
في 1 أبريل ، انتهى نهائيات SNA Hackathon 2019 ، حيث شارك المشاركون في فرز موجز الشبكة الاجتماعية باستخدام تقنيات تعلم الآلة الحديثة ، رؤية الكمبيوتر ، أنظمة الاختبار والتوصية. الاختيار الصعب على الإنترنت ويومين من العمل الشاق على 160 غيغا بايت من البيانات لم تذهب سدى :). نتحدث عن ما ساعد المشاركين على تحقيق النجاح وعن ملاحظات أخرى مثيرة للاهتمام.
حول البيانات والمهمة
قدمت المسابقة بيانات من آليات إعداد الخلاصة لمستخدمي شبكة التواصل الاجتماعي OK ، والتي تتكون من ثلاثة أجزاء:
- سجلات عرض المحتوى في خلاصات المستخدم مع عدد كبير من السمات التي تصف المستخدم والمحتوى والمؤلف وغيرها من الخصائص ؛
- النصوص المتعلقة بالمحتوى المعروض ؛
- أجسام الصور المستخدمة في المحتوى.
يتجاوز إجمالي كمية البيانات 160 غيغابايت ، منها أكثر من 3 حسابات للسجلات و 3 أخرى للنصوص والباقي للصور. لم تخيف كمية البيانات الكبيرة المشاركين: وفقًا لإحصائيات ML Bootcamp ، شارك ما يقرب من 200 شخص في المسابقة ، الذين أرسلوا أكثر من 3000 إرسال ، وتمكنت أكثرها نشاطًا من كسر 100 حلول مرسلة. ربما تم تحفيزهم من قبل مجموعة الجوائز التي تضم 700000 روبل + 3 بطاقات رسومات GTX 2080 Ti.

يحتاج المشاركون في المسابقة إلى حل مشكلة فرز الشريط: لكل مستخدم فردي ، قم بتصنيف الكائنات المعروضة بطريقة كانت تلك التي حصلت على علامة "Class!" أقرب إلى رأس القائمة.
تم استخدام ROC-AUC كمقياس لتقييم الجودة. في الوقت نفسه ، لم يتم أخذ القياس في الاعتبار لجميع البيانات ككل ، ولكن بشكل منفصل لكل مستخدم ثم تم حساب المتوسط. يعتبر خيار الحساب هذا جديرًا بالملاحظة في أن الخوارزميات التي تعلمت التمييز بين المستخدمين الذين وضعوا في العديد من الفئات لا تتلقى مزايا. من ناحية أخرى ، لا يوجد خيار من هذا القبيل في حزم بيثون القياسية ، والتي كشفت عن بعض النقاط المثيرة للاهتمام ، والتي سيتم مناقشتها أدناه.
حول التكنولوجيا
تقليديًا ، لا يعد SNA Hackathon خوارزميات فحسب ، بل هو أيضًا خوارزميات - يتجاوز حجم البيانات المشحونة 160 غيغا بايت ، مما يضع المشاركين أمام المهام الفنية المثيرة للاهتمام.
الباركيه مقابل CSV
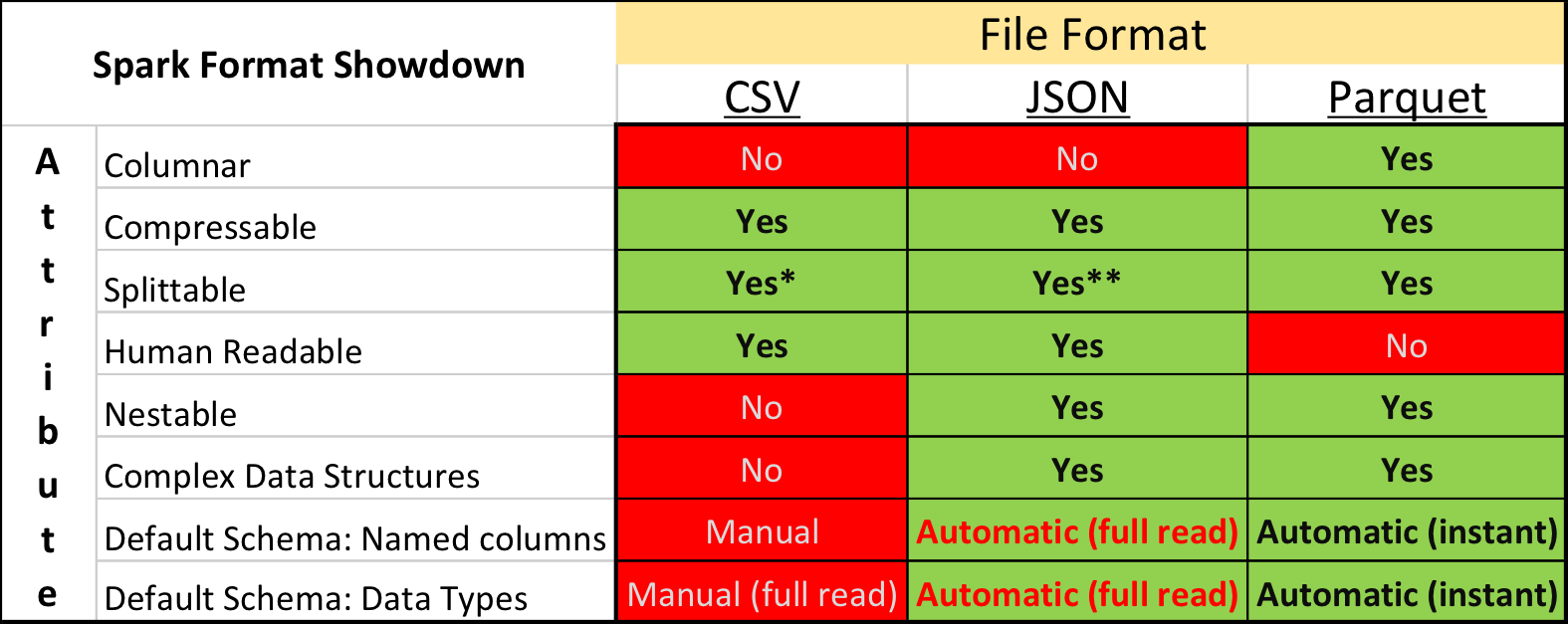
في البحوث الأكاديمية وعلى Kaggle ، تنسيق البيانات السائد هو CSV ، وكذلك تنسيقات النص العادي الأخرى. ومع ذلك ، يختلف الوضع في الصناعة إلى حد ما - حيث يمكن تحقيق سرعات معالجة أكثر تعقيدًا بشكل كبير باستخدام تنسيقات التخزين "الثنائية".
على وجه الخصوص ، في النظام الإيكولوجي المبني على أساس Apache Spark ، يعد Apache Parquet الأكثر شعبية - تنسيق تخزين بيانات العمود مع دعم للعديد من الميزات التشغيلية الهامة:
- دائرة محددة صراحة مع دعم التطور ؛
- قراءة فقط الأعمدة الضرورية من القرص ؛
- الدعم الأساسي للفهارس والمرشحات عند القراءة ؛
- ضغط السلسلة.
ولكن على الرغم من المزايا الواضحة ، فإن تقديم البيانات للمسابقة في تنسيق Apache Parquet قد واجه انتقادات شديدة من بعض المشاركين. بالإضافة إلى المحافظة وعدم الرغبة في قضاء وقت في تطوير شيء جديد ، كانت هناك عدة لحظات غير سارة حقًا.
أولاً ، دعم التنسيق في مكتبة Apache Arrow ، الأداة الرئيسية للعمل مع Parquet من Python ، ليس مثاليًا. عند إعداد البيانات ، كان لا بد من توسيع جميع الحقول الهيكلية إلى مسطح ، ومع ذلك ، عند قراءة النصوص ، واجه العديد من المشاركين خللًا واضطروا إلى تثبيت الإصدار القديم من المكتبة 0.11.1 بدلاً من الإصدار الحالي 0.12 في ذلك الوقت. ثانياً ، لن تنظر إلى ملف الباركيه باستخدام أدوات مساعدة بسيطة لوحدة التحكم: القط ، أقل ، إلخ. ومع ذلك ، من السهل نسبياً تعويض هذا العيب عن استخدام حزمة أدوات الباركيه .
ومع ذلك ، فإن أولئك الذين حاولوا في البداية تحويل جميع البيانات إلى ملف CSV ، ثم العمل في بيئة مألوفة ، تخلوا عن هذه الفكرة في النهاية - بعد كل شيء ، تعمل النيابة العامة بشكل أسرع.
تعزيز و GPU

في مؤتمر SmartData في سانت بطرسبرغ ، "المعروف على نطاق واسع في الدوائر الضيقة" ، قارن أليكسي Natekin أداء العديد من أدوات التعزيز الشعبية أثناء العمل على وحدة المعالجة المركزية / GPU وتوصل إلى استنتاج مفاده أن GPU لا يعطي مكاسب ملموسة. لكن حتى مع ذلك ، أدى هذا الاستنتاج إلى جدال نشط ، في المقام الأول مع مطوري أداة CatBoost المحلية.
على مدار العامين الماضيين ، لم يتوقف التقدم في تطوير وحدات معالجة الرسومات وتكييف الخوارزميات ، ويمكن اعتبار نهائي SNA Hackathon انتصارًا لزوج CatBoost + GPU - حيث استخدمه جميع الفائزين وسحبوا المقياس نظرًا للقدرة على زيادة عدد الأشجار في كل وحدة زمنية.
ساهم التنفيذ المتكامل لترميز الهدف المتوسط أيضًا في الحصول على نتيجة عالية للحلول القائمة على CatBoost ، لكن عدد الأشجار وعمقها زاد زيادة كبيرة.
أدوات التعزيز الأخرى تتحرك في اتجاه مماثل ، إضافة وتحسين دعم GPU. لذلك تنمو المزيد من الأشجار!
شرارة مقابل PySpark

أداة Apache Spark هي شركة رائدة في مجال علوم البيانات الصناعية ، ويرجع الفضل في ذلك جزئيًا إلى Python API. ومع ذلك ، يأتي استخدام Python مع حمولة إضافية للتكامل بين أوقات التشغيل المختلفة ومترجم العمل.
هذا في حد ذاته لا يمثل مشكلة إذا كان المستخدم على علم بالمدى الذي يؤدي به مقدار التكاليف الإضافية إلى اتخاذ إجراء معين. ومع ذلك ، فقد تبين أن الكثيرين لا يدركون حجم المشكلة - على الرغم من حقيقة أن المشاركين لم يستخدموا Apache Spark ، والمناقشات حول Python vs. ظهر Scala بانتظام في دردشة hackathon ، مما أدى إلى ظهور المنشور الذي تم تحليله .
باختصار ، يمكن تقسيم التباطؤ في استخدام Spark إلى Python مقارنة باستخدام Spark عبر Scala / Java إلى المستويات التالية:
- يتم استخدام واجهة برمجة تطبيقات Spark SQL فقط دون وظائف محددة من قبل المستخدم (UDF) - في هذه الحالة لا يوجد أي حمل عمليًا تقريبًا ، حيث يتم حساب خطة تنفيذ الاستعلام بالكامل في إطار JVM ؛
- يتم استخدام UDF في Python دون استدعاء الحزم التي تحتوي على رمز C ++ - في هذه الحالة ، فإن أداء المرحلة التي يتم فيها حساب UDF ينخفض من 7 إلى 10 مرات ؛
- يتم استخدام UDF في Python مع الوصول إلى حزمة C ++ (سيئة ، sklearn ، وما إلى ذلك) - في هذه الحالة ، ينخفض الأداء من 10 إلى 50 مرة .
جزئيًا ، يمكن تعويض التأثير السلبي عن استخدام PyPy (JIT لـ Python) و UDFs المتجه ، ومع ذلك ، حتى في هذه الحالات يكون الفرق في الأداء متعددًا ، وتعقيد التنفيذ والنشر يأتي مع "مكافأة" إضافية.
حول الخوارزميات
ولكن الشيء الأكثر إثارة للاهتمام حول hackathons Data Science هو ، بالطبع ، ليس التكنولوجيات ، ولكن خوارزميات جديدة وعصرية ثبت. سيطر CatBoost على SNA Hackathon هذا العام ، ولكن كانت هناك عدة طرق بديلة. سنتحدث عنهم :).
الرسوم البيانية المختلفة

تم تخصيص أحد المنشورات الأولى للقرارات المستندة إلى نتائج الجولة التصفيات ليس للأشجار ، ولكن الرسوم البيانية القابلة للتمييز (وتسمى أيضًا الشبكات العصبية الاصطناعية). المؤلف هو موظف في OK ، لذلك لا يستطيع أن يطارد الجوائز ، بل يستمتع ببناء حل واعد على أساس أساس رياضي قوي.
كانت الفكرة الرئيسية للحل المقترح هي بناء رسم بياني فردي يمكن تمييزه يترجم الميزات المتاحة إلى تنبؤ يأخذ في الاعتبار الجوانب المختلفة لبيانات الإدخال:
- تتيح لك نقابات الكائنات والمستخدم إضافة عنصر من التوصيات التعاونية الكلاسيكية ؛
- يتيح لك الانتقال من التضمين العددي إلى التجميع من خلال MLP إضافة خصائص اعتباطية ؛
- أتاح الاهتمام بقيمة مفتاح الاستعلام للنموذج أن يتكيف ديناميكيًا مع سلوك حتى مستخدم غير مألوف سابقًا ينظر إلى تاريخه الحديث.
أثبت هذا النموذج أنه جيد جدًا في الاختيار عبر الإنترنت في حل مشكلة التوصية بالمحتوى النصي ، لذا حاولت عدة فرق تشغيله في النهائيات مرة واحدة ، ومع ذلك ، لم ينجحوا. كان هذا جزئيًا بسبب حقيقة أن هذا يتطلب وقتًا وخبرة ، ويرجع جزئيًا إلى حقيقة أن عدد السمات في المباراة النهائية كان أكبر من ذلك بكثير ، وحصلت الطرق المعتمدة على الأشجار على ميزة كبيرة بسببها.
المهيمنة التعاونية

بالطبع ، عند تنظيم المسابقة ، علمنا أن هناك إشارة قوية إلى حد ما في السجلات ، لأن العلامات التي تم جمعها تعكس جزءًا كبيرًا من العمل المنجز في OK لتصنيف الخلاصة. ومع ذلك ، حتى النهاية ، كانوا يأملون في أن ينجح المشاركون في التعامل مع "لعنة الشخصية الثالثة" - الحالات التي استثمرت فيها الموارد البشرية والآلية الضخمة في تطوير نموذج لاستخراج السمات من المحتوى (النصوص والصور) إلى مكاسب متواضعة للغاية في الجودة مقارنة بالمكاسب الموجودة بالفعل أعدت ، التعاونية أساسا ، الصفات.
مع العلم حول هذه المشكلة ، قمنا في البداية بتقسيم المهمة إلى ثلاثة مسارات في جولة التصفيات وشكلنا مجموعة بيانات مجمعة فقط في النهائي ، ولكن بتنسيق hackathon بمقياس ثابت ، وجدت الفرق التي استثمرت في تطوير نماذج المحتوى نفسها في موقف خاسر متعمد مقارنة بفرق تطوير متعاونة جزء.
ساعدت هيئة المحلفين في تعويض هذا الظلم ...
الكتلة العميقة

الذي حصل بالإجماع تقريبًا على جائزة العمل على إعادة إنتاج واختبار خوارزمية Deep Cluster من facebook. أسلوب الترميز الأولي البسيط الذي لا يتطلب إنشاء مجموعات وتزيين الصور أعجب بأفكار جديدة ونتائج واعدة.
جوهر الطريقة بسيط للغاية:
- حساب ناقلات تضمين للصور مع أي شبكة عصبية ذات مغزى ؛
- تجمع المتجهات في الفضاء الناتج مع وسائل k ؛
- تدريب مصنف شبكة عصبية للتنبؤ بمجموعة من الصور ؛
- كرر الخطوات 2-3 حتى التقارب (إذا كان لديك 800 وحدة معالجة الرسومات) أو أثناء وجود وقت كافٍ.
مع بذل الحد الأدنى من الجهود ، تمكنا من الحصول على مجموعة عالية الجودة من الصور موافق ، والزخارف الجيدة وزيادة متري في الرقم الثالث.
انظر الى المستقبل

في أي بيانات ، يمكنك العثور على "ثغرات" لتحسين التوقعات. في حد ذاته ، هذا ليس سيئًا للغاية ، فمن الأسوأ إذا وجدت الثغرات نفسها ولم تظهر لفترة طويلة إلا في شكل تباينات غير مفهومة بين نتائج التحقق من صحة البيانات التاريخية واختبارات A / B.
واحدة من أكثر الثغرات انتشارا من هذا النوع هو استخدام المعلومات من المستقبل. غالبًا ما تكون هذه المعلومات إشارة قوية للغاية وستبدأ خوارزمية التعلم الآلي ، إذا تم تمكينها ، في استخدامها بثقة. عندما تصنع نموذجًا لمنتجك ، فإنك تحاول تجنب تسرب المعلومات من المستقبل ، لكن في hackathon هذه فرصة جيدة لرفع المقياس ، الذي استخدمه المشاركون.
كانت الثغرة الأكثر وضوحًا هي وجود numLikes و numDislikes في هذه الحقول مع تعداد رد الفعل في الكائن في وقت العرض. بمقارنة الحدثين الأقرب في الوقت المرتبط بالكائن نفسه ، كان من الممكن تحديد بدقة رد الفعل على الكائن في أولهما. كان هناك العديد من العدادات المتشابهة في البيانات ، وكان استخدامها يعطي ميزة ملحوظة. بطبيعة الحال ، في الاستخدام الفعلي ، لن تكون هذه المعلومات متاحة.
في الحياة ، يمكن أن تتعثر مشكلة مماثلة دون إدراكها ، وعادة ما تكون النتائج سلبية. على سبيل المثال ، حساب الإحصائيات على عدد العلامات "Class!" للكائن وفقا لجميع البيانات وأخذها كسمة منفصلة. أو ، كما فعلوا في أحد الفرق المشاركة ، إضافة معرف كائن إلى النموذج كسمة قاطعة. في مجموعة التدريب ، يعمل النموذج الذي يحتوي على مثل هذه الميزة بشكل جيد ، ولكن لا يمكن التعميم على مجموعة اختبار.
بدلا من الاستنتاج

تتوفر جميع مواد المسابقة ، بما في ذلك البيانات والعروض التقديمية لقرارات المشاركين في Mail.ru Cloud . البيانات متاحة للاستخدام من قبل المشاريع البحثية دون قيود ، باستثناء توافر الروابط. للقصة ، دعنا نترك الجدول النهائي هنا بمقاييس الفرق النهائية:
- كراوتشينج سكالا ، يختبئ بيثون - 0.7422 ، تحليل الحل متاح هنا ، والكود هنا وهناك.
- مدينة السحر - 0.7256
- الكفير - 0.7226
- الفريق 6 - 0.7205
- ثلاثة في قارب - 0.7188
- القاعة رقم 14 - 0.7167 وجائزة لجنة التحكيم
- بيزنا - 0.7147
- بونغا - 0.7117
- الفريق 5 - 0.7112
كان SNA Hackathon 2019 ، مثل الأحداث السابقة للمسلسل ، ناجحًا بكل معنى الكلمة. تمكنا من جمع مهنيين رائعين في مجالات مختلفة تحت سقف واحد ولدينا وقت مثمر ، وذلك بفضل جزيل الشكر للمشاركين أنفسهم ولجميع الذين ساعدوا في المنظمة.
هل يمكن القيام بشيء ما بشكل أفضل؟ بالطبع نعم! كل مسابقة أقيمت تُثرينا بتجربة جديدة ، نأخذها في الاعتبار عند إعداد المسابقة التالية ولن تتوقف عند هذا الحد. لذا ، أراك قريبًا في SNA Hackathon!