ما زلنا نتحدث عن مشاريع الربيع hackathon DevDays ، والتي شارك فيها طلاب برنامج الماجستير
"هندسة البرمجيات / هندسة البرمجيات" .

بالمناسبة ، نريد دعوة القراء للانضمام إلى
مجموعة VK للقضاة . سننشر فيه آخر الأخبار حول التوظيف والدراسة. يمكن أيضًا العثور على الفيديو من اليوم المفتوح في المجموعة. نذكركم: سيتم عقد الحدث في 29 أبريل ، وتفاصيل
على الموقع .
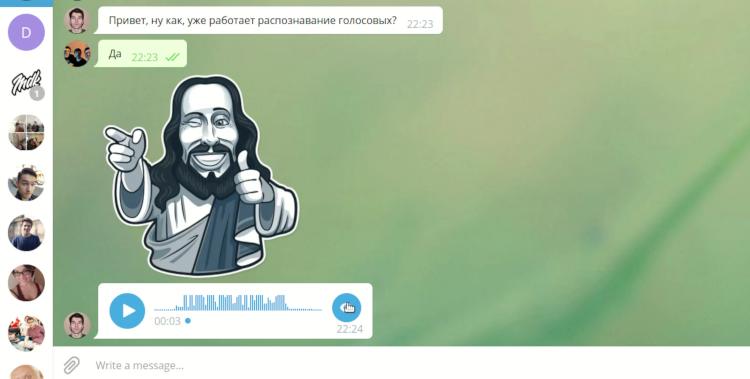
محلل الرسائل الصوتية في برقية سطح المكتب
 مؤلف الفكرة
مؤلف الفكرةخوروشيف أرتيوم
تكوين الفريقخوروشيف أرتيم - مدير المشروع / المطور / ضمان الجودة
إليزيف أنتون - محلل أعمال / أخصائي تسويق
Kuklina Maria - مصمم / مطور واجهة المستخدم
Bakhvalov Pavel - مصمم UI / المطور / QA
من وجهة نظرنا ، يعد Telegram رسولًا حديثًا ومريحًا ، وإصداره الشخصي معروف ومفتوح المصدر ، لذلك من الممكن تعديله. يقدم العميل وظائف غنية إلى حد ما. بالإضافة إلى الرسائل النصية القياسية ، تحتوي على مكالمات صوتية ورسائل فيديو ورسائل صوتية. وهذه الأخيرة هي التي تزعج أحيانًا متلقيها. في كثير من الأحيان لا توجد وسيلة للاستماع إلى رسالة صوتية أثناء وجوده على جهاز كمبيوتر أو كمبيوتر محمول. قد تتداخل الضوضاء المحيطة ، ونقص سماعات الرأس ، أو لا تريد أن يسمع أي شخص محتويات الرسالة. لا تحدث مثل هذه المشكلات تقريبًا إذا كنت تستخدم البرقيات على هاتفك الذكي ، لأنه يمكنك فقط توصيلها إلى أذنك ، على عكس الكمبيوتر المحمول أو الكمبيوتر الشخصي. حاولنا حل هذه المشكلة.
كان هدف مشروعنا في DevDays هو إضافة القدرة على ترجمة الرسائل الصوتية المستلمة إلى نص في عميل Telegram Desktop (يشار إليه فيما يلي باسم Telegram Desktop).
جميع النظائر في الوقت الحالي عبارة عن روبوتات يمكنك إرسال رسالة صوتية إليها ، وفي المقابل تتلقى رسالة نصية. هذا ليس ملائمًا للغاية بالنسبة لنا: إعادة توجيه رسالة إلى الروبوت ليس ملائمًا للغاية ، أود الحصول على وظائف أصلية. بالإضافة إلى ذلك ، أي روبوت هو طرف ثالث يعمل كوسيط بين API التعرف على الكلام والمستخدم ، وهذا على الأقل غير آمن.
كما ذُكر سابقًا ، يتميز تطبيق telegram-desktop بميزتين للوزن: الخفة والسرعة. وهذا ليس صدفة ، لأنه مكتوب بالكامل في C ++. وبما أننا قررنا إضافة وظائف جديدة مباشرةً إلى العميل ، فقد اضطررنا إلى تطويرها في C ++.

كان هناك 4 أشخاص في فريقنا. في البداية ، كان اثنان يبحثان عن مكتبة مناسبة للتعرف على الكلام ، ودرس شخص واحد الكود المصدري لـ Telegram-desktop ، وآخر كان ينشر مشروع مشروع
Telegram Desktop . في وقت لاحق ، كان الجميع مشغولًا بإصلاحات واجهة المستخدم وتصحيح الأخطاء.
يبدو أن تنفيذ الوظيفة المقصودة لن يكون صعبًا ، ولكن ، كما هو الحال دائمًا ، نشأت صعوبات.
يتكون حل المشكلة من مهمتين فرعيتين مستقلتين: اختيار الوسائل المناسبة للتعرف على الكلام وتنفيذ واجهة المستخدم للوظائف الجديدة.
عند اختيار مكتبة للتعرف على الصوت ، اضطررنا على الفور إلى التخلي عن جميع واجهات برمجة التطبيقات (API) غير المتصلة بالإنترنت ، لأن نماذج اللغة تشغل مساحة كبيرة. لكن هذه لغة واحدة فقط. أصبح من الواضح أنه سيتعين عليك استخدام واجهة برمجة التطبيقات على الإنترنت. لاحقًا ، تبين أن خدمات التعرف على الكلام الخاصة بعمالقة مثل Google و Yandex و Microsoft ليست مجانية على الإطلاق ، وعلينا أن نكون راضين عن فترة تجريبية. نتيجةً لذلك ، تم اختيار Google Speech-To-Text ، لأنه يتيح لك الحصول على رمز مميز لاستخدام الخدمة ، التي ستستمر لمدة عام كامل.
المشكلة الثانية التي واجهناها ترتبط ببعض عيوب C ++ - حديقة حيوانات المكتبات المختلفة في غياب مستودع مركزي. لقد حدث أن Telegram Desktop يعتمد على العديد من المكتبات الأخرى ذات الإصدارات المحددة. يحتوي المستودع الرسمي على
تعليمات لبناء المشروع. وأيضًا عدد كبير من المشكلات المفتوحة حول مشاكل البناء ، على سبيل المثال ،
مرة واحدة ومرتين . تبين أن جميع المشكلات كانت مرتبطة بحقيقة أن البرنامج النصي للبناء قد كتب لأوبونتو 14.04 ، ولكي أقوم ببناء البرقية بنجاح تحت Ubuntu 18.04 ، كان علي إجراء تغييرات.
يستغرق تطبيق Telegram Desktop نفسه بعض الوقت: على جهاز كمبيوتر محمول به Intel Core i5-7200U ، يستغرق التجميع الكامل (علامة -j 4) مع كل التبعيات حوالي ثلاث ساعات. من هذه ، يستغرق الأمر حوالي 30 دقيقة لربط العميل نفسه (فيما بعد تبين أنه في تكوين Debug ، يستغرق الارتباط حوالي 10 دقائق) ، ولكن يجب تكرار خطوة الارتباط في كل مرة بعد إجراء التغييرات.
على الرغم من المشكلات ، فقد نجحنا في تطبيق فكرتنا ، وكذلك تحديث
البرنامج النصي للبناء لأوبونتو 18.04. مظاهرة العمل يمكن أن ينظر إليه
هنا . نحن نطبق أيضا العديد من الرسوم المتحركة. لقد ظهر زر بالقرب من جميع الرسائل الصوتية ، مما يسمح لك بترجمة الرسالة إلى نص. عند النقر بزر الماوس الأيمن ، يمكنك تحديد اللغة التي سيتم استخدامها للترجمة اختياريًا. العميل متاح للتحميل
عبر الرابط .
مستودع.في رأينا ، حصلنا على وظيفة Proof of Concept الجيدة التي ستكون ملائمة للعديد من المستخدمين. نأمل أن نرى ذلك في الإصدارات المستقبلية من Telegram Desktop.
دعم اللغة الطبيعية الموسعة في IntelliJ IDEA
 مؤلف الفكرة
مؤلف الفكرةالدبابات فلاديسلاف
تكوين الفريقTanks Vladislav (قائد الفريق ، يعمل مع LanguageTool و IntelliJ IDEA)
Sokolov Nikita (العمل مع LanguageTool وإنشاء واجهة مستخدم)
Hvorov Alexander (العمل مع LanguageTool وتحسين الأداء)
Sadovnikov Alexander (دعم تحليل لغات الترميز والرمز)
لقد قمنا بتطوير مكون إضافي لبرنامج IntelliJ IDEA يقوم بمراجعة النصوص المختلفة (التعليقات والوثائق ، الخطوط الحرفية في التعليمات البرمجية ، النص المنسق في Markdown أو XML) من أجل الدقة النحوية والإملائية والأسلوبية (يسمى هذا باللغة الإنجليزية تصحيح التجارب المطبعية).
كانت فكرة المشروع هي توسيع التدقيق الإملائي القياسي IntelliJ IDEA إلى مقياس نحوي ، لعمل نوع من القواعد النحوية داخل IDE.
يمكنك إلقاء نظرة على ما حدث من
خلال النقر على الرابط .
حسنًا ، أدناه سنتحدث أكثر عن قدرات المكون الإضافي ، وكذلك حول الصعوبات التي نشأت أثناء إنشائه.
حافزهناك العديد من المنتجات المصممة لكتابة النصوص باللغات الطبيعية ، ولكن يتم كتابة الوثائق والتعليقات على الكود في معظم الأحيان في بيئات التطوير. في الوقت نفسه ، تقوم IDEs بعمل رائع للعثور على أخطاء في كتابة التعليمات البرمجية ، ولكن يتم تكييفها بشكل سيء للنصوص باللغات الطبيعية. لهذا السبب ، من السهل جدًا ارتكاب أخطاء في قواعد اللغة أو علامات الترقيم أو النمط ، ولن تشير بيئة التطوير إليهم. من الأهمية بمكان ارتكاب خطأ في كتابة واجهة المستخدم ، حيث سيؤثر ذلك ليس فقط على شمولية الشفرة ، ولكن أيضًا على مستخدمي التطبيق المطوَّر نفسه.
تعد IntelliJ IDEA واحدة من أكثر بيئات التطوير شهرة وتطوراً ، بالإضافة إلى IDEs القائمة على منصة IntelliJ. يحتوي IntelliJ Platform بالفعل على مدقق إملائي مضمن ، إلا أنه لا يوفر حتى أبسط الأخطاء النحوية. قررنا دمج أحد أنظمة تحليل اللغة الطبيعية الشائعة في IntelliJ IDEA.
تطبيق
لم نضع أنفسنا مهمة إنشاء نظامنا الخاص للتحقق من النصوص ، لذلك استفدنا من الحل الحالي. كان الخيار الأنسب هو
LanguageTool . لقد سمح لنا الترخيص باستخدامه مجانًا لأغراضنا: فهو مجاني ومكتوب بلغة Java ويوضع في مصدر مفتوح. بالإضافة إلى ذلك ، يدعم 25 لغة وقد تم تطويره لأكثر من خمسة عشر عامًا. على الرغم من انفتاحها ، تعتبر LanguageTool منافسًا جادًا لحلول التحقق من النصوص المدفوعة ، وحقيقة أنها قادرة على العمل محليًا هي حرفتها القاتلة.
رمز البرنامج المساعد في
المستودع على جيثب . تمت كتابة المشروع بالكامل في Kotlin مع إضافة صغيرة من Java لـ UI. خلال hackathon ، تمكنت من تنفيذ الدعم ل Markdown و JavaDoc و HTML و Plain Text. بعد hackathon ، أضاف تحديث كبير دعم XML ، سلسلة الأحرف في Java و Kotlin و Python ، وكذلك التدقيق الإملائي.
الصعوباتبسرعة كبيرة ، أدركنا أننا إذا قمنا بتغذية كل النص في كل مرة لفحص LanguageTool ، فإن واجهة IDEA ستعلق على أي نصوص أكثر أو أقل خطورة ، لأن التفتيش نفسه يحظر دفق واجهة المستخدم. تم حل المشكلة من خلال التحقق من "ProgressManager.checkCancelled" - هذه الوظيفة تلقي استثناءً إذا رأت IDEA أنه يجب مقاطعة الفحص.
أدى هذا إلى التخلص من حالات تعليق البيانات تمامًا ، لكن من المستحيل استخدامه: لقد تمت معالجة النص لفترة طويلة جدًا. علاوة على ذلك ، في حالتنا ، غالبًا ما يتغير جزء صغير جدًا من النص وأريد تخزين النتائج مؤقتًا بطريقة أو بأخرى. هذا ما فعلناه. حتى لا نتحقق من كل شيء في كل مرة ، قمنا بتقسيم النص بشكل قطعي إلى أجزاء وفحصنا فقط تلك التي تغيرت. نظرًا لأن النصوص يمكن أن تكون كبيرة ولا ترغب في تحميل ذاكرة التخزين المؤقت ، فقد قمنا بتخزين النصوص نفسها ، ولكن لم يتم تخزينها. سمح هذا للمكون الإضافي بالعمل بسلاسة حتى في الملفات الكبيرة.
يدعم LanguageTool أكثر من 25 لغة ، لكن يكاد لا يحتاجها مستخدم واحد. كنت أرغب في إعطاء الفرصة لتنزيل المكتبات بلغة معينة عند الطلب (إذا تم تحديدها بواسطة علامة في واجهة المستخدم). لقد قمنا بتنفيذها ، لكن اتضح أنها معقدة للغاية ولا يمكن الاعتماد عليها. على وجه الخصوص ، اضطررنا إلى تحميل LanguageTool بمجموعة جديدة من اللغات كمحمل فصل دراسي منفصل ، ثم قم بتهيئتها بعناية. في الوقت نفسه ، كانت جميع المكتبات في مستودع المستخدم .m2 ، وفي كل مرة كان علينا التحقق من سلامتها. في النهاية ، قررنا أنه إذا واجه المستخدمون مشكلات في حجم المكون الإضافي ، فسنوفر مكونًا إضافيًا منفصلاً للعديد من اللغات الأكثر شيوعًا.
بعد الاختراقانتهى الاختراق ، ولكن استمر العمل على المكون الإضافي بتكوين أضيق. أردت دعم الخطوط والتعليقات وحتى بنيات اللغة ، مثل أسماء المتغيرات والفئات. هذه الخدمة مدعومة حاليًا فقط لجافا و Kotlin و Python ، لكننا نأمل أن تنمو هذه القائمة. لقد أصلحنا العديد من الأخطاء الصغيرة وأصبحنا أكثر توافقًا مع المدقق الإملائي المدمج في Idea. بالإضافة إلى ذلك ، ظهرت دعم XML والتدقيق الإملائي. كل هذا يمكن العثور عليه في الإصدار الثاني الذي نشرناه مؤخرًا.
ما التالي؟يمكن أن يكون هذا المكون الإضافي مفيدًا ليس فقط للمطورين ، ولكن أيضًا للكتاب التقنيين (يعمل كثيرًا ، على سبيل المثال ، مع XML في IDE). كل يوم يتعين عليهم العمل مع اللغة الطبيعية ، دون الحاجة إلى مساعد في شكل نصائح المحرر حول الأخطاء المحتملة. يوفر الملحق الخاص بنا مثل هذه التلميحات ويقوم بذلك بدرجة عالية من الدقة.
نحن نخطط لتطوير البرنامج المساعد عن طريق إضافة لغات جديدة واستكشاف النهج العام لتنظيم التحقق من صحة النص. في المستقبل القريب ، يقوم تطبيق ملفات تخصيص الأنماط (مجموعات من القواعد التي تحدد دليل الأنماط للنص ، على سبيل المثال ، "لا تكتب على سبيل المثال ، ولكن اكتب النموذج الكامل") ، وتوسيع القاموس وتحسين واجهة المستخدم (على وجه الخصوص ، نريد أن نمنح المستخدم القدرة على عدم تجاهل الكلمة فحسب ، ولكن له في القاموس ، مشيرا إلى جزء من الكلام).