كيفية العمل بفعالية مع json في R؟
إنه استمرار للمنشورات السابقة .
بيان المشكلة
كقاعدة عامة ، المصدر الرئيسي للبيانات بتنسيق json هو REST API. يتيح استخدام json ، بالإضافة إلى استقلال النظام الأساسي وراحة إدراك الإنسان للبيانات ، تبادل أنظمة البيانات غير المهيكلة مع بنية شجرة معقدة.
في مهام بناء API ، هذا مريح للغاية. من السهل ضمان إصدار بروتوكولات الاتصال ، ومن السهل توفير مرونة تبادل المعلومات. في الوقت نفسه ، فإن تعقيد بنية البيانات (يمكن أن تكون مستويات التعشيش 5 ، 6 ، 10 أو حتى أكثر) ليس مخيفًا ، لأن كتابة محلل مرن لسجل واحد يأخذ في الاعتبار كل شيء وكل شيء ليس بالغ الصعوبة.
تتضمن مهام معالجة البيانات أيضًا الحصول على البيانات من مصادر خارجية ، بما في ذلك في شكل json. يحتوي R على مجموعة جيدة من الحزم ، خاصة jsonlite ، المصممة لتحويل json إلى كائنات R ( list أو ، data.frame ، إذا سمحت بنية البيانات).
ومع ذلك ، في الممارسة العملية ، فئتان من المشاكل غالبا ما تنشأ عند استخدام jsonlite وما شابه ذلك يصبح غير فعال للغاية. تبدو المهام مثل هذا:
- معالجة كمية كبيرة من البيانات (وحدة القياس - غيغا بايت) التي تم الحصول عليها أثناء تشغيل أنظمة المعلومات المختلفة ؛
- يجمع بين عدد كبير من الاستجابات المتغيرة الهيكلية المستلمة خلال حزمة من طلبات REST API ذات المعلمات في تمثيل مستطيل موحد (
data.frame ).
مثال على بنية مماثلة في الرسوم التوضيحية:
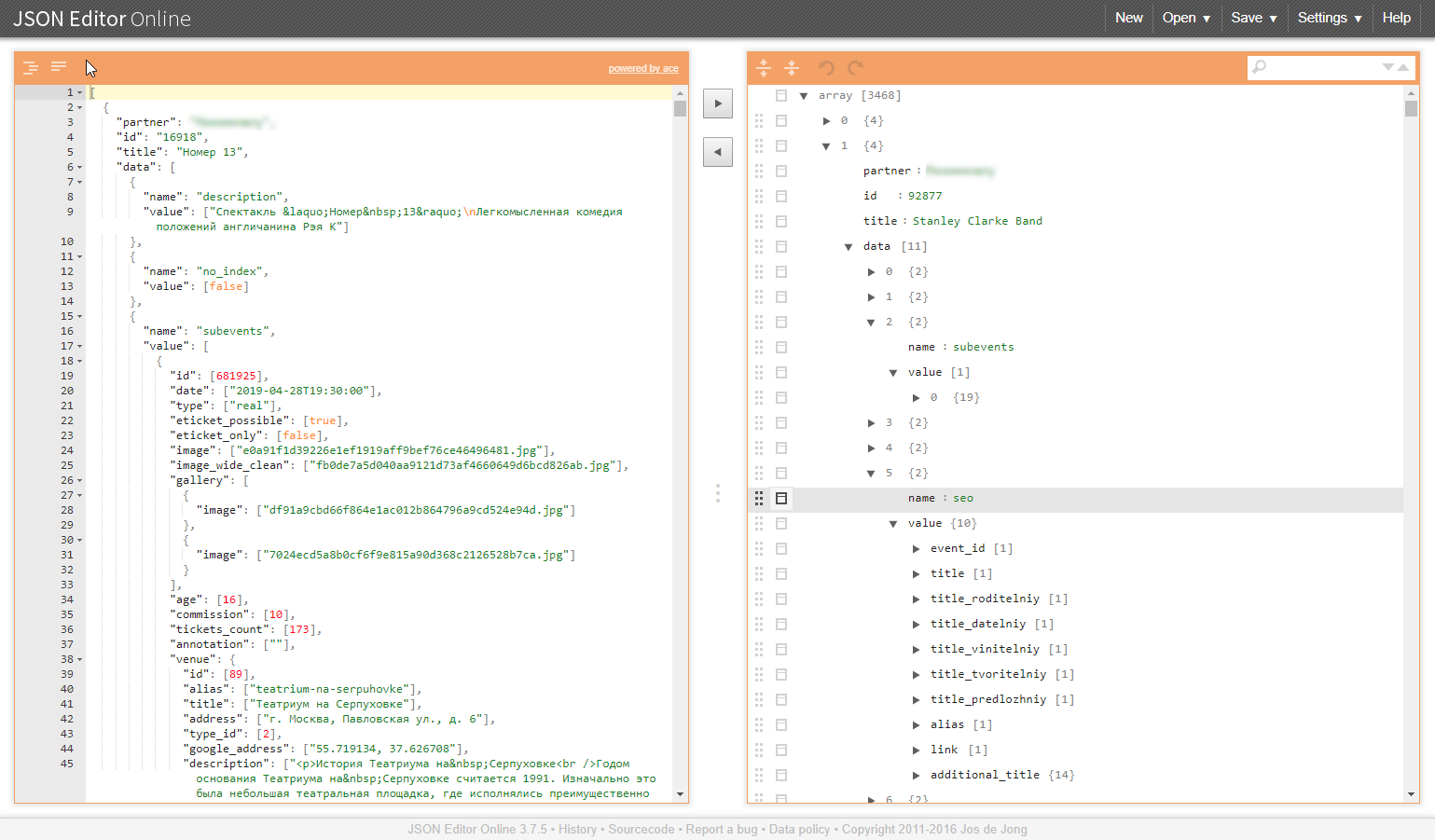
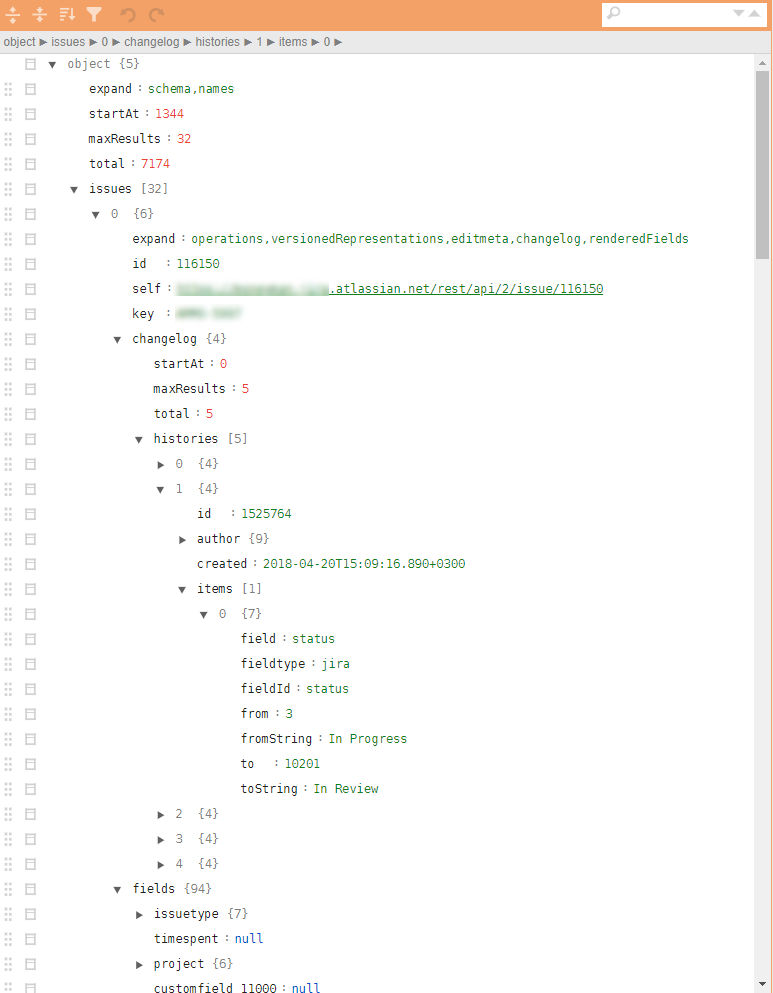
لماذا هذه الفئات مهمة إشكالية؟
كمية كبيرة من البيانات
كقاعدة عامة ، يعتبر التفريغ من أنظمة المعلومات بتنسيق json كتلة بيانات غير قابلة للتجزئة. لتحليلها بشكل صحيح ، تحتاج إلى قراءة كل شيء وتجاوز حجمه بالكامل.
المشاكل المستحثة:
- هناك حاجة إلى كمية مقابلة من ذاكرة الوصول العشوائي وموارد الحوسبة ؛
- تعتمد سرعة التحليل بشدة على جودة المكتبات المستخدمة ، وحتى إذا كانت هناك موارد كافية ، يمكن أن يكون وقت التحويل عشرات أو حتى مئات الدقائق ؛
- في حالة فشل التحليل ، لا يتم الحصول على نتيجة في المخرجات ، ولا يوجد سبب للأمل في أن كل شيء سوف يسير دائمًا بشكل سلس ، وليس هناك سبب ، بل العكس ؛
- سيكون ناجحًا جدًا إذا كانت البيانات التي تم تحليلها يمكن تحويلها إلى
data.frame .
دمج هياكل شجرة
تنشأ مهام مماثلة ، على سبيل المثال ، عندما يكون من الضروري تجميع الأدلة التي تتطلبها عملية الأعمال للعمل بواسطة حزمة من الطلبات من خلال واجهة برمجة التطبيقات. بالإضافة إلى ذلك ، تشير الدلائل إلى التوحيد والاستعداد للتضمين في خط الأنابيب التحليلي والتحميل المحتمل إلى قاعدة البيانات. وهذا مرة أخرى يجعل من الضروري تحويل هذه البيانات الموجزة إلى data.frame بيانات.
المشاكل المستحثة:
- هياكل شجرة أنفسهم لن تتحول إلى تلك المسطحة. سيقوم المحللون json بتحويل المدخلات إلى مجموعة من القوائم المتداخلة ، والتي تحتاج بعد ذلك يدويًا إلى نشرها لفترة طويلة ومؤلمة ؛
- الحرية في سمات بيانات المخرجات (قد لا يتم عرض تلك الغائبة) تؤدي إلى ظهور كائنات
NULL ذات صلة بالقوائم ، لكن لا يمكن " data.frame " في data.frame ، مما يعقد عملية المعالجة اللاحقة ويؤدي إلى تعقيد العملية الأساسية لدمج أوراق الصفوف الفردية في data.frame (لا يهم rbindlist أو rbind أو 'map_dfr' أو rbind ).
JQ - مخرج
في المواقف الصعبة بشكل خاص ، يؤدي استخدام طرق ملائمة جدًا لحزمة jsonlite "تحويل الكل إلى كائنات R" للأسباب المذكورة أعلاه إلى حدوث خلل خطير. حسنًا ، إذا تمكنت من الوصول إلى نهاية المعالجة. والأسوأ من ذلك ، إذا كان عليك نشر ذراعيك والاستسلام في المنتصف.
بديل لهذا النهج هو استخدام المعالج الأولي json ، والذي يعمل مباشرة على بيانات json. مكتبة jqr . تدل الممارسة على أنه لم يتم استخدامه كثيرًا فحسب ، ولكن القليل منهم سمعوا به مطلقًا ، ولكن دون جدوى.
فوائد مكتبة jq .
- يمكن استخدام المكتبة في R وفي Python وفي سطر الأوامر ؛
- يتم إجراء جميع التحويلات على مستوى json ، دون التحول إلى تمثيل لكائنات R / Python ؛
- يمكن تقسيم المعالجة إلى عمليات ذرية واستخدام مبدأ السلاسل (الأنابيب) ؛
- يتم إخفاء دورات معالجة متجهات الكائنات داخل المحلل اللغوي ، يتم تبسيط بناء الجملة التكرار ؛
- القدرة على تنفيذ جميع إجراءات توحيد بنية json ونشر العناصر الضرورية واختيارها من أجل إنشاء تنسيق json يتم تحويله بطريقة دفعية إلى
data.frame باستخدام jsonlite ؛ - التقليل من شفرة R المسؤولة عن معالجة بيانات json ؛
- سرعة المعالجة الضخمة ، اعتمادًا على حجم وتعقيد بنية البيانات ، يمكن أن يكون الربح 1-3 أوامر من حيث الحجم ؛
- أقل بكثير متطلبات ذاكرة الوصول العشوائي.
يتم ضغط رمز المعالجة لملاءمة الشاشة وقد يبدو مثل هذا:
cont <- httr::content(r3, as = "text", encoding = "UTF-8") m <- cont %>% # jqr::jq('del(.[].movie.rating, .[].movie.genres, .[].movie.trailers)') %>% jqr::jq('del(.[].movie.countries, .[].movie.images)') %>% # jqr::jq('del(.[].schedules[].hall, .[].schedules[].language, .[].schedules[].subtitle)') %>% # jqr::jq('del(.[].cinema.location, .[].cinema.photo, .[].cinema.phones)') %>% jqr::jq('del(.[].cinema.goodies, .[].cinema.subway_stations)') # m2 <- m %>% jqr::jq('[.[] | {date, movie, schedule: .schedules[], cinema}]') df <- fromJSON(m2) %>% as_tibble()
JQ أنيقة جدا وسريعة! إلى من يهمهم الأمر: تنزيل ، تعيين ، فهم. نحن نسرع المعالجة ، ونبسط الحياة لأنفسنا وزملائنا.
الوظيفة السابقة - "كيفية بدء تطبيق R في Enterprise. مثال على النهج العملي . "