع SPADE بحل أكثر أناقة لا يتطلب تشفيرًا.
 مخطط شبكة Pix2pixHD على مستوى "مرتفع". تشير الكتل "المتبقية" و "+ العملية" إلى تقنية "تخطي التوصيلات" من الشبكة العصبية المتبقية . هناك كتل تخطي في الشبكة ، مترابطة في التشفير وفك التشفير.
مخطط شبكة Pix2pixHD على مستوى "مرتفع". تشير الكتل "المتبقية" و "+ العملية" إلى تقنية "تخطي التوصيلات" من الشبكة العصبية المتبقية . هناك كتل تخطي في الشبكة ، مترابطة في التشفير وفك التشفير.التطبيع الدفعي مشكلة
تستخدم جميع الشبكات العصبية التلافيفية الحديثة تقريبًا للدفعات أو أحد نظائرها لتسريع وتثبيت عملية التدريب. يؤدي تنشيط كل قناة إلى تغيير الوسط إلى 0 والانحراف المعياري إلى 1 قبل زوج من معلمات القناة
و
دعهم يزيلوا الطابع الطبيعي مرة أخرى.
لسوء الحظ ، يضر التطبيع الدفعي بالمولدات ، مما يجعل من الصعب على الشبكة تنفيذ بعض أنواع معالجة الصور. بدلاً من تطبيع مجموعة من الصور ، يستخدم pix2pixHD
معيارًا للتطبيع ، يعمل على تطبيع كل صورة على حدة.
Pix2pixHD التدريب
الشبكات العصبية الحديثة ، مثل pix2pixHD و SPADE ، تقيس الواقعية لصور المخرجات الخاصة بها بطريقة مختلفة قليلاً عن ما تم وصفه للتصميم الأصلي لشبكات التنافس التوليدي.
لحل مشكلة إنشاء صور عالية الدقة ، يستخدم pix2pixHD ثلاثة أدوات تمييز من نفس الهيكل ، يستقبل كل منها صورة الإخراج بمقياس مختلف (الحجم العادي ، يتم تقليله مرتين ومخفض بمقدار 4 مرات).
يستخدم Pix2pixHD
، ويتضمن أيضًا عنصرًا آخر مصممًا لجعل استنتاجات المولد أكثر واقعية (بغض النظر عما إذا كان هذا يساعد على خداع المميّز). هذا البند
« » — ,
.
, :
, .
 pix2pixHD , ( ), ().
pix2pixHD , ( ), ()., , «» 70×70 ( ). «» .
,
, ,
. , .
 pix2pixHD . CelebA , .
pix2pixHD . CelebA , .pix2pixHD?
, . , pix2pixHD .
, pix2pixHD , , , . , . «» ()
. β- , : , «», «», «» - .
pix2pixHD . , , .— SPADE.
: SPADE
- : - () (SPADE).
SPADE , , γ, β, , . , 2 .
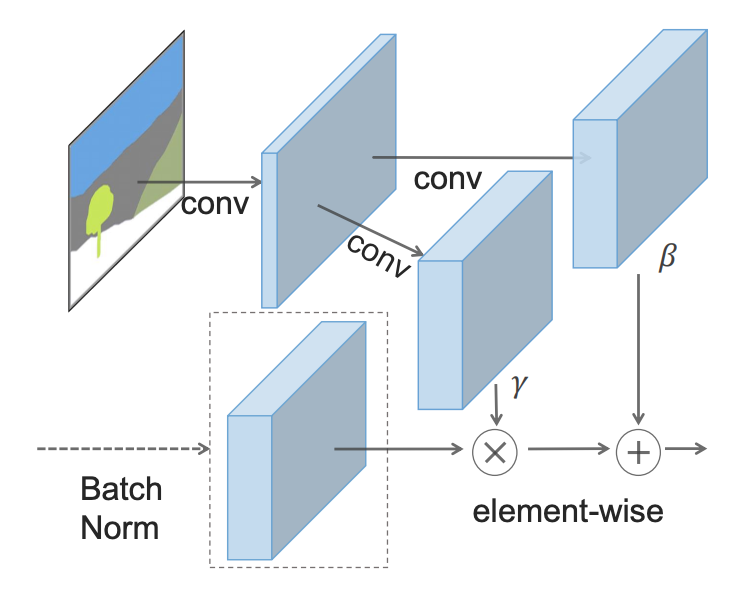 , SPADE .
, SPADE .SPADE « », ( ):
 SPADE pix2pixHD
SPADE pix2pixHD, «» , . GAN, . (« »). «» pix2pixHD, .
SPADE , pix2pixHD, :
hinge loss .
:
 SPADE pix2pixHD
SPADE pix2pixHD, SPADE . . GauGAN «» , . , - SPADE , «» , .
, SPADE , «» .
, , «». SPADE , , ? 55, «».
, , 5x5 . , .
SPADE , , , , pix2pixHD. , .
SPADE — (, , , ).
 SPADE , .
SPADE , .: ,
, . , , SPADE , , .
, . , ,
.
هذه هي الطريقة التي يعمل بها SPADE / GaiGAN. آمل أن يكون هذا المقال راضيا عن فضولك حول كيفية عمل نظام NVIDIA الجديد. يمكنك الاتصال بي عبر TwitterAdamDanielKin أو البريد الإلكتروني adam@AdamDKing.com.