في الآونة الأخيرة ، في مجموعة ABBYY للتعرف ، نستخدم الشبكات العصبية بشكل متزايد في العديد من المهام. جيد جداً لقد أثبتوا أنهم في المقام الأول لأنواع معقدة من الكتابة. في المشاركات السابقة ، تحدثنا عن كيفية استخدامنا للشبكات العصبية للتعرف على النصوص اليابانية والصينية والكورية.
 الرد على التعرف على الشخصيات اليابانية والصينية الشخصية الكورية الاعتراف آخر
الرد على التعرف على الشخصيات اليابانية والصينية الشخصية الكورية الاعتراف آخرفي كلتا الحالتين ، استخدمنا الشبكات العصبية لاستبدال طريقة التصنيف لرمز واحد تمامًا. تضمنت كل الأساليب العديد من الشبكات المختلفة ، وشملت بعض المهام الحاجة إلى العمل بشكل كافٍ على الصور التي ليست رموزًا. يجب أن يشير النموذج في هذه المواقف بطريقة ما إلى أننا لسنا رمزًا. اليوم سنتحدث فقط عن السبب الذي قد يكون ذلك ضروريًا من حيث المبدأ ، وعن الأساليب التي يمكن استخدامها لتحقيق التأثير المطلوب.
حافز
ما هي المشكلة؟ لماذا العمل على الصور التي ليست أحرف منفصلة؟ يبدو أنه يمكنك تقسيم جزء من سلسلة إلى أحرف وتصنيفها جميعًا وجمع النتيجة من هذا ، على سبيل المثال ، في الصورة أدناه.
نعم ، على وجه التحديد في هذه الحالة ، يمكن فعل ذلك حقًا. ولكن ، للأسف ، فإن العالم الحقيقي أكثر تعقيدًا ، وفي الممارسة العملية ، عند إدراكك ، يتعين عليك التعامل مع التشوهات الهندسية وطمس البقع والبقع والصعوبات الأخرى.
نتيجة لذلك ، غالبًا ما يتعين عليك التعامل مع هذه الأجزاء:
أعتقد أنه من الواضح للجميع ما هي المشكلة. وفقًا لمثل هذه الصورة من جزء ما ، ليس من السهل تقسيمها بشكل لا لبس فيه إلى رموز منفصلة من أجل التعرف عليها بشكل فردي. علينا أن نطرح مجموعة من الفرضيات حول مكان الحدود بين الأحرف ، ومكان الحروف نفسها. لهذا ، نستخدم ما يسمى رسم بياني تقسيم خطي (GLD). في الصورة أعلاه ، يظهر هذا الرسم البياني في الأسفل: القطاعات الخضراء هي أقواس GLD المشيدة ، أي الفرضيات حول مكان وجود الرموز الفردية.
وبالتالي ، فإن بعض الصور التي يتم تشغيل وحدة التعرف على الأحرف الفردية بها ، في الواقع ، ليست أحرف فردية ، ولكنها أخطاء تجزئة. ويجب أن تشير هذه الوحدة نفسها إلى أن أمامها ، على الأرجح ، ليس رمزًا ، مما يعيد الثقة المنخفضة لجميع خيارات التعرف. وإذا لم يحدث هذا ، في النهاية ، يمكن اختيار الخيار الخاطئ لتقسيم هذه القطعة حسب الرموز ، مما سيزيد بشكل كبير عدد أخطاء التقسيم الخطي.
بالإضافة إلى أخطاء التجزئة ، يجب أن يكون النموذج أيضًا مقاومًا لقمامة سابقة من الصفحة. على سبيل المثال ، يمكن أيضًا إرسال هذه الصور للتعرف على شخصية واحدة:
إذا قمت ببساطة بتصنيف هذه الصور إلى أحرف منفصلة ، فسوف تندرج نتائج التصنيف في نتائج التعرف. علاوة على ذلك ، في الواقع ، هذه الصور هي مجرد قطع أثرية لخوارزمية الترميز الثنائي ، لا ينبغي أن يقابلها شيء في النتيجة النهائية. لذلك بالنسبة لهم ، أيضًا ، يجب أن تكون قادرًا على استعادة الثقة المنخفضة في التصنيف.
كل الصور المشابهة: أخطاء تجزئة ، بيانات غير مسبوقة ، إلخ. سوف يطلق علينا فيما يلي أمثلة سلبية. سوف يطلق على صور الرموز الحقيقية أمثلة إيجابية.
مشكلة نهج الشبكة العصبية
الآن دعنا نتذكر كيف تعمل الشبكة العصبية العادية للتعرف على الحروف الفردية. عادة ما يكون هذا نوعًا من الطبقات التلافيفية والمتصلة تمامًا ، حيث يتم تشكيل متجه احتمالات الانتماء لكل فئة معينة من صورة الإدخال.
علاوة على ذلك ، يتزامن عدد الفصول مع حجم الأبجدية. أثناء تدريب الشبكة العصبية ، يتم تقديم صور الرموز الحقيقية وتعليمها لإرجاع احتمال كبير لفئة الرموز الصحيحة.
وماذا سيحدث إذا تم تغذية الشبكة العصبية بأخطاء تجزئة وفضلات سابقة؟ في الواقع ، من الناحية النظرية البحتة ، يمكن أن يحدث أي شيء ، لأن الشبكة لم تر مثل هذه الصور على الإطلاق في عملية التعلم. بالنسبة لبعض الصور ، قد يكون الحظ محظوظًا ، وستعود الشبكة باحتمالية منخفضة لجميع الفئات. لكن في بعض الحالات ، قد تبدأ الشبكة في البحث بين القمامة عند مدخل الخطوط العريضة المألوفة لرمز معين ، على سبيل المثال ، الرمز "A" والتعرف عليها باحتمال 0.99.
في الممارسة العملية ، عندما عملنا ، على سبيل المثال ، على نموذج شبكة عصبية للكتابة اليابانية والصينية ، أدى استخدام الاحتمال الخام من إخراج الشبكة إلى ظهور عدد كبير من أخطاء التجزئة. وعلى الرغم من أن النموذج الرمزي يعمل بشكل جيد جدًا على أساس الصور ، لم يكن من الممكن دمجه في خوارزمية التعرف الكامل.
قد يتساءل شخص ما: لماذا بالضبط مع الشبكات العصبية تنشأ مثل هذه المشكلة؟ لماذا لم يعمل مصنفو السمات بنفس الطريقة ، لأنهم درسوا أيضًا على أساس الصور ، مما يعني أنه لم تكن هناك أمثلة سلبية في عملية التعلم؟
الفرق الأساسي ، في رأيي ، هو في كيفية تمييز العلامات بدقة عن الصور الرمزية. في حالة المصنف المعتاد ، يصف الشخص نفسه كيفية استخراجها ، مسترشداً ببعض المعرفة بجهازه. في حالة الشبكة العصبية ، يعد استخراج المعالم أيضًا جزءًا مدربًا من النموذج: يتم تكوينه بحيث يمكن التمييز بين الشخصيات والفئات المختلفة بأفضل طريقة. وفي الممارسة العملية ، اتضح أن الخصائص التي وصفها شخص ما هي أكثر مقاومة للصور التي ليست رموزًا: فهي أقل احتمالًا لتكون مماثلة لصور الرموز الحقيقية ، مما يعني أنه يمكن إرجاع قيمة ثقة أقل إليهم.
تعزيز الاستقرار النموذجي مع فقدان المركز
لأن المشكلة ، وفقًا لشكوكنا ، كانت كيفية اختيار الشبكة العصبية للعلامات ، قررنا محاولة تحسين هذا الجزء بالذات ، أي تعلم كيفية إبراز بعض العلامات "الجيدة". في التعلم العميق ، يوجد قسم منفصل مخصص لهذا الموضوع ، ويسمى "تعلم التمثيل". قررنا أن نجرب مختلف الأساليب الناجحة في هذا المجال. تم اقتراح معظم الحلول لتدريب التمثيل في مشاكل التعرف على الوجوه.
يبدو أن النهج الموصوف في مقالة "أسلوب
تعليمي لتمييز الميزات في التعرف على الوجه العميق " جيد جدًا. الفكرة الرئيسية للمؤلفين: إضافة مصطلح إضافي إلى وظيفة الخسارة ، مما يقلل من المسافة الإقليدية في مساحة الميزة بين عناصر من نفس الفئة.
بالنسبة للقيم المختلفة لوزن هذا المصطلح في دالة الخسارة العامة ، يمكن للمرء الحصول على صور متنوعة في مسافات السمة:
يوضح هذا الشكل توزيع عناصر عينة الاختبار في مساحة سمة ثنائية الأبعاد. تعتبر مشكلة تصنيف الأرقام المكتوبة بخط اليد (عينة MNIST).
واحدة من الخصائص الهامة التي ذكرها المؤلفون: زيادة في القدرة على تعميم الخصائص التي تم الحصول عليها للأشخاص الذين لم يكونوا في مجموعة التدريب. كانت وجوه بعض الناس لا تزال موجودة في مكان قريب ، وكانت وجوه أناس مختلفين متباعدة.
قررنا التحقق مما إذا كانت خاصية مماثلة لاختيار الشخصية محفوظة. في هذه الحالة ، تم إرشادهم بالمنطق التالي: إذا تم تجميع جميع عناصر نفس الفئة في مساحة الميزة بشكل مضغوط بالقرب من نقطة واحدة ، فسيكون احتمال ظهور علامات الأمثلة السلبية بالقرب من نفس النقطة. لذلك ، كمعيار رئيسي للتصفية ، استخدمنا المسافة الإقليدية إلى المركز الإحصائي لفئة معينة.
لاختبار الفرضية ، أجرينا التجربة التالية: قمنا بتدريب نماذج للتعرف على مجموعة فرعية صغيرة من الأحرف اليابانية من الحروف الهجائية المقطعية (ما يسمى kana). بالإضافة إلى عينة التدريب ، درسنا أيضًا 3 قواعد صناعية من الأمثلة السلبية:
- أزواج - مجموعة من أزواج من الشخصيات الأوروبية
- تخفيضات - أجزاء من الخطوط اليابانية تقطع الفجوات ، وليس الأحرف
- لا kana - أحرف أخرى من الأبجدية اليابانية التي لا تتعلق بالمجموعة الفرعية التي تم اعتبارها
لقد أردنا مقارنة الطريقة الكلاسيكية مع وظيفة خسارة Cross Entropy والنهج مع Center Loss في قدرتها على تصفية الأمثلة السلبية. كانت معايير التصفية للأمثلة السلبية مختلفة. في حالة Cross Entropy Loss ، استخدمنا استجابة الشبكة من الطبقة الأخيرة ، وفي حالة خسارة المركز ، استخدمنا المسافة الإقليدية إلى المركز الإحصائي للفئة في مساحة السمة. في كلتا الحالتين ، اخترنا عتبة الإحصائيات المقابلة ، والتي لا يتم فيها إزالة أكثر من 3٪ من الأمثلة الإيجابية من عينة الاختبار ونظرت في نسبة الأمثلة السلبية من كل قاعدة بيانات تم إزالتها في هذه العتبة.
كما ترون ، فإن نهج "مركز الخسارة" يؤدي حقًا وظيفة أفضل في تصفية الأمثلة السلبية. علاوة على ذلك ، في كلتا الحالتين ، لم يكن لدينا صور من الأمثلة السلبية في عملية التعلم. هذا في الواقع أمر جيد للغاية ، لأنه في الحالة العامة ، فإن الحصول على قاعدة تمثيلية لجميع الأمثلة السلبية في مشكلة التعرف الضوئي على الحروف ليست مهمة سهلة.
طبقنا هذا النهج على مشكلة التعرف على الأحرف اليابانية (في المستوى الثاني من نموذج ثنائي المستوى) ، وأسعدتنا النتيجة: تم تقليل عدد أخطاء التقسيم الخطي بشكل كبير. على الرغم من أن الأخطاء قد بقيت ، إلا أنه يمكن تصنيفها بالفعل من خلال أنواع محددة: سواء أكانت أزواجًا من الأرقام أو الهيروغليفية مع رمز علامات الترقيم. بالنسبة لهذه الأخطاء ، كان من الممكن بالفعل تشكيل قاعدة تركيبية من الأمثلة السلبية واستخدامها في عملية التعلم. حول كيفية القيام بذلك ، وسيتم مناقشته أكثر.
باستخدام قاعدة الأمثلة السلبية في التدريب
إذا كان لديك بعض الأمثلة السلبية ، فمن الغباء عدم استخدامها في عملية التعلم. ولكن دعونا نفكر في كيفية القيام بذلك.
أولاً ، ضع في اعتبارك أبسط مخطط: نقوم بتجميع جميع الأمثلة السلبية في فصل منفصل وإضافة خلية عصبية أخرى إلى طبقة الإخراج المقابلة لهذه الفئة. الآن في الإخراج لدينا توزيع الاحتمالات لفئة
N + 1 . ونحن نعلم هذا الخسارة المعتادة عبر الانتروبيا.
يمكن اعتبار المعيار الذي يكون فيه المثال سالباً قيمة استجابة الشبكة الجديدة المقابلة. لكن في بعض الأحيان ، يمكن تصنيف الشخصيات الحقيقية ذات الجودة العالية على أنها أمثلة سلبية. هل من الممكن جعل الانتقال بين الأمثلة الإيجابية والسلبية أكثر سلاسة؟
في الواقع ، يمكنك محاولة عدم زيادة إجمالي عدد المخرجات ، ولكن ببساطة جعل النموذج ، عند التعلم ، يُرجع ردودًا منخفضة لجميع الفئات عند تطبيق أمثلة سلبية على المدخلات. للقيام بذلك ، لا يمكننا إضافة إخراج
N + 1st بشكل صريح إلى النموذج ، ولكن ببساطة إضافة قيمة
-max من الاستجابات لجميع الفئات الأخرى إلى العنصر
N + 1st . ثم ، عند تطبيق الأمثلة السلبية على المدخلات ، ستحاول الشبكة القيام بأكبر قدر ممكن ، مما يعني أن أقصى استجابة ستحاول جعل أقل قدر ممكن.
بالضبط مثل هذا المخطط الذي طبقناه في المستوى الأول من نموذج من مستويين لليابانيين بالاقتران مع نهج خسارة المركز في المستوى الثاني. وبالتالي ، تم تصفية بعض الأمثلة السلبية في المستوى الأول ، والبعض الآخر في الثانية. مجتمعة ، تمكنا بالفعل من الحصول على حل جاهز للتضمين في خوارزمية التعرف العام.
بشكل عام ، قد يسأل المرء أيضًا: كيفية استخدام قاعدة الأمثلة السلبية في المنهج مع Center Loss؟ اتضح أننا بطريقة ما نحتاج إلى تأجيل الأمثلة السلبية الموجودة بالقرب من المراكز الإحصائية للفئات في مساحة السمة. كيفية وضع هذا المنطق في وظيفة الخسارة؟
سمح
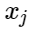
- علامات الأمثلة السلبية ، و
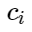
- مراكز الفصول. ثم يمكننا النظر في الإضافة التالية لوظيفة الخسارة:
هنا
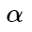
- وجود فجوة معينة مسموح بها بين المركز والأمثلة السلبية ، حيث يتم فرض عقوبة على أمثلة سلبية.
مزيج من مركز الخسارة مع المضافة المذكورة أعلاه ، قمنا بتطبيق بنجاح ، على سبيل المثال ، على بعض المصنفات الفردية في مهمة التعرف على الأحرف الكورية.
النتائج
بشكل عام ، يمكن تطبيق جميع الأساليب المتبعة لتصفية ما يسمى "الأمثلة السلبية" الموضحة أعلاه في أي مشكلات تتعلق بالتصنيف عندما يكون لديك فئة غير متوازنة بدرجة كبيرة ضمنيا بالنسبة إلى البقية دون وجود قاعدة جيدة من الممثلين ، والتي تحتاج مع ذلك إلى حساب بطريقة ما . التعرف الضوئي على الحروف هو مجرد مهمة معينة تكون فيها هذه المشكلة أكثر حدة.
بطبيعة الحال ، تنشأ كل هذه المشكلات فقط عند استخدام الشبكات العصبية كنموذج رئيسي للتعرف على الأحرف الفردية. عند استخدام التعرف على سطر من طرف إلى طرف كنموذج منفصل بالكامل ، لا تنشأ مثل هذه المشكلة.
مجموعة OCR New Technologies