مرحبا يا هبر!
نذكرك أنه بعد الكتاب على
Kafka أصدرنا عملًا مثيرًا للاهتمام بنفس القدر على مكتبة
Kafka Streams API .

حتى الآن ، لا يفهم المجتمع سوى حدود هذه الأداة القوية. لذلك ، تم نشر مقال مؤخرًا ، مع الترجمة التي نريد أن نقدمها لك. على تجربته الخاصة ، يخبر المؤلف كيفية إنشاء مستودع بيانات موزع من كافكا ستريمز. هل لديك قراءة لطيفة!
تُستخدم مكتبة Apache
Kafka Streams في جميع أنحاء العالم في المؤسسات لمعالجة التوزيع الموزع أعلى Apache Kafka. أحد الجوانب التي تم التقليل من قيمتها في هذا الإطار هو أنه يسمح لك بتخزين حالة محلية بناءً على معالجة التدفق.
في هذه المقالة ، سوف أخبرك كيف استغلت شركتنا هذه الفرصة بنجاح لتطوير منتج من أجل أمان التطبيقات السحابية. باستخدام Kafka Streams ، أنشأنا خدمات ميكروية مشتركة ، كل منها يخدمنا كمصدر للتسامح مع الأعطال ويمكن الوصول إليه بشكل كبير لمعلومات موثوقة حول حالة الكائنات في النظام. بالنسبة لنا ، هذه خطوة للأمام سواء من حيث الموثوقية وسهولة الدعم.
إذا كنت مهتمًا بنهج بديل يسمح لك باستخدام قاعدة بيانات مركزية واحدة لدعم الحالة الرسمية للكائنات الخاصة بك - اقرأ ، سيكون من المثير للاهتمام ...
لماذا اعتقدنا أن الوقت قد حان لتغيير أساليبنا في العمل مع الدولة المشتركةكنا بحاجة للحفاظ على حالة الكائنات المختلفة بناءً على تقارير الوكلاء (على سبيل المثال: هل تعرض الموقع لهجوم)؟ قبل التبديل إلى Kafka Streams ، اعتمدنا غالبًا على قاعدة بيانات مركزية واحدة (+ API service) لإدارة حالتنا. لهذا النهج عيوبه: في
المواقف الكثيفة الاستخدام للبيانات ، يتحول دعم التناسق والتزامن إلى تحد حقيقي. قد تصبح قاعدة البيانات عنق الزجاجة ، أو قد تكون في
حالة سباق وتعاني من عدم القدرة على التنبؤ.
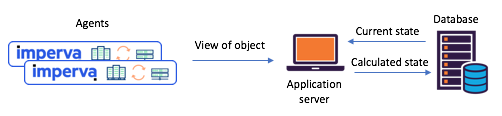 الشكل 1: سيناريو حالة انقسام نموذجية تمت مصادفته قبل الانتقال إلى
الشكل 1: سيناريو حالة انقسام نموذجية تمت مصادفته قبل الانتقال إلى
تدفقات Kafka و Kafka: يقوم الوكلاء بإبلاغ بياناتهم عبر واجهة برمجة التطبيقات ، ويتم حساب الحالة المحدثة من خلال قاعدة بيانات مركزيةتعرف على تيارات كافكا - الآن أصبح من السهل إنشاء خدمات ميكروسوفت مشتركةقبل عام تقريبًا ، قررنا مراجعة سيناريوهات الحالة المشتركة الخاصة بنا بشكل شامل من أجل التعامل مع مثل هذه المشكلات. قررنا على الفور تجربة تطبيق Kafka Streams - من المعروف مدى قابلية التوسع وقابلية التواجد والتسامح الكبير مع الخطأ ، ومدى ثراء وظائف البث (التحويلات ، بما في ذلك تلك التي تحافظ على الدولة). فقط ما نحتاجه ، ناهيك عن مدى نضج وموثوقية نظام المراسلة في كافكا.
تم بناء كل واحدة من الخدمات المجهرية المحافظة على الدولة التي أنشأناها على أساس مثيل تيارات كافكا مع طوبولوجيا بسيطة إلى حد ما. يتكون من 1) مصدر 2) معالج مع تخزين دائم للمفاتيح والقيم 3) استنزاف:
 الشكل 2: الهيكل الافتراضي لحالات البث الخاصة بنا للحصول على خدمات ميكروية دقيقة. يرجى ملاحظة أن هناك أيضًا مستودع تخزين يحتوي على بيانات تعريف التخطيط.
الشكل 2: الهيكل الافتراضي لحالات البث الخاصة بنا للحصول على خدمات ميكروية دقيقة. يرجى ملاحظة أن هناك أيضًا مستودع تخزين يحتوي على بيانات تعريف التخطيط.باستخدام هذا النهج الجديد ، يقوم الوكلاء بتكوين رسائل يتم إرسالها إلى الموضوع الأصلي ، ويقبل المستهلكون - على سبيل المثال ، خدمة إعلام عبر البريد - الحالة المشتركة المحسوبة من خلال المخزون (موضوع الإخراج).
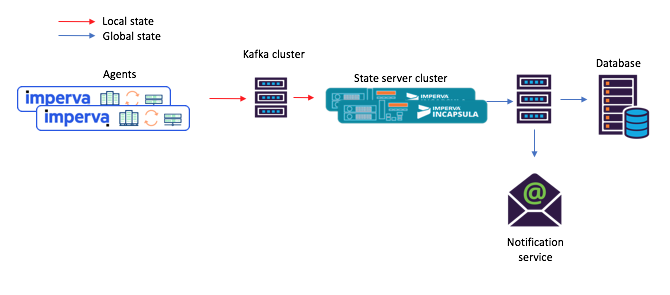 الشكل 3: مثال جديد لتدفق المهمة لسيناريو باستخدام الخدمات المصغرة المشتركة: 1) ينشئ الوكيل رسالة تصل إلى موضوع كافكا الأصلي ؛ 2) تقوم خدمة مجهرية ذات حالة مشتركة (باستخدام تدفقات كافكا) بمعالجتها وتكتب الحالة المحسوبة إلى موضوع كافكا النهائي ؛ وبعد ذلك 3) قبول المستهلكين الدولة الجديدةمهلا ، هذا مستودع المفاتيح والقيم المدمج مفيد للغاية!
الشكل 3: مثال جديد لتدفق المهمة لسيناريو باستخدام الخدمات المصغرة المشتركة: 1) ينشئ الوكيل رسالة تصل إلى موضوع كافكا الأصلي ؛ 2) تقوم خدمة مجهرية ذات حالة مشتركة (باستخدام تدفقات كافكا) بمعالجتها وتكتب الحالة المحسوبة إلى موضوع كافكا النهائي ؛ وبعد ذلك 3) قبول المستهلكين الدولة الجديدةمهلا ، هذا مستودع المفاتيح والقيم المدمج مفيد للغاية!كما ذكر أعلاه ، يحتوي طوبولوجيا الحالة المشتركة على مجموعة من المفاتيح والقيم. لقد وجدنا العديد من الخيارات لاستخدامه ، ويرد وصفان أدناه.
الخيار رقم 1: استخدام مخزن المفاتيح ومخزن القيمة لإجراء العمليات الحسابيةيحتوي مستودعنا الأول للمفاتيح والقيم على بيانات مساعدة نحتاجها لإجراء العمليات الحسابية. على سبيل المثال ، في بعض الحالات ، تم تحديد الحالة المشتركة على أساس مبدأ "تصويت الأغلبية". في المستودع ، كان من الممكن الاحتفاظ بجميع أحدث تقارير الوكلاء حول حالة كائن معين. بعد ذلك ، عند استلام تقرير جديد من أحد الوكلاء ، يمكننا حفظه ، واستخراج تقارير من جميع الوكلاء الآخرين حول حالة الكائن نفسه من المستودع ، وتكرار الحساب.
يوضح الشكل 4 أدناه كيف فتحنا الوصول إلى متجر المفاتيح والقيمة لطريقة معالجة المعالج ، حتى نتمكن من معالجة الرسالة الجديدة.
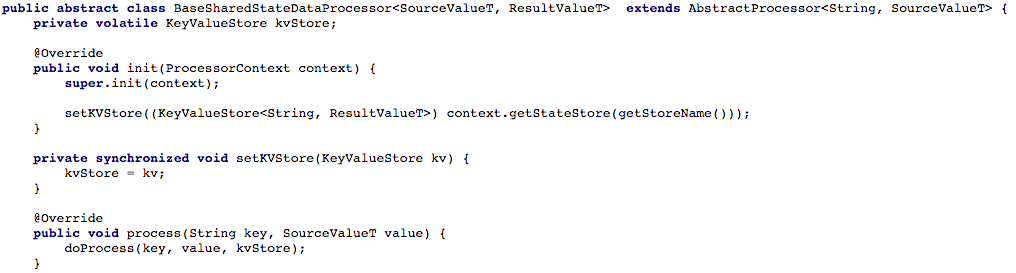 الشكل 4: نفتح الوصول إلى تخزين المفاتيح والقيم لطريقة معالجة المعالج (بعد ذلك ، في كل برنامج نصي يعمل مع حالة مشتركة ، يجب تنفيذ طريقة
الشكل 4: نفتح الوصول إلى تخزين المفاتيح والقيم لطريقة معالجة المعالج (بعد ذلك ، في كل برنامج نصي يعمل مع حالة مشتركة ، يجب تنفيذ طريقة doProcess )الخيار رقم 2: إنشاء API CRUD أعلى تدفقات Kafkaبعد ضبط التدفق الأساسي للمهام ، بدأنا في محاولة كتابة RESTful CRUD API لخدماتنا المصغرة للخدمة المشتركة. أردنا أن نكون قادرين على استخراج حالة بعض الكائنات أو جميعها ، وكذلك تعيين أو حذف حالة الكائن (هذا مفيد بدعم من جانب الخادم).
لدعم جميع واجهات برمجة تطبيقات Get State ، كلما احتجنا إلى إعادة حساب الحالة أثناء المعالجة ، وضعناها في مستودع المفاتيح والقيم المدمج لفترة طويلة. في هذه الحالة ، يصبح تطبيق واجهة برمجة التطبيقات هذه أمرًا بسيطًا للغاية باستخدام مثيل واحد من تدفقات Kafka ، كما هو موضح في القائمة أدناه:
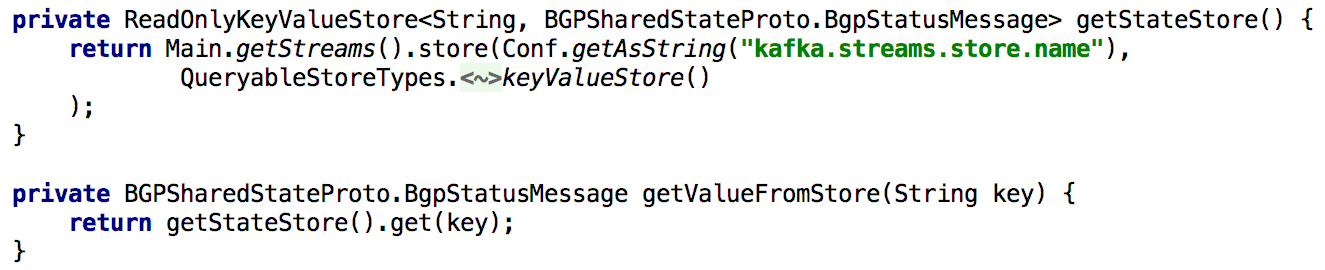 الشكل 5: استخدام التخزين المدمج في المفاتيح والقيم للحصول على حالة ما قبل حساب الكائن
الشكل 5: استخدام التخزين المدمج في المفاتيح والقيم للحصول على حالة ما قبل حساب الكائنمن السهل أيضًا تنفيذ تحديث حالة الكائن عبر واجهة برمجة التطبيقات. من حيث المبدأ ، لهذا فقط تحتاج إلى إنشاء منتج كافكا ، وبمساعدتها في إنشاء سجل يتم فيه إنشاء دولة جديدة. يضمن ذلك أن تتم معالجة جميع الرسائل التي يتم إنشاؤها من خلال واجهة برمجة التطبيقات بنفس الطريقة التي يتم تلقيها من المنتجين الآخرين (مثل الوكلاء).
 الشكل 6: يمكنك ضبط حالة الكائن باستخدام المنتج Kafkaمضاعفات بسيطة: يحتوي كافكا على العديد من الأقسام.
الشكل 6: يمكنك ضبط حالة الكائن باستخدام المنتج Kafkaمضاعفات بسيطة: يحتوي كافكا على العديد من الأقسام.بعد ذلك ، أردنا توزيع حمل المعالجة وتحسين التوافر من خلال توفير مجموعة خدمات microservice مشتركة لكل سيناريو. تم تقديم الإعداد إلينا بأقصى قدر ممكن: بعد أن قمنا بتكوين جميع المثيلات بحيث عملت مع نفس معرف التطبيق (ومع نفس خوادم التمهيد) ، تم تنفيذ كل شيء تقريبًا تلقائيًا. وضعنا أيضًا أن كل موضوع مصدر سيتألف من عدة أقسام ، بحيث يمكن تعيين كل مثيل على مجموعة فرعية من هذه الأقسام.
سوف أذكر أيضًا أنه من الطبيعي عمل نسخة احتياطية من متجر الحالة ، بحيث ، على سبيل المثال ، في حالة الاسترداد بعد الفشل ، قم بنقل هذه النسخة إلى مثيل آخر. لكل متجر حكومي في تدفقات Kafka ، يتم إنشاء موضوع منسوخ مع سجل التغيير (حيث يتم تعقب التحديثات المحلية). وهكذا ، يؤمن كافكا باستمرار المتجر الحكومي. لذلك ، في حالة فشل مثيل واحد أو آخر من تدفقات Kafka ، يمكن استعادة المتجر الرسمي بسرعة إلى مثيل آخر ، حيث ستذهب الأقسام المقابلة. أظهرت اختباراتنا أنه يمكن القيام بذلك في ثوانٍ حتى لو كان هناك ملايين السجلات في المستودع.
بالانتقال من خدمة microservice واحدة مشتركة إلى مجموعة من microservices ، يصبح تطبيق تطبيق State State أقل تافهة. في الحالة الجديدة ، يحتوي مخزن الحالة لكل خدمة microservice على جزء فقط من الصورة الكلية (تلك الكائنات التي تم تعيين مفاتيحها إلى قسم معين). كان علينا أن نحدد على أي مثيل تم احتواء حالة الكائن الذي نحتاجه ، وفعلنا ذلك بناءً على البيانات الأولية للتدفق ، كما هو موضح أدناه:
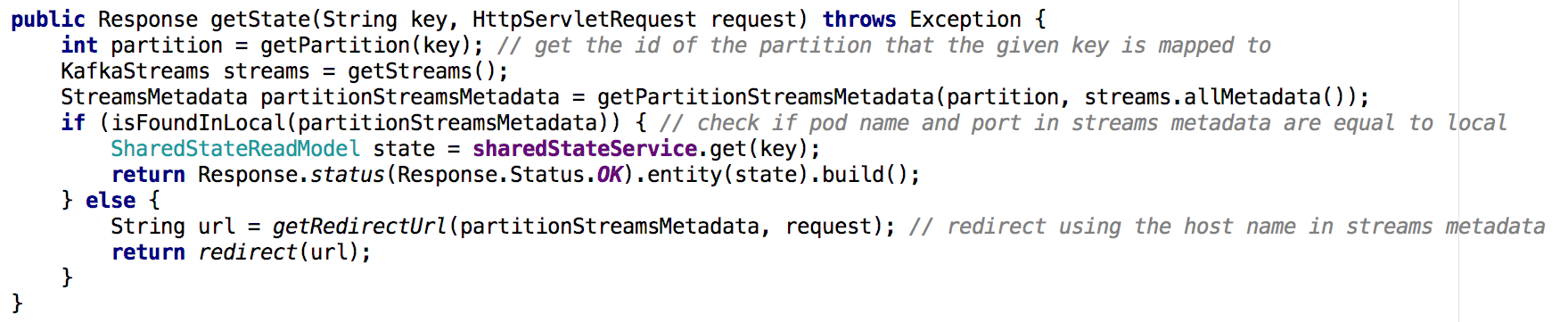 الشكل 7: باستخدام بيانات تعريف التدفق التي نحددها من أي مثيل لطلب حالة الكائن المطلوب ؛ تم استخدام نهج مماثل مع واجهة برمجة تطبيقات GET ALLالنتائج الرئيسية
الشكل 7: باستخدام بيانات تعريف التدفق التي نحددها من أي مثيل لطلب حالة الكائن المطلوب ؛ تم استخدام نهج مماثل مع واجهة برمجة تطبيقات GET ALLالنتائج الرئيسيةمخازن الدولة في كافكا ستريمز ، بحكم الواقع ، يمكن أن تكون بمثابة قاعدة بيانات موزعة ،
- تكرارها باستمرار في كافكا
- على رأس مثل هذا النظام بنيت بسهولة CRUD API
- معالجة أقسام متعددة معقدة بعض الشيء
- من الممكن أيضًا إضافة واحد أو أكثر من متاجر الحالة إلى طبولوجيا الدفق لتخزين البيانات المساعدة. يمكن استخدام هذا الخيار من أجل:
- تخزين طويل الأجل للبيانات اللازمة للحسابات في معالجة التدفق
- تخزين طويل الأجل للبيانات التي قد تكون مفيدة في المرة التالية التي يتم فيها تهيئة مثيل الدفق
- أكثر بكثير ...
بفضل هذه المزايا وغيرها ، تعد Kafka Streams رائعة لدعم المكانة العالمية في نظام موزع مثل نظامنا. أثبتت Kafka Streams أنها موثوقة للغاية في الإنتاج (منذ لحظة نشرها ، لم نفقد الرسائل عمليا) ، ونحن على يقين من أن قدراتها لا تقتصر على ذلك!