
تم تطوير التقنيات والنماذج لنظام رؤية الكمبيوتر المستقبلية وتحسينها تدريجيًا في مشاريع مختلفة لشركتنا - في Mail و Cloud و Search. ينضج مثل الجبن الجيد أو كونياك. بمجرد أن أدركنا أن شبكاتنا العصبية أظهرت نتائج اعتراف ممتازة ، وقررنا إدخالها في منتج b2b واحد - الرؤية - الذي نستخدمه الآن ونعرض عليك استخدامه.
اليوم ، تعمل تقنية رؤية الكمبيوتر لدينا على منصة Mail.Ru Cloud Solutions بنجاح وتحل المشكلات العملية المعقدة للغاية. يعتمد على عدد من الشبكات العصبية التي يتم تدريبها على مجموعات البيانات الخاصة بنا والمتخصصة في حل المشكلات التطبيقية. جميع الخدمات تدور حول قدرات الخادم الخاصة بنا. يمكنك دمج واجهة برمجة تطبيقات Vision العامة في تطبيقاتك ، والتي من خلالها تتوفر جميع ميزات الخدمة. واجهة برمجة التطبيقات سريعة - بفضل وحدات معالجة الرسومات في الخادم ، يبلغ متوسط وقت الاستجابة داخل شبكتنا 100 مللي ثانية.
تعال إلى الأسفل ، هناك قصة مفصلة والعديد من الأمثلة على الرؤية.
كمثال على الخدمة التي نستخدم فيها أنفسنا تقنيات التعرف على الوجوه المذكورة أعلاه ، يمكننا الاستشهاد
بالأحداث . أحد مكوناته هو حوامل صور Vision ، التي نقوم بتثبيتها في مؤتمرات مختلفة. إذا صعدت إلى حامل الصور هذا ، والتقطت صورة بالكاميرا المدمجة وأدخلت بريدك ، فسوف يجد النظام على الفور بين مجموعة الصور التي التقطها المصورون العاديون للمؤتمرات ، وإذا رغبت في ذلك ، أرسل الصور التي عثر عليها إليك عبر البريد. ولا يتعلق الأمر بلقطات صورية على مراحل - تدرك Vision لك حتى في الخلفية وسط حشد من الزوار. بطبيعة الحال ، لا يتم التعرف عليها بواسطة الصورة التي تقف في حد ذاتها ، فهي فقط أقراص في سواحل جميلة تقوم ببساطة بتصوير الضيوف على كاميراتهم المدمجة ونقل المعلومات إلى الخوادم ، حيث يحدث كل سحر الاعتراف. وقد لاحظنا مرارًا وتكرارًا مدى مفاجأة فعالية التكنولوجيا حتى بين المتخصصين في التعرف على الصور. أدناه سنتحدث عن بعض الأمثلة.
1. لدينا نموذج التعرف على الوجه
1.1. الشبكة العصبية وسرعة المعالجة
للاعتراف ، نستخدم تعديلًا لنموذج الشبكة العصبية ResNet 101. يتم استبدال متوسط التجميع في النهاية بطبقة متصلة تمامًا ، على غرار الطريقة التي تم بها في ArcFace. ومع ذلك ، فإن حجم تمثيل المتجهات هو 128 ، وليس 512. تحتوي مجموعة التدريب الخاصة بنا على حوالي 10 ملايين صورة لـ 273،593 شخصًا.
يعمل النموذج بسرعة كبيرة بفضل بنية تكوين الخادم المحددة بعناية وحوسبة GPU. يستغرق الأمر 100 مللي ثانية للحصول على استجابة من واجهة برمجة التطبيقات (API) في شبكاتنا الداخلية - ويشمل ذلك اكتشاف الوجه (اكتشاف الوجه في الصورة) ، والتعرف على معرف الهوية وإعادته في استجابة واجهة برمجة التطبيقات. مع وجود كميات كبيرة من البيانات الواردة - الصور ومقاطع الفيديو - سوف يستغرق نقل البيانات إلى الخدمة وتلقي استجابة وقتًا أطول بكثير.
1.2. تقييم فعالية النموذج
لكن تحديد كفاءة الشبكات العصبية مهمة مختلطة للغاية. تعتمد جودة عملهم على مجموعات البيانات التي تم تدريب النماذج عليها وما إذا كانت قد تم تحسينها للعمل مع بيانات محددة.
بدأنا في تقييم دقة نموذجنا من خلال اختبار التحقق LFW الشهير ، لكنه صغير جدًا وبسيط. بعد الوصول إلى دقة 99.8 ٪ ، لم يعد مفيدا. هناك منافسة جيدة لتقييم نماذج الاعتراف - Megaface على ذلك ، فقد وصلنا تدريجياً إلى 82٪ من المرتبة 1. يتكون اختبار Megaface من مليون صورة - مُشتات - ويجب أن يكون النموذج قادرًا على التمييز جيدًا بين عدة آلاف من صور المشاهير من مجموعة بيانات Facescrub عن المشتتات. ومع ذلك ، بعد مسح اختبار Megaface للأخطاء ، اكتشفنا أنه في الإصدار الذي تم تنظيفه ، نحقق دقة تبلغ 98٪ في المرتبة 1 (صور المشاهير بوجه عام محددة جدًا). لذلك ، قاموا بإنشاء اختبار هوية منفصل ، على غرار Megaface ، ولكن مع صور لأشخاص "عاديين". مزيد من تحسين دقة الاعتراف على مجموعات البيانات الخاصة بهم ومضي قدما. بالإضافة إلى ذلك ، نستخدم اختبار جودة المجموعات ، والذي يتكون من عدة آلاف من الصور الفوتوغرافية ؛ إنه يحاكي ترميز الوجوه في سحابة المستخدم. في هذه الحالة ، المجموعات هي مجموعات من الأفراد المتشابهين ، وهي مجموعة لكل شخص يمكن التعرف عليه. فحصنا جودة العمل في مجموعات حقيقية (صواب).
بالطبع ، أي نموذج لديه أخطاء الاعتراف. ولكن غالبًا ما يتم حل هذه المواقف عن طريق صقل العتبات لظروف معينة (بالنسبة لجميع المؤتمرات التي نستخدمها نفس العتبات ، وعلى سبيل المثال ، بالنسبة إلى ACS ، يتعين علينا زيادة العتبات بشكل كبير بحيث يكون عدد الإيجابيات الخاطئة أقل). تم التعرف على الغالبية العظمى من الحاضرين في المؤتمر من خلال صور الرؤية الخاصة بنا. في بعض الأحيان نظر أحدهم إلى المعاينة التي تم اقتصاصها وقال: "كان نظامك خاطئًا ، لست أنا". ثم فتحنا الصورة بأكملها ، واتضح أن هذا الزائر كان موجودًا بالفعل في الصورة ، فقط لم يلتقطها ، لكن شخصًا آخر ، ظهر رجل بطريق الخطأ في الخلفية في منطقة التمويه. علاوة على ذلك ، فإن الشبكة العصبية غالبًا ما تتعرف بشكل صحيح حتى عندما لا يكون جزء من الوجه مرئيًا ، أو يكون الشخص في وضع جانبي ، أو حتى نصف الوجه. يمكن للنظام أن يتعرف على أي شخص ، حتى لو وقع الشخص في مجال التشويه البصري ، على سبيل المثال ، عند التصوير باستخدام عدسة واسعة الزاوية.
1.3. اختبار الأمثلة في المواقف الصعبة
فيما يلي أمثلة على تشغيل شبكتنا العصبية. عند المدخل ، يتم تقديم الصور ، والتي يجب أن تحددها باستخدام PersonID - معرف فريد للشخص. إذا كانت هناك صورتان أو أكثر لها نفس المعرف ، فطبقًا للطرازات ، تعرض هذه الصور شخصًا واحدًا.
على الفور ، نلاحظ أنه خلال الاختبار ، يمكننا الوصول إلى مختلف المعلمات وعتبات النماذج التي يمكننا تكوينها لتحقيق نتيجة معينة. تم تحسين واجهة برمجة التطبيقات العامة لتحقيق أقصى درجات الدقة في الحالات الشائعة.
لنبدأ بالأبسط ، مع التعرف على الوجوه في الوجه.

حسنًا ، كان ذلك سهلاً جدًا. نحن تعقيد المهمة ، إضافة لحية وحفنة من السنوات.

سيقول شخص ما إن هذا لم يكن أمرًا صعبًا للغاية ، لأنه في كلتا الحالتين يكون الوجه مرئيًا بالكامل ، تحتوي الخوارزمية على الكثير من المعلومات حول الوجه. حسنًا ، أدر توم هاردي في ملف التعريف. هذه المهمة أكثر تعقيدًا بكثير ، وقد بذلنا الكثير من الجهد في حلها الناجح من خلال الحفاظ على مستوى منخفض من الأخطاء: اخترنا مجموعة تدريب ، وفكرنا في بنية الشبكة العصبية ، وشحذنا وظائف الخسارة ، وحسننا المعالجة الأولية للصور.
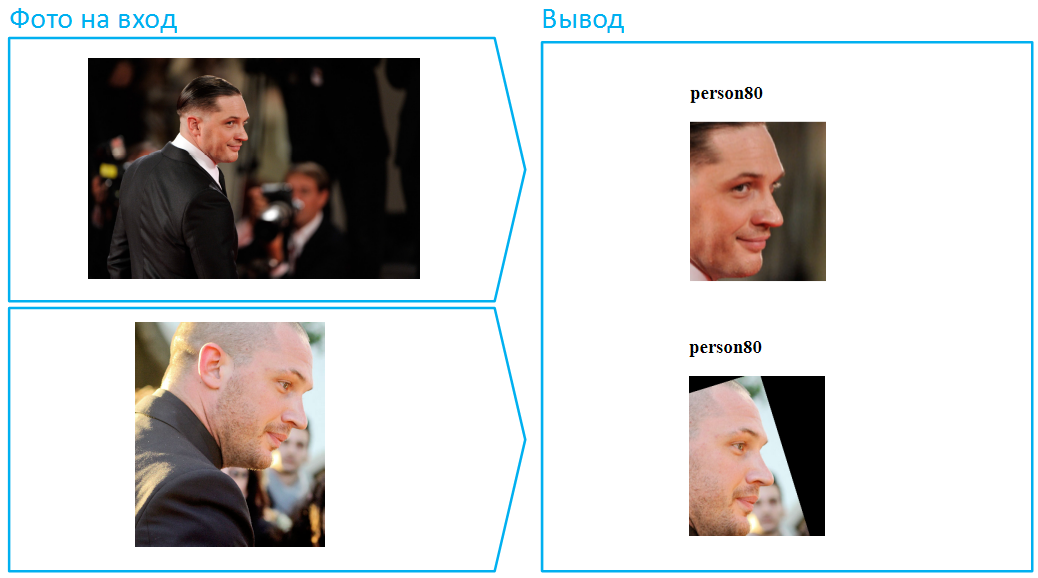
دعونا نضع قبعة عليه:

بالمناسبة ، هذا مثال على موقف صعب للغاية ، لأن الوجه مغطى للغاية هنا ، وفي الصورة السفلية هناك أيضًا ظل عميق يخفي العينين. في الحياة الواقعية ، غالبًا ما يغير الناس مظهرهم بمساعدة النظارات الداكنة. افعل نفس الشيء مع توم.

حسنًا ، دعنا نحاول تحميل الصور من مختلف الأعمار ، وهذه المرة سنقوم بتجربة ممثل آخر. لنأخذ مثالًا أكثر تعقيدًا عندما تكون التغييرات المرتبطة بالعمر واضحة بشكل خاص. الوضع ليس بعيد المنال ، بل يحدث دائمًا عندما تحتاج إلى مقارنة صورة في جواز سفرك مع وجه حاملها. بعد كل شيء ، فإن الصورة الأولى عالقة في جواز السفر عندما يبلغ المالك 20 عامًا ، ويمكن أن يتغير 45 شخصًا إلى حد كبير:

هل تعتقد أن الخاص الرئيسي في مهمة مستحيلة لم يتغير كثيرا مع تقدم العمر؟ أعتقد أنه حتى عدد قليل من الناس يجمعون بين الصور العلوية والسفلية ، فقد تغير الصبي كثيرًا على مر السنين.

تواجه الشبكات العصبية تغييرات في المظهر في كثير من الأحيان. على سبيل المثال ، في بعض الأحيان يمكن للمرأة تغيير صورتها بشكل كبير بمساعدة مستحضرات التجميل:

الآن دعنا نجعل المهمة أكثر تعقيدًا: دع أجزاء مختلفة من الوجه مغطاة بصور مختلفة. في مثل هذه الحالات ، لا يمكن للخوارزمية مقارنة العينات بأكملها. ومع ذلك ، الرؤية يعالج مثل هذه الحالات بشكل جيد.
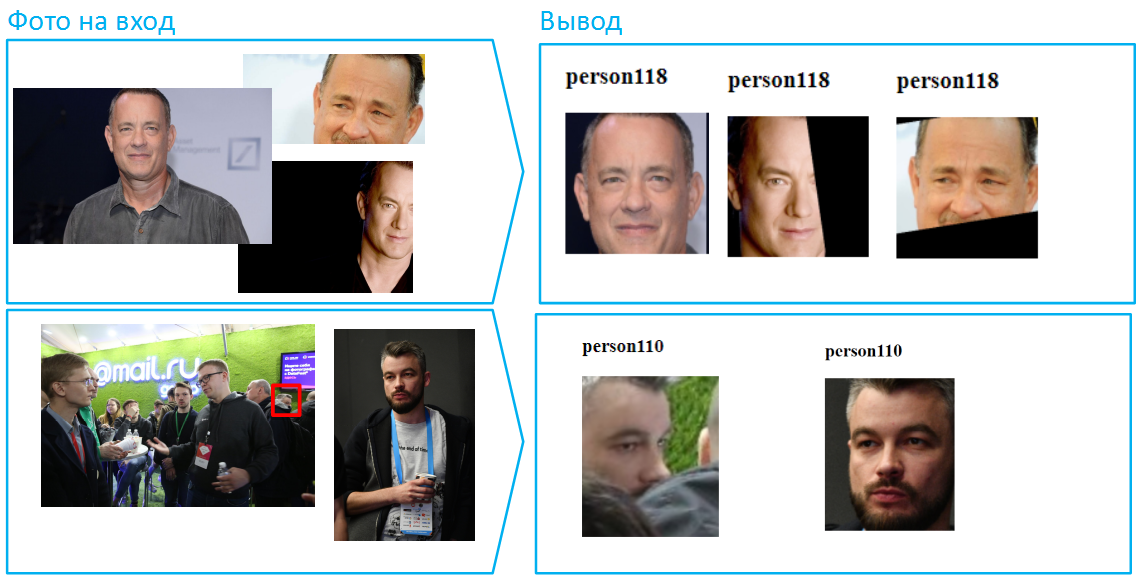
بالمناسبة ، هناك الكثير من الوجوه في الصور ، على سبيل المثال ، يمكن لأكثر من 100 شخص وضع صورة مشتركة للقاعة. هذا وضع صعب بالنسبة للشبكات العصبية ، حيث يمكن إضاءة العديد من الوجوه بشكل مختلف ، أي شخص خارج منطقة الحدة. ومع ذلك ، إذا تم التقاط الصورة بدقة وجودة كافية (على الأقل 75 بكسل لكل مربع تغطي الوجه) ، ستكون Vision قادرة على التعرف عليها والتعرف عليها.

إن خصوصية الإبلاغ عن الصور الفوتوغرافية والصور من كاميرات المراقبة هي أن الناس غالبًا ما يكونون ضبابيين لأنهم كانوا خارج مجال الحدة أو كانوا يتحركون في تلك اللحظة:

أيضا ، يمكن لشدة الإضاءة تختلف اختلافا كبيرا من صورة إلى أخرى. يتحول هذا أيضًا في كثير من الأحيان إلى حجر عثرة ، حيث تواجه العديد من الخوارزميات صعوبة كبيرة في معالجة الصور المظلمة والخفيفة جدًا بشكل صحيح ، ناهيك عن المقارنة الدقيقة. واسمحوا لي أن أذكرك بأنه من أجل تحقيق هذه النتيجة ، تحتاج إلى تعيين عتبات بطريقة معينة ، فإن هذا الاحتمال لم يصبح متاحًا للجمهور حتى الآن. بالنسبة لجميع العملاء ، نستخدم نفس الشبكة العصبية ، ولديها عتبات مناسبة لمعظم المهام العملية.

في الآونة الأخيرة ، طرحنا نسخة جديدة من النموذج الذي يتعرف على الوجوه الآسيوية بدقة عالية. في السابق ، كانت هذه مشكلة كبيرة ، والتي كانت تسمى حتى "تعلم آلة العنصرية" (أو "الشبكات العصبية"). أدركت الشبكات العصبية الأوروبية والأمريكية أن أورباويد يواجه بشكل جيد ، وكانت الأمور أسوأ بكثير مع المغولي والنيجروي. ربما في نفس الصين ، كان الوضع عكس ذلك تمامًا. الأمر كله يتعلق بمجموعات بيانات التدريب التي تعكس الأنواع السائدة من الأشخاص في بلد معين. ومع ذلك ، فإن الوضع يتغير ، واليوم هذه المشكلة أبعد ما تكون عن الحاد. الرؤية ليست لديها أي صعوبات مع ممثلي مختلف الأجناس.

التعرف على الوجوه هو مجرد واحد من العديد من تطبيقات تقنيتنا ، يمكن تعليم Vision التعرف على أي شيء. على سبيل المثال ، أرقام السيارات ، بما في ذلك في الظروف الصعبة للخوارزميات: في زوايا حادة ، أرقام قذرة ويصعب قراءتها.

2. حالات الاستخدام العملي
2.1. التحكم في الوصول المادي: عندما يذهب اثنان على نفس المسار
بمساعدة Vision ، من الممكن تطبيق أنظمة المحاسبة لوصول ومغادرة الموظفين. يحتوي النظام التقليدي القائم على التصاريح الإلكترونية على عيوب واضحة ، على سبيل المثال ، يمكنك تصفح شريطين معًا. إذا تم استكمال نظام التحكم في الوصول (ACS) بالرؤية ، فسوف يسجل بصراحة من جاء ومن ذهب.
2.2. تتبع الوقت
ترتبط حالة الاستخدام هذه الخاصة بـ Vision ارتباطًا وثيقًا بالحالة السابقة. إذا استكملنا نظام التحكم في الوصول مع خدمة التعرف على الوجوه الخاصة بنا ، فسيمكنك ليس فقط ملاحظة انتهاكات التحكم في الوصول ، ولكن أيضًا تسجيل الإقامة الفعلية للموظفين في المبنى أو في المنشأة. بمعنى آخر ، ستساعد Vision في التفكير بصدق في من جاء ومدى العمل الذي خلفه وغادر معه ، وحتى من تخطاه ، حتى لو قام زملاؤه بتغطيته أمام رؤسائه.
2.3. تحليلات الفيديو: تتبع الناس والأمن
من خلال تتبع الأشخاص الذين يستخدمون Vision ، يمكنك تقييم دقة المباح الفعلي لمناطق التسوق ومحطات القطار والمعابر والشوارع والعديد من الأماكن العامة الأخرى. يمكن أن يكون تتبعنا مفيدًا أيضًا في التحكم في الوصول ، على سبيل المثال ، إلى أحد المستودعات أو المباني المكتبية المهمة الأخرى. وبالطبع ، يساعد تتبع الأشخاص والوجوه في حل المشكلات الأمنية. القبض على شخص يسرق من متجرك؟ قم بإضافته إلى PersonID ، الذي قام بإرجاع Vision ، في القائمة السوداء لبرنامج تحليلات الفيديو ، وفي المرة التالية سيقوم النظام بتنبيه الأمان فور ظهور هذا النوع مرة أخرى.
2.4. في التجارة
تهتم شركات التجزئة والخدمات المتنوعة بالاعتراف بقائمة الانتظار. باستخدام Vision ، يمكنك أن تدرك أن هذا ليس حشدًا عشوائيًا من الناس ، ولكنه قائمة انتظار وتحديد طوله. ثم يقوم النظام بإبلاغ المسؤولين عن قائمة الانتظار لفهم الموقف: إما أنه يمثل تدفقًا للزائرين ويجب استدعاء عمال إضافيين ، أو يقوم شخص ما باختراق مسؤوليات عمله.
مهمة أخرى مثيرة للاهتمام هي فصل موظفي الشركة في القاعة عن الزوار. عادةً ، يتعلم النظام فصل الكائنات في ملابس معينة (رمز اللباس) أو مع ميزة مميزة (وشاح التوقيع ، شارة على الصدر ، وما إلى ذلك). يساعد ذلك في تقييم الحضور بشكل أكثر دقة (بحيث لا "يختتم" الموظفون وحدهم إحصاءات الأشخاص الموجودين في القاعة).
باستخدام التعرف على الوجوه ، يمكنك تقييم جمهورك: ما هو ولاء الزوار ، أي عدد الأشخاص الذين يعودون إلى مؤسستك وبأي تردد. احسب عدد الزوار الفريدين الذين يأتون إليك في غضون شهر. لتحسين تكاليف الجذب والاستبقاء ، يمكنك معرفة وتغيير الحضور حسب يوم الأسبوع وحتى وقت اليوم.
يمكن لأصحاب الامتياز وشركات الشبكة أن يطلبوا تقييم جودة العلامات التجارية لمختلف منافذ البيع بالتجزئة من الصور الفوتوغرافية: وجود الشعارات والعلامات والملصقات واللافتات وغيرها.
2.5. في النقل
مثال آخر على الأمن من خلال تحليلات الفيديو هو تحديد العناصر المتبقية في قاعات المطار أو محطة القطار. يمكن تدريب Vision على التعرف على كائنات مئات الفئات: الأثاث والحقائب وحقائب السفر والمظلات وأنواع مختلفة من الملابس والزجاجات وما إلى ذلك. إذا اكتشف نظام تحليلات الفيديو الخاص بك كائنًا بدون مالك وتعرّف عليه باستخدام Vision ، فإنه يرسل إشارة إلى خدمة الأمان. تتعلق مهمة مماثلة بالاكتشاف التلقائي للمواقف غير القياسية في الأماكن العامة: مرض شخص ، أو شخص مدخن في المكان الخطأ ، أو سقط الشخص على القضبان ، وما إلى ذلك - كل هذه الأنماط من نظام تحليلات الفيديو يمكن التعرف عليها من خلال API Vision.
2.6. تدفق الوثائق
تطبيق آخر مثير للاهتمام مستقبلاً من الرؤية التي نقوم بتطويرها حاليًا هو التعرف على الوثائق وتحليلها التلقائي في قواعد البيانات. بدلاً من القيادة يدويًا (أو الأسوأ من ذلك ، الكتابة) في سلسلة لا نهائية من الأرقام والأرقام وتواريخ الإصدار وأرقام الحسابات والتفاصيل المصرفية والتواريخ وأماكن الميلاد والعديد من البيانات الرسمية الأخرى ، يمكنك مسح المستندات وإرسالها تلقائيًا عبر قناة آمنة من خلال واجهة برمجة التطبيقات في السحابة ، حيث سيكون النظام سريعًا ، سيتم التعرف على هذه المستندات وتحليلها وإرجاعها استجابة للبيانات بالتنسيق المطلوب للدخول التلقائي إلى قاعدة البيانات. تعرف Vision اليوم بالفعل كيفية تصنيف المستندات (بما في ذلك في PDF) - فهي تميز جوازات السفر ، SNILS ، TIN ، شهادات الميلاد ، شهادات الزواج وغيرها.
بالطبع ، كل هذه الحالات لا تستطيع الشبكة العصبية التعامل معها. في كل حالة ، يتم تصميم نموذج جديد لعميل معين ، وتؤخذ في الاعتبار العديد من العوامل والفروق الدقيقة والمتطلبات ، ويتم اختيار مجموعات البيانات ، ويتم تكرار إعدادات التدريب.
3. خطة عمل API
"بوابة مدخل" Vision للمستخدمين هي REST API. عند المدخل ، يمكنه التقاط الصور وملفات الفيديو والبث من كاميرات الشبكة (تدفقات RTSP).
لاستخدام Vision ، تحتاج إلى
التسجيل في Mail.ru Cloud Solutions والوصول إلى الرموز المميزة (client_id + client_secret). يتم إجراء مصادقة المستخدم باستخدام بروتوكول OAuth. يتم إرسال البيانات المصدر في نصوص طلبات POST إلى API. واستجابة لذلك ، يتلقى العميل نتيجة الاعتراف من API بتنسيق JSON ، ويتم تنظيم الاستجابة: أنه يحتوي على معلومات حول الكائنات الموجودة وإحداثياتها.

مثال الاستجابة{ "status":200, "body":{ "objects":[ { "status":0, "name":"file_0" }, { "status":0, "name":"file_2", "persons":[ { "tag":"person9" "coord":[149,60,234,181], "confidence":0.9999, "awesomeness":0.45 }, { "tag":"person10" "coord":[159,70,224,171], "confidence":0.9998, "awesomeness":0.32 } ] } { "status":0, "name":"file_3", "persons":[ { "tag":"person11", "coord":[157,60,232,111], "aliases":["person12", "person13"] "confidence":0.9998, "awesomeness":0.32 } ] }, { "status":0, "name":"file_4", "persons":[ { "tag":"undefined" "coord":[147,50,222,121], "confidence":0.9997, "awesomeness":0.26 } ] } ], "aliases_changed":false }, "htmlencoded":false, "last_modified":0 }
الجواب لديه الذهول مثيرة للاهتمام المعلمة - وهذا هو "البرودة" الشرطية للوجه في الصورة ، حيث نختار أفضل لقطة وجه من التسلسل. قمنا بتدريب الشبكة العصبية للتنبؤ باحتمالية أن تكون الصورة على الشبكات الاجتماعية. كلما كانت الصورة أفضل وأكثر سلاسة للوجه ، زادت الذهول.
يستخدم Vision API مفهومًا مثل المساحة. هذه أداة لإنشاء مجموعات مختلفة من الوجوه. أمثلة على المساحات هي القوائم السوداء والبيضاء ، وقوائم الزوار والموظفين والعملاء ، إلخ. لكل رمز مميز في Vision ، يمكنك إنشاء ما يصل إلى 10 مسافات ، في كل مساحة يمكن أن يوجد ما يصل إلى 50 ألف PersonID ، أي ما يصل إلى 500 ألف لرمز واحد . علاوة على ذلك ، فإن عدد الرموز المميزة لكل حساب غير محدود.
اليوم ، تدعم واجهة برمجة التطبيقات (API) طرق الكشف والتعرف التالية:
- التعرف على / تعيين - تعريف والاعتراف الوجوه. يعيّن معرفًا شخصيًا تلقائيًا لكل وجه فريد ، ويعيد هوية الشخص وينسق الوجوه الموجودة.
- حذف - حذف معرف شخص معين من قاعدة بيانات الشخص.
- اقتطاع - مسح المساحة بأكملها من PersonID ، مفيد إذا تم استخدامه كاختبار وتحتاج إلى إعادة تعيين الأساس للإنتاج.
- الكشف - تعريف الكائنات ، المشاهد ، لوحات الترخيص ، المعالم السياحية ، قوائم الانتظار ، إلخ. إرجاع فئة الكائنات التي تم العثور عليها وإحداثياتها
- الكشف عن المستندات - يكتشف أنواعًا معينة من مستندات الاتحاد الروسي (يميز جواز السفر ، snls ، نزل ، إلخ).
أيضًا ، سننتهي قريبًا من العمل على أساليب التعرف الضوئي على الحروف (OCR) ، وتحديد الجنس والعمر والعواطف ، وكذلك حل مهام الترويج ، أي التحكم في عرض البضائع في المتاجر تلقائيًا. يمكنك العثور على وثائق API الكاملة هنا:
https://mcs.mail.ru/help/vision-api4. الخلاصة
الآن من خلال واجهة برمجة التطبيقات (API) العامة ، يمكنك الوصول إلى التعرف على الوجوه في الصور ومقاطع الفيديو ، وهو يدعم تعريف الكائنات المختلفة ، ولوحات الترخيص ، ومناطق الجذب ، والمستندات ، ومشاهد كاملة. سيناريوهات التطبيق - البحر. تعال ، اختبر خدمتنا ، اضبط المهام الأكثر صعوبة لذلك. أول 5000 معاملة مجانية. قد يكون "العنصر المفقود" لمشاريعك.
يمكن الحصول على الوصول إلى واجهة برمجة التطبيقات على الفور عند التسجيل والاتصال بـ
Vision . جميع مستخدمي Habra - رمز ترويجي للمعاملات الإضافية. اكتب عنوان بريد إلكتروني شخصي تم تسجيل الحساب عليه!