لقد تعرفنا بالفعل على
محرك فهرسة PostgreSQL وواجهة طرق الوصول وناقشنا
فهارس التجزئة ،
B-tree ، وكذلك فهارس
GiST و
SP-GiST . وستحتوي هذه المقالة على مؤشر GIN.
GIN
"الجن؟ .. الجن ، على ما يبدو ، مثل هذا الخمور الأمريكي؟ .."
"أنا لست شرابًا ، يا ولد فضولي!" مرة أخرى اندلعت الرجل العجوز ، مرة أخرى أدرك نفسه وأخذ نفسه مرة أخرى في متناول اليد. "أنا لست شرابًا ، لكن روحًا قوية وغير متحمسة ، ولا يوجد مثل هذا السحر في العالم الذي لن أتمكن من فعله".- لازار لاجين ، "خوتاباخ القديمة".
يرمز Gin لمؤشر مقلوب معمم وينبغي اعتباره جنيًا وليس شرابًا.-
اقرأالمفهوم العام
GIN هو الفهرس المقلوب المعمم المختصر. هذا هو ما يسمى
فهرس مقلوب . إنه يتعامل مع أنواع البيانات التي قيمها ليست ذرية ، ولكنها تتألف من عناصر. سوف نسمي هذه الأنواع المركبة. وهذه ليست القيم التي يتم فهرستها ، ولكن العناصر الفردية ؛ كل عنصر يشير إلى القيم التي يحدث فيها.
والقياس الجيد لهذه الطريقة هو الفهرس في نهاية الكتاب ، والذي يوفر لكل صفحة قائمة بالصفحات التي يحدث فيها هذا المصطلح. يجب أن تضمن طريقة الوصول البحث السريع للعناصر المفهرسة ، تمامًا مثل الفهرس في كتاب. لذلك ، يتم تخزين هذه العناصر
كشجرة B مألوفة (يتم استخدام تطبيق مختلف وأبسط لذلك ، ولكن لا يهم في هذه الحالة). ترتبط مجموعة مرتبة من المراجع إلى صفوف الجدول التي تحتوي على قيم مركبة مع العنصر بكل عنصر. يعد الترتيب أمرًا ضروريًا لاسترجاع البيانات (لا يعني ترتيب الفرز الخاص بالأرقام القياسية للأرقام الكثير) ، ولكنه مهم بالنسبة للهيكل الداخلي للفهرس.
لا يتم حذف العناصر من فهرس GIN. يُفترض أن القيم التي تحتوي على عناصر يمكن أن تختفي أو تنشأ أو تختلف ، لكن مجموعة العناصر التي تتكون منها تكون مستقرة إلى حد ما. هذا الحل يبسط الخوارزميات بشكل كبير للعمل المتزامن لعدة عمليات مع الفهرس.
إذا كانت قائمة TIDs صغيرة جدًا ، فيمكن أن تنسجم مع نفس الصفحة مثل العنصر (وتسمى "قائمة النشر"). ولكن إذا كانت القائمة كبيرة ، فثمة حاجة إلى بنية بيانات أكثر كفاءة ، ونحن بالفعل على دراية بها - إنها شجرة B مرة أخرى. تقع هذه الشجرة على صفحات بيانات منفصلة (وتسمى "شجرة النشر").
لذلك ، يتكون فهرس GIN من شجرة B من العناصر ، وترتبط الأشجار B أو القوائم المسطحة من TIDs بصفوف أوراق تلك الشجرة B.
تمامًا مثل فهارس GiST و SP-GiST ، التي تمت مناقشتها سابقًا ، يوفر GIN مطور تطبيقات مع واجهة لدعم العمليات المختلفة عبر أنواع البيانات المركبة.
البحث عن النص الكامل
مجال التطبيق الرئيسي لطريقة GIN هو تسريع البحث عن النص الكامل ، وبالتالي ، من المعقول أن يتم استخدامه كمثال في مناقشة أكثر تفصيلاً لهذا الفهرس.
قدمت المقالة المتعلقة بـ GiST بالفعل مقدمة صغيرة للبحث عن النص الكامل ، لذلك دعونا ننتقل مباشرة إلى النقطة دون تكرار. من الواضح أن القيم المركبة في هذه الحالة هي
مستندات ، وعناصر هذه المستندات
معجم .
دعنا ننظر في المثال من المقال المتعلق بـ GiST:
postgres=# create table ts(doc text, doc_tsv tsvector); postgres=# insert into ts(doc) values ('Can a sheet slitter slit sheets?'), ('How many sheets could a sheet slitter slit?'), ('I slit a sheet, a sheet I slit.'), ('Upon a slitted sheet I sit.'), ('Whoever slit the sheets is a good sheet slitter.'), ('I am a sheet slitter.'), ('I slit sheets.'), ('I am the sleekest sheet slitter that ever slit sheets.'), ('She slits the sheet she sits on.'); postgres=# update ts set doc_tsv = to_tsvector(doc); postgres=# create index on ts using gin(doc_tsv);
يظهر الهيكل المحتمل لهذا الفهرس في الشكل:
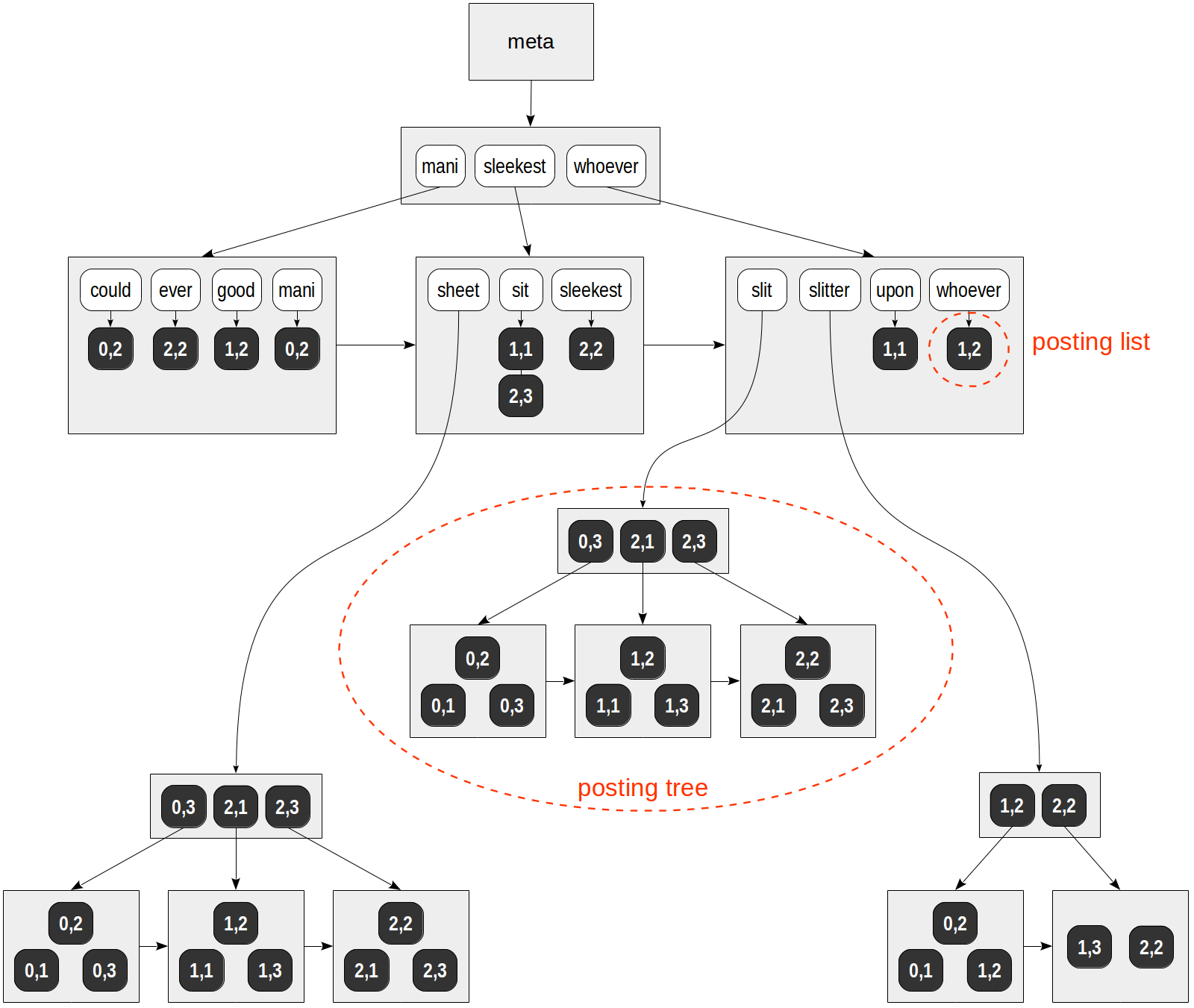
بخلاف جميع الأشكال السابقة ، يتم الإشارة إلى المراجع إلى صفوف الجدول (TID) بقيم رقمية على خلفية مظلمة (رقم الصفحة وموضعها على الصفحة) بدلاً من الأسهم.
postgres=# select ctid, left(doc,20), doc_tsv from ts;
ctid | left | doc_tsv -------+----------------------+--------------------------------------------------------- (0,1) | Can a sheet slitter | 'sheet':3,6 'slit':5 'slitter':4 (0,2) | How many sheets coul | 'could':4 'mani':2 'sheet':3,6 'slit':8 'slitter':7 (0,3) | I slit a sheet, a sh | 'sheet':4,6 'slit':2,8 (1,1) | Upon a slitted sheet | 'sheet':4 'sit':6 'slit':3 'upon':1 (1,2) | Whoever slit the she | 'good':7 'sheet':4,8 'slit':2 'slitter':9 'whoever':1 (1,3) | I am a sheet slitter | 'sheet':4 'slitter':5 (2,1) | I slit sheets. | 'sheet':3 'slit':2 (2,2) | I am the sleekest sh | 'ever':8 'sheet':5,10 'sleekest':4 'slit':9 'slitter':6 (2,3) | She slits the sheet | 'sheet':4 'sit':6 'slit':2 (9 rows)
في هذا المثال المضاربي ، تتوافق قائمة TIDs مع الصفحات العادية لجميع المعجمات ، لكن "sheet" و "slit" و "slitter". حدثت هذه المعجمات في العديد من المستندات ، وتم وضع قوائم TID الخاصة بهم في أشجار B الفردية.
بالمناسبة ، كيف يمكننا معرفة عدد الوثائق التي تحتوي على قاموس؟ بالنسبة لطاولة صغيرة ، ستعمل تقنية "مباشرة" ، كما هو موضح أدناه ، ولكن سوف نتعلم أكثر ما يجب فعله بجداول أكبر.
postgres=# select (unnest(doc_tsv)).lexeme, count(*) from ts group by 1 order by 2 desc;
lexeme | count ----------+------- sheet | 9 slit | 8 slitter | 5 sit | 2 upon | 1 mani | 1 whoever | 1 sleekest | 1 good | 1 could | 1 ever | 1 (11 rows)
لاحظ أيضًا أنه بخلاف شجرة B العادية ، يتم ربط صفحات فهرس GIN بقائمة أحادية الاتجاه بدلاً من قائمة ثنائية الاتجاه. هذا يكفي لأن اجتياز شجرة تتم بطريقة واحدة فقط.
مثال على استفسار
كيف سيتم تنفيذ الاستعلام التالي على سبيل المثال لدينا؟
postgres=# explain(costs off) select doc from ts where doc_tsv @@ to_tsquery('many & slitter');
QUERY PLAN --------------------------------------------------------------------- Bitmap Heap Scan on ts Recheck Cond: (doc_tsv @@ to_tsquery('many & slitter'::text)) -> Bitmap Index Scan on ts_doc_tsv_idx Index Cond: (doc_tsv @@ to_tsquery('many & slitter'::text)) (4 rows)
يتم استخراج lexemes الفردية (مفاتيح البحث) من الاستعلام أولاً: "mani" و "slitter". يتم ذلك عن طريق وظيفة API متخصصة تأخذ في الاعتبار نوع البيانات والاستراتيجية التي تحددها فئة المشغل:
postgres=# select amop.amopopr::regoperator, amop.amopstrategy from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop where opc.opcname = 'tsvector_ops' and opf.oid = opc.opcfamily and am.oid = opf.opfmethod and amop.amopfamily = opc.opcfamily and am.amname = 'gin' and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy -----------------------+-------------- @@(tsvector,tsquery) | 1 matching search query @@@(tsvector,tsquery) | 2 synonym for @@ (for backward compatibility) (2 rows)
في B-tree of lexemes ، سنجد بعد ذلك كلا المفتاحين ونستعرض قوائم جاهزة من TIDs. نحصل على:
ل "ماني" - (0،2).
عن "المشقق" - (0،1) ، (0،2) ، (1،2) ، (1،3) ، (2،2).
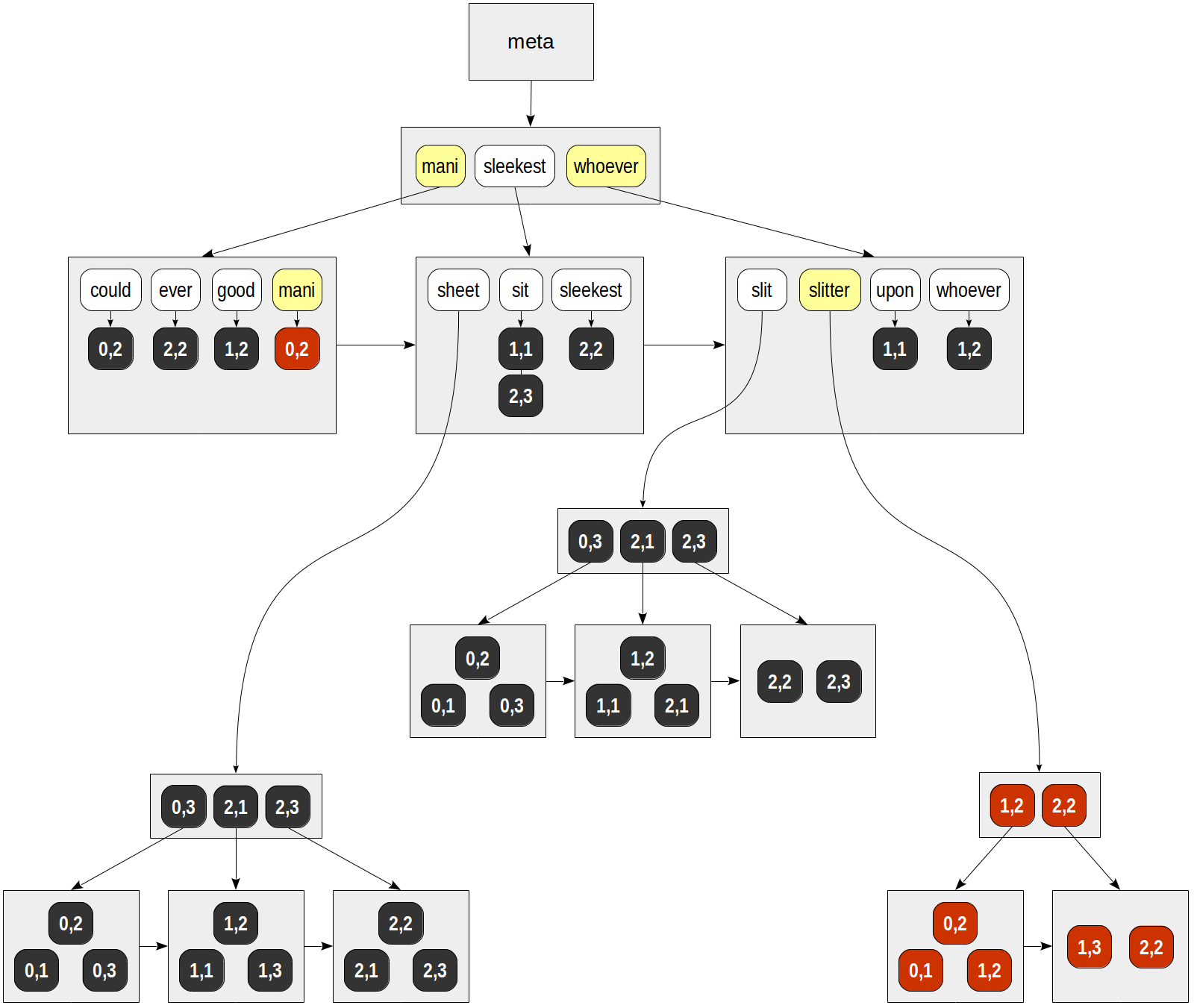
أخيرًا ، لكل TID تم العثور عليها ، تسمى وظيفة تناسق API ، والتي يجب أن تحدد أي من الصفوف التي تم العثور عليها تطابق استعلام البحث. نظرًا لأن lexemes في طلب البحث لدينا ينضم إلى Boolean "و" ، فإن الصف الوحيد الذي يتم إرجاعه هو (0،2):
| | | consistency | | | function TID | mani | slitter | slit & slitter -------+------+---------+---------------- (0,1) | f | T | f (0,2) | T | T | T (1,2) | f | T | f (1,3) | f | T | f (2,2) | f | T | f
والنتيجة هي:
postgres=# select doc from ts where doc_tsv @@ to_tsquery('many & slitter');
doc --------------------------------------------- How many sheets could a sheet slitter slit? (1 row)
إذا قارنا هذا النهج مع النهج الذي تمت مناقشته بالفعل لـ GiST ، فإن ميزة GIN للبحث عن النص الكامل تبدو واضحة. ولكن هناك ما هو أكثر مما تراه العين.
مسألة التحديث البطيء
الشيء هو أن إدخال البيانات أو تحديثها في فهرس GIN بطيء جدًا. يحتوي كل مستند عادةً على العديد من المعجم المطلوب فهرسته. لذلك ، عند إضافة مستند واحد فقط أو تحديثه ، يتعين علينا تحديث شجرة الفهرس بشكل كبير.
من ناحية أخرى ، إذا تم تحديث عدة مستندات في وقت واحد ، فقد تكون بعض معجمها كما هي ، وسيكون إجمالي حجم العمل أصغر من عند تحديث المستندات واحدًا تلو الآخر.
يحتوي فهرس GIN على معلمة تخزين "fastupdate" ، والتي يمكننا تحديدها أثناء إنشاء الفهرس وتحديثه لاحقًا:
postgres=# create index on ts using gin(doc_tsv) with (fastupdate = true);
عند تشغيل هذه المعلمة ، سيتم تجميع التحديثات في قائمة منفصلة غير مرتبة (على الصفحات المتصلة الفردية). عندما تصبح هذه القائمة كبيرة بما يكفي أو أثناء التنظيف ، يتم إجراء كافة التحديثات المتراكمة على الفور في الفهرس. يتم تحديد القائمة التي يجب اعتبارها "كبيرة بما يكفي" بواسطة معلمة التكوين "gin_pending_list_limit" أو بواسطة معلمة تخزين الاسم نفسه الفهرس.
ولكن هذا النهج له عيوب: أولاً ، يتم إبطاء البحث (نظرًا لأن القائمة غير المرتبة تحتاج إلى البحث بالإضافة إلى الشجرة) ، وثانيا ، قد يستغرق التحديث التالي وقتًا غير متوقع في حالة تجاوز قائمة غير مرتبة.
البحث عن تطابق جزئي
يمكننا استخدام التطابق الجزئي في البحث عن النص الكامل. على سبيل المثال ، ضع في الاعتبار الاستعلام التالي:
gin=# select doc from ts where doc_tsv @@ to_tsquery('slit:*');
doc -------------------------------------------------------- Can a sheet slitter slit sheets? How many sheets could a sheet slitter slit? I slit a sheet, a sheet I slit. Upon a slitted sheet I sit. Whoever slit the sheets is a good sheet slitter. I am a sheet slitter. I slit sheets. I am the sleekest sheet slitter that ever slit sheets. She slits the sheet she sits on. (9 rows)
سيعثر هذا الاستعلام على مستندات تحتوي على معجم تبدأ من "شق". في هذا المثال ، تكون مثل هذه الكتل "شق" و "شق".
بالتأكيد سوف يعمل الاستعلام على أي حال ، حتى بدون الفهارس ، لكن GIN يسمح أيضًا بتسريع البحث التالي:
postgres=# explain (costs off) select doc from ts where doc_tsv @@ to_tsquery('slit:*');
QUERY PLAN ------------------------------------------------------------- Bitmap Heap Scan on ts Recheck Cond: (doc_tsv @@ to_tsquery('slit:*'::text)) -> Bitmap Index Scan on ts_doc_tsv_idx Index Cond: (doc_tsv @@ to_tsquery('slit:*'::text)) (4 rows)
هنا يتم البحث عن جميع lexemes التي لها البادئة المحددة في استعلام البحث في الشجرة وينضم إليها Boolean "أو".
lexemes متكررة ونادرة
لمشاهدة كيفية عمل الفهرسة على البيانات الحية ، دعنا نأخذ أرشيف البريد الإلكتروني "pgsql-hackers" ، والذي استخدمناه بالفعل أثناء مناقشة GiST.
يحتوي هذا الإصدار من الأرشيف على 356125 رسالة بها تاريخ الإرسال والموضوع والمؤلف والنص.
fts=# alter table mail_messages add column tsv tsvector; fts=# update mail_messages set tsv = to_tsvector(body_plain);
NOTICE: word is too long to be indexed DETAIL: Words longer than 2047 characters are ignored. ... UPDATE 356125
fts=# create index on mail_messages using gin(tsv);
دعنا نفكر في lexeme الذي يحدث في العديد من الوثائق. سوف يفشل الاستعلام باستخدام "unnest" في العمل على مثل هذا الحجم الكبير من البيانات ، والتقنية الصحيحة هي استخدام الدالة "ts_stat" ، والتي توفر المعلومات حول lexemes ، وعدد المستندات التي حدثت فيها ، وإجمالي عدد التكرارات.
fts=# select word, ndoc from ts_stat('select tsv from mail_messages') order by ndoc desc limit 3;
word | ndoc -------+-------- re | 322141 wrote | 231174 use | 176917 (3 rows)
دعنا نختار "كتب".
وسوف نأخذ بعض الكلمات النادرة بالنسبة للبريد الإلكتروني للمطورين ، على سبيل المثال ، "وشم":
fts=# select word, ndoc from ts_stat('select tsv from mail_messages') where word = 'tattoo';
word | ndoc --------+------ tattoo | 2 (1 row)
هل هناك أي مستندات تحدث فيها كلا اللغتين؟ يبدو أن هناك:
fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote & tattoo');
count ------- 1 (1 row)
يطرح سؤال حول كيفية إجراء هذا الاستعلام. إذا حصلنا على قوائم TID لكلا اللغتين ، كما هو موصوف أعلاه ، فمن الواضح أن البحث سيكون غير فعال: سيتعين علينا المرور بأكثر من 200 ألف قيمة ، سيتم ترك واحدة منها فقط. لحسن الحظ ، باستخدام إحصائيات المخطط ، تفهم الخوارزمية أن "اللوكسم" المكتوب يحدث بشكل متكرر ، في حين أن "الوشم" يحدث بشكل متكرر. لذلك ، يتم إجراء البحث في lexeme نادرًا ، ثم يتم التحقق من الوثيقتين المستردتين بحثًا عن حدوث "lexeme" المكتوب. وهذا واضح من الاستعلام الذي يتم تنفيذه بسرعة:
fts=# \timing on fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote & tattoo');
count ------- 1 (1 row) Time: 0,959 ms
يستغرق البحث عن "كتب" وحده وقتًا أطول:
fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote');
count -------- 231174 (1 row) Time: 2875,543 ms (00:02,876)
هذا التحسين بالتأكيد لا يعمل فقط مع اثنين من القواميس ، ولكن في الحالات الأكثر تعقيدًا أيضًا.
الحد من نتيجة الاستعلام
إحدى ميزات طريقة الوصول إلى GIN هي أن النتيجة تُرجع دائمًا كصورة نقطية: لا يمكن لهذه الطريقة إرجاع النتيجة TID بواسطة TID. لهذا السبب ، تستخدم جميع خطط الاستعلام في هذه المقالة المسح النقطي.
لذلك ، يعد الحد من نتائج مسح الفهرس باستخدام جملة LIMIT غير فعال. انتبه إلى التكلفة المتوقعة للعملية (حقل "التكلفة" في عقدة "الحد"):
fts=# explain (costs off) select * from mail_messages where tsv @@ to_tsquery('wrote') limit 1;
QUERY PLAN ----------------------------------------------------------------------------------------- Limit (cost=1283.61..1285.13 rows=1) -> Bitmap Heap Scan on mail_messages (cost=1283.61..209975.49 rows=137207) Recheck Cond: (tsv @@ to_tsquery('wrote'::text)) -> Bitmap Index Scan on mail_messages_tsv_idx (cost=0.00..1249.30 rows=137207) Index Cond: (tsv @@ to_tsquery('wrote'::text)) (5 rows)
تقدر التكلفة بـ 1285.13 ، وهي أكبر قليلاً من تكلفة بناء الصورة النقطية بأكملها 1249.30 (حقل "التكلفة" في عقدة مسح صورة نقطية).
لذلك ، يحتوي الفهرس على قدرة خاصة للحد من عدد النتائج. يتم تحديد قيمة العتبة في معلمة التكوين "gin_fuzzy_search_limit" وتساوي الصفر افتراضيًا (لا يتم تحديد أي قيود). ولكن يمكننا تعيين قيمة العتبة:
fts=# set gin_fuzzy_search_limit = 1000; fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote');
count ------- 5746 (1 row)
fts=# set gin_fuzzy_search_limit = 10000; fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote');
count ------- 14726 (1 row)
كما نرى ، يختلف عدد الصفوف التي يتم إرجاعها بواسطة الاستعلام عن قيم معلمات مختلفة (إذا تم استخدام الوصول إلى الفهرس). القيد ليس صارمًا: يمكن إرجاع عدد أكبر من الصفوف المحددة ، مما يبرر الجزء "الغامض" من اسم المعلمة.
التمثيل المضغوط
من بين البقية ، فهارس GIN جيدة بفضل ضغطها. أولاً ، إذا حدث نفس المعجم في عدة مستندات (وهذه هي الحالة عادةً) ، فسيتم تخزينها في الفهرس مرة واحدة فقط. ثانياً ، يتم تخزين TID في الفهرس بطريقة مرتبة ، وهذا يتيح لنا استخدام ضغط بسيط: يتم تخزين كل TID التالي في القائمة في الواقع اختلافًا عن السابق. هذا عادة ما يكون عددًا صغيرًا ، وهو ما يتطلب عددًا أقل من وحدات البت التي تحتوي على TID كامل بستة بايت.
للحصول على فكرة عن الحجم ، دعنا نبني شجرة B من نص الرسائل. لكن المقارنة العادلة لن تحدث بالتأكيد:
- تم بناء GIN على نوع بيانات مختلف ("tsvector" بدلاً من "text") ، وهو أصغر ،
- في الوقت نفسه ، يجب تقصير حجم رسائل B-tree إلى حوالي كيلو بايت.
ومع ذلك ، فإننا نواصل:
fts=# create index mail_messages_btree on mail_messages(substring(body_plain for 2048));
سنقوم ببناء مؤشر GiST أيضًا:
fts=# create index mail_messages_gist on mail_messages using gist(tsv);
حجم الفهارس عند "فراغ كامل":
fts=# select pg_size_pretty(pg_relation_size('mail_messages_tsv_idx')) as gin, pg_size_pretty(pg_relation_size('mail_messages_gist')) as gist, pg_size_pretty(pg_relation_size('mail_messages_btree')) as btree;
gin | gist | btree --------+--------+-------- 179 MB | 125 MB | 546 MB (1 row)
نظرًا لضغط التمثيل ، يمكننا محاولة استخدام فهرس GIN أثناء الترحيل من Oracle كبديل لفهارس الصورة النقطية (دون الخوض في التفاصيل ، أقدم
مرجعًا إلى منشور Lewis لعقول فضولية). كقاعدة عامة ، يتم استخدام فهارس الصور النقطية للحقول التي تحتوي على عدد قليل من القيم الفريدة ، وهو أمر ممتاز أيضًا بالنسبة إلى GIN. وكما هو موضح
في المقالة الأولى ، يمكن لـ PostgreSQL إنشاء صورة نقطية بناءً على أي فهرس ، بما في ذلك GIN ، أثناء الطيران.
GiST أو الجن؟
بالنسبة إلى العديد من أنواع البيانات ، تتوفر فئات المشغلين لكل من GiST و GIN ، مما يثير سؤالًا حول الفهرس الذي يجب استخدامه. ربما ، يمكننا بالفعل تقديم بعض الاستنتاجات.
وكقاعدة عامة ، يتفوق GIN على GiST في الدقة وسرعة البحث. إذا لم يتم تحديث البيانات بشكل متكرر وكانت هناك حاجة إلى بحث سريع ، فسيكون GIN على الأرجح خيارًا.
من ناحية أخرى ، إذا تم تحديث البيانات بشكل مكثف ، فقد يبدو أن التكاليف العامة لتحديث GIN كبيرة للغاية. في هذه الحالة ، سيتعين علينا مقارنة الخيارين واختيار الخيار الذي تتوازن خصائصه بشكل أفضل.
المصفوفات
مثال آخر لاستخدام GIN هو فهرسة المصفوفات. في هذه الحالة ، تدخل عناصر الصفيف في الفهرس ، والذي يسمح بتسريع عدد من العمليات على المصفوفات:
postgres=# select amop.amopopr::regoperator, amop.amopstrategy from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop where opc.opcname = 'array_ops' and opf.oid = opc.opcfamily and am.oid = opf.opfmethod and amop.amopfamily = opc.opcfamily and am.amname = 'gin' and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy -----------------------+-------------- &&(anyarray,anyarray) | 1 intersection @>(anyarray,anyarray) | 2 contains array <@(anyarray,anyarray) | 3 contained in array =(anyarray,anyarray) | 4 equality (4 rows)
تحتوي
قاعدة البيانات التجريبية الخاصة بنا على طريقة "طرق" تتضمن معلومات عن الرحلات الجوية. من بين البقية ، يحتوي هذا العرض على عمود "days_of_week" - مجموعة من أيام الأسبوع عندما تتم الرحلات الجوية. على سبيل المثال ، تغادر رحلة من فنوكوفو إلى غيليندزيك يومي الثلاثاء والخميس والأحد:
demo=# select departure_airport_name, arrival_airport_name, days_of_week from routes where flight_no = 'PG0049';
departure_airport_name | arrival_airport_name | days_of_week ------------------------+----------------------+-------------- Vnukovo | Gelendzhik | {2,4,7} (1 row)
لبناء الفهرس ، دعنا "نجسد" العرض في جدول:
demo=# create table routes_t as select * from routes; demo=# create index on routes_t using gin(days_of_week);
الآن يمكننا استخدام الفهرس للتعرف على جميع الرحلات التي تغادر يومي الثلاثاء والخميس والأحد:
demo=# explain (costs off) select * from routes_t where days_of_week = ARRAY[2,4,7];
QUERY PLAN ----------------------------------------------------------- Bitmap Heap Scan on routes_t Recheck Cond: (days_of_week = '{2,4,7}'::integer[]) -> Bitmap Index Scan on routes_t_days_of_week_idx Index Cond: (days_of_week = '{2,4,7}'::integer[]) (4 rows)
يبدو أن هناك ستة منهم:
demo=# select flight_no, departure_airport_name, arrival_airport_name, days_of_week from routes_t where days_of_week = ARRAY[2,4,7];
flight_no | departure_airport_name | arrival_airport_name | days_of_week -----------+------------------------+----------------------+-------------- PG0005 | Domodedovo | Pskov | {2,4,7} PG0049 | Vnukovo | Gelendzhik | {2,4,7} PG0113 | Naryan-Mar | Domodedovo | {2,4,7} PG0249 | Domodedovo | Gelendzhik | {2,4,7} PG0449 | Stavropol | Vnukovo | {2,4,7} PG0540 | Barnaul | Vnukovo | {2,4,7} (6 rows)
كيف يتم تنفيذ هذا الاستعلام؟ بالضبط بنفس الطريقة الموضحة أعلاه:
- من الصفيف {2،4،7} ، الذي يلعب دور استعلام البحث هنا ، يتم استخراج العناصر (كلمات البحث الرئيسية). من الواضح أن هذه هي قيم "2" و "4" و "7".
- في شجرة العناصر ، يتم العثور على المفاتيح المستخرجة ، ويتم تحديد قائمة TID لكل منها.
- من بين جميع TID التي تم العثور عليها ، تحدد وظيفة التناسق تلك التي تطابق المشغل من الاستعلام. بالنسبة إلى
= عامل التشغيل ، تتطابق مع TID فقط تلك التي حدثت في جميع القوائم الثلاث (بمعنى آخر ، يجب أن يحتوي الصفيف الأولي على جميع العناصر). لكن هذا لا يكفي: يلزم أيضًا ألا يحتوي الصفيف على أي قيم أخرى ، ولا يمكننا التحقق من هذا الشرط مع الفهرس. لذلك ، في هذه الحالة ، تطلب طريقة الوصول من محرك الفهرسة إعادة فحص جميع TID التي تم إرجاعها مع الجدول.
ومن المثير للاهتمام ، أن هناك استراتيجيات (على سبيل المثال ، "مضمنة في صفيف") لا يمكنها التحقق من أي شيء ويجب إعادة التحقق من جميع TID الموجودة في الجدول.
ولكن ماذا نفعل إذا كنا بحاجة إلى معرفة الرحلات الجوية التي تغادر من موسكو أيام الثلاثاء والخميس والأحد؟ لن يدعم الفهرس الحالة الإضافية ، والتي ستدخل في عمود "التصفية".
demo=# explain (costs off) select * from routes_t where days_of_week = ARRAY[2,4,7] and departure_city = 'Moscow';
QUERY PLAN ----------------------------------------------------------- Bitmap Heap Scan on routes_t Recheck Cond: (days_of_week = '{2,4,7}'::integer[]) Filter: (departure_city = 'Moscow'::text) -> Bitmap Index Scan on routes_t_days_of_week_idx Index Cond: (days_of_week = '{2,4,7}'::integer[]) (5 rows)
هذا على ما يرام (يحدد الفهرس ستة صفوف فقط على أي حال) ، ولكن في الحالات التي يزيد فيها الشرط الإضافي من القدرة الانتقائية ، يكون من المطلوب الحصول على مثل هذا الدعم. ومع ذلك ، لا يمكننا فقط إنشاء الفهرس:
demo=# create index on routes_t using gin(days_of_week,departure_city);
ERROR: data type text has no default operator class for access method "gin" HINT: You must specify an operator class for the index or define a default operator class for the data type.
ولكن التمديد "
btree_gin " سيساعد ، حيث يضيف فئات مشغلي GIN التي تحاكي عمل شجرة B العادية.
demo=# create extension btree_gin; demo=# create index on routes_t using gin(days_of_week,departure_city); demo=# explain (costs off) select * from routes_t where days_of_week = ARRAY[2,4,7] and departure_city = 'Moscow';
QUERY PLAN --------------------------------------------------------------------- Bitmap Heap Scan on routes_t Recheck Cond: ((days_of_week = '{2,4,7}'::integer[]) AND (departure_city = 'Moscow'::text)) -> Bitmap Index Scan on routes_t_days_of_week_departure_city_idx Index Cond: ((days_of_week = '{2,4,7}'::integer[]) AND (departure_city = 'Moscow'::text)) (4 rows)
JSONB
أحد الأمثلة الأخرى لنوع البيانات المركب الذي يحتوي على دعم GIN مضمن هو JSON. للعمل مع قيم JSON ، يتم تعريف عدد من العوامل والوظائف في الوقت الحالي ، ويمكن تسريع بعضها باستخدام فهارس:
postgres=# select opc.opcname, amop.amopopr::regoperator, amop.amopstrategy as str from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop where opc.opcname in ('jsonb_ops','jsonb_path_ops') and opf.oid = opc.opcfamily and am.oid = opf.opfmethod and amop.amopfamily = opc.opcfamily and am.amname = 'gin' and amop.amoplefttype = opc.opcintype;
opcname | amopopr | str ----------------+------------------+----- jsonb_ops | ?(jsonb,text) | 9 top-level key exists jsonb_ops | ?|(jsonb,text[]) | 10 some top-level key exists jsonb_ops | ?&(jsonb,text[]) | 11 all top-level keys exist jsonb_ops | @>(jsonb,jsonb) | 7 JSON value is at top level jsonb_path_ops | @>(jsonb,jsonb) | 7 (5 rows)
كما نرى ، تتوفر فئتان من عوامل التشغيل: "jsonb_ops" و "jsonb_path_ops".
يتم استخدام فئة المشغل الأولى "jsonb_ops" افتراضيًا. جميع المفاتيح والقيم وعناصر الصفيف تصل إلى الفهرس كعناصر في وثيقة JSON الأولية. تتم إضافة سمة إلى كل عنصر من هذه العناصر ، مما يشير إلى ما إذا كان هذا العنصر مفتاحًا (وهذا ضروري لاستراتيجيات "موجودة" ، والتي تميز بين المفاتيح والقيم).
على سبيل المثال ، دعونا نمثل بضعة صفوف من "التوجيهات" كـ JSON كما يلي:
demo=# create table routes_jsonb as select to_jsonb(t) route from ( select departure_airport_name, arrival_airport_name, days_of_week from routes order by flight_no limit 4 ) t; demo=# select ctid, jsonb_pretty(route) from routes_jsonb;
ctid | jsonb_pretty -------+------------------------------------------------- (0,1) | { + | "days_of_week": [ + | 1 + | ], + | "arrival_airport_name": "Surgut", + | "departure_airport_name": "Ust-Ilimsk" + | } (0,2) | { + | "days_of_week": [ + | 2 + | ], + | "arrival_airport_name": "Ust-Ilimsk", + | "departure_airport_name": "Surgut" + | } (0,3) | { + | "days_of_week": [ + | 1, + | 4 + | ], + | "arrival_airport_name": "Sochi", + | "departure_airport_name": "Ivanovo-Yuzhnyi"+ | } (0,4) | { + | "days_of_week": [ + | 2, + | 5 + | ], + | "arrival_airport_name": "Ivanovo-Yuzhnyi", + | "departure_airport_name": "Sochi" + | } (4 rows)
demo=# create index on routes_jsonb using gin(route);
قد يبدو الفهرس كما يلي:
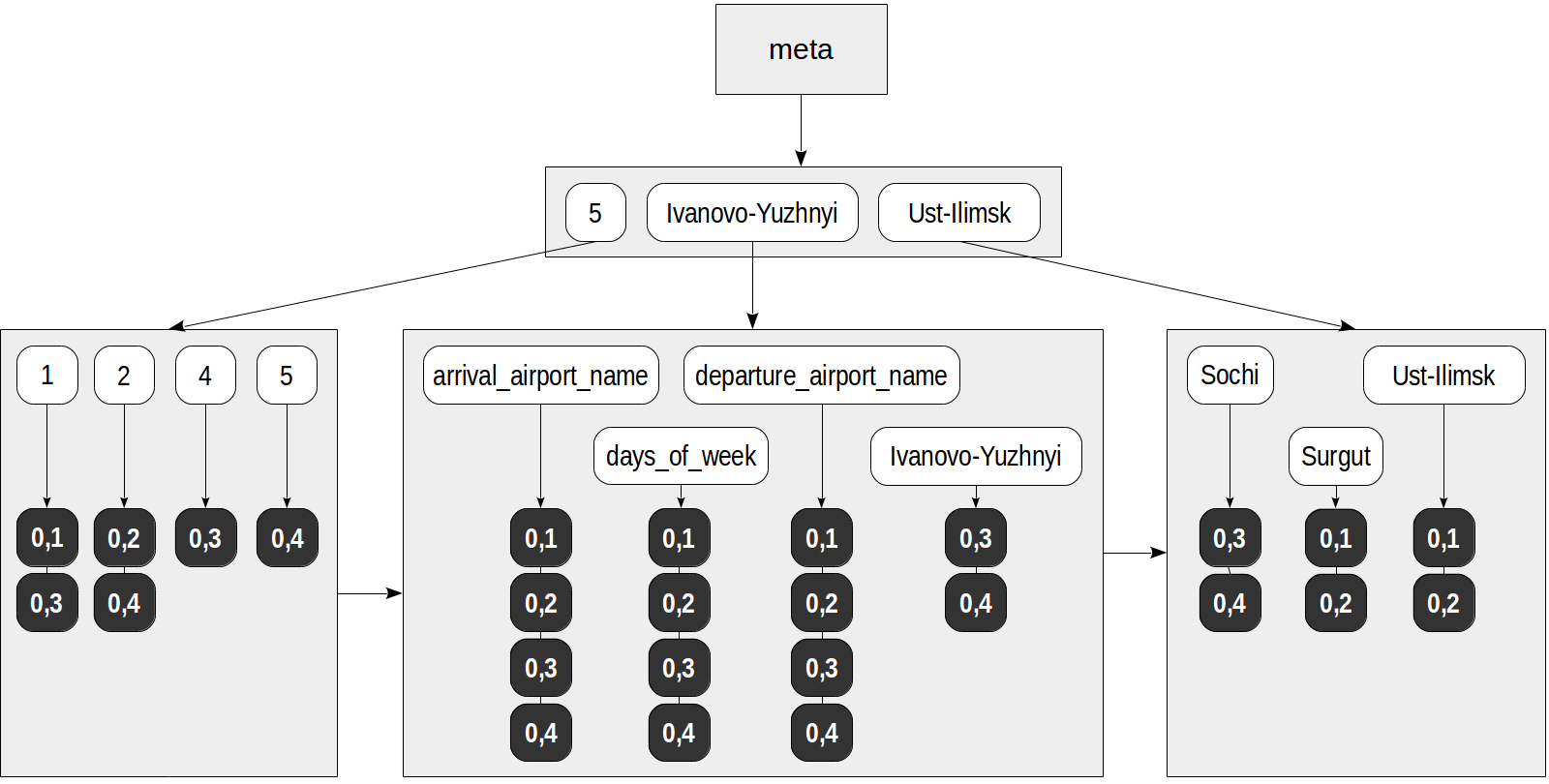
الآن ، قد يتم إجراء استعلام مثل هذا ، على سبيل المثال ، باستخدام الفهرس:
demo=# explain (costs off) select jsonb_pretty(route) from routes_jsonb where route @> '{"days_of_week": [5]}';
QUERY PLAN --------------------------------------------------------------- Bitmap Heap Scan on routes_jsonb Recheck Cond: (route @> '{"days_of_week": [5]}'::jsonb) -> Bitmap Index Scan on routes_jsonb_route_idx Index Cond: (route @> '{"days_of_week": [5]}'::jsonb) (4 rows)
بدءًا من جذر مستند JSON ، يتحقق عامل التشغيل
@> ما إذا كان المسار المحدد (
"days_of_week": [5] ) يحدث. هنا سيعود الاستعلام صف واحد:
demo=# select jsonb_pretty(route) from routes_jsonb where route @> '{"days_of_week": [5]}';
jsonb_pretty ------------------------------------------------ { + "days_of_week": [ + 2, + 5 + ], + "arrival_airport_name": "Ivanovo-Yuzhnyi",+ "departure_airport_name": "Sochi" + } (1 row)
يتم تنفيذ الاستعلام على النحو التالي:
- في استعلام البحث (
"days_of_week": [5] ) يتم استخراج العناصر (مفاتيح البحث): "days_of_week" و "5".
- في شجرة العناصر ، تم العثور على المفاتيح المستخرجة ، ولكل منهم تحديد قائمة TID: من أجل "5" - (0.4) ، و "days_of_week" - (0،1) ، (0،2) ) ، (0.3) ، (0.4).
- من بين جميع TID التي تم العثور عليها ، تحدد وظيفة التناسق تلك التي تطابق المشغل من الاستعلام. بالنسبة إلى عامل التشغيل
@> ، لن تعمل المستندات التي لا تحتوي على جميع عناصر استعلام البحث بشكل مؤكد ، لذا تبقى فقط (0،4). لكننا ما زلنا بحاجة إلى إعادة فحص TID لليسار مع الجدول لأنه غير واضح من الفهرس بالترتيب الذي تحدث به العناصر الموجودة في وثيقة JSON.
لاكتشاف المزيد من التفاصيل عن المشغلين الآخرين ، يمكنك قراءة
الوثائق .
بالإضافة إلى العمليات التقليدية للتعامل مع JSON ، فإن امتداد "jsquery" متاح منذ فترة طويلة ، والذي يحدد لغة الاستعلام ذات الإمكانات الأكثر ثراءً (وبالتأكيد ، بدعم من فهارس GIN). إلى جانب ذلك ، في عام 2016 ، تم إصدار معيار SQL جديد ، والذي يحدد مجموعة العمليات الخاصة به ولغة الاستعلام "مسار SQL / JSON". تم تنفيذ هذا المعيار بالفعل ، ونعتقد أنه سيظهر في PostgreSQL 11.
تم الالتزام بتصحيح مسار SQL / JSON أخيرًا لـ PostgreSQL 12 ، بينما لا تزال القطع الأخرى في الطريق. نأمل أن نرى الميزة المطبقة بالكامل في PostgreSQL 13.
الداخلية
يمكننا البحث داخل فهرس GIN باستخدام ملحق "
pageinspect ".
fts=# create extension pageinspect;
المعلومات الواردة من صفحة التعريف تعرض إحصائيات عامة:
fts=# select * from gin_metapage_info(get_raw_page('mail_messages_tsv_idx',0));
-[ RECORD 1 ]----+----------- pending_head | 4294967295 pending_tail | 4294967295 tail_free_size | 0 n_pending_pages | 0 n_pending_tuples | 0 n_total_pages | 22968 n_entry_pages | 13751 n_data_pages | 9216 n_entries | 1423598 version | 2
توفر
بنية الصفحة مساحة خاصة حيث تخزن طرق الوصول معلوماتهم ؛ هذا المجال هو "مبهمة" للبرامج العادية مثل الفراغ. تعرض وظيفة "Gin_page_opaque_info" هذه البيانات لـ GIN. على سبيل المثال ، يمكننا التعرف على مجموعة صفحات الفهرس:
fts=# select flags, count(*) from generate_series(1,22967) as g(id),
flags | count ------------------------+------- {meta} | 1 meta page {} | 133 internal page of element B-tree {leaf} | 13618 leaf page of element B-tree {data} | 1497 internal page of TID B-tree {data,leaf,compressed} | 7719 leaf page of TID B-tree (5 rows)
توفر وظيفة "Gin_leafpage_items" معلومات عن TIDs المخزنة في الصفحات {data ، ورقة ، مضغوطة}:
fts=# select * from gin_leafpage_items(get_raw_page('mail_messages_tsv_idx',2672));
-[ RECORD 1 ]--------------------------------------------------------------------- first_tid | (239,44) nbytes | 248 tids | {"(239,44)","(239,47)","(239,48)","(239,50)","(239,52)","(240,3)",... -[ RECORD 2 ]--------------------------------------------------------------------- first_tid | (247,40) nbytes | 248 tids | {"(247,40)","(247,41)","(247,44)","(247,45)","(247,46)","(248,2)",... ...
لاحظ هنا أن صفحات ترك TIDs تحتوي فعليًا على قوائم مضغوطة صغيرة من المؤشرات إلى صفوف الجدول بدلاً من المؤشرات الفردية.
خصائص
دعونا نلقي نظرة على خصائص طريقة الوصول إلى GIN (
تم تقديم الاستعلامات
بالفعل ).
amname | name | pg_indexam_has_property --------+---------------+------------------------- gin | can_order | f gin | can_unique | f gin | can_multi_col | t gin | can_exclude | f
ومن المثير للاهتمام ، يدعم GIN إنشاء فهارس متعددة الأعمدة. ومع ذلك ، بخلاف شجرة B العادية ، بدلاً من المفاتيح المركبة ، سيظل فهرس الأعمدة المتعددة يخزن العناصر الفردية ، وسيتم الإشارة إلى رقم العمود لكل عنصر.
تتوفر خصائص طبقة الفهرس التالية:
name | pg_index_has_property ---------------+----------------------- clusterable | f index_scan | f bitmap_scan | t backward_scan | f
لاحظ أن إرجاع النتائج TID بواسطة TID (مسح الفهرس) غير معتمد ؛ المسح النقطي الوحيد هو ممكن.
الفحص الخلفي غير مدعوم أيضًا: هذه الميزة ضرورية لفهرسة الفهرس فقط ، ولكن ليس للفحص النقطي.
وفيما يلي خصائص طبقة العمود:
name | pg_index_column_has_property --------------------+------------------------------ asc | f desc | f nulls_first | f nulls_last | f orderable | f distance_orderable | f returnable | f search_array | f search_nulls | f
لا يوجد شيء متاح هنا: لا يوجد فرز (وهو أمر واضح) ، لا فائدة من الفهرس كغطاء (حيث أن المستند نفسه غير مخزّن في الفهرس) ، لا يتم معالجة NULLs (لأنه لا معنى لعناصر النوع المركب) .
أنواع البيانات الأخرى
تتوفر بعض الإضافات الإضافية التي تضيف دعمًا لـ GIN لبعض أنواع البيانات.
- تمكننا " pg_trgm " من تحديد "تشابه" الكلمات من خلال مقارنة عدد متواليات الحروف الثلاثة المتساوية (ثلاثية) المتاحة. تتم إضافة فئتي عاملين ، "gist_trgm_ops" و "gin_trgm_ops" ، اللذين يدعمان العديد من العوامل ، بما في ذلك المقارنة عن طريق LIKE والتعبيرات العادية. يمكننا استخدام هذا الامتداد مع البحث عن النص الكامل لاقتراح خيارات الكلمات لإصلاح الأخطاء المطبعية.
- " hstore " تنفذ "القيمة الرئيسية" التخزين. بالنسبة لنوع البيانات هذا ، تتوفر فئات المشغلين لطرق الوصول المختلفة ، بما في ذلك GIN. ومع ذلك ، مع إدخال نوع البيانات "jsonb" ، لا توجد أسباب خاصة لاستخدام "hstore".
- تعمل " intarray " على توسيع وظائف الصفائف الصحيحة. يتضمن دعم الفهرس GiST ، وكذلك GIN (فئة المشغل "gin__int_ops").
وقد سبق ذكر هذين الامتدادين أعلاه:
- يضيف " btree_gin " دعم GIN لأنواع البيانات المنتظمة من أجل استخدامها في فهرس متعدد الأعمدة إلى جانب الأنواع المركبة.
- يعرّف " jsquery " لغة لاستعلام JSON وفئة مشغل لدعم الفهرس لهذه اللغة. لا يتم تضمين هذا الامتداد في تسليم PostgreSQL قياسي.
اقرأ على .