مرحبا اسمي Ibadov Ilkin ، أنا طالب في جامعة Ural Federal.
في هذه المقالة ، أود أن أتحدث عن تجربتي مع الحل التلقائي لبرنامج Google captcha - "reCAPTCHA". أود أن أحذر القارئ مقدمًا من أنه في وقت كتابة هذا المقال ، لا يعمل النموذج الأولي بكفاءة كما قد يبدو من العنوان ، ومع ذلك ، توضح النتيجة أن النهج الذي يتم تنفيذه قادر على حل المشكلة.
من المحتمل أن يكون كل شخص في حياته مرتبطًا بكلمة captcha: إدخال نص من صورة ، أو حل تعبير بسيط أو معادلة معقدة ، واختيار السيارات ، وصنابير الإطفاء ، ومعابر المشاة ... تعد حماية الموارد من الأنظمة الآلية أمرًا ضروريًا وتلعب دورًا مهمًا في الأمان: حماية captcha من هجمات DDoS ، والتسجيل التلقائي والمنشورات ، والتحليل ، ويمنع البريد المزعج واختيار كلمة المرور للحسابات.
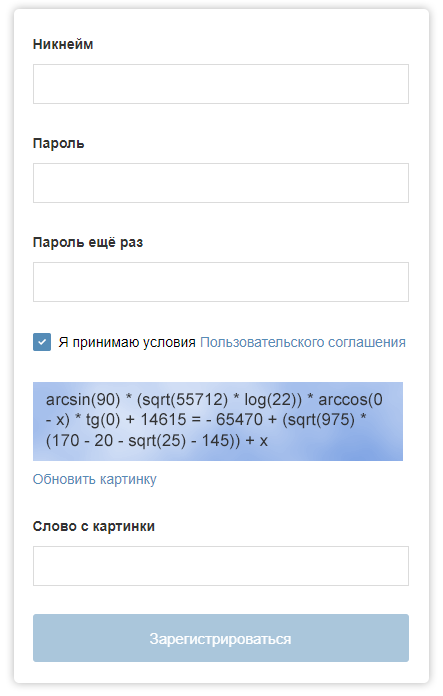 يمكن أن يكون نموذج التسجيل على "Habré" مع هذا الاختبار.
يمكن أن يكون نموذج التسجيل على "Habré" مع هذا الاختبار.مع تطور تقنيات التعلم الآلي ، قد يكون أداء اختبار captcha في خطر. في هذه المقالة ، أصف النقاط الرئيسية لبرنامج يمكنه حل مشكلة تحديد الصور يدويًا في Google reCAPTCHA (لحسن الحظ ، ليس دائمًا حتى الآن).
للتغلب على captcha ، من الضروري حل مشكلات مثل: تحديد فئة captcha المطلوبة ، وكشف وتصنيف الكائنات ، والكشف عن خلايا captcha ، وتقليد الأنشطة البشرية في حل captcha (حركة المؤشر ، والنقر فوق).
للبحث عن كائنات في صورة ما ، يتم استخدام الشبكات العصبية المدربة التي يمكن تنزيلها على جهاز كمبيوتر والتعرف على الكائنات في الصور أو مقاطع الفيديو. ولكن لحل اختبار captcha ، لا يكفي مجرد اكتشاف الكائنات: تحتاج إلى تحديد موضع الخلايا ومعرفة الخلايا التي تريد تحديدها (أو عدم تحديد الخلايا على الإطلاق). لهذا ، يتم استخدام أدوات رؤية الكمبيوتر: في هذا العمل ، هذه هي
مكتبة OpenCV الشهيرة.
من أجل العثور على كائنات في الصورة ، أولاً ، الصورة نفسها مطلوبة. أحصل على لقطة لجزء من الشاشة باستخدام وحدة
PyAutoGUI ذات أبعاد كافية لاكتشاف الكائنات. في بقية الشاشة ، أقوم بعرض إطارات لعمليات تصحيح الأخطاء ومراقبتها.
كشف الكائن
اكتشاف وتصنيف الأشياء هو ما تفعله الشبكة العصبية. تسمى المكتبة التي تسمح لنا بالعمل مع الشبكات العصبية "
Tensorflow " (تم تطويره بواسطة Google). اليوم ،
هناك العديد من النماذج المدربة المختلفة لاختيارك
على بيانات مختلفة ، مما يعني أنه يمكن لكل منهم إرجاع نتيجة اكتشاف مختلفة: بعض النماذج ستكتشف الكائنات بشكل أفضل ، والبعض الآخر أسوأ.
في هذا البحث ، أستخدم نموذج ssd_mobilenet_v1_coco. تم تدريب النموذج المختار على مجموعة بيانات
COCO ، التي تسلط الضوء على 90 فصلًا مختلفًا (من الأشخاص والسيارات إلى فرشاة الأسنان وأمشاط). الآن هناك نماذج أخرى يتم تدريبها على نفس البيانات ، ولكن مع معايير مختلفة. بالإضافة إلى ذلك ، يحتوي هذا الطراز على معلمات الأداء والدقة المثلى ، وهو أمر مهم لجهاز كمبيوتر سطح المكتب. يقول المصدر أن وقت المعالجة لإطار واحد من 300 × 300 بكسل هو 30 مللي ثانية. على "نفيديا غيفورسي GTX TITAN X".
نتيجة الشبكة العصبية هي مجموعة من المصفوفات:
- مع قائمة فئات الكائنات المكتشفة (معرفاتها) ؛
- مع قائمة تصنيفات الكائنات المكتشفة (في المئة) ؛
- مع قائمة إحداثيات الكائنات المكتشفة ("الصناديق").
تتوافق مؤشرات العناصر في هذه المصفوفات مع بعضها البعض ، أي: العنصر الثالث في صفيف فئات الكائن يناظر العنصر الثالث في صفيف "مربعات" الكائنات المكتشفة والعنصر الثالث في صفيف تصنيفات الكائن.
 يتيح لك النموذج المحدد اكتشاف الكائنات من 90 فئة في الوقت الفعلي.
يتيح لك النموذج المحدد اكتشاف الكائنات من 90 فئة في الوقت الفعلي.الكشف عن الخلايا
يوفر لنا "OpenCV" القدرة على العمل مع كيانات تسمى "
الدوائر ": يمكن اكتشافها فقط من خلال وظيفة "findContours ()" من مكتبة "OpenCV". من الضروري إرسال صورة ثنائية إلى إدخال مثل هذه الوظيفة ، والتي يمكن الحصول عليها من
خلال وظيفة تحويل العتبة :
_retval, binImage = cv2.threshold(image,254,255,cv2.THRESH_BINARY) contours = cv2.findContours(binImage, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)[0]
بعد تعيين القيم القصوى لمعلمات وظيفة تحويل العتبة ، نتخلص أيضًا من أنواع مختلفة من الضوضاء. أيضًا ، لتقليل مقدار العناصر الصغيرة والضوضاء غير الضرورية ، يمكن تطبيق
التحولات المورفولوجية : تآكل (ضغط) ووظائف تراكم (توسيع). هذه الوظائف هي أيضًا جزء من OpenCV. بعد التحويلات ، يتم تحديد الأكفة التي يكون عدد القمم فيها أربعة (بعد إجراء دالة
التقريب مسبقًا على الأكفة).
 في النافذة الأولى ، نتيجة التحول العتبة. والثاني مثال على التحول المورفولوجي. في الإطار الثالث ، تم بالفعل تحديد الخلايا وكابتشا: تمييز في اللون برمجياً.
في النافذة الأولى ، نتيجة التحول العتبة. والثاني مثال على التحول المورفولوجي. في الإطار الثالث ، تم بالفعل تحديد الخلايا وكابتشا: تمييز في اللون برمجياً.بعد كل التحولات ، لا تزال المخططات التي ليست خلايا تقع في الصفيف النهائي مع الخلايا. من أجل تصفية الضوضاء غير الضرورية ، أختار وفقًا لقيم الطول (المحيط) ومنطقة الخطوط الكنتورية.
تم الكشف تجريبياً أن قيم دوائر الاهتمام تكمن في النطاق من 360 إلى 900 وحدة. يتم تحديد هذه القيمة على الشاشة بقطر 15.6 بوصة ودقة 1366 × 768 بكسل. علاوة على ذلك ، يمكن حساب القيم الموضحة للكفافيات بناءً على حجم شاشة المستخدم ، ولكن لا يوجد مثل هذا الرابط في النموذج الأولي الجاري إنشاؤه.
تتمثل الميزة الرئيسية للنهج الذي تم اختياره في اكتشاف الخلايا في أننا لا نهتم بالشكل الذي ستبدو عليه الشبكة وعدد الخلايا التي سيتم عرضها على صفحة captcha: 8 أو 9 أو 16.
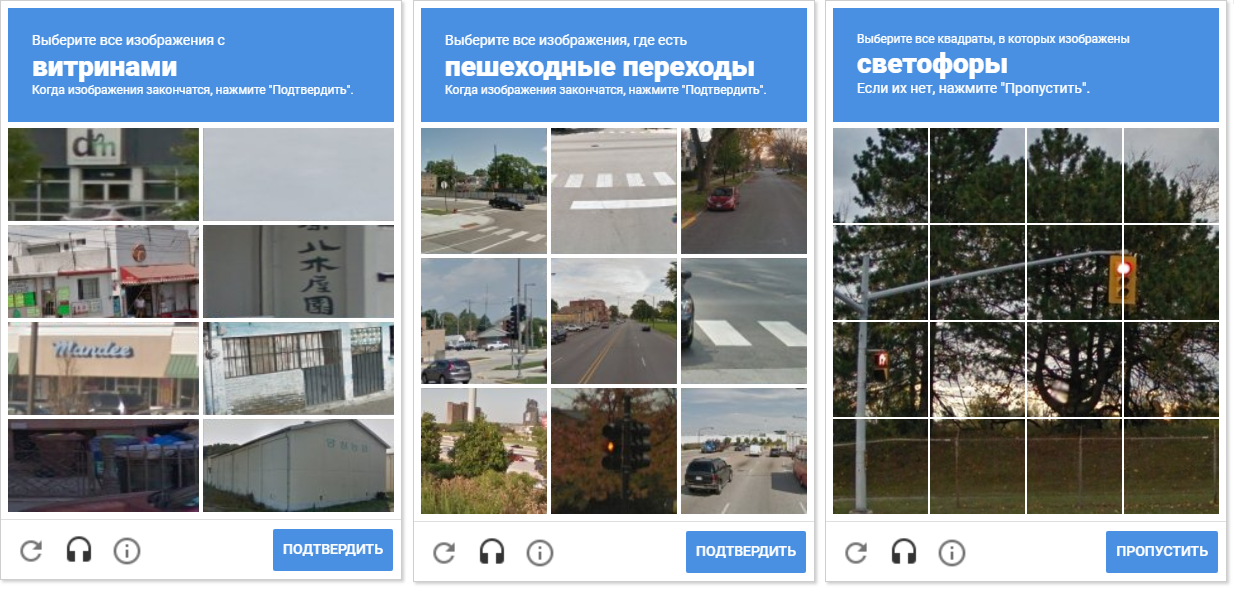 تظهر الصورة مجموعة متنوعة من شبكات captcha. يرجى ملاحظة أن المسافة بين الخلايا مختلفة. لفصل الخلايا عن بعضها البعض يسمح ضغط المورفولوجية.
تظهر الصورة مجموعة متنوعة من شبكات captcha. يرجى ملاحظة أن المسافة بين الخلايا مختلفة. لفصل الخلايا عن بعضها البعض يسمح ضغط المورفولوجية.ميزة إضافية لاكتشاف المعالم هي أن OpenCV يسمح لنا باكتشاف مراكزها (نحتاج إليها لتحديد إحداثيات الحركة وفوق الماوس).
اختيار الخلايا لتحديد
وجود صفيف مع ملامح نظيفة لخلايا CAPTCHA بدون دوائر ضوضاء غير ضرورية ، يمكننا التنقل بين كل خلية من خلايا CAPTCHA ("الدائرة" في المصطلحات "OpenCV") والتحقق مما إذا كانت تتقاطع مع "المربع" المكتشف من الكائن المستلم من الشبكة العصبية.
لإثبات هذه الحقيقة ، تم استخدام نقل "المربع" المكتشف إلى دائرة مشابهة للخلايا. لكن تبين أن هذا النهج خاطئ ، لأن الحالة التي يكون فيها الكائن داخل الخلية لا تعتبر تقاطعًا. بطبيعة الحال ، لم تبرز هذه الخلايا في كلمة التحقق.
تم حل المشكلة عن طريق إعادة رسم الخطوط العريضة لكل خلية (مع تعبئة بيضاء) على ورقة سوداء. بطريقة مماثلة ، تم الحصول على صورة ثنائية لإطار مع كائن. السؤال الذي يطرح نفسه - كيف الآن لإثبات حقيقة تقاطع الخلية مع الإطار المظلل للكائن؟ في كل تكرار لصفيف مع خلايا ، يتم تنفيذ عملية فصل (منطقية أو) على صورتين ثنائيتين. نتيجة لذلك ، نحصل على صورة ثنائية جديدة يتم فيها تمييز المناطق المتقاطعة. وهذا هو ، إذا كان هناك مثل هذه المناطق ، ثم تتقاطع الخلية وإطار الكائن. بشكل برمجي ، يمكن إجراء هذا الفحص باستخدام طريقة "
.any () ": سيعود "صواب" إذا كان للصفيف عنصر واحد على الأقل يساوي عنصرًا أو "خطأ" في حالة عدم وجود وحدات.
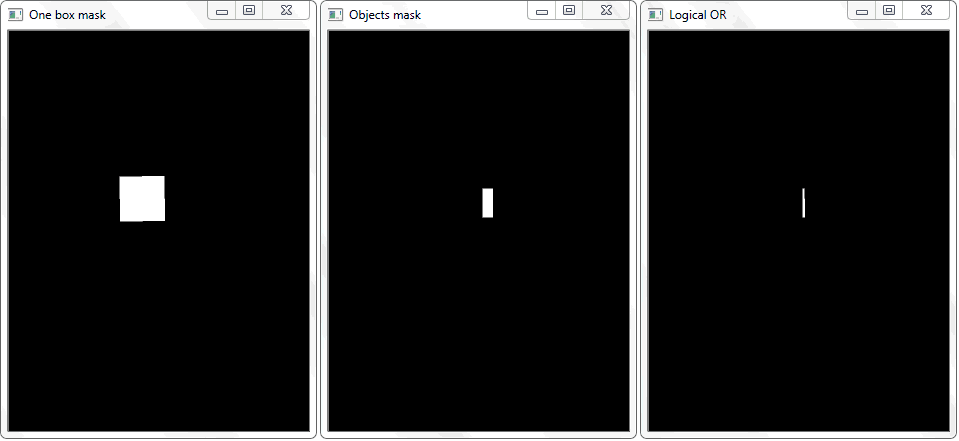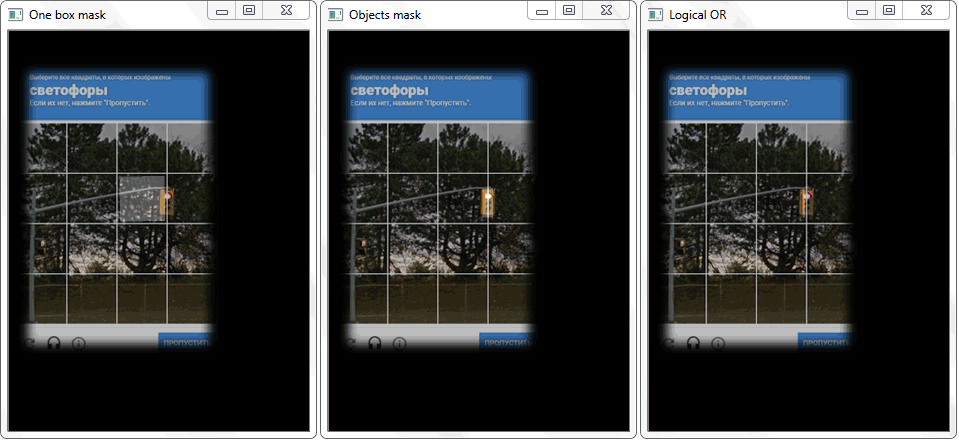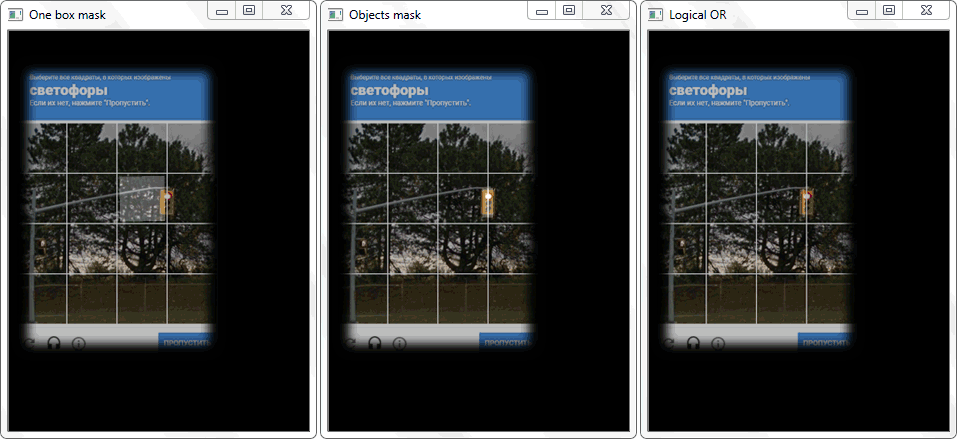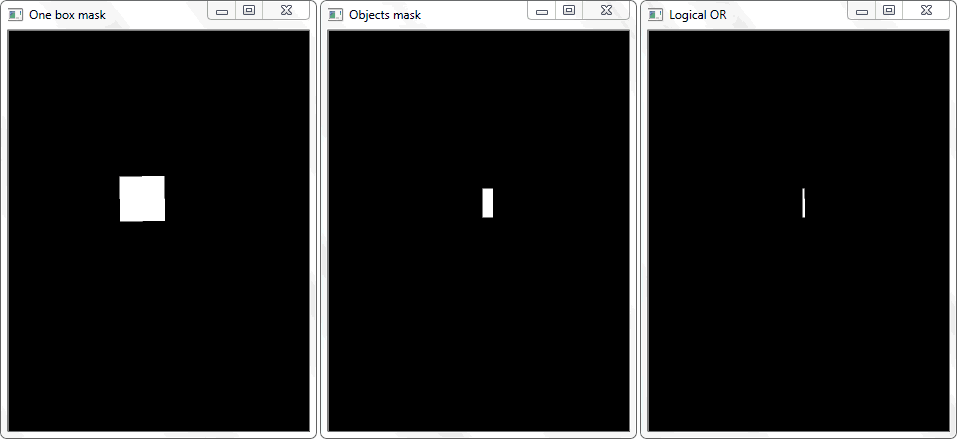 ستعود الدالة "any ()" للصورة "Logical OR" في هذه الحالة إلى حقيقة ، وبذلك ستثبت حقيقة تقاطع الخلية مع منطقة الإطار للكائن المكتشف.
ستعود الدالة "any ()" للصورة "Logical OR" في هذه الحالة إلى حقيقة ، وبذلك ستثبت حقيقة تقاطع الخلية مع منطقة الإطار للكائن المكتشف.إدارة
يتم توفير التحكم في المؤشر في "Python" بفضل الوحدة النمطية "win32api" (ومع ذلك ، اتضح فيما بعد أن "PyAutoGUI" المستوردة بالفعل في المشروع تعرف أيضًا كيفية القيام بذلك). يتم تنفيذ الضغط على زر الماوس الأيسر وتحريره ، وكذلك نقل المؤشر إلى الإحداثيات المطلوبة ، عن طريق الوظائف المقابلة لوحدة win32api. ولكن في النموذج الأولي ، كانت ملفوفة في وظائف المعرفة من قبل المستخدم من أجل توفير المراقبة البصرية لحركة المؤشر. هذا يؤثر سلبا على الأداء وتم تنفيذه فقط للتظاهر.
أثناء عملية التطوير ، نشأت فكرة اختيار الخلايا بترتيب عشوائي. من المحتمل أن لا يكون هذا منطقيًا (لأسباب واضحة ، فإن Google لا تقدم لنا تعليقات وأوصاف لآليات عملية captcha) ، ولكن تحريك المؤشر عبر الخلايا بطريقة فوضوية يبدو أكثر متعة.
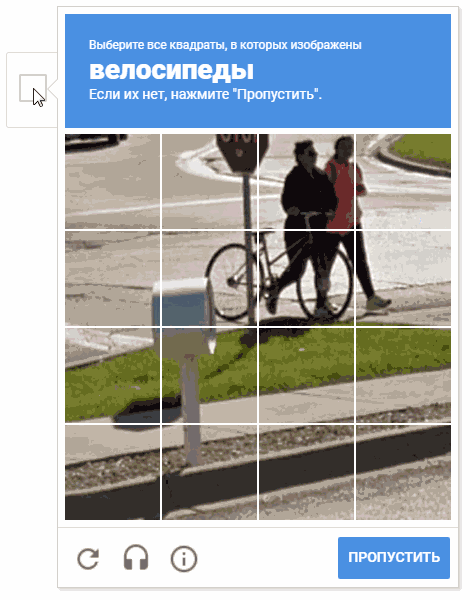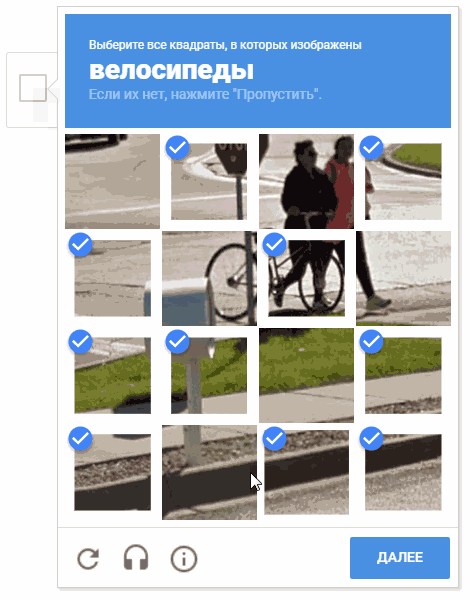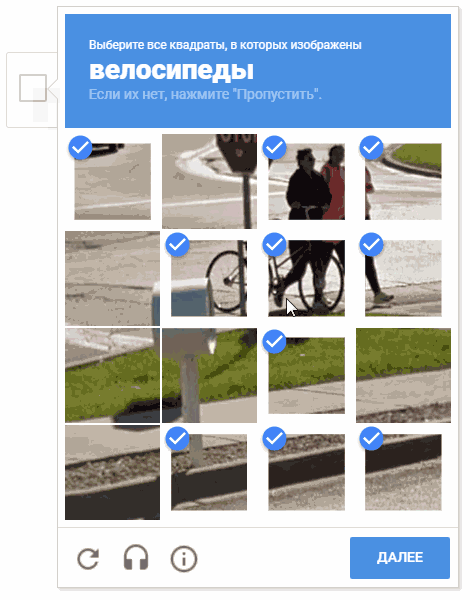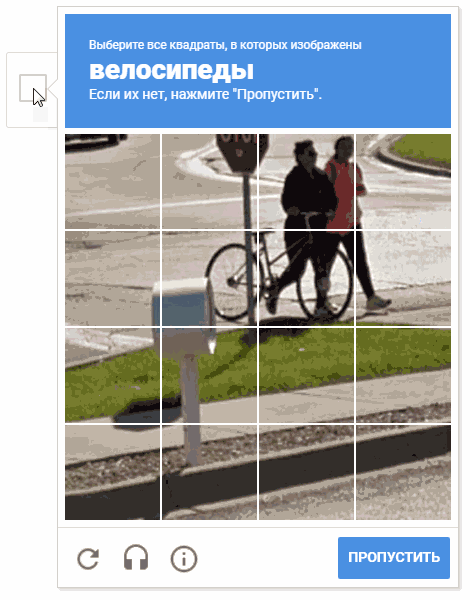 على الرسوم المتحركة ، والنتيجة هي "random.shuffle (boxesForSelect)".
على الرسوم المتحركة ، والنتيجة هي "random.shuffle (boxesForSelect)".التعرف على النص
من أجل الجمع بين جميع التطورات المتاحة في كلية واحدة ، هناك حاجة إلى رابط واحد آخر: وحدة الاعتراف للفئة المطلوبة من كلمة التحقق. نحن نعرف بالفعل كيفية التعرف على الكائنات المختلفة في الصورة وتمييزها ، ويمكننا النقر فوق خلايا captcha التعسفية ، لكننا لا نعرف الخلايا التي يجب النقر عليها. إحدى الطرق لحل هذه المشكلة هي التعرف على النص من عنوان captcha. أولاً وقبل كل شيء ، حاولت تطبيق التعرف على النص باستخدام أداة التعرف الضوئي على الأحرف "
Tesseract-OCR ".
في أحدث الإصدارات ، يمكن تثبيت حزم اللغات مباشرة في نافذة برنامج التثبيت (تم القيام بذلك يدويًا في السابق). بعد تثبيت Tesseract-OCR واستيراده في مشروعي ، حاولت التعرف على النص من عنوان captcha.
النتيجة ، لسوء الحظ ، لم تعجبني على الإطلاق. قررت أن النص الموجود في الرأس تم تسليط الضوء عليه بالخط العريض والمندمج لسبب ما ، لذلك حاولت تطبيق تحويلات متنوعة على الصورة: الترميز الثنائي ، الضيق ، التوسع ، التشويش ، التشويه وتغيير حجم العمليات. لسوء الحظ ، لم يعط ذلك نتيجة جيدة: في أفضل الحالات ، تم تحديد جزء فقط من الحروف الصفية ، وعندما كانت النتيجة مرضية ، قمت بتطبيق نفس التحولات ، ولكن بالنسبة إلى الأحرف الاستهلالية الأخرى (بنص مختلف) ، وكانت النتيجة سيئة مرة أخرى.
 عادة ما يؤدي التعرف على قبعات Tesseract-OCR إلى نتائج غير مرضية.
عادة ما يؤدي التعرف على قبعات Tesseract-OCR إلى نتائج غير مرضية.من المستحيل أن نقول بشكل لا لبس فيه أن "Tesseract-OCR" لا يتعرف على النص جيدًا ، وهذا ليس صحيحًا: تتعامل الأداة مع صور أخرى (وليس أحرف استهلالية) بشكل أفضل.
قررت استخدام خدمة تابعة لجهة خارجية توفر واجهة برمجة تطبيقات للعمل معها مجانًا (يلزم تسجيل واستلام مفتاح لعنوان البريد الإلكتروني). تحتوي الخدمة على 500 تمييز يوميًا ، لكن لم أواجه أية مشكلات تتعلق بالقيود طوال فترة التطوير بأكملها. على العكس من ذلك: لقد قدمت الصورة الأصلية للرأس إلى الخدمة (دون تطبيق أي تحويلات على الإطلاق) وكانت النتيجة مثيرة للإعجاب.
تم إرجاع الكلمات من الخدمة عمليا دون أخطاء (عادة حتى تلك المكتوبة بخط صغير). علاوة على ذلك ، فقد عادوا بتنسيق مناسب جدًا - مفصولًا بسطر مع أحرف كسر السطر. في كل الصور ، كنت مهتمًا فقط بالخط الثاني ، لذلك قمت بالوصول إليه مباشرةً. لا يسعني ذلك إلا أن أفرح ، لأن هذا التنسيق حررني من الحاجة إلى إعداد سطر: لم أكن مضطرًا إلى قطع بداية النص بالكامل أو نهايته ، والقيام بـ "الديكورات" ، والاستبدال ، والعمل باستخدام تعبيرات منتظمة ، وتنفيذ عمليات أخرى على الخط ، بهدف تسليط الضوء على كلمة واحدة (وأحيانا اثنين!) - مكافأة لطيفة!
text = serviceResponse['ParsedResults'][0]['ParsedText']
الخدمة التي تم التعرف على النص لم ترتكب أي خطأ في اسم الفئة ، لكنني ما زلت قررت ترك جزء من اسم الفصل لخطأ محتمل. هذا اختياري ، لكنني لاحظت أن "Tesseract-OCR" في بعض الحالات يتعرف بشكل غير صحيح على نهاية الكلمة التي تبدأ من المنتصف. بالإضافة إلى ذلك ، هذا النهج يلغي خطأ التطبيق في حالة اسم فئة طويلة أو اسم من كلمتين (في هذه الحالة ، ستعود الخدمة ليس 3 ، ولكن 4 خطوط ، وأنا لا يمكن العثور على الاسم الكامل للفئة في السطر الثاني).
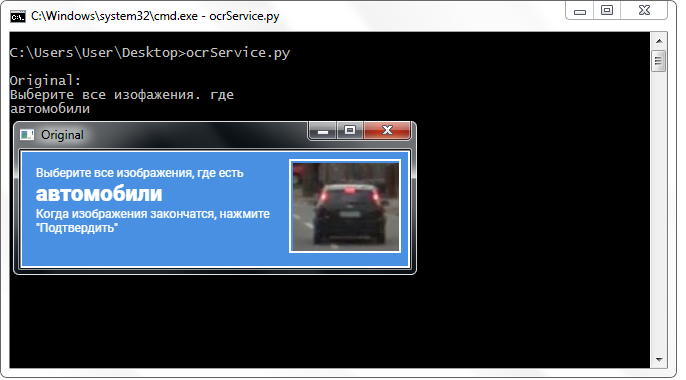 تتعرف خدمة الجهة الخارجية على اسم الفئة جيدًا دون أي تحويلات على الصورة.
تتعرف خدمة الجهة الخارجية على اسم الفئة جيدًا دون أي تحويلات على الصورة.التطورات دمج
الحصول على نص من الرأس لا يكفي. يجب مقارنتها مع معرّفات فئات النماذج المتاحة ، لأن الشبكة العصبية في مصفوفة الفصل تُرجع معرف الفئة تمامًا وليس اسمها ، كما قد يبدو. عند تدريب النموذج ، كقاعدة عامة ، يتم إنشاء ملف يتم فيه مقارنة أسماء الفصول ومعرفاتها (تُعرف أيضًا باسم "خريطة التسمية"). قررت القيام بذلك بشكل أسهل وتحديد معرفات الفصل يدويًا ، حيث لا يزال captcha يتطلب دروسًا باللغة الروسية (بالمناسبة ، يمكن تغيير ذلك):
if "" in query:
كل ما هو موضح أعلاه مستنسخ في الدورة الرئيسية للبرنامج: إطارات الكائن ، الخلية ، التقاطعات الخاصة بها محددة ، يتحرك المؤشر والنقرات. عند اكتشاف رأس ، يتم تنفيذ التعرف على النص. إذا لم تستطع الشبكة العصبية اكتشاف الفئة المطلوبة ، فسيتم إجراء تحول تعسفي للصورة يصل إلى 5 مرات (أي ، يتم تغيير الإدخال إلى الشبكة العصبية) ، وإذا كان الكشف لا يزال لا يحدث ، فسيتم النقر فوق الزر "تخطي / تأكيد" (يتم اكتشاف موضعه بشكل مشابه) كشف الخلايا والقبعات).
إذا كنت في كثير من الأحيان تحل اختبار captcha ، فيمكنك ملاحظة الصورة عندما تختفي الخلية المحددة ، وتظهر خلية جديدة ببطء وببطء في مكانها. نظرًا لأن النموذج الأولي مبرمج للانتقال على الفور إلى الصفحة التالية بعد تحديد جميع الخلايا ، فقد قررت أن أتوقف مؤقتًا لمدة 3 ثوانٍ لاستبعاد النقر على زر "التالي" دون اكتشاف الكائنات الموجودة في الخلية التي تظهر ببطء.
لن تكتمل المقالة إذا لم تتضمن وصفًا لأهم شيء - علامة اختيار اجتياز اختبار captcha بنجاح. قررت أن
مقارنة قالب بسيط يمكن أن تفعل هذا. تجدر الإشارة إلى أن مطابقة الأنماط أبعد ما تكون عن أفضل طريقة لاكتشاف الكائنات. على سبيل المثال ، اضطررت إلى ضبط حساسية الكشف على "0.01" بحيث تتوقف الوظيفة عن رؤية علامات التجزئة في كل شيء ، لكنني رأيتها عندما يكون هناك بالفعل علامة. وبالمثل ، لقد تصرفت مع مربع اختيار فارغ يلبي المستخدم والذي يبدأ منه اختبار captcha (لم تكن هناك مشاكل تتعلق بالحساسية).
يؤدي
كانت نتيجة جميع الإجراءات الموصوفة تطبيقًا ، تم اختبار أدائه على "
محمصة الخبز ":
تجدر الإشارة إلى أن الفيديو لم يتم تصويره في المحاولة الأولى ، حيث واجهت غالبًا الحاجة لاختيار فئات غير موجودة في النموذج (على سبيل المثال ، معابر المشاة أو الدرج أو نوافذ المتاجر).
يُرجع "Google reCAPTCHA" قيمة معينة إلى الموقع ، ويوضح كيف "أنت روبوت" ، ويمكن لمسؤولي الموقع ، بدوره ، تعيين عتبة لتمرير هذه القيمة. من الممكن أن تكون عتبة captcha منخفضة نسبيًا على Toaster. هذا ما يفسر مرور البرنامج بطريقة سهلة إلى حد ما ، على الرغم من حقيقة أنه كان مخطئًا مرتين ، ولم تشاهد إشارة المرور من الصفحة الأولى وصنابير النار من الصفحة الرابعة من captcha.
بالإضافة إلى محمصة الخبز ، أجريت تجارب على
الصفحة التجريبية الرسمية لـ
reCAPTCHA . نتيجة لذلك ، لوحظ أنه بعد اكتشافات خاطئة متعددة (وغير اكتشافات) ، يصبح الحصول على اختبار captcha أمرًا بالغ الصعوبة حتى بالنسبة للشخص: فصول جديدة مطلوبة (مثل الجرارات وأشجار النخيل) ، وتظهر خلايا بدون كائنات في العينات (ألوان رتيبة تقريبًا) ويزيد عدد الصفحات بشكل كبير ، للذهاب من خلال.
كان هذا ملحوظًا بشكل خاص عندما قررت محاولة النقر فوق خلايا عشوائية في حالة عدم اكتشاف كائنات (بسبب عدم وجودها في النموذج). لذلك ، يمكننا القول بالتأكيد أن النقرات العشوائية لن تؤدي إلى حل لهذه المشكلة. للتخلص من هذا "الحظر" من قبل الفاحص ، أعدنا الاتصال بالإنترنت وقمنا بمسح بيانات المتصفح ، لأنه أصبح من المستحيل اجتياز مثل هذا الاختبار - لقد كان لا نهاية له تقريبًا!
 إذا كنت تشك في إنسانيتك ، فهذه النتيجة ممكنة.
إذا كنت تشك في إنسانيتك ، فهذه النتيجة ممكنة.تنمية
إذا كانت المقالة والتطبيق يثيران اهتمام القارئ ، فسأواصل بكل سرور تنفيذه واختباراته ووصفه الإضافي في شكل أكثر تفصيلاً.
يتعلق الأمر بإيجاد فئات ليست جزءًا من الشبكة الحالية ، مما سيؤدي إلى تحسين كفاءة التطبيق إلى حد كبير. في الوقت الحالي ، هناك حاجة ملحة للتعرف على فئات على الأقل مثل: معابر المشاة ونوافذ المتاجر والمداخن - سوف أخبرك بكيفية إعادة تدريب النموذج. خلال عملية التطوير ، قمت بعمل قائمة مختصرة للفئات الأكثر شيوعًا:
- معابر المشاة.
- صنابير الحريق
- نوافذ متجر
- أنابيب المداخن.
- السيارات؛
- الحافلات.
- إشارات المرور
- الدراجات الهوائية.
- وسائل النقل
- سلالم.
- علامات.
يمكن تحقيق تحسين جودة اكتشاف الكائنات باستخدام عدة طرز في نفس الوقت: يمكن أن يؤدي ذلك إلى انخفاض الأداء ، ولكن زيادة الدقة.
هناك طريقة أخرى لتحسين جودة اكتشاف الكائنات وهي تغيير إدخال الصورة إلى الشبكة العصبية: في الفيديو ، يمكنك أن ترى أنه عندما لا يتم اكتشاف الكائنات ، أقوم بتغيير صورة تعسفي عدة مرات (في حدود 10 بكسل أفقياً وعموديًا) ، وغالبًا ما تتيح لك هذه العملية رؤية الكائنات التي كانت في السابق لم يتم الكشف عنها.
تؤدي الزيادة في الصورة من مربع صغير إلى مربع كبير (يصل إلى 300 × 300 بكسل) أيضًا إلى اكتشاف كائنات غير مكتشفة.
 لم يتم العثور على كائنات على اليسار: المربع الأصلي مع جانب 100 بكسل. على اليمين ، تم اكتشاف حافلة: مربع مكبّر يصل إلى 300 × 300 بكسل.
لم يتم العثور على كائنات على اليسار: المربع الأصلي مع جانب 100 بكسل. على اليمين ، تم اكتشاف حافلة: مربع مكبّر يصل إلى 300 × 300 بكسل.هناك تحول مثير آخر يتمثل في إزالة الشبكة البيضاء فوق الصورة باستخدام أدوات OpenCV: من الممكن عدم اكتشاف صنبور النار في الفيديو لهذا السبب (هذه الفئة موجودة في الشبكة العصبية).
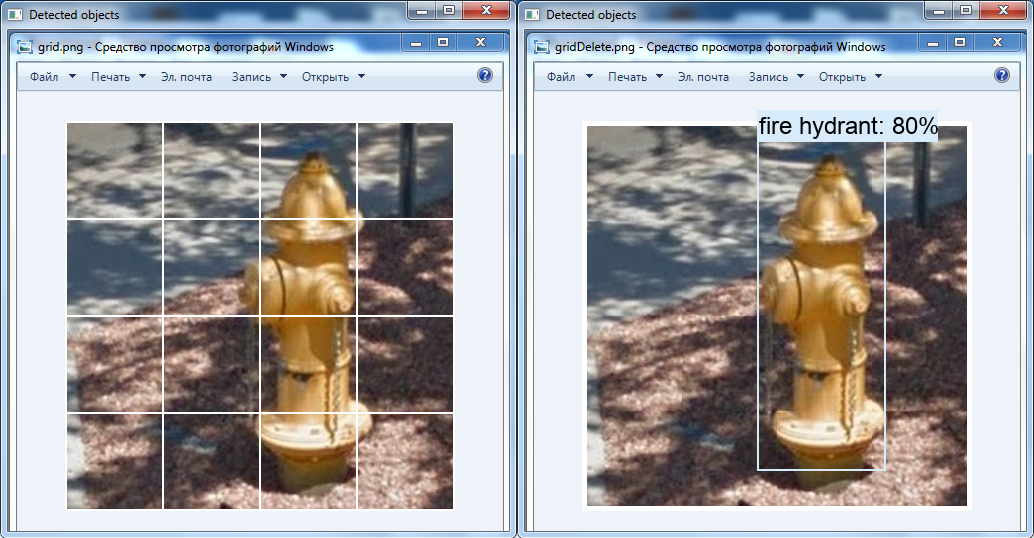 على اليسار توجد الصورة الأصلية ، وعلى اليمين الصورة التي تم تغييرها في محرر الرسومات: يتم حذف الشبكة ، ويتم نقل الخلايا إلى بعضها البعض.
على اليسار توجد الصورة الأصلية ، وعلى اليمين الصورة التي تم تغييرها في محرر الرسومات: يتم حذف الشبكة ، ويتم نقل الخلايا إلى بعضها البعض.النتائج
مع هذه المقالة ، أردت أن أخبرك أن captcha ليس على الأرجح أفضل حماية ضد برامج الروبوت ، ومن المحتمل أن تكون هناك حاجة في المستقبل القريب إلى وسائل حماية جديدة ضد الأنظمة الآلية.
يوضح النموذج الأولي المطوَّر ، حتى في حالة لم تنته بعد ، أنه مع الفئات المطلوبة في نموذج الشبكة العصبية وتطبيق التحويلات على الصور ، من الممكن تحقيق أتمتة عملية لا ينبغي أن تتم آلياً.
كذلك ، أود أن أسترعي انتباه Google إلى حقيقة أنه بالإضافة إلى طريقة التحايل على اختبار captcha الموضح في هذه المقالة ، هناك أيضًا
طريقة أخرى يتم بها
نسخ عينة صوتية. في رأيي ، من الضروري الآن اتخاذ التدابير المتعلقة بتحسين جودة منتجات البرمجيات والخوارزميات ضد الروبوتات.
من محتوى المادة وجوهرها ، قد يبدو أنني لا أحب Google ، ولا سيما reCAPTCHA ، لكن هذا بعيد عن الحال ، وإذا كان هناك تطبيق لاحق ، فسأخبرك لماذا.
تم تطويرها وإظهارها من أجل تحسين التعليم وتحسين الأساليب التي تهدف إلى ضمان أمن المعلومات.
شكرا لاهتمامكم