
منذ عام 2008 ، تعمل شركتنا بشكل أساسي في إدارة البنية التحتية والدعم الفني على مدار الساعة لمشاريع الويب: لدينا أكثر من 400 عميل ، أي حوالي 15 ٪ من التجارة الإلكترونية في روسيا. وفقا لذلك ، يتم دعم بنية متنوعة للغاية. إذا وقع شيء ما ، يجب علينا إصلاحه في غضون 15 دقيقة. ولكن من أجل فهم وقوع حادث ، يجب عليك مراقبة المشروع والاستجابة للحوادث. كيف نفعل ذلك؟
أعتقد أن تنظيم نظام الرصد الصحيح في ورطة. إذا لم تكن هناك مشكلة ، فإن خطابي يتكون من أطروحة واحدة: "الرجاء تثبيت Prometheus + Grafana والإضافات 1 ، 2 ، 3." لسوء الحظ ، هذا لا يعمل الآن. والمشكلة الرئيسية هي أن الجميع ما زالوا يؤمنون بشيء كان موجودًا في عام 2008 ، من حيث مكونات البرامج.
فيما يتعلق بتنظيم نظام المراقبة ، فإنني أخاطر بالقول إن ... المشروعات ذات المراقبة المختصة غير موجودة. والوضع سيء للغاية إذا حدث شيء ما ، فهناك خطر في أن يمر دون أن يلاحظها أحد - الجميع على يقين من أن "كل شيء يتم مراقبته".
ربما يتم رصد كل شيء. لكن كيف؟
لقد واجهنا جميعًا قصة مشابهة لما يلي: ديوب معين ، يعمل مسؤول معين ، ويأتي إليهم فريق تطوير ويقول: "لقد حصلنا عليه ، والآن تتم مراقبته". ما الشاشة؟ كيف يعمل؟
تقريبا. نحن نراقب الطريقة القديمة. لكن الأمر بدأ يتغير بالفعل ، واتضح أنك راقبت الخدمة A ، التي أصبحت الخدمة B ، والتي تتفاعل مع الخدمة C. لكن فريق التطوير يقول لك: "تثبيت البرنامج ، يجب عليه مراقبة كل شيء!"
إذن ما الذي تغير؟ - لقد تغير كل شيء!
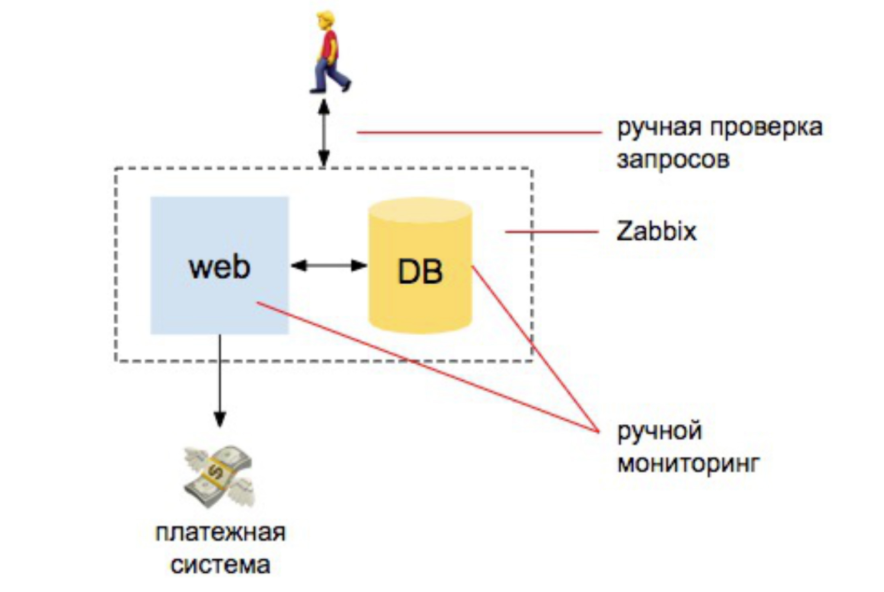
عام 2008. كل شيء على ما يرام
هناك عدة مطورين ، خادم واحد ، خادم قاعدة بيانات واحد. من هنا يذهب كل شيء. لدينا بعض INFA ، نضع zabbix ، Nagios ، الصبار. ثم نضع تنبيهات واضحة على وحدة المعالجة المركزية ، على تشغيل الأقراص ، في المكان على الأقراص. نحن نقوم أيضًا بالتحقق اليدوي من أن الموقع يجيب على أن الطلبات تأتي إلى قاعدة البيانات. وهذا كل شيء - نحن محميون إلى حد ما.
إذا قمنا بمقارنة مقدار العمل الذي قام به المسؤول لضمان المراقبة ، فقد كان 98٪ تلقائيًا: يجب أن يفهم الشخص الذي يراقب كيفية تثبيت Zabbix ، وكيفية تكوينه وتكوين التنبيهات. و 2 ٪ - للفحوصات الخارجية: أن يستجيب الموقع ويجعل طلب قاعدة البيانات التي وصلت الطلبات الجديدة.
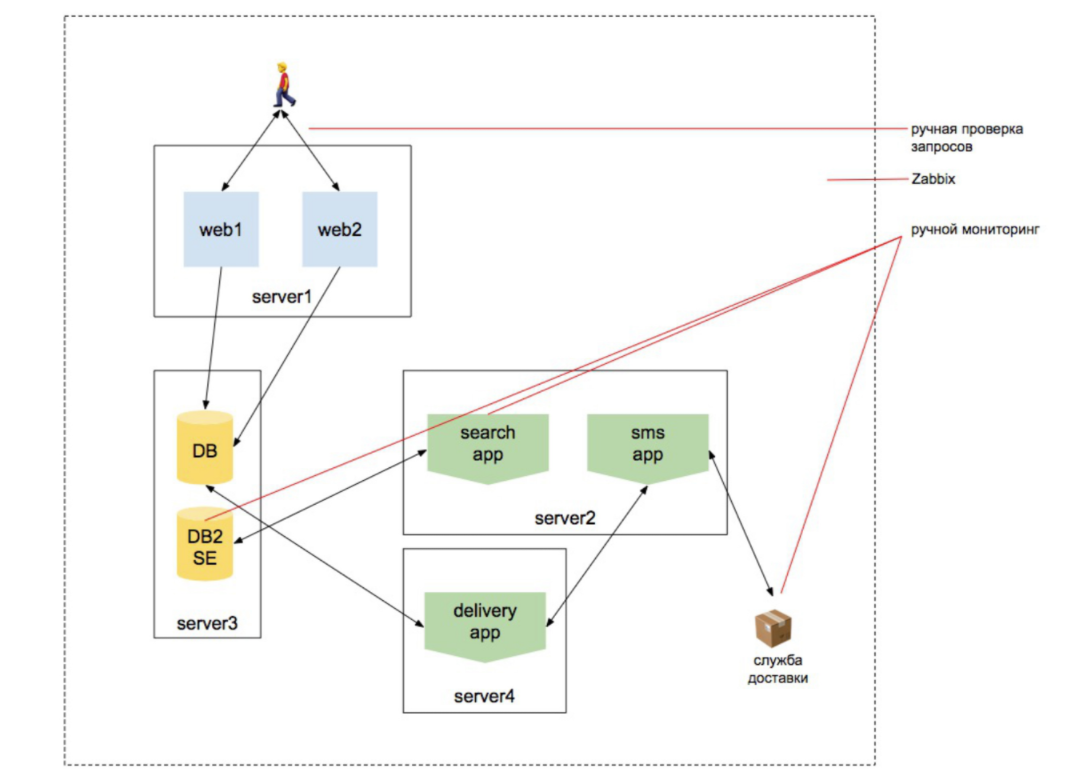
2010 العام. الحمل ينمو
نبدأ في توسيع نطاق الويب ، إضافة محرك بحث. نريد أن نتأكد من أن كتالوج المنتجات يحتوي على جميع المنتجات. وهذا البحث المنتج يعمل. أن قاعدة البيانات تعمل ، وأن الطلبات يتم إجراؤها ، وأن الموقع يستجيب من الخارج ويستجيب من خادمين ، ولا يتم إخراج المستخدم من الموقع أثناء إعادة توازنه إلى خادم آخر ، إلخ. هناك المزيد من الكيانات.
علاوة على ذلك ، لا يزال الكيان المرتبط بالبنية التحتية هو الأكبر في رأس المدير. لا تزال الفكرة في رأسي أن الشخص الذي يراقب هو الشخص الذي سيقوم بتثبيت zabbix ويكون قادرًا على تكوينه.
ولكن في الوقت نفسه ، هناك أعمال على إجراء عمليات فحص خارجية ، وإنشاء مجموعة من البرامج النصية للاستعلام عن مفهرس البحث ، ومجموعة من البرامج النصية للتحقق من أن البحث يتغير أثناء عملية الفهرسة ، ومجموعة من النصوص التي تتحقق من نقل البضائع إلى خدمة التوصيل ، إلخ. إلخ

ملاحظة: كتبت "مجموعة نصية" 3 مرات. أي أن الشخص المسؤول عن المراقبة لم يعد هو الشخص الذي قام بتثبيت zabbix فقط. هذا هو الشخص الذي يبدأ في الكود. لكن لم يتغير شيء في أذهان الفريق بعد.
لكن العالم يتغير ، ويصبح أكثر تعقيدًا. طبقة المحاكاة الافتراضية ، تتم إضافة العديد من الأنظمة الجديدة. يبدأون بالتفاعل مع بعضهم البعض. من قال "صفعات الخدمات الميكروية؟" ولكن كل خدمة لا تزال تبدو بشكل فردي مثل الموقع. يمكننا أن نتوجه إليه ونفهم أنه يعطي المعلومات الضرورية ويعمل من تلقاء نفسه. وإذا كنت مسؤولاً تشارك باستمرار في مشروع تم تطويره لمدة تتراوح بين 5 و 10 سنوات ، فلديك هذه المعرفة المتراكمة: يظهر مستوى جديد - أدركت ذلك ، ظهر مستوى آخر - أدركته ...
ولكن نادراً ما يرافق أي شخص المشروع لمدة 10 سنوات.
رجل رصد ملخص
لنفترض أنك أتيت إلى شركة ناشئة جديدة سجلت على الفور 20 مطورًا ، وكتبت 15 خدمة ميكروية ، وأنت المسؤول الذي قيل له: "قم بإنشاء CI / CD. من فضلك. " لقد قمت بإنشاء CI / CD وفجأة تسمع: "من الصعب علينا العمل مع الإنتاج في" المكعب "دون فهم كيف سيعمل التطبيق فيه. تجعلنا رمل في نفس "المكعب".
قمت بعمل رمل في هذا المكعب. يخبرونك على الفور: "نريد قاعدة بيانات على مراحل ، يتم تحديثها كل يوم من الإنتاج ، لفهم أنها تعمل على قاعدة البيانات ، ولكن لا تفسد قاعدة بيانات الإنتاج."
أنت تعيش في كل شيء. يتبقى أمامك أسبوعان حتى الإصدار ، ويقولون لك: "الآن ستتم مراقبة كل شيء ..." مراقبة البنية التحتية للمجموعة ، ومراقبة بنية الخدمات المصغرة ، ومراقبة العمل مع الخدمات الخارجية ...
ويأخذ الزملاء مثل هذا المخطط المألوف من رؤوسهم ويقولون: "هنا كل شيء واضح! قم بتثبيت برنامج يراقب كل شيء ". نعم: بروميثيوس + غرافانا + الإضافات.
ويضيفون في الوقت نفسه: "أمامك أسبوعين ، تأكد من أن كل شيء يمكن الاعتماد عليه".
في كومة المشاريع التي نراها ، يتم تخصيص شخص واحد للمراقبة. تخيل أننا نريد استئجار شخص لمدة أسبوعين للمراقبة ، وسوف نكتب له سيرة ذاتية. ما المهارات التي يجب أن يمتلكها هذا الشخص - بالنظر إلى كل ما قلناه من قبل؟
- يجب أن يفهم رصد وتفاصيل عمل البنية التحتية للحديد.
- يجب عليه فهم تفاصيل مراقبة Kubernetes (والجميع يريد "مكعبًا" ، لأنه يمكنك تجاهل كل شيء ، والاختباء ، لأن المشرف سوف يكتشف ذلك) - بحد ذاته ، بنيته التحتية ، وفهم كيفية مراقبة التطبيقات في الداخل.
- يجب أن يفهم أن الخدمات تتواصل مع بعضها البعض بطرق خاصة ، وأن تعرف تفاصيل تفاعل الخدمات فيما بينها. من الواقعي رؤية مشروع تتواصل فيه بعض الخدمات بشكل متزامن ، لأنه لا توجد طريقة أخرى. على سبيل المثال ، تستمر الواجهة الخلفية على REST ، على gRPC إلى خدمة الكتالوج ، وتتلقى قائمة بالسلع وتعود مرة أخرى. لا يمكنك الانتظار هنا. ومع الخدمات الأخرى ، يعمل بشكل غير متزامن. نقل الطلب إلى خدمة التوصيل ، وإرسال خطاب ، إلخ.
ربما كنت أبحرت بالفعل من كل هذا؟ والسباحة ، الذي يحتاج إلى مراقبة هذا ، سبح أكثر. - يجب أن يكون قادرًا على التخطيط والتخطيط بشكل صحيح - لأن العمل يصبح أكثر فأكثر.
- لذلك ، يجب عليه إنشاء استراتيجية من الخدمة التي تم إنشاؤها من أجل فهم كيفية مراقبتها على وجه التحديد. يحتاج إلى فهم بنية المشروع وتطويره + فهم التقنيات المستخدمة في التطوير.
دعونا نتذكر حالة طبيعية تمامًا: جزء من الخدمات في php ، وجزء من الخدمات في Go ، وجزء من الخدمات في JS. انهم يعملون بطريقة ما فيما بينهم. هنا يأتي المصطلح "microservice": يوجد الكثير من الأنظمة المنفصلة التي لا يستطيع المطورين فهم المشروع ككل. يكتب جزء من الفريق خدمات في JS تعمل من تلقاء نفسها ولا تعرف كيف يعمل باقي النظام. الجزء الآخر يكتب الخدمات في بيثون ولا يذهب إلى الطريقة التي تعمل بها الخدمات الأخرى ، فهي معزولة في مجالهم. ثالثا - يكتب الخدمات في php أو أي شيء آخر.
كل هؤلاء الأشخاص الـ 20 مقسمون إلى 15 خدمة ، وهناك مسؤول واحد فقط يجب أن يفهم كل هذا. توقف عن ذلك! نحن فقط نقسم النظام إلى 15 خدمة microservices ، لأن 20 شخصًا لا يستطيعون فهم النظام بأكمله.
ولكن يجب مراقبتها بطريقة أو بأخرى ...
ما هي النتيجة؟ نتيجة لذلك ، هناك شخص واحد يتضمن كل شيء لا يستطيع فريق كامل من المطورين فهمه ، ومع ذلك يجب عليه أيضًا معرفة ما ذكرناه أعلاه والقدرة على ذلك - البنية التحتية الحديدية والبنية التحتية Kubernetes ، إلخ.
ماذا يمكنني أن أقول ... هيوستن ، لدينا مشاكل.
مراقبة مشروع البرمجيات الحديثة هو مشروع برمجيات في حد ذاته
من الاعتقاد الخاطئ بأن الرصد هو برنامج ، لدينا ثقة في المعجزات. لكن المعجزات ، للأسف ، لا تحدث. لا يمكنك تثبيت zabbix والانتظار حتى يعمل كل شيء. ليس من المنطقي وضع غرافانا والأمل في أن كل شيء سيكون على ما يرام. سيتم قضاء معظم الوقت في تنظيم عمليات التحقق من تشغيل الخدمات وتفاعلها مع بعضها البعض ، ويتحقق من كيفية عمل الأنظمة الخارجية. في الواقع ، سيتم إنفاق 90 ٪ من الوقت ليس على كتابة البرامج النصية ، ولكن على تطوير البرمجيات. ويجب أن يكون فريقًا يفهم عمل المشروع.
إذا تم إلقاء شخص واحد في هذه الحالة للمراقبة ، فستحدث مشكلة. الذي يحدث في كل مكان.
على سبيل المثال ، هناك العديد من الخدمات التي تتواصل مع بعضها البعض من خلال كافكا. تم إرسال طلب ، أرسلنا رسالة حول الأمر إلى كافكا. هناك خدمة تستمع إلى معلومات حول الطلب وتقوم بشحن البضائع. هناك خدمة تستمع إلى معلومات حول الطلب وترسل خطابًا إلى المستخدم. وبعد ذلك لا تزال هناك مجموعة من الخدمات ، ونحن نبدأ بالحيرة.
وإذا كنت لا تزال تقدمه إلى المسؤول والمطورين في مرحلة ما إذا كان هناك وقت قصير قبل الإصدار ، فسوف يحتاج الشخص إلى فهم هذا البروتوكول بالكامل. أي يستغرق تنفيذ مشروع بهذا الحجم وقتًا كبيرًا ، ويجب إدراجه في تطوير النظام.
ولكن في كثير من الأحيان ، خاصة في حالة الاحتراق ، في الشركات الناشئة ، نرى كيف يتم تأجيل المراقبة إلى وقت لاحق. "الآن سنجعل إثبات المفهوم ، سنبدأ به ، وسنخسره - نحن مستعدون للتضحية. ثم سنراقب كل شيء ". عندما يبدأ (أو إذا) المشروع في جني الأموال ، ترغب الشركة في خفض عدد أكبر من الميزات - لأنه بدأ العمل ، لذلك عليك أن تذهب أبعد من ذلك! وأنت في نقطة تحتاج في البداية إلى مراقبة كل شيء سابق ، والذي لا يستغرق 1٪ من الوقت ، ولكن أكثر من ذلك بكثير. وبالمناسبة ، سيحتاج المطورون إلى المراقبة ، ومن الأسهل وضعهم في ميزات جديدة. نتيجة لذلك ، يتم كتابة ميزات جديدة ، يتم اختتام كل شيء ، وأنت في مأزق لا نهاية له.
فكيف تراقب مشروعًا منذ البداية ، وماذا لو حصلت على مشروع تحتاج إلى مراقبته ، لكنك لا تعرف من أين تبدأ؟
أولا ، تحتاج إلى خطة.
الاستنشاق الغنائي: غالبًا ما يبدأ بمراقبة البنية التحتية. على سبيل المثال ، لدينا Kubernetes. بادئ ذي بدء ، وضعنا Prometheus مع Grafana ، ونضع الإضافات تحت مراقبة "المكعب". ليس للمطورين فحسب ، بل للمسؤولين أيضًا ممارسة مؤسفة: "سنقوم بتثبيت هذا المكون الإضافي ، وربما يعرف المكون الإضافي كيفية القيام بذلك." يحب الناس أن يبدأوا بالإجراءات البسيطة والمفهومة بدلاً من الإجراءات المهمة. ومراقبة البنية التحتية سهلة.أولاً ، قرر ما وكيف تريد مراقبته ، ثم التقط الأداة ، لأن الآخرين لا يستطيعون التفكير بك. نعم ، أليس كذلك؟ فكر آخرون في أنفسهم ، حول النظام العالمي - أو لم يفكروا على الإطلاق عند كتابة هذا البرنامج المساعد. وحقيقة أن هذا البرنامج المساعد لديه 5 آلاف مستخدم لا يعني أنه يجلب أي فائدة. ربما ستصبح رقم 5001 لأنه ببساطة كان هناك 5000 شخص من قبل.
إذا بدأت في مراقبة البنية الأساسية وتوقف الواجهة الخلفية للتطبيق عن الاستجابة ، فسيفقد جميع المستخدمين الاتصال بتطبيق الهاتف المحمول. خطأ سوف يطير. سيأتون إليك ويقولون ، "لا يعمل التطبيق ، ماذا تفعل هنا؟" "نحن نراقب". - "كيف تراقب إذا كنت لا ترى أن التطبيق لا يعمل؟"
- أعتقد أنه من الضروري البدء في المراقبة من نقطة دخول المستخدم. إذا كان المستخدم لا يرى أن التطبيق يعمل - هذا كل شيء ، فسيكون ذلك فشلًا. ونظام الرصد يجب أن يحذر من هذا في المقام الأول.
- وعندها فقط يمكننا مراقبة البنية التحتية. أو القيام بذلك بشكل متواز. البنية التحتية أبسط - هنا يمكننا أخيرًا تثبيت zabbix.
- والآن تحتاج إلى الانتقال إلى جذور التطبيق لفهم أين لا يعمل ذلك.
أفكاري الرئيسي هو أن الرصد يجب أن يتماشى مع عملية التطوير. إذا قمت بتمزيق فريق المراقبة للقيام بمهام أخرى (إنشاء CI / CD ، وصناديق رمل ، وإعادة تنظيم البنية التحتية) ، فستبدأ عملية المراقبة في التأخير ولن تتمكن أبدًا من متابعة التطوير (أو عاجلاً أم آجلاً ، يجب إيقافها).
كل حسب المستويات
هذه هي الطريقة التي أرى بها تنظيم نظام المراقبة.
1) مستوى التطبيق:
- مراقبة منطق العمل للتطبيق ؛
- مراقبة المقاييس الصحية للخدمات ؛
- رصد التكامل.
2) مستوى البنية التحتية:
- مراقبة مستوى تزامن؛
- برمجيات نظام المراقبة ؛
- رصد مستوى "الحديد".
3) مرة أخرى ، على مستوى التطبيق - ولكن كمنتج هندسي:
- جمع ومراقبة سجلات التطبيق ؛
- APM.
- البحث عن المفقودين.
4) تنبيه:
- تنظيم نظام تحذير ؛
- تنظيم نظام مراقبة ؛
- تنظيم "قاعدة المعرفة" ومعالجة حادث سير العمل.
مهم : وصلنا إلى حالة تأهب ليس بعد ، ولكن على الفور! ليس من الضروري البدء في المراقبة والتفكير "لاحقًا" في معرفة من سيتلقى التنبيهات. بعد كل شيء ، ما هي مهمة المراقبة: فهم أين لا يعمل شيء ما في النظام ، وإعلام الأشخاص المناسبين به. إذا تم ترك هذا حتى النهاية ، فسوف يكتشف الأشخاص المناسبون أن هناك شيئًا ما يحدث بشكل خاطئ ، فقط من خلال الاتصال بـ "لا شيء يناسبنا".
طبقة التطبيق - مراقبة منطق الأعمال
نحن هنا نتحدث عن التحقق من حقيقة أن التطبيق يعمل للمستخدم.
يجب أن يتم هذا المستوى في مرحلة التصميم. على سبيل المثال ، لدينا بروميثيوس الشرطي: يزحف إلى الخادم الذي يشارك في عمليات التحقق ، ويسحب نقطة النهاية ، وينقضي نقطة النهاية ويتحقق من واجهة برمجة التطبيقات.
عندما يُطلب منك في كثير من الأحيان مراقبة الصفحة الرئيسية للتأكد من أن الموقع يعمل ، يعطي المبرمجون قلمًا يمكن سحبه في كل مرة تحتاج فيها للتأكد من أن واجهة برمجة التطبيقات تعمل. والمبرمجين في هذه اللحظة لا يزال يأخذ ويكتب / api / test / helloworld
الطريقة الوحيدة للتأكد من أن كل شيء يعمل؟ - لا!
- إنشاء مثل هذه الاختبارات هو في الأساس مهمة المطورين. يجب أن تكون اختبارات الوحدة مكتوبة بواسطة المبرمجين الذين يكتبون الكود. لأنه إذا قمت بدمج هذا في المشرف "Dude ، فإليك قائمة بروتوكولات واجهة برمجة التطبيقات لجميع وظائف 25 ، يرجى مراقبة كل شيء!" - لن ينجح شيء.
- إذا قمت بطباعة "hello world" ، فلن يعلم أحد أن واجهة برمجة التطبيقات يجب أن تعمل بالفعل. يجب أن يؤدي كل تغيير في واجهة برمجة التطبيقات إلى تغيير عمليات الفحص.
- إذا كانت لديك بالفعل مثل هذه الكارثة ، فقم بإيقاف الميزات وتحديد المطورين الذين سيكتبون هذه الفحوصات ، أو يتصالحون مع الخسائر ، يتصالحون مع عدم التحقق من أي شيء وسيسقط.
نصائح فنية:
- تأكد من تنظيم خادم خارجي لتنظيم عمليات التفتيش - يجب أن تكون متأكدًا من أن مشروعك في متناول العالم الخارجي.
- تنظيم التحقق من الصحة عبر بروتوكول API بالكامل ، وليس فقط نقاط النهاية الفردية.
- إنشاء نقطة النهاية بروميثيوس مع نتائج الاختبار.
مستوى التطبيق - رصد القياسات الصحية
الآن نحن نتحدث عن مقاييس الصحة الخارجية للخدمات.
قررنا أن نراقب جميع "الأقلام" للتطبيق باستخدام عمليات فحص خارجية ندعوها من نظام مراقبة خارجي. لكن هذه هي بالتحديد "الأقلام" التي يراها المستخدم. نريد أن نتأكد من أن الخدمات نفسها تعمل من أجلنا. إليك قصة أفضل: تحتوي K8s على فحوصات طبية حتى يتأكد المكعب على الأقل من أن الخدمة تعمل. لكن نصف الشيكات التي رأيتها هي نفس "عالم الترحيب" المطبوع. أي هنا ينسحب مرة واحدة بعد النشر ، أجابه أن كل شيء على ما يرام - وهذا كل شيء. وإذا كانت الخدمة تقع على واجهة API الخاصة بها ، فلديها عدد كبير من نقاط الدخول لواجهة برمجة التطبيقات نفسها ، والتي تحتاج أيضًا إلى مراقبتها ، لأننا نريد أن نعرف أنها تعمل. ونحن نراقب ذلك بالفعل في الداخل.
كيفية تنفيذها بشكل صحيح تقنيًا: تحدد كل خدمة نقطة نهاية حول أدائها الحالي ، وفي الرسوم البيانية لـ Grafana (أو أي تطبيق آخر) نرى حالة جميع الخدمات.
- يجب أن يؤدي كل تغيير في واجهة برمجة التطبيقات إلى تغيير عمليات الفحص.
- إنشاء خدمة جديدة على الفور مع مقاييس الصحة.
- يمكن للمشرف أن يأتي إلى المطورين ويسأل "أضفني اثنين من الميزات حتى أفهم كل شيء وإضافة معلومات حول هذا إلى نظام المراقبة الخاص بي." لكن المطورين يجيبون عادة ، "لن نضيف أي شيء قبل أسبوعين من الإصدار".
دع مديري التطوير يعلمون أنه ستكون هناك مثل هذه الخسائر ، كما يعلم رؤساء مديري التطوير أيضًا. لأنه عندما يسقط كل شيء ، سيظل شخص ما يتصل ويطلب مراقبة "الخدمة المتساقطة باستمرار" (ج) - بالمناسبة ، حدد مطورين لكتابة مكونات إضافية لـ Grafana - ستكون هذه مساعدة جيدة للمشرفين.
طبقة التطبيق - مراقبة التكامل
تركز مراقبة التكامل على مراقبة التواصل بين الأنظمة الحيوية للأعمال.
على سبيل المثال ، هناك 15 خدمة تتواصل مع بعضها البعض. هذه لم تعد المواقع الفردية. أي لا يمكننا سحب الخدمة من تلقاء نفسها ، get / helloworld ونفهم أن الخدمة تعمل. نظرًا لأن خدمة الويب الخاصة بوضع أمر يجب أن ترسل معلومات حول الطلب إلى الحافلة - يجب أن تتلقى خدمة المستودع هذه الرسالة من الحافلة وأن تعمل معها بشكل أكبر. ويجب على خدمة توزيع البريد الإلكتروني التعامل مع هذا بطريقة أو بأخرى ، إلخ.
وفقا لذلك ، لا يمكننا أن نفهم ، بدس في كل خدمة فردية ، أن كل هذا يعمل. لأن لدينا حافلة معينة يتواصل خلالها كل شيء ويتفاعل معه.
لذلك ، ينبغي أن تشير هذه المرحلة إلى مرحلة خدمات الاختبار للتفاعل مع الخدمات الأخرى. بعد مراقبة وسيط الرسائل ، لا يمكنك تنظيم مراقبة الاتصالات. إذا كانت هناك خدمة تُصدر البيانات وخدمة تستقبلها ، عند مراقبة وسيط ، سنرى فقط البيانات التي تطير من جانب إلى آخر. حتى لو تمكنا بطريقة ما من مراقبة تفاعل هذه البيانات داخل - أن بعض المنتجين نشر البيانات ، شخص ما يقرأها ، هذا التدفق لا يزال يذهب إلى كافكا - لا يزال لن يقدم لنا معلومات إذا أعطت خدمة واحدة رسالة في إصدار واحد ، ولكن لم تتوقع خدمة أخرى هذا الإصدار وتخطاها. لن نتعرف على ذلك ، لأن الخدمات ستخبرنا أن كل شيء يعمل.
كما أوصي به:
- للاتصال المتزامن: تنفذ نقطة النهاية طلبات الخدمات ذات الصلة. أي نأخذ نقطة النهاية هذه ، وسحب البرنامج النصي داخل الخدمة ، والذي يذهب إلى جميع النقاط ويقول "يمكنني أن أسحب إلى هناك ، وسحب هناك ، يمكنني سحب ..."
- للاتصال غير المتزامن: الرسائل الواردة - تقوم نقطة النهاية بفحص الحافلة بحثًا عن رسائل الاختبار وتعرض حالة المعالجة.
- للاتصال غير المتزامن: الرسائل الصادرة - نقطة النهاية ترسل رسائل اختبار إلى الناقل.
كما يحدث عادة: لدينا خدمة تلقي البيانات على الحافلة. نأتي إلى هذه الخدمة ونطلب منك التحدث عن صحة تكاملها. وإذا احتاجت الخدمة إلى بيع بعض الرسائل في مكان آخر (WebApp) ، فستصدر رسالة الاختبار هذه. وإذا سحبنا الخدمة من جانب OrderProcessing ، فسوف يقوم أولاً بنشر شيء يمكنه نشره بشكل مستقل ، وإذا كان هناك أي أشياء تابعة ، فإنه يقرأ مجموعة من رسائل الاختبار من الحافلة ، ويفهم أنه قادر على معالجتها والإبلاغ عنها و ، إذا لزم الأمر ، انشرها أكثر ، وحول هذا الموضوع - كل شيء على ما يرام ، أنا على قيد الحياة.
في كثير من الأحيان نسمع السؤال "كيف يمكننا اختبار هذا على البيانات القتالية؟" على سبيل المثال ، نحن نتحدث عن نفس الخدمة. يرسل الطلب رسائل إلى المستودع حيث يتم شطب البضائع: لا يمكننا اختبار هذا على بيانات القتال ، لأن "البضائع ستشطب!" الخروج: في المرحلة الأولية ، تخطط لهذا الاختبار بأكمله. لديك اختبارات الوحدة التي تفعل وهمية. لذا ، قم بذلك على مستوى أعمق ، حيث سيكون لديك قناة اتصال لن تضر بالأعمال.
مستوى البنية التحتية
مراقبة البنية التحتية هي ما يعتبر منذ فترة طويلة مراقبة نفسه.
- يمكن ويجب إطلاق مراقبة البنية التحتية كعملية منفصلة.
- يجب ألا تبدأ بمراقبة البنية التحتية في مشروع العمل ، حتى لو كنت تريد ذلك حقًا. هذا هو قرحة لجميع devops. "أولاً ، أراقب المجموعة ، أراقب البنية التحتية" - أي أولاً ، ستراقب ما يكمن أدناه ، لكنها لن تصعد إلى التطبيق. لأن التطبيق هو شيء غير مفهوم بالنسبة لل devopa. لقد تسربوه إليه ، وهو لا يفهم كيف يعمل. وهو يفهم البنية التحتية ويبدأ بها. لكن لا - تحتاج دائمًا إلى مراقبة التطبيق أولاً.
- . , , - . on-call, , « ». .
-
:
- ELK. . - , .
- APM. APM (NewRelic, BlackFire, Datadog). , - , .
- Tracing. , . , tracing — . – ! . Jaeger/Zipkin
- : . Grafana. PagerDuty. (, …). ,
- : ( , ). Oncall : , , , — ( — , : , ). , — (« — »), .
- « » workflow : , , . , — ; .
, :
- — Prometheus + Grafana;
- — ELK;
- APM Tracing — Jaeger (Zipkin).
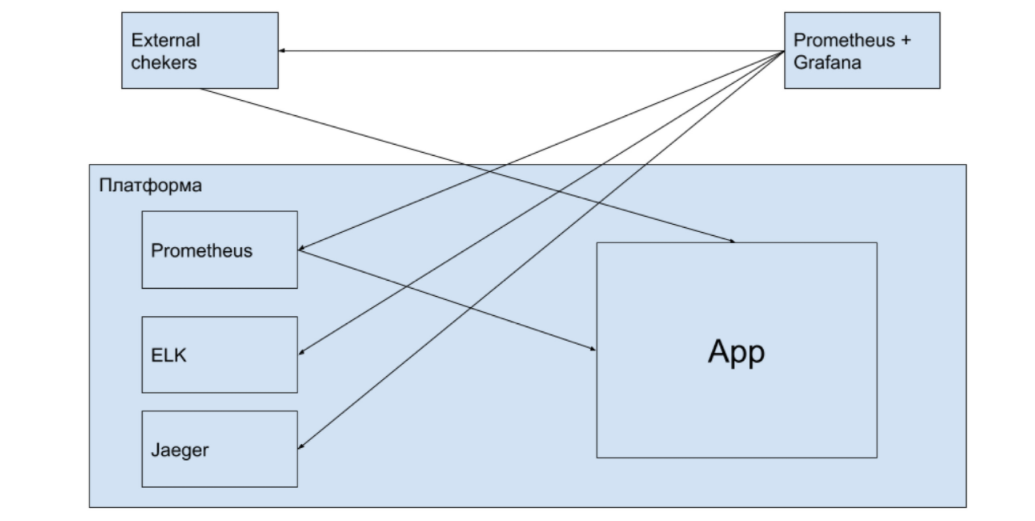
. , , , . , . , , , — .
, :
Prometheus Kubernetes — ?! , ? , , — , .
. . , Promtheus, , , . ? , , .
النتائج
- — , . 98% — . , , , --.
- : 30% , .
- , , - , — . , — .
- ( ) — .
- , , « » — , .
Saint Highload++.UPD ( ):
1. , , , «, , , ». , : DevOps , — , , , .
2. , « , — ITSumma». , — . , -, , , , , .
إذا كنت مهتمًا بأفكاري وأفكاري حولها وهكذا ، يمكنك
قراءة القناة :-)