مقدمة
في كثير من الأحيان ، يواجه المستخدمون والمطورون والمسؤولون في MS SQL Server DBMSs مشاكل في أداء قاعدة البيانات أو DBMS بشكل عام ، وبالتالي فإن مراقبة MS SQL Server لها صلة كبيرة.
هذه المقالة هي إضافة إلى المقالة
باستخدام Zabbix لمراقبة قاعدة بيانات MS SQL Server ، وسوف تبحث في بعض جوانب مراقبة MS SQL Server ، على وجه الخصوص: كيفية تحديد الموارد المفقودة بسرعة ، وكذلك توصيات لإعداد إشارات التتبع.
لكي تعمل البرامج النصية التالية ، يجب عليك إنشاء مخطط inf في قاعدة البيانات المطلوبة كما يلي:
إنشاء مخطط الوقود النووي المشعuse <_>; go create schema inf;
طريقة للكشف عن نقص ذاكرة الوصول العشوائي
المؤشر الأول لنقص ذاكرة الوصول العشوائي هو الحال عندما يقوم مثيل MS SQL Server بتناول جميع ذاكرة الوصول العشوائي المخصصة له.
للقيام بذلك ، قم بإنشاء طريقة عرض inf.vRAM التالية:
إنشاء عرض inf.vRAM CREATE view [inf].[vRAM] as select a.[TotalAvailOSRam_Mb]
ثم يمكنك تحديد أن مثيل MS SQL Server يستهلك كل الذاكرة المخصصة له بواسطة الاستعلام التالي:
select SQL_server_physical_memory_in_use_Mb, SQL_server_committed_target_Mb from [inf].[vRAM];
إذا كان مؤشر SQL_server_physical_memory_in_use_Mb لا يقل باستمرار عن SQL_server_committed_target_Mb ، فأنت بحاجة إلى التحقق من إحصائيات التوقعات.
لتحديد نقص ذاكرة الوصول العشوائي من خلال إحصاءات التوقع ، قم بإنشاء طريقة عرض inf.vWaits:
إنشاء عرض inf.vWaits CREATE view [inf].[vWaits] as WITH [Waits] AS (SELECT [wait_type],
في هذه الحالة ، يمكنك تحديد نقص ذاكرة الوصول العشوائي عن طريق الاستعلام التالي:
SELECT [Percentage] ,[AvgWait_S] FROM [inf].[vWaits] where [WaitType] in ( 'PAGEIOLATCH_XX', 'RESOURCE_SEMAPHORE', 'RESOURCE_SEMAPHORE_QUERY_COMPILE' );
تحتاج هنا إلى الانتباه إلى أداء Percentage و AvgWait_S. إذا كانت كبيرة في مجملها ، فهناك احتمال كبير أن ذاكرة الوصول العشوائي ليست كافية لمثيل MS SQL Server. يتم تحديد القيم الأساسية بشكل فردي لكل نظام. ومع ذلك ، يمكنك البدء بالقياس التالي: Percentage> = 1 و AvgWait_S> = 0.005.
لإخراج مؤشرات إلى نظام مراقبة (على سبيل المثال ، Zabbix) ، يمكنك إنشاء الاستفسارين التاليين:
- كم النسبة المئوية التي تشغلها أنواع التوقعات الخاصة بذاكرة الوصول العشوائي (مجموع كل هذه الأنواع من التوقعات):
select coalesce(sum([Percentage]), 0.00) as [Percentage] from [inf].[vWaits] where [WaitType] in ( 'PAGEIOLATCH_XX', 'RESOURCE_SEMAPHORE', 'RESOURCE_SEMAPHORE_QUERY_COMPILE' );
- عدد الميلي ثانية التي تشغلها أنواع التوقعات الخاصة بذاكرة الوصول العشوائي (الحد الأقصى لقيمة كل التأخيرات المتوسطة لجميع أنواع التوقعات):
select coalesce(max([AvgWait_S])*1000, 0.00) as [AvgWait_MS] from [inf].[vWaits] where [WaitType] in ( 'PAGEIOLATCH_XX', 'RESOURCE_SEMAPHORE', 'RESOURCE_SEMAPHORE_QUERY_COMPILE' );
استنادًا إلى ديناميات القيم التي تم الحصول عليها لهذين المؤشرين ، يمكننا استنتاج ما إذا كان هناك ذاكرة RAM كافية لمثيل MS SQL Server.
وحدة المعالجة المركزية طريقة الكشف الزائد
لتحديد نقص وقت وحدة المعالجة المركزية ، ما عليك سوى استخدام طريقة عرض نظام sys.dm_os_schedulers. هنا ، إذا كان مؤشر runnable_tasks_count أكبر دائمًا من 1 ، فهناك احتمال كبير بأن عدد المراكز لا يكفي لمثيل MS SQL Server.
لعرض المؤشر في نظام مراقبة (على سبيل المثال ، Zabbix) ، يمكنك إنشاء الاستعلام التالي:
select max([runnable_tasks_count]) as [runnable_tasks_count] from sys.dm_os_schedulers where scheduler_id<255;
استنادًا إلى ديناميات القيم التي تم الحصول عليها لهذا المؤشر ، يمكننا استنتاج ما إذا كان هناك وقت معالج كافٍ (عدد مراكز وحدة المعالجة المركزية) لمثيل MS SQL Server.
ومع ذلك ، من المهم تذكر حقيقة أن الطلبات نفسها يمكن أن تطلب مؤشرات ترابط متعددة مرة واحدة. وأحيانًا يتعذر على المُحسِّن تقييم مدى تعقيد الطلب نفسه بشكل صحيح. ثم يمكن تخصيص الطلب الكثير من مؤشرات الترابط التي في وقت معين لا يمكن معالجتها في وقت واحد. ويؤدي ذلك أيضًا إلى حدوث نوع من الانتظار المرتبط بنقص وقت المعالج ، ونمو قائمة الانتظار للمبرمجين الذين يستخدمون نوى CPU محددة ، أي أن مؤشر runnable_tasks_count سينمو في ظل هذه الظروف.
في هذه الحالة ، قبل زيادة عدد مراكز وحدة المعالجة المركزية ، يجب عليك تكوين خصائص التوازي لمثيل MS SQL Server بشكل صحيح ، ومن الإصدار 2016 ، قم بتكوين خصائص التوازي لقواعد البيانات المطلوبة بشكل صحيح:

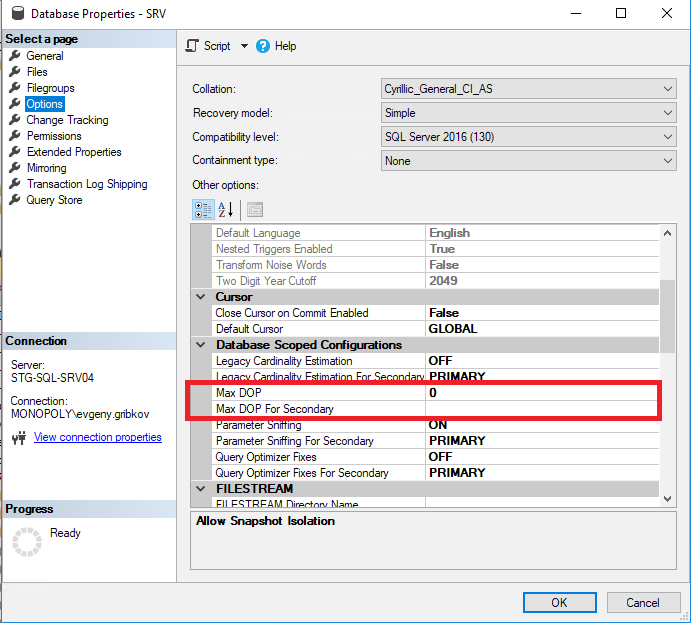
هنا يجدر الانتباه إلى المعايير التالية:
- Max Degree of Parallelism - يعين الحد الأقصى لعدد مؤشرات الترابط التي يمكن تخصيصها لكل طلب (الافتراضي هو 0 قيود فقط من قبل نظام التشغيل وإصدار MS SQL Server)
- حد التكلفة للتوازي - التكلفة التقديرية للتوازي (الافتراضي هو 5)
- يعيّن Max DOP الحد الأقصى لعدد مؤشرات الترابط التي يمكن تخصيصها لكل استعلام على مستوى قاعدة البيانات (ولكن ليس أكثر من قيمة خاصية "الحد الأقصى لدرجة التوازي") (الافتراضي هو تقييد 0 فقط بواسطة نظام التشغيل وإصدار MS SQL Server ، بالإضافة إلى القيود المفروضة على خاصية "Max Degree of Parallelism" لمثيل MS SQL Server بالكامل)
من المستحيل إعطاء وصفة جيدة على قدم المساواة لجميع الحالات ، أي أنك تحتاج إلى تحليل الطلبات الصعبة.
من تجربتي الخاصة ، أوصي بخوارزمية الإجراءات التالية لأنظمة OLTP لتكوين خصائص التوازي:
- حظر التزامن الأول عن طريق تحديد مستوى كامل مثيل أقصى درجة من التوازي إلى 1
- تحليل أصعب الطلبات واختيار العدد الأمثل من المواضيع لهم
- ضبط Max Degree of Parallelism على العدد الأمثل المحدد من سلاسل العمليات التي تم الحصول عليها من البند 2 ، وبالنسبة لقواعد البيانات المحددة ، حدد قيمة Max DOP التي تم الحصول عليها من البند 2 لكل قاعدة بيانات
- تحليل أصعب الطلبات وتحديد التأثير السلبي للتعدد. إذا كان الأمر كذلك ، فقم بزيادة حد التكلفة للتوازي.
بالنسبة لأنظمة مثل 1C و Microsoft CRM و Microsoft NAV ، في معظم الحالات ، يكون حظر تعدد الإرسال مناسبًا.
أيضًا ، في حالة تثبيت الإصدار القياسي ، يكون حظر تعدد الإرسال في معظم الحالات مناسبًا نظرًا لحقيقة أن هذه الطبعة محدودة بعدد مراكز وحدة المعالجة المركزية.
بالنسبة لأنظمة OLAP ، الخوارزمية الموضحة أعلاه غير مناسبة.
من تجربتي الخاصة ، أوصي بخوارزمية الإجراءات التالية لأنظمة OLAP لتحديد خصائص التوازي:
- تحليل أصعب الطلبات واختيار العدد الأمثل من المواضيع لهم
- اضبط Max Degree of Parallelism على العدد الأمثل المحدد من سلاسل العمليات التي تم الحصول عليها من البند 1 ، وكذلك لقواعد بيانات محددة ، حدد قيمة Max DOP التي تم الحصول عليها من البند 1 لكل قاعدة بيانات
- تحليل أصعب الطلبات وتحديد التأثير السلبي للحد التزامن. إذا كان الأمر كذلك ، فقم إما بتخفيض قيمة حد التكلفة للتوازي ، أو كرر الخطوات 1-2 من هذه الخوارزمية
وهذا يعني ، بالنسبة لأنظمة OLTP ، أن ننتقل من ترابط واحد إلى تعدد مؤشرات ترابط ، وأنظمة OLAP ، على العكس من ذلك ، نذهب من تعدد مؤشرات الترابط إلى ترابط واحد. وبالتالي ، من الممكن تحديد إعدادات التزامن المثلى لكل من قاعدة بيانات محددة ومثيل MS SQL Server بأكمله.
من المهم أيضًا فهم أن إعدادات خصائص التزامن يجب تغييرها بمرور الوقت استنادًا إلى نتائج مراقبة أداء MS SQL Server.
توصيات لوضع علامات التتبع
من تجربتي الخاصة وتجربة زملائي ، أوصي بتعيين إشارات التتبع التالية على مستوى بدء تشغيل خدمة MS SQL Server للإصدارات 2008-2016 للحصول على الأداء الأمثل:
- 610 - تقليل تسجيل الإدراج في الجداول المفهرسة. يمكن أن يساعد في إدراج الجداول في عدد كبير من السجلات والعديد من المعاملات ، مع توقعات طويلة ومتكررة من WRITELOG للتغييرات في الفهارس
- 1117 - إذا كان ملف في مجموعة ملفات يلبي حد النمو التلقائي ، يتم توسيع جميع الملفات في مجموعة الملفات
- 1118 - يفرض تحديد موقع جميع الكائنات في نطاقات مختلفة (حظر النطاقات المختلطة) ، مما يقلل من الحاجة إلى مسح صفحة SGAM التي يتم استخدامها لتتبع النطاقات المختلطة
- 1224 - تعطيل تصعيد القفل بناءً على عدد الأقفال. قد يشمل الاستخدام المفرط للذاكرة تصعيد القفل.
- 2371 - يغير عتبة تحديثات الإحصائيات التلقائية الثابتة إلى عتبة تحديثات الإحصاءات التلقائية الديناميكية. من المهم تحديث خطط الاستعلام للجداول الكبيرة حيث يؤدي تحديد عدد السجلات بشكل غير صحيح إلى خطط تنفيذ خاطئة
- 3226 - منع رسائل النسخ الاحتياطي الناجحة في سجل الأخطاء
- 4199 - يتضمن التغييرات على محسّن الاستعلام الذي تم إصداره في التحديث التراكمي وحزم خدمة SQL Server
- 6532-6534 - يتضمن أداء استعلام محسنًا لأنواع البيانات المكانية
- 8048 - تحويل كائنات الذاكرة المقسمة NUMA إلى وحدة المعالجة المركزية المقسمة
- 8780 - يتيح تخصيص وقت إضافي لجدولة الطلب. قد يتم رفض بعض الطلبات بدون هذه العلامة لأنها لا تحتوي على خطة طلب (خطأ نادر جدًا)
- 9389 - يتضمن مخزن مؤقت للذاكرة ديناميكيًا إضافيًا يتم توفيره مؤقتًا لمشغلي وضع الدُفعات ، مما يُمكّن مشغل وضع الدُفعات من طلب ذاكرة إضافية وتجنب نقل البيانات إلى tempdb في حالة توفر ذاكرة إضافية
قبل إصدار عام 2016 ، من المفيد تضمين إشارة التتبع 2301 ، والتي تتضمن تحسين دعم القرار الممتد وبالتالي تساعد في اختيار خطط استعلام أكثر صوابًا. ومع ذلك ، بدءًا من الإصدار 2016 ، غالبًا ما يكون له تأثير سلبي في وقت تنفيذ الاستعلام طويلًا إلى حد ما.
أيضًا ، بالنسبة للأنظمة التي يوجد بها الكثير من الفهارس (على سبيل المثال ، لقواعد بيانات 1C) ، نوصي بتمكين إشارة التتبع 2330 ، والتي تعطل المجموعة عن استخدام الفهارس ، والتي لها تأثير إيجابي بشكل عام على النظام.
تعرف على المزيد حول تتبع العلامات
هنا .
باستخدام الرابط أعلاه ، من المهم أيضًا مراعاة إصدارات وتجميعات MS SQL Server ، لأنه بالنسبة للإصدارات الأحدث ، يتم تمكين بعض إشارات التتبع افتراضيًا أو لا يكون لها أي تأثير. على سبيل المثال ، في إصدار 2017 ، من المناسب تعيين إشارات التتبع الخمسة التالية فقط: 1224 و 3226 و 6534 و 8780 و 9389.
يمكنك تمكين أو تعطيل علامة التتبع باستخدام الأمرين DBCC TRACEON و DBCC TRACEOFF ، على التوالي. انظر
هنا لمزيد من التفاصيل.
يمكنك الحصول على حالة إشارات التتبع باستخدام أمر DBCC TRACESTATUS:
المزيد .
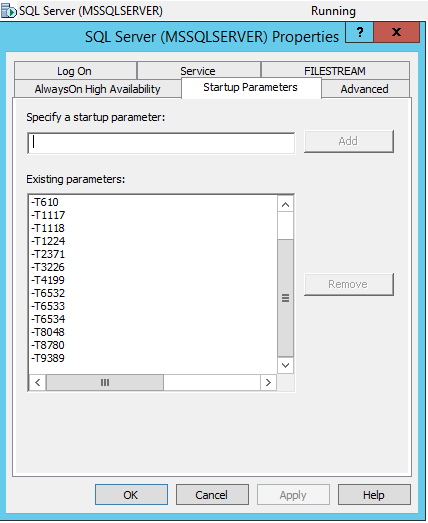
لتضمين إشارات التتبع في التشغيل التلقائي لخدمة MS SQL Server ، تحتاج إلى الدخول إلى SQL Server Configuration Manager وإضافة علامات التتبع هذه في خصائص الخدمة عبر -T:
النتائج
في هذه المقالة ، تم فحص بعض جوانب مراقبة MS SQL Server ، والتي يمكنك من خلالها التعرف بسرعة على عدم وجود ذاكرة الوصول العشوائي ووقت الفراغ لوحدة المعالجة المركزية ، بالإضافة إلى عدد من المشاكل الأخرى الأقل وضوحًا. تم اعتبار أعلام التتبع الأكثر استخدامًا.
مصادر
مزود خدمة الاحصائيات الاستعداد»
إحصائيات توقعات SQL Server أو من فضلك قل لي أين يؤلمني»
نظام عرض sys.dm_os_schedulersاستخدام Zabbix لتتبع MS SQL Server قاعدة البيانات»
SQL Lifestyle»
تتبع الأعلام»
Sql.ru