
يتفهم الجميع النصوص بشكل فريد ، بغض النظر عما إذا كان هذا الشخص يقرأ الأخبار على الإنترنت أو الروايات الكلاسيكية المعروفة عالميًا. ينطبق هذا أيضًا على مجموعة متنوعة من الخوارزميات وتقنيات التعلم الآلي ، التي تفهم النصوص بطريقة رياضية أكثر ، أي باستخدام مساحة متجهة عالية الأبعاد.
تم تخصيص هذه المقالة لتصور حفلات كلمة Word2Vec عالية الأبعاد باستخدام t-SNE. يمكن أن يكون التصور مفيدًا لفهم كيفية عمل Word2Vec وكيفية تفسير العلاقات بين المتجهات التي تم التقاطها من النصوص قبل استخدامها في الشبكات العصبية أو خوارزميات التعلم الآلي الأخرى. كبيانات تدريب ، سوف نستخدم مقالات من أخبار Google والأعمال الأدبية الكلاسيكية التي كتبها ليو تولستوي ، الكاتب الروسي الذي يعتبر أحد أعظم المؤلفين في كل العصور.
ننتقل إلى نظرة عامة مختصرة على خوارزمية t-SNE ، ثم ننتقل إلى حساب احتفالات الكلمات باستخدام Word2Vec ، وأخيرًا ، ننتقل إلى تصوُّر متجهات الكلمات باستخدام t-SNE في الفضاء ثنائي وثلاثي الأبعاد. سوف نكتب نصوصنا في بيثون باستخدام Jupyter Notebook.
T- توزيع الجار العشوائي التضمين
T-SNE هي خوارزمية تعلم آلي لتصور البيانات ، والتي تستند إلى تقنية تقليل الأبعاد غير الخطية. الفكرة الأساسية في t-SNE هي تقليل مساحة الأبعاد مع الحفاظ على المسافة النسبية بين النقاط. بمعنى آخر ، تقوم الخوارزمية بتخطيط البيانات متعددة الأبعاد إلى بعدين أو أكثر ، حيث توجد النقاط التي كانت بعيدة في البداية عن بعضها البعض ، ويتم أيضًا تحويل النقاط القريبة إلى نقاط قريبة. يمكن القول أن t-SNE تبحث عن تمثيل جديد للبيانات حيث يتم الحفاظ على علاقات الجوار. الوصف التفصيلي لمنطق t-SNE بأكمله يمكن العثور عليه في المقال الأصلي [1].
نموذج Word2Vec
بادئ ذي بدء ، يجب علينا الحصول على تمثيلات متجهة للكلمات. لهذا الغرض ، قمت بتحديد Word2vec [2] ، وهذا هو ، نموذج تنبؤي فعال من الناحية الحسابية لتعلم زخارف الكلمات متعددة الأبعاد من البيانات النصية الأولية. المفهوم الرئيسي لـ Word2Vec هو تحديد موقع الكلمات ، التي تشترك في سياقات مشتركة في مجموعة التدريب ، على مقربة من مساحة المتجه بالمقارنة مع الآخرين.
كبيانات إدخال للتصور ، سنستخدم مقالات من أخبار Google وبعض الروايات التي كتبها ليو تولستوي. تم نشر المتجهات المدربة مسبقًا على جزء من مجموعة بيانات أخبار Google (حوالي 100 مليار كلمة) بواسطة Google على
الصفحة الرسمية ، لذلك سنستخدمها.
import gensim model = gensim.models.KeyedVectors.load_word2vec_format('GoogleNews-vectors-negative300.bin', binary=True)
بالإضافة إلى النموذج الذي تم تدريبه مسبقًا ، سنقوم بتدريب نموذج آخر على روايات تولستوي باستخدام مكتبة Gensim [3]. يأخذ Word2Vec الجمل كبيانات إدخال وينتج متجهات الكلمات كإخراج. أولاً ، من الضروري تنزيل Punkt Sentence Tokenizer الذي تم تدريبه مسبقًا ، والذي يقسم النص إلى قائمة من الجمل التي تراعي اختصارات الكلمات ، والترجمات ، والكلمات ، والتي ربما تشير إلى بداية أو نهاية الجمل. بشكل افتراضي ، لا تتضمن حزمة بيانات NLTK رمز مميز لـ Punkt مُدرَّب مسبقًا على اللغة الروسية ، لذلك سنستخدم نماذج الجهات الخارجية من
github.com/mhq/train_punkt .
import re import codecs def preprocess_text(text): text = re.sub('[^a-zA-Z--1-9]+', ' ', text) text = re.sub(' +', ' ', text) return text.strip() def prepare_for_w2v(filename_from, filename_to, lang): raw_text = codecs.open(filename_from, "r", encoding='windows-1251').read() with open(filename_to, 'w', encoding='utf-8') as f: for sentence in nltk.sent_tokenize(raw_text, lang): print(preprocess_text(sentence.lower()), file=f)
في مرحلة تدريب Word2Vec ، استخدمت المعلمات الفوقية التالية:
- أبعاد متجه الميزة 200.
- الحد الأقصى للمسافة بين الكلمات التي تم تحليلها داخل الجملة هو 5.
- يتجاهل جميع الكلمات التي يقل ترددها الإجمالي عن 5 لكل مجموعة.
import multiprocessing from gensim.models import Word2Vec def train_word2vec(filename): data = gensim.models.word2vec.LineSentence(filename) return Word2Vec(data, size=200, window=5, min_count=5, workers=multiprocessing.cpu_count())
تصور حفلات الزفاف كلمة باستخدام t-SNE
T-SNE مفيد جدًا في حالة الضرورة لتصور التشابه بين الكائنات الموجودة في مساحة متعددة الأبعاد. مع مجموعة البيانات الكبيرة ، أصبح من الصعب أكثر فأكثر إنشاء مؤامرة t-SNE سهلة القراءة ، لذلك فمن الممارسات الشائعة تصور مجموعات من أكثر الكلمات تشابهًا.
دعنا نختار بضع كلمات من مفردات نموذج أخبار Google الذي تم تدريبه مسبقًا ونعد متجهات الكلمات للتصور.
keys = ['Paris', 'Python', 'Sunday', 'Tolstoy', 'Twitter', 'bachelor', 'delivery', 'election', 'expensive', 'experience', 'financial', 'food', 'iOS', 'peace', 'release', 'war'] embedding_clusters = [] word_clusters = [] for word in keys: embeddings = [] words = [] for similar_word, _ in model.most_similar(word, topn=30): words.append(similar_word) embeddings.append(model[similar_word]) embedding_clusters.append(embeddings) word_clusters.append(words)
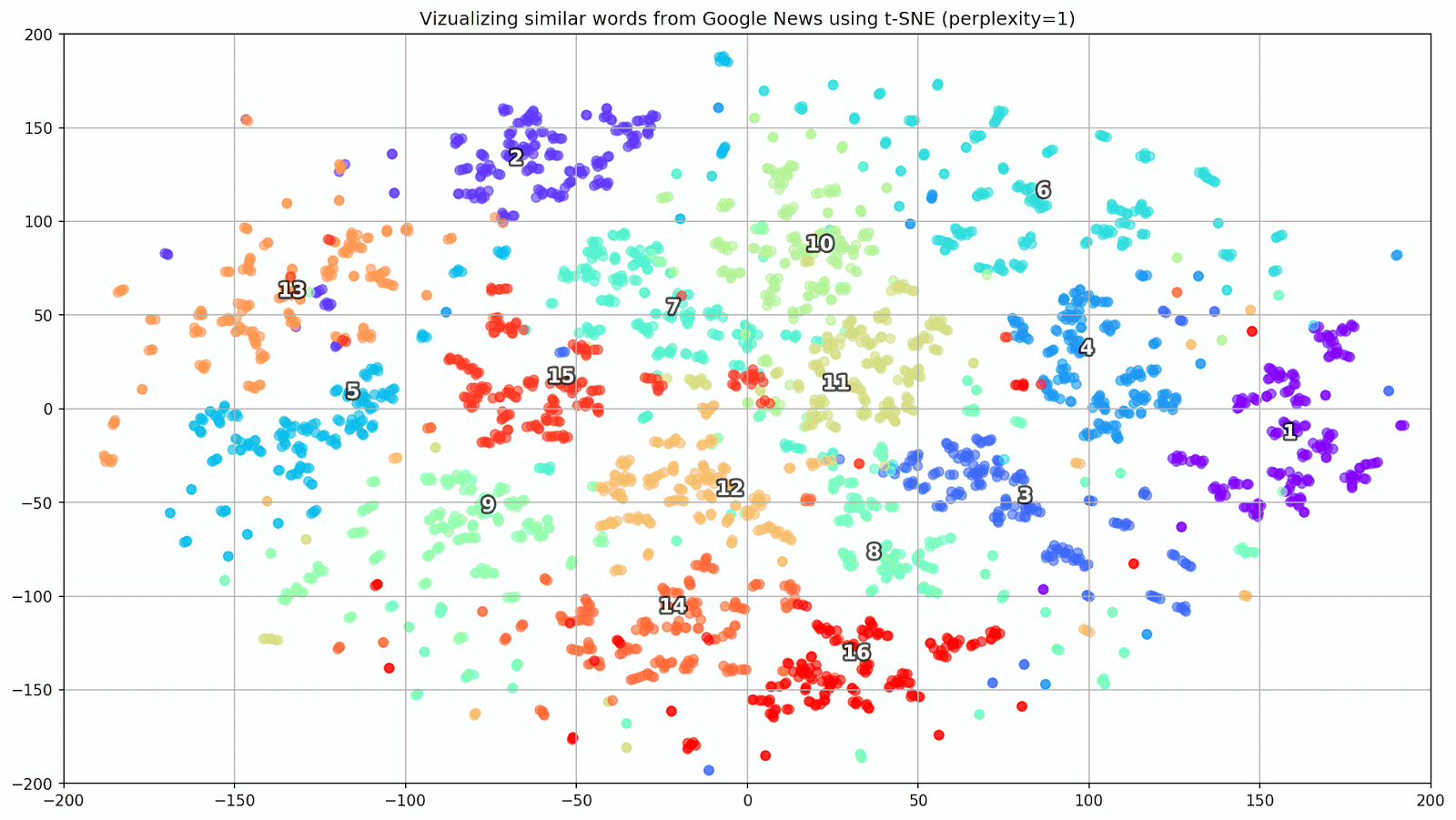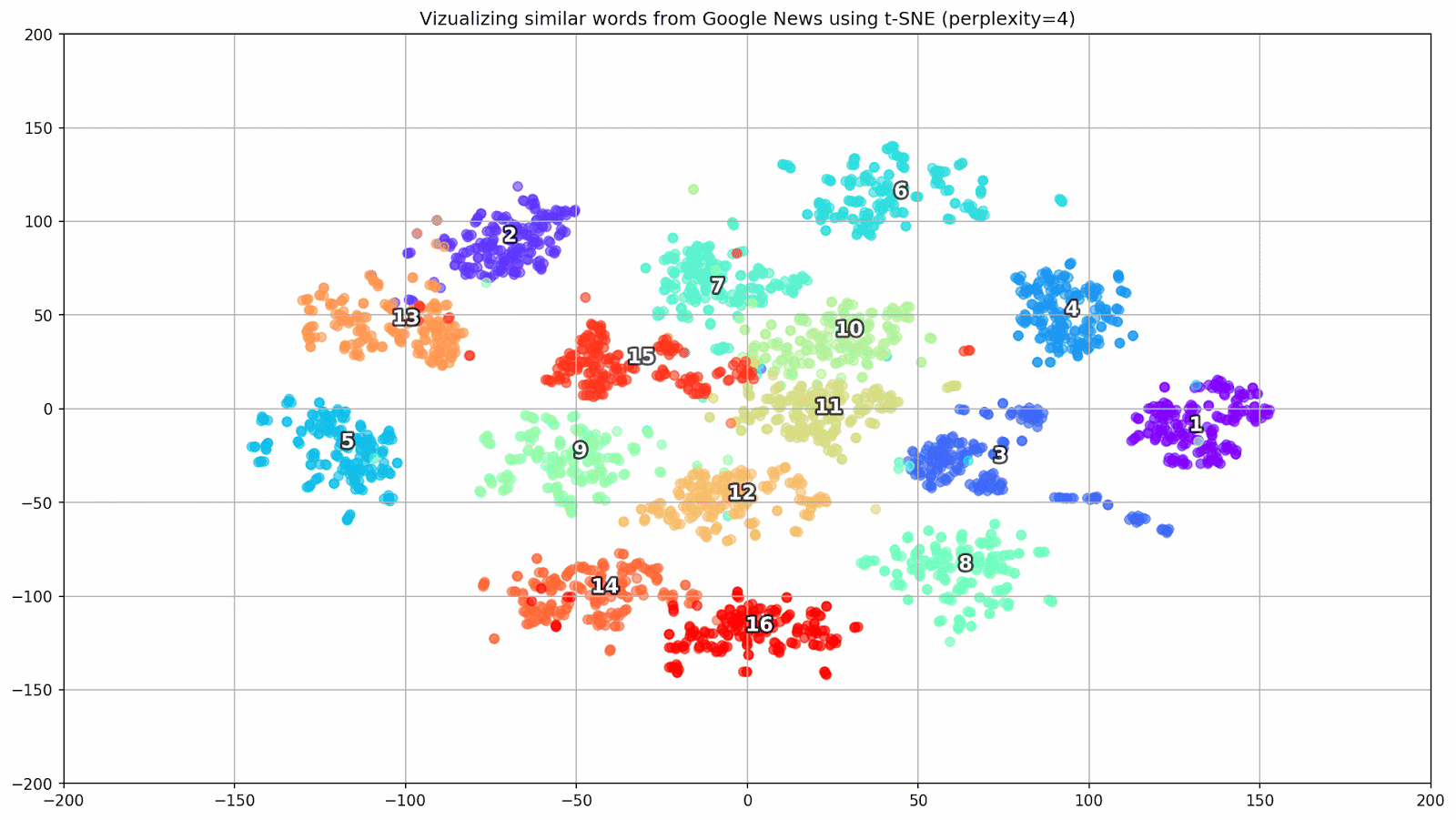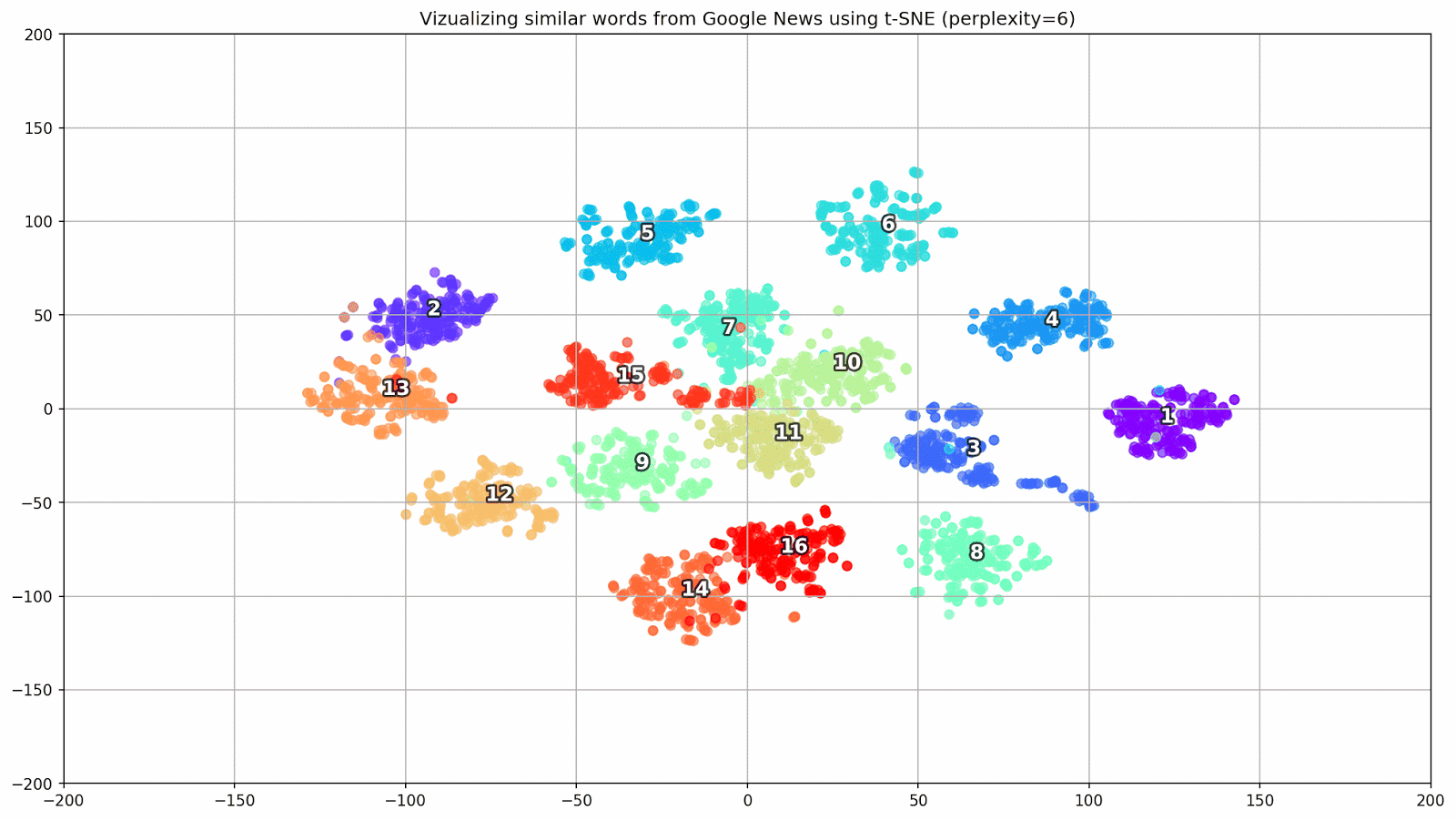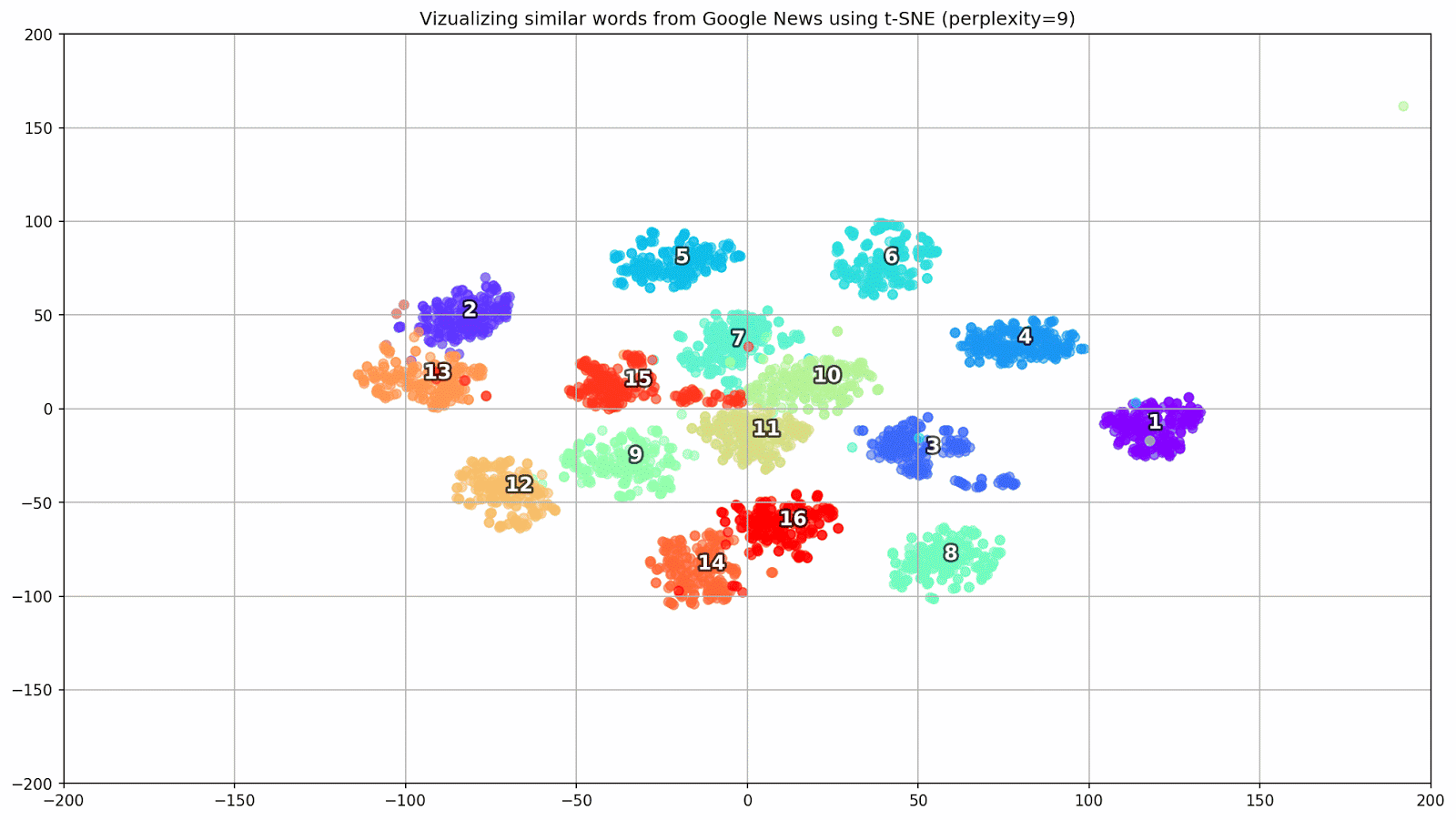 التين. 1. تأثير قيم الحيرة المختلفة على شكل مجموعات الكلمات.
التين. 1. تأثير قيم الحيرة المختلفة على شكل مجموعات الكلمات.بعد ذلك ، ننتقل إلى الجزء الرائع من هذه الورقة ، تكوين t-SNE. في هذا القسم ، ينبغي أن نولي اهتمامنا للمعايير الفوقية التالية.
- عدد المكونات ، أي بُعد مساحة الخرج.
- يمكن اعتبار قيمة الحيرة ، والتي في سياق t-SNE ، مقياسًا سلسًا لعدد الجيران الفعال. إنه مرتبط بعدد أقرب الجيران العاملين في العديد من المتعلمين الآخرين (انظر الصورة أعلاه). وفقًا لـ [1] ، يوصى بتحديد قيمة بين 5 و 50.
- نوع التهيئة الأولية لحفلات الزفاف.
tsne_model_en_2d = TSNE(perplexity=15, n_components=2, init='pca', n_iter=3500, random_state=32) embedding_clusters = np.array(embedding_clusters) n, m, k = embedding_clusters.shape embeddings_en_2d = np.array(tsne_model_en_2d.fit_transform(embedding_clusters.reshape(n * m, k))).reshape(n, m, 2)
تجدر الإشارة إلى أن t-SNE لديه وظيفة موضوعية غير محدبة ، والتي يتم تقليلها باستخدام تحسين النسب التدرج مع بدء عشوائي ، لذلك ينتج تشغيل مختلفة نتائج مختلفة قليلاً.
يمكنك العثور أدناه على برنامج نصي لإنشاء مخطط مبعثر ثنائي الأبعاد باستخدام Matplotlib ، إحدى المكتبات الأكثر شهرة لتصور البيانات في Python.
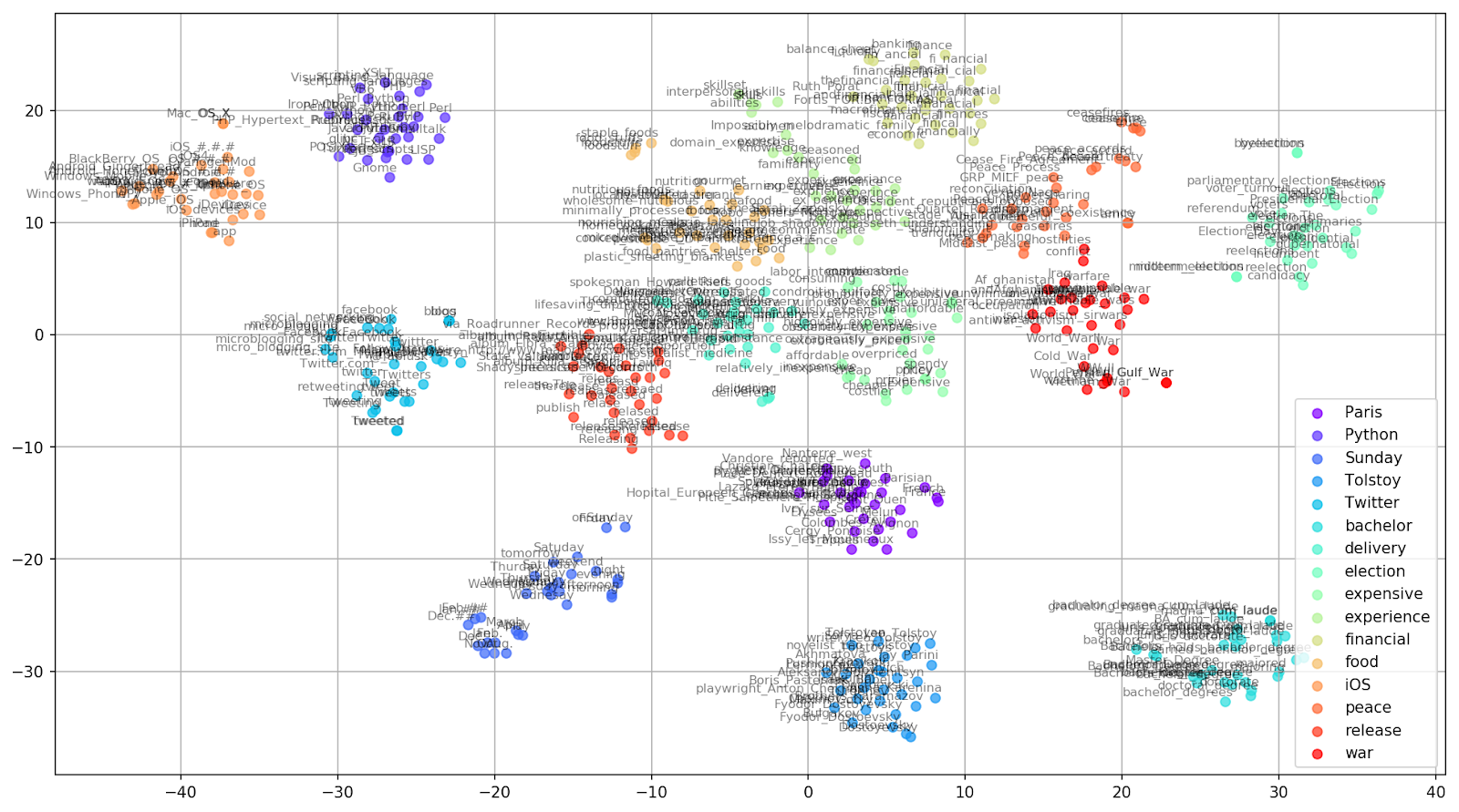 التين. 2. مجموعات من الكلمات المتشابهة من أخبار Google (preplexity = 15).
التين. 2. مجموعات من الكلمات المتشابهة من أخبار Google (preplexity = 15). from sklearn.manifold import TSNE import matplotlib.pyplot as plt import matplotlib.cm as cm import numpy as np % matplotlib inline def tsne_plot_similar_words(labels, embedding_clusters, word_clusters, a=0.7): plt.figure(figsize=(16, 9)) colors = cm.rainbow(np.linspace(0, 1, len(labels))) for label, embeddings, words, color in zip(labels, embedding_clusters, word_clusters, colors): x = embeddings[:,0] y = embeddings[:,1] plt.scatter(x, y, c=color, alpha=a, label=label) for i, word in enumerate(words): plt.annotate(word, alpha=0.5, xy=(x[i], y[i]), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom', size=8) plt.legend(loc=4) plt.grid(True) plt.savefig("f/.png", format='png', dpi=150, bbox_inches='tight') plt.show() tsne_plot_similar_words(keys, embeddings_en_2d, word_clusters)
في بعض الحالات ، قد يكون من المفيد رسم كل متجهات الكلمات في وقت واحد لرؤية الصورة كاملة. دعونا الآن نحلل آنا كارنينا ، وهي رواية ملحمية للعاطفة والمؤامرات والمآسي والخلاص.
prepare_for_w2v('data/Anna Karenina by Leo Tolstoy (ru).txt', 'train_anna_karenina_ru.txt', 'russian') model_ak = train_word2vec('train_anna_karenina_ru.txt') words = [] embeddings = [] for word in list(model_ak.wv.vocab): embeddings.append(model_ak.wv[word]) words.append(word) tsne_ak_2d = TSNE(n_components=2, init='pca', n_iter=3500, random_state=32) embeddings_ak_2d = tsne_ak_2d.fit_transform(embeddings)
def tsne_plot_2d(label, embeddings, words=[], a=1): plt.figure(figsize=(16, 9)) colors = cm.rainbow(np.linspace(0, 1, 1)) x = embeddings[:,0] y = embeddings[:,1] plt.scatter(x, y, c=colors, alpha=a, label=label) for i, word in enumerate(words): plt.annotate(word, alpha=0.3, xy=(x[i], y[i]), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom', size=10) plt.legend(loc=4) plt.grid(True) plt.savefig("hhh.png", format='png', dpi=150, bbox_inches='tight') plt.show() tsne_plot_2d('Anna Karenina by Leo Tolstoy', embeddings_ak_2d, a=0.1)
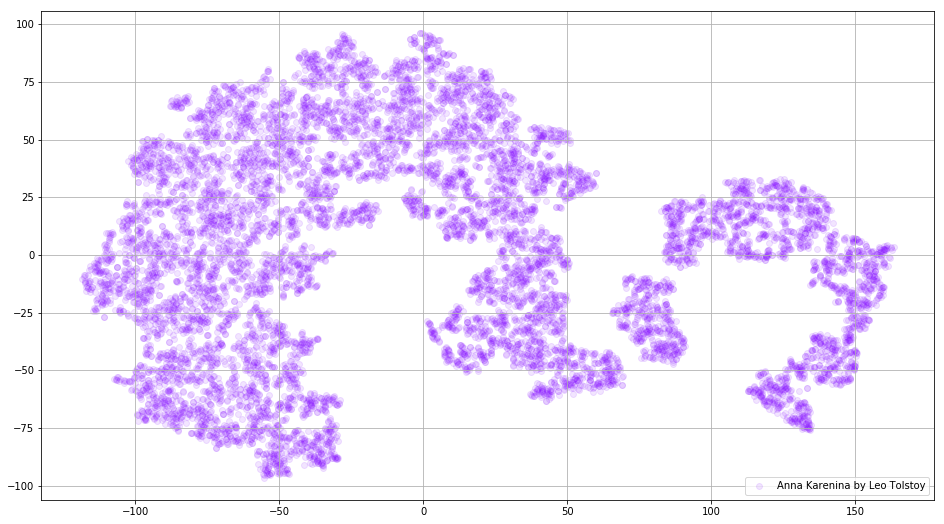
 التين. 3. تصور لنموذج Word2Vec المدربين على آنا كارنينا.
التين. 3. تصور لنموذج Word2Vec المدربين على آنا كارنينا.يمكن أن تكون الصورة بأكملها أكثر إفادة إذا قمنا بتخطيط حفلات الزفاف الأولية في مساحة ثلاثية الأبعاد. في هذا الوقت ، دعونا نلقي نظرة على الحرب والسلام ، وهي واحدة من الروايات الحيوية للأدب العالمي وأحد أعظم إنجازات تولستوي الأدبية.
prepare_for_w2v('data/War and Peace by Leo Tolstoy (ru).txt', 'train_war_and_peace_ru.txt', 'russian') model_wp = train_word2vec('train_war_and_peace_ru.txt') words_wp = [] embeddings_wp = [] for word in list(model_wp.wv.vocab): embeddings_wp.append(model_wp.wv[word]) words_wp.append(word) tsne_wp_3d = TSNE(perplexity=30, n_components=3, init='pca', n_iter=3500, random_state=12) embeddings_wp_3d = tsne_wp_3d.fit_transform(embeddings_wp)
from mpl_toolkits.mplot3d import Axes3D def tsne_plot_3d(title, label, embeddings, a=1): fig = plt.figure() ax = Axes3D(fig) colors = cm.rainbow(np.linspace(0, 1, 1)) plt.scatter(embeddings[:, 0], embeddings[:, 1], embeddings[:, 2], c=colors, alpha=a, label=label) plt.legend(loc=4) plt.title(title) plt.show() tsne_plot_3d('Visualizing Embeddings using t-SNE', 'War and Peace', embeddings_wp_3d, a=0.1)
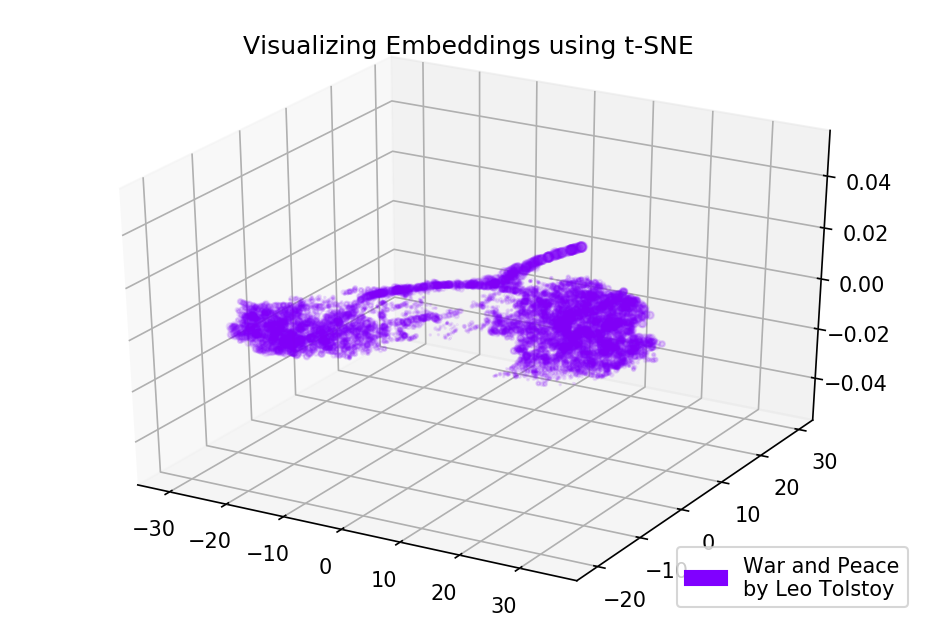 التين. 4. تصور لنموذج Word2Vec المدربين على الحرب والسلام.
التين. 4. تصور لنموذج Word2Vec المدربين على الحرب والسلام.النتائج
هذا هو ما تبدو عليه النصوص من Word2Vec و t-SNE المحتملين. لقد رسمنا مخططًا غني بالمعلومات عن الكلمات المتشابهة من أخبار Google ومخططين لروايات تولستوي. أيضًا ، هناك شيء واحد آخر وهو صور GIF! صور GIF رائعة ، لكن رسم صور GIF مماثل تقريبا للتخطيط للرسوم البيانية العادية. لذلك ، قررت عدم ذكرها في المقال ، ولكن يمكنك العثور على رمز لتوليد الرسوم المتحركة في المصادر.
شفرة المصدر متاحة في
جيثب .
تم نشر المقال في الأصل في
اتجاه نحو علم البيانات .
مراجع
- L. Maate and G. Hinton، “Visualizing data using t-SNE”، Journal of Machine Learning Research، vol. 9 ، ص. 2579-2605 ، 2008.
- T. Mikolov، I. Sutskever، K. Chen، G. Corrado and J. Dean، "Distributed تمثيل of للكلمات والعبارات وتركيبها"، Advances in Neural Information Processing Systems، pp. 3111-3119 ، 2013.
- ر. Rehurek و P. Sojka ، "إطار البرمجيات لنمذجة المواضيع مع الشركات الكبيرة" ، وقائع ورشة عمل LREC 2010 حول التحديات الجديدة لأطر البرمجة اللغوية العصبية ، 2010.