
كيف تكتب اسمك في التاريخ للأبد؟ أول من يطير إلى القمر؟ أول من يلتقي بعقل أجنبي؟ لدينا طريقة أكثر بساطة - يمكنك أن تتناسب مع معيار لغة C ++.
يقدم إريك نيبلر ، مؤلف كتاب C ++ Ranges ، مثالاً جيدًا. "تذكر هذا. وكتب على تويتر يوم 19 فبراير 2019 وهو اليوم الذي تحدث فيه مصطلح "nibloid" لأول مرة في اجتماع WG21.
في الواقع ، إذا ذهبت إلى CppReference ، في قسم cpp / algorithm / rangescpp / algorithm / ranges ، ستجد العديد من المراجع هناك (niebloid). لهذا الغرض ، تم إنشاء قالب ويكي dsc_niebloid منفصل.
لسوء الحظ ، لم أجد أي مقالة رسمية كاملة حول هذا الموضوع وقررت أن أكتب مقالتي الخاصة. هذه رحلة صغيرة ولكنها رائعة إلى هاوية رواد الفضاء المعماريين ، حيث يمكننا الغطس في هاوية جنون ADL والتعرف على nibloids.
هام: أنا لست عامل لحام حقيقيًا ، لكنني javist الذي يصحح الأخطاء في كود C ++ أحيانًا حسب الضرورة. إذا كنت تأخذ بعض الوقت للمساعدة في العثور على أخطاء في التفكير ، فسيكون ذلك لطيفًا. "ساعد داشا المسافر في جمع شيء معقول."
بحث
تحتاج أولا إلى اتخاذ قرار بشأن الشروط. هذه أشياء معروفة ، ولكن "الصريح أفضل من الضمني" ، لذلك سنناقشها بشكل منفصل. لا أستخدم مصطلحات حقيقية باللغة الروسية ، لكنني أستخدم اللغة الإنجليزية بدلاً من ذلك. يعد ذلك ضروريًا لأنه حتى كلمة "التقييد" في سياق هذه المقالة يمكن أن ترتبط بثلاثة إصدارات إنجليزية على الأقل ، والفرق بينها مهم للفهم.
على سبيل المثال ، في C ++ هناك مفهوم البحث عن اسم أو ، بمعنى آخر ، بحث: عندما يظهر اسم في برنامج ما ، يتم تجميعه مع إعلانه أثناء التحويل البرمجي.
يمكن أن يكون البحث مؤهلًا (إذا كان الاسم على يمين عامل إذن النطاق :: :) ، وغير ماهر في حالات أخرى. إذا كان البحث مؤهلاً ، فإننا نتجاوز الأعضاء المطابقين في الفصل أو مساحة الاسم أو التعداد. يمكن للمرء أن يسمي هذا الإصدار "الكامل" من التسجيل (كما يبدو أنه تم في ترجمة Straustrup) ، ولكن من الأفضل ترك الإملاء الأصلي ، لأن هذا يشير إلى نوع محدد للغاية من الاكتمال.
ADL
إذا لم يكن البحث مؤهلاً ، فيجب علينا أن نفهم بالضبط مكان البحث عن الاسم. وهنا يتم تضمين ميزة خاصة تسمى ADL: البحث المعتمد على الوسيطة ، وإلا - البحث عن Koenig (الشخص الذي صاغ مصطلح "anti-pattern" ، والذي يعتبر رمزيًا قليلاً في ضوء النص التالي). يصفها نيكولاي جوتيس في كتابه "مكتبة C ++ القياسية: برنامج تعليمي ومرجع" على النحو التالي: "النقطة هي أنك لست بحاجة إلى تأهيل مساحة اسم الوظيفة إذا تم تعريف واحد على الأقل من أنواع الوسيطات في مساحة اسم هذه الوظيفة."
ما ينبغي أن تبدو؟
#include <iostream> int main() { // . // , operator<< , ADL , // std std::operator<<(std::ostream&, const char*) std::cout << "Test\n"; // . - . operator<<(std::cout, "Test\n"); // same, using function call notation // : // Error: 'endl' is not declared in this namespace. // endl(), ADL . std::cout << endl; // . // , ADL. // std, endl std. endl(std::cout); // : // Error: 'endl' is not declared in this namespace. // , - (endl) - . (endl)(std::cout); }
النزول الى الجحيم مع ADL
قد يبدو بسيطا. أم لا؟ أولاً ، اعتمادًا على نوع الوسيطة ، يعمل ADL في تسع طرق مختلفة ، للقتل باستخدام المكنسة.
ثانيا ، عملي بحت ، تخيل أن لدينا نوع من وظيفة المبادلة. اتضح أن std::swap(obj1,obj2); using std::swap; swap(obj1, obj2); using std::swap; swap(obj1, obj2); يمكن أن تتصرف بشكل مختلف تماما. إذا تم تمكين ADL ، ثم من عدة مقايضات مختلفة ، يتم تحديد الذي تحتاجه بالفعل بناءً على مساحات أسماء الوسائط! اعتمادًا على وجهة النظر ، يمكن اعتبار هذا المصطلح مثالًا إيجابيًا وسلبيًا :-)
إذا بدا لك أن هذا لا يكفي ، يمكنك إسقاط الحطب في فرن القبعة. وقد كتب هذا مؤخرًا جيدًا بواسطة آرثر أودوير . آمل ألا يعاقبني على استخدام مثاله.
تخيل أن لديك برنامج من هذا النوع:
#include <stdio.h> namespace A { struct A {}; void call(void (*f)()) { f(); } } void f() { puts("Hello world"); } int main() { call(f); }
بالطبع ، لا يتم تجميعها مع وجود خطأ:
error: use of undeclared identifier 'call'; did you mean 'A::call'? call(f); ^~~~ A::call
ولكن إذا أضفت حمولة زائدة غير مستخدمة بالكامل من الوظيفة f ، فسيعمل كل شيء!
#include <stdio.h> namespace A { struct A {}; void call(void (*f)()) { f(); } } void f() { puts("Hello world"); } void f(A::A); // UNUSED int main() { call(f); }
في Visual Studio ، ستظل تتكسر ، لكن هذا هو مصيرها ، لا تعمل.
كيف حدث هذا؟ دعنا نتطرق إلى المعيار (بدون الترجمة ، لأن مثل هذه الترجمة ستكون عبارة عن mishmash استثنائية من الكلمات الطنانة):
إذا كانت الوسيطة هي اسم أو عنوان مجموعة من الوظائف الزائدة و / أو قوالب الوظائف ، فإن الكيانات ومساحات الأسماء المرتبطة بها هي اتحاد لتلك المرتبطة بكل من أعضاء المجموعة ، أي الكيانات ومساحات الأسماء المرتبطة بمعلمتها. أنواع ونوع العودة. [...] بالإضافة إلى ذلك ، إذا تم تسمية المجموعة المذكورة أعلاه من الوظائف التي تم تحميلها بشكل زائد بمعرف قالب ، فإن الكيانات ومساحات الأسماء المرتبطة بها تشمل أيضًا وسيطات قالب النوع الخاصة به ووسائط قالب القالب الخاصة به.
الآن تأخذ رمز مثل هذا:
#include <stdio.h> namespace B { struct B {}; void call(void (*f)()) { f(); } } template<class T> void f() { puts("Hello world"); } int main() { call(f<B::B>); }
في كلتا الحالتين ، يتم الحصول على الوسائط التي ليس لها نوع. f و f<B::B> هما اسماء مجموعات الدالات المثقلة (من التعريف أعلاه) ، وليس لهذه المجموعة أي نوع. لطي التحميل الزائد في وظيفة واحدة ، يجب أن تفهم نوع مؤشر الوظيفة الأنسب لأفضل حمل زائد call . لذلك ، تحتاج إلى جمع مجموعة من المرشحين call ، مما يعني بدء بحث عن اسم call . ولهذا ADL سيبدأ!
لكن عادة بالنسبة ADL يجب أن نعرف أنواع الحجج! وهنا يقطع Clang و ICC و MSVC عن طريق الخطأ كما يلي (لكن دول مجلس التعاون الخليجي لا تنفجر):
[build] ..\..\main.cpp(15,5): error: use of undeclared identifier 'call'; did you mean 'B::call'? [build] call(f<B::B>); [build] ^~~~ [build] B::call [build] ..\..\main.cpp(4,10): note: 'B::call' declared here [build] void call(void (*f)()) { [build] ^
حتى المبدعين من المجمعين مع ADL لديهم علاقة متوترة قليلا.
حسنًا ، هل ما زالت ADL تبدو فكرة جيدة؟ من ناحية ، لم نعد بحاجة إلى كتابة مثل هذا الرمز السلبي بطريقة مهذبة:
std::cout << "Hello, World!" << std::endl; std::operator<<(std::operator<<(std::cout, "Hello, World!"), "\n");
من ناحية أخرى ، تبادلنا باختصار حقيقة أن هناك الآن نظامًا يعمل بطريقة غير إنسانية تمامًا. قصة مأساوية ورائعة حول كيف يمكن لسهولة كتابة Halloworld أن تؤثر على اللغة بأكملها على مدى عقود.
النطاقات والمفاهيم
إذا قمت بفتح وصف مكتبة Nibler Rangers ، فحتى قبل ذكر nibloids ، ستتعثر على العديد من العلامات الأخرى المسماة (concept) . هذه بالفعل أشياء جميلة ، ولكن فقط في حالة (لكبار السن و javists) سأذكرك بما هي عليه .
تسمى المفاهيم مجموعات القيود المسموح بها والتي تنطبق على وسيطات القوالب لتحديد أفضل وظائف التحميل الزائد وتخصصات القوالب الأنسب.
template <typename T> concept bool HasStringFunc = requires(T a) { { to_string(a) } -> string; }; void print(HasStringFunc a) { cout << to_string(a) << endl; }
لقد فرضنا هنا قيودًا على أن الوسيطة يجب أن تتضمن دالة to_string تقوم بإرجاع سلسلة. إذا حاولنا وضع بعض الألعاب داخل print التي لا تندرج تحت القيود ، فلن يتم تجميع هذا الرمز.
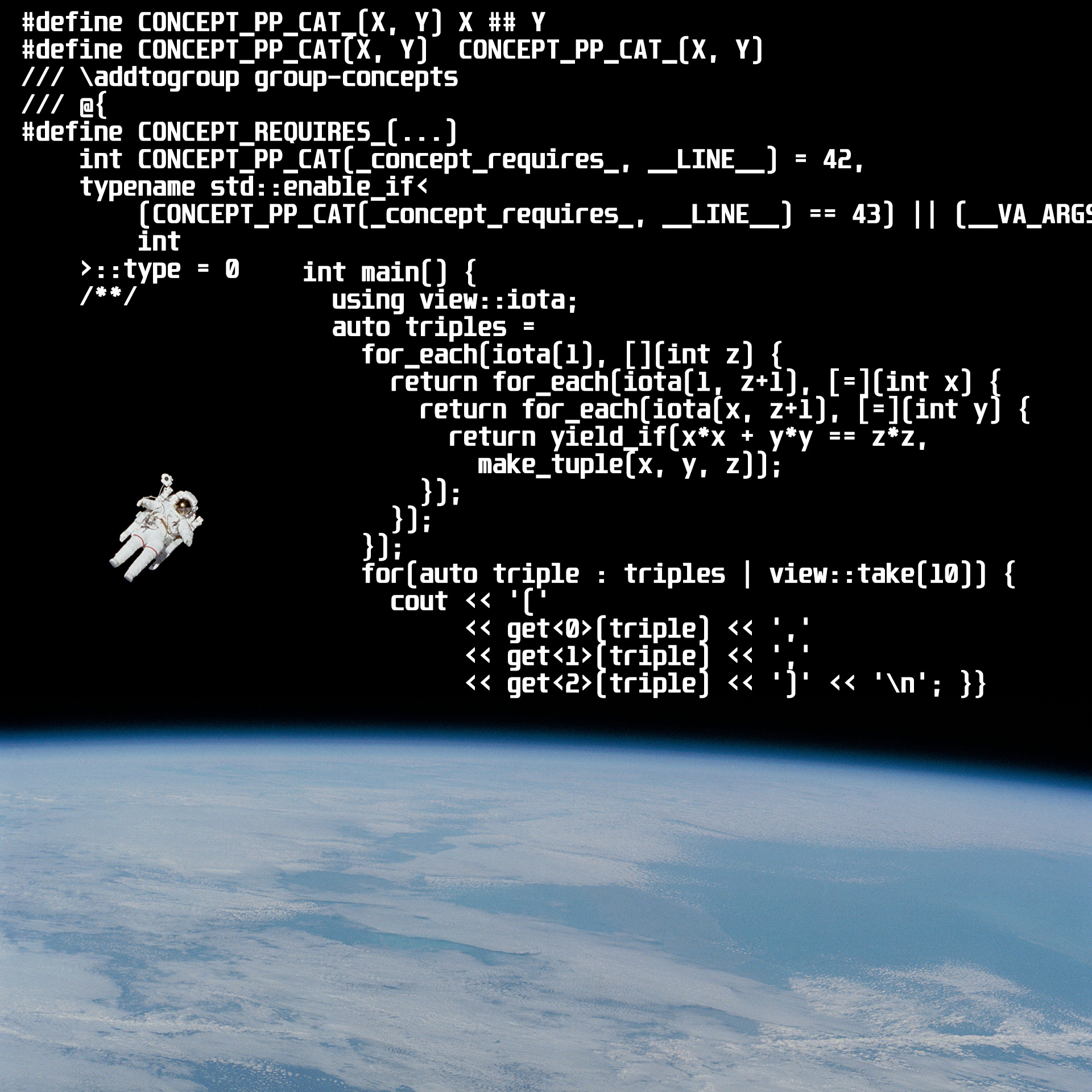
هذا يبسط إلى حد كبير رمز. على سبيل المثال ، راجع كيف قام Nibler بالفرز في النطاقات v3 ، والذي يعمل في الإصدار C ++ 11/14/17. هناك كود رائع مثل هذا:
#define CONCEPT_PP_CAT_(X, Y) X ## Y #define CONCEPT_PP_CAT(X, Y) CONCEPT_PP_CAT_(X, Y)
بحيث يمكنك لاحقًا القيام بما يلي:
struct Sortable_ { template<typename Rng, typename C = ordered_less, typename P = ident, typename I = iterator_t<Rng>> auto requires_() -> decltype( concepts::valid_expr( concepts::model_of<concepts::ForwardRange, Rng>(), concepts::is_true(ranges::Sortable<I, C, P>()) )); }; using Sortable = concepts::models<Sortable_, Rng, C, P>; template<typename Rng, typename C = ordered_less, typename P = ident, CONCEPT_REQUIRES_(!Sortable<Rng, C, P>())> void operator()(Rng &&, C && = C{}, P && = P{}) const { ...
آمل أنك تريد بالفعل رؤية كل هذا واستخدام المفاهيم المعدة في برنامج تجميع جديد.
نقاط التخصيص
الشيء المثير للاهتمام التالي الذي يمكن العثور عليه في المعيار هو customization.point.object . يتم استخدامها بنشاط في مكتبة Nibler Ranges.
نقطة التخصيص هي وظيفة تستخدمها المكتبة القياسية بحيث يمكن تحميلها بشكل زائد على أنواع المستخدمين في مساحة اسم المستخدم ، ويمكن العثور على هذه الأحمال الزائدة باستخدام ADL.
تم تصميم نقاط التخصيص مع وضع المبادئ المعمارية التالية في cust (يُعتبر cust اسمًا لبعض نقاط التخصيص الوهمية):
- تتم كتابة التعليمات البرمجية التي تستدعي
cust إما في النموذج المؤهل std::cust(a) أو بشكل غير مؤهل: using std::cust; cust(a); using std::cust; cust(a); . كلا الإدخالات يجب أن تتصرف متطابقة. على وجه الخصوص ، يجب أن يعثروا على أي حمل زائد للمستخدم في مساحة الاسم المرتبطة بالوسائط. - رمز يستخدم الحجز في شكل إدخال
std::cust; cust(a); std::cust; cust(a); يجب ألا تكون قادرة على التحايل على القيود المفروضة على std::cust . - يجب أن تعمل مكالمات النقطة المخصصة بكفاءة وعلى النحو الأمثل على أي مترجم حديث إلى حد ما.
- يجب ألا ينشئ القرار أي انتهاكات جديدة لقاعدة التعريف الفردي (ODR) .
لفهم ما هو عليه ، يمكنك إلقاء نظرة على N4381 . للوهلة الأولى ، يبدو أنها طريقة لكتابة إصداراتك الخاصة من begin swap data وما شابهها ، والمكتبة القياسية تلتقطها باستخدام ADL.
والسؤال هو ، كيف يختلف هذا عن الممارسة القديمة ، عندما يكتب المستخدم عبئا زائدا على البعض begin لنوعه ومساحة الاسم الخاصة به؟ ولماذا هم حتى الأشياء؟
في الواقع ، هذه هي مثيلات الكائنات الوظيفية في std . الغرض منها هو سحب الشيكات من النوع الأول (المصممة كمفاهيم) على جميع الوسائط في صف واحد ، ثم إرسال الدعوة إلى الوظيفة الصحيحة في std أو التخلي عنها للبيع في ADL.
في الواقع ، ليس هذا هو الشيء الذي ستستخدمه في برنامج غير مكتبة عادي. هذه إحدى ميزات المكتبة القياسية ، والتي ستتيح لك إضافة التحقق من المفاهيم عند نقاط الامتداد المستقبلية ، والتي بدورها ستؤدي إلى عرض أخطاء أكثر جمالا ومفهومة إذا قمت بإفساد شيء ما في القوالب.
النهج الحالي لنقاط التخصيص لديه اثنين من المشاكل. أولاً ، من السهل جدًا كسر كل شيء. تخيل هذا الكود:
template<class T> void f(T& t1, T& t2) { using std::swap; swap(t1, t2); }
إذا أجرينا بطريق الخطأ مكالمة مؤهلة إلى std::swap(t1, t2) فلن تبدأ نسخة swap الخاصة بنا أبدًا ، بصرف النظر عما نضعه هناك. ولكن الأهم من ذلك ، أنه لا توجد طريقة لإرفاق اختبارات المفهوم مركزيًا بتطبيقات الوظائف المخصصة هذه. في N4381 يكتبون:
"تخيل أنه في يوم من الأيام في المستقبل ، ستتطلب std::begin أن يتم تصميم Range كمفهوم Range . إضافة مثل هذا التقييد ببساطة لن يكون له أي تأثير على الكود اصطلاحياً باستخدام std::begin :
using std::begin; begin(a);
بعد كل شيء ، إذا تم إرسال استدعاء begin إلى الإصدار المثقل الذي أنشأه المستخدم ، فسيتم ببساطة تجاهل القيود المفروضة على std::begin . "
الحل الموصوف في propozal يحل كلتا المشكلتين ، لهذا نستخدم النهج من هذا المضاربة في تنفيذ std::begin start (يمكنك إلقاء نظرة على godbolt ):
#include <utility> namespace my_std { namespace detail { struct begin_fn { /* , begin(arg) arg.begin(). - . */ template <class T> auto operator()(T&& arg) const { return impl(arg, 1L); } template <class T> auto impl(T&& arg, int) const requires requires { begin(std::declval<T>()); } { return begin(arg); } // ADL template <class T> auto impl(T&& arg, long) const requires requires { std::declval<T>().begin(); } { return arg.begin(); } // ... }; } // inline constexpr detail::begin_fn begin{}; }
يتم إجراء مكالمة مؤهلة من بعض my_std::begin(someObject) دائمًا من خلال my_std::detail::begin_fn - وهذا أمر جيد. ماذا يحدث لمكالمة غير مؤهلة؟ دعنا نقرأ ورقتنا مرة أخرى:
"في الحالة التي يتم فيها استدعاء my_std::begin بدون مؤهل فور ظهور my_std::begin داخل النطاق ، يتغير الموقف إلى حد ما. في المرحلة الأولى من البحث ، begin حل الاسم إلى الكائن العمومي my_std::begin . نظرًا لأن البحث عثر على كائن ، وليس وظيفة ، لم يتم تنفيذ المرحلة الثانية من البحث. بمعنى آخر ، إذا كان my_std::begin عبارة عن كائن ، فعندئذٍ استخدام construction my_std::detail::begin_fn begin; begin(a); my_std::detail::begin_fn begin; begin(a); ما يعادل ببساطة std::begin(a); "وكما رأينا ، يطلق هذا ADL مخصصًا."
هذا هو السبب في أن التحقق من صحة المفهوم يمكن القيام به في كائن دالة في std قبل أن تستدعي ADL الوظيفة التي يوفرها المستخدم. لا توجد وسيلة لخداع هذا السلوك.
كيف يتم تخصيص نقاط التخصيص؟
في الواقع ، "كائن نقطة التخصيص" (CPO) ليس اسمًا جيدًا. من الاسم ، ليس من الواضح كيف تتوسع ، وما هي الآليات الموجودة أسفل الغطاء ، وما هي الوظائف التي تفضلها ...
مما يقودنا إلى مصطلح "nibloid". إن nibloid هو CPO الذي يستدعي الدالة X إذا تم تعريفها في الفئة ، وإلا فإنه يستدعي الدالة X إذا كانت هناك وظيفة حرة مناسبة ، وإلا فإنه يحاول تنفيذ بعض الاستعاضة عن الوظيفة X.
على سبيل المثال ، ranges::swap nibloid ranges::swap عند استدعاء ranges::swap(a, b) سيحاول أولاً استدعاء a.swap(b) . إذا لم يكن هناك مثل هذه الطريقة ، swap(a, b) استدعاء swap(a, b) باستخدام ADL. إذا لم ينجح هذا ، فحاول auto tmp = std::move(a); a = std::move(b); b = std::move(tmp) auto tmp = std::move(a); a = std::move(b); b = std::move(tmp) auto tmp = std::move(a); a = std::move(b); b = std::move(tmp) .
النتائج
كما مات مازحًا على Twitter ، اقترح ديف مرة واحدة جعل الأشياء الوظيفية "تعمل" مع ADL تمامًا مثل الوظائف العادية ، لأسباب الاتساق. المفارقة هي أن قدرتهم على تعطيل ADL وأن يكونوا غير مرئيين له أصبحت الآن مزاياها الرئيسية.
كان هذا المقال بأكمله تحضيرا لهذا.
" لقد فهمت كل شيء ، هذا كل شيء. هل تستمع ؟
هل سبق لك أن نظرت إلى شيء ما ، وبدا مجنونًا ، ثم في ضوء مختلف
أشياء مجنونة رؤيتهم طبيعية؟

لا تخف. لا تخف. أشعر أنني بحالة جيدة جدا في القلب. كل شيء سيكون على ما يرام. لم أشعر أنني بحالة جيدة لسنوات عديدة. كل شيء سيكون على ما يرام.
دقيقة من الإعلانات. بالفعل هذا الأسبوع ، من 19 إلى 20 أبريل ، سيعقد C ++ Russia 2019 - وهو مؤتمر مليء بالعروض التقديمية المتشددة حول اللغة نفسها والقضايا العملية مثل تعدد الإصدارات والأداء. بالمناسبة ، افتتح المؤتمر نيكولاي خوسوتيس ، مؤلف مكتبة C ++ القياسية: دروس ومراجع ، المذكورة في المقال. يمكنك التعرف على البرنامج وشراء التذاكر على الموقع الرسمي . هناك القليل من الوقت المتبقي ، هذه هي الفرصة الأخيرة.