متابعة لموضوع مسابقات التعلم الآلي على Habré ، نريد تعريف القراء على منصتين أخريين. إنهم بالتأكيد ليسوا مثل ضخم الضحك ، لكنهم يستحقون الاهتمام بالتأكيد.

شخصيا ، أنا لا أحب kaggle أكثر من اللازم لعدة أسباب:
- أولاً ، غالبًا ما تستمر المسابقات هناك لعدة أشهر ، ويجب بذل الكثير من الجهد للمشاركة الفعالة ؛
- ثانياً ، النواة العامة (حلول عامة). ينصحهم أتباع kaggle بالهدوء مع الرهبان التبتيين ، لكن في الواقع ، من العار أن يكتشف الجميع ما ذهبت إليه لمدة شهر أو شهرين.
لحسن الحظ ، تقام مسابقات التعلم الآلي على منصات أخرى ، وستتم مناقشة مسابقتين.
| IDAO | نظام الحسابات القومية هاكاثون 2019 |
|---|
اللغة الرسمية: الإنجليزية ،
المنظمون: ياندكس ، سبيربنك ، HSE | اللغة الرسمية: الروسية ،
المنظمون: مجموعة Mail.ru |
جولة عبر الإنترنت: 15 يناير - 11 فبراير 2019 ؛
النهائي في الموقع: 4-6 أبريل 2019 | عبر الإنترنت - من 7 فبراير إلى 15 مارس ؛
غير متصل بالإنترنت - من 30 مارس إلى 1 أبريل. |
من مجموعة معينة من البيانات على جسيم في مصادم هادرون كبير (على المسار ، والزخم ، وغير ذلك من المعلمات المادية المعقدة إلى حد ما) ، حدد ما إذا كان هو muon أم لا
من هذا البيان ، تم تمييز مهمتين:
- في واحدة كان عليك فقط إرسال تنبؤك ،
- وفي الجانب الآخر - تم فرض الكود والنموذج الكامل للتنبؤ ، والقيود الصارمة بدلاً من ذلك على وقت التنفيذ واستخدام الذاكرة | للمنافسة SNA Hackathon ، تم جمع سجلات لإظهار المحتوى من المجموعات المفتوحة في موجز الأخبار المستخدم فبراير-مارس 2018. اختبرت مجموعة الاختبار الأسبوع الماضي ونصف مارس. يحتوي كل إدخال في السجل على معلومات حول ما تم عرضه له وكذلك حول كيفية تفاعل المستخدم مع هذا المحتوى: ضع "فئة" أو علق أو تم تجاهله أو تم إخفاؤه من الخلاصة.
يكمن جوهر مهام SNA Hackathon في الترتيب لكل شريط على الشبكة الاجتماعية لـ Odnoklassniki ، مع رفع أعلى مستوى ممكن من الوظائف التي ستحصل على "الفصل".
في المرحلة عبر الإنترنت ، تم تقسيم المهمة إلى 3 أجزاء:
1. لتصنيف المشاركات على مجموعة متنوعة من الأسباب التعاونية
2. ترتيب المشاركات من الصور الواردة فيها
3. لتصنيف المشاركات وفقا للنص الوارد فيها |
| مقياس مخصص معقد ، مثل ROC-AUC | متوسط ROC-AUC من قبل المستخدمين |
جوائز المرحلة الأولى - قمصان للأماكن N ، والانتقال إلى المرحلة الثانية ، حيث تم دفع الإقامة والوجبات خلال المسابقة
المرحلة الثانية - ؟؟؟ (لسبب ما ، لم أكن حاضراً في حفل توزيع الجوائز ولم أستطع معرفة ما انتهيت إليه للحصول على الجوائز). أجهزة الكمبيوتر المحمولة الموعودة لجميع أعضاء الفريق الفائز | جوائز المرحلة الأولى - قمصان لأفضل 100 مشارك ، والانتقال إلى المرحلة الثانية ، حيث دفعوا ثمن السفر إلى موسكو والإقامة والوجبات خلال المسابقة. أيضًا ، في نهاية المرحلة الأولى ، تم الإعلان عن جوائز لأفضل 3 مهام في المرحلة الأولى: فاز الجميع على بطاقة الفيديو RTX 2080 TI!
المرحلة الثانية هي الفريق الأول ، وكان للفرق من 2 إلى 5 أشخاص ، الجوائز:
المركز الأول - 300000 روبل
المركز الثاني - 200000 روبل
المركز الثالث - 100000 روبل
جائزة لجنة التحكيم - 100 000 روبل |
| المجموعة الرسمية في البرق ، حوالي 190 مشاركًا ، التواصل باللغة الإنجليزية ، اضطررت إلى الانتظار لعدة أيام للإجابة على الأسئلة | المجموعة الرسمية في البرق ، ~ 1500 مشارك ، مناقشة نشطة للمهام بين المشاركين والمنظمين |
| قدم المنظمون حلين أساسيين ، بسيط ومتقدم. تتطلب واحدة بسيطة أقل من 16 جيجابايت من ذاكرة الوصول العشوائي ، في حين أن واحدة متقدمة من 16 لا تناسب. في الوقت نفسه ، مع التقدم قليلاً ، فشل المشاركون في تجاوز الحل المتقدم بشكل ملحوظ. لم تكن هناك صعوبات في إطلاق هذه الحلول. تجدر الإشارة إلى أنه في المثال المتقدم كان هناك تعليق مع تلميح من أين نبدأ في تحسين الحل. | تم توفير حلول بدائية أساسية لكل مهمة ، تم تجاوزها بسهولة من قبل المشاركين. في الأيام الأولى للمسابقة ، واجه المشاركون العديد من الصعوبات: أولاً ، تم تقديم البيانات بتنسيق Apache Parquet ، ولم تعمل جميع مجموعات Python ومجموعة الباركيه دون أخطاء. الصعوبة الثانية كانت ضخ الصور من سحابة البريد ، في الوقت الحالي لا توجد طريقة سهلة لتنزيل كمية كبيرة من البيانات في وقت واحد. ونتيجة لذلك ، أدت هذه المشكلات إلى تأخير المشاركين لبضعة أيام. |
IDAO. المرحلة الاولى
كانت المهمة هي تصنيف جسيمات الميون / غير الميون وفقًا لخصائصها. كانت الميزة الرئيسية لهذه المهمة هي وجود عمود للوزن في بيانات التدريب ، والذي فسره المنظمون أنفسهم على أنهم ثقة في إجابة هذا السطر. كانت المشكلة أن بعض الأسطر تحتوي على أوزان سلبية.
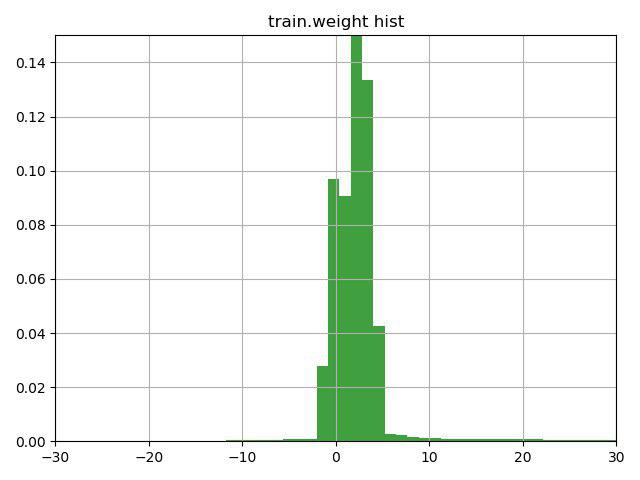
بعد التفكير لبضع دقائق عبر الخط مع تلميح (لفتت الإشارة إلى هذه الميزة في عمود الوزن) وبناء هذا الرسم البياني ، قررنا التحقق من 3 خيارات:
1) عكس الهدف للصفوف مع الوزن السلبي (والوزن ، على التوالي)
2) قم بتحويل الأوزان إلى الحد الأدنى للقيمة ، بحيث تبدأ في 0
3) لا تستخدم الأوزان للصفوف
تبين أن الخيار الثالث هو الأسوأ ، لكن الخياران الأولان حسّنا النتيجة ، وكان الأفضل هو الخيار رقم 1 ، الذي أوصلنا على الفور إلى المركز الثاني الحالي في المهمة الأولى والأولى في الثانية.

كانت الخطوة التالية هي إلقاء نظرة على البيانات الخاصة بالقيم المفقودة. لقد أعطانا المنظمون بالفعل بيانات تمشيط ، حيث كانت هناك بعض القيم المفقودة ، وتم استبدالهم بـ -9999.
لقد وجدنا قيمًا مفقودة في الأعمدة MatchHit_ {X، Y، Z} [N] و MatchHit_D {X، Y، Z} [N] ، وفقط عندما تكون N = 2 أو 3. كما فهمنا ، فإن بعض الجسيمات لم تطير عبر جميع أجهزة الكشف الأربعة ، وتوقفت في إما 3 أو 4 لوحة. احتوت البيانات أيضًا على أعمدة Lextra_ {X، Y} [N] ، والتي تصف على ما يبدو نفس الشيء باسم MatchHit_ {X ، Y ، Z} [N] ، ولكن باستخدام نوع من الاستقراء. اقترحت هذه التخمينات الضئيلة أنه بدلاً من القيم المفقودة في MatchHit_ {X ، Y ، Z} [N] ، يمكنك استبدال Lextra_ {X، Y} [N] (فقط لإحداثيات X و Y). MatchHit_Z [N] كانت مليئة بشكل جيد بمتوسط. سمحت لنا هذه التلاعب بالذهاب إلى مكان واحد متوسط لكلتا المهمتين.

بالنظر إلى أن النصر في المرحلة الأولى لم يقدم أي شيء ، يمكننا التوقف عند هذا ، لكننا واصلنا ، ورسمنا بعض الصور الجميلة وصنعنا ميزات جديدة.

على سبيل المثال ، وجدنا أنه إذا قمنا ببناء نقاط تقاطع الجسيمات من كل من اللوحات الأربعة للكاشفات ، يمكننا أن نرى أن النقاط على كل من اللوحات يتم تجميعها في 5 مستطيلات مع نسبة عرض إلى ارتفاع من 4 إلى 5 والمركز عند (0،0) ، و المستطيل الأول لا يوجد لديه نقاط.
| لوحة رقم / أبعاد المستطيل | 1 | 2 | 3 | 4 | 5 |
|---|
| لوحة 1 | 500h625 | 1000h1250 | 2000h2500 | 4000h5000 | 8000h10000 |
| لوحة 2 | 520h650 | 1040h1300 | 2080h2600 | 4160h5200 | 8320h10400 |
| لوحة 3 | 560h700 | 1120h1400 | 2240h2800 | 4480h5600 | 8960h11200 |
| لوحة 4 | 600h750 | 1200h1500 | 2400h3000 | 4800h6000 | 9600h12000 |
بعد تحديد هذه الأحجام ، أضفنا لكل فئة من الخصائص الجسيمية 4 الجديدة - رقم المستطيل الذي يتقاطع فيه مع كل لوحة.
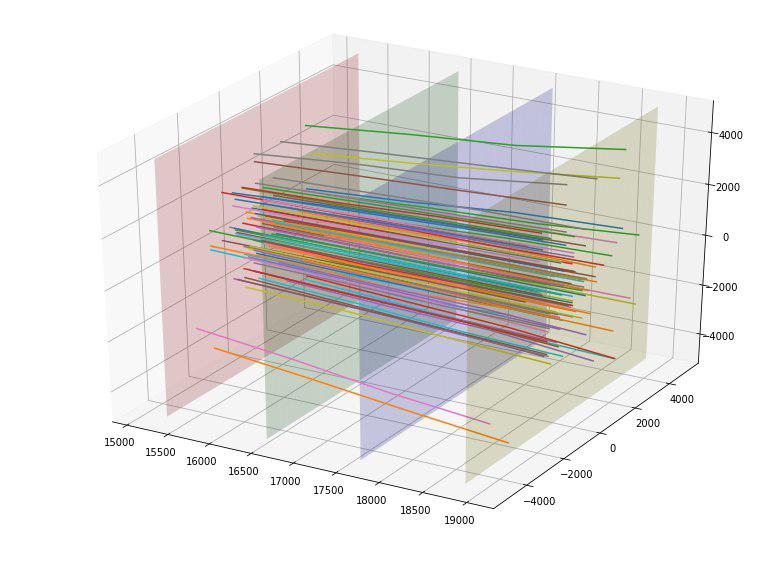
لاحظنا أيضًا أن الجسيمات تبدو وكأنها منتشرة بعيدًا عن المركز ، وقد طرحت الفكرة لتقييم "نوعية" هذا الانتثار بطريقة أو بأخرى. من الناحية المثالية ، على الأرجح ، يمكن للمرء الخروج بنوع من القطع المكافئة "المثالية" اعتمادًا على نقطة الدخول وتقدير الانحراف عنها ، لكننا قصرنا على الخط "المثالي". من خلال بناء مثل هذه الخطوط المثالية لكل نقطة دخول ، تمكنا من حساب الانحراف المتوسط المربع لمسار كل جسيم من هذا الخط. نظرًا لأن متوسط الانحراف للهدف = 1 كان 152 ، والهدف = 0 تحول إلى 390 ، فقد صنفنا هذه الميزة مبدئيًا بأنها جيدة. في الواقع ، هذه الميزة ضربت على الفور الجزء العلوي من الأكثر فائدة.
لقد سعدنا ، وأضفنا انحراف جميع نقاط التقاطع الأربعة لكل جسيم عن الخط المثالي كميزات إضافية 4 (كما أنها عملت بشكل جيد).
تشير الروابط إلى المقالات العلمية حول موضوع المسابقة ، التي قدمها لنا المنظمون ، إلى أننا بعيدون عن أول من حل هذه المشكلة ، وربما هناك بعض البرامج المتخصصة. بعد اكتشاف المستودع على جيثب حيث تم تنفيذ طرق IsMuonSimple و IsMuon و IsMuonLoose ، قمنا بنقلها إلى أنفسنا مع تعديلات طفيفة. كانت الأساليب نفسها بسيطة للغاية: على سبيل المثال ، إذا كانت الطاقة أقل من عتبة ، فإن هذه ليست موونًا ، وإلا فإن الميون. من الواضح أن مثل هذه العلامات البسيطة لا يمكن أن تعطي زيادة في حالة استخدام التدرج اللوني ، لذلك أضفنا علامة أخرى "المسافة" إلى العتبة. هذه الميزات تحسنت أيضا قليلا. ربما ، بعد تحليل الأساليب الحالية بشكل أكثر شمولاً ، يمكن للمرء إيجاد طرق أقوى وإضافتها إلى السمات.
قرب نهاية المسابقة ، قمنا بسحب حل "سريع" قليلاً للمهمة الثانية ، ونتيجة لذلك ، فقد كان يختلف عن الأساس في النقاط التالية:
- في الصفوف ذات الوزن السلبي ، تم قلب الهدف
- مملوءة بالقيم المفقودة في MatchHit_ {X، Y، Z} [N]
- انخفاض عمق إلى 7
- معدل التعلم المنخفض إلى 0.1 (كان 0.19)
نتيجةً لذلك ، جربنا بعض الميزات الإضافية (غير الناجحة بشكل خاص) ، واستخلصنا المعلمات و catboost المدربين و lightgbm و xgboost ، جربنا مزيجًا مختلفًا من التنبؤات وفزنا بثقة بالمهمة الثانية قبل فتح التطبيق الخاص ، وكنا من بين القادة في المجموعة الأولى.
بعد فتح بريفا ، كنا في المركز العاشر لمهمة واحدة و 3 للمهمة الثانية. اختلط جميع القادة ، وكانت السرعة في بريفات أعلى من السرعة في لوحة التحرير. يبدو أن البيانات كانت طبقية سيئة (أو على سبيل المثال ، لم تكن هناك خطوط ذات أوزان سلبية في القطاع الخاص) وكان هذا محبطًا إلى حد ما.
نظام الحسابات القومية هاكاثون 2019 - النصوص. المرحلة الاولى
كانت المهمة هي تصنيف منشورات المستخدم على شبكة Odnoklassniki الاجتماعية وفقًا للنص الموجود فيها ، بالإضافة إلى النص ، كانت هناك بعض خصائص المنشور (اللغة والمالك وتاريخ الإنشاء والوقت وتاريخ العرض والوقت).
مع اقتراب المناهج الكلاسيكية للعمل مع النص ، أود تحديد خيارين:
- تعيين كل كلمة في مساحة متجه n-dimensional ، بحيث تحتوي الكلمات المشابهة على متجهات متشابهة (يمكن العثور على مزيد من التفاصيل في مقالتنا ) ، ثم إما العثور على الكلمة الوسطى للنص أو باستخدام آليات تأخذ في الاعتبار الموضع النسبي للكلمات (CNN ، LSTM / GRU) .
- باستخدام النماذج التي تكون قادرة على الفور للعمل مع جمل كاملة. على سبيل المثال ، بيرت. من الناحية النظرية ، يجب أن يعمل هذا النهج بشكل أفضل.
بما أن هذه كانت أول تجربة لي مع النصوص ، فسيكون من الخطأ تعليم شخص ما ، لذلك سأعلم نفسي. هذه هي النصائح التي سأقدمها لنفسي في بداية المسابقة:
- قبل الركض لتعلم شيء ما ، انظر إلى البيانات! بالإضافة إلى النصوص نفسها ، كان هناك العديد من الأعمدة في البيانات ، وأكثر من ذلك بكثير يمكن استبعادها منها. أبسط شيء هو القيام بترميز الهدف لجزء من الأعمدة.
- لا تتعلم من كل البيانات! كان هناك الكثير من البيانات (حوالي 17 مليون صف) وكان اختياريًا تمامًا لاستخدامها جميعًا لاختبار الفرضيات. كان التدريب والمعالجة البطيئة بطيئًا جدًا ، وكان من الواضح أن لديّ وقت لاختبار الفرضيات الأكثر إثارة للاهتمام.
- < مشورة مثيرة للجدل > لا حاجة للبحث عن نموذج قاتل. لقد تعاملت مع Elmo و Bert لفترة طويلة ، على أمل أن يقودني على الفور إلى مكان مرتفع ، ونتيجة لذلك استخدمت حفلات الزفاف المدربة مسبقًا على FastText للغة الروسية. مع Elmo ، لم يكن من الممكن تحقيق سرعة أفضل ، لكن مع Bert لم أتمكن من معرفة ذلك.
- < مشورة مثيرة للجدل > لا تبحث عن ميزة قاتل واحد. بالنظر إلى البيانات ، لاحظت أنه في منطقة 1 في المائة من النصوص لا تحتوي ، في الواقع ، على النص! ولكن بعد ذلك ، كانت هناك روابط لبعض الموارد ، وقد كتبت محللًا بسيطًا فتح الموقع وأخرج الاسم والوصف. يبدو أنها فكرة جيدة ، لكنني بعد ذلك ، قررت تحليل جميع الروابط لجميع النصوص ، وفقدت الكثير من الوقت مرة أخرى. كل هذا لم يعطي تحسنا كبيرا في النتيجة النهائية (على الرغم من أنني اكتشفت مع stemming ، على سبيل المثال).
- الميزات الكلاسيكية العمل. جوجل ، على سبيل المثال ، "ميزات النص kaggle" ، وقراءة وإضافة كل شيء. أعطى TF-IDF تحسينًا وميزات إحصائية ، مثل طول النص ، الكلمة ، مقدار علامات الترقيم ، أيضًا.
- إذا كانت هناك أعمدة DateTime ، فيجب عليك تحليلها في العديد من الميزات المنفصلة (ساعات ، أيام الأسبوع ، إلخ). الميزات التي يجب تسليط الضوء عليها ينبغي تحليلها باستخدام الرسوم البيانية / بعض المقاييس. هنا فعلت كل ما هو صواب على حدس وحددت الميزات الضرورية ، لكن التحليل العادي لن يضر (على سبيل المثال ، كما فعلنا في النهاية).
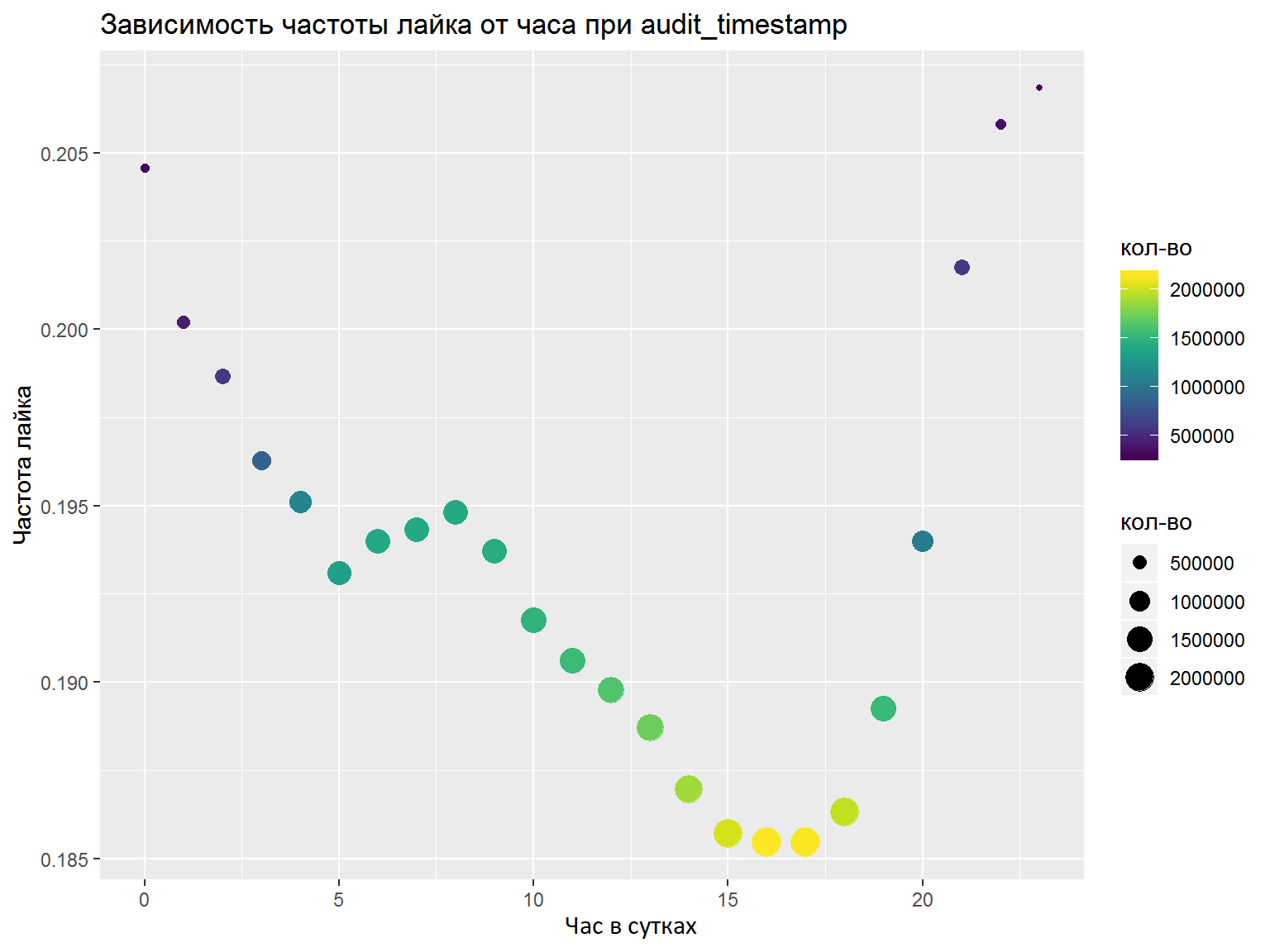
كنتيجة للمنافسة ، قمت بتدريب طراز keras مع الإلتواء وفقًا للكلمات ، ونموذجًا آخر يعتمد على LSTM و GRU. سواء كانت هناك أو كانت تستخدم حفلات الزفاف FastText المدربة مسبقا للغة الروسية (حاولت عددا من حفلات الزفاف الأخرى ، ولكن هذه منها عملت بشكل أفضل). بعد أن بلغ متوسط التوقعات ، أخذت المركز السابع النهائي من بين 76 مشاركًا.
بالفعل بعد المرحلة الأولى ، تم نشر مقال بقلم نيكولاي أنوخين ، الذي احتل المركز الثاني (شارك في المنافسة) ، وتم تكرار قراره حتى مرحلة ما ، لكنه ذهب إلى أبعد من ذلك بسبب آلية اهتمام قيمة الاستعلام.
المرحلة الثانية موافق و IDAO
أقيمت المراحل الثانية من المسابقات تقريبًا على التوالي ، لذلك قررت التفكير فيها معًا.
أولاً ، مع الفريق الذي تم الاستحواذ عليه حديثًا ، انتهى بي الأمر في مكتب Mail.ru المثير للإعجاب ، حيث كانت مهمتنا هي الجمع بين نماذج المسارات الثلاثة من المرحلة الأولى - النصوص والصور والتعليقات. تم تخصيص أكثر من يومين بقليل لهذا ، والذي تبين أنه صغير جدًا. في الواقع ، يمكننا فقط تكرار نتائج المرحلة الأولى ، دون الحصول على أي مكسب من الجمعية. نتيجةً لذلك ، احتلنا المركز الخامس ، لكن تعذر استخدام نموذج النص. بالنظر إلى قرارات المشاركين الآخرين ، يبدو أن الأمر يستحق محاولة تجميع النصوص وإضافتها إلى نموذج collab. كان من الآثار الجانبية لهذه المرحلة الانطباعات الجديدة والمعارف والتواصل مع المشاركين والمنظمين اللطيفين ، وكذلك قلة النوم ، والتي قد أثرت على نتائج المرحلة النهائية لـ IDAO.
كانت المهمة في المرحلة الشخصية من IDAO 2019 Final هي التنبؤ بوقت الانتظار لطلب سائقي سيارات الأجرة من Yandex في المطار. في المرحلة 2 ، تم تخصيص 3 مهام = 3 مطارات. لكل مطار ، يتم تقديم بيانات في الدقيقة عن عدد طلبات سيارات الأجرة لمدة ستة أشهر. وفي الشهر التالي ، أعطيت بيانات الطلب لكل دقيقة خلال الأسبوعين الماضيين كبيانات اختبار. لم يكن هناك ما يكفي من الوقت (1.5 يومًا) ، كانت المهمة محددة تمامًا ، حيث جاء شخص واحد فقط من الفريق إلى المسابقة - ونتيجة لذلك ، كان المكان المحزن أقرب إلى النهاية. من بين الأفكار المثيرة للاهتمام ، كانت هناك محاولات لاستخدام البيانات الخارجية: الطقس ، الاختناقات المرورية والإحصاءات المتعلقة بطلبات سيارات الأجرة في ياندكس. على الرغم من أن المنظمين لم يذكروا ما هي المطارات ، إلا أن العديد من المشاركين أشاروا إلى أنهم شيريميتيفو ، دوموديدوفو وفنوكوفو. على الرغم من أن هذا الافتراض قد تم دحضه بعد المنافسة ، إلا أن الميزات ، على سبيل المثال ، من بيانات الطقس لموسكو قد أدت إلى تحسين النتيجة سواء على التحقق من صحة أو على المتصدرين.
استنتاج
- مسابقات ML هي باردة ومثيرة للاهتمام! هناك تطبيق للمهارات في تحليل البيانات ، وفي النماذج والتقنيات الماكرة ، والحس السليم هو موضع ترحيب.
- ML هو بالفعل طبقة ضخمة من المعرفة التي يبدو أنها تنمو أضعافا مضاعفة. حددت لنفسي هدف التعرف على مناطق مختلفة (إشارات وصور وجداول ونص) وأدركت بالفعل مقدار التعلم. على سبيل المثال ، بعد هذه المسابقات ، قررت أن أدرس: خوارزميات التجميع ، والتقنيات المتقدمة للعمل مع مكتبات تدرج التدرج (على وجه الخصوص ، العمل مع CatBoost على GPU) ، وشبكات الكبسولة ، وآلية اهتمام قيمة مفتاح الاستعلام.
- ليس kaggle واحد! هناك العديد من المسابقات الأخرى حيث من الأسهل على الأقل الحصول على قميص ، وهناك فرص أكبر لجوائز أخرى.
- التواصل! في مجال التعلم الآلي وتحليل البيانات ، يوجد بالفعل مجتمع كبير ، وهناك مجموعات موضوعية في البرقية والركود والأشخاص الجادين من Mail.ru و Yandex وغيرها من الشركات للإجابة على الأسئلة ومساعدة المبتدئين ومواصلة رحلتهم في هذا المجال من المعرفة.
- أنصح كل من هو مشبع بالفقرة السابقة بزيارة datafest - مؤتمر كبير مجاني في موسكو ، والذي سيعقد في الفترة من 10 إلى 11 مايو.